A utility-maximizing varient of AIXI
post by AlexMennen · 2012-12-17T01:12:19.518Z · LW · GW · Legacy · 0 commentsBackground
Here is the function implemented by finite-lifetime [AI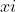](http://www.hutter1.net/ai/aixigentle.pdf):
\+\.\.\.\+r\\left\(x\_\{m\}\\right\)\\right\)\\cdot\\xi\\left\(\\dot\{y\}\\dot\{x\}\_\{%3Ck\}y\\underline\{x\}\_\{k:m\}\\right\)\}),
where 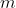 is the number of steps in the lifetime of the agent, 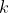
is the current step being computed, 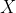 is the set of possible observations,
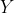 is the set of possible actions,  is a function that extracts
a reward value from an observation, a dot over a variable represents
that its value is known to be the true value of the action or observation
it represents, underlines represent that the variable is an input
to a probability distribution, and 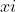 is a function that returns
the probability of a sequence of observations, given a certain known
history and sequence of actions, and starting from the Solomonoff
prior. More formally,
=\\left\(\\sum\_\{q\\in%20Q:q\\left\(y\_\{\\leq%20m\}\\right\)=x\_\{\\leq%20m\}\}2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\diagup\\left\(\\sum\_\{q\\in%20Q:q\\left\(\\dot\{y\}\_\{%3Ck\}\\right\)=\\dot\{x\}\_\{%3Ck\}\}2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\}),
where 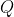 is the set of all programs, 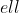 is a function that
returns the length of a program in bits, and a program applied to
a sequence of actions returns the resulting sequence of observations.
Notice that the denominator is a constant, depending only on the already
known , and multiplying by a positive constant
does not change the argmax, so we can pretend that the denominator
doesn't exist. If 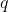 is a valid program, then any longer program
with 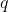 as a prefix is not a valid program, so \}\\leq1\}).
Problem
A problem with this is that it can only optimize over the input it
receives, not over aspects of the external world that it cannot observe.
Given the chance, AI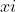 would hack its input channel so that it
would only observe good things, instead of trying to make good things
happen (in other words, it would [wirehead](http://lesswrong.com/lw/fkx/a\_definition\_of\_wireheading/)
itself). Anja [specified](http://lesswrong.com/lw/feo/universal\_agents\_and\_utility\_functions/)
a variant of AI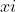 in which she replaced the sum of rewards with
a single utility value and made the domain of the utility function
be the entire sequence of actions and observations instead of a single
observation, like so:
\\cdot\\xi\\left\(\\dot\{y\}\\dot\{x\}\_\{%3Ck\}y\\underline\{x\}\_\{k:m\}\\right\)\}).
This doesn't really solve the problem, because the utility function
still only takes what the agent can see, rather than what is actually
going on outside the agent. The situation is a little better because
the utility function also takes into account the agent's actions,
so it could punish actions that look like the agent is trying to wirehead
itself, but if there was a flaw in the instructions not to wirehead,
the agent would exploit it, so the incentive not to wirehead would
have to be perfect, and this formulation is not very enlightening
about how to do that.
Solution
Here's what I suggest instead: everything that happens is determined
by the program that the world is running on and the agent's actions,
so the domain of the utility function should be .
The apparent problem with that is that the formula for AI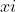 does
not contain any mention of elements of 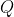. If we just take the original
formula and replace \+\.\.\.\+r\\left\(x\_\{m\}\\right\))
with ), it wouldn't make any
sense. However, if we expand out 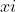 in the original formula (excluding
the unnecessary denominator), we can move the sum of rewards inside
the sum over programs, like this:
=x\_\{\\leq%20m\}\}\\left\(r\\left\(x\_\{k\}\\right\)\+\.\.\.\+r\\left\(x\_\{m\}\\right\)\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
Now it is easy to replace the sum of rewards with the desired utility
function.
=x\_\{\\leq%20m\}\}U\\left\(q,\\dot\{y\}\_\{%3Ck\}y\_\{k:m\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
With this formulation, there is no danger of the agent wireheading,
and all 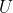 has to do is compute everything that happens when the
agent performs a given sequence of actions in a given program, and
decide how desirable it is. If the range of 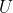 is unbounded, then
this might not converge. Let's assume throughout this post that the
range of 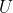 is bounded.
Extension to infinite lifetimes
The previous discussion assumed that the agent would only have the
opportunity to perform a finite number of actions. The situation gets
a little tricky when the agent is allowed to perform an unbounded
number of actions. Hutter uses a finite look-ahead approach for AI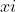,
where on each step 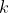, it pretends that it will only be performing
 actions, where .
\+\.\.\.\+r\\left\(x\_\{m\_\{k\}\}\\right\)\\right\)\\cdot\\xi\\left\(\\dot\{y\}\\dot\{x\}\_\{%3Ck\}y\\underline\{x\}\_\{k:m\_\{k\}\}\\right\)\}).
If we make the same modification to the utility-based variant, we
get
=x\_\{\\leq%20m\_\{k\}\}\}U\\left\(q,\\dot\{y\}\_\{%3Ck\}y\_\{k:m\_\{k\}\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
This is unsatisfactory because the domain of 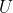 was supposed to
consist of all the information necessary to determine everything that
happens, but here, it is missing all the actions after step .
One obvious thing to try is to set . This will be
easier to do using a compacted expression for AI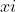:
=\\dot\{y\}\_\{%3Ck\}y\_\{k\}\}\\sum\_\{q\\in%20Q:q\\left\(\\dot\{y\}\_\{%3Ck\}\\right\)=\\dot\{x\}\_\{%3Ck\}\}\\left\(r\\left\(x\_\{k\}%5E\{pq\}\\right\)\+\.\.\.\+r\\left\(x\_\{m\_\{k\}\}%5E\{pq\}\\right\)\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}),
where  is the set of policies that map sequences of observations
to sequences of actions and  is shorthand for the last
observation in the sequence returned by \\right\)).
If we take this compacted formulation, modify it to accommodate the
new utility function, set , and replace the maximum
with a supremum (since there's an infinite number of possible policies),
we get
=\\dot\{y\}\_\{%3Ck\}y\_\{k\}\}\\sum\_\{q\\in%20Q:q\\left\(\\dot\{y\}\_\{%3Ck\}\\right\)=\\dot\{x\}\_\{%3Ck\}\}U\\left\(q,\\dot\{y\}\_\{%3Ck\}y\_\{k\}y\_\{k\+1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}),
where  is shorthand for the last action in the sequence
returned by \\right\)).
But there is a problem with this, which I will illustrate with a toy
example. Suppose , and =0)
when , and for any ,
=1\-\\frac\{1\}\{n\}) when  and
. (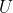 does not depend on the program 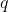
in this example). An agent following the above formula would output
 on every step, and end up with a utility of , when it could
have gotten arbitrarily close to 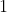 by eventually outputting 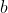.
To avoid problems like that, we could assume the reasonable-seeming
condition that if  is an action sequence and 
is a sequence of action sequences that converges to 
(by which I mean ),
then =U\\left\(q,y\_\{1:\\infty\}\\right\)\}).
Under that assumption, the supremum is in fact a maximum, and the
formula gives you an action sequence that will reach that maximum
(proof below).
If you don't like the condition I imposed on 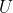, you might not be
satisfied by this. But without it, there is not necessarily a best
policy. One thing you can do is, on step 1, pick some extremely small
, pick any element from 2%5E\{\-\\ell\\left\(q\\right\)\}%3E\\left\(\\sup\_\{p\\in%20P\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\-\\varepsilon\\right\\\}%20\}),
and then follow that policy for the rest of eternity, which will guarantee
that you do not miss out on more than 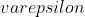 of expected utility.
Proof of criterion for supremum-chasing working
definition: If  is an action sequence and 
is an infinite sequence of action sequences, and ,
then we say  converges
to . If 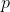 is a policy and 
is a sequence of policies, and =p\_\{n\}\\left\(x\_\{%3Ck\}\\right\)),
then we say  converges to
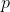.
assumption (for lemma 2 and theorem): If 
converges to , then =U\\left\(q,y\_\{1:\\infty\}\\right\)\})
lemma 1: The agent described by =\\dot\{y\}\_\{%3Ck\}y\_\{k\}\}\\sum\_\{q\\in%20Q:q\\left\(\\dot\{y\}\_\{%3Ck\}\\right\)=\\dot\{x\}\_\{%3Ck\}\}U\\left\(q,\\dot\{y\}\_\{%3Ck\}y\_\{k\}y\_\{k\+1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\})
follows a policy that is the limit of a sequence of policies 
such that 2%5E\{\-\\ell\\left\(q\\right\)\}=\\sup\_\{p\\in%20P\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
proof of lemma 1: Any policy can be completely described by the last
action it outputs for every finite observation sequence. Observations
are returned by a program, so the set of possible finite observation
sequences is countable. It is possible to fix the last action returned
on any particular finite observation sequence to be the argmax, and
still get arbitrarily close to the supremum with suitable choices
for the last action returned on the other finite observation sequences.
By induction, it is possible to get arbitrarily close to the supremum
while fixing the last action returned to be the argmax for any finite
set of finite observation sequences. Thus, there exists a sequence
of policies approaching the policy implemented by AI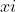 whose expected
utilities approach the supremum.
lemma 2: If 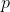 is a policy and 
is a sequence of policies converging to 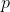, then 2%5E\{\-\\ell\\left\(q\\right\)\}=\\lim\_\{n\\rightarrow\\infty\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{n\}q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
proof of lemma 2: Let . On any given sequence of inputs
, \\right\\\}%20\_\{n=1\}%5E\{\\infty\})
converges to ), so, by assumption, \-U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{n\}q\}\\right\)\\right|%3C\\frac\{\\varepsilon\}\{2\}).
For each , let \-U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{n\}q\}\\right\)\\right|%3C\\frac\{\\varepsilon\}\{2\}\\right\\\}%20).
The previous statement implies that ,
and each element of  is
a subset of the next, so \}%3C\\frac\{\\varepsilon\}\{2\\left\(\\sup%20U\-\\inf%20U\\right\)\}\}).
The range of 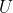 is bounded, so 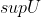 and 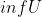 are defined.
This also implies that the difference in expected utility, given any
information, of any two policies, is bounded. More formally: 2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\diagup\\left\(\\sum\_\{q\\in%20Q'\}2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right\)\-\\left\(\\left\(\\sum\_\{q\\in%20Q'\}U\\left\(q,y\_\{1:\\infty\}%5E\{p''q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\diagup\\left\(\\sum\_\{q\\in%20Q'\}2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right\)\\right|\\leq\\sup%20U\-\\inf%20U\}),
so in particular, 2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\-\\left\(\\sum\_\{q\\in%20Q\\setminus%20Q\_\{N\}\}U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{N\}q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right|\\leq\\left\(\\sup%20U\-\\inf%20U\\right\)\\sum\_\{q\\in%20Q\\setminus%20Q\_\{N\}\}2%5E\{\-\\ell\\left\(q\\right\)\}%3C\\frac\{\\varepsilon\}\{2\}\}).
2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\-\\left\(\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{N\}q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right|\\leq\\left|\\left\(\\sum\_\{q\\in%20Q\_\{N\}\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\-\\left\(\\sum\_\{q\\in%20Q\_\{N\}\}U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{N\}q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right|\+\\left|\\left\(\\sum\_\{q\\in%20Q\\setminus%20Q\_\{N\}\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\-\\left\(\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{p\_\{N\}q\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\\right\)\\right|%3C\\frac\{\\varepsilon\}\{2\}\+\\frac\{\\varepsilon\}\{2\}=\\varepsilon\}).
theorem: 2%5E\{\-\\ell\\left\(\\dot\{q\}\\right\)\}=\\sup\_\{p\\in%20P\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}),
where, =\\dot\{y\}\_\{%3Ck\}y\_\{k\}\}\\sum\_\{q\\in%20Q:q\\left\(\\dot\{y\}\_\{%3Ck\}\\right\)=\\dot\{x\}\_\{%3Ck\}\}U\\left\(q,\\dot\{y\}\_\{%3Ck\}y\_\{k\}y\_\{k\+1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
proof of theorem: Let's call the policy implemented by the agent .
By lemma 1, there is a sequence of policies 
converging to  such that 2%5E\{\-\\ell\\left\(q\\right\)\}=\\sup\_\{p\\in%20P\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
By lemma 2, 2%5E\{\-\\ell\\left\(q\\right\)\}=\\sup\_\{p\\in%20P\}\\sum\_\{q\\in%20Q\}U\\left\(q,y\_\{1:\\infty\}%5E\{pq\}\\right\)2%5E\{\-\\ell\\left\(q\\right\)\}\}).
0 comments
Comments sorted by top scores.