One Study, Many Results (Matt Clancy)
post by aarongertler · 2021-07-18T23:10:24.588Z · LW · GW · 19 commentsThis is a link post for https://mattsclancy.substack.com/p/one-study-many-results
Contents
Summary The post Crowdsourcing Science Resist Science Nihilism! None 19 comments
I didn't see this post, its author, or the study involved elsewhere on LW, so I'm crossposting the content. Let me know if this is redundant, and I'll take it down.
Summary
This post looks at cases where teams of researchers all began with the same data, then used it to answer a question — and got a bunch of different answers, based on their different approaches to statistical testing, "judgment calls", etc.
This shows the difficulty of doing good replication work even without publication bias; none of the teams here had any special incentive to come up with a certain result, and they all seemed to be doing their best to really answer the question.
Also, I'll copy the conclusion of the post and put it here:
More broadly, I take away three things from this literature:
- Failures to replicate are to be expected, given the state of our methodological technology, even in the best circumstances, even if there’s no publication bias.
- Form your ideas based on suites of papers, or entire literatures, not primarily on individual studies.
- There is plenty of randomness in the research process for publication bias to exploit. More on that in the future.
The post
Science is commonly understood as being a lot more certain than it is. In popular science books and articles, an extremely common approach is to pair a deep dive into one study with an illustrative anecdote. The implication is that’s enough: the study discovered something deep, and the anecdote made the discovery accessible. Or take the coverage of science in the popular press (and even the academic press): most coverage of science revolves around highlighting the results of a single new (cool) study. Again, the implication is that one study is enough to know something new. This isn’t universal, and I think coverage has become more cautious and nuanced in some outlets during the era of covid-19, but it’s common enough that for many people “believe science” is a sincere mantra, as if science made pronouncements in the same way religions do.
But that’s not the way it works. Single studies - especially in the social sciences - are not certain. In the 2010s, it has become clear that a lot of studies (maybe the majority) do not replicate. The failure of studies to replicate is often blamed (not without evidence) on a bias towards publishing new and exciting results. Consciously or subconsciously, that leads scientists to employ shaky methods that get them the results they want, but which don’t deliver reliable results.
But perhaps it’s worse than that. Suppose you could erase publication bias and just let scientists choose whatever method they thought was the best way to answer a question. Freed from the need to find a cool new result, scientists would pick the best method to answer a question and then, well, answer it.
The many-analysts literature shows us that’s not the case though. The truth is, the state of our “methodological technology” just isn’t there yet. There remains a core of unresolvable uncertainty and randomness in the best of circumstances. Science isn’t certain.
Crowdsourcing Science
In many-analyst studies, multiple teams of researchers test the same previously specified hypothesis, using the exact same dataset. In all the cases we’re going to talk about today, publication is not contingent on results, so we don’t have scientists cherry-picking the results that make their results look most interesting; nor do we have replicators cherry-picking results to overturn prior results. Instead, we just have researchers applying judgment to data in the hopes of answering a question. Even still results can be all over the map.
Let’s start with a really recent paper in economics: Huntington-Klein et al. (2021). In this paper, seven different teams of researchers tackle two research questions that had been previously published in top economics journals (but which were not so well known that the replicators knew about them). In each case, the papers were based on publicly accessible data, and part of the point of the exercise was to see how different decisions about building a dataset from the same public sources lead to different outcomes. In the first case, researchers used variation across US states in compulsory schooling laws to assess the impact of compulsory schooling on teenage pregnancy rates.
Researchers were given a dataset of schooling laws across states and times, but to assess the impact of these laws on teen pregnancy, they had to construct a dataset on individuals from publicly available IPUMS data. In building the data, researchers diverged in how they handled different judgement calls. For examples:
One team dropped data on women living in group homes; others kept them.
Some teams counted teenage pregnancy as pregnancy after the age of 14, but one counted pregnancy at the age of 13 as well
One team dropped data on women who never had any children
In Ohio, schooling was compulsory until the age of 18 in every year except 1944, when the compulsory schooling age was 8. Was this a genuine policy change? Or a typo? One team dropped this observation, but the others retained it.
Between this and other judgement calls, no team assembled exactly the same dataset. Next, the teams needed to decide how, exactly, to perform the test. Again, each team differed a bit in terms of what variables it chose to control for and which it didn’t. Race? Age? Birth year? Pregnancy year?
It’s not immediately obvious which decisions are the right ones. Unfortunately, they matter a lot! Here were the seven teams’ different results.
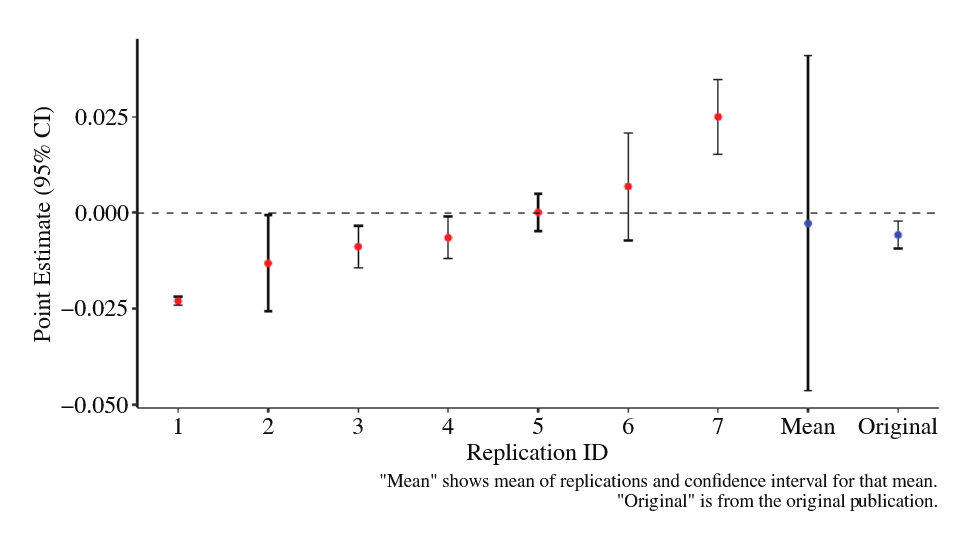
Depending on your dataset construction choices and exact specification, you can find either that compulsory schooling lowers or increases teenage pregnancy, or has no impact at all! (There was a second study as well - we will come back to that at the end)
This isn’t the first paper to take this approach. An early paper in this vein is Silberzahn et al. (2018). In this paper, 29 research teams composed of 61 analysts sought to answer the question “are soccer players with dark skin tone more likely to receive red cards from referees?” This time, teams were given the same data but still had to make decisions about what to include and exclude from analysis. The data consisted of information on all 1,586 soccer players who played in the first male divisions of England, Germany, France and Spain in the 2012-2013 season, and for whom a photograph was available (to code skin tone). There was also data on player interactions with all referees throughout their professional careers, including how many of these interactions ended in a red card and a bunch of additional variables.
As in Huntington-Klein et al. (2021), the teams adopted a host of different statistical techniques, data cleaning methods, and exact specifications. While everyone included “number of games” as one variable, just one other variable was included in more than half of the teams regression models. Unlike Huntington-Klein et al. (2021), in this study, there was also a much larger set of different statistical estimation techniques. The resulting estimates (with 95% confidence intervals) are below.
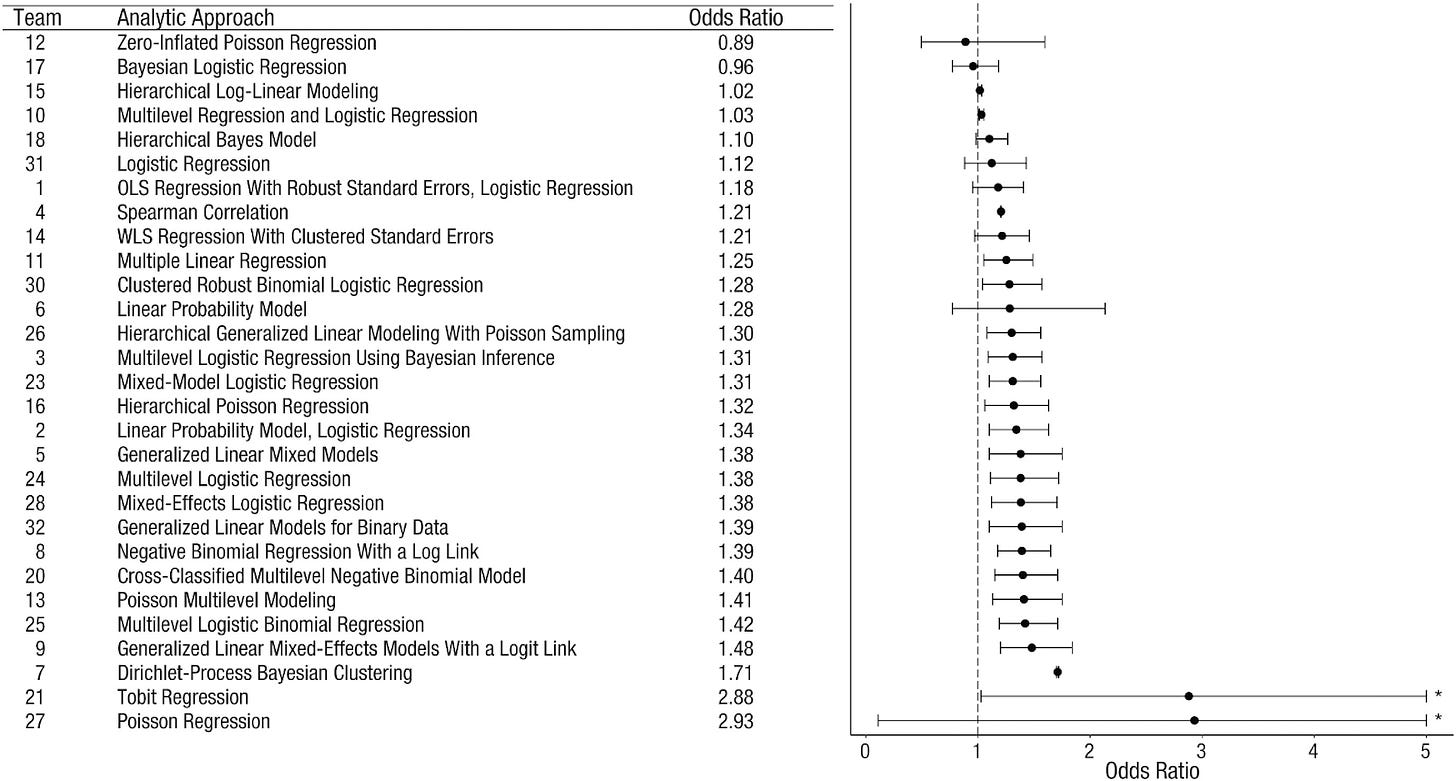
Is this good news or bad news? On the one hand, most of the estimates lie between 1 and 1.5. On the other hand, about a third of the teams cannot rule out zero impact of skin tone on red cards; the other two thirds find a positive effect that is statistically significant at standard levels. In other words, if we picked two of these teams’ results at random and called one the “first result” and the other a “replication,” they would only agree whether the result is statistically significant or not about 55% of the time!
Let’s look at another. Breznau et al. (2021) get 73 teams, comprising 162 researchers to answer the question “does immigration lower public support for social policies?” Again, each team was given the same data. This time, that consisted of responses to surveys about support for government social policies (example: “On the whole, do you think it should or should not be the government’s responsibility to provide a job for everyone who wants one?”), measures of immigration (at the country level), and various country-level explanatory variables such as GDP per capita and the Gini coefficient. The results spanned the spectrum of possible conclusions.
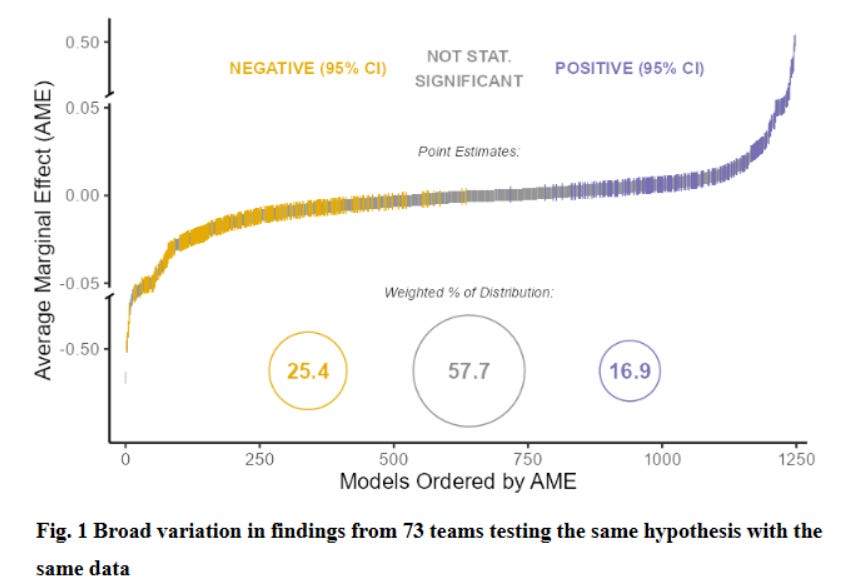
Slightly more than half of the results found no statistically significant link between immigration levels and support for policies - but a quarter found more immigration reduced support, and more than a sixth found more immigration increased support. If you picked two results at random, they would agree on the direction and statistical significance of the results less than half the time!
We could do morestudies, but the general consensus is the same: when many teams answer the same question, beginning with the same dataset, it is quite common to find a wide spread of conclusions (even when you remove motivations related to beating publication bias).
At this point, it’s tempting to hope the different results stem from differing levels of expertise, or differing quality of analysis. “OK,” we might say, “different scientists will reach different conclusions, but maybe that’s because some scientists are bad at research. Good scientists will agree.” But as best as these papers can tell, that’s not a very big factor.
The study on soccer players tried to answer this in a few ways. First, the teams were split into two groups based on various measures of expertise (teaching classes on statistics, publishing on methodology, etc). The half with greater expertise was more likely to find a positive and statistically significant effect (78% of teams, instead of 68%), but the variability of their estimates was the same across the groups (just shifted in one direction or another). Second, the teams graded each other on the quality of their analysis plans (without seeing the results). But in this case, the quality of the analysis plan was unrelated to the outcome. This was the case even when they only looked at the grades given by experts in the statistical technique being used.
The last study also split its research teams into groups based on methodological expertise or topical expertise. In neither case did it have much of an impact on the kind of results discovered.
So; don’t assume the results of a given study are definitive to the question. It’s quite likely that a different set of researchers, tackling the exact same question and starting with the exact same data would have obtained a different result. Even if they had the same level of expertise!
Resist Science Nihilism!
But while most people probably overrate the degree of certainty in science, there also seems to be a sizable online contingent that has embraced the opposite conclusion. They know about the replication crisis and the unreliability of research, and have concluded the whole scientific operation is a scam. This goes too far in the opposite direction.
For example, a science nihilist might conclude that if expertise doesn’t drive the results above, then it must be that scientists simply find whatever they want to find, and that their results are designed to fabricate evidence for whatever they happen to believe already. But that doesn’t seem to be the case, at least in these multi-analyst studies. In both the study of soccer players and the one on immigration, participating researchers reported their beliefs before doing their analysis. In both cases there wasn’t a statistically significant correlation between prior beliefs and reported results.
If it’s not expertise and it’s not preconceived beliefs that drive results, what is it? I think it really is simply that research is hard and different defensible decisions can lead to different outcomes. Huntington-Klein et al. (2021) perform an interesting exercise where they apply the same analysis to different teams data, or alternatively, apply different analysis plans to the same dataset. That exercise suggests roughly half of the divergence in the teams conclusions stems from different decisions made in the database construction stage and half from different decisions made about analysis. There’s no silver bullet - just a lot of little decisions that add up.
More importantly, while it’s true that any scientific study should not be viewed as the last word on anything, studies still do give us signals about what might be true. And the signals add up.
Looking at the above results, while I am not certain of anything, I come away thinking it’s slightly more likely that compulsory schooling reduces teenage pregnancy, pretty likely that dark skinned soccer players get more red cards, and that there is no simple meaningful relationship between immigration and views on government social policy. Given that most of the decisions are defensible, I go with the results that show up more often than not.
And sometimes, the results are pretty compelling. Earlier, I mentioned that Huntington-Klein et al. (2021) actually investigated two hypotheses. In the second, Huntington-Klein et al. (2021) ask researchers to look at the effect of employer-provided healthcare on entrepreneurship. The key identifying assumption is that in the US, people become eligible for publicly provided health insurance (Medicare) at age 65. But people’s personalities and opportunities tend to change more slowly and idiosyncratically - they also don’t suddenly change on your 65th birthday. So the study looks at how rates of entrepreneurship compare between groups just older than the 65 threshold and those just under it. Again, researchers have to build a dataset from publicly available data. Again every team made different decisions, such that none of the data sets are exactly alike. Again, researchers must decide exactly how to test the hypothesis, and again they choose slight variations in how to test it. But this time, at least the estimated effects line up reasonably well.
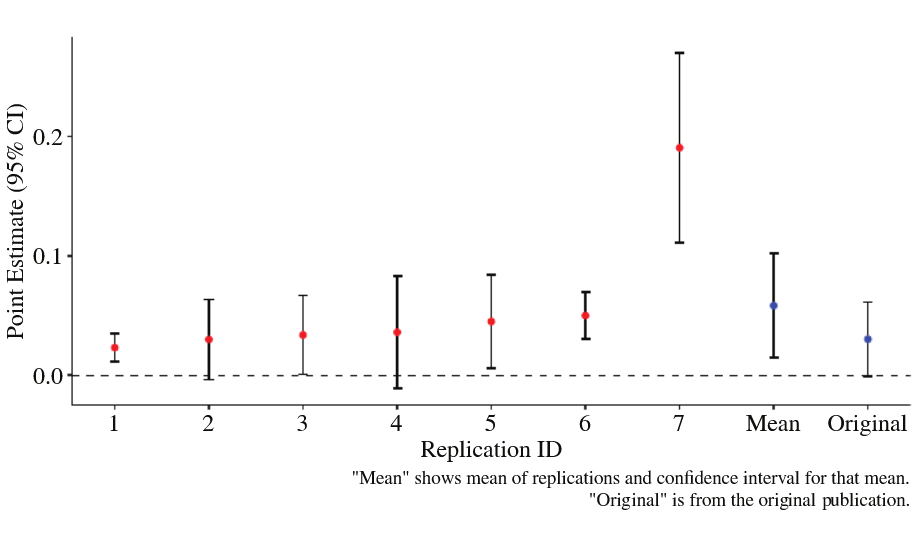
I think this is pretty compelling evidence that there’s something really going on here - at least for the time and place under study.
And it isn’t necessary to have teams of researchers generate the above kinds of figures. “Multiverse analysis” asks researchers to explicitly consider how their results change under all plausible changes to the data and analysis; essentially, it asks individual teams to try and behave like a set of teams. In economics (and I’m sure in many other fields - I’m just writing about what I know here), something like this is supposedly done in the “robustness checks” section of a paper. In this part of a study, the researchers show how their results are or are not robust to alternative data and analysis decisions. The trouble has long been that robustness checks have been selective rather than systematic; the fear is that researchers highlight only the robustness checks that make their core conclusion look good and bury the rest.
But I wonder if this is changing. The robustness checks section of economics papers has been steadily ballooning over time, contributing to the novella-like length of many modern economics papers (the average length rose from 15 pages to 45 pages between 1970 and 2012). Some papers are now beginning to include figures like the following, which show how the core results change when assumptions change and which closely mirror the results generated by multiple-analyst papers. Notably, this figure includes many sets of assumptions that show results that are not statistically different from zero (the authors aren’t hiding everything).
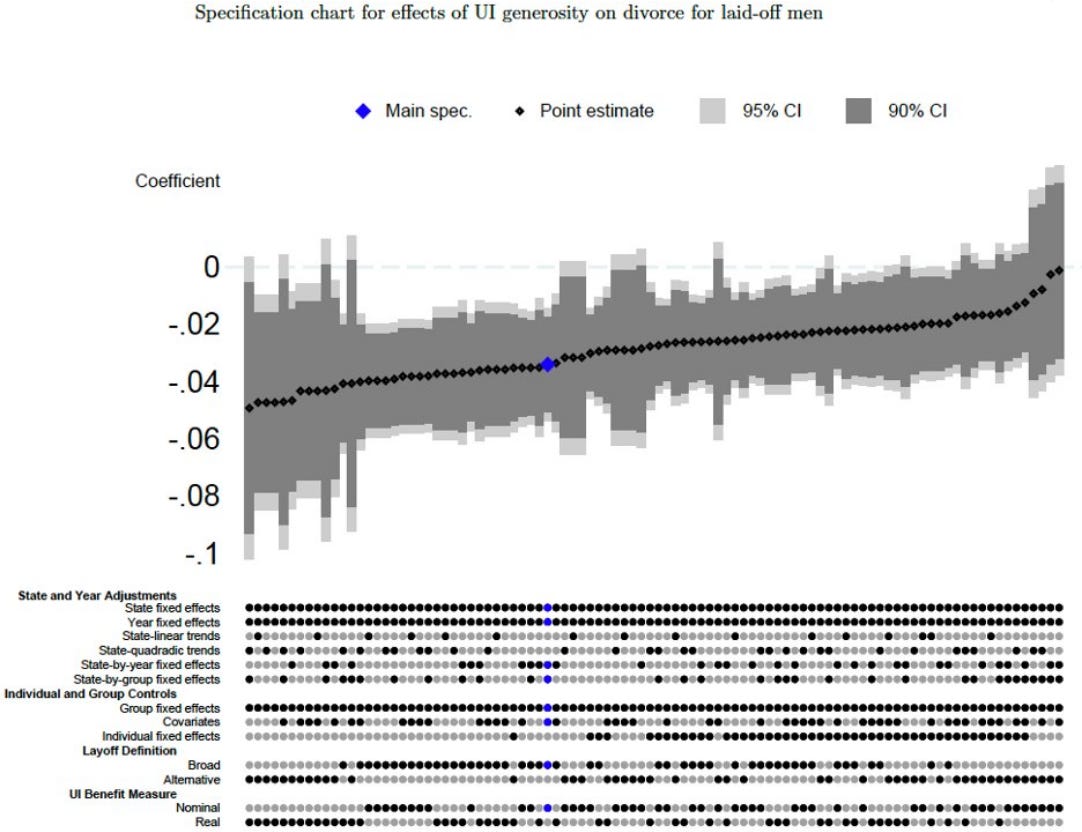
Economists complain about how difficult these requirements make the publication process (and how unpleasant they make it to read papers), but the multiple-analyst work suggests it’s probably still a good idea, at least until our “methodological technology” catches up so that you don’t have a big spread of results when you make different defensible decisions.
More broadly, I take away three things from this literature:
- Failures to replicate are to be expected, given the state of our methodological technology, even in the best circumstances, even if there’s no publication bias.
- Form your ideas based on suites of papers, or entire literatures, not primarily on individual studies.
- There is plenty of randomness in the research process for publication bias to exploit. More on that in the future.
19 comments
Comments sorted by top scores.
comment by johnswentworth · 2021-07-22T14:20:18.110Z · LW(p) · GW(p)
The examples in the post where authors disagreed heavily about the sign of the effect (school -> pregnancy and immigration -> social policy support) are both questions where I'd expect, a priori, to find small-and-inconsistent effect sizes. And if we ignore "statistical significance" and look at effect sizes in the graphs, it indeed looks like almost all the researchers on those questions found tiny effects - plus or minus 0.02 for the first, or 0.05 for the second. (Unclear what the units are on those, so maybe I'm wrong about the effects being small, but I'm guessing it's some kind of standardized effect size.) The statistical significance or sign of the effect isn't all that relevant - the important part is that almost all researchers agree the effect is tiny.
On the flip side, for the soccer study, the effect sizes are reasonably large. Assuming I'm reading that graph right, the large majority of researchers find that dark-skinned players are ~30% more likely to get a red-card. There's still a wide range of estimates, but the researchers mostly agree that the effect is large, and they mostly agree on the direction.
So I don't think it really makes sense to interpret these as "many results". The takeaway is not "analysis has too many degrees of freedom for results to replicate". The takeaway is "statistical significance by itself sucks, look at effect sizes". It's effect sizes which reproduce, and it's effect sizes which matter anyway for most practical purposes (as opposed to just getting papers published). For the most part, the teams only disagree on whether numbers which are basically 0 are +0 or -0.
Replies from: ryan_b↑ comment by ryan_b · 2021-08-05T19:49:58.148Z · LW(p) · GW(p)
Are the methods of analysis considered part of the "methodological technology" this thread of research considers incomplete?
If so, the whole thing sort of trivializes to "statistics suck, and therefore science methodologically sucks." On the flip side, how difficult/expensive would it be to run a series of these specifying the analytical methods in the same way the hypothesis and data sources were specified? One group does effect sizes instead of significance, one group does likelihood functions instead of significance, etc.
I keep updating in favor of a specialization-of-labor theory for reorganizing science. First order of business: adding analysts to create a Theory/Experiment/Analysis trifecta.
comment by TheMajor · 2021-07-19T18:52:30.549Z · LW(p) · GW(p)
Thank you for the wonderful links, I had no idea that (meta)research like this was being conducted. Of course it doesn't do to draw conclusion from just one or two papers like that, we would need a bunch more to be sure that we really need a bunch more before we can accept the conclusion.
Jokes aside, I think there is a big unwarranted leap in the final part of your post. You correctly state that just because the outcome of research seems to not replicate we should not assume evil intent (subconscious or no) on the part of the authors. I agree, but also frankly I don't care. The version of Science Nihilism you present almost seems like strawman Nihilism: "Science does not replicate therefore everything a Scientist says is just their own bias". I think a far more interesting statement would be "The fact that multiple well-meaning scientists get diametrically opposed results using the same data and techniques, which are well-accepted in the field, shows that the current standards in Science are insufficient to draw the type of conclusions we want."
Or, from a more information-theoretic point of view, our process of honest effort by scientists followed by peer review and publication is not a sufficiently sharp tool to assign numbers to the questions we're asking, and a large part of the variance in the published results is indicative of numerous small choices by the researchers instead of indicative of patterns in the data. Whether or not scientists are evil shills with social agendas (hint: they're mostly not) is somewhat irrelevant if the methods used won't separate truth from fiction. To me that's proper Science Nihilism, none of this 'intent' or 'bias' stuff.
In a similar vein I wonder if the page count of the robustness check is really an indication of a solution to this problem. The alternative seems bleak (well, you did call it Nihilism) but maybe we should allow for the possibility that the entire scientific process as commonly practiced is insufficiently powerful to answer these research questions (for example, maybe the questions are ill-posed). To put it differently, to answer a research question we need to separate the hypothetical universes where it has one answer from the hypothetical universes where it has a different answer, and then observe data to decide which universe we happen to be in. In many papers this link between the separation and the data to be observed is so strenuous that I would be surprised if the outcome was determined by anything but the arbitrary choices of the researchers.
Replies from: justinpombrio, AllAmericanBreakfast↑ comment by justinpombrio · 2021-07-19T22:11:40.058Z · LW(p) · GW(p)
Yeah, that was my reaction too: regardless of intentions, the scientific method is, in the "soft" sciences, frequently not arriving at the truth.
The follow up question should of course be: how can we fix it? Or more pragmatically, how can you identify whether a study's conclusion can be trusted? I've seen calls to improve all the things that are broken right now: reduce p-hacking and publication bias, aim for lower p values, spread better knowledge of statistics, do more robustness checks, etc. etc.. This post adds to the list of things that must be fixed before studies are reliable.
But one thing I've wondered is: what about focusing more on studies that find large effects? There are two advantages: (i) it's harder to miss large effects, making the conclusion more reliable and easier to reproduce, and (ii) if the effects is small, it doesn't matter as much anyways. For example, I trust the research on the planning fallacy more because the effect is so pronounced. And I'm much more interested to know about things that are very carcinogenic than about things that are just barely carcinogenic enough to be detected.
So, has someone written the book "Top 20 Largest Effects Found in [social science / medicine / etc.]"? I would buy it in a heartbeat.
Replies from: TheMajor↑ comment by TheMajor · 2021-07-19T23:37:08.663Z · LW(p) · GW(p)
I've seen calls to improve all the things that are broken right now: <list>
I think this is a flaw in and of itself. There are many, many ways to go wrong, and the entire standard list (p-hacking, selective reporting, multiple stopping criteria, you name it) should be interpreted more as symptoms than as causes of a scientific crisis.
The crux of the whole scientific approach is that you empirically separate hypothetical universes. You do this by making your universe-hypotheses spit out predictions, and then verify them. It seems to me that by and large this process is ignored or even completely absent when we start asking difficult soft science questions. And to clarify: I don't particularly blame any researcher, or institute, or publishing agency or peer doing some reviewing. I think that the task at hand is so inhumanly difficult that collectively we are not up to it, and instead we create some semblance of science and call it a day.
From a distanced perspective, I would like my entire scientific process to look like reverse-engineering a big black box labeled 'universe'. It has input buttons and output channels. Our paradigm postulate correlations between input settings and outputs, and then an individual hypothesis makes a claim about the input settings. We track forward what outputs would be caused by any possible input setting, observe the reality, and update with Bayesian odds ratios.
The problem is frequently that the data we are relying on is influenced by an absolutely gargantuan number of factors - as an example in the OP, the teenage pregnancy rate. I have no trouble believing that statewide schooling laws have some impact on this, but possibly so do for example above-average summer weather, people's religious background, the ratio of boys to girls in a community, economic (in)stability, recent natural disasters and many more factors. So having observed the teenage pregnancy rates, inferring the impact of the statewide schooling laws is a nigh impossible task. Even just trying to put this into words my mind immediately translated this to "what fraction of the state-by-state variance in teenage pregnancy rates can be attributed to this factor, and what fraction to other factors" but even this is already an oversimplification - why are we comparing states at a fixed time, instead of tracking states over time, or even taking each state-time snapshot as an individual dataset? And why is a linear correlation model accurate, who says we can split the multi-factor model into additive components (implied by the fractions)?
The point I am failing to make is that in this case it is not at all clear what difference in the pregnancy rates we would observe if the statewide schooling laws had a decidedly negative, small negative, small positive or decidedly positive impact, as opposed to one or several of the other factors dominating the observed effects. And without that causal connection we can never infer the impact of these laws from the observed data. This is not a matter of p-hacking or biased science or anything of the sort - the approach doesn't have the (information theoretic) power to discern the answer we are looking for in the first place, i.e. to single out the true hypothesis from between the false ones.
As for your pragmatic question, how can we tell if a study is to be trusted? I'd recommend asking experts in your field first, and only listening to cynics second. If you insist on asking, my method is to evaluate whether or not it seems plausible to me that, assuming that the conclusion of the paper holds, this would show up as the announced effect observed in the paper. Simultaneously I try to think of several other explanations for the same data. If either of these tries gives some resounding result I tend to chuck the study in the bin. This approach is fraught with confirmation bias ("it seems implausible to me because my view of the world suggests you shouldn't be able to measure an effect like this"), but I don't have a better model of the world to consult than my model of the world.
↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-07-19T22:08:12.660Z · LW(p) · GW(p)
Of course it doesn't do to draw conclusion from just one or two papers like that, we would need a bunch more to be sure that we really need a bunch more before we can accept the conclusion.
I think this is a really important, serious point. This post links five meta-studies:
- Huntington-Klein et al. (2021)
- Silberzahn et al. (2018)
- Breznau et al. (2021)
- Botvinik-Nezer, R., Holzmeister, F., Camerer, C.F. et al (2020)
- Bastiaansen et al. (2020)
Respectively, their fields are microeconomics, psychology, political science, neuroscience imaging, and psychology again. That's not a representative sample of "science" by field.
Furthermore, the same assumptions about biased analyses apply to these meta-studies. It seems possible to me that these researchers targeted specific topics they thought would be likely to produce these results. That can be extremely valuable when the goal is to reveal which specific topics have inadequate methodologies.
If instead, the goal is to argue that science as a whole is subject to a "hidden universe of uncertainty," then we need to find some way to control for this topic-selection bias in meta-studies. Perhaps specialists in various subfiels could submit a range of datasets and hypotheses, with their own forecasts for the chance that a meta-study would turn up a consistent directional effect. Without such control measures, these meta-studies seem vulnerable to the same publication bias as the fields they investigate.
Do these studies purport to be investigating particular methods, or are they themselves arguing that their results should inform our uncertainty level for all of science?
- I can't access Huntington-Klein, as Sci-Hub isn't cataloguing 2021 publications at the moment.
- Silberzahn asks, "What if scientific results are highly contingent on subjective decisions at the analysis stage?"
- Breznau states, "We argue that outcome variability across researchers is also a product of a vast but sometimes hidden universe of analytical flexibility," apparently referring to researchers in general across the scientific enterprise.
- Botvinik-Nezer refers to "researcher degrees of freedom" in many areas of science, but contextualizes their work as specifically investigating this issue with respect to psychology.
- Bastiaansen very specifically contextualize their work as an investigation into the reliability of experience-based sampling.
It seems to me that we should be really careful before extrapolating from the specific datasets, methods, and subfields these researchers are investigating into others. In particular, I'd like to see some care put into forecasting and selecting research topics that are likely or unlikely to stand up to a multiteam analysis.
Replies from: TheMajor↑ comment by TheMajor · 2021-07-19T23:43:10.242Z · LW(p) · GW(p)
It seems to me that we should be really careful before extrapolating from the specific datasets, methods, and subfields these researchers are investigating into others. In particular, I'd like to see some care put into forecasting and selecting research topics that are likely or unlikely to stand up to a multiteam analysis.
I think this is good advice, but only when taken literally. In my opinion there is more than sufficient evidence to suggest that the choices made by researchers (pick any of the descriptions you cited) have a significant impact on the conclusions of papers across a wide variety of fields. Indeed, I think this should be the default assumption until proven otherwise. I'd motivate this primarily by the argument that there are many different ways to draw a wrong conclusion (especially under uncertainty), but only one right way to weigh up all the evidence. Put differently, I think undue influence of arbitrary decisions is the default, and it is only through hard work and collective scientific standards that we stand a chance of avoiding this.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-07-20T07:28:57.189Z · LW(p) · GW(p)
Let me reframe this. Settled science is the set of findings that we think are at low risk of being falsified in the future. These multi team analyses are basically showing that unsettled science is just that - unsettled... which is exactly what readers should have been expecting all along.
So not only should we be careful about extrapolating from these findings to the harder sciences, we should be careful not to extrapolate from the fragility of unsettled science to assume that settled science is similarly fragile. Just because the stuff that makes it into a research paper might be overturned, doesn’t mean that the contents of your textbooks are likely to be overturned.
This is why the very broad “science” framing concerns me. I think these scientists are doing good work, but the story some of them are telling is a caution that their readers shouldn’t require. But maybe I have too high an opinion of the average reader of scientific literature?
Replies from: TheMajor↑ comment by TheMajor · 2021-07-20T10:01:47.465Z · LW(p) · GW(p)
That is very interesting, mostly because I do exactly think that people are putting too much faith in textbook science. I'm also a little bit uncomfortable with the suggested classification.
I have high confidence in claims that I think are at low risk of being falsified soon, not because it is settled science but because this sentence is a tautology. The causality runs the other way: if our confidence in the claim is high, we provisionally accept it as knowledge.
By contrast, I am worried about the social process of claims moving from unsettled to settled science. In my personal opinion there is an abundance of overconfidence in what we would call "settled science". The majority of the claims therein are likely to be correct and hold up under scrutiny, but the bar is still lower than I would prefer.
But maybe I'm way off the mark here, or maybe we are splitting hairs and describing the same situation from a different angle. There is lots of good science out there, and you need overwhelming evidence to justify questioning a standard textbook. But there is also plenty of junk that makes it all the way into lecture halls, never mind all the previous hoops it had to pass through to get there. I am very worried about the statistical power of our scientific institutes in separating truth from fiction, and I don't think the settled/unsettled distinction helps address this.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-07-20T17:14:42.941Z · LW(p) · GW(p)
I have another way of stating my concern with the rhetoric and thought here.
People start as "level 1" readers of science, and they may end up leveling up as they read more. One of the "skill slots" they can improve on is their skepticism. This means understanding intuitively about how much confidence to place in a claim, and why.
To me, this line of argument is mainly aimed at those "level 1" readers. The message is "Hey, there's a lot of junk out there, and some of it even makes it into textbooks! It's hard to say how much, but watch out!" That sentence is useful to its audience if it builds more accurate intuitions about how to interpret science. And it's clear that it might well have that effect in a nonzero number of cases.
However, it seems to me that it could also build worse intuitions about how to read science in "level 1" readers, by causing them to wildly overcorrect. For example, I have a friend who is deep into intelligent design, and has surrounded himself with other believers in ID (who are PhD-holding scientists). He views them as mentors. They've taught him not only about ID, but also a robust set of techniques for absolutely trashing every piece of research into evolution that he gets his hands on. It's a one-sided demand for rigor, to be sure, but it's hard to see or accept that when your community of practice has downleveled your ability to read scientific literature.
I spend quite a bit of time reading the output of the online rationalist and rat-adjacent community. I see almost no explicit writing on when and why we should sometimes believe the contents of scientific literature, and a gigantic amount of writing on why we should be profoundly skeptical that it has truth content. I see a one-sided demand for rigor in this, on a community-wide level.
It's this problem that I am trying to correct for, by being skeptical of the skepticism, using its own heuristics:
- We should be careful before we extrapolate.
- There is a range of appropriate intuitive priors for published peer-reviewed literature, ranging "unsettled" to "settled." We should determine that prior when we consider the truth-value of a particular claim.
Here's how I might express this to a "level 1" reader of science:
Replies from: TheMajorIn the soft sciences, scientists can identify datasets and hypotheses where they're confident that the garden of forking paths has many destinations. This aligns with statistical studies of replication rate failures, as well as our knowledge of the limited resources and incentive structures in scientific research. Furthermore, not all experimental methods are really appropriate for the thematic questions they claim to investigate.
Given all this, it's wise to be skeptical of individual experiments. And we should be aware of the perspective Scott Alexander articulated in "Beware the Man of One Study," where for some topics, like the effect of the minimum wage, the challenge of parsing the research either requires a dedicated expert, or simply can't be done responsibly by anyone.
HOWEVER.
The emerging field of what we might call "empirical skepticism" is itself unsettled science. It's a hot, relatively new field. Its methods are difficult to interpret, and may not be reliable in some cases. It is subject to exactly the same biases and incentive structures as the rest of science. We should have the same careful, skeptical attitude when we interpret its results as we'd have for any other new field.
If there are real stakes for your reading of science, and you're trying earnestly to find the truth, then there's a whole suite of questions to consider both to select which publications to prioritize for your reading, and how to interpret what you find there. What is the mechanism of action? How much risk is there for a garden of forking paths? Do the researchers stand to benefit the most from getting a publication, or from finding the truth? Are the methods appropriate for the question at hand? How reputable is the source? Do you have enough background knowledge to interpret the object-level claims? Is this in the "hard" or the "soft" sciences?
As you build skill in reading science, and get plugged into the right recommendation networks, you'll gain more savvy for which of these questions are most important to address for any particular paper. If you read a lot, and ask good questions along the way, you'll stumble your way toward a more sophisticated understanding of the literature, and possibly even the truth!
↑ comment by TheMajor · 2021-07-20T18:52:33.850Z · LW(p) · GW(p)
I've upvoted you for the clear presentation. Most of the points you state are beliefs I held several years ago, and sounded perfectly reasonable to me. However, over time the track record of this view worsened and worsened, to the point where I now disagree not so much on the object level as with the assumption that this view is valuable to have. I hope you'll bear with me as I try to give explaining this a shot.
I think the first, major point of disagreement is that the target audience of a paper like this is the "level 1" readers. To me it seems like the target audience consists of scientists and science fans, most of whom already have a lot of faith in the accuracy of the scientific process. It is completely true that showing this piece to someone who has managed to work their way into an unreasonable belief can make it harder to escape that particular trap, but unfortunately that doesn't make it wrong. That's the valley of bad rationality [? · GW] and all that. In fact, I think that strongly supports my main original claim - there are so many ways of using sophisticated arguments to get to a wrong conclusion, and only one way to accurately tally up the evidence, that it takes skill and dedication to get to the right answer consistently.
I'm sorry to hear about your friend, and by all means try to keep them away from posts like this. If I understand correctly, you are roughly saying "Science is difficult and not always accurate, but posts like this overshoot on the skepticism. There is some value in trusting published peer-reviewed science over the alternatives, and this view is heavily underrepresented in this community. We need to acknowledge this to dodge the most critical of errors, and only then look for more nuanced views on when to place exactly how much faith in the statements researchers make." I hope I'm not misrepresenting your view here, this is a statement I used to believe sincerely. And I still think that science has great value, and published research is the most accurate source of information out there. But I no longer believe that this "level 2 view", extrapolating (always dangerous :P) from your naming scheme, is a productive viewpoint. I think the nuance that I would like to introduce is absolutely essential, and that conflating different fields of research or even research questions within a field under this umbrella does more harm than good. In other words, I would like to discuss the accuracy of modern science with the understanding that this may apply to smaller or larger degree to any particular paper, exactly proportional to the hypothetical universe-separating ability of the data I introduced earlier. I'm not sure if I should spell that out in great detail every couple of sentences to communicate that I am not blanket arguing against science, but rather comparing science-as-practiced with truthfinding-in-theory and looking for similarities and differences on a paper-by-paper basis.
Most critically, I think the image of 'overshooting' or 'undershooting' trust in papers in particular or science in general is damaging to the discussion. Evaluating the accuracy of inferences is a multi-faceted problem. In some sense, I feel like you are pointing out that if we are walking in a how-much-should-I-trust-science landscape, to a lot of people the message "it's really not all it's cracked up to be" would be moving further away from the ideal point. And I agree. But simultaneously, I do not know of a way to get close (not "help the average person get a bit closer", but get really close) to the ideal point without diving into this nuance. I would really like to discuss in detail what methods we have for evaluating the hard work of scientists to the best of our ability. And if some of that, taken out of context, forms an argument in the arsenal of people determined to metaphorically shoot their own foot off that is a tragedy but I would still like to have the discussion.
As an example, in your quote block I love the first paragraph but think the other 4 are somewhere between irrelevant and misleading. Yes, this discussion will not be a panacea to the replication crisis, and yes, without prior experience comparing crackpots to good sources you may well go astray on many issues. Despite all that, I would still really like to discuss how to evaluate modern science. And personally I believe that we are collectively giving it more credit than it deserves, which is spread in complicated ways between individual claims, research topics and entire fields of science.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-07-20T23:41:44.262Z · LW(p) · GW(p)
I pulled out statements of your positive statements and beliefs, and give my response to each.
- To me it seems like the target audience consists of scientists and science fans, most of whom already have a lot of faith in the accuracy of the scientific process.
This makes sense as a target audience, and why you'd place a difference emphasis than I do in addressing them.
- There are so many ways of using sophisticated arguments to get to a wrong conclusion, and only one way to accurately tally up the evidence, that it takes skill and dedication to get to the right answer consistently.
Agreed.
- I think the nuance that I would like to introduce is absolutely essential, and that conflating different fields of research or even research questions within a field under this umbrella does more harm than good. In other words, I would like to discuss the accuracy of modern science with the understanding that this may apply to smaller or larger degree to any particular paper, exactly proportional to the hypothetical universe-separating ability of the data I introduced earlier.
So it sounds like you agree with my point that the appropriate confidence level in particular findings and theories may vary widely across publication types and fields. You just want to make the general point that you can't trust everything you read, with the background understanding that sometimes this is more important, and sometimes less. So our points are, at least here, a matter of where we wish to place emphasis?
- I feel like you are pointing out that if we are walking in a how-much-should-I-trust-science landscape, to a lot of people the message "it's really not all it's cracked up to be" would be moving further away from the ideal point. And I agree.
Agreed.
- I would really like to discuss in detail what methods we have for evaluating the hard work of scientists to the best of our ability.
My interpretation of this is that you want to have a discussion focused on "what methods do we have for figuring out how accurate published scientific findings are?" without worry about how this might get misinterpreted by somebody who already has too little trust in science. Is that right?
- I would still really like to discuss how to evaluate modern science. And personally I believe that we are collectively giving it more credit than it deserves, which is spread in complicated ways between individual claims, research topics and entire fields of science.
This seems like a really odd claim to me, depending crucially on who you mean by "we." Again, if you mean science enthusiasts, then OK, that makes sense. If you mean, say, the first-world public, then I'd point out that two big persistent stories these days are the anti-vax people and climate change skeptics. But my guess is that you mean the former, and I agree with you that I have had a fair number of frustrating discussions with somebody who thinks the responsible position is to swallow scientific studies in fields like nutrition and psychology hook, line, and sinker.
Even if we set aside my concerns about how an audience with low trust in science might interpret this stuff, I still think that my points stand. We should be careful about extrapolation, and read these studies with the same general skepticism we should be applying to other studies. That might seem "misleading and irrelevant" to you, but I really don't understand why. They're good basic reminders for any discussion of science.
Replies from: TheMajor↑ comment by TheMajor · 2021-07-21T09:29:41.669Z · LW(p) · GW(p)
I agree with your reading of my points 1,2,4 and 5 but think we are not seeing eye to eye on points 3 and 6. It also saddens me that you condensed the paragraph on how I would like to view the how-much-should-we-trust-science landscape to its least important sentence (point 4), at least from my point of view.
As for point 3, I do not want to make a general point about the reliability of science at all. I want to discuss what tools we have to evaluate the accuracy of any particular paper or claim, so that we can have more appropriate confidence across the board. I think this is the most important discussion regardless of whether it increases or decreases general confidence. In my opinion, attempting to give a 0th-order summary by discussing the average change in confidence from this approach is doing more harm than good. The sentence "You just want to make the general point that you can't trust everything you read, with the background understanding that sometimes this is more important, and sometimes less." is exactly backwards from what I am trying to say.
For point 6, I think it might be very relevant to point out that I'm European, and the anti-vax and global warming denialism really is not that popular around where I live. They are more considered stereotypes of being untrustworthy than properly held beliefs, thankfully. But ignoring that, I think that most of the people influencing social policy and making important decisions are leaning heavily on science, and unfortunately particularly on the types of science I have the lowest confidence in. I was hoping to avoid going into great detail on this, but as short summary I think it is reasonable to be less concerned with the accuracy of papers that have low (societal) impact and more concerned with papers that have high impact. If you randomly sample a published paper on Google Scholar or whatever I'll happily agree that you are likely to find an accurate piece of research. But this is not an accurate representation of how people encounter scientific studies in reality. I see people break the fourth virtue [LW · GW] all the way from coffeehouse discussions to national policy debates, which is so effective precisely because the link between data and conclusion is murky. So a lot of policy proposals can be backed by some amount of references. Over the past few years my attempts to be more even have led me to strongly decrease my confidence in a large number of scientific studies, if only to account for the selection effect that these, and not others, were brought to my attention.
Also I think psychology and nutrition are doing a lot better than they were a decade or two ago, which I consider a great sign. But that's more of an aside than a real point.
Replies from: AllAmericanBreakfast↑ comment by DirectedEvolution (AllAmericanBreakfast) · 2021-07-21T20:15:20.947Z · LW(p) · GW(p)
This makes a lot of sense, actually. You're focused on mechanisms that a good thinker could use to determine whether or not a particular scientific finding is true or not. I'm worried about the ways that the conversation around skepticism can and does go astray.
Perhaps I read some of the quotes from the papers uncharitably. Silberzahn asks "What if scientific results are highly contingent on subjective decisions at the analysis stage?" I interpreted this question, in conjunction with the paper's conclusion, as pointing to a line of thinking that goes something like this:
- What if scientific results are highly contingent on subjective decisions at the analysis stage?
- Some scientific results are highly contingent on subjective decisions at the analysis stage.
- What if ALL scientific results are highly contingent on subjective decisions at the analysis stage across the board???!!!
But a more charitable version for the third step is:
3. This method helped us uncover one such case, and might help us uncover more. Also, it's a reminder to avoid overconfidence in published research, especially in politically charged and important issues where good evidence is hard to come by.
I spent the last ten years teaching children, and so my default mode is one of "educating the young and naive to be a little more sophisticated." Part of my role was to sequence and present ideas with care in order to increase the chance that an impressionable and naive young mind absorbed the healthy version of an idea, rather than a damaging misinterpretation. Maybe that informs the way I perceive this debate.
Replies from: TheMajorcomment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-21T11:53:28.332Z · LW(p) · GW(p)
In both the study of soccer players and the one on immigration, participating researchers reported their beliefs before doing their analysis. In both cases there wasn’t a statistically significant correlation between prior beliefs and reported results.
What? No way! ... are you sure? This seems to be evidence that confirmation bias isn't a thing, at least not for scientists analyzing data. But that conclusion is pretty surprising and implausible. Is there perhaps another explanation? E.g. maybe the scientists involved are a particularly non-bias-prone bunch, or maybe they knew why they were being asked to report their beliefs so they faked that they didn't have an opinion one way or another when really they did?
This is fascinating, thanks!
comment by ShardPhoenix · 2021-07-21T06:37:09.182Z · LW(p) · GW(p)
If two groups come up with different estimates, that's one thing - if they come up with different estimates with wildly non-overlapping error bars (as in some of these examples) that suggests that there's a problem of overconfidence. Perhaps the reported error bars should be much bigger for this kind of research - though I wouldn't know how to quantify that.
comment by Thoroughly Typed · 2021-07-20T16:35:50.595Z · LW(p) · GW(p)
In economics (and I’m sure in many other fields - I’m just writing about what I know here), something like this is supposedly done in the “robustness checks” section of a paper.
Machine learning sometimes has ablation studies, where you remove various components of your system and rerun everything. To figure out whether the fancy new layer you added actually contributes to the overall performance.