Regress Thyself to the Mean
post by Gordon Seidoh Worley (gworley) · 2017-10-19T22:42:08.925Z · LW · GW · 0 commentsThis is a link post for https://mapandterritory.org/regress-thyself-to-the-mean-932d5fd9789d
Contents
Regressive Statistics Put a Number on It Entropic Regression None No comments
I don’t usually write about well understood things: others are better explainers than I am, and I have more fun working at the edge. But a few weeks ago I was commenting on a Facebook post and the exchange went something like this:
Them: I think [subculture] is fading out because it’s being softened by the surrounding culture of the city.
Me: Actually, that seems insufficiently parsimonious to me. I think a simpler explanation is that people in [subculture] are aging.
Someone else: You don’t even need to suppose it’s aging related. It’s probably just regression to the mean.
Me:

So to atone for my sin of neglecting the most likely reason anything ever happens, I present to you my penance — an introduction to regression to the mean.
Regressive Statistics
Suppose you are sitting on a park bench, watching people walk by. You notice the height of each person that passes you and develop a sense for how the height of people at the park is distributed. After some time a friend joins you on the bench and, hearing about what you’ve been doing, ask you if the next person to walk by is likely to be taller or shorter than the last person who did.
Regression to the mean tells you how to answer this. Whatever the distribution of the heights of the park goers, each person who walks by, lacking any other information to inform your decision, is likely to be in the direction of the mean within the height distribution relative to the previous person. So if a short person walks by, you tell your friend the next person is likely to be taller and vice versa, and most of the time you will be right!
There are several ways to understand why this works, but I think the most straightforward is to think in terms of sampling from a distribution. You know the heights of the people you’ve seen in the park, so if you charted a histogram of their height measurements you’d get a picture that looked approximately like this:
Then if you observe someone of any particular height, you can divide the histogram into two sections: those shorter than the observed height and those taller. Because of the way the data is distributed, though, the side with the mean will always have more of the probability density than the other side, so it is always more likely than not that the next sample will be in the direction where the mean is located. Thus the tendency to regress towards the mean.
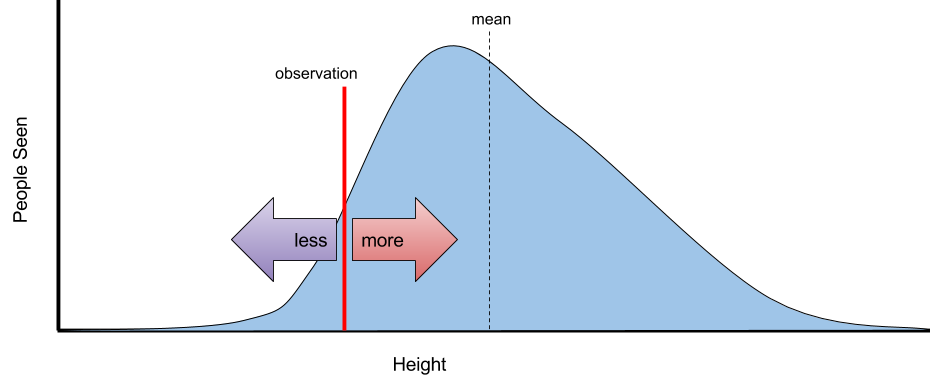
Note though that regression to the mean does not imply that the next person to walk by will likely be closer to the mean, just more likely to be in the direction of it relative to the last sample. The distinction is important because for observations close to the mean the opposite — that the next person is farther away from the mean than the previous person — is more likely to be true because of variance. For example, if a person is only 1 inch taller than average but the variance in height is 6 inches, the next person is more likely to be more than 1 inch shorter/taller than average than the last person and thus farther away from the mean. After all, regression to the mean applies to variance too.
But you probably don’t care much about how tall people are, so I hope you are asking yourself “what else can I use this for?”. As it turns out, just about everything.
Put a Number on It
I might not go as far as Jacob Falkovich in my desire to put numbers to things, but a lot of opportunities open up if you think of the world as measurable, even when it seems totally impossible to take measurements. Being able to use regression to the mean as an explanation is one such opportunity.
Take the conversation that spawned this post as an example: someone said that a subculture had grown “less distinct” over time, but for a subculture to be less or more distinct means we must be able to measure it in terms of distinctness. It doesn’t really matter for our purposes how this measurement is done, just that we can take a measure. Once we have our measure we can take sample measurements of different subcultures at different times and come up with a distribution of subcultures’ distinctnesses. Then it’s straight forward to say that more distinct subcultures are likely to become less distinct over time and vice versa because subsequent measures are likely to regress to the mean. If it looks like a subculture is less distinct now than it used to be, the obvious line of reasoning should be that its distinctness is regressing to the mean.
We can similarly apply regression to the mean to help understand almost anything we can measure — test scores, fashion, salaries, productivity, prestige, cuteness, etc. — but only if we apply it correctly. Consider students in a class where their grade is determined by a midterm and final exam. Does regression to the mean imply that students who do poorly on the midterm will do better on the final exam and vice-versa? No. The trouble is that the students’ scores are not identically and independently distributed random variables: how they perform on the midterm impacts how they will perform on the final. Some possibilities:
- A student who gets a bad score on the midterm may study harder to get a better score on the final so they can pass the class.
- A student who gets a good score on the midterm may slack off because they can get a lower score on the final and still pass the class.
- A student who does well on the midterm may also do well on the final because they study hard all semester.
- A student who fails the midterm may give up and drop the class or stop studying and intentionally fail.
In the language of control systems we might say the students are negative feedback loops working to keep their inputs on target, and in the language of information theory we would say that our samples (test scores) from each random variable (student) possess mutual information. We won’t see regression to the mean in this case, though, even if all the students followed a move-in-the-direction-of-the-mean pattern, and any such resemblance to regression to the mean would be coincidental, because regression to the mean is what happens when nothing tries to affect the value measured. If work is being done then regression to the mean is not happening.
Entropic Regression
This sounds an awful lot like regression to the mean should never happen since the universe is full of things doing work, everything is tangled up with everything else, and mutual information always exists except when it doesn’t matter. We could suppose to the contrary that every instance of what we think is regression to the mean is actually negative feedback, but this hardly seems parsimonious since nothing happening is generally more likely than something happening, and any feedback whatsoever demands at least phenomenological consciousness. So how can it be that we see regression to the mean so often if in reality the conditions of its operation are never met?
The answer is entropy. Regression to the mean isn’t a process so much as a manifestation of the general tendency of the universe to move towards low energy states as seen through the lens of statistics. Thus it’s not that the existence of mutual information prevents regression to the mean from happening, but that mutual information is the work being done to counteract regression to the mean, and if the amount mutual information is too small — if not enough entropy is displaced to notice a local rise in complexity — then it fades into the background noise and goes unnoticed because it’s weaker than the static that is regression to the mean.

This is the “real” reason regression to the mean explains so much: it’s what happens by default if nobody does anything. Regression to the mean, entropy, static, noise, and kipple are all the same “thing” in that they are all the no-thing of emptiness that fills the void between intentional stuff. They are the yin to purposeful work’s yang; the resting state everything returns to absent effort. Thus regression to the mean is one of the many ways we see the nothing out of which the workings of extropy or Dao are born.
0 comments
Comments sorted by top scores.