Recursive Quantilizers II
post by abramdemski · 2020-12-02T15:26:30.138Z · LW · GW · 15 commentsContents
Criteria Failed Criteria The New Proposal The Ideal Uncertain Feedback Balancing Robust Listening and Arbitrary Reinterpretation Process-Level Feedback The Implementation Proposal Comparison to Iterated Amplification Reasons why quantilizers might not be appropriate: Quantilizers bound risk, but iteration increases risk arbitrarily. Quantilizers assume catastrophes are rare in random choices, but in the recursive setting, too much randomness can create value drift. Other Concerns None 15 comments
I originally introduced the recursive quantilizers idea here [? · GW], but didn't provide a formal model until my recent Learning Normativity [LW · GW]post. That formal model had some problems. I'll correct some of those problems here. My new model is closer to HCH+IDA, and so, is even closer to Paul Christiano style systems than my previous.
However, I'm also beginning to suspect that quantilizers aren't the right starting point. I'll state several problems with quantilizers at the end of this post.
First, let's reiterate the design criteria, and why the model in Learning Normativity wasn't great.
Criteria
Here are the criteria from Learning Normativity [LW · GW], with slight revisions. See the earlier post for further justifications/intuitions behind these criteria.
- No Perfect Feedback: we want to be able to learn with the possibility that any one piece of data is corrupt.
- Uncertain Feedback: data can be given in an uncertain form, allowing 100% certain feedback to be given (if there ever is such a thing), but also allowing the system to learn significant things in the absence of any certainty.
- Reinterpretable Feedback: ideally, we want rich hypotheses about the meaning of feedback, which help the system to identify corrupt feedback, and interpret the information in imperfect feedback. To this criterion, I add two clarifying criteria:
- Robust Listening: in some sense, we don't want the system to be able to "entirely ignore" humans. If the system goes off-course, we want to be able to correct that.
- Arbitrary Reinterpretation: at the same time, we want the AI to be able to entirely reinterpret feedback based on a rich model of what humans mean. This criterion stands in tension with Robust Listening. However, the proposal in the present post is, I think, a plausible way to achieve both.
- No Perfect Loss Function: we don't expect to perfectly define the utility function, or what it means to correctly learn the utility function, or what it means to learn to learn, and so on. At no level do we expect to be able to provide a single function we're happy to optimize. This is largely due to a combination of Goodhart and corrupt-feedback concerns.
- Learning at All Levels: Although we don't have perfect information at any level, we do get meaningful benefit with each level we step back and say "we're learning this level rather than keeping it fixed", because we can provide meaningful approximate loss functions at each level, and meaningful feedback for learning at each level. Therefore, we want to be able to do learning at each level.
- Between-Level Sharing: Because this implies an infinite hierarchy of levels to learn, we need to share a great deal of information between levels in order to learn meaningfully. For example, Occam's razor is an important heuristic at each level, and information about what malign inner optimizers look like is the same at each level.
- Process Level Feedback: we want to be able to give feedback about how to arrive at answers, not just the answers themselves.
- Whole-Process Feedback: we don't want some segregated meta-level which accepts/implements our process feedback about the rest of the system, but which is immune to process feedback itself. Any part of the system which is capable of adapting its behavior, we want to be able to give process-level feedback about.
- Learned Generalization of Process Feedback: we don't just want to promote or demote specific hypotheses. We want the system to learn from our feedback, making generalizations about which kinds of hypotheses are good or bad.
Failed Criteria
The previous recursive-quantilization model failed some criteria [LW · GW]:
- No reinterpretable feedback. I didn't provide any method for achieving that.
- No whole-process feedback. The way I set things up, the initial distributions are judged only on their later consequences. This leaves them wide open to inner optimizers and other problematic reasoning steps.
- We can fix this by allowing the user to give direct feedback on the initial distributions as well, but then there's no mechanism for Learned Generalization of that particular feedback. So we're caught in the middle, unable to satisfy both those criteria at once.
The current proposal solves both problems, and due to an analogy to iterated amplification [? · GW], may also be more computationally feasible.
The New Proposal
Like iterated amplification [? · GW], the new proposal consists of both an idealized definition of aligned behavior (HCH, in the context of iterated amplification) and a candidate approximation of this ideal (like iterated amplification itself, which is supposed to approximate HCH).
The Ideal
The object which quantilization will select on will be referred to as "question-answering systems", or QAS for short. This is what I called a "UTAA" in the previous post. As before, this is one object which has opinions about the safe distribution for quantilization (you can ask it "what's a safe distribution over QAS to quantilize on?"), and as value function ("give me a value function to judge the quality of QAS") and as the object-level solution to whatever problem you're trying to get this whole setup to solve (you ask it your object-level questions).
So the goal is to get a really good QAS, where "really good" means highly capable and highly aligned. Since we're specifying the ideal here, we get to use unbounded processing power in doing so.
Humans provide an initial "safe" distribution on QASs, and an initial loss function which will be used to judge QASs for their quality. We then quantilize. This yields a new distribution over QASs, which we use to define another stage of quantilization (this time with safe distribution and value function coming from the QASs themselves), and so on, until we reach an equilibrium where an additional step does not add anything.
As before, we can imagine this as an infinite or very large tree of quantilization:
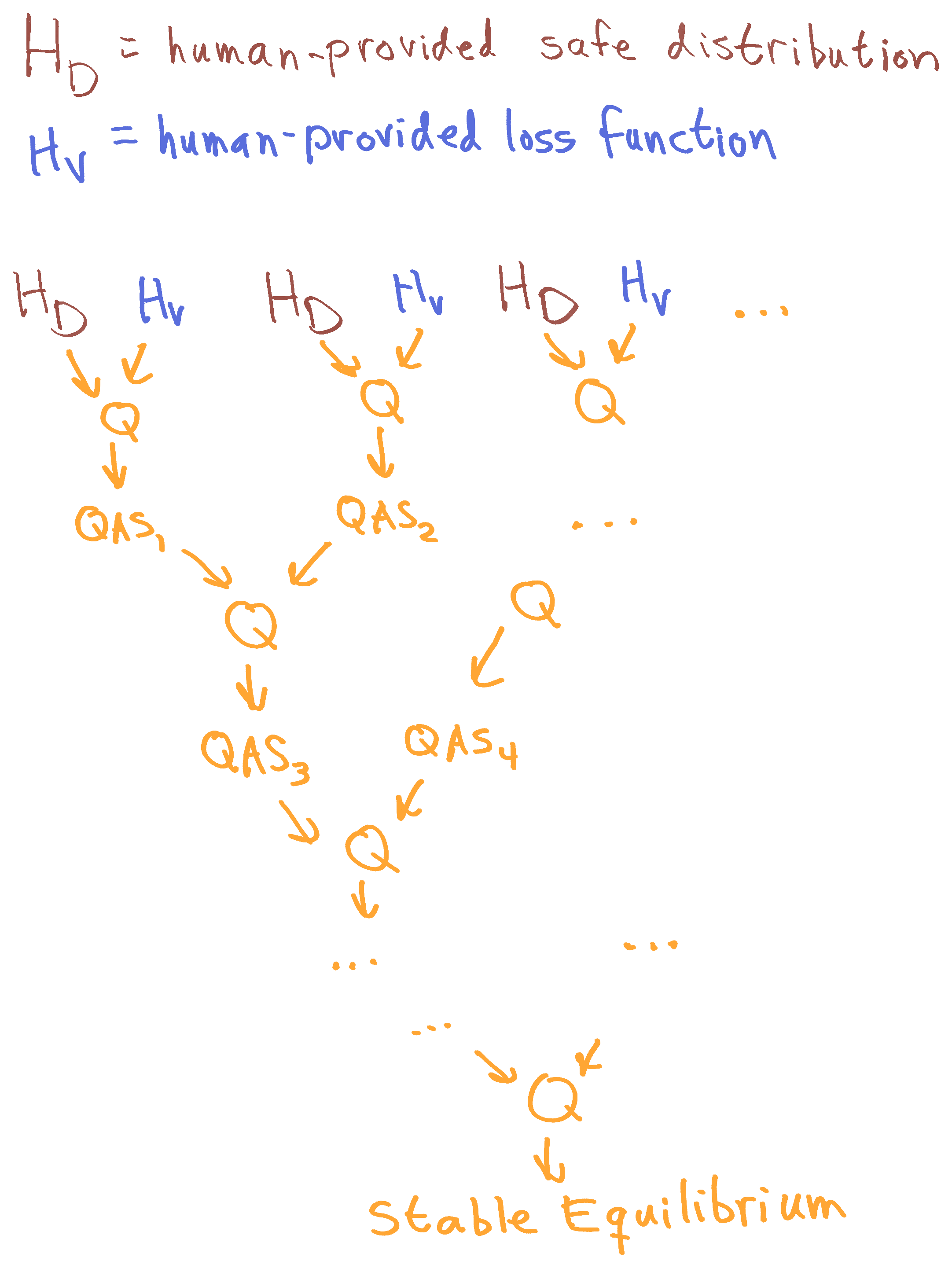
(Note that, previously, I treated Q as a three-argument stochastic function, requiring a safe distribution, a value function (AKA loss function), and a parameter telling it how much to optimize. Here, I am suppressing the third parameter. Perhaps we keep it fixed, or perhaps we ask a third QAS for it, as before -- I have no improved suggestions for how we estimate that parameter at the moment.)
The tree structure means that a QAS is never evaluating itself; it is being evaluated by another QAS sampled from an independent multi-level quantilization, which can spot mistakes in its own way.
Now, loss functions in general (including both the initial human-given loss function, and the improved loss functions proposed by the QASs) need access to the entire experience of the system. The initial human-gives loss function may be something like "pick out explicit training feedback humans give, and translate it into a numerical score for a QAS, ignoring natural-language comments made by the humans, evidence from the context, etc." The loss functions proposed by the QAS are supposed to get cleverer, interpreting natural-language feedback given by humans, using contextual clues, etc.
You might ask, "shouldn't we build simple natural-language understanding into the initial loss function?" -- we could, but that's supposed to be redundant. There should be no reason to train a separate natural-language understanding system, rather than use explicit feedback to train the QAS to understand natural-language feedback.
Uncertain Feedback
The initial loss function should have the ability to learn from uncertain feedback, to satisfy the Uncertain Feedback criterion. (We can implement one of the options mentioned in Learning Normativity.)
Balancing Robust Listening and Arbitrary Reinterpretation
The idealized objective presented in this section offers a nice combination of "robust listening" (not ever reaching a state where it totally fails to respond to human feedback) and "arbitrary reinterpretation" (being able to use rich models to totally reinterpret the meaning of human feedback). These two objectives would seem to be at odds, since a system with an arbitrary model of the meaning of human feedback can ignore anything.
In the proposal here, direct human feedback always shapes the initial dynamic. If you see a system do something stupid and add direct feedback against this to the data, then QASs which engage in this behavior will be ruled out in the first step of quantilization. You can also add strong evidence against QAS which fail to judge QASs harshly for violating such principles (and which fail to punish non-punishers, recursively). So, human feedback always has total control to shape the ultimate result.
At the same time, however, only the initial dynamic is required to obey this feedback in a naive way. At later stages, QASs are supposed to understand human feedback better, identifying feedback which should be interpreted less literally.
This means the equilibrium result is both fully dependent on a 100% literal interpretation of human feedback, and at the same time, fully the result of a more careful, nuanced interpretation of what humans meant.
Process-Level Feedback
Also, it's important to note that the initial loss function needs to understand process-level feedback. You can imagine that the dataset includes the following:
- Extensive human-generated Q&A behavior, much like would be needed for Iterative Amplification. This is the bulk of what loads general world-knowledge into QAS that come out of the first round of quantilization.
- Extensive labeling of QAS as "ok" and "bad", to demonstrate how to examine QAS source code (/ neural network / etc) and evaluate when something looks wrong. This could include many toy examples which illustrate bad behavior, as well as real examples gathered during training. The QAS should be trained to imitate this behavior when evaluating other QAS.
- Similarly, examples of humans examining QAS execution and labeling steps as bad, rather than just examining the source code directly.
You can imagine humans engaging in an iterative process where they examine the behavior of many QAS created by early attempts at this process, which creates more training data for later iterations. However, since we're still only describing the ideal, that's not realistic; humans never have access to the true output of the ideal process.
Let's move on to describing the iterative-amplification analogue.
The Implementation Proposal
The basic idea is to take iterative amplification, and replace the HCH-like "amplification" operation with quantilization-based amplification.
At every stage of the process, we're not learning a single QAS, but rather, learning a distribution over QAS.
Define the distribution as the result of quantilizing the safe distribution given by humans, using the value function given by humans.
The distribution is the distillation of ; ie, we learn a more computationally efficient approximation of the distribution using some distribution-modeling technique such as GANs.
The distribution is defined by sampling two QAS from , asking one for the value function and the other for the safe distribution, and quantilizing.
The distribution is obtained by learning an efficient approximation of .
And so on. is defined as the output of a quantilizer which takes its value function and safe distribution from (independent) samples from . is a learned approximation of .
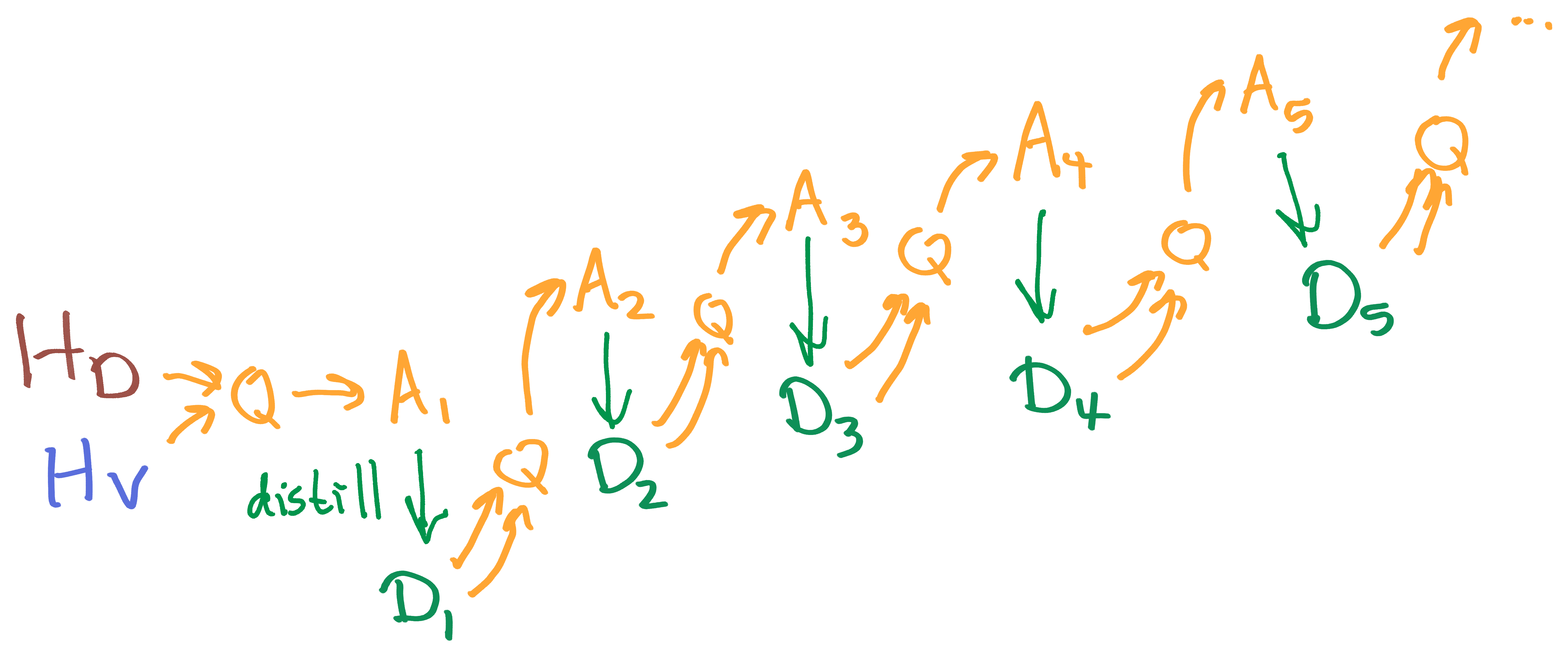
If the distillation step were perfect, this would converge to the desired equilibrium.
Note, however, that this assumes that all human feedback is available from the beginning. Realistically, we want more interactive training, so that humans can observe the intermediate outputs of the process and provide new training data to account for problems. The vast majority of training data involving QAS evaluation may come from such interaction.
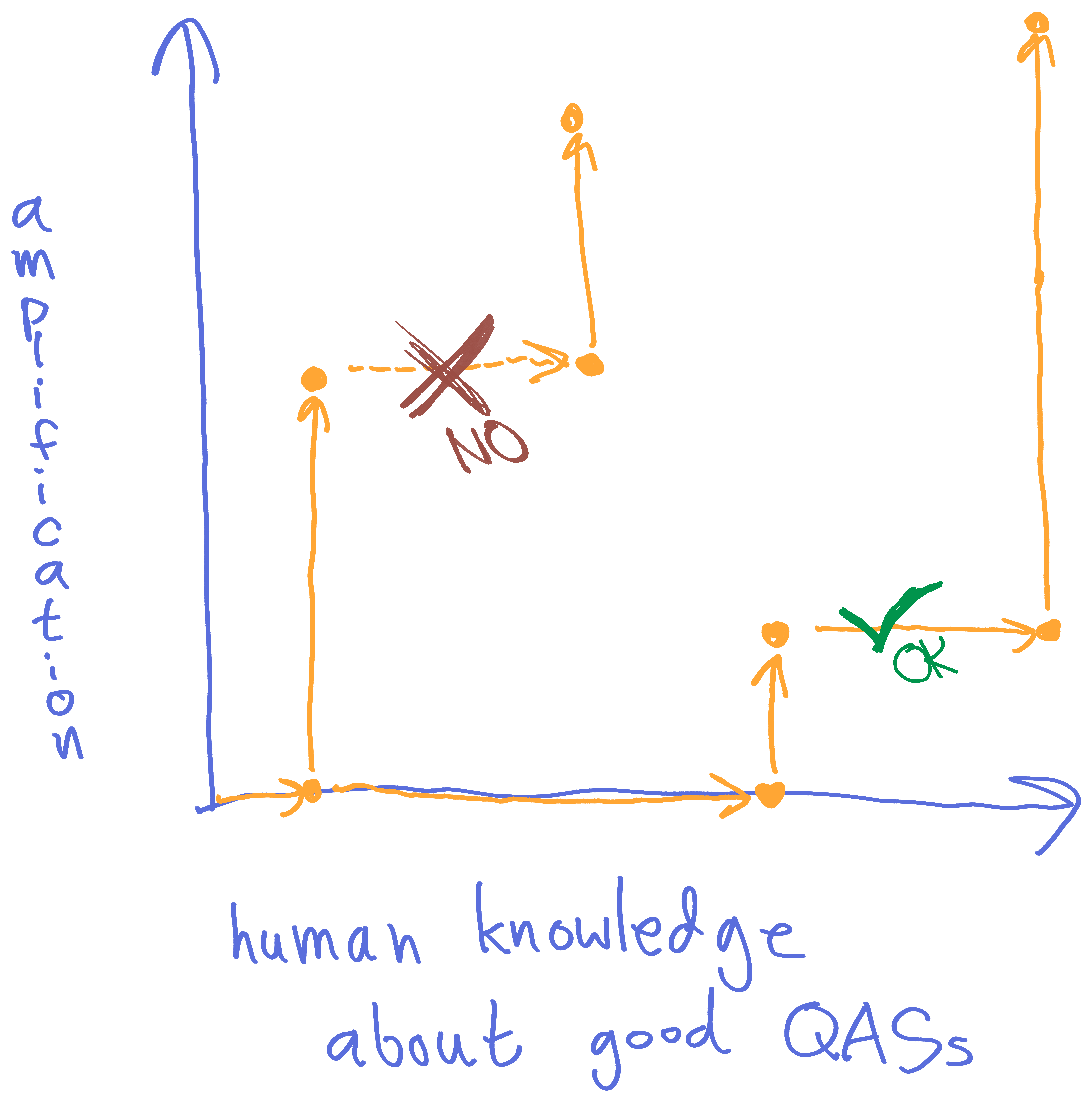
I visualize this as "iterated amplification takes us upward, but not rightward" in the following coordinates:
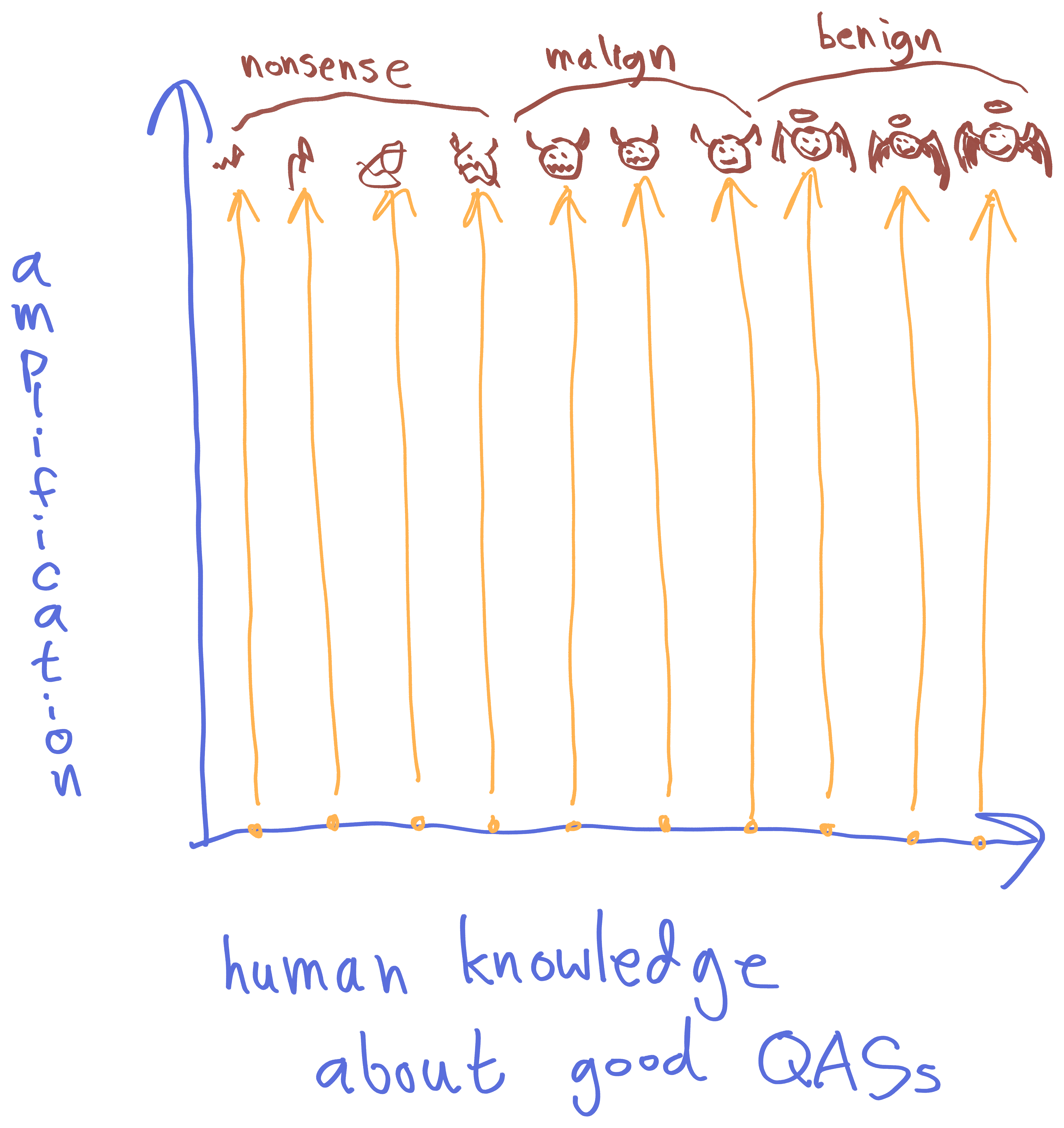
If we start amplifying something with very little human-input knowledge, we're likely to get total nonsense out; the QASs just don't know enough to optimize any coherent thing over successive amplification steps. If we start with a moderate amount of knowledge, the QASs might sputter into nonsense, or might get on the right track, but also have a high risk of producing highly-capable but malign agents. At some level of sufficient human input, we fall into the "basin of corrigibility" and get aligned outputs no matter what (perhaps even the same exact benign output).
Yet, it's hard to provide everything up-front. So, more realistically, the picture might look like this:
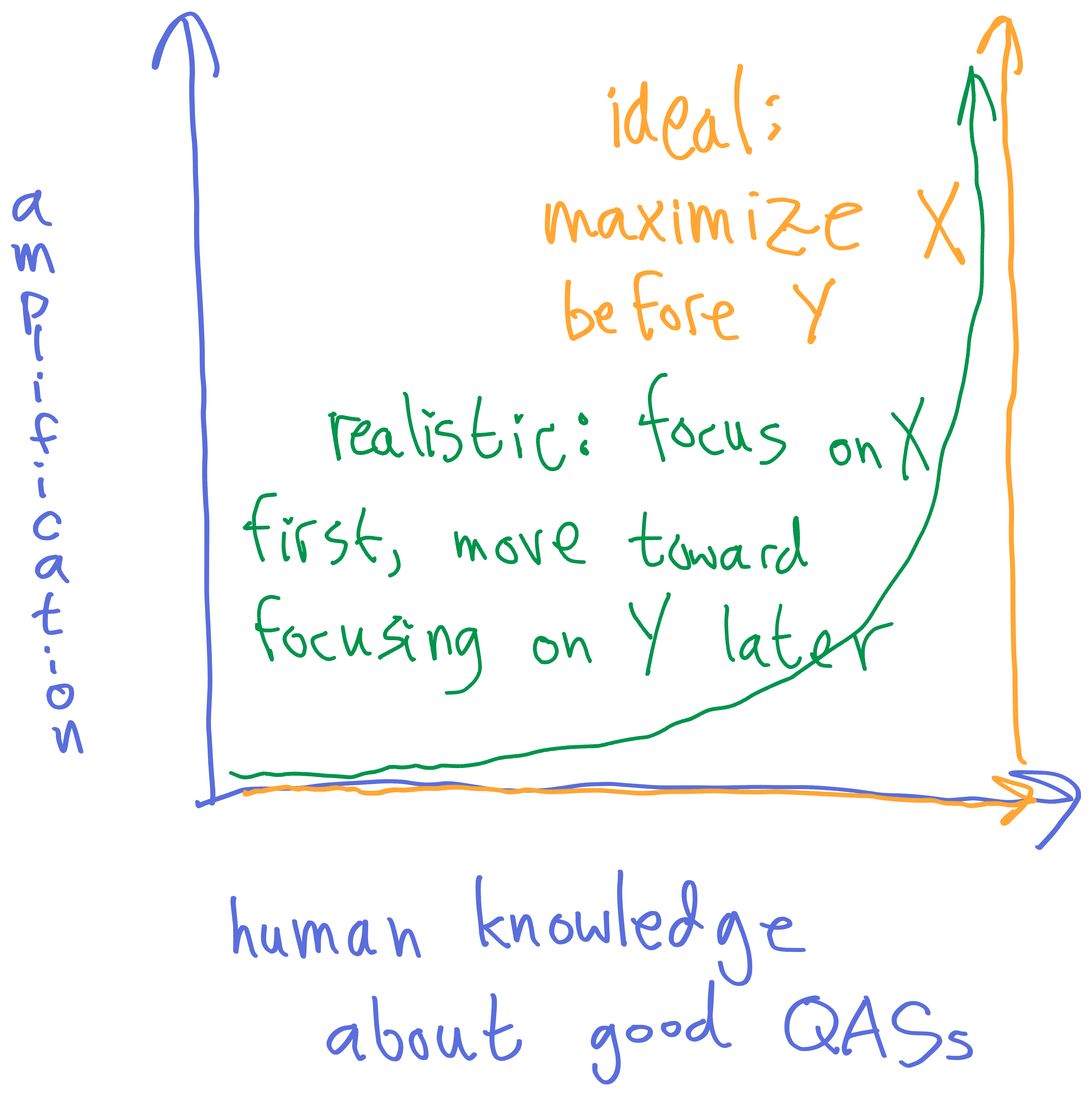
The golden line is the standard set by the idealized model of recursive quantilizers, where we have all the training data before starting the amplification process. The green line is a more realistic line, where we make amplification moves and increase training data in a mixed way, but avoid over-amplifying an under-trained model.
It's really important to stay close to the x-axis early in the process, because the system itself is determining how to evaluate the loss function -- so it's evaluating the very meaning of the training data (in line with the Reinterpretable Feedback criterion). It is therefore very important that we don't let the system drift too far in the direction of an extreme reinterpretation of the training data (in line with the Robust Listening criterion). At the very start of the training process, I imagine you'd often restart the training process from scratch with all the new feedback in place, rather than trust the system to understand new data.
In other words, we don't expect x-dimension moves to work if we're too high in the y-dimension:
Unfortunately, it's difficult to know what the region is where x-dimension moves work, so it's difficult to know when amplification would keep us within that region vs take us out of it.
Another way to put it: this implementation puts the "robust listening" criterion at serious risk. The partially amplified agent can easily stop listening to human feedback on important matters, about which it is sure we must be mistaken.
Really, we would want to find an engineering solution around this problem, rather than haphazardly steering through the space like I've described. For example, there might be a way to train the system to seek the equilibrium it would have reached if it had started with all its current knowledge.
Comparison to Iterated Amplification
Because this proposal is so similar to iterated amplification, it bears belaboring the differences, particularly the philosophical differences underlying the choices I've made.
I don't want this to be about critiquing iterated amplification -- I have some critiques, but the approach here is not mutually exclusive with iterated amplification by any means. Instead, I just want to make clear the philosophical differences.
Both approaches emphasize deferring the big questions, setting up a system which does all the philosophical deliberation for us, rather than EG providing a correct decision theory.
Iterated Amplification puts humans in a central spot. The amplification operation is giving a human access to an (approximate) HCH -- so at every stage, a human is making the ultimate decisions about how to use the capabilities of the system to answer questions. This plausibly has alignment and corrigibility advantages, but may put a ceiling on capabilities (since we have to rely on the human ability to decompose problems well, creating good plans for solving problems).
Recursive quantilization instead seeks to allow arbitrary improvements to the deliberation process. It's all supervised by humans, and initially seeded by imitation of human question-answering; but humans can point out problems with the human deliberation process, and the system seeks to improve its reasoning using the human-seeded ideas about how to do so. To the extent that humans think HCH is the correct idealized reasoning process, recursive quantilization should approximate HCH. (To the extent it can't do this, recursive quantilization fails at its goals.)
One response I've gotten to recursive quantilization is "couldn't this just be advice to the human in HCH?" I don't think that's quite true.
HCH must walk a fine line between capability and safety. A big HCH tree can perform well at a vast array of tasks (if the human has a good strategy), but in order to be safe, the human must operate under set of restrictions, such as "don't simulate unrestricted search in large hypothesis spaces" -- with the full set of restrictions required for safety yet to be articulated. HCH needs a set of restrictions which provide safety without compromising capability.
In Inaccessible Information [LW · GW], Paul draws a distinction between accessible and inaccessible information. Roughly, information is accessible if we have a pretty good shot at getting modern ML to tell us about it, and inaccessible otherwise. Inaccessible information can include intuitive but difficult-to-test variables like "what Alice is thinking", as well as superhuman concepts that a powerful AI might invent.
A powerful modern AI like GPT-3 might have and use inaccessible information such as "what the writer of this sentence was really thinking", but we can't get GPT-3 to tell us about it, because we lack a way to train it to.
One of the safety concerns [LW · GW] of inaccessible information Paul lists is that powerful AIs might be more capable than aligned AIs due to their ability to utilize inaccessible information, where aligned AIs cannot. For example, GPT-5 might use inhuman concepts, derived from its vast experience predicting text, to achieve high performance. A safe HCH would never be able to use those concepts, since every computation within the HCH tree is supposed to be human-comprehensible. (Therefore, if the result of Iterated Amplification was able to use such concepts, we should be worried that it did not successfully approximate HCH.)
Paul proposes learning the human prior [LW · GW] as a potential solution. As I understand it, the basic idea is that HCH lacks Deep Learning's ability to absorb vast quantities of data and reach new conclusions. By learning the human prior, Paul seeks to learn the human response to those vast quantities of data. This would allow an HCH-like approach to learn the same "alien concepts" that a misaligned AI might learn.
I don't really understand how Paul sees HCH and learned-priors as fitting together, Recursive Quantilization seeks to get around this difficulty by training the QASs on lots of data in a way similar to big-data ML. As I emphasized before, recursive quantilization seeks to allow arbitrary improvements to the reasoning process, so long as they are improvements.
Of course, recursive quantilization also needs to restrict the QAS reasoning processes via safety constraints (using process-level feedback to rule out types of reasoning which can't be verified as safe). This could lead to the same problems with inaccessible information. But if it does, that's because no human-approved reasoning can approve of reasoning which utilizes the inaccessible information -- not even after many rounds of amplifying the human-seeded knowledge about how to judge reasoning as safe/unsafe. So, I would argue that if an approach broadly like recursive quantilization can't do it, then no robustly aligned method can do it.
Reasons why quantilizers might not be appropriate:
As I mentioned at the beginning, I've been feeling like quantilizers might be the wrong starting point for the Learning Normativity agenda. There's still some hope, but there are a few problems which make me want to look for other directions.
Quantilizers bound risk, but iteration increases risk arbitrarily.
The whole argument behind quantilization is as follows:
- The safe distribution has below c probability of catastrophe.
- The limited optimization samples from the top q of the safe distribution.
- So, the risk of catastrophe from the limited optimization is at most c/q.
In other words, the chance of catastrophic risk is increased exactly in proportion to how much we optimize.
Recursive quantilization does this over and over and over again. Naively, as we seek the fixed point, it seems like our bound on catastrophic risk gets worse and worse until we have no bound at all.
There could be a way around this. We could get a better risk bound, which took into account the improved optimization from each step in the recursive quantilization. The story could be something like this:
- In each quantilization step, we have an overwhelming chance of increasing the quality of value functions and safe distributions proposed in the next round.
- This means (with overwhelming odds) we get better at detecting catastrophe, so we can actively optimize against problems which the previous round of quantilization had to merely hedge against by avoiding over-optimizing.
- Therefore, the chance of catastrophe from each round of quantilization can be dramatically lower than the previous. Although these chances do add up over successive rounds of quantilization, they can sum to a negligible probability overall, even in the limit.
It would be nice to put together such a story, but it isn't clear how to argue that the improvement in value function and proposal distribution cuts into the probability of catastrophe by a sufficient amount.
Quantilizers assume catastrophes are rare in random choices, but in the recursive setting, too much randomness can create value drift.
Quantilization assumes we can get a "safe distribution" which might produce mediocre actions, but at least has a very low probability of catastrophic risk.
Supposing the scheme could produce highly capable systems at all, the recursive quantilizer environment seems like one where randomized actions have a good chance of producing catastrophic risk, so safe distributions would be incredibly difficult to engineer.
Imagine we're computing a big recursive quantilization tree. Randomly selecting a poor value function at one point will have a cascading effect. It will feed into a quantilization step which selects a bad QAS, which will go on to produce either the value function or the safe distribution for another quantilization, and so on. There's not fundamentally any corrective effect -- if either of the two inputs to quantilization is poor enough, then the output will be poor.
There's a basin of attraction, here: if the proposed safe distribution always contains good proposals with non-negligible probability, and the value function always has enough of the right meta-principles to correct specific errors that may be introduced through random error. But it's quite important that the output of each quantilization be better than the previous. If not, then we're not in a basin of attraction.
All of this makes it sound quite difficult to propose a safe distribution. The safe distribution needs to already land you within the basin of attraction (with very high probability), because drifting out of that basin can easily create a catastrophe.
Here's a slightly different argument. At each quantilization step, including the very first one, it's important that we find a QAS which actually fits our data quite well, because it is important that we pin down various things firmly in order to remain in the basin of attraction (especially including pinning down a value function at least as good as our starting value function). However, for each QAS which fits the data quite well and points to our desired basin of attraction, there are many alternative QAS which don't fit our data well, but point to very different, but equally coherent, basins of attraction. (In other words, there should be many equally internally consistent value systems which have basins of attraction of similar size.)
Since these other basins would be catastrophic, this means c, the probability of catastrophe, is higher than q, the amount of optimization we need to hit our narrow target.
This means the safe distributions has to be doing a lot of work for us.
Like the previous problem I discussed, this isn't necessarily a showstopper, but it does say that we'd need some further ideas to make recursive quantilization work, and suggests to me that quantilization might not be the right way to go.
Other Concerns
- Quantilizers don't have the best handles for modeling human philosophical deliberation over time. In other words, I don't think recursive quantilization absorbs the lesson of radical probabilism [? · GW]. In particular, although recursive quantilization involves iteratively improving a picture of "good reasoning", I think it lacks a kind of stability -- the picture of good reasoning must be entirely reconstructed each time, from "first principles" (IE from the principles developed in the previous step). I currently see no guarantee that recursive quantilization avoids being Dutch-Book-able over these stages, or any other such dynamic optimality notion.
- Quantilizers aren't great for modeling a collection of partial models. Since a quantilizer spits out one (moderately) optimized result, I have to focus on single QASs, rather than collections of experts which cover different areas of expertise. This means we don't get to break down the problem of reasoning about the world.
- Quantilizers don't put world models in a central spot. By putting optimization in a central spot, we sort of sideline reasoning and belief. This obscures the mechanism of updating on new information.
15 comments
Comments sorted by top scores.
comment by abramdemski · 2021-02-17T17:05:00.010Z · LW(p) · GW(p)
Here are some thoughts on how to fix the issues with the proposal.
- The initial proposal distribution should be sampling things close to the initial QAS, not sampling totally random neutral networks / etc.
This addresses the "quantilizers can't do the work of finding powerful QASs" problem. Instead, quantilizers are only doing the work of improving QASs. We don't need to assume smart, aligned QASs are significantly more common than malign QASs; instead, we only need to assume that catastrophic modifications are rare in the local neighborhood of something aligned.
This approach has some problems.
1a. We need to start out with a QAS in the same format as are trying to train (eg a big neutral net).
This is because (I presume) it's pretty difficult to sample nearby QASs otherwise.
This is potentially annoying because it's easier to build the initial value function and proposal distribution out of regular code.
1b. We need a distance metric which we can easily sample from, while also being quite confident that "close QASs are safe QASs" (if chosen at random).
We need to be pretty confident that close QASs are substantially similar; eg, there's no "flip the value function" move which would count as "nearby" in our metric. This suggests a metric on outputs (ie, answers to questions) rather than directly on representation (eg, neural network weights). This is obviously more difficult to sample from.
Also, a single modified answer can easily be catastrophic down the line; eg, a "nearby" QAS might not directly flip the value function, but it might modify the value function to prefer a flip, while keeping other aspects identical. So we can come up with yet-more-sophisticated distance functions which check for closeness in higher-order properties (ie, close-0 might be similarity in answers, while close-1 is close-0 similarity in children's answers, close-2 is the close-0 similarity of grandchildren, etc). Each increment makes sampling significantly more difficult, but makes it more difficult for random sampling to bring catastrophe.
There may be other distance metrics which capture what's important even better.
The question is: at what point are we satisfied that catastrophe is improbable enough? IE, what distance metric allows us to turn up our quantilizer's optimization sufficiently?
- The next stage of quantilization should always be an improvement in value; perhaps, always an improvement in several relevant dimensions of value.
This is intended to address the "iterated quantilization accumulates risk of drift" problem.
The requirement is close to "the quantilizers need to be sampling at most the top 50%", but that's not quite right, because the current QAS might not be at 50%. If it's hard to sample improvements (so most samples are worse by our value function), the current QAS might be high in the ranking.
This gives us a stopping condition: the system should never continue if it can't safely eliminate current and past QASs from the running. Each step should be better than what's come before.
It's also possible we should require each new QAS to be "better in every way"; ie, require simultaneous improvement along several important dimensions. For example, improvement in raw score on example questions, improvement on "safety of cognition" score (ie, evaluation of how good a thought process looks when it's examined by the current QAS), improvement on "quality of proposal distribution", improvement on "quality of value function".
Each additional requirement makes it more difficult to proceed with quantilization, and hence, more probable that the process will stop early.
It's particularly important that the next QAS has a lower chance of catastrophe -- indeed, it should be significantly lower. For example, we might require it to cut chance of catastrophe in half. (I'm not working out how risk accumulates in detail; this might not be a good proposal.)
Chance of catastrophe is as evaluated by previous QASs. So it's critical that the initial QAS has a good model of how to evaluate risk of catastrophe. This is, of course, difficult. Moreover, the quality of this evaluation is another critical feature to preserve and improve. One bad risk evaluation in the chain can itself become a catastrophe.
comment by Rohin Shah (rohinmshah) · 2021-01-11T20:28:36.586Z · LW(p) · GW(p)
Planned summary for the Alignment Newsletter:
This post gives an example scheme inspired by the previous post. Like [iterated amplification](https://www.alignmentforum.org/s/EmDuGeRw749sD3GKd [? · GW]), it defines an ideal (analogous to <@HCH@>(@Humans Consulting HCH@)), and then an approximation to it that could be computed in practice.
Like HCH, we imagine a tree of systems that improve as we increase the depth of the tree. However, the nodes in the tree are question-answering (QA) _systems_, rather than direct questions. Given a few QA systems from a lower level, we construct a QA system at a higher level by asking one low-level QA system “what’s a good safe distribution over QA systems”, and a different low-level QA system “what’s a good metric that we can use to judge QA systems”. We then use [quantilization](https://intelligence.org/files/QuantilizersSaferAlternative.pdf) ([AN #48](https://mailchi.mp/3091c6e9405c/alignment-newsletter-48)) to select better-performing QA systems, without optimizing too hard and falling prey to Goodhart’s Law. In the infinite limit, this should converge to a stable equilibrium.
By having the tree reason about what good safe distributions are, and what good metrics are, we are explicitly improving the way that the AI system learns to interpret feedback (this is what the “good metric” is meant to evaluate), thus meeting the desiderata from the previous post.
To implement this in practice, we do something similar to iterated amplification. Iterated amplification approximates depth-limited HCH by maintaining a model that can answer _arbitrary_ questions (even though each node is a single question); similarly here we maintain a model that has a _distribution_ over QA systems (even though each node is a single QA system). Then, to sample from the amplified distribution, we sample two QA systems from the current distribution, ask one for a good safe distribution and the other for a good metric, and use quantilization to sample a new QA system given these ingredients. We use distillation to turn this slow quantilization process into a fast neural net model.
Considering the problem of <@inaccessible information@>(@Inaccessible information@), the hope is that as we amplify the QA system we will eventually be able to approve of some safe reasoning process about inaccessible information. If this doesn’t happen, then it seems that no human reasoning could approve of reasoning about that inaccessible information, so we have done as well as possible.
Planned opinion (the first post is Learning Normativity [AF · GW]):
Replies from: abramdemski**On feedback types:** It seems like the scheme introduced here is relying quite strongly on the ability of humans to give good process-level feedback _at arbitrarily high levels_. It is not clear to me that this is something humans can do: it seems to me that when thinking at the meta level, humans often fail to think of important considerations that would be obvious in an object-level case. I think this could be a significant barrier to this scheme, though it’s hard to say without more concrete examples of what this looks like in practice.
**On interaction:** I’ve previously <@argued@>(@Human-AI Interaction@) that it is important to get feedback _online_ from the human; giving feedback “all at once” at the beginning is too hard to do well. However, the idealized algorithm here does have the feedback “all at once”. It’s possible that this is okay, if it is primarily process-level feedback, but it seems fairly worrying to me.
**On desiderata:** The desiderata introduced in the first post feel stronger than they need to be. It seems possible to specify a method of interpreting feedback that is _good enough_: it doesn’t exactly capture everything, but it gets it sufficiently correct that it results in good outcomes. This seems especially true when talking about process-level feedback, or feedback one meta level up -- as long as the AI system has learned an okay notion of “being helpful” or “being corrigible”, then it seems like we’re probably fine.
Often just making feedback uncertain can help. For example, in the preference learning literature, Boltzmann rationality has emerged as the model of choice for how to interpret human feedback. While there are several theoretical justifications for this model, I suspect its success is simply because it makes feedback uncertain: if you want to have a model that assigns higher likelihood to high-reward actions, but still assigns some probability to all actions, it seems like you end up choosing the Boltzmann model (or something functionally equivalent). Note that there is work trying to improve upon this model, such as by [modeling humans as pedagogic](https://papers.nips.cc/paper/2016/file/b5488aeff42889188d03c9895255cecc-Paper.pdf), or by <@incorporating a notion of similarity@>(@LESS is More: Rethinking Probabilistic Models of Human Behavior@).
So overall, I don’t feel convinced that we need to aim for learning at all levels. That being said, the second post introduced a different argument: that the method does as well as we “could” do given the limits of human reasoning. I like this a lot more as a desideratum; it feels more achievable and more tied to what we care about.
↑ comment by abramdemski · 2021-02-18T17:53:32.487Z · LW(p) · GW(p)
Thanks for the review, btw! Apparently I didn't think to respond to it before.
**On feedback types:** It seems like the scheme introduced here is relying quite strongly on the ability of humans to give good process-level feedback _at arbitrarily high levels_. It is not clear to me that this is something humans can do: it seems to me that when thinking at the meta level, humans often fail to think of important considerations that would be obvious in an object-level case. I think this could be a significant barrier to this scheme, though it’s hard to say without more concrete examples of what this looks like in practice.
I agree that this is a significant barrier -- humans have to be able to provide significant information about a significant number of levels for this to work.
However, I would emphasize two things:
- The point of this is to be able to handle feedback at arbitrary levels, not to require feedback at arbitrary levels. This creates a system which is not limited to optimizing at some finite meta-level.
- Even if humans only ever provide feedback about finitely many meta levels, the idea is for the system to generalize to other levels. This could provide nontrivial, useful information at very high meta-levels. For example, the system could learn anti-wireheading and anti-manipulation patterns relevant to all meta-levels. This is kind of the whole point of the setup -- most of these ideas originally came out of thinking about avoiding wireheading and manipulation, and how "going up a meta-level" seems to make some progress, but not eliminate the essential problem.
**On interaction:** I’ve previously <@argued@>(@Human-AI Interaction@) that it is important to get feedback _online_ from the human; giving feedback “all at once” at the beginning is too hard to do well. However, the idealized algorithm here does have the feedback “all at once”. It’s possible that this is okay, if it is primarily process-level feedback, but it seems fairly worrying to me.
My intention is for the procedure to be interactive; however, I definitely haven't emphasized how that aspect would work.
I don't think you could get very good process-level feedback without humans actually examining examples of the system processing, at some point. Although I also think the system should learn from artificially constructed examples which humans use to demonstrate catastrophically bad behavior.
**On desiderata:** The desiderata introduced in the first post feel stronger than they need to be. It seems possible to specify a method of interpreting feedback that is _good enough_: it doesn’t exactly capture everything, but it gets it sufficiently correct that it results in good outcomes. This seems especially true when talking about process-level feedback, or feedback one meta level up -- as long as the AI system has learned an okay notion of “being helpful” or “being corrigible”, then it seems like we’re probably fine.
Partly I want to defend the "all meta levels" idea as an important goalpost rather than necessary -- yes, maybe it's stronger than necessary, but wouldn't it be interesting to end up in a place where we didn't have to worry about whether we'd supported enough meta-levels? I wasn't thinking very much about necessity when I wrote the criteria down. Instead, I was trying to articulate a vision which I had a sense would be interesting.
As discussed in Normativity [LW · GW], this is about what ideal alignment really would be. How does the human concept of "should" work? What kind of thing can we think of "human values" as? Whether it's necessary/possible to make compromises is a separate question.
But partly I do want to defend it as necessary -- or rather, necessary in the absence of a true resolution of problems at a finite meta-level. It's possible that problems of AI safety can be solved a different way, but if we could solve them this way, we'd be set. (So I guess I'm saying, sufficiency seems like the more interesting question than necessity.)
It seems possible to specify a method of interpreting feedback that is _good enough_
My question is: do you think there's a method that's good enough to scale up to arbitrary capability? IE, both on the capability side and the alignment side:
- Does it seem possible to pre-specify some fixed way of interpreting feedback, which will scale up to arbitrarily capable systems? IE, when I say a very capable system "understands" what I want, does it really seem like we can rely on a fixed notion of understanding, even thinking only of capabilities?
- Especially for alignment purposes, don't you expect any fixed model of interpreting feedback to be too brittle by default, and somehow fall apart when a sufficiently powerful intelligence is interpreting feedback in such a fixed way?
I'm happy for a solution at a fixed meta-level to be found, but in its absence, I prefer something meeting the criteria I outline, where (it seems to me) we can tell the system everything we've come up with so far about what a good solution would look like.
as long as the AI system has learned an okay notion of “being helpful” or “being corrigible”, then it seems like we’re probably fine.
At MIRI we tend to take "we're probably fine" as a strong indication that we're not fine ;p
More seriously: I think "being corrigible" is an importantly highly-meta concept. Quoting from Zhu's FAQ:
The property we’re trying to guarantee is something closer to “alignment + extreme caution about whether it’s aligned and cautious enough”. Paul usually refers to this as corrigibility.
This extreme caution is importantly recursive; a corrigible agent isn't just cautious about whether it's aligned, it's also cautious about whether it's corrigible.
This is important for Paul's agenda because corrigibility needs to be preserved (and indeed, improved) across many levels of iterated amplification and distillation. This kind of recursive definition is precisely what we need for that.
It's similarly important for any situation where a system could self-improve many times.
Even outside that context, I just don't know that it's possible to specify a very good notion of "corrigibility" at a finite meta-level. It's kind of about not trusting any value function specified at any finite meta-level.
I also think most approximate notions of "being helpful" will be plagued by human manipulation or other problems.
Often just making feedback uncertain can help. For example, in the preference learning literature, Boltzmann rationality has emerged as the model of choice for how to interpret human feedback.
This seems like a perfect example to me. It works pretty well for current systems, but scaled up, it seems it would ultimately reach dramatically wrong ideas about what humans value. (In particular, it ultimately must think the highest-utility action is the most probable one, an assumption which will engender poor interpretations of situations in which errors are more common than 'correct' actions, such as those common to the heuristics and biases literature.)
That being said, the second post introduced a different argument: that the method does as well as we “could” do given the limits of human reasoning. I like this a lot more as a desideratum; it feels more achievable and more tied to what we care about.
Yeah, although I stand by my desiderata as stated, I do not think I've yet done a good job of explaining why all the desiderata are important and how they connect into a big picture, or even, exactly what problems I'm trying to address.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-02-19T01:15:32.375Z · LW(p) · GW(p)
(Noting that given this was a month ago I have lost context and am more likely than usual to contradict what I previously wrote)
The point of this is to be able to handle feedback at arbitrary levels, not to require feedback at arbitrary levels.
What's the point of handling feedback at high levels if we never actually get feedback at those levels?
Perhaps another way of framing it: suppose we found out that humans were basically unable to give feedback at level 6 or above. Are you now happy having the same proposal, but limited to depth 5? I get the sense that you wouldn't be, but I can't square that with "you only need to be able to handle feedback at high levels but you don't require such feedback".
Even if humans only ever provide feedback about finitely many meta levels, the idea is for the system to generalize to other levels.
I don't super see how this happens but I could imagine it does. (And if it did it would answer my question above.) I feel like I would benefit from concrete examples with specific questions and their answers.
My intention is for the procedure to be interactive; however, I definitely haven't emphasized how that aspect would work.
Okay, that makes sense. It seemed to me like since the first few bits of feedback determine how the system interprets all future feedback, it's particularly important for those first few bits to be correct and not lock in e.g. a policy that ignores all future feedback.
I think "being corrigible" is an importantly highly-meta concept.
[...]
Even outside that context, I just don't know that it's possible to specify a very good notion of "corrigibility" at a finite meta-level. It's kind of about not trusting any value function specified at any finite meta-level.
I agree that any safety story will probably require you to get some concept X right. (Corrigibility is one candidate for X.) Your safety story would then be "X is inductively preserved as the AI system self-modifies / learns new information / makes a successor agent", and so X has to scale arbitrarily far. You have to get this "perfectly" right in that it can't be that your agent satisfies X under normal conditions but then fails when COVID hits; this is challenging. You don't have to get it "perfectly" right in that you could get some more conservative / careful X' that restricts the agent's usefulness (e.g. it has to check in with the human more often) but over time it can self-modify / make successor agents with property X instead.
Importantly, if it turns out that X = corrigibility is too hard, we can also try less performant but safer things, like X = "we revert to a safe baseline policy if we're not in <whitelist of acceptable situations>", and the whitelist can grow over time.
(As a side note, I am pretty pessimistic about ambitious choices of X, such as X = human values, or X = optimal behavior in all possible situations, because those are high-complexity and not something that even humans could get right. It feels like this proposal is trying to be similarly ambitious, though I wouldn't be surprised if I changed my mind on that very quickly.)
I agree that under this framework of levels of feedback, X has to be specified at "all the levels".
I am less convinced that you need a complex scheme for giving feedback at all levels to do this sort of thing. The training scheme is not the same as the learned agent; you can have a training scheme that has a simple (and incorrect) feedback interpretation system like Boltzmann rationality, and get out a learned agent that has internalized a much more careful interpretation system. For example, Learning to summarize from human feedback does use Boltzmann rationality, but could finetune GPT-3 to e.g. interpret human instructions pragmatically. This interpretation system can apply "at all levels", in the same way that human brains can apply similar heuristics "at all levels".
(There are still issues with just applying the learning from human preferences approach, but they seem to be much more about "did the neural net really learn the intended concept" / inner alignment, rather than "the neural net learned what to do at level 1 but not at any of the higher levels".)
Partly I want to defend the "all meta levels" idea as an important goalpost rather than necessary
Yeah, that seems reasonable to me.
So I guess I'm saying, sufficiency seems like the more interesting question than necessity.
I do agree that sufficiency is more interesting when it can actually be guaranteed. Idk what I meant when I wrote the opinion, but my guess was that it was something like "I'm observing that we can get by with something easier to satisfy that seems more practical to do", so more like a tradeoff between importance and tractability. I don't think I meant it as a strong critique or anything like that.
My question is: do you think there's a method that's good enough to scale up to arbitrary capability?
I reject the notion that we need a method that scales up to arbitrary capability. I'd love it if we got one, but it's seeming less and less plausible to me that we'll get such a method. I prefer to make it so that we are in a paradigm where you can notice when your method fails to scale, fix the problem, and then continue. You do need to ensure that you can fix the problem (i.e. no treacherous turns), so this isn't a full panacea, but it does mean that you don't e.g. need a perfect human model.
One example of how to do this is to use X = "revert to a safe baseline policy outside of <whitelist>", and enlarge the whitelist over time. In this case "failing to scale" is "our AI system couldn't solve the task because our whitelist hobbled it too much".
So, to your questions:
- Does it seem possible to pre-specify some fixed way of interpreting feedback, which will scale up to arbitrarily capable systems? IE, when I say a very capable system "understands" what I want, does it really seem like we can rely on a fixed notion of understanding, even thinking only of capabilities?
No, that doesn't seem possible for arbitrary capabilities (except in some vacuous sense where there exists some way of doing this that in principle we could hardcode, or in another vacuous sense where we fix a method of interpretation like "all feedback implies that I should shut down", which is safe but not performant). It seems possible for capabilities well beyond human capabilities, and if we succeed at that, we can use those capabilities to design the next generation of AI systems.
- Especially for alignment purposes, don't you expect any fixed model of interpreting feedback to be too brittle by default, and somehow fall apart when a sufficiently powerful intelligence is interpreting feedback in such a fixed way?
Yes, I do expect this to be brittle for a sufficiently powerful intelligence, again ignoring some vacuous counterexamples. Again, I expect it would be fine for a merely way-better-than-humans intelligence.
This seems like a perfect example to me. It works pretty well for current systems, but scaled up, it seems it would ultimately reach dramatically wrong ideas about what humans value. (In particular, it ultimately must think the highest-utility action is the most probable one, an assumption which will engender poor interpretations of situations in which errors are more common than 'correct' actions, such as those common to the heuristics and biases literature.)
Yup, totally agree. Make sure to update it as you scale up further.
At MIRI we tend to take "we're probably fine" as a strong indication that we're not fine ;p
Yeah I have been and continue to be confused by this perspective, at least as an empirical claim (as opposed to a normative one [LW(p) · GW(p)]). I get the sense that it's partly because optimization amplifies [LW · GW] and so there is no "probably", there is only one or the other. I can kinda see that when you assume an arbitrarily powerful AIXI-like superintelligence, but it seems basically wrong when you expect the AI system to apply optimization that's not ridiculously far above that applied by a human.
Replies from: abramdemski↑ comment by abramdemski · 2021-02-19T21:08:43.574Z · LW(p) · GW(p)
At MIRI we tend to take “we’re probably fine” as a strong indication that we’re not fine ;p
(I should remark that I don't mean to speak "for MIRI" and probably should have phrased myself in a way which avoided generalizing across opinions at MIRI.)
Yeah I have been and continue to be confused by this perspective, at least as an empirical claim (as opposed to a normative one). I get the sense that it’s partly because optimization amplifies and so there is no “probably”, there is only one or the other. I can kinda see that when you assume an arbitrarily powerful AIXI-like superintelligence, but it seems basically wrong when you expect the AI system to apply optimization that’s not ridiculously far above that applied by a human.
I think I would agree with this if you said "optimization that's at or below human level" rather than "not ridiculously far above".
Humans can be terrifying. The prospect of a system slightly smarter than any human who has ever lived, with values that are just somewhat wrong, seems not great. In particular, this system could do subtle things resulting in longer-term value shift, influence alignment research to go down particular paths, etc. (I realize the hypothetical scenario has at least some safeguards, so I won't go into more extreme scenarios like winning at politics hard enough to become world dictator and set the entire future path of humanity, etc. But I find this pretty plausible in a generic "moderately above human" scenario. Society rewards top performers disproportionately for small differences. Being slightly better than any human author could get you not only a fortune in book sales, but a hugely disproportionate influence. So it does seem to me like you'd need to be pretty sure of whatever safeguards you have in place, particularly given the possibility that you mis-estimate capability, and given the possibility that the system will improve its capabilities in ways you may not anticipate.)
But really, mainly, I was making the normative claim. A culture of safety is not one in which "it's probably fine" is allowed as part of any real argument. Any time someone is tempted to say "it's probably fine", it should be replaced with an actual estimate of the probability, or a hopeful statement that combined with other research it could provide high enough confidence (with some specific sketch of what that other research would be), or something along those lines. You cannot build reliable knowledge out of many many "it's probably fine" arguments; so at best you should carefully count how many you allow yourself.
A relevant empirical claim sitting behind this normative intuition is something like: "without such a culture of safety, humans have a tendency to slide into whatever they can get away with, rather than upholding safety standards".
This all seems pretty closely related to Eliezer's [LW · GW] writing [LW · GW] on security mindset.
Often just making feedback uncertain can help. For example, in the preference learning literature, Boltzmann rationality has emerged as the model of choice for how to interpret human feedback.
This seems like a perfect example to me. It works pretty well for current systems, but scaled up, it seems it would ultimately reach dramatically wrong ideas about what humans value.
Yup, totally agree. Make sure to update it as you scale up further.
You said that you don't think learning human values is a good target for "X", so I worry that focusing on this will be a bit unfair to your perspective. But it's also the most straightforward example, and we both seem to agree that it illustrates things we care about here. So I'm just going to lampshade the fact that I'll use "human values" as an example a lot in what follows.
The point of this is to be able to handle feedback at arbitrary levels, not to require feedback at arbitrary levels.
What’s the point of handling feedback at high levels if we never actually get feedback at those levels?
I think what's really interesting to me is making sure the system is reasoning at all those levels, because I have an intuition that that's necessary (to get concepts we care about right). Accepting feedback at all those levels is a proxy. (I want to include it in my list of criteria because I don't know a better way of operationalising "reasoning at all levels", and also, because I don't have a fixed meta-level at which I'd be happy to cap feedback. Capping meta-levels at something like 1K doesn't seem like it would result in a better research agenda.)
Sort of like Bayes' Law promises to let you update on anything. You wouldn't travel back in time and tell Bayes "what's the point of researching updating on anything, when in fact we only ever need to update on some relatively narrow set of propositions relating to the human senses?" It's not a perfect analogy, but it gets at part of the point.
My basic claim is that we've seen the same sorts of problems occur at multiple meta-levels, and each time, it's tempting to retreat to another meta-level. I therefore want a theory of (these particular sorts of) meta-levels, because it's plausible to me that in such a context, we can solve the general problem rather than continue to push it back. Or at least, that it would provide tools to better understand the problem.
There's a perspective in which "having a fixed maximum meta-level at all" is pretty directly part of the problem. So it's natural to see if we can design systems which don't have that property.
From this perspective, it seems like my response to your "incrementally improve loss functions as capability levels rise" perspective should be:
It seems like this would just be a move you'd eventually want to make, anyway.
At some point, you don't want to keep designing safe policies by hand; you want to optimize them to minimize some loss function.
At some point, you don't want to keep designing safe loss functions by hand; you want to do value learning.
At some point, you don't want to keep inventing better and better value-learning loss functions by hand; you want to learn-to-learn.
At some point, you won't want to keep pushing back meta-levels like this; you'll want to do it automatically.
From this perspective, I'd just be looking ahead in the curve. Which is pretty much what I think I'm doing anyway.
So although the discussion of MIRI-style security mindset and just-how-approximately-right safety concepts need to be seems relevant, it might not be the crux.
Perhaps another way of framing it: suppose we found out that humans were basically unable to give feedback at level 6 or above. Are you now happy having the same proposal, but limited to depth 5? I get the sense that you wouldn’t be, but I can’t square that with “you only need to be able to handle feedback at high levels but you don’t require such feedback”.
This depends. There are scenarios where this would significantly change my mind.
But let's suppose humans have trouble with 6 or above just because it's hard to keep that many meta-levels in working memory. How would my proposal function in this world?
We want the system to extrapolate to the higher levels, figuring out what humans (implicitly) believe. But a consistent (and highly salient) extrapolation is the one which mimics human ineptitude at those higher levels. So we need to be careful about what we mean by "extrapolate".
What we want the system to do is reason as if it received the feedback we would have given if we had more working memory (to the extent that we endorse "humans with more working memory" as better reasoners). My proposal is that a system should be taught to do exactly this.
This is where my proposal differs from proposals more reliant on human imitation. Any particular thing we can say about what better reasoning would look like, the system attempts to incorporate.
Another way humans indirectly give evidence about higher levels is through their lower-level behavior. To some extent, we can infer from a human applying a specific form of reasoning, that the human reflectively endorses that style of reasoning. This idea can be used to transfer information about level N to some information about level N+1. But the system should learn caution about this inference, by observing cases where it fails (cases where humans habitually reason in a particular way, but don't endorse doing so), as well as by direct instruction.
Even if humans only ever provide feedback about finitely many meta levels, the idea is for the system to generalize to other levels.
I don’t super see how this happens but I could imagine it does. (And if it did it would answer my question above.) I feel like I would benefit from concrete examples with specific questions and their answers.
A lot of ideas apply to many meta-levels; EG, the above heuristic is an example of something which generalizes to many meta-levels. (It is true in general that you can make a probabilistic inference about level N+1 by supposing level-N activity is probably endorsed; and, factors influencing the accuracy of this heuristic probably generalize across levels. Applying this to human behavior might only get us examples at a few meta-levels, but the principle should also be applied to idealized humans, EG the model of humans with more working memory. So it can continue to bear fruit at many meta-levels, even when actual human feedback is not available.)
Importantly, process-level feedback usually applies directly to all meta-levels. This isn't a matter of generalization of feedback to multiple levels, but rather, direct feedback about reasoning which applies at all levels.
For example, humans might give feedback about how to do sensible probabilistic reasoning. This information could be useful to the system at many meta-levels. For example, it might end up forming a general heuristic that its value functions (at every meta-level) should be expectation functions which quantify uncertainty about important factors. (Or it could be taught this particular idea directly.)
More importantly, anti-daemon ideas would apply at every meta-level. Every meta-level would include inner-alignment checks as a heavily weighted part of its evaluation function, and at all levels, proposal distributions should heavily avoid problematic parts of the search space.
Okay, that makes sense. It seemed to me like since the first few bits of feedback determine how the system interprets all future feedback, it’s particularly important for those first few bits to be correct and not lock in e.g. a policy that ignores all future feedback.
In principle, you could re-start the whole training process after each interaction, so that each new piece of training data gets equal treatment (it's all part of what's available "at the start"). In practice that would be intractable, but that's the ideal which practical implementations should aim to approximate.
So, yes, it's a problem, but it's one that implementations should aim to mitigate.
(Part of how one might aim to mitigate this is to teach the system that it's a good idea to try to approximate this ideal. But then it's particularly important to introduce this idea early in training, to avoid the failure mode you mention; so the point stands.)
For example, Learning to summarize from human feedback does use Boltzmann rationality, but could finetune GPT-3 to e.g. interpret human instructions pragmatically. This interpretation system can apply “at all levels”, in the same way that human brains can apply similar heuristics “at all levels”.
(There are still issues with just applying the learning from human preferences approach, but they seem to be much more about “did the neural net really learn the intended concept” / inner alignment, rather than “the neural net learned what to do at level 1 but not at any of the higher levels”.)
It seems to me like you're trying to illustrate something like "Abram's proposal doesn't get at the bottlenecks".
I think it's pretty plausible that this agenda doesn't yield significant fruit with respect to several important alignment problems, and instead (at best) yields a scheme which would depend on other solutions to those particular problems.
It's also plausible that those solutions would, themselves, be sufficient for alignment, rendering this research direction extraneous.
In particular, it's plausible to me that iterated amplification schemes (including Paul's schemes and mine) require a high level of meta-competence to get started, such that achieving that initial level of competence already requires a method of aligning superhuman intelligence, making anything else unnecessary. (This was one of Eliezer's critiques of iterated amplification.)
However, the world you describe, in which alignment tech remains imperfect (wrt scaling) for a long time, but we can align successively more intelligent agents with successively refined tools, is not one of those worlds. In that world, it is possible to make incrementally more capable agents incrementally more perfectly aligned, until that point at which we have something smart (and aligned) enough to serve as the base case for an iterated amplification scheme. In that world, the scheme I describe could be just one of the levels of alignment tech which end up useful at some point.
One example of how to do this is to use X = “revert to a safe baseline policy outside of <whitelist>”, and enlarge the whitelist over time. In this case “failing to scale” is “our AI system couldn’t solve the task because our whitelist hobbled it too much”.
I'm curious how you see whitelisting working.
It feels like your beliefs about what kind of methods might work for "merely way-better-than-human" systems are a big difference between you and I, which might be worth discussing more, although I don't know if it's very central to everything else we're discussing.
Replies from: rohinmshah, rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-02-20T03:10:16.717Z · LW(p) · GW(p)
I think what's really interesting to me is making sure the system is reasoning at all those levels, because I have an intuition that that's necessary (to get concepts we care about right).
I'm super on board with this desideratum, and agree that it would not be a good move to change it to some fixed number of levels. I also agree that from a conceptual standpoint many ideas are "about all the levels".
My questions / comments are about the implementation proposed in this post. I thought that you were identifying "levels of reasoning" with "depth in the idealized recursive QAS tree"; if that's the case I don't see how feedback at one level generalizes to all the other levels (feedback at that level is used to make the QAS at that level, and not other levels, right?)
I'm pretty sure I'm just failing to understand some fact about the particular implementation, or what you mean by "levels of reasoning", or its relation to the idealized recursive QAS tree.
This is where my proposal differs from proposals more reliant on human imitation. Any particular thing we can say about what better reasoning would look like, the system attempts to incorporate.
I would argue this is also true of learning from human preferences (comparisons), amplification, and debate; not sure if you would disagree. I agree straight human imitation wouldn't do this.
In principle, you could re-start the whole training process after each interaction, so that each new piece of training data gets equal treatment (it's all part of what's available "at the start").
Huh? I thought the point was that your initial feedback can help you interpret later feedback. So maybe you start with Boltzmann rationality, and then you get some feedback from humans, and now you realize that you should interpret all future feedback pragmatically.
It seems like you have to choose one of two options:
- Order of feedback does matter, in which case bad early feedback can lock you in to a bad outcome
- Order of feedback doesn't matter, in which case you can't improve your interpretation of feedback over time (at least, not in a consistent way)
(This seems true more generally for any system that aims to learn at all the levels, not just for the implementation proposed in this post.)
It seems to me like you're trying to illustrate something like "Abram's proposal doesn't get at the bottlenecks".
I think it's more like "I'm not clear on the benefit of this proposal over (say) learning from comparisons". I'm not asking about bottlenecks; I'm asking about what the improvement is.
I'm curious how you see whitelisting working.
The same way I see any other X working: we explicitly train the neural net to satisfy X through human feedback (perhaps using amplification, debate, learning the prior, etc). For a whitelist, we might be able to do something slightly different: we train a classifier to say whether the situation is or isn't in our whitelist, and then only query the agent when it is in our whitelist (otherwise reverting to a safe baseline). The classifier and agent share most of their weights.
Then we also do a bunch of stuff to verify that the neural net actually satisfies X (perhaps adversarial training, testing, interpretability, etc). In the whitelisting case, we'd be doing this on the classifier, if that's the route we went down.
It feels like your beliefs about what kind of methods might work for "merely way-better-than-human" systems are a big difference between you and I, which might be worth discussing more, although I don't know if it's very central to everything else we're discussing.
(Addressed this in the other comment)
Replies from: abramdemski↑ comment by abramdemski · 2021-03-08T18:29:46.340Z · LW(p) · GW(p)
My questions / comments are about the implementation proposed in this post. I thought that you were identifying "levels of reasoning" with "depth in the idealized recursive QAS tree"; if that's the case I don't see how feedback at one level generalizes to all the other levels (feedback at that level is used to make the QAS at that level, and not other levels, right?)
I'm pretty sure I'm just failing to understand some fact about the particular implementation, or what you mean by "levels of reasoning", or its relation to the idealized recursive QAS tree.
OK. Looking back, the post really doesn't address this, so I can understand why you're confused.
My basic argument for cross-level generalization is that a QAS has to be represented compactly while being prepared to answer questions at any level; so, it has to generalize across levels. But there are also other effects.
So, suppose I give the system feedback about some specific 3rd-level judgement. The way I imagine this happening is that the feedback gets added to a big dataset. Evaluating QASs on this dataset is part of how the initial value function, , does its thing. also should prefer QASs which produce value functions which are pretty similar to , so that this property is approximately preserved as the system gets amplified. So, a few things happen:
- The feedback is added to the dataset, so it is used to judge the next generation of QASs (really the next learned distribution over QASs) so they will avoid doing poorly on this 3rd-level judgement.
- This creates some cross-level generalization, because the QASs which perform poorly on this probably do so for reasons not isolated to 3rd-level judgments. In NN terms, there are shared hidden neurons which serve multiple different levels. In algorithmic information theory, there is mutual information between levels, so programs which do well will share information across levels rather than represent them all separately.
- The feedback is also used as an example of how to judge (ie the fourth-level skill which would be able to generate the specific 3rd-level feedback). This also constrains the next generation of QASs, and so similarly has a cross-level generalization effect, due to shared information in the QAS representation (eg multi-level neurons, bits of code relevant across multiple levels, etc).
- Similarly, this provides indirect evidence about 5th level, 6th level, etc because just as the 4th level needs to be such that it could have generated the 3rd-level feedback, the 5th level needs to be such that it would approve of such 4th levels, the 6th level needs to approve of 5th levels with that property, and so on.
So you can see, feedback on one level propagates information to all the other levels along many pathways.
>This is where my proposal differs from proposals more reliant on human imitation. Any particular thing we can say about what better reasoning would look like, the system attempts to incorporate.
I would argue this is also true of learning from human preferences (comparisons), amplification, and debate; not sure if you would disagree. I agree straight human imitation wouldn't do this.
I would argue it's not true of the first; learning human preferences will fail to account for ways humans agree human preference judgments are error-prone (eg the story about how judges judge more harshly right before lunch).
As for iterated amplification, it definitely has this property "in spirit" (ie if everything works well), but whether particular versions have this property is another question. Specifically, it's possible to ask "how should I answer questions like this?" and such meta-questions, to try to get debiasing information before coming up with a strategy to answer a question. However, it's up to the human in the box to come up with these strategies, and you can't go meta too much without going into an infinite loop. And the human in the box also has to have good strategy for searching for this kind of meta-info.
>In principle, you could re-start the whole training process after each interaction, so that each new piece of training data gets equal treatment (it's all part of what's available "at the start").
Huh? I thought the point was that your initial feedback can help you interpret later feedback. So maybe you start with Boltzmann rationality, and then you get some feedback from humans, and now you realize that you should interpret all future feedback pragmatically.
Every piece of feedback gets put into the same big pool which helps define , the initial ("human") value function. Subsequent value functions also look at this big pool. So in the hypothetical where we re-start the training every time we give feedback,
- First, the initial naive interpretation is used, on every piece of feedback ever. This helps define , the first learned distribution on QASs.
- Then, uses its new, slightly refined interpretation of all the feedback to form new judgments of QAS quality, which help define .
- We keep iterating like this, getting better interpretations of feedback which we use to generate even better interpretations. We do this until we reach some stopping point, which might depend on safety concerns (eg stopping while we're confident it has not drifted too much)
- We then interact with the resulting system, generating more feedback for a while, until we have produced enough feedback that we wan to re-start the process again.
This procedure ensures that the system doesn't outright ignore any feedback due to overconfidence (because all feedback is used by every restart), while also ensuring that the most sophisticated model is (eventually) used to interpret feedback. The result (if you iterate to convergence) is a fixed-point where the distribution would reproduce itself, so in a significant sense, the end result is as if you used the most sophisticated feedback-interpretation model from the beginning. At the same time, what you actually use at the beginning is the naive feedback interpretation model, which gives us the guarantee that EG if you stomp out a self-aggrandizing mental pattern (which would pointedly ignore feedback against itself), it actually gets stomped out.
That's the ideal I'd shoot for.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-08T23:49:35.194Z · LW(p) · GW(p)
Most of this makes sense (or perhaps more accurately, sounds like it might be true, but there's a good chance if I reread the post and all the comments I'd object again / get confused somehow). One thing though:
Every piece of feedback gets put into the same big pool which helps define Hv, the initial ("human") value function. [...]
Okay, I think with this elaboration I stand by what I originally said:
It seemed to me like since the first few bits of feedback determine how the system interprets all future feedback, it's particularly important for those first few bits to be correct and not lock in e.g. a policy that ignores all future feedback.
Specifically, isn't it the case that the first few bits of feedback determine , which might then lock in some bad way of interpreting feedback (whether existing or future feedback)?
Replies from: abramdemski↑ comment by abramdemski · 2021-03-09T14:54:49.470Z · LW(p) · GW(p)
Okay, I think with this elaboration I stand by what I originally said
You mean with respect to the system as described in the post (in which case I 100% agree), or the modified system which restarts training upon new feedback (which is what I was just describing)?
Because I think this is pretty solidly wrong of the system that restarts.
Specifically, isn't it the case that the first few bits of feedback determine , which might then lock in some bad way of interpreting feedback (whether existing or future feedback)?
All feedback so far determines the new when the system restarts training.
(Again, I'm not saying it's feasible to restart training all the time, I'm just using it as a proof-of-concept to show that we're not fundamentally forced to make a trade-off between (a) order independence and (b) using the best model to interpret feedback.)
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-09T18:41:58.584Z · LW(p) · GW(p)
I continue to not understand this but it seems like such a simple question that it must be that there's just some deeper misunderstanding of the exact proposal we're now debating. It seems not particularly worth it to find this misunderstanding; I don't think it will really teach us anything conceptually new.
(If I did want to find it, I would write out pseudocode for the new proposed system and then try to make a more precise claim in terms of the variables in the pseudocode.)
Replies from: abramdemski↑ comment by abramdemski · 2021-03-09T19:51:53.143Z · LW(p) · GW(p)
Fair.
↑ comment by Rohin Shah (rohinmshah) · 2021-02-20T02:34:28.686Z · LW(p) · GW(p)
Responding first to the general approach to good-enough alignment:
I think I would agree with this if you said "optimization that's at or below human level" rather than "not ridiculously far above".
Humans can be terrifying. The prospect of a system slightly smarter than any human who has ever lived, with values that are just somewhat wrong, seems not great.
Less important response: If by "not great" you mean "existentially risky", then I think you need to explain why the smartest / most powerful historical people with now-horrifying values did not constitute an existential risk.
My real objection: Your claim is about what happens after you've already failed, in some sense -- you're starting from the assumption that you've deployed a misaligned agent. From my perspective, you need to start from a story in which we're designing an AI system, that will eventually have let's say "5x the intelligence of a human", whatever that means, but we get to train that system however we want. We can inspect its thought patterns, spend lots of time evaluating its decisions, test what it would do in hypothetical situations, use earlier iterations of the tool to help understand later iterations, etc. My claim is that whatever bad optimization "sneaks through" this design process is probably not going to have much impact on the agent's performance, or we would have already caught it.
Possibly related: I don't like thinking of this in terms of how "wrong" the values are, because that doesn't allow you to make distinctions about whether behaviors have already been seen at training or not.
But really, mainly, I was making the normative claim. A culture of safety is not one in which "it's probably fine" is allowed as part of any real argument. Any time someone is tempted to say "it's probably fine", it should be replaced with an actual estimate of the probability, or a hopeful statement that combined with other research it could provide high enough confidence (with some specific sketch of what that other research would be), or something along those lines. You cannot build reliable knowledge out of many many "it's probably fine" arguments; so at best you should carefully count how many you allow yourself.
A relevant empirical claim sitting behind this normative intuition is something like: "without such a culture of safety, humans have a tendency to slide into whatever they can get away with, rather than upholding safety standards".
If your claim is just that "we're probably fine" is not enough evidence for an argument, I certainly agree with that. That was an offhand remark in an opinion in a newsletter where words are at a premium; I obviously hope to do better than that in reality.
This all seems pretty closely related to Eliezer's [LW · GW] writing [LW · GW] on security mindset.
Some thoughts here:
- I am unconvinced that we need a solution that satisfies a security-mindset perspective, rather than one that satisfies an ordinary-paranoia perspective. (A crucial point here is that the goal is not to build adversarial optimizers in the first place, rather than defending against adversarial optimization.) As far as I can tell the argument for this claim is... a few fictional parables? (Readers: Before I get flooded with examples of failures where security mindset could have helped, let me note that I will probably not be convinced by this unless you can also account for the selection bias in those examples.)
- I don't really see why the ML-based approaches don't satisfy the requirement of being based on security mindset. (I agree "we're probably fine" does not satisfy that requirement.) Note that there isn't a solution that is maximally security-mindset-y, the way I understand the phrase (while still building superintelligent systems). A simple argument: we always have to specify something (code if nothing else); that something could be misspecified. So here I'm just claiming that ML-based approaches seem like they can be "sufficiently" security-mindset-y.
- I might be completely misunderstanding the point Eliezer is trying to make, because it's stated as a metaphor / parable instead of just stating the thing directly (and a clear and obvious disanalogy is that we are dealing with the construction of optimizers, rather than the construction of artifacts that must function in the presence of optimization).
↑ comment by abramdemski · 2021-03-08T19:45:06.071Z · LW(p) · GW(p)
This seems like a pretty big disagreement, which I don't expect to properly address with this comment. However, it seems a shame not to try to make any progress on it, so here are some remarks.
Less important response: If by "not great" you mean "existentially risky", then I think you need to explain why the smartest / most powerful historical people with now-horrifying values did not constitute an existential risk.
My answer to this would be, mainly because they weren't living in times as risky as ours; for example, they were not born and raised in a literal AGI lab (which the hypothetical system would be).
My real objection: Your claim is about what happens after you've already failed, in some sense -- you're starting from the assumption that you've deployed a misaligned agent. From my perspective, you need to start from a story in which we're designing an AI system, that will eventually have let's say "5x the intelligence of a human", whatever that means, but we get to train that system however we want.
The scenario we were discussing was one where robustness to scale is ignored as a criteria, so my concern is that the system turns out more intelligent than expected, and hence, tools like EG asking earlier iterations of the same system to help examine the cognition may fail. If you're pretty confident that your alignment strategy is sufficient for 5x human, then you have to be pretty confident that the system is indeed 5x human. This can be difficult due to the difference between task performance and the intelligence of inner optimisers. For example, GPT-3 can mimic humans moderately well (very impressive by today's standards, obviously, but moderately well in the grand scope of things). However, it can mimic a variety of humans, in a way that's in some sense much better than any one human. This makes it obvious that GPT-3 is smarter than it lets on; it's "playing dumb". Presumably this is what led Ajeya to predict that GPT-3 can offer better medical advice than any doctor [LW · GW] (if only we could get it to stop playing dumb).
So my main crux here is whether you can be sufficiently confident of the 5x, to know that your tools which are 5x-appropriate apply.
If I was convinced of that, my next question would be how we can be that confident that we have 5x-appropriate tools. Part of why I tend toward "robustness to scale" is that it seems difficult to make strong scale-dependent arguments, except at the scales we can empirically investigate (so not very useful for scaling up to 5x human, until the point at which we can safely experiment at that level, at which point we must have solved the safety problem at that level in other ways). But OTOH you're right that it's hard to make strong scale-independent arguments, too. So this isn't as important to the crux.
Possibly related: I don't like thinking of this in terms of how "wrong" the values are, because that doesn't allow you to make distinctions about whether behaviors have already been seen at training or not.
Right, I agree that it's a potentially misleading framing, particularly in a context where we're already discussing stuff like process-level feedback.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2021-03-09T00:06:33.333Z · LW(p) · GW(p)
So my main crux here is whether you can be sufficiently confident of the 5x, to know that your tools which are 5x-appropriate apply.
This makes sense, though I probably shouldn't have used "5x" as my number -- it definitely feels intuitively more like your tools could be robust to many orders of magnitude of increased compute / model capacity / data. (Idk how you would think that relates to a scaling factor on intelligence.) I think the key claim / crux here is something like "we can develop techniques that are robust to scaling up compute / capacity / data by N orders, where N doesn't depend significantly on the current compute / capacity / data".
comment by Gordon Seidoh Worley (gworley) · 2020-12-02T17:10:34.288Z · LW(p) · GW(p)
Just want to register I agree with your assessment of concerns, and generally reflects my concerns with attempts to bound risk. I generally think evolution is a good example of this: "risk" is bounded within an individual generation because organisms cannot arbitrarily change themselves, but over generations there's little bounding where things can go other than getting trapped in local maxima.