LessWrong 2.0 Reader
View: New · Old · Top← previous page (newer posts) · next page (older posts) →
← previous page (newer posts) · next page (older posts) →
Can I subscribe to your newsletter?
dr_s on Transformers Represent Belief State Geometry in their Residual StreamGiven that the model eventually outputs the next token, shouldn't the final embedding matrix be exactly your linear fit matrix multiplied by the probability of each state to output a given token? Could you use that?
dr_s on Transformers Represent Belief State Geometry in their Residual StreamThis is extremely cool! Can you go into more detail about the step used to project the 64 dimensional residual stream to 3 dimensional space? Did you do a linear fit over a few test points and then used it on all the others?
morpheus on Morpheus's ShortformCan anyone here recommend particular tools to practice grammar? Or with strong opinions on the best workflow/tool to correct grammar on the fly? I already know Grammarly and LanguageTool, but Grammarly seems steep at $30 per month when I don’t know if it is any good. I have tried GPT-4 before, but the main problems I have there, is that it is too slow and changes my sentences more than I would like (I tried to make it do that less through prompting, which did not help that much).
I notice that feeling unconfident about my grammar/punctuation leads me to write less online, especially applying for jobs or fellowships, feels more icky because of it. That seems like an avoidable failure mode.
Ideally, I would like something like the German Orthografietrainer (It was created to teach middle and high school children spelling and grammar). It teaches you on a sentence by sentence basis where to put the commas and why by explaining the sentence structure (Illustrated through additional examples). Because it trains you with particularly tricky sentences, the training is effective, and I rapidly got better at punctuation than my parents within ~3 hours. Is there a similar tool for English that I have never heard of?
While writing this, I noticed that I did not have the free version of Grammarly enabled anymore and tried the free version while writing this. One trick I noticed is that it lists what kinds of error you are making across the whole text. So it is easy to infer what particular mistake I made in which spot, and then I correct it myself. Also, Grammarly did not catch a few simple spelling and punctuation mistakes that Grammarly caught (like “anymore” or the comma at the start of this sentence.). At the end, I also tried ProWritingAid, which found additional issues. Its free version is also just $10, so I will try it first.
nathan-young on Nathan Young's ShortformI recall a comment on the EA forum about Bostrom donating a lot to global dev work in the early days. I've looked for it for 10 minutes. Does anyone recall it or know where donations like this might be recorded?
ann-brown on What's up with all the non-Mormons? Weirdly specific universalities across LLMsHope so, yeah. I'm cautiously optimistic he's doing well by his standards at least.
johnlawrenceaspden on Daniel Dennett has died (1942-2024)A Great Man and an inspiration to me and to this community and to all thinking men.
God rest his soul in peace in Paradise.
thesofakillers on Rome – ACX Meetups Everywhere Spring 2024Due to the weather, we're moving this from Saturday to Sunday. Same time same place.
cousin_it on Transformers Represent Belief State Geometry in their Residual StreamI have maybe a naive question. How much do we need to know to find the MSP image within the neural network? Is it only doable if we know the HMM to begin with? Or could it be feasible someday to inspect a neural network, find something that looks like an MSP image, and infer the HMM from it?
mir on Self-Blinded L-Theanine RCTEdit: I found the post usefwl, thankmuch!!
Mh, was gonna ask when you were taking it. I'm preparing to try it as a sleep-aid for when I adjust my polyphasic sleep-schedule (wanting to go fm 16h-cycles potentially down to 9h) bc it seems potentially drowsymaking and has much faster plasma decay-rate[1] compared to alts. This is good for polyphasic if not want drowsy aft wake.
The data in [1] concerns 100mg tablets, however, and a larger dose (eg 400mg) may be longer. The kinetic model[2] they use will prob be good estimate of plasma concentrations even if adjust dose.
Questions is whether it's good estimation for duration of action in the brain, esp given that it's "single-compartment model" (the blood is one compartment, and the brain is another). My heuristic for whether plasma T predicts brain T is whether the molecule v easily passes the BBB (as melatonin does), since then I can guess that the curve for the brain will look similar to the curve for the blood, offset slightly down and to the right.
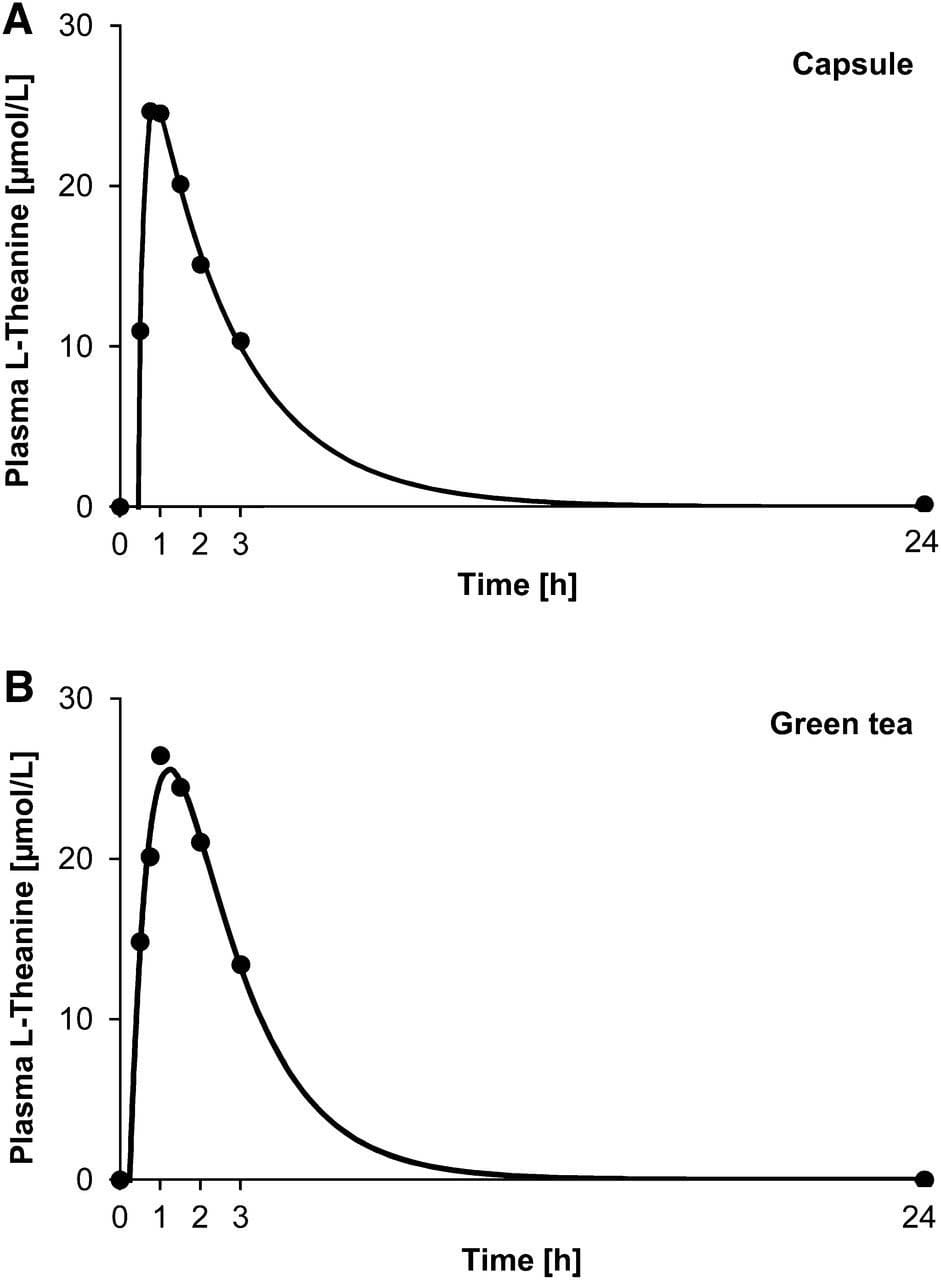
Typical concentration-time curve of plasma ʟ-theanine of one participant after intake of 100 mg ʟ-theanine via one capsule (A) or 250 mL green tea (B). Circles represent measured concentrations of ʟ-theanine. The line represents the modeled plasma concentration-time curve by the use of the 1-compartment model.
— Kinetics of ʟ-Theanine Uptake and Metabolism in Healthy Participants Are Comparable after Ingestion of ʟ-Theanine via Capsules and Green Tea, , 4 - ScienceDirect
Hot tip, you can screenshot pdf equations and ask gpt-4-turbo (updated) to write it in latex and/or jupyter-notebook-compatible python[3].
Getting a tweakable python model for it was nontrivial after 35m of trying, so i'll prob j wing it w 200mg 1h pre bedtime and do 3h sleep, and adjust bon feelings. ig the primary variable that determines how alert i feel upon waking up is getting the sleep-cycle timing right, and planning my wake-up routines (lights & text-to-speech-model as alarm) for j after I've done REM-sleep[4].
While I probably would feel alert if waking up in middle of REM-sleep (after emerging from deep), I want to avoid that bc studies show bad effects from targeted deprivation of REM (leaving other phases untouched).