Cross-Validation vs Bayesian Model Comparison
post by johnswentworth · 2019-07-21T18:14:34.207Z · LW · GW · 2 commentsContents
Biased/Unbiased Die Simulation Different Questions Prediction vs Understanding Conclusion? None 2 comments
Suppose we need to predict the outcomes of simulated dice rolls as a project for a machine learning class. We have two models: an "unbiased" model, which assigns equal probability to all outcomes, and a "biased" model, which learns each outcome frequency from the data.
In a machine learning class, how would we compare the performance of these two models?
We'd probably use a procedure like this:
- Train both models on the first 80% of the data (although training is trivial for the first model).
- Run both models on the remaining 20%, and keep whichever one performs better.
This method is called cross-validation (along with its generalizations). It's simple, it's intuitive, and it's widely-used.
So far in this sequence [? · GW], we've talked about Bayesian model comparison [? · GW]: to compare two models, calculate the posterior for each model. How do cross-validation and Bayesian model comparison differ?
Biased/Unbiased Die Simulation
Let's run a simulation. We'll roll a 100-sided die N times, using both a biased die and an unbiased die. We'll apply both cross-validation and Bayesian model comparison to the data, and see which model each one picks. Specifics:
- We'll use N-fold cross-validation with log likelihood loss: for each data point , we learn the maximum-likelihood parameters based on all data except . To get the a final metric, we then sum log likelihood over all points:
- For Bayesian model comparison, we'll compute for an unbiased model, and a model with uniform prior on the biases, just like we did for Wolf's Dice [? · GW]
- The simulated biased die has probability 1/200 on half the faces and 3/200 on the other half
We'll plot the difference in score/evidence/whatever-you-want-to-call-it assigned to each model by each method, as the number of data points N ranges from 1 up to 10000.
Here are the results from one run:
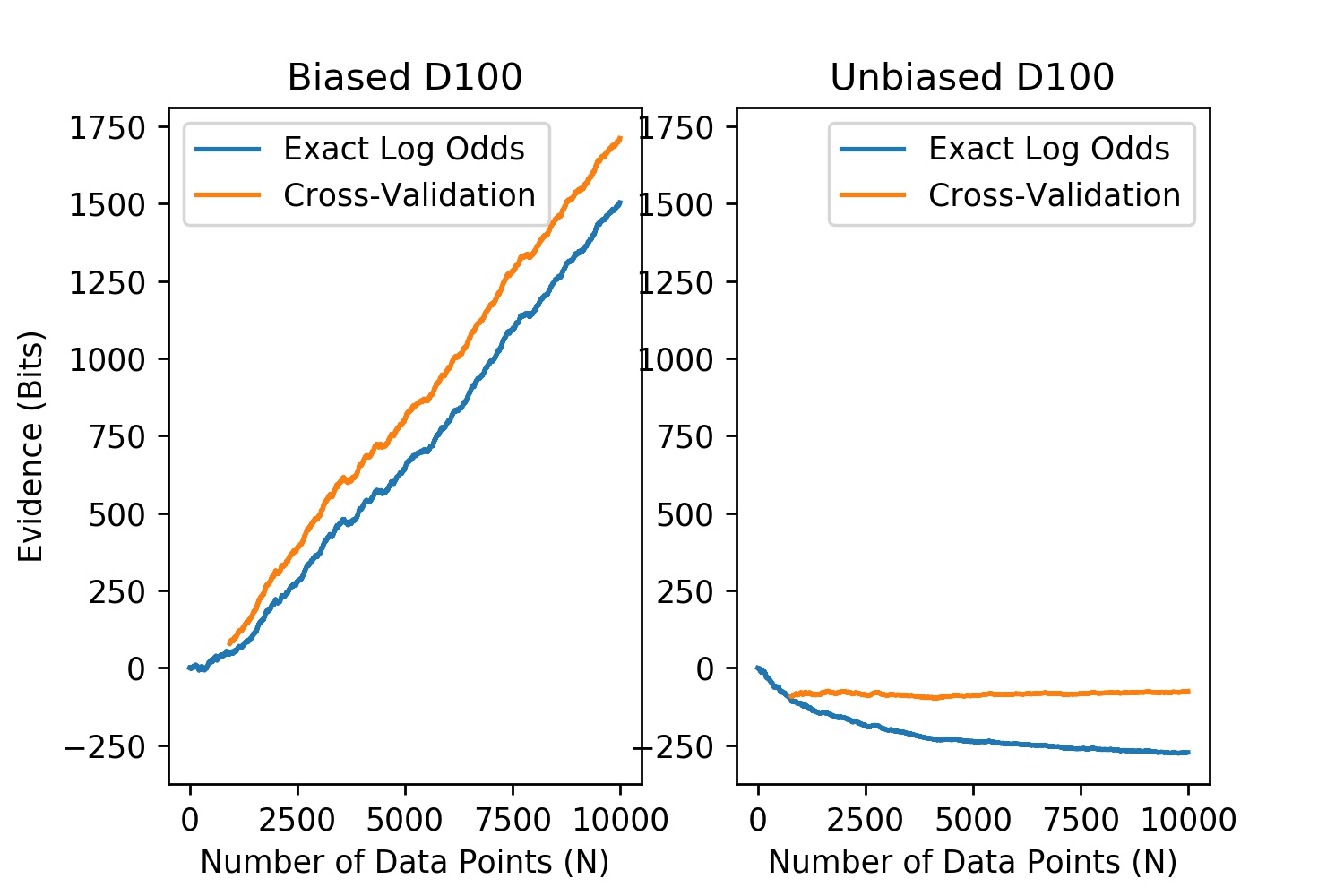
First and most important: both cross-validation and Bayesian model comparison assign more evidence to the biased model (i.e. line above zero) when the die is biased, and more evidence to the unbiased model (i.e. line below zero) when the die is unbiased.
The most striking difference between the methods is in the case of an unbiased die: Bayesian model comparison assigns lower and lower probability to the biased model, whereas cross-validation is basically flat. In theory, as , the cross-validation metric will be random with roughly zero mean.
Why the difference? Because cross-validation and Bayesian model comparison answer different questions.
Different Questions
Compare:
- Cross-validation: how accurately will this model predict future data gathered the same way?
- Bayesian: How likely is this model given the data? Or equivalently, via Bayes' rule: how well does this model predict the data we've seen?
So one is asking how well the model can predict future data, while the other is asking how well the model predicted past data. To see the difference, think about the interesting case from the simulation: biased vs unbiased model running on data from an unbiased die. As , the biased model learns the true (unbiased) frequencies, so the two models will make the same predictions going forward. With the same predictions, cross-validation is indifferent.
For cross-validation purposes, a model which gave wrong answers early but eventually learned the correct answers is just as good as a model which gave correct answers from the start.
If all we care about is predicting future data, then we don't really care whether a model made correct predictions from the start or took a while to learn. In that case, cross-validation works great (and it's certainly much computationally easier than the Bayesian method). On the other hand, if one model made correct predictions from the start and the other took a long time to learn, then that's Bayesian evidence in favor of the model which was correct from the start.
That difference becomes important in cases like Wolf's Dice II [? · GW], where we wanted to deduce the physical asymmetries of a die. In that case, the fully-general model and our final model both make the same predictions about future rolls once they have enough data. But they differ on predictions about what the world looks like aside from the data itself - for instance, they make different predictions about what we would find if we took out some calipers and actually measured the dimensions of Wolf's white die.
Prediction vs Understanding
Years ago, while working in the lab of a computational biologist, he and I got into an argument about the objective of "understanding". I argued that, once some data can be predicted, there is nothing else left to understand about it. Whether it's being predicted by a detailed physical simulation or a simple abstract model or a neural network is not relevant.
Today, I no longer believe that.
Wolf's Dice II [? · GW] is an excellent counter-example which highlights the problem. If two models always make the same predictions about everything, then sure, there's no important difference between them. But don't confuse "make the same predictions about everything" with "make the same predictions about the data" or "make the same predictions about future data of this form". Even if two models eventually come to the exact same conclusion about the outcome distribution from rolls of a particular die, they can still make different predictions about the physical properties of the die itself.
If two models make different predictions about something out in the world, then it can be useful to evaluate the probabilities of the two models - even if they make the same predictions about future data of the same form as the training data.
Physical properties of a die are one example, but we can extend this to e.g. generalization problems. If we have models which make similar predictions about future data from the training distribution, but make different predictions more generally, then we can apply Bayesian model comparison to (hopefully) avoid generalization error. Of course, Bayesian model comparison is not a guarantee against generalization problems - even in principle it can only work if there's any generalization-relevant evidence in the data at all. But it should work in almost any case where cross-validation is sufficient, and many other cases as well. (I'm hedging a bit with "almost any"; it is possible for cross-validation to "get lucky" and outperform sometimes, but that should be rare as long as our priors are reasonably accurate.)
Conclusion?
In summary:
- Cross-validation tells us how well a model will predict future data of the same form as the training data. If that's all you need to know, then use cross-validation; it's much easier computationally than Bayesian model comparison.
- Bayesian model comparison tells us how well a model predicted past data, and thus the probability of the model given the data. If want to evaluate models which make different predictions about the world even if they converge to similar predictions about future data, then use Bayesian model comparison.
One final word of caution unrelated to the main point of this post. One practical danger of cross-validation is that it will overfit if we try to compare too many different models. As an extreme example, imagine using one model for every possible bias of a coin - a whole continuum of models. Bayesian model comparison, in that case, would simply yield the posterior distribution of the bias; the maximum-posterior model would likely be overfit (depending on the prior), but the full distribution would be correct. This is an inherent danger of maximization as an epistemic technique: it's always an approximation to the posterior, so it will fail whenever the posterior isn't dominated by the maximal point.
2 comments
Comments sorted by top scores.
comment by Pattern · 2019-07-22T02:27:03.031Z · LW(p) · GW(p)
Even if two models eventually come to the exact same conclusion about the outcome distribution from rolls of a particular die, they can still make different predictions about the physical properties of the die itself.
That's surprising. I thought the "biased coins model" would come to agree with the "unbiased coins model" by converging (close) to the same (uniform) distribution.
Replies from: johnswentworth↑ comment by johnswentworth · 2019-07-22T05:44:35.561Z · LW(p) · GW(p)
They do converge to the same distribution. But they make different predictions about a physical die: the unbiased model predicts uniform outcomes because the die is physically symmetric, whereas the general biased model doesn't say anything about the geometry of a physical die. So if I see uniform outcomes from a physical die, then that's Bayesian evidence that the die is physically symmetric.
See Wolf's Dice II [LW · GW] for more examples along these lines.