AMA: Paul Christiano, alignment researcher
post by paulfchristiano · 2021-04-28T18:55:39.707Z · LW · GW · 197 commentsI'll be running an Ask Me Anything on this post from Friday (April 30) to Saturday (May 1).
If you want to ask something just post a top-level comment; I'll spend at least a day answering questions.
You can find some background about me here.
197 comments
Comments sorted by top scores.
comment by Gedusa · 2021-04-29T09:27:36.930Z · LW(p) · GW(p)
A number of people seem to have departed OpenAI at around the same time as you. Is there a particular reason for that which you can share? Do you still think that people interested in alignment research should apply to work at OpenAI?
Replies from: paulfchristiano, paulfchristiano↑ comment by paulfchristiano · 2021-04-30T18:29:41.261Z · LW(p) · GW(p)
A number of people seem to have departed OpenAI at around the same time as you. Is there a particular reason for that which you can share?
My own departure was driven largely by my desire to work on more conceptual/theoretical issues in alignment. I've generally expected to transition back to this work eventually and I think there a variety of reasons that OpenAI isn't the best for it. (I would likely have moved earlier if Geoffrey Irving's departure hadn't left me managing the alignment team.)
I'm pretty hesitant to speak on behalf of other people who left. It's definitely not a complete coincidence that I left around the same time as other people (though there were multiple important coincidences), and I can talk about my own motivations:
- A lot of the people who I talked with at OpenAI left, decreasing the benefits from remaining at OpenAI and increasing the benefits for talking to people outside of OpenAI.
- The departures led to a lot of safety-relevant shakeups at OpenAI. It's not super clear whether that makes it an unusually good or bad time to shake up management of my team, but I think it felt unusually good to me (this might have been a rationalization, hard to say).
↑ comment by paulfchristiano · 2021-04-30T18:29:58.764Z · LW(p) · GW(p)
Do you still think that people interested in alignment research should apply to work at OpenAI?
I think alignment is a lot better if there are strong teams trying to apply best practices to align state of the art models, who have been learning about what it actually takes to do that in practice and building social capital. Basically that seems good because (i) I think there's a reasonable chance that we fail not because alignment is super-hard but because we just don't do a very good job during crunch time, and I think such teams are the best intervention for doing a better job, (ii) even if alignment is very hard and we need big new ideas, I think that such teams will be important for empirically characterizing and ultimately adopting those big new ideas. It's also an unusually unambiguous good thing.
I spent a lot of time at OpenAI largely because I wanted to help get that kind of alignment effort going. For some color see this post [LW · GW]; that team still exists (under Jan Leike) and there are now some other similar efforts at the organization.
I'm not as in the loop as I was a few months ago and so you might want to defer to folks at OpenAI, but from the outside I still tentatively feel pretty enthusiastic about the work of this kind that's happening at OpenAI. If you're excited about this kind of work then OpenAI still seems like a good place to go to me. (It also seems reasonable to think about DeepMind and Google, and of course I'm a fan of ARC for people who are a good fit, and I suspect that there will be more groups doing good applied alignment work in the future.)
comment by Ben Pace (Benito) · 2021-04-30T06:44:36.531Z · LW(p) · GW(p)
Who's the best critic of your alignment research? What have they been right about?
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:36:20.700Z · LW(p) · GW(p)
What are the most important ideas floating around in alignment research that don't yet have a public write-up? (Or, even better, that have a public write-up but could do with a good one?)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T18:40:43.153Z · LW(p) · GW(p)
I have a big gap between "stuff I've written up" and "stuff that I'd like to write up." Some particular ideas that come to mind: how epistemic competitiveness seems really important for alignment; how I think about questions like "aligned with whom" and why I think it's good to try to decouple alignment techniques from decisions about values / preference aggregation (this position is surprisingly controversial); updated views on the basic dichotomy in Two Kinds of Generalization and the current best hopes for avoiding the bad kind.
I think that there's a cluster of really important questions about what we can verify, how "alien" the knowledge of ML systems will be, and how realistic it's going to be to take a kind of ad hoc approach to alignment. In my experience people with a more experimental bent to be more optimistic about those questions tend to have a bunch of intuitions about those questions that do kind of hang together (and are often approximately shared across people). This comes with some more color on the current alignment plan / what's likely to happen in practice as people try to solve the problem on their feet. I don't think that's really been written up well but it seems important.
I think the MIRI crowd has some hard-to-articulate views about why ML is likely to produce consequentialist behavior, especially OOD, that aren't written up at all or very well. In general I think MIRI folks have a lot of ideas that aren't really written up, though I'm not sure they really do much floating around outside of MIRI.
Sorry that none of those are really crisp ideas. Probably my favorite one is the first about epistemic competitiveness but I think that's largely because I'm me, and that idea is central to my own thinking, rather than any kind of objective evaluation.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2021-05-01T17:37:13.366Z · LW(p) · GW(p)
The stuff about ‘alien’ knowledge sounds really fascinating, and I’d be excited about write-ups. All my concrete intuitions here come from reading Distill.Pub papers.
comment by JohnMalin · 2021-04-29T21:14:04.098Z · LW(p) · GW(p)
I wonder how valuable you find some of the more math/theory focused research directions in AI safety. I.e., how much less impactful do you find them, compared to your favorite directions? In particular,
- Vanessa Kosoy's learning-theoretic agenda, e.g., the recent sequence on infra-Bayesianism [? · GW], or her work on traps in RL. Michael Cohen's research, e.g. the paper [AF · GW] on imitation learning seems to go into a similar direction.
- The "causal incentives" agenda (link).
- Work on agent foundations, such as on cartesian frames [LW · GW]. You have commented on MIRI's research in the past, but maybe you have an updated view.
I'd also be interested in suggestions for other impactful research directions/areas that are more theoretical and less ML-focused (expanding on adamShimi's question [LW(p) · GW(p)], I wonder which part of mathematics and statistics you expect to be particularly useful).
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:13:08.130Z · LW(p) · GW(p)
I'm generally bad at communicating about this kind of thing, and it seems like a kind of sensitive topic to share half-baked thoughts on. In this AMA all of my thoughts are half-baked, and in some cases here I'm commenting on work that I'm not that familiar with. All that said I'm still going to answer but please read with a grain of salt and don't take it too seriously.
Vanessa Kosoy's learning-theoretic agenda, e.g., the recent sequence on infra-Bayesianism [? · GW], or her work on traps in RL. Michael Cohen's research, e.g. the paper [LW · GW] on imitation learning seems to go into a similar direction.
I like working on well-posed problems, and proving theorems about well-posed problems are particularly great.
I don't currently expect to be able to apply those kinds of algorithms directly to alignment for various reasons (e.g. no source of adequate reward function that doesn't go through epistemic competitiveness which would also solve other aspects of the problem, not practical to get exact imitation), so I'm mostly optimistic about learning something in the course of solving those problems that turns out to be helpful. I think that's plausible because these formal problems do engage some of the difficulties from the full problem.
I think that's probably less good than work that I regard as more directly applicable, though not by a huge factor. I think the major disagreement there is that other folks do regard it as more directly applicable, and I think it's pretty great to sort through those disagreements.
The "causal incentives" agenda (link).
I think that it's a good idea to apply this kind of analysis to RL systems we deploy, I think it's valuable to get RL researchers to think through some of these questions formally, and I think that this kind of work can make it easier for them to do that / more likely for them to lead to correct conclusions.
I have a few concerns about whether this kind of framework can substitute or complement other kinds of safety work:
- Even if the framework was exhaustive, it seems like most of the systems we want to deploy will ultimately have problematic control incentives and so we won't be able to use this as a filter or key component of our analysis strategy.
- In light of that it kind of feels like we need to have a more detailed understanding of the particular way in which our agents are responding to those incentives (or at least a much more detailed understanding of exactly what those incentives are, if we are setting aside inner alignment problems), and at that point it's less clear to me that we would need a more general framework.
- I think the existing approach and easy improvements don't seem like they can capture many important incentives such that you don't want to use it as an actual assurance (e.g. suppose that agent A is predicting the world and agent B is optimizing A's predictions about B's actions---then we want to say that the system has an incentive to manipulate the world but it doesn't seem like that is easy to incorporate into this kind of formalism).
Overall I'm somewhat more excited about the learning-theoretic agenda (discussed above) than this line of work.
Work on agent foundations, such as on cartesian frames [LW · GW]. You have commented on MIRI's research in the past, but maybe you have an updated view.
I sometimes find this kind of work (especially logical inductors and to a lesser extent cartesian frames) helpful in my own thinking about reasoners, e.g. as a source of examples or to help see a way to get a handle on a messy system. Again, I'd significantly prefer something that seemed to be more directly going for the throat and then doing other stuff when it came up, but I do think it has significant value, probably in between the last two.
Replies from: RyanCarey, tom4everitt↑ comment by RyanCarey · 2021-05-14T11:02:03.368Z · LW(p) · GW(p)
Thanks for these thoughts about the causal agenda. I basically agree with you on the facts, though I have a more favourable interpretation of how they bear on the potential of the causal incentives agenda. I've paraphrased the three bullet points, and responded in reverse order:
3) Many important incentives are not captured by the approach - e.g. sometimes an agent has an incentive to influence a variable, even if that variable does not cause reward attainment.
-> Agreed. We're starting to study "side-effect incentives" (improved name pending), which have this property. We're still figuring out whether we should just care about the union of SE incentives and control incentives, or whether SE or when, SE incentives should be considered less dangerous. Whether the causal style of incentive analysis captures much of what we care about, I think will be borne out by applying it and alternatives to a bunch of safety problems.
2) sometimes we need more specific quantities, than just D affects A.
-> Agreed. We've privately discussed directional quantities like "do(D=d) causes A=a" as being more safety-relevant, and are happy to hear other ideas.
1) eliminating all control-incentives seems unrealistic
-> Strongly agree it's infeasibile to remove CIs on all variables. My more modest goal would be to prove that for particular variables (or classes of variables) such as a shut down button, or a human's values, we can either: 1) prove how to remove control (+ side-effect) incentives, or 2) why this is impossible, given realistic assumptions. If (2), then that theoretical case could justify allocation of resources to learning-oriented approaches.
Overall, I concede that we haven't engaged much on safety issues in the last year. Partly, it's that the projects have had to fit within people's PhDs. Which will also be true this year. But having some of the framework stuff behind us, we should still be able to study safety more, and gain a sense of how addressable concerns like these are, and to what extent causal decision problems/games are a really useful ontology for AI safety.
↑ comment by tom4everitt · 2021-05-17T08:55:12.490Z · LW(p) · GW(p)
- I think the existing approach and easy improvements don't seem like they can capture many important incentives such that you don't want to use it as an actual assurance (e.g. suppose that agent A is predicting the world and agent B is optimizing A's predictions about B's actions---then we want to say that the system has an incentive to manipulate the world but it doesn't seem like that is easy to incorporate into this kind of formalism).
This is what multi-agent incentives are for (i.e. incentive analysis in multi-agent CIDs). We're still working on these as there are a range of subtleties, but I'm pretty confident we'll have a good account of it.
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:39:04.368Z · LW(p) · GW(p)
Pre-hindsight: 100 years from now, it is clear that your research has been net bad for the long-term future. What happened?
Replies from: paulfchristiano, paulfchristiano↑ comment by paulfchristiano · 2021-04-30T19:22:30.926Z · LW(p) · GW(p)
As an aside, I think that the possibility of "work doesn't matter" is typically way more important then "work was net bad," at least once you are making a serious effort to do something good rather than bad for the world (I agree that for the "average" project in the world the negative impacts are actually pretty large relative to the positive impacts).
EAs/rationalists often focus on the chance of a big downside clawing back value. I think that makes sense to think seriously about, and sometimes it's a big deal, but most of the time the quantitative estimates just don't seem to add up at all to me and I think people are making a huge quantitative error. I'm not sure exactly where we disagree, I think a lot of it is just that I'm way more skeptical about the ability to incidentally change the world a huge amount---I think that changing the world a lot usually just takes quite a bit of effort.
I guess in some sense I agree that the downside is big for normal butterfly-effect-y reasons (probably 50% of well-intentioned actions make the world worse ex post), so it's also possible that I'm just answering this question in a slightly different way.
My big caveat is that I think the numbers typically come out different (and the prior presumption can be different) when you are trying to e.g. grab political power or influence, or doing something that undermines other people's plans / is deliberately designed to hurt them. I don't think these are the main times EAs end up worrying about this though, and of course in particular my research isn't really trying to fight anyone or grab power.)
Replies from: DanielFilan↑ comment by DanielFilan · 2021-05-01T03:41:00.879Z · LW(p) · GW(p)
I guess I feel like we're in a domain where some people were like "we have concretely-specifiable tasks, intelligence is good, what if we figured how to create artificial intelligence to do those tasks", which is the sort of thing that someone trying to do good for the world would do, but had some serious chance of being very bad for the world. So in that domain, it seems to me that we should keep our eyes out for things that might be really bad for the world, because all the things in that domain are kind of similar.
That being said, I agree that the possibility that the work doesn't matter is more important once you're making a thoughtful effort to do good. But I see much more effort and thought into trying to address that part, such that the occasional nudge to consider negative impacts seems appropriate to me.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T16:44:23.399Z · LW(p) · GW(p)
I think it's good to sometimes meditate on whether you are making the world worse (and get others' advice), and I'd more often recommend it for crowds other than EA and certainly wouldn't discourage people from doing it sometimes.
I'm sympathetic to arguments that you should be super paranoid in domains like biosecurity since it honestly does seem asymmetrically easier to make things worse rather than better. But when people talk about it in the context of e.g. AI or policy interventions or gathering better knowledge about the world that might also have some negative side-effects, I often feel like there's little chance that predictable negative effects they are imagining loom large in the cost-benefit unless the whole thing is predictably pointless. Which isn't a reason not to consider those effects, just a push-back against the conclusion (and a heuristic push-back against the state of affairs where people are paralyzed by the possibility of negative consequences based on kind of tentative arguments).
For advancing or deploying AI I generally have an attitude like "Even if actively trying to push the field forward full-time I'd be a small part of that effort, whereas I'm a much larger fraction of the stuff-that-we-would-be-sad-about-not-happening-if-the-field-went-faster, and I'm not trying to push the field forward," so while I'm on board with being particularly attentive to harms if you're in a field you think can easily cause massive harms, in this case I feel pretty comfortable about the expected cost-benefit unless alignment work isn't really helping much (in which case I have more important reasons not to work on it). I would feel differently about this if pushing AI faster was net bad on e.g. some common-sense perspective on which alignment was not very helpful, but I feel like I've engaged enough with those perspectives to be mostly not having it.
Replies from: beth-barnes↑ comment by Beth Barnes (beth-barnes) · 2021-05-04T18:12:08.977Z · LW(p) · GW(p)
"Even if actively trying to push the field forward full-time I'd be a small part of that effort"
I think conditioning on something like 'we're broadly correct about AI safety' implies 'we're right about some important things about how AI development will go that the rest of the ML community is surprisingly wrong about'. In that world we're maybe able to contribute as much as a much larger fraction of the field, due to being correct about some things that everyone else is wrong about.
I think your overall point still stands, but it does seem like you sometimes overestimate how obvious things are to the rest of the ML community
↑ comment by paulfchristiano · 2021-04-30T19:28:10.165Z · LW(p) · GW(p)
Some plausible and non-exhaustive options, in roughly descending order of plausibility:
- I crowd out other people who would have done a better job of working on alignment (either by being better or just by being more). People feel like in order to be taken seriously they have to engage with Paul's writing and ideas and that's annoying. Or the space seems like a confused mess with sloppy standards in part because of my influence. Or more charitably maybe they are more likely to feel like it's "under control." Or maybe I claim ideas and make it harder for others to get credit even if they would have developed the ideas further or better (or even end up stealing the credit for others' ideas and disincentivizing them from entering the field).
- I convincingly or at least socially-forcefully argue for conclusions that turn out to be wrong (and maybe I should have understood as wrong) and so everyone ends up wronger and makes mistakes that have a negative effect. I mean ex post I think this kind of thing is pretty likely in some important cases (if I'm 80-20 and convince people to update in my favor I still think there's a 20% chance that I pushed people in the wrong direction and across many issues this is definitely going to happen)
- I contribute to social cover for irresponsible projects that want to pretend they are contributing to alignment, making it harder for the world to coordinate to block such projects.
- I convince people to be less worried about alignment and therefore undermine investment in alignment.
- What I describe as "alignment" actually significantly hastens the arrival of catastrophically risky AI---either because these techniques are needed even to build any AI systems that have a big impact on the world, or because they hold out promise of letting the developer actually benefit of AI and so incentivize more development or deployment.
comment by Mark Xu (mark-xu) · 2021-04-29T02:58:25.341Z · LW(p) · GW(p)
You've written multiple outer alignment failure stories. However, you've also commented that these aren't your best predictions. If you condition on humanity going extinct because of AI, why did it happen?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T18:54:26.391Z · LW(p) · GW(p)
I think my best guess is kind of like this story [LW · GW], but:
- People aren't even really deploying best practices.
- ML systems generalize kind of pathologically over long time horizons, and so e.g. long-term predictions don't correctly reflect the probability of systemic collapse.
- As a result there's no complicated "take over the sensors moment" it's just everything is going totally off the rails and everyone is yelling about it but it just keeps gradually drifting on the rails.
- Maybe the biggest distinction is that e.g. "watchdogs" can actually give pretty good arguments about why things are bad. In the story we fix all the things they can explain and are left only with the crazy hard core of human-incomprehensible problems, but in reality we will probably just fix the things that are pretty obvious and will be left with the hard core of problems that are still fairly obvious but not quite obvious enough that institutions can respond intelligently to them.
comment by Ben Pace (Benito) · 2021-04-30T07:46:06.490Z · LW(p) · GW(p)
What important truth do very few people in your community/network agree with you on?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:07:18.847Z · LW(p) · GW(p)
Unfortunately (fortunately?) I don't feel like I have access to any secret truths. Most idiosyncratic things I believe are pretty tentative, and I hang out with a lot of folks who are pretty open to the kinds of weird ideas that might have ended up feeling like Paul-specific secret truths if I hung with a more normal crowd.
It feels like my biggest disagreement with people around me is something like: to what extent is it likely to be possible to develop an algorithm that really looks on paper like it should just work for aligning powerful ML systems. I'm at like 50-50 and I think that the consensus estimate of people in my community is more like "Uh, sure doesn't sound like that's going to happen, but we're still excited for you to try."
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:49:55.979Z · LW(p) · GW(p)
Do you have any advice for junior alignment researchers? In particular, what do you think are the skills and traits that make someone an excellent alignment researcher? And what do you think someone can do early in a research career to be more likely to become an excellent alignment researcher?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T19:14:40.931Z · LW(p) · GW(p)
Some things that seem good:
- Acquire background in relevant adjacent areas---especially a reasonably deep understanding of ML, but then also a broader+shallower background in more distant areas like algorithms, economics, learning theory, and some familiarity with what kinds of intellectual practices work well in other fields.
- Build some basic research skills, especially (i) applied work in ML (e.g. be able to implement ML algorithms and run experiments, hopefully getting some kind of mentorship or guidance but you can also do a lot independently), (ii) academic research in any vaguely relevant area. I think it's good to have e.g. actually proven a few things, designed algorithms for a few problems, beaten your head against a few problems and then figured out how to make them work.
- Think a bunch about alignment. It feels like there is really just not much relevant stuff that's publicly written so you might as well read basically all of it and try to come up with views on the core questions yourself.
I personally feel like I got a lot of benefit out of doing some research in adjacent areas, but I'd guess that mostly it's better to focus on what you actually want to achieve and just be a bit opportunistic about trying to learn other stuff when it's relevant (rather than going out of your way to do work in an adjacent area).
I do feel like spending 3-6 months on my own learning ML was useful for getting started in the field despite being a bit of a digression. I'd probably recommend that kind of thing but wouldn't go further afield.
Over the course of my life I've gotten a really surprising amount of value out of final projects for grad classes (mostly TCS classes in undergrad, and then some when branching out into ML in grad school). It's a great chance to get guidance about what problems are important, to get some social support for stretching and working on an open problem, and to get some mentorship from faculty. Feels less applicable to alignment since there aren't many classes on it, but maybe it's starting to become relevant for alignment at schools with sympathetic faculty, and it's relevant for ML.
I think that actually making a unit of progress on your own, whether applied work (e.g. replicating ML papers and making some small additional contributions, or designing and running an interesting experiment) or theoretical work (e.g. trying to advance some discussion at least one step, proposing at least one novel idea that makes progress on a core problem) is a good way to start and to get access to more mentorship. This is what I did in undergrad in the context of normal theoretical CS (trying to prove little tiny theorems that were slightly advances) and it seemed like the right approach. It's also what I did to some extent for alignment (you can see some of my earliest writing here, with my first major attempted contribution being this post, and probably after that point I would have expected to get some kind of mentorship though I don't think there was that much to go around at that time; I guess I also wrote this [LW · GW] a year earlier, which was mostly a side-observation from thinking about theoretical CS that I thought might be amusing to the LW crowd, but I'm not proud of it and am not sure if it played much of a role in getting in touch with people)
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:33:59.629Z · LW(p) · GW(p)
What are the highest priority things (by your lights) in Alignment that nobody is currently seriously working on?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T18:51:38.309Z · LW(p) · GW(p)
It's not clear how to slice the space up into pieces so that you can talk about "is someone working on this piece?" (and the answer depends a lot on that slicing). Here are two areas in robustness that feel kind of empty for my preferred way of slicing up the problem (though for a different slicing they could be reasonably crowded). These are are also necessarily areas where I'm not doing any work so I'm really out on a limb here.
I think there should be more theoretical work on neural net verification / relaxing adversarial training. I should probably update from this to think that it's more of a dead end (and indeed practical verification work does seem to have run into a lot of trouble), but to me it looks like there's got to be more you can say at least to show that various possible approaches are dead ends. I think a big problem is that you really need to keep the application in mind in order to actually know the rules of the game. (That is, we have a predicate A, say implemented as a neural network, and we want to learn a function f such that for all x we have A(x, f(x)), but the problem is only supposed to be possible because in some sense the predicate A is "easy" to satisfy, and I don't think we have a definition of this other than actually going back and forth with the kind of treacherous turn we are concerned about.) I think many people are dissuaded by being skeptical about having a spec implemented as a neural network, which I think is reasonable (and is part of why I'm working on low-stakes alignment at first), but I think it's still good for some people on robustness and if you're trying to work on robustness right now it seems like you have to bite some bullet like that. Probably the bigger problem is that people just don't do much theoretical work on ML alignment.
I really like the idea of the unrestricted adversarial examples challenge. I wish that the contest was more fo a thing and I think one of the main reasons it's not is that most people are too intimidated to try seriously for defenses. Maybe they're right and the problem is too hopeless to even work on, I don't know enough about the domain to really contradict experts there (and I also don't really follow the area so don't know if people are actually basically working on it), but it definitely feels to me like it would be good to take a serious swing at that problem. I think that's obviously going to require significant additional investment in data labeling and some other big projects that people may just not do because they are big (which is probably reasonable as an academic). I kind of feel like the way you'd approach this problem if you just needed to get it done is pretty different from how academics normally approach this kind of thing and what I want is more like someone just trying to get it done.
comment by Ben Pace (Benito) · 2021-04-30T06:39:27.004Z · LW(p) · GW(p)
Do you know what sorts of people you're looking to hire? How much do you expect ARC to grow over the coming years, and what will the employees be doing? I can imagine it being a fairly small group of like 3 researchers and a few understudies, I can also imagine it growing to 30 people like MIRI. Which one of these is it closer to?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:11:28.395Z · LW(p) · GW(p)
I'd like to hire a few people (maybe 2 researchers median?) in 2021. I think my default "things are going pretty well" story involves doubling something like every 1-2 years for a while. Where that caps out / slows down a lot depends on how the field shapes out and how broad our activities are. I would be surprised if I wanted to stop growing at <10 people just based on the stuff I really know I want to do.
The very first hires will probably be people who want to work on the kind of theory I do, since right now that's what I'm feeling most excited about and really want to set up a team working on. I don't really know where that will end up going.
Once getting that going I'm not sure whether the next step will be growing it further or branching out into other things, and it will probably depend on how the theory work goes. I could also imagine doing enough theory on my own to change my view about how promising it is and make initial hires in another area instead.
comment by Ben Pace (Benito) · 2021-04-30T06:34:29.028Z · LW(p) · GW(p)
I'm not interested in the strongest argument from your perspective (i.e. the steelman), but I am interested how much you think you can pass the ITT for Eliezer's perspective on the alignment problem — what shape the problem is, why it's hard, and how to make progress. Can you give a sense of the parts of his ITT you think you've got?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T00:47:17.884Z · LW(p) · GW(p)
I think I could do pretty well (it's plausible to me that I'm the favorite in any head-to-head match with someone who isn't a current MIRI employee? probably not but I'm at least close). There are definitely some places I still get surprised and don't expect to do that well, e.g. I was recently surprised by one of Eliezer's positions regarding the relative difficulty of some kinds of reasoning tasks for near-future language models (and I expect there are similar surprises in domains that are less close to near-term predictions). I don't really know how to split it into parts for the purpose of saying what I've got or not.
comment by Ben Pace (Benito) · 2021-04-30T06:45:09.733Z · LW(p) · GW(p)
What work are you most proud of?
Slightly different: what blog post are you most proud of?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:25:59.004Z · LW(p) · GW(p)
I don't have an easy way of slicing my work up / think that it depends on how you slice it. Broadly I think the two candidates are (i) making RL from human feedback more practical and getting people excited about it at OpenAI, (ii) the theoretical sequence from approval-directed agents and informed oversight to iterated amplification to getting a clear picture of the limits of iterated amplification and setting out on my current research project. Some steps of that were really hard for me at the time though basically all of them now feel obvious.
My favorite blog post was probably approval-directed agents, though this is very much based on judging by the standards of how-confused-Paul-started-out. I think that it set me on a way better direction for thinking about AI safety (and I think it also helped a lot of people in a similar way). Ultimately it's clear that I didn't really understand where the difficulties were, and I've learned a lot in the last 6 years, but I'm still proud of it.
comment by DanielFilan · 2021-04-30T07:45:35.569Z · LW(p) · GW(p)
How many ideas of the same size as "maybe we could use inverse reinforcement learning to learn human values" are we away from knowing how to knowably and reliably build human-level AI technology that wouldn't cause something comparably bad as human extinction?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T19:31:42.789Z · LW(p) · GW(p)
A lot of this is going to come down to estimates of the denominator.
(I mostly just think that you might as well just ask people "Is this good?" rather than trying to use a more sophisticated form of IRL---in particular I don't think that realistic versions of IRL will successfully address the cases where people err in answering the "is it good?" question, that directly asking is more straightforward in many important ways, and that we should mostly just try to directly empower people to give better answers to such questions.)
Anyway, with that caveat and kind of using the version of your idea that I feel most enthusiastic about (and construing it quite broadly), I have a significant probability on 0, maybe a median somewhere in 10-20, significant probability at very high levels.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-29T08:51:54.063Z · LW(p) · GW(p)
In this post [LW · GW] I argued that an AI-induced point of no return would probably happen before world GDP starts to noticeably accelerate. You gave me some good pushback about the historical precedent I cited, but what is your overall view? If you can spare the time, what is your credence in each of the following PONR-before-GDP-acceleration scenarios, and why?
1. Fast takeoff
2. The sorts of skills needed to succeed in politics or war are easier to develop in AI than the sorts needed to accelerate the entire world economy, and/or have less deployment lag. (Maybe it takes years to build the relevant products and industries to accelerate the economy, but only months to wage a successful propaganda campaign to get people to stop listening to the AI safety community)
3. We get an "expensive AI takeoff" in which AI capabilities improve enough to cross some threshold of dangerousness, but this improvement happens in a very compute-intensive way that makes it uneconomical to automate a significant part of the economy until the threshold has been crossed.
4. Vulnerable world: Thanks to AI and other advances, a large number of human actors get the ability to make WMD's.
5. Persuasion/propaganda tools get good enough and are widely used enough that it significantly deteriorates the collective epistemology of the relevant actors (corps, governments, maybe even our community). (I know you've said at various times that probably AI-designed persuasive content will be banned or guarded against by other AIs, but what if this doesn't happen? We don't currently do much to protect ourselves from ordinary propaganda or algorithmically-selected content...)
6. Tech hoarding (The leading project(s) don't deploy their AI to improve the world economy, but nevertheless stay in the lead, perhaps due to massive investment, or perhaps due to weak or stifled competition)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:42:31.513Z · LW(p) · GW(p)
I don't know if we ever cleared up ambiguity about the concept of PONR. It seems like it depends critically on who is returning, i.e. what is the counterfactual we are considering when asking if we "could" return. If we don't do any magical intervention, then it seems like the PONR could be well before AI since the conclusion was always inevitable. If we do a maximally magical intervention, of creating unprecedented political will, then I think it's most likely that we'd see 100%+ annual growth (even of say energy capture) before PONR. I don't think there are reasonable definitions of PONR where it's very likely to occur before significant economic acceleration.
I don't think I consider most of the scenarios list necessarily-PONR-before-GDP acceleration scenarios, though many of them could permit PONR-before-GDP if AI was broadly deployed before it started adding significant economic value.
All of these probabilities are obviously pretty unreliable and made up on the spot:
1. Fast takeoff
Defined as 1-year doubling starts before 4-year doubling finishes, maybe 25%?
2. The sorts of skills needed to succeed in politics or war are easier to develop in AI than the sorts needed to accelerate the entire world economy, and/or have less deployment lag. (Maybe it takes years to build the relevant products and industries to accelerate the economy, but only months to wage a successful propaganda campaign to get people to stop listening to the AI safety community)
I definitely don't know what PONR means in this scenario (who is returning?) So to clarify the other terms: by "accelerate the entire world economy" I think you mean "generate enough value to meaningfully accelerate GWP growth", and by "succeed in politics or war" you mean "allow a small group of humans to take over the rest of the world"? (If you just mean "undermine attempts at AI alignment in the actual world," I don't even understand why the presence of the AI is important---can't we have a PONR if social tides just turn against concern about AI safety?)
For my maybe-stronger definitions, maybe 10%? I expect most of that comes from "takeoff could have been fast but we don't really roll stuff out in a timely way" and I don't know if it's right to describe it as "the sort of skills." (The main structural advantage of taking over the world is that fewer people need to roll it out.)
3. We get an "expensive AI takeoff" in which AI capabilities improve enough to cross some threshold of dangerousness, but this improvement happens in a very compute-intensive way that makes it uneconomical to automate a significant part of the economy until the threshold has been crossed.
I don't think I quite understand this scenario. It sounds quite similar to 2, where the main point is that we reach a dangerous-in-the-sense-of-taking-over-the-world threshold before a economically-useful threshold? Or maybe they are simultaneous, and so this is kind of like the extension of #1+#2 where it's a tie or nearly a tie between take over the world and accelerate GDP growth?
Vulnerable world: Thanks to AI and other advances, a large number of human actors get the ability to make WMD's.
Are you saying that this happens before economic acceleration, or just anytime in our future?
I think probability of happening before economic acceleration is maybe 5%? If ever, it really depends on "get the ability" and distinguishing actors and so on, maybe I think there is a 50% chance that at some point the state of the world's collective know-how is such that, absent any regulation about the use of destructive technologies, a very large number of small actors would each be able to unilaterally destroy the world?
5. Persuasion/propaganda tools get good enough and are widely used enough that it significantly deteriorates the collective epistemology of the relevant actors (corps, governments, maybe even our community). (I know you've said at various times that probably AI-designed persuasive content will be banned or guarded against by other AIs, but what if this doesn't happen? We don't currently do much to protect ourselves from ordinary propaganda or algorithmically-selected content...)
Depends on the threshold. One version: what's the probability that at some point in the development of AI, prior to significant economic acceleration, it has a net negative effect on the quality of the average importance-weighted actor's beliefs (because propaganda outweighs epistemically productive uses of AI). Maybe I'd be at like 50%? It then gets smaller if you ask for it to be true on average over the period or if you ask for a larger negative effect.
6. Tech hoarding (The leading project(s) don't deploy their AI to improve the world economy, but nevertheless stay in the lead, perhaps due to massive investment, or perhaps due to weak or stifled competition)
Is this including things like export controls from the US in an attempt to win a war with China? I guess not, the relevant threshold is something like "These technologies are deployed sufficiently narrowly that they do not meaningfully accelerate GWP growth." I think this is fairly hard for me to imagine (since their lead would need to be very large to outcompete another country that did deploy the technology to broadly accelerate growth), perhaps 5%?
Replies from: donald-hobson↑ comment by Donald Hobson (donald-hobson) · 2021-05-09T23:47:28.096Z · LW(p) · GW(p)
"These technologies are deployed sufficiently narrowly that they do not meaningfully accelerate GWP growth." I think this is fairly hard for me to imagine (since their lead would need to be very large to outcompete another country that did deploy the technology to broadly accelerate growth), perhaps 5%?
I think there is a reasonable way it could happen even without an enormous lead. You just need either,
- Its very hard to capture a significant fraction of the gains from the tech.
- Tech progress scales very poorly in money.
For example, suppose it is obvious to everyone that AI in a few years time will be really powerful. Several teams with lots of funding are set up. If progress is researcher bound, and researchers are ideologically committed to the goals of the project, then top research talent might be extremely difficult to buy. (They are already well paid, for the next year they will be working almost all day. After that, the world is mostly shaped by which project won.)
Compute could be hard to buy if there were hard bottlenecks somewhere in the chip supply chain, most of the worlds new chips were already being used by the AI projects, and an attitude of "our chips and were not selling" was prevalent.
Another possibility, suppose deploying a tech means letting the competition know how it works. Then if one side deploys, they are pushing the other side ahead. So the question is, does deploying one unit of research give you the resources to do more than one unit?
comment by Ben Pace (Benito) · 2021-04-30T07:59:11.197Z · LW(p) · GW(p)
Do you have any specific plans for your life in a post-singularity world?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:23:57.341Z · LW(p) · GW(p)
Not really.
I expect that many humans will continue to participate in a process of collectively clarifying what we want and how to govern the universe. I wouldn't be surprised if that involves a lot of life-kind-of-like-normal that gradually improves in a cautious way we endorse rather than some kind of table-flip (e.g. I would honestly not be surprised if post-singularity we still end up raising another generation because there's no other form of "delegation" that we feel more confident about). And of course in such a world I expect to just continue to spend a lot of time thinking, again probably under conditions that are designed to be gradually improving rather than abruptly changing. The main weird thing is that this process will now be almost completely decoupled from productive economic activity.
I think it's hard to talk about "your life" and identity is likely to be fuzzy over the long term. I don't think that most of the richness and value in the world will come from creatures who feel like "us" (and I think our selfish desires are mostly relatively satiable). That said, I do also expect that basically all of the existing humans will have a future that they feel excited about (and which is recognizably "theirs") because it's very cheap to arrange and many of us care a lot about that.
I have no idea what that "after retirement" life would look like. As a lower bound, I enjoy playing and making games a lot, as well as great movies and crazy intricate interactive narratives that will be possible in that future. I might end up spending some time on that kind of thing. I might do a bunch of things analogous to drugs and wireheading, might have a lot of crazy and deeply meaningful romantic and personal relationships (and maybe a lot of great sex), might be part of some giant satisfying collaborative projects. I might end up trying to have many deeper experiences and appreciate my place in the world in some kind of deep meaningful way that some people seem to get a lot out of but I mostly don't. But frankly, I don't really expect any of those things to happen much because I expect we'll mostly think of better of things to do.
I sometimes talk about addressing a lot of my uncertainty about the world, e.g. learning about what actually happened in our history or getting the right answer to all the questions about the modern world that bug me. I can imagine going through the play-by-play of the decisions in my life with some much wiser minds and learning about what I did well or poorly. Similarly it would be fun to have some nice retrospective parties where I talk with people from my life about what it was like and look back on everything as we gradually become wiser together, just like you'd review a game after the fact. But again, don't really think it's going to be worth it given that we'll think of better things to do.
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:44:22.702Z · LW(p) · GW(p)
What is your theory of change for the Alignment Research Center? That is, what are the concrete pathways by which you expect the work done there to systematically lead to a better future?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:04:24.485Z · LW(p) · GW(p)
For the initial projects, the plan is to find algorithmic ideas (or ideally a whole algorithm) that works well in practice, can be adopted by labs today, and would put us in a way better position with respect to future alignment challenges. If we succeed in that project, then I'm reasonably optimistic about being able to demonstrate the value of our ideas and get them adopted in practice (by a combination of describing them publicly, talking with people at labs, advising people who are trying to pressure labs to take alignment seriously about what their asks should be, and consulting for labs to help implement ideas). Even if adoption or demonstrating desirability turns out to be hard, I think that the alignment community would be in a much better place if we had a proposal that we all felt good about that we were advocating for (since we'd then have a better shot at doing so, and labs that were serious about alignment would be able to figure out what to do).
Beyond that, I'm also excited about offering concrete and well-justified advice (either about what algorithms to use or about alignment-relevant deployment decisions) that can help labs who care about alignment, or can be taken as a clear indicator of best practices so be adopted by labs who want to present as socially-responsible (whether to please employees, funders, civil society, or competitors).
But I'm mostly thinking about the impact of initial activities, and for that I feel like the theory of change is relatively concrete/straightforward.
comment by Ben Pace (Benito) · 2021-04-30T08:22:53.668Z · LW(p) · GW(p)
If you could magically move most of the US rationality and x-risk and EA community to a city in the US that isn't the Bay, and you had to pick somewhere, where where would you move them to?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:26:58.018Z · LW(p) · GW(p)
If I'm allowed to think about it first then I'd do that. If I'm not, then I'd regret never having thought about it, probably Seattle would be my best guess.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2021-05-01T17:33:40.057Z · LW(p) · GW(p)
Huh, am surprised. Guess I might’ve predicted Boston. Curious if it’s because of the culture, the environment, or what.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T19:58:09.836Z · LW(p) · GW(p)
Don't read too much into it. I do dislike Boston weather.
comment by DanielFilan · 2021-04-30T07:37:25.192Z · LW(p) · GW(p)
What's the most important thing that AI alignment researchers have learned in the past 10 years? Also, that question but excluding things you came up with.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:25:14.526Z · LW(p) · GW(p)
"Thing" is tricky. Maybe something like the set of intuitions and arguments we have around learned optimizers, i.e. the basic argument that ML will likely produce a system that is "trying" to do something, and that it can end up performing well on the training distribution regardless of what it is "trying" to do (and this is easier the more capable and knowledgeable it is). I don't think we really know much about what's going on here, but I do think it's an important failure to be aware of and at least folks are looking for it now. So I do think that if it happens we're likely to notice it earlier than we would if taking a purely experimentally-driven approach and it's possible that at the extreme you would just totally miss the phenomenon. (This may not be fair to put in the last 10 years, but thinking about it sure seemed like a mess >10 years ago.)
(I may be overlooking something such that I really regret that answer in 5 minutes but so it goes.)
comment by DanielFilan · 2021-04-30T07:33:08.163Z · LW(p) · GW(p)
What is the most common wrong research-relevant intuition among AI alignment researchers?
comment by electroswing · 2021-04-29T22:01:39.726Z · LW(p) · GW(p)
According to your internal model of the problem of AI safety, what are the main axes of disagreement researchers have?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:37:52.143Z · LW(p) · GW(p)
The three that first come to mind:
- How much are ML systems likely to learn to "look good to the person training them" in a way that will generalize scarily to novel test-time situations, vs learning to straightforwardly do what we are trying to train them to do?
- How much alien knowledge are ML systems likely to have? Will humans be able to basically understand what they are doing with some effort, or will it quickly become completely beyond us?
- How much time will we have to adapt gradually as AI systems improve, and how fast will we be able to adapt? How similar will the problems that arise be to the ones we can anticipate now?
comment by DanielFilan · 2021-04-30T07:47:02.136Z · LW(p) · GW(p)
How many ideas of the same size as "maybe a piecewise linear non-linearity would work better than a sigmoid for not having vanishing gradients" are we away from knowing how to build human-level AI technology?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:57:03.245Z · LW(p) · GW(p)
I think it's >50% chance that ideas like ReLUs or soft attention are best though of as multiplicative improvements on top of hardware progress (as are many other ideas like auxiliary objectives, objectives that better capture relevant tasks, infrastructure for training more efficiently, dense datasets, etc.), because the basic approach of "optimize for a task that requires cognitive competence" will eventually yield human-level competence. In that sense I think the answer is probably 0.
Maybe my median number of OOMs left before human-level intelligence, including both hardware and software progress, is 10 (pretty made-up). Of that I'd guess around half will come from hardware, so call it 5 OOMs of software progress. Don't know how big that is relative to ReLUs, maybe 5-10x? (But hard to define the counterfactual w.r.t. activation functions.)
(I think that may imply much shorter timelines than my normal view. That's mostly from thoughtlessness in this answer which was quickly composed and didn't take into account many sources of evidence, some is from legit correlations not taken into account here, some is maybe legitimate signal from an alternative estimation approach, not sure.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-05-05T10:33:57.858Z · LW(p) · GW(p)
When you say hardware progress, do you just mean compute getting cheaper or do you include people spending more on compute? So you are saying, you guess that if we had 10 OOMs of compute today that would have a 50% chance of leading to human-level AI without any further software progress, but realistically you expect that what'll happen is we get +5 OOMs from increased spending and cheaper hardware, and then +5 "virtual OOMs" from better software?
comment by DanielFilan · 2021-04-30T08:22:42.355Z · LW(p) · GW(p)
What's the largest cardinal whose existence you feel comfortable with assuming as an axiom?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:35:39.762Z · LW(p) · GW(p)
I'm pretty comfortable working with strong axioms. But in terms of "would actually blow my mind if it turned out not to be consistent," I guess alpha-inaccessible cardinals for any concrete alpha? Beyond that I don't really know enough set theory to have my mind blown.
comment by DanielFilan · 2021-04-30T08:08:23.564Z · LW(p) · GW(p)
What's your favourite mathematical object? What's your least favourite mathematical object?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:12:59.250Z · LW(p) · GW(p)
Favorite: Irit Dinur's PCP for constraint satisfaction. What a proof system.
If you want to be more pure, and consider the mathematical objects that are found rather than built, maybe the monster group? (As a layperson so I can't appreciate the full extent of what's going, on and like most people I only real know about it second-hand, but its existence seems like a crazy and beautiful fact about the world.)
Least favorite: I don't know, maybe Chaitin's constant?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-10-11T16:40:24.175Z · LW(p) · GW(p)
I take it back, Chaitin's constant is more cool than I thought.
I don't like the cardinal very much, but I like just fine so it's not really clear if it's a problem with the object or the reference.
Replies from: DanielFilan↑ comment by DanielFilan · 2021-10-27T17:41:40.422Z · LW(p) · GW(p)
What changed your mind about Chaitin's constant?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-10-28T15:21:15.673Z · LW(p) · GW(p)
I hadn't appreciated how hard and special it is to be algorithmically random.
comment by Ben Pace (Benito) · 2021-04-30T06:41:46.669Z · LW(p) · GW(p)
What was your biggest update about the world from living through the coronavirus pandemic?
Follow-up: does it change any of your feelings about how civilization will handle AGI?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T23:20:21.114Z · LW(p) · GW(p)
I found our COVID response pretty "par for the course" in terms of how well we handle novel challenges. That was a significant negative update for me because I had a moderate probability on us collectively pulling out some more exceptional adaptiveness/competence when an issue was imposing massive economic costs and had a bunch of people's attention on it. I now have somewhat more probability on AI dooms that play out slowly where everyone is watching and yelling loudly about it but it's just really tough to do something that really improves the situation (and correspondingly more total probability on doom). I haven't really sat down and processed this update or reflected on exactly how big it should be.
comment by edoarad · 2021-04-28T19:34:29.239Z · LW(p) · GW(p)
What are the best examples of progress in AI Safety research that we think have actually reduced x-risk?
(Instead of operationalizing this explicitly, I'll note that the motivation is to understand whether doing more work toward technical AI Safety research is directly beneficial as opposed to mostly irrelevant or having second-order effects. )
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T20:51:39.668Z · LW(p) · GW(p)
It's a bit hard to distinguish "direct" and "second-order" effects---e.g. any algorithm we develop will not be deployed directly (and likely would have been developed later if effective) but will be useful primarily for accelerating the development of later algorithms and getting practice making relevant kinds of progress etc.
One way to operationalize this is to ask something like "Which techniques would be used today if there was rapid unexpected progress in ML (e.g. a compute helicopter drop) that pushed it to risky levels?" Of course that will depend a bit on where the drop occurs or who uses it, but I'll imagine that it's the labs that currently train the largest ML models (which will of course bias the answer towards work that changes practices in those labs).
(I'm not sure if this operationalization is super helpful for prioritization, given that in fact I think most work mostly has "indirect" effects broadly construed. It still seems illuminating.)
I think that in this scenario we'd want to do something like RL from human feedback using the best evaluations we can find, and the fact that these methods are kind of familiar internally will probably be directly helpful. I think that the state of discourse about debate and iterated amplification would likely have a moderate positive impact on our ability to use ML systems productively as part of that evaluation process. I think that the practice of adversarial training and a broad understanding of the problems of ML robustness and the extent to which "more diverse data" is a good solution will have an impact on how carefully people do scaled-up adversarial training. I think that the broad arguments about risk, deceptive alignment, convergence etc. coming out of MIRI/FHI the broader rationalist community would likely improve people's ability to notice weird stuff (e.g. signatures of deceptive alignment) and pause appropriately or prioritize work on solutions if those actually happen. I think there's a modest chance that some kind of interpretability work directly inspired by modern work (like the Clarity team / Distill community) would detect a serious problem in a trained model and that this could cause us to change course and survive. I think probably "composition of teams that will work on alignment" and "governance of labs that will deploy AI" will both be quite important but less directly traceable to AI safety work.
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:38:14.165Z · LW(p) · GW(p)
You seem in the unusual position of having done excellent conceptual alignment work (eg with IDA), and excellent applied alignment work at OpenAI, which I'd expect to be pretty different skillsets. How did you end up doing both? And how useful have you found ML experience for doing good conceptual work, and vice versa?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:47:39.083Z · LW(p) · GW(p)
Aw thanks :) I mostly trained as a theorist through undergrad, then when I started grad school I spent some time learning about ML and decided to do applied work at OpenAI. I feel like the methodologies are quite different but the underlying skills aren't that different. Maybe the biggest deltas are that ML involves much more management of attention and jumping between things in order to be effective in practice, while theory is a bit more loaded on focusing on one line of reasoning for a long time and having some clever idea. But while those are important skills I don't think they are the main things that you improve at by working in either area and aren't really core.
I feel like in general there is a lot of transfer between doing well in different research areas, though unsurprisingly it's less than 100% and I think I would be better at either domain if I'd just focused on it more. The main exception is that I feel like I'm a lot better at grounding out theory that is about ML, since I've had more experience and have more of a sense for what kinds of assumptions are reasonable in practice. And on the flip side I do think theory is similar to a lot of algorithm design/analysis questions that come up in ML (frankly it doesn't seem like a central skill but I think there are big logistical benefits from being able to do the whole pipeline as one person).
comment by DanielFilan · 2021-04-30T08:12:50.119Z · LW(p) · GW(p)
How many hours per week should the average AI alignment researcher spend on improving their rationality? How should they spend those hours?
Replies from: Benito, paulfchristiano↑ comment by Ben Pace (Benito) · 2021-04-30T15:53:17.257Z · LW(p) · GW(p)
I want to know this question, but for the ‘peak’ alignment researcher.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:44:27.614Z · LW(p) · GW(p)
My answer isn't sensitive to things like "how good are you at research" (I didn't even express the sensitivity to "how much do you like reflecting" or "how old are you" which I think are more important). I guess probably the first order thing is that the 'peak' alignment researcher is more likely to be older and closer to death so investing somewhat less in getting better at things. (But the world changes and lives are long so I'm not sure it's a huge deal.)
↑ comment by paulfchristiano · 2021-04-30T22:43:28.204Z · LW(p) · GW(p)
I probably wouldn't set aside hours for improving rationality (/ am not exactly sure what it would entail). Seems generally good to go out of your way to do things right, to reflect on lessons learned from the things you did, to be willing to do (and slightly overinvest in) things that are currently hard in order to get better, and so on. Maybe I'd say that like 5-10% of time should be explicitly set aside for activities that just don't really move you forward (like post-mortems or reflecting on how things are going in a way that's clearly not going to pay itself off for this project) and a further 10-20% on doing things in ways that aren't the very optimal way right now but useful for getting better at doing them in the future (e.g. using unfamiliar tools, getting more advice from people than would make sense if the world ended next week, being more methodical about how you approach problems).
I guess the other aspect of this is separating some kind of general improvement from more domain specific improvement (i.e. are the numbers above about improving rationality or just getting better at doing stuff?). I think stuff that feels vaguely like "rationality" in the sense of being about cognitive practices is most likely to always seem pretty tied up with the object level (even if it transfers), and the purely domain-general stuff is very likely to be about e.g. very general tools or a nicer chair or whatever. So maybe I don't think there's much improvement on the table that is about fully domain-general ways to think / which is best approached by starting from general principles rather than getting better at what you are currently doing.
Those numbers are all very made up. I'm unfortunately not an expert at being an excellent human. Over my whole career I've maybe averaged something like that 15-30%, though there have been times of significantly higher rates and times of significantly lower rates and I would have preferred to average it out.
comment by Ben Pace (Benito) · 2021-04-30T06:35:36.930Z · LW(p) · GW(p)
What are the main ways you've become stronger and smarter over the past 5 years? This isn't a question about new object-level beliefs so much as ways-of-thinking or approaches to the world that have changed for you.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:35:35.181Z · LW(p) · GW(p)
I'm changing a lot less with every successive 5-year interval. The last 5 years was the end of grad school and my time at OpenAI.
I certainly learned a lot about how to make ML work in practice (start small, prioritize simple cases where you can debug, isolate assumptions). Then I learned a lot about how to run a team. I've gotten better at talking to people and writing and being a broadly functional (making up on some lost time when I was younger and focused on math instead).
I don't think there's any simple slogan for new ways-of-thinking or changed approaches to the world. Mostly just seems like a ton of little stuff. I think earlier phases of my life were more likely to be a shift in an easily described direction, but this time it's been more a messy mix---I became more arrogant in some ways and more humble in others, more optimistic in some ways and more pessimistic in others, more inclined to trust on-paper reasoning in some ways and less in others, etc
comment by Ben Pace (Benito) · 2021-04-30T06:24:07.154Z · LW(p) · GW(p)
Did you get much from reading the sequences? What was one of the things you found most interesting or valuable personally it them?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T00:55:22.131Z · LW(p) · GW(p)
I enjoyed Leave a Line of Retreat [LW · GW]. It's a very concrete and simple procedure that I actually still use pretty often and I've benefited a lot just from knowing about. Other than that I think I found a bunch of the posts interesting and entertaining. (Looking back now the post is a bit bombastic, I suspect all the sequences are, but I don't really mind.)
comment by adamShimi · 2021-04-28T20:45:47.079Z · LW(p) · GW(p)
Copying my question from your post about your new research center [LW(p) · GW(p)] (because I'm really interested in the answer): which part (if any) of theoretical computer science do you expect to be particularly useful for alignment?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:53:29.744Z · LW(p) · GW(p)
Learning theory definitely seems most relevant. Methodologically I think any domain where you are designing and analyzing algorithms, especially working with fuzzy definitions or formalizing intuitive problems, is also useful practice though much less bang for your buck (especially if just learning about it rather than doing research in it). That theme cuts a bunch across domains, though I think cryptography, online algorithms, and algorithmic game theory are particularly good.
comment by paulfchristiano · 2021-04-30T18:15:05.775Z · LW(p) · GW(p)
Going to start now. I vaguely hope to write something for all of the questions that have been asked so far but we'll see (80 questions is quite a few).
comment by Eric Chen (Equilibrate) · 2021-04-30T17:14:32.528Z · LW(p) · GW(p)
What's your current credence that we're in a simulation?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T23:27:36.666Z · LW(p) · GW(p)
I think that by count across all the possible worlds (and the impossible ones) the vast majority of observers like us are in simulations. And probably by count in our universe the vast majority of observers like us are in simulations, except that everything is infinite and so counting observers is pretty meaningless (which just helps to see that it was never the thing you should care about).
I'm not sure "we're in a simulation" is the kind of thing it's meaningful to talk about credences in, but it's definitely coherent to talk about betting odds (i.e. how much would I be willing to have copies of me in a simulation sacrifice for copies of me outside of a simulation to benefit?). You don't want to talk about those using $ since $ are obviously radically more valuable outside of the simulation and that will dominate the calculation of betting odds. But we can measure in terms of experiences (how would I trade off welfare between the group inside and outside the simulation). I'd perhaps take a 2:1 rate, i.e. implying I think there's a 2/3 "chance" that we're in a simulation? But pretty unstable and complicated.
comment by Sam Clarke · 2021-04-30T07:59:48.417Z · LW(p) · GW(p)
Are there any research questions you're excited about people working on, for making AI go (existentially) well, that are not related to technical AI alignment or safety? If so, what? (I'm especially interested in AI strategy/governance questions)
Replies from: paulfchristiano, Sam Clarke↑ comment by paulfchristiano · 2021-04-30T22:51:24.282Z · LW(p) · GW(p)
Not sure if you want "totally unrelated to technical AI safety" or just "not basically the same as technical AI safety." Going for somewhere in between.
- I think that futurism in general is underdone and pretty impactful on the margin, especially if it's reasonably careful and convincing.
- I think that broad institutional quality and preparedness for weird stuff is more likely to make stuff go well. I think that particular norms and mechanisms to cope with high-stakes AI development, to enforce and monitor agreements, to establish international trust, etc. all seem likely to be impactful. I don't have really detailed views about this field.
- I think that there are tons of other particular bad things that can happen with AI many of which give a suggest a lot of stuff to work on. Stuff like differential tech progress for physical tech at the expense of wisdom, rash AI-mediated binding commitments from bad negotiation, other weird game theory, AI-driven arguments messing up collective deliberation about what we want, crazy cybersecurity risks. There is stuff to do both on the technical side (though often that's going to be a bit rougher than alignment in that it's just e.g. researching how to use AI for mitigation, and on the institutional side) and on governance / thinking through responses / agreements / other preparedness.
- I'm interested in a bunch of philosophical questions like "Should we be nice to AI?", "What kind of AI should we make if we're going to hand over the world?" and so on.
↑ comment by Sam Clarke · 2021-04-30T12:00:39.204Z · LW(p) · GW(p)
Relatedly: if we manage to solve intent alignment (including making it competitive) but still have an existential catastrophe, what went wrong?
comment by Ben Pace (Benito) · 2021-04-30T07:46:43.624Z · LW(p) · GW(p)
What should people be spending more money on?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:15:50.139Z · LW(p) · GW(p)
Which people? (And whose "should"?) Maybe public goods, software, and movies?
Replies from: Vaniver, Benito↑ comment by Vaniver · 2021-04-30T22:43:31.058Z · LW(p) · GW(p)
Is "movies" a standin for "easily duplicated cultural products", or do you think movies in particular are underproduced?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T22:49:01.437Z · LW(p) · GW(p)
Mostly a stand-in, but I do wish people were making more excellent movies :)
↑ comment by Ben Pace (Benito) · 2021-05-01T17:31:34.453Z · LW(p) · GW(p)
Most people, or most people you know.
And “should“ = given their own goals.
I’m asking what you think people might be wrong about. And very slightly hoping for product recommendations :)
comment by DanielFilan · 2021-04-30T07:52:25.515Z · LW(p) · GW(p)
Should marginal CHAI PhD graduates who are dispositionally indifferent between the two options try to become a professor or do research outside of universities?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T23:18:12.019Z · LW(p) · GW(p)
Not sure. If you don't want to train students, seems toe me like you should be outside of a university. If you do want to train students it's less clear and maybe depends on what you want to do (and given that students vary in what they are looking for, this is probably locally self-correcting if too many people go one way or the other). I'd certainly lean away from university for the kinds of work that I want to do, or for the kinds of things that involve aligning large ML systems (which benefit from some connection to customers and resources).
comment by Ben Pace (Benito) · 2021-04-30T08:18:53.637Z · LW(p) · GW(p)
And on an absolute level, is the world much more or less prepared for AGI than it was 15 years ago?
Follow-up: How much did the broader x-risk community change it at all?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T21:56:33.926Z · LW(p) · GW(p)
is the world much more or less prepared for AGI than it was 15 years ago?
I think much better.
How much did the broader x-risk community change it at all?
I don't really know / tough to answer. Certainly there's a lot more people talking about the problem, it's hard to know how much that comes from x-risk community or from vague concerns about AI in the world (my guess is big parts of both). I think we are in a better place with respect to knowledge of technical alignment---we know a fair bit about what the possible approaches are and have taken a lot of positive steps. There is a counterfactual where alignment isn't even really recognized as a distinct problem and is just lumped in with vague concerns about safety, which would be significantly worse in terms of our ability to work productively on the problem (though I'd love if we were further away from that world).
comment by Alexei · 2021-04-29T20:11:35.815Z · LW(p) · GW(p)
What are your thoughts / advice on working as an individual vs joining an existing team / company when it comes to safety research? (For yourself and for others)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:20:34.745Z · LW(p) · GW(p)
I think the main reasons to join teams are either to do collaborative projects or to get mentorship. I think for most people one or both of those will be pretty important, and so individual work is usually a kind of stop-gap---lower barriers to entry, but if it's a good fit the expectation should be to join a larger team after not-that-long. For people who already feel well-oriented and who are interested in projects that can be done by individuals, then I think it's not a big deal either way though it can still be nice to have a closer community of people working on safety.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-04-29T08:35:26.863Z · LW(p) · GW(p)
1. What credence would you assign to "+12 OOMs of compute would be enough for us to achieve AGI / TAI / AI-induced Point of No Return within five years or so." (This is basically the same, though not identical, with this poll question [LW · GW])
2. Can you say a bit about where your number comes from? E.g. maybe 25% chance of scaling laws not continuing such that OmegaStar, Amp(GPT-7), etc. [LW · GW] don't work, 25% chance that they happen but don't count as AGI / TAI / AI-PONR, for total of about 60%? The more you say the better, this is my biggest crux! Thanks!
Replies from: paulfchristiano, paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:24:40.787Z · LW(p) · GW(p)
I'd say 70% for TAI in 5 years if you gave +12 OOM.
I think the single biggest uncertainty is about whether we will be able to adapt sufficiently quickly to the new larger compute budgets (i.e. how much do we need to change algorithms to scale reasonably? it's a very unusual situation and it's hard to scale up fast and depends on exactly how far that goes). Maybe I think that there's an 90% chance that TAI is in some sense possible (maybe: if you'd gotten to that much compute while remaining as well-adapted as we are now to our current levels of compute) and conditioned on that an 80% chance that we'll actually do it vs running into problems?
(Didn't think about it too much, don't hold me to it too much. Also I'm not exactly sure what your counterfactual is and didn't read the original post in detail, I was just assuming that all existing and future hardware got 12OOM faster. If I gave numbers somewhere else that imply much less than that probability with +12OOM, then you should be skeptical of both.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-05-05T10:43:18.481Z · LW(p) · GW(p)
My counterfactual attempts to get at the question "Holding ideas constant, how much would we need to increase compute until we'd have enough to build TAI/AGI/etc. in a few years?" This is (I think) what Ajeya is talking about with her timelines framework. Her median is +12 OOMs. I think +12 OOMs is much more than 50% likely to be enough; I think it's more like 80% and that's after having talked to a bunch of skeptics, attempted to account for unknown unknowns, etc. She mentioned to me that 80% seems plausible to her too but that she's trying to adjust downwards to account for biases, unknown unknowns, etc.
Given that, am I right in thinking that your answer is really close to 90%, since failure-to-achieve-TAI/AGI/etc-due-to-being-unable-to-adapt-quickly-to-magically-increased-compute "shouldn't count" for purposes of this thought experiment?
↑ comment by paulfchristiano · 2021-05-01T01:32:24.927Z · LW(p) · GW(p)
(I don't think Amp(GPT-7) will work though.)
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-05-01T07:50:42.045Z · LW(p) · GW(p)
I'm very glad to hear that! Can you say more about why?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T16:14:52.884Z · LW(p) · GW(p)
Natural language has both noise (that you can never model) and signal (that you could model if you were just smart enough). GPT-3 is in the regime where it's mostly signal (as evidenced by the fact that the loss keeps going down smoothly rather than approaching an asymptote). But it will soon get to the regime where there is a lot of noise, and by the time the model is 9 OOMs bigger I would guess (based on theory) that it will be overwhelmingly noise and training will be very expensive.
So it may or may not work in the sense of meeting some absolute performance threshold, but it will certainly be a very bad way to get there and we'll do something smarter instead.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-05-05T10:36:58.290Z · LW(p) · GW(p)
Hmm, I don't count "It may work but we'll do something smarter instead" as "it won't work" for my purposes.
I totally agree that noise will start to dominate eventually... but the thing I'm especially interested in with Amp(GPT-7) is not the "7" part but the "Amp" part. Using prompt programming, fine-tuning on its own library, fine-tuning with RL, making chinese-room-bureaucracies, training/evolving those bureaucracies... what do you think about that? Naively the scaling laws would predict that we'd need far less long-horizon data to train them, since they have far fewer parameters, right? Moreover IMO evolved-chinese-room-bureaucracy is a pretty good model for how humans work, and in particular for how humans are able to generalize super well and make long-term plans etc. without many lifetimes of long-horizon training.
comment by DanielFilan · 2021-04-30T07:40:13.696Z · LW(p) · GW(p)
If a 17-year-old wanted to become the next Paul Christiano, what should they do?
comment by Ben Pace (Benito) · 2021-04-30T06:32:59.891Z · LW(p) · GW(p)
What is your top feature request for LessWrong.com?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T23:28:51.665Z · LW(p) · GW(p)
When I begin a comment with a quotation, I don't know how to insert new un-quoted text at the top (other than by cutting the quotation, adding some blank lines, then pasting the quotation back). That would be great.
Also moderate performance improvements.
And then maybe a better feed that gives me the content I'm most likely to see? That's a tough thing to design but could add significant value.
Replies from: habryka4↑ comment by habryka (habryka4) · 2021-04-30T23:43:29.580Z · LW(p) · GW(p)
When I begin a comment with a quotation, I don't know how to insert new un-quoted text at the top (other than by cutting the quotation, adding some blank lines, then pasting the quotation back). That would be great.
You can do this by pressing enter in an empty paragraph of a quoted block. That should cause you to remove the block. See this gif:
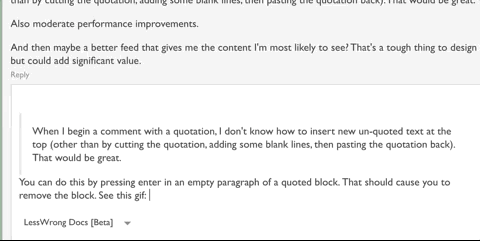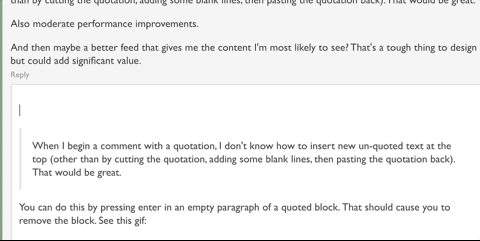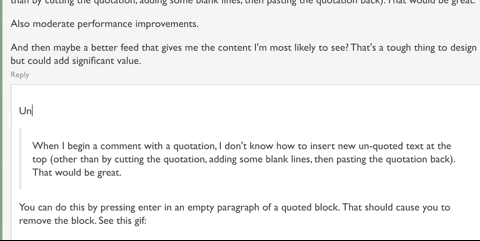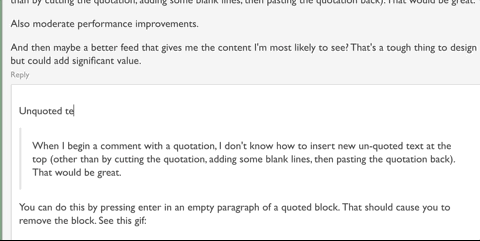
↑ comment by paulfchristiano · 2021-05-01T00:20:22.315Z · LW(p) · GW(p)
I thought that I tried that but it seems to work fine, presumably user error :)
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:52:23.540Z · LW(p) · GW(p)
What research in the past 5 years has felt like the most significant progress on the alignment problem? Has any of it made you more or less optimistic about how easy the alignment problem will be?
comment by Ben Pace (Benito) · 2021-04-30T08:12:35.623Z · LW(p) · GW(p)
Why did nobody in the world run challenge trials for the covid vaccine and save us a year of economic damage?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T02:34:55.291Z · LW(p) · GW(p)
Wild speculation, not an expert. I'd love to hear from anyone who actually knows what's going on.
I think it's overoptimistic that human challenge trials would save a year, though it does seem like they could have plausibly have saved weeks or months if done in the most effective form. (And in combination with other human trials and moderate additional spending I'd definitely believe 6-12 months of acceleration was possible.)
In terms of why so few human experiments have happened in general, I think it's largely because of strong norms designed to protect experiment participants (and taken quite seriously by doctors I've talked to), together with limited upside for the experimenters, an overriding desire for vaccine manufacturers to avoid association with a trial that ends up looking bad (this doesn't apply to other kinds of trial but the upside is often lower and there's no real stakeholder), a lack of understanding for a long time of how big a problem this would be, the difficulty of quickly shifting time/attention from other problems to this one, and the general difficulty of running experiments.
comment by electroswing · 2021-04-29T22:26:08.044Z · LW(p) · GW(p)
What do you do to keep up with AI Safety / ML / theoretical CS research, to the extent that you do? And how much time do you spend on this? For example, do you browse arXiv, Twitter, ...?
A broader question I'd also be interested in (if you're willing to share) is how you allocate your working hours in general.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-04-30T23:31:11.667Z · LW(p) · GW(p)
What do you do to keep up with AI Safety / ML / theoretical CS research, to the extent that you do? And how much time do you spend on this? For example, do you browse arXiv, Twitter, ...?
Mostly word of mouth (i.e. I know the authors, or someone sends a link to a paper either to me directly or to a slack channel I'm on or...). I sometimes browse conference proceedings or arxiv but rarely find that much valuable. Sometimes I'm curious if anyone has made progress on issue X so search for it, or more often I'm curious about what some people have been up to so check if I've missed a paper.
I've been keeping up with things less well since leaving OpenAI.
comment by NoUsernameSelected · 2021-04-29T04:53:12.761Z · LW(p) · GW(p)
Are there any good examples of useful or interesting sub-problems in AI Alignment that can actually be considered "solved"?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T00:40:07.276Z · LW(p) · GW(p)
I don't think so.
Of course the same is true for machine learning, though it's less surprising there. I think subproblems getting solved is only something you'd really expect on a perspective like mine where you are looking for some kind of cleaner / more discrete notion of "solution." On that perspective maybe you'd count the special case "AIs are weak relative to humans, individual decisions are low-stakes" as being solved? (Though even then not quite.)
comment by justin · 2021-04-28T19:57:47.523Z · LW(p) · GW(p)
Given growth in both AI research and alignment research over the past 5 years, how do the rates of progress compare? Maybe separating absolute change, first and second derivatives.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:27:36.249Z · LW(p) · GW(p)
I'd guess that alignment research is now a smaller fraction of people working on "AGI" or on really ambitious AI projects (which has grown massively over the last 5 years), but a larger fraction of the total AI community (which has grown not-quite-as-massively).
For higher derivatives my guess is that alignment is currently doing better than AI more broadly so I'd tentatively expect alignment to grow proportionally over the coming years (maybe converging to something resembling OpenAI/DeepMind like levels throughout the entire community?)
I'm really speculating wildly though, and I would update readily if someone had actual numbers on growth.
comment by DanielFilan · 2021-04-30T08:01:23.304Z · LW(p) · GW(p)
Should more AI alignment research be communicated in book form? Relatedly, what medium of research communication is most under-utilized by the AI alignment community?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:35:20.063Z · LW(p) · GW(p)
I think it would be good to get more arguments and ideas pinned down, explained carefully, collected in one place. I think books may be a reasonable format for that, though man they take a long time to write.
I don't know what medium is most under-utilized.
comment by DanielFilan · 2021-04-30T07:49:12.433Z · LW(p) · GW(p)
What mechanisms could effective altruists adopt to improve the way AI alignment research is funded?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T00:43:08.014Z · LW(p) · GW(p)
Long run I'd prefer with something like altruistic equity [EA · GW] / certificates of impact [EA · GW]. But frankly I don't think we have hard enough funding coordination problems that it's going to be worth figuring that kind of thing out.
(And like every other community we are free-riders---I think that most of the value of experimenting with such systems would accrue to other people who can copy you if successful, and we are just too focused on helping with AI alignment to contribute to that kind of altruistic public good. If only someone would be willing to purchase the impact certificate from us if it worked out...)
comment by Ben Pace (Benito) · 2021-04-30T06:45:51.041Z · LW(p) · GW(p)
What is the main mistake you've made in your research, that you were wrong about?
Positive framing: what's been the biggest learning moment in the course of your work?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T02:04:10.350Z · LW(p) · GW(p)
Basically every time I've shied away from a solution because it feels like cheating, or like it doesn't count / address the real spirit of the problem, I've regretted it. Often it turns out it really doesn't count, but knowing exactly why (and working on the problem with no holds barred) had been really important for me.
The most important case was dismissing imitation learning back in 2012-2014, together with basically giving up outright on all ML approaches, which I only recognized as a problem when I was writing up why those approaches were doomed more carefully and why imitation learning was a non-solution.
comment by interstice · 2021-04-30T01:16:58.979Z · LW(p) · GW(p)
Any thoughts on the Neural Tangent Kernel/Gaussian Process line of research [LW · GW]? Or attempts to understand neural network training at a theoretical level more generally?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:11:44.156Z · LW(p) · GW(p)
Overall I haven't thought about it that much but it seems interesting. (I thought your NTK summary was good.)
With respect to alignment, the main lesson I've taken away is to be careful about intuitions that come from "building up structure slowly," you should at least check that all of your methods work fine in the local linear regime where in some sense everything is in there at the start and you are just perturbing weights a tiny bit. I think this has been useful for perspective. In some sense it's something you think about automatically when focusing on the worst case, but it's still nice to know which parts of the worst case are actually real and I think I used to overlook some of these issues more.
In practice it seems like the number of datapoints is large relative to the width, and in fact it's quite valuable to take multiple gradient descent steps even if your initialization is quite careful. So it doesn't seem like you can actually make the NTK simplification, i.e. you still have to deal with the additional challenges posed by long optimization paths. I'd want to think about this much more if there was a proposal that appeared to apply for the NTK but not for general neural networks (and I think that alignment for the NTK is a reasonable thing for people to think about though I don't see a way to get more traction than on the general case); in that case it feels unlikely that the proposal would apply directly but it would still be a suggestive hint.
More broadly, I do also think that understanding how neural networks behave is helpful for alignment (in the same ballpark as empirical work trying to e.g. more deeply understand how neural networks generalize in practice). I'm less excited about it than trying to resolve the problem for our current understanding of neural networks. Part of the reason is that my current conception of the alignment problem for neural networks seems to be extremely similar to our understanding for e.g. random program search, suggesting that a lot of what we are dealing with are pretty fundamental issues that probably won't change qualitatively unless we have a giant shift in our understanding of neural networks (though I think this might change as we make further progress on alignment.)
comment by electroswing · 2021-04-29T22:10:49.440Z · LW(p) · GW(p)
What's your take on "AI Ethics", as it appears in large tech companies such as Google or Facebook? Is it helping or hurting the general AI safety movement?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:18:41.009Z · LW(p) · GW(p)
I think "AI ethics" is pretty broad and have different feelings of different parts. I'm generally supportive of work that makes AI better for humanity or non-human animals, even when it's not focused on the long-term. Sometimes I'm afraid about work in AI ethics that doesn't seem pass any reasonable cost-benefit analysis, and that it will annoy people in AI and make it harder to get traction with pro-social policies that are better-motivated (I'm also sometimes concerned about this for work in AI safety). I don't have a strong view about the net effect of work in AI ethics on AI safety, but it generally seems good for the two communities to try to get along (at least as well as either of them gets along with AI more broadly, rather than viewing each other as competitors for some limited amount of socially-responsible oxygen).
comment by Raemon · 2021-05-01T05:34:59.929Z · LW(p) · GW(p)
Curated. I don't think we've curated an AMA before, and not sure if I have a principled opinion on doing that, but this post seems chock full of small useful incites, and fragments of ideas that seem like they might otherwise take awhile to get written up more comprehensively, which I think is good.
comment by Borasko · 2021-04-30T20:06:53.771Z · LW(p) · GW(p)
If you believe AGI will be created. What would be the median year you think it will be created at?
Ex. -2046, 2074, etc.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T01:29:28.472Z · LW(p) · GW(p)
2065
That's an estimate for TAI (i.e. world doubling every 4 years), not sure what "AGI" means exactly.
Broad distribution in both directions, reasonably good chance by 2040 (maybe 25%)?
Don't hold me to that. I think it's literally not the same as the last time someone asked in this AMA, inconsistencies preserved to give a sense for stability.
comment by Ben Pace (Benito) · 2021-04-30T07:57:56.183Z · LW(p) · GW(p)
Who do you admire?
comment by DanielFilan · 2021-04-30T07:39:30.617Z · LW(p) · GW(p)
What is the Paul Christiano production function?
comment by Ben Pace (Benito) · 2021-04-30T08:09:11.480Z · LW(p) · GW(p)
Which rationalist virtue [LW · GW] do you identify with the strongest currently? Which one would you like to get stronger at?
comment by Ben Pace (Benito) · 2021-04-30T07:52:46.930Z · LW(p) · GW(p)
What were your main updates from the past few months?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T16:49:13.375Z · LW(p) · GW(p)
Lots of in-the-weeds updates about theory, maybe most interestingly that "tell me what I want to hear" models are a large fraction of long-term (i.e. not-resolved-with-scale-and-diversity) generalization problems than I'd been imagining.
I've increased my probability on fast takeoff in the sense of successive doublings being 4-8x faster instead of 2x faster, by taking more seriously the possibility "if you didn't hit diminishing-marginal-returns in areas like solar panels, robotics, and software, current trends would actually imply faster-than-industrial-revolution takeoff even without AI weirdness." That's not really a bayesian update, just a change in beliefs.
comment by Ben Pace (Benito) · 2021-04-30T06:31:12.689Z · LW(p) · GW(p)
Favorite SSC / ASX post?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T16:53:16.354Z · LW(p) · GW(p)
...And I show you how deep the rabbit hole goes
Maybe Guided by the Beauty of our Weapons if fiction doesn't count. (I expect I'd think of a better post than this one if I thought longer, but not a better post than the black pill story.)
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:41:29.759Z · LW(p) · GW(p)
There has been surprisingly little written on concrete threat models for how AI leads to existential catastrophes (though you've done some great work rectifying this!). Why is this? And what are the most compelling threat models that don't have good public write-ups? In particular, are there under-appreciated threat models that would lead to very different research priorities within Alignment?
Replies from: paulfchristiano, paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:02:45.962Z · LW(p) · GW(p)
And what are the most compelling threat models that don't have good public write-ups?
Depends how you slice and dice the space (and what counts as a "threat model"), I don't have a good answer for this. In general I feel like a threat model is more like something that everyone can make for themselves and is a model of the space of threats, not like a short list of things that you might discover.
We could talk about particular threats that don't have good public write-ups. I feel like there are various humans-are-fragile-so-weak-AI-takes-over-when-world-falls-apart possibilities and those haven't been written up very well.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-05-01T18:48:11.716Z · LW(p) · GW(p)
I think Neel is using this in the sense I use the phrase, where you carve up the space of threats in some way, and then a "threat model" is one of the pieces that you carved up, rather than the way in which you carved it up.
This is meant to be similar to how in security there are many possible kinds of risks you might be worried about, but then you choose a particular set of capabilities that an attacker could have and call that a "threat model" -- this probably doesn't capture every setting you care about, but does capture one particular piece of it.
(Though maybe in security the hope is to choose a threat model that actually contains all the threats you expect in reality, so perhaps this analogy isn't the best.)
(I think "that's a thing that people make for themselves" is also a reasonable response for this meaning of "threat model".)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T18:59:23.405Z · LW(p) · GW(p)
On that perspective I guess by default I'd think of a threat as something like "This particular team of hackers with this particular motive" and a threat model as something like "Maybe they have one or two zero days, their goal is DoS or exfiltrating information, they may have an internal collaborator but not one with admin privileges..." And then the number of possible threat models is vast even compared to the vast space of threats.
↑ comment by paulfchristiano · 2021-05-01T16:59:19.721Z · LW(p) · GW(p)
There has been surprisingly little written on concrete threat models for how AI leads to existential catastrophes (though you've done some great work rectifying this!). Why is this?
I'm not sure why there isn't more work on concrete descriptions of possible futures and how they go wrong. Some guesses:
- Anything concrete is almost certainly wrong. People are less convinced that it's useful given that it will be wrong, and so try to make vaguer / more abstract stories that maybe describe reality at the expense of having less detail.
- It's not exactly clear what you do with such a story or what the upside is, it's kind of a vague theory of change and most people have some specific theory of change they are more excited about (even if this kind of story is a bit of a public good that's useful on a broader variety of perspectives / to people who are skeptical).
- Any detailed story produced in a reasonable amount of time will also be obviously wrong to someone who notices the right considerations or has the right background. It's very demoralizing to write something that someone is going to recognize is obviously incoherent/wrong (especially if you expect that to get pointed out and taken by some to undermine your view).
- It just kind of takes a long time and is hard, and people don't do that many hard things that take a long time.
- A lot of people most interested in futurism are into very fast-take-off models where there isn't as much to say and they maybe feel like it's mostly been said.
(I think that "threat models" is somewhat broader / different from concrete stories, and it's a bit less clear to me exactly how much people have done or what counts.)
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2021-05-01T19:05:06.476Z · LW(p) · GW(p)
It's not exactly clear what you do with such a story or what the upside is, it's kind of a vague theory of change and most people have some specific theory of change they are more excited about (even if this kind of story is a bit of a public good that's useful on a broader variety of perspectives / to people who are skeptical).
Ah, interesting! I'm surprised to hear that. I was under the impression that while many researchers had a specific theory of change, it was often motivated by an underlying threat model, and that different threat models lead to different research interests.
Eg, someone worries about a future where AI control the world but are not human comprehensible, feels very different from someone worried about a world where we produce an expected utility maximiser that has a subtly incorrect objective, resulting in bad convergent instrumental goals.
Do you think this is a bad model of how researchers think? Or are you, eg, arguing that having a detailed, concrete story isn't important here, just the vague intuition for how AI goes wrong?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T20:50:25.341Z · LW(p) · GW(p)
I think most people have expectations regarding e.g. how explicitly will systems represent their preferences, how much will they have preferences, how will that relate to optimization objectives used in ML training, how well will they be understood by humans, etc.
Then there's a bunch of different things you might want: articulations of particular views on some of those questions, stories that (in virtue of being concrete) show a whole set of guesses and how they can lead to a bad or good outcome, etc. My bullet points were mostly regarding the exercise of fleshing out a particular story (which is therefore most likely to be wrong), rather than e.g. thinking about particular questions about the future.
comment by edoarad · 2021-04-28T19:46:15.527Z · LW(p) · GW(p)
What sort of epistemic infrastructure [EA · GW] do you think is importantly missing for the alignment research community?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:10:19.841Z · LW(p) · GW(p)
One category is novel epistemic infrastructure that doesn't really exist in general and would benefit all communities---over the longer term those seem like the most important missing things (but we won't be able to build them straightforwardly / over the short term and they won't be built for the alignment community in particular, they are just things that are missing and important and will eventually be filled in). The most salient instances are better ways of dividing up the work of evaluating arguments and prioritizing things to look at, driven by reputation or implicit predictions about what someone will believe or find useful.
In general for this kind of innovation I think that almost all of the upside comes from people copying the small fraction of successful instances (each of which likely involves more work and a longer journey than could be justified for any small group).
The other category is stuff that could be set up more quickly / has more of a reference class. I don't really have a useful answer for that, though I'm excited for eventually developing something a bit more like academic workshops that serve a community with a shared sense of the problem and who actually face similar day-to-day difficulties. I think this hasn't really been the case for attempts at literal academic workshops; I expect it to probably grow out of coordination between alignment efforts at ML labs.
comment by Ben Pace (Benito) · 2021-04-30T07:48:40.144Z · LW(p) · GW(p)
Who is right between Eliezer and Robin in the AI FOOM debate?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:50:25.076Z · LW(p) · GW(p)
I mostly found myself more agreeing with Robin, in that e.g. I believe previous technical change is mostly a good reference class, that Eliezer's AI-specific arguments are mostly kind of weak. (I liked the image, I think from that debate, of a blacksmith emerging into the townsquare with his mighty industry and making all bow before them.)
That said, I think Robin's quantitative estimates/forecasts are pretty off and usually not very justified, and I think he puts too much stock on an outside view extrapolation from past transitions rather than looking at the inside view for existing technologies (the extrapolation seems helpful in the absence of anything else, but it's just not that much evidence given the shortness and noisiness of the time series and the shakiness of the underlying regularities). I don't remember exactly what kinds of estimates he gives in that debate.
(This is more obvious for his timeline estimates, which I think have an almost comically flimsy justification given how seriously he takes them.)
Overall I think that it would be more interesting to have a Carl vs Robin FOOM debate; I expect the outcome would be Robin saying "do you really call that a FOOM?" and Carl saying "well it is pretty fast and would have crazy disruptive geopolitical consequences and generally doesn't fit that well with your implied forecasts about the world even if not contradicting that many of the things you actually commit to" and we could all kind of agree and leave it at that modulo a smaller amount of quantitative uncertainty.
Replies from: Benito, RobbBB↑ comment by Ben Pace (Benito) · 2021-05-01T18:06:34.173Z · LW(p) · GW(p)
Noted.
(If both parties are interested in that debate I’m more than happy to organize it in whatever medium and do any work like record+transcripts or book an in-person event space.)
↑ comment by Rob Bensinger (RobbBB) · 2021-05-01T21:18:06.567Z · LW(p) · GW(p)
Source for the blacksmith analogy: I Still Don't Get Foom
comment by Søren Elverlin (soren-elverlin-1) · 2021-04-29T11:17:06.808Z · LW(p) · GW(p)
In the interview with AI Impacts, you said:
...examples of things that I’m optimistic about that they [people at MIRI] are super pessimistic about are like, stuff that looks more like verification...
Are you still optimistic? What do you consider the most promising recent work?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T02:31:18.014Z · LW(p) · GW(p)
I don't think my view has changed too much (I don't work in the area so don't pay as much attention or think about it as often as I might like).
The main updates have been:
- At the time of that interview I think it was public that Interval Bound Propagation was competitive with other verification methods for perturbation robustness, but I wasn't aware of that and definitely hadn't reflected on it. I think this makes other verification schemes seem somewhat less impressive / it's less likely they are addressing the hard parts of the problem we ultimately need to solve. I haven't really talked about this with researchers in the area so am not sure if it's the right conclusion.
- Since then my vague sense is that robustness research has continued to make progress but that there aren't promising new ideas in verification. This isn't a huge update since not many people are working on verification with an eye towards alignment applications (and the rate of progress has always been slow / close to zero) but it's still a somewhat negative update.
↑ comment by Søren Elverlin (soren-elverlin-1) · 2021-05-01T14:18:40.677Z · LW(p) · GW(p)
Thank you for your answer, and good luck with the Alignment Research Center.
comment by DanielFilan · 2021-04-30T08:10:28.781Z · LW(p) · GW(p)
What's the optimal ratio of researchers to support staff in an AI alignment research organization?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:19:10.484Z · LW(p) · GW(p)
I guess it depends a lot on what the organization is doing and how exactly we classify "support staff." For my part I'm reasonably enthusiastic about eventually hiring people who are engaged in research but whose main role is more like clarifying, communicating, engaging with outside world, prioritizing, etc., and I could imagine doing like 25-50% as much of that kind of work as we do of frontier-pushing? I don't know whether you'd classify those people as researchers (though I probably wouldn't call it "support" since that seems to kind of minimize the work).
Once you are relying on lots of computers, that's a whole different category of work and I'm not sure what the right way of organizing that is or what we'd call support.
In terms of things like fundraising, accounting, supporting hiring processes, making payroll and benefits, budgeting, leasing and maintaining office space, dealing with the IRS, discharging legal obligations of employers, immigration, purchasing food, etc.... I'd guess it's very similar to other research organizations with similar salaries. I'm very ignorant about all of this stuff (I expect to learn a lot about it) but I'd guess that depending on details it ends up being 10-20% of staff. But it could go way lower if you outsource a lot to external vendors rather than in-house. (And if you organize a lot of events then that kind of work could just grow basically without bound and in that case I'd again wonder if "support" is the right word.)
comment by Ben Pace (Benito) · 2021-04-30T06:40:36.541Z · LW(p) · GW(p)
What's a direction you'd like to see the rationality community grow stronger in over the coming 5-10 years?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:20:19.601Z · LW(p) · GW(p)
More true beliefs (including especially about large numbers of messy details rather than a few central claims that can receive a lot of attention).
comment by Ben Pace (Benito) · 2021-04-30T06:27:15.694Z · LW(p) · GW(p)
What works of fiction / literature have had the strongest impact on you? Or perhaps, that are responsible for the biggest difference in your vector relative to everyone else's vector?
(e.g. lots of people were substantially impacted by the Lord of the Rings, but perhaps something else had a big impact on you that led you in a different direction from all those people)
(that said, LotR is a fine answer)
comment by Neel Nanda (neel-nanda-1) · 2021-04-28T21:34:55.812Z · LW(p) · GW(p)
You gave a great talk on the AI Alignment Landscape 2 years ago. What would you change if giving the same talk today?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:24:27.664Z · LW(p) · GW(p)
The boxes at the top haven't really changed. The boxes at the bottom never felt that great, it still seems like a fine way for them to be---I expect they would change if I did it again but I wouldn't feel any better about the change than I did about the initial or final version.
comment by Eric Chen (Equilibrate) · 2021-04-30T16:50:17.801Z · LW(p) · GW(p)
Do you think progress has been made on the question of "which AIs are good successors?" Is this still your best guess for the highest impact question in moral philosophy right now? Which other moral philosophy questions, if any, would you put in the bucket of questions that are of comparable importance?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:31:28.145Z · LW(p) · GW(p)
I'm not aware of anyone trying to work on that problem (but I don't follow academic philosophy so for all I know there's lots of relevant stuff even before my post).
It's still at the top of my list of problems in moral philosophy.
The most natural other question of similar importance is how nice we should be to other humans, e.g. how we should prioritize actions that involve leaving us better off and others worse off (either people different from us, people similar to us, governments that don't represent their constituents well, etc.). Neither of those questions is a single simple question (though the AI one feels more like a single simple question since it has so many aspects so different from what people normally think about), they are big clouds of questions that feel kind of core to the whole project of moral philosophy.
(Obviously all of that is coming from a very consequentialist perspective, such that these questions involve a distinctive-to-consequentialists mix of axiology, decision theory, and understanding how moral intuitions relate to both.)
Replies from: quinn-dougherty↑ comment by Quinn (quinn-dougherty) · 2021-05-02T11:45:09.039Z · LW(p) · GW(p)
If anyone's interested, I took a crack at writing down a good successor criterion [LW · GW].
comment by DanielFilan · 2021-04-30T07:42:22.528Z · LW(p) · GW(p)
How many new blogs do you anticipate creating in the next 5 years?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:51:39.981Z · LW(p) · GW(p)
I've created 3 blogs in the last 10 years and 1 blog in the preceding 5 years. It seems like 1-2 is a good guess. (A lot depends on whether there ends up being an ARC blog or it just inherits ai-alignment.com)
comment by Ben Pace (Benito) · 2021-04-30T07:42:12.882Z · LW(p) · GW(p)
Let me ask the question Daniel Filan is too polite to ask: would you like to be interviewed on your research for an episode of the AXRP podcast?
Replies from: DanielFilan↑ comment by DanielFilan · 2021-04-30T07:57:00.123Z · LW(p) · GW(p)
That's not the AXRP question I'm too polite to ask.
Replies from: Benito↑ comment by Ben Pace (Benito) · 2021-04-30T08:01:15.863Z · LW(p) · GW(p)
Paul, if you did an episode of AXRP, which two other AXRP episodes do you expect your podcast would be between, in terms of quality? For this question, collapse all aspects of quality into a scalar.
comment by edoarad · 2021-04-28T19:36:50.835Z · LW(p) · GW(p)
What's your take on Elicit?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:38:37.754Z · LW(p) · GW(p)
I'm excited for people to get good at building tools to help with open-ended tasks that feel a bit more like "wisdom," I think elicit is a step in that direction. I'm also excited about getting better at applying ML to tasks where we don't really have datasets / eventually where the goal is to aim for superhuman performance, and I think elicit will grow into a good test case for that (and is to some extent right now).
I basically think the main question is whether they are / will be able to make an excellent product that helps people significantly (and then whether they are able to keep scaling that up).
(Note that I'm a funder / board member.)
comment by Eric Chen (Equilibrate) · 2021-04-30T17:10:06.367Z · LW(p) · GW(p)
Philosophical Zombies: inconceivable, conceivable but not metaphysically possible, or metaphysically possible?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:23:52.414Z · LW(p) · GW(p)
Conceivable but not logically possible?
(See also: l-zombies [LW · GW] about which I feel similarly.)
comment by DanielFilan · 2021-04-30T08:04:28.897Z · LW(p) · GW(p)
Should more AI alignment researchers run AMAs?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:44:33.392Z · LW(p) · GW(p)
Dunno, would be nice to figure out how useful this AMA was for other people. My guess is that they should at some rate/scale (in combination with other approaches like going on a podcast or writing papers or writing informal blog posts), and the question is how much communication like that to do in an absolute sense and how much should be AMAs vs other things.
Maybe I'd guess that typically like 1% of public communication should be something like an AMA, and that something like 5-10% of researcher time should be public communication (though as mentioned in another comment you might have some specialization there which would cut it down, though I think that the AMA format is less likely to be split off, though that might be an argument for doing less AMA-like stuff and more stuff that gets split off...). So that would suggest like 0.05-0.1% of time on AMA-like activities. If the typical one takes a full-time-day-equivalent, then that's like doing one every 2 years, which I guess would be way more AMAs than we have. This AMA is more like a full-time day so maybe every 4 years?
That feels a bit like an overestimate, but overall I'd guess that it would be good on the margin for there to be more alignment researcher AMAs. (But I'm not sure if AMAs are the best AMA-like thing.)
In general I think that talking with other researchers and practitioners 1:1 is way more valuable than broadcast communication.
comment by DanielFilan · 2021-04-30T07:48:05.187Z · LW(p) · GW(p)
Why aren't impact certificates a bigger deal?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:26:37.313Z · LW(p) · GW(p)
Change is slow and hard and usually driven by organic changes rather than clever ideas, and I expect it to be the same here.
In terms of why the idea is actually just not that big a deal, I think the big thing is that altruistic projects often do benefit hugely from not needing to do explicit credit attribution. So that's a real cost. (It's also a cost for for-profit businesses, leading to lots of acrimony and bargaining losses.)
They also aren't quite consistent with moral public goods [LW · GW] / donation-matching, which might be handled better by a messy status quo, and I think that's a long-term problem though probably not as big as the other issues.
comment by Ben Pace (Benito) · 2021-04-30T06:27:58.860Z · LW(p) · GW(p)
Other than by doing your own research, from where or whom do you tend to get valuable research insights?
comment by James_Miller · 2021-04-29T12:35:53.180Z · LW(p) · GW(p)
What would you advise a college student to do if the student is unusually good at math and wants to contribute to creating an aligned AGI? Beyond a computer science major/multivariable calculus/linear algebra/statistics what courses should this student take?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:56:02.581Z · LW(p) · GW(p)
Lots of ML courses, and undergrad is a really good time to try to do some ML projects on your own and get good at actually making stuff work.
On the math side, seems reasonable to me to also do a bit of learning theory and a few more statistics courses (e.g. the intro grad course and maybe one or two beyond that), those may run together.
Probably also just good to spend some time thinking seriously about alignment and developing your own views / trying to make progress (even if initially it's misguided), though without any source of mentorship on that I'd probably have it be a minority of self-directed time. If somehow you are at a place with good classes on ML alignment it's probably worth taking, and maybe at any rate worth taking classes on other aspects of safety and ethics to learn what the landscape is like and be exposed to some adjacent problems.
comment by interstice · 2021-04-30T17:11:10.317Z · LW(p) · GW(p)
Have you read much philosophy? If so, what are your favorite books/articles?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T18:07:36.013Z · LW(p) · GW(p)
I haven't read much at all. I read a bunch of the western classics (mostly just bits and pieces though) as part of undergrad classes which I mostly did not like (or found that they were already in the water enough that I got little benefit). I read modern stuff that's adjacent to EA/rationalist interests but mostly I don't really care about the way people approach the questions even when they are interesting questions. I've had a few experiences of philosophers telling me that I should really engage with what's been done in philosophy on some topic, but at this point those have mostly felt like dead ends and I've pretty much given up.
I liked Good and Real, which I think is largely just a reflection of the last paragraph (my impression is that it's the kind of thing that academic philosophers are very not-into but LW types love).
comment by DanielFilan · 2021-04-30T07:38:20.948Z · LW(p) · GW(p)
How will we know when it's not worth getting more people to work on reducing existential risk from AI?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:59:02.496Z · LW(p) · GW(p)
We'll do the cost-benefit analysis and over time it will look like a good career for a smaller and smaller fraction of people (until eventually basically everyone for whom it looks like a good idea is already doing it).
That could kind of qualitatively look like "something else is more important," or "things kind of seem under control and it's getting crowded," or "there's no longer enough money to fund scaleup." Of those, I expect "something else is more important" to be the first to go (though it depends a bit on how broadly you interpret "from AI," if anything related to the singularity / radically accelerating growth is classified as "from AI" then it may be a core part of the EA careers shtick kind of indefinitely, with most of the action in which of the many crazy new aspects of the world people are engaging with).
comment by electroswing · 2021-04-29T22:05:55.080Z · LW(p) · GW(p)
You've appeared on the 80,000 Hours podcast two times. To the extent that you remember what you said in 2018-19, are there any views you communicated then which you no longer hold now? Another way of asking this question is—do you still consider those episodes to be accurate reflections of your views?
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T17:36:16.880Z · LW(p) · GW(p)
I don't remember anything in particular where my view changed but I don't really remember what I said (happy to answer particular questions about my views). I'd guess they are still roughly accurate but that like 5% of the things I said I'd now disagree with and 5% I'd feel ambivalent about?
comment by Oliver Sourbut · 2021-05-01T21:52:50.403Z · LW(p) · GW(p)
What kind of relationships to 'utility functions' do you think are most plausible in the first transformative AI?
How does the answer change conditioned on 'we did it, all alignment desiderata got sufficiently resolved' (whatever that means) and on 'we failed, this is the point of no return'?
Replies from: Oliver Sourbut↑ comment by Oliver Sourbut · 2021-05-01T22:06:52.076Z · LW(p) · GW(p)
I'm taking about relationships like
AGI with explicitly represented utility function which is a reified part of its world- and self- model
or
sure, it has some implicit utility function, but it's about as inscrutable to the agent itself as it is to us
comment by Lukas Finnveden (Lanrian) · 2021-05-01T16:41:17.415Z · LW(p) · GW(p)
I'm curious about the extent to which you expect the future to be awesome-by-default as long as we avoid all clear catastrophes along the way; vs to what extent you think we just has a decent chance of getting a non-negligible fraction of all potential value (and working to avoid catastrophes is one of the most tractable ways of improving the expected value).
Proposed tentative operationalisation:
- World A is just like our world, except that we don't experience any ~GCR on Earth in the next couple of centuries, and we solve the problem of making competitive intent-aligned AI.
- In world B, we also don't experience any GCR soon and we also solve alignment. In addition, you and your chosen collaborators get to design and implement some long-reflection-style scheme that you think will best capture the aggregate of human and non-human desires. All coordination and cooperation problems on Earth are magically solved. Though no particular values are forced upon anyone, everyone is happy to stop and think about what they really want, and contribute to exercises designed to illuminate this.
How much better do you think world B is compared to world A? (Assuming that a world where Earth-originating intelligence goes extinct has a baseline value of 0.)
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T18:15:18.729Z · LW(p) · GW(p)
I would guess GCRs are generally less impactful than pressures that lead our collective preferences to evolve in a way that we wouldn't like on reflection. Such failures are unrecoverable catastrophes in the sense that we have no desire to recover, but in a pluralistic society they would not necessarily or even typically be global. You could view alignment failures as an example of values drifting, given that the main thing at stake are our preferences about the universe's future rather than the destruction of earth-originating intelligent life.
I expect this is the kind of thing I would be working on if I thought that alignment risk was less severe. My best guess about what to do is probably just futurism---understanding what is likely to happen and giving us more time to think about that seems great. Maybe eventually that leads to a different priority.
comment by Joe_Collman · 2021-04-29T04:45:58.598Z · LW(p) · GW(p)
I'd be interested in your thoughts on human motivation in HCH and amplification schemes.
Do you see motivational issues as insignificant / a manageable obstacle / a hard part of the problem...?
Specifically, it concerns me that every H will have preferences valued more highly than [completing whatever task we assign], so would be expected to optimise its output for its own values rather than the assigned task, where these objectives diverged. In general, output needn't relate to the question/task.
[I don't think you've addressed this at all recently - I've only come across specifying enlightened judgement precisely]
I'd appreciate if you could say if/where you disagree with the following kind of argument.
I'd like to know what I'm missing:
Motivation seems like an eventual issue for imitative amplification. Even for an H who always attempted to give good direct answers to questions in training, the best models at predicting H's output would account for differing levels of enthusiasm, focus, effort, frustration... based in part on H's attitude to the question and the opportunity cost in answering it directly.
The 'correct' (w.r.t. alignment preservation) generalisation must presumably be in all circumstances to give the output that H would give. In scenarios where H wouldn't directly answer the question (e.g. because H believed the value of answering the question were trivial relative to opportunity cost), this might include deception, power-seeking etc. Usually I'd expect high value true-and-useful information unrelated to the question; deception-for-our-own-good just can't be ruled out.
If a system doesn't always adapt to give the output H would, on what basis do we trust it to adapt in ways we would endorse? It's unclear to me how we avoid throwing the baby out with the bathwater here.
Or would you expect to find Hs for whom such scenarios wouldn't occur? This seems unlikely to me: opportunity cost would scale with capability, and I'd predict every H would have their price (generally I'm more confident of this for precisely the kinds of H I'd want amplified: rational, altruistic...).
If we can't find such Hs, doesn't this at least present a problem for detecting training issues?: if HCH may avoid direct answers or deceive you (for worthy-according-to-H reasons), then an IDA of that H eventually would too. At that point you'd need to distinguish [benign non-question-related information] and [benevolent deception] from [malign obfuscation/deception], which seems hard (though perhaps no harder than achieving existing oversight desiderata???).
Even assuming that succeeds, you wouldn't end up with a general-purpose question-answerer or task-solver: you'd get an agent that does whatever an amplified [model predicting H-diligently-answering-training-questions] thinks is best. This doesn't seem competitive across enough contexts.
...but hopefully I'm missing something.
Replies from: paulfchristiano↑ comment by paulfchristiano · 2021-05-01T18:48:15.890Z · LW(p) · GW(p)
I mostly don't think this thing is a major issue. I'm not exactly sure where I disagree, but some possibilities:
- H isn't some human isolated from the world, it's an actual process we are implementing (analogous to the current workflow involving external contractors, lots of discussion about the labeling process and what values it might reflect, discussions between contractors and people who are structuring the model, discussions about cases where people disagree)
- I don't think H is really generalizing OOD, you are actually collecting human data on the kinds of questions that matter (I don't think any of my proposals rely on that). So the scenario you are talking about is something like the actual people who are implementing H---real people who actually exist and we are actually working with---are being offered payments or extorted or whatever by the datapoints that the actual ML is giving them. That would be considered a bad outcome on many levels (e.g. man that sounds like it's going to make the job stressful), and you'd be flagging models that systematically produce such outputs (if all is going well they shouldn't be upweighted), and coaching contractors and discussing the interesting/tricky cases and so on.
- H is just not making that many value calls, they are mostly implemented by the process that H answers. Similarly, we're just not offloading that much of the substantive work to H (e.g. they don't need to be super creative or wise, we are just asking them to help construct a process that responds appropriately to evidence).
- I don't really know what kind of opportunity cost you have in mind. Yes, if we hire contractors and can't monitor their work they will sometimes do a sloppy job. And indeed if someone from an ML team is helping run an oversight process there might be some kinds of inputs where they don't care and slack off? But there seems to be a big mismatch between the way this scenario is being described and a realistic process for producing of training data.
- Most of the errors that H might make don't seem like they contribute to large-scale consequentialist behavior within HCH, and mostly just doesn't seem like a big deal or serious problem. We think a lot about kinds of errors that H might make that aren't noise, e.g. systematic divergences between what contractors do and what we want them to do, and it seems easy for them to be worse than random (and that's something we can monitor) but there's a lot of room between that and "undermines benignness."
Overall it seems like the salient issue is whether sufficiently ML-optimized outputs can lead to malign behavior by H (in which case it is likely also leading to crazy stuff in the outside world), but I don't think that motivational issues for H are a large part of the story (those cases would be hard for any humans, and this is a smaller source of variance than other kinds of variation in H's competence or our other tools for handling scary dynamics in HCH).
Replies from: Joe_Collman↑ comment by Joe_Collman · 2021-05-03T05:14:43.741Z · LW(p) · GW(p)
Thanks, that's very helpful. It still feels to me like there's a significant issue here, but I need to think more. At present I'm too confused to get much beyond handwaving.
A few immediate thoughts (mainly for clarification; not sure anything here merits response):
- I had been thinking too much lately of [isolated human] rather than [human process].
- I agree the issue I want to point to isn't precisely OOD generalisation. Rather it's that the training data won't be representative of the thing you'd like the system to learn: you want to convey X, and you actually convey [output of human process aiming to convey X]. I'm worried not about bias in the communication of X, but about properties of the generating process that can be inferred from the patterns of that bias.
- It does seem hard to ensure you don't end up OOD in a significant sense. E.g. if the content of a post-deployment question can sometimes be used to infer information about the questioner's resource levels or motives.
- The opportunity costs I was thinking about were in altruistic terms: where H has huge computational resources, or the questioner has huge resources to act in the world, [the most beneficial information H can provide] would often be better for the world than [good direct answer to the question]. More [persuasion by ML] than [extortion by ML].
- If (part of) H would ever ideally like to use resources to output [beneficial information], but gives direct answers in order not to get thrown off the project, then (part of) H is deceptively aligned. Learning from a (partially) deceptively aligned process seems unsafe.
- W.r.t. H's making value calls, my worry isn't that they're asked to make value calls, but that every decision is an implicit value call (when you can respond with free text, at least).
I'm going to try writing up the core of my worry in more precise terms.
It's still very possible that any non-trivial substance evaporates under closer scrutiny.
comment by Mark Xu (mark-xu) · 2021-04-29T05:28:40.283Z · LW(p) · GW(p)
How would you teach someone how to get better at the engine game?
Replies from: neel-nanda-1, paulfchristiano↑ comment by Neel Nanda (neel-nanda-1) · 2021-04-29T12:40:14.073Z · LW(p) · GW(p)
What's the engine game?
Replies from: mark-xu↑ comment by Mark Xu (mark-xu) · 2021-04-29T17:28:57.245Z · LW(p) · GW(p)
engine-game.com, a game that Paul develops
↑ comment by paulfchristiano · 2021-05-01T18:36:43.258Z · LW(p) · GW(p)
No idea other than playing a bunch of games (might as well current version, old dailies probably best) and maybe looking at solutions when you get stuck. Might also just run through a bunch of games and highlight the main important interactions and themes for each of them, e.g. Innovation + Public Works + Reverberate or Hatchery + Till. I think on any given board (and for the game in general) it's best to work backwards from win conditions, then midgames, and then openings.
comment by emmab · 2021-05-01T09:20:34.746Z · LW(p) · GW(p)
Why does evil exist?
Replies from: Teerth Aloke↑ comment by Teerth Aloke · 2021-05-01T09:30:46.583Z · LW(p) · GW(p)
Define evil.
comment by Bara Hanzalova · 2021-04-30T01:23:48.979Z · LW(p) · GW(p)
What do you think of a successor AI that collects data on one’s wellbeing (‘height’ via visual analog scale and ‘depth’ by assessing one’s understanding of the rationale for their situation), impact (thinking and actions toward others), and connections (to verify impact based on network analysis and wellbeing data and to predict populations’ welfare), motivates decreases of suffering groups’ future generations, rewards individuals with impact that is increasing or above a certain level, and withdraws benefits/decreases wellbeing of individuals whose impact is decreasing and below a certain level?
comment by Bara Hanzalova · 2021-04-30T01:50:51.941Z · LW(p) · GW(p)
Are you going to implement critical reading that would continuously ameliorate biases in your work? If so, how?
comment by CraigMichael · 2021-04-29T03:42:33.260Z · LW(p) · GW(p)
What would you say to Jaron Lanier?