Fun With DAGs
post by johnswentworth · 2018-05-13T19:35:49.014Z · LW · GW · 21 commentsContents
Utility Functions Circuits Dynamic Programming Turing-Computable Functions: Circuits + Symmetry Parallelization Causality None 21 comments
Crossposted here.
Directed acyclic graphs (DAGs) turn out to be really fundamental to our world. This post is just a bunch of neat stuff you can do with them.
Utility Functions
Suppose I prefer chicken over steak, steak over pork, and pork over chicken. We can represent my preferences with a directed graph like this:
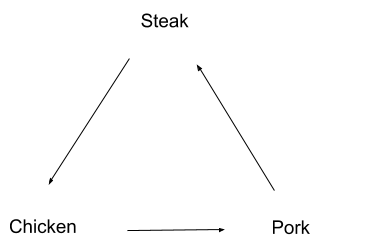
This poses a problem. If I’m holding a steak, then I’ll pay a penny to upgrade it to chicken — since I prefer chicken over steak. But then I’ll pay another penny to upgrade my chicken to pork, and another to upgrade it to steak, and then we’re back to the beginning and I’ll pay to upgrade the steak to chicken again! Someone can stand there switching out chicken/pork/steak with me, and collect my money all day.
Any time our preference graph contains cycles, we risk this sort of “money-pump”. So, to avoid being money-pumped, let’s make our preferences not contain any cycles:
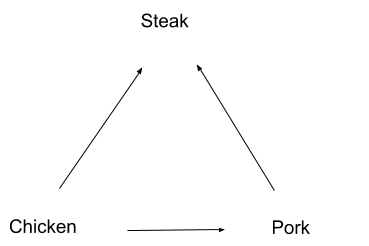
Now our preferences are directed (the arrows), acyclic (no cycles), and a graph (arrow-and-box drawing above). It’s a DAG!
Notice that we can now sort the DAG nodes, spatially, so that each node only points to higher-up nodes:
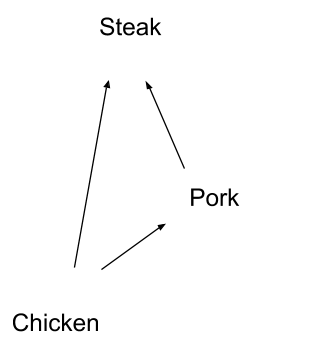
Reading off the nodes from bottom to top, the order is: chicken, pork, steak.
This is called a topological sort, or topo sort for short. We can always topo sort a DAG — there is always some order of the nodes such that each node only points to nodes after it in the sort order.
In this case, the topo sort orders our preferences. We prefer pork over everything which comes before pork in the topo sort, and so forth. We could even number the items according to their topo-sorted order: 1 for chicken, 2 for pork, 3 for steak. We prefer whichever thing has the higher number, i.e. the higher position in the topo-sort order.
This is called a utility function. This utility function U is defined by U(chicken) = 1, U(pork) = 2, U(steak) = 3. We prefer things with higher utility — in other words, we want to maximize the utility function!
To summarize: if our preferences do contain cycles, we can be money-pumped. If they don’t, then our preferences form a DAG, so we can topo sort to find a utility function.
Circuits
Here’s a really simple circuit to compute f = (x+y)*(x-y):
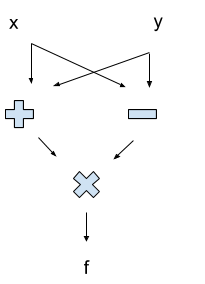
Notice that the circuit is a DAG. In this case, the topo sort tells us the order in which things are computed: “+” and “-” both come before “x” (the multiplication, not the input). If the graph contained any cycles, then we wouldn’t know how to evaluate it — if the value of some node changed as we went around a cycle, we might get stuck updating in circles indefinitely!
It’s the DAG structure that makes a circuit nice to work with: we can evaluate things in order, and we only need to evaluate each node once.
Dynamic Programming
Here’s a classic algorithms problem:
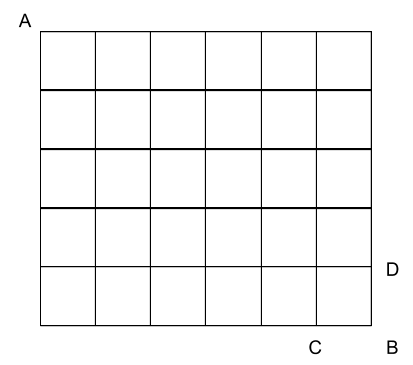
Suppose we want to compute the number of paths from corner A to corner B, travelling only down and right along the lines. (I’m about to give a solution, so pause to think if you don’t want to be spoilered.)
Our main trick is that the number of paths to B is the number of paths to C plus the number of paths to D. Likewise, for any other node, the number of paths to the node is the sum of the numbers above and to the left. So we can turn the picture above into a circuit, by sticking “+” operations at each node and filling in the arrowheads:
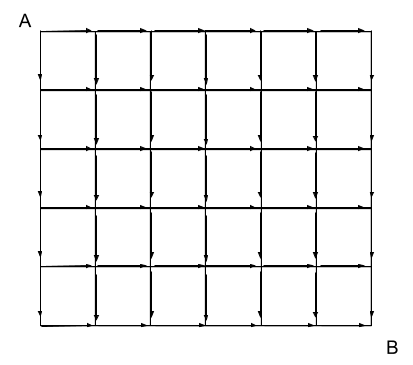
I’ve omitted all the tiny “+” signs, but each node in this circuit sums the values from the incoming arrows. Start with 1 at corner A (there is only one path from A to itself), and the circuit will output the number of paths from A to B at corner B.
Why is this interesting? Well, consider coding this up. We can make a simple recurrent function:
f(row, col):
if row == 0 or col == 0:
return 1
return f(row-1, col) + f(row, col-1)
… but this function is extremely inefficient. In effect, it starts at B, then works backward toward A, exploring every possible path through the grid and adding them all up. The total runtime will be exponential in the size of the grid.
However, note that there are not that many combinations of (row, col) at which f will be evaluated — indeed, there’s only one (row, col) combination for each node in the grid. The inefficiency is because our simple recurrent function calls f(row, col) multiple times for each node, and runs the full computation each time. Instead, we could just compute f for each node once.
How can we do that? We already did! We just need to treat the problem as a circuit. Remember, when evaluating a circuit, we work in topo-sorted order. In this case, that means starting from A, which means starting from f(0,0). Then we store that value somewhere, and move on — working along the top f(0, col) and the side f(row, 0). In general, we work from upper left to lower right, following topo sort order, and storing results as we go. Rather than using function calls, as in the recursive formulation, we just lookup stored values. As long as we follow topo sort order, each value we need will be stored before we need it.
This is “dynamic programming”, or DP: taking a recursive function, and turning it into a circuit. Traditionally, DP is taught with tables, but I find this deeply confusing — the key to DP is that it isn’t really about tables, it’s about DAGs. We take the computational DAG of some recursive function, and turn it into a circuit. By evaluating in topo-sort order, we avoid re-evaluating the function at the same node twice.
Turing-Computable Functions: Circuits + Symmetry
To turn circuits into fully general Turing-computable functions (i.e. anything which can be written in a programming language), we just need to allow recursion.
Here’s a recursive factorial function:
f(n):
if n == 0:
return 1
return n * f(n-1)
We can represent this as an infinite circuit:

Each of the dashed boxes corresponds to a copy of the function f. The infinite ladder handles the recursion — when f calls itself, we move down into another box. We can view this as a symmetry relation: the full circuit is equivalent to the top box, plus a copy of the full circuit pasted right below the top box.
Of course, if we actually run the code for f, it won’t run forever — we won’t evaluate the whole infinite circuit! Because of the conditional “n == 0?”, the behavior of the circuit below some box is irrelevant to the final value, so we don’t need to evaluate the whole thing. But we will evaluate some subset of the circuit. For n = 2, we would evaluate this part of the circuit:

This is the “computational DAG” for f(2). While the code for f defines the function, the computational DAG shows the computation — which steps are actually performed, in what order, with what dependencies.
Parallelization
The computational DAG forms the basis for parallelization: speeding up an algorithm by running on multiple cores at once.
Consider our simple circuit from earlier:
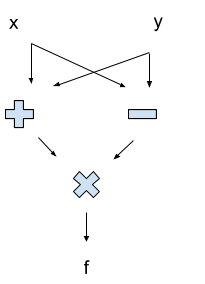
Where can we perform steps in parallel? Well, we can evaluate the “-” and “+” at the same time. But we can’t perform the “x” until after both the “-” and “+” are done: the “x” requires the results from those two steps.
More generally, look at the topo sort order of the circuit. The topo sort is not unique — “+” could come before or after “-”, since there’s no directed path between them. That means they can be performed in parallel: neither requires the result from the other. On the other hand, “x” comes strictly later in the topo sort order, because it does require the other values as input.
For a more complicated function, we’d have to think about the computational DAG. Whenever one node comes strictly after another in the computational DAG, those two nodes cannot be parallelized. But as long as neither node comes strictly after the other, we can parallelize them. For instance, in our DP example above, the points C and D in the grid could be evaluated in parallel.
This sort of thinking isn’t restricted to computer science. Suppose we have a company producing custom mail-order widgets, and every time an order comes in, there’s a bunch of steps to crank out the widget:
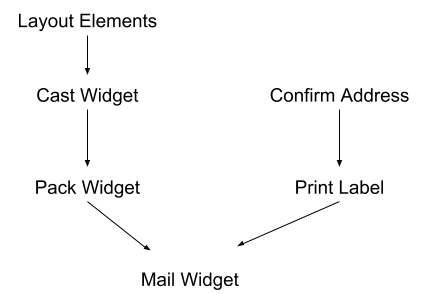
Some steps depend on others, but some don’t. We can confirm the address and print the label in parallel to producing the widget itself, in order to mail it out sooner. A lot of optimization in real-world company processes looks like this.
Causality
Here’s a classic example from Pearl:
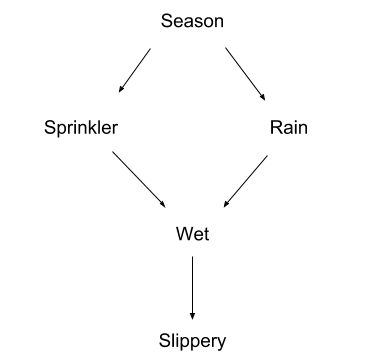
The season could cause rain, or it could cause you to run the sprinkler, but the season will not directly cause the sidewalk to be wet. The sidewalk will be wet in some seasons more than others, but that goes away once you control for rain and sprinkler usage. Similarly, rain can cause the sidewalk to be wet, which causes it to be slippery. But if something keeps the sidewalk dry — a covering, for instance — then it won’t be slippery no matter how much it rains; therefore rain does not directly cause slipperiness.
These are the sort of common-sense conclusions we can encode in a causal DAG. The DAG’s arrows show direct cause-effect relations, and paths of arrows show indirect cause and effect.
A few of the neat things we can do with a causal DAG:
- Mathematically reason about how external changes (e.g. covering a sidewalk) will impact cause-effect systems
- Account for causality when updating beliefs. For instance, a wet sidewalk makes rain more likely, but not if we know the sprinkler ran.
- Find a compact representation for the probability distribution of the variables in the DAG
- Statistically test whether some data is compatible with a particular causal DAG
Most of these are outside the scope of this post, but Highly Advanced Epistemology 101 [LW · GW] has more.
The DAG structure of causality is the main reason for the ubiquity of DAGs: causality is everywhere, so DAGs are everywhere. Circuits are really just cause-effect specifications for calculations. Not utility, though — that one’s kind of an outlier.
21 comments
Comments sorted by top scores.
comment by justinpombrio · 2018-05-13T21:22:32.569Z · LW(p) · GW(p)
This is called a utility function. This utility function U is defined by U(chicken) = 1, U(pork) = 2, U(steak) = 3. We prefer things with higher utility — in other words, we want to maximize the utility function!
Just because you have a DAG of your preferences, does not mean that you have a utility function. There are many utility functions that are consistent with any particular DAG, so if all you have is a DAG then your utility function is under-specified.
First, maybe you don't care about the difference between pork and steak, and remove that arrow from your DAG. In that case, the toposort is going to produce either U(chicken) = 1, U(pork) = 2, U(steak) = 3 or U(chicken) = 1, U(steak) = 2, U(pork) = 3, arbitrarily. Toposort is guaranteed to produce an ordering that matches the DAG, but there might be several of them. (A slight variant on toposort could produce U(chicken) = 1, U(pork) = 2, U(steak) = 2 instead, but that's still a bit questionable because it's conflating incomparability with equality.)
Second, the magnitude of these numbers is pretty arbitrary in a toposort (they're just sequential integers), but very important in a utility function. For example, maybe you really like steak, so that the more appropriate utility function is U(chicken) = 1, U(pork) = 2, U(steak) = 10. You're not going to get this from a toposort.
I just wanted to clarify this, because the post could be read as saying DAG==utility-function.
Replies from: johnswentworth↑ comment by johnswentworth · 2018-05-13T21:37:17.043Z · LW(p) · GW(p)
Roughly correct. The missing piece is completeness: for the DAG to uniquely define a utility function, we have to have an edge between each pair of nodes. Then the argument works.
The relative magnitude of the numbers matters only in nondeterministic scenarios, where we take an expectation over possible outcomes. If we restrict ourselves to deterministic situations, then any monotonic transformation of the utility function produces the exact same preferences. In that case, the toposort numbers are fine.
Replies from: justinpombrio↑ comment by justinpombrio · 2018-05-13T22:14:25.103Z · LW(p) · GW(p)
And if we assume that the nodes are whole worlds, rather than pieces of worlds.
For example, if I'm also ordering a soda, and prefer Pepsi to Coke, then the relative magnitudes become important. (There's an implicit assumption here that the utility of the whole is the sum of the utilities of the parts.) However, if the node includes the entire meal, so that there are six nodes (chicken, pepsi), (chicken, coke), (pork, pepsi), (pork, coke), (steak, pepsi), (steak, coke), then the magnitude doesn't matter. Are utility functions generally assumed to be whole-world like this?
Replies from: johnswentworth, rossry↑ comment by johnswentworth · 2018-05-13T23:20:28.016Z · LW(p) · GW(p)
Yes, although I would word it as "the nodes include everything relevant to our implied preferences", rather than "whole worlds", just to be clear what we're talking about. Certainly the entire notion of adding together two utilities is something which requires additional structure.
↑ comment by rossry · 2018-05-13T23:17:21.990Z · LW(p) · GW(p)
However, if the node includes the entire meal, so that there are six nodes (chicken, pepsi), (chicken, coke), (pork, pepsi), (pork, coke), (steak, pepsi), (steak, coke), then the magnitude doesn't matter.
I don't think this is right; you still want to be able to decide between actions which might have probabilistic "outcomes" (given that your action is necessarily being taken under incomplete information about its exact results).
You could define a continuous DAG over probability distributions, but that structure is actually too general; you do want to be able to rely on linear additivity if you're using utilitarianism (rather than some other consequentialism that cares about the whole distribution in some nonlinear way).
Of course, once you have your function from worlds to utilities, you can construct the ordering between nodes of {100% to be X | outcomes X}, but that transformation is lossy (and you don't need the full generality of a DAG, since you're just going to end up with a linear ordering.
(For modeling incomplete preferences, DAGs are great! Not so great for utility functions.)
comment by Jameson Quinn (jameson-quinn) · 2018-05-15T15:49:21.771Z · LW(p) · GW(p)
Causal DAGs are used in statistics for causal analysis. Also, widely misused. When real causality isn't acyclic and real dependence is highly nonlinear, inference based on the assumption that there exists some (quasi-linear) causal DAG can go very very wrong. It may be closer to being true than just assuming that the most complicated structure is bivariate interaction (Z depends on the combination of X and Y), but it is also a lot more dangerous.
comment by Said Achmiz (SaidAchmiz) · 2018-05-13T23:47:15.800Z · LW(p) · GW(p)
This is called a utility function. This utility function U is defined by U(chicken) = 1, U(pork) = 2, U(steak) = 3. We prefer things with higher utility — in other words, we want to maximize the utility function!
It seems like you’ve got this backwards, given the stated preference ordering, yes? U(chicken) = 3, U(pork) = 2, U(steak) = 1 would make more sense.
comment by Said Achmiz (SaidAchmiz) · 2018-05-13T23:44:54.034Z · LW(p) · GW(p)
Suppose I prefer chicken over steak, steak over pork, and pork over chicken. … This poses a problem. If I’m holding a steak, then I’ll pay a penny to upgrade it to chicken — since I prefer chicken over steak. But then I’ll pay another penny to upgrade my chicken to pork, and another to upgrade it to steak, and then we’re back to the beginning and I’ll pay to upgrade the steak to chicken again!
This is an unwarranted conclusion, as it relies on additional unstated assumptions.
If I prefer chicken over steak, then that plausibly means that, if I am offered a choice between a world where I have chicken, and a world which is identical to the first except that I instead have steak, and no other alternatives are available to me, and I have no option to avoid choosing—then I will choose chicken. Any less trivial conclusions than this require additional assumptions.
You can easily see this to be true by considering the possibility that someone will choose chicken over steak if offered a choice of one or the other, but will not pay a penny to “upgrade” from steak to chicken. (It is not necessary that any actual person exhibits this pattern of behavior, only that this is a coherent scenario—which it clearly is.)
Note that we haven’t even gotten to the matter of non-transitivity of preferences, etc.; just the basic logic of “prefers X to Y” -> “would pay a penny to upgrade from Y to X” is already flawed.
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-14T20:18:46.322Z · LW(p) · GW(p)
I encourage you to make a full post on this topic. I don't think I've seen one about this before. You could explain what assumptions we're making, why the're unwarranted, what assumptions you make, what exactly coherence is, etc, in full and proper arguments. Because leaving comments on random posts that mention utility is not productive.
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2018-05-14T20:47:37.693Z · LW(p) · GW(p)
Perhaps. Frankly, I find it hard to see what more there is to say. What I said in the grandparent seems perfectly straightforward to me; I was aiming simply to point it out, to bring it to the attention of readers. There’s just not much to disagree with, in what I said; do you think otherwise? What did I say that wasn’t simply true?
(Note that I said nothing about the assumptions in question being unwarranted; it’s just that they’re unstated—which, if one is claiming to be reasoning in a straightforward way from basic principles, rather undermines the whole endeavor. As for what assumptions I would make—well, I wouldn’t! Why should I? I am not the one trying to demonstrate that beliefs X inevitably lead to outcome Y…)
(Re: “what exactly coherence is”, I was using the term in the usual way, not in any specific technical sense. Feel free to substitute “only that this scenario could take place”, or some similar phrasing, if the word “coherent” bothers you.)
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-15T08:01:52.686Z · LW(p) · GW(p)
I meant a post not just on this, but on all of your problems with preferences and utilities and VNM axioms. It seems to me that you have many beliefs about those, and you could at least put them all in one place.
Now, your current disagreement seems less about utility and more about the usefulness of the preference model itself. But I'm not sure what you're saying exactly. The case where Alice would choose X over Y, but wouldn't pay a penny to trade her Y for Bob's X, is indeed possible, and there are a few ways to model that in preferences. But maybe you're saying that there are agents where the entire preference model breaks down? And that these are "intelligent" and "sane" agents that we could actually care about?
Note that I said nothing about the assumptions in question being unwarranted
But surely you believe they are unwarranted? Because if the only problem with those assumptions is that they are unstated, then you're just being pedantic.
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2018-05-15T15:04:22.587Z · LW(p) · GW(p)
I meant a post not just on this, but on all of your problems with preferences and utilities and VNM axioms. It seems to me that you have many beliefs about those, and you could at least put them all in one place.
Hmm… an analogy:
Suppose you frequented some forum where, on occasion, other people said various things like:
“2 + 2 equals 3.7.”
“Adding negative numbers is impossible.”
“64 is a prime number.”
“Any integer is divisible by 3.”
And so on. Whenever you encountered any such strange, mistaken statement about numbers/arithmetic/etc., you replied with a correction. But one day, another commenter said to you: “Why don’t you make a post about all of your problems with numbers and arithmetic etc.? It seems to me that you have many beliefs about those, and you could at least put them all in one place.”
What might you say, to such a commenter? Perhaps something like:
“Textbooks of arithmetic, number theory, and so on are easy to find. It would be silly and absurd for me to recapitulate their contents from scratch in a post. I simply correct mistakes where I see them, which is all that may reasonably be asked.”
Now, your current disagreement seems less about utility and more about the usefulness of the preference model itself. But I’m not sure what you’re saying exactly. The case where Alice would choose X over Y, but wouldn’t pay a penny to trade her Y for Bob’s X, is indeed possible, and there are a few ways to model that in preferences. But maybe you’re saying that there are agents where the entire preference model breaks down? And that these are “intelligent” and “sane” agents that we could actually care about?
What I’m saying is nothing more than what I said. I don’t see what’s confusing about it. If someone prefers X to Y, that doesn’t mean that they’ll pay to upgrade from Y to X. Without this assumption, it is, at least, a good deal harder to construct Dutch Book arguments. (This is, among other reasons, why it’s actually very difficult—indeed, usually impossible—to money-pump actual people in the real world, despite the extreme ubiquity of “irrational” (i.e., VNM-noncompliant) preferences.)
But surely you believe they are unwarranted? Because if the only problem with those assumptions is that they are unstated, then you’re just being pedantic.
I disagree wholeheartedly. Unstated assumptions are poison to “from first principles” arguments. Whether they’re warranted is of entirely secondary importance to the question of whether they are out in the open, so that they may be examined in order to determine whether they’re warranted.
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-15T16:15:16.620Z · LW(p) · GW(p)
Why don’t you make a post about all of your problems with numbers and arithmetic etc.? It seems to me that you have many beliefs about those, and you could at least put them all in one place.
Yes, even in your analogy this makes sense. There are several benefits.
- you would then be able to link to this post instead of repeating those same corrections over and over again.
- you would be able to measure to what extent the other users on this site actually disagree with you. You may find out that you have been strawmanning them all along.
- other users would be able to try to build constructive arguments why you are wrong (hopefully, the possibility of being wrong has occured to you).
If someone prefers X to Y, that doesn’t mean that they’ll pay to upgrade from Y to X.
Yes, the statement that there exists an agent that would choose X over Y but would not pay to upgrade Y to X, is not controversial. I've already agreed to that. And I don't see that the OP disagrees with it either. It is, however, true that most people would upgrade, for many instances of X and Y. It is normal to make simplifying assumptions in such cases, and you're supposed to be able to parse them.
Replies from: SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2018-05-15T16:35:09.587Z · LW(p) · GW(p)
Yes, even in your analogy this makes sense. There are several benefits. …
It doesn’t make any sense whatsoever in the analogy (and, analogically, in the actual case). If my analogy (and subsequent commentary) has failed to convince you of this, I’m not sure what more there is to say.
It is, however, true that most people would upgrade, for many instances of X and Y.
Citation needed. (To forestall the obvious follow-up question: yes, I actually don’t think the quoted claim is true, on any non-trivial reading—I’m not merely asking for a citation out of sheer pedantry.)
It is normal to make simplifying assumptions in such cases
The “simplifying” assumptions, in this case, are far too strong, and far too simplifying, to bear being assumed without comment.
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-15T18:51:14.301Z · LW(p) · GW(p)
If my analogy (and subsequent commentary) has failed to convince you of this, I’m not sure what more there is to say.
Well, you could, for example, address my bullet points. Honestly, I didn't see any reasons against making a post yet from you. I'd only count the analogy as a reason if it's meant to imply that everyone in LW is insane, which you hopefully do not believe. Also, I think you're overestimating the time required for a proper post with proper arguments, compared to the time you put into these comments.
Citation needed.
Really? Take X="a cake" and Y="a turd". Would you really not pay to upgrade? Or did you make some unwarranted assumptions about X and Y? Yes, when X and Y are very similar, people will sometimes not trade, because trading is a pain in the ass.
Replies from: SaidAchmiz, SaidAchmiz↑ comment by Said Achmiz (SaidAchmiz) · 2018-05-15T23:32:46.150Z · LW(p) · GW(p)
I’d only count the analogy as a reason if it’s meant to imply that everyone in LW is insane, which you hopefully do not believe.
Why insane? Even in the analogy, no one needs to be insane, only wildly mistaken (which I do indeed believe that many, maybe most, people on LW [of those who have an opinion on the subject at all] are, where utility functions and related topics are concerned).
That said, I will take your suggestion to write a post about this under advisement.
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-16T09:13:00.236Z · LW(p) · GW(p)
Why insane?
Because sane people can be reasoned with. If a sane person is wildly mistaken, and you correct them, in a way that's not insulting and in a way that's useful to them (as opposed to pedantry), they can be quite grateful for that, at least sometimes.
↑ comment by Said Achmiz (SaidAchmiz) · 2018-05-15T23:29:09.190Z · LW(p) · GW(p)
Really? Take X=“a cake” and Y=“a turd”. Would you really not pay to upgrade? Or did you make some unwarranted assumptions about X and Y? Yes, when X and Y are very similar, people will sometimes not trade, because trading is a pain in the ass.
Fair point. I was, indeed, making some unwarranted assumptions; your example is, of course, correct and illustrative.
However, this leaves us with the problem that, when those assumptions (which involve, e.g., X and Y both being preferred to some third alternative which might be described as “neutral”, or X and Y both being describable as “positive value” on some non-preference-ordering-based view of value, or something along such lines) are relaxed, we find that this…
most people would upgrade, for many instances of X and Y
… while now clearly true, is no longer a useful claim to make. Yes, perhaps most people would upgrade, for many instances of X and Y, but the claim in the OP can only be read as a universal claim—or else it’s vacuous. (Note also that transitive preferences are quite implausible in the absence of the aforesaid assumptions.)
Replies from: zulupineapple↑ comment by zulupineapple · 2018-05-16T09:30:58.913Z · LW(p) · GW(p)
those assumptions (which involve, e.g., X and Y both being preferred to some third alternative which might be described as “neutral”, or X and Y both being describable as “positive value” on some non-preference-ordering-based view of value, or something along such lines)
X being "good" and Y being "bad" has nothing to do with it (although those are the most obvious examples). E.g. if X=$200 and Y=$100, then anyone would also pay to upgrade, when clearly both X and Y are "good" things. Or if X="flu" and Y="cancer", anyone would upgrade, when both are "bad".
The only case where people really wouldn't upgrade is when X and Y are in some sense very close, e.g. if we have Y < X < Y + "1 penny" + "5 minutes of my time".
But I agree, it is indeed reasonable that if someone has intransitive preferences, those preferences are actually very close in this sense and money pumping doesn't work.
comment by Gordon Seidoh Worley (gworley) · 2018-05-19T22:50:22.585Z · LW(p) · GW(p)
I want to throw some cold water on this notion because it's dangerously appealing. When I was doing my PhD in graph theory I had a similar feeling that graphs were everything, but this is a more general property of mathematics. Graphs are appealing to a certain kind of thinker, but there is nothing so special about them beyond their efficacy at modeling certain things and many isomorphic models are possible. In particular they admit helpful visualizations but they are ultimately no more powerful (or any less powerful!) than many equivalent mathematical models. I just worry from the tone of your post you might be overvaluing graphs so I'd like to pass down my wisdom that they are valuable but not especially valuable in general.
Replies from: johnswentworth↑ comment by johnswentworth · 2018-05-20T03:30:58.237Z · LW(p) · GW(p)
Oh lord no, this is just a bunch of random applications. Though I've also seen the failure mode you describe, so good warning.
Convex optimization, though. That's everything.