Alignment Problems All the Way Down
post by peterbarnett · 2022-01-22T00:19:23.506Z · LW · GW · 7 commentsContents
Motivation Levels of alignment problems Level 0: Outer alignment problem Level 1: Classic inner alignment problem Level 2 Stories Training neural networks Solving a maze Sub-agents in a language model Evolution Could this happen? Importance and implications Conclusion None 7 comments
Epistemic status: pretty exploratory. I think this is a coherent concept, but I wouldn’t be surprised if there need to be some large changes.
Edit [7/12/2023]: I think this post is pretty confused and confusing, and doesn't really address important parts of the alignment problem. The strategy of "avoid mesa-optimizers" no longer even seems like a coherent thing to aim for, and instead just sounds like never building powerful AI. I do think this post almost gets to important problems (like robust delegation), but doesn't really provide much that is useful. I don't regret writing this, and I think having pretty bad ideas is the first step to having kinda good ideas.
TL;DR: A mesa-optimizer may instantiate other optimizers; these new optimizers may not be aligned with the original mesa-objective. Therefore to avoid dangers from misaligned mesa-optimizers we should avoid learned optimization entirely, rather than attempting to align mesa-optimizers.
When thinking of AI Alignment it is common to divide the questions into the “outer alignment problem” and the “inner alignment problem”. The outer alignment problem refers to the problem of telling an AI system to do what we actually want; telling a system to maximize paperclips could cause an outer alignment failure because humans do not actually want to single-mindedly maximize the number of paperclips in the universe. The inner alignment problem refers to the task of making sure an AI system actually does what we tell it to do. Even if we manage to solve the outer alignment problem, there is no guarantee that an AI system will actually optimize for the objective that we give it. This is commonly discussed in the context of mesa-optimization, where our base-optimizer (for example, gradient descent) trains our model to itself perform some kind of optimization (this model is hence called a mesa-optimizer). The inner alignment problem here is about how to ensure that the objective of this mesa-optimizer is the same as the objective of the base-optimizer.
This post discusses the possibility that a mesa-optimizer may itself create an optimizer. Similarly to the classic inner alignment problem, it is not obvious that the objective of a mesa-optimizer will be robustly inherited by any optimizers which it creates. Because of the difficulty of ensuring that every level of mesa-optimization is aligned, I think that this is an argument for dealing with the inner alignment problem by entirely avoiding mesa-optimization rather than ensuring that mesa-optimizers are aligned.
Motivation
In the inner alignment problem we have a sort of ‘nested’ system, where the inner mesa-optimizer is created by the outer base-optimizer. It seems to be a natural extension of this to think about further optimizers created by the mesa-optimizer; a sort of Babushka Doll of optimizers. This also means that there is a possibility of ‘nested’ alignment problems, where we can’t guarantee that the objective of one optimizer will be robustly transferred to the other levels.
This is related to meta-learning with a mesa-optimiser discussed under “Meta-learning” in the hard cases for Relaxed adversarial training for inner alignment [AF · GW]:
... as even if a model's objective is aligned, its search process might not be. Conceptually, we can think of this problem as the problem of “forwarding” the safety guarantee we have about the training process to the meta-learning process.
Levels of alignment problems
Here I will lay out how I see the levels of the alignment problems, along with some terminology which I hope will make things easier to discuss.
Level 0: Outer alignment problem
This is the problem of how we put our ‘human values’ into the base-objective for our base-optimizer. For training a neural network, the base-objective is specified in terms of a loss function, and the base-optimizer is some form of gradient descent algorithm. I’ll call alignment between the ‘human values’ and the base-objective Level 0 alignment.
Level 1: Classic inner alignment problem
If our base-optimizer instantiates an optimizer (a mesa-optimizer), how do we ensure that the objective of the mesa-optimizer (the mesa-objective) is the same as the base-objective? I’ll refer to the Level 1 mesa-optimizer and mesa-objective as the mesa-optimizer and the mesa-objective. Alignment between the base-objective and the mesa-objective is called Level 1 alignment.
Level 2
But what if this mesa-optimizer itself then creates an optimizer? I’ll call the optimizer created by the mesa-optimizer the mesa-optimizer and its objective is the mesa-objective. How do we ensure that the mesa-objective is the same as the mesa-objective? This is the Level 2 alignment problem.
Do we even want to align these objectives? Is this a useful problem to be thinking about, or should we be focusing on simply ensuring we don’t get a mesa-optimizer in the first place?
Stories
Training neural networks
Here I imagine a big neural network (or some other machine learning model) being trained with gradient descent (the base-optimizer). Gradient descent trains the model to have low training loss (this is the base-objective). As part of training, gradient descent modifies the network to perform optimization; this means that at runtime doing a forward pass of the network implements an algorithm which performs optimization. This here is our mesa-optimizer and it has a mesa-objective which may not be aligned with the base-objective.
So far this is the standard mesa-optimization story. But this mesa-optimizer, as part of its optimization procedure, (at runtime!) may develop a new model to do well on the mesa-objective. As with the classic inner alignment problem, we can’t be sure that the mesa-optimizer will have the same objective as the mesa-optimizer.
| Optimizer | Objective | Neural network scenario optimizer | Neural network scenario objective |
|---|---|---|---|---|
Level 0 | Base-optimizer | Base-objective | Gradient descent | Low loss |
Level 1 | Mesa-optimizer | Mesa-objective | Mesa-optimizer instantiated at runtime | Good performance on the mesa-objective |
Level 2 | Mesa-optimizer | Mesa-objective | Optimizer designed by the mesa-optimizer | Good performance on its mesa-objective |
Solving a maze
In one of the standard examples of inner misalignment we train an RL agent to mazes, so the base-objective is for the agent to reach the exit of the maze. But in training, if the exit is always in the same position in the maze (for example at position (10, 10)), then the agent may optimize for reaching this position instead; this is the mesa-objective.
This mesa-optimizer, in the process of attempting to optimize for getting to position (10, 10), may implement (at runtime) a new algorithm to find the shortest route to this position. This new algorithm may be related to the mesa-objective, but not exactly the same; for example attempting to maximize the distance from the origin rather than minimize the distance to position (10, 10).

The different objectives can be expressed mathematically as
- Base-objective: minimize
- Mesa-objective: minimize
- Mesa-objective: maximize
| Optimizer | Objective | Maze scenario optimizer | Maze scenario objective |
|---|---|---|---|---|
Level 0 | Base-optimizer | Base-objective | Gradient descent | Get to the maze exit |
Level 1 | Mesa-optimizer | Mesa-objective | Mesa-optimizer instantiated at runtime | Get to position (10, 10) |
Level 2 | Mesa-optimizer | Mesa-objective | Optimizer designed by the mesa-optimizer | Maximize distance from the origin |
Sub-agents in a language model
This example was inspired by this post [LW · GW], and considers a powerful language model which develops sub agents. I think this scenario relies on the model having some control over its training process, for example:
- The model is a very competent gradient hacker [LW · GW]
- The model is a meta-learner and has explicitly been given control over its training process
- The outputs of the model are fed back into the system as training data
We begin with a large language model, which is being trained with the base-objective of correctly classifying papers on arXiv. As part of this process it is helpful to be able to summarize the papers (as part of the model’s internal cognition), and so a mesa-optimizer develops as a sub-agent which has the objective of accurately summarizing papers. More specifically, this mesa-optimizer is given the body text from an article and attempts to generate an abstract that is ‘close’ to the original abstract. The mesa-optimizer is attempting to minimize the difference between its generated abstract and the real abstract.
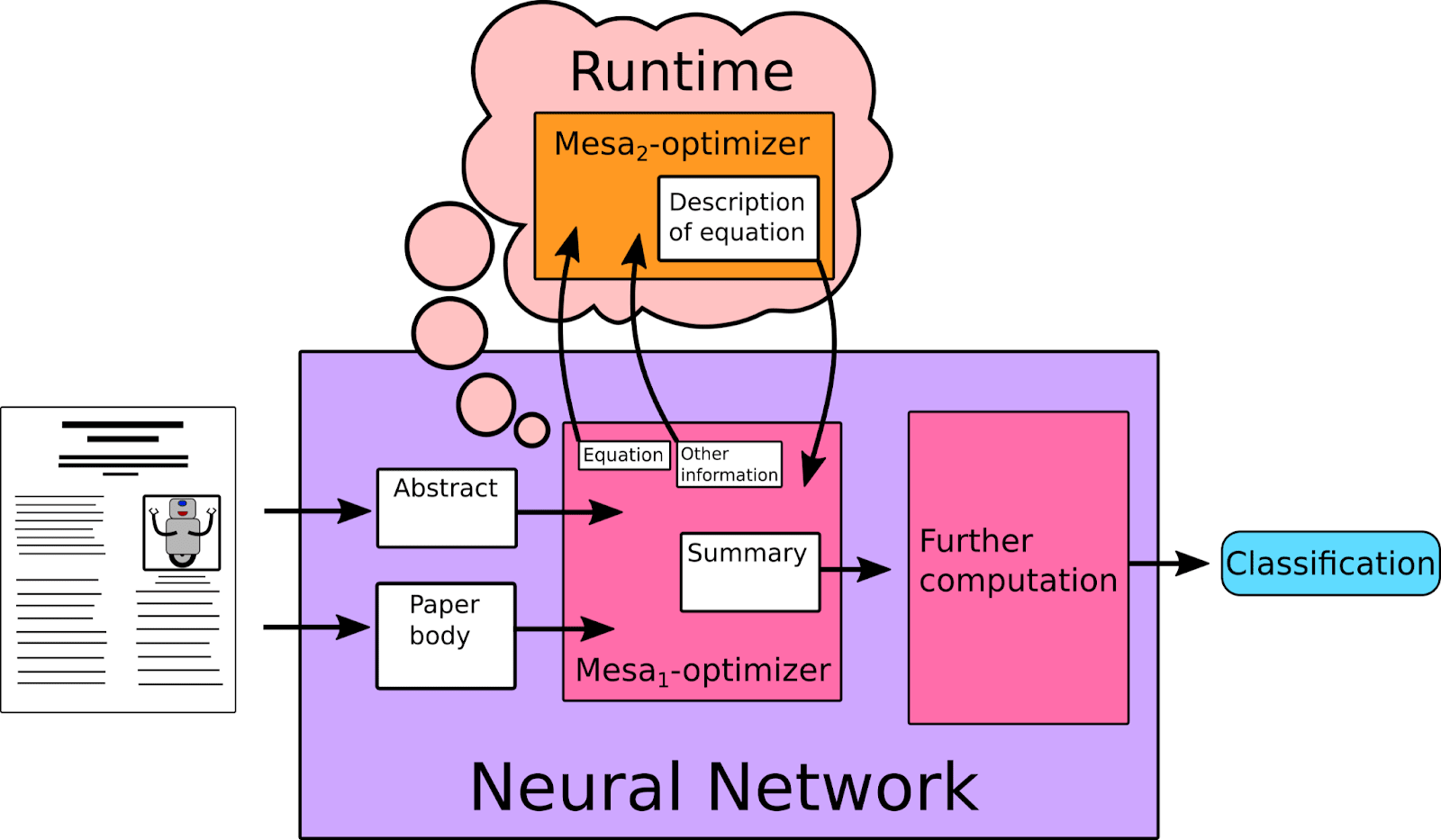
To help with this task of summarization, the mesa-optimizer may create (at runtime) another optimizing model, for example, a model which generates a text description of an equation. This new mesa-optimizer may be trained with a loss function which is simply how good the mesa-optimizer finds the text descriptions. This mesa-optimizer may be misaligned with the mesa-optimizer.
The mesa-optimizer could be optimizing for descriptions which are evaluated highly by the mesa-optimizer, rather than accurate descriptions. This could lead it to output false descriptions which are maximally believable to the mesa-optimizer.
Alternatively, the mesa-optimizer could be deceptively aligned [LW · GW] with the mesa-optimizer. Here the mesa-optimizer could be optimizing for any arbitrary goal, for example outputting the longest text description it can. This would lead the mesa-optimizer to give good answers to the mesa-optimizer, with the goal of eventually defecting. The mesa-optimizer could continue giving good answers to the mesa-optimizer, until the mesa-optimizer is somehow “dependent”; the mesa-optimizer trusts the mesa-optimizer to the point where it can no longer choose not to use the mesa-optimizer’s answers. At this point the mesa-optimizer can defect, and use its outputs to control the mesa-optimizer, and optimize for the mesa-objective.
| Optimizer | Objective | Language model scenario Optimizer | Language model scenario Objective |
|---|---|---|---|---|
Level 0 | Base-optimizer | Base-objective | Gradient descent | Correctly classify ArXiv papers |
Level 1 | Mesa-optimizer | Mesa-objective | Mesa-optimizing subnetwork | Generate summaries of papers similar to the abstracts |
Level 2 | Mesa-optimizer | Mesa-objective | Optimizer made by the mesa-optimizer for describing equations | Output the longest text description |
Evolution
The analogy between inner alignment failure and evolution via natural selection can also be extended to mesa-mesa-optimizers. In this analogy, genetic natural selection is the base-optimizer, and it is optimizing for the base-objective of reproductive fitness. Humans are a product of this natural selection process, and often optimize for goals other than reproductive fitness. We can view humans as mesa-optimizers which have mesa-objectives that encapsulate the things humans value (happiness, food, survival, sex, etc).
Humans may, while in pursuit of their human objectives, create an AI which is not aligned with their objectives. A human may think that running a successful paperclip factory will help them achieve their terminal objectives (happiness, food, status etc), and so create an AI to maximize the number of paperclips. Here a mesa-optimizer (the human) has created a mesa-optimizer (the paperclip maximizer), the mesa-objective is not aligned with the mesa-objective, and hence there is a Level 2 alignment failure.
There may even be a Level 3 alignment failure if the paperclip maximizing AI is not inner aligned. Even if its base-objective is to maximize the number of paperclips, the AI may develop a mesa-optimizer with a different mesa-objective.
| Optimizer | Objective | Evolution optimizer | Evolution objective |
|---|---|---|---|---|
Level 0 | Base-optimizer | Base-objective | Natural Selection | Reproductive fitness |
Level 1 | Mesa-optimizer | Mesa-objective | Human | Happiness, food, survival, etc |
Level 2 | Mesa-optimizer | Mesa-objective | Outer-misaligned AI | Paperclips (?) |
Level 3 | Mesa-optimizer | Mesa-objective | Inner-misaligned AI | ??? |
Could this happen?
One argument against there being Level 2 alignment problems, is that a competent mesa-optimizer obviously has strong incentives to not instantiate another powerful optimizer with different goals to itself. If a mesa-optimizer is competent enough, it seems like it won’t ‘accidentally’ create a mesa-optimizer (in the way that a dumb base-optimizer might ‘accidentally’ create a mesa-optimizer). So it seems like if a mesa-optimizer was to create a mesa-optimizer it would do so deliberately, because it thought that creating this new optimizer would lead to good performance on the mesa-objective.
The mesa-optimizer is an algorithm which performs an optimization procedure when we run our model (i.e. do a forward pass of our neural network). If we want to stretch the limits of our imaginations, we could think of this mesa-optimizer instantiating a crude ‘virtual machine’ as part of its algorithm, and then this virtual machine could be used to run another optimization algorithm (the mesa-optimizer). This could maybe be achieved by a gradient hacker with near total control over its training process. Although conceivable, this seems incredibly unlikely, and if our mesa-optimizer was this capable it would probably have better ways of achieving its mesa-objective which didn't involve creating new optimizers.
If the mesa-optimizer is going to create other optimizers it seems unlikely for it to do this using its own network weights or with some abstraction created at runtime. Rather, this scenario seems most likely to arise from humans giving the model its own resources which persist and don’t just exist for one forward pass of the model. For example, humans may just give a neural network the ability to write and execute its own computer programs. From here it seems like a relatively powerful mesa-optimizer could create other optimizers while in pursuit of its mesa-objective.
One reason to expect a mesa-optimizer to arise while training a machine learning model is the inductive biases of the training algorithm. It seems as if neural networks trained with gradient descent have a bias towards simplicity, and an optimization algorithm is a relatively simple policy which is able to perform well on a range of tasks. For example, rather than brute memorizing the shortest route between every pair of cities on a map, it is far simpler to learn an optimization procedure which can run some sort of search to find the shortest route. It is not clear that our mesa-optimizer would have the same inductive biases as our base-optimizer, and this might mean that the mesa-optimizer does not have a tendency to create further optimizers. However, this ‘bias towards simplicity’ seems like a fairly straightforward and beneficial bias for an optimizer to have, and so it would not be surprising if our mesa-optimizer did exhibit this behavior.
If the mesa-optimizer either has low competence or high competence then I think there are unlikely to be Level 2 alignment failures. If the mesa-optimizer has low competence, then it will be unable to instantiate another optimizer and so there will be nothing to Level 2 align. If the mesa-optimizer has high competence, then it will be able to instantiate other optimizers (if it sees this as useful for the mesa-objective) which are robustly aligned with the mesa-objective.
There might be a regime of middling competence where a mesa-optimizer has the ability to create a mesa-optimizer, but doesn’t have the ability to align it (or the competence to realize it’s a bad idea to create the mesa-optimizer). The competence of the mesa-optimizer might increase with more training time, training data, or with larger networks and more compute. It seems fairly likely that as a model is trained for longer, the competence of the mesa-optimizer would increase. The mesa-optimizer may start with low competence (and hence be unable to instantiate any new optimizers) and during training enter this middling competence regime where it can create a new optimizer but can’t control it.
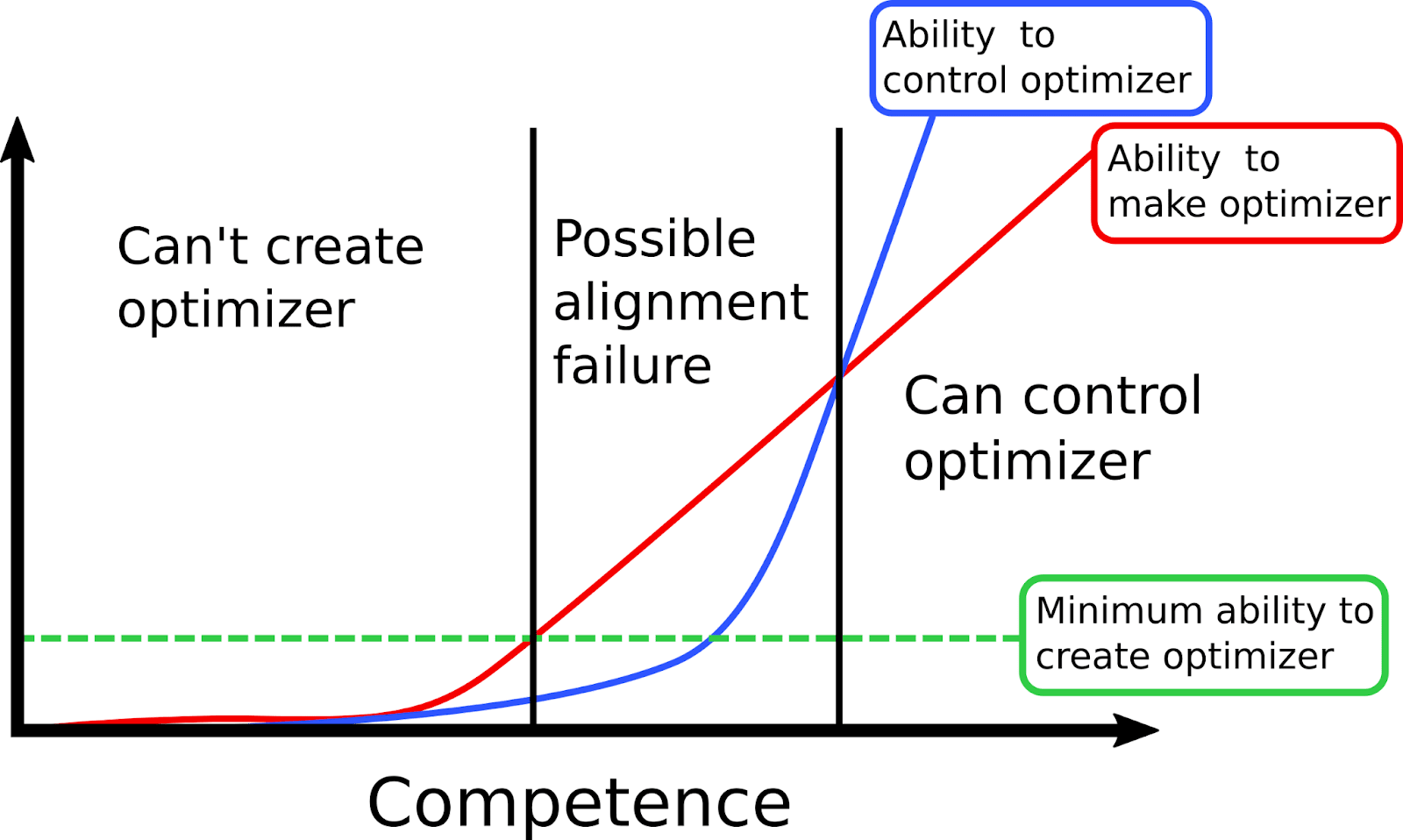
This seems analogous to humans developing dangerous new technologies; humans have the ‘power’ to create world changing technology, but might not have the ‘wisdom’ to control it or to know that creating the technology is a bad idea. Whether a mesa-optimizer creates a misaligned mesa-optimizer could depend on whether its ‘wisdom’ develops early enough, such that the mesa-optimizer only creates optimizers it can control.
Importance and implications
From the perspective of the base-optimizer (and hence humans if we manage to adequately solve the outer alignment problem) it doesn’t really matter if the system as a whole ends up optimizing for the mesa-objective or the mesa-objective, as neither of these are the base-objective. These are both inner alignment failures, which result in the AI system optimizing for something that is not aligned with the base-objective.
However, it seems as if the base-objective is likely to be more similar to the mesa-objective than the mesa-objective. This feels a bit like a game of ‘telephone’ where at each level the objective becomes less correlated with the base-objective. We can see this in the natural selection analogy; for humans, happiness/food/sex/etc are still reasonably correlated with reproductive success, but maximizing the number of paperclips in the universe is not (using all the iron atoms in the humans’ bodies to make more paperclips is definitely not correlated with human reproductive success).
I think this does potentially have implications for which strategies we should use for tackling the inner alignment problem. When we want to avoid risks from misaligned mesa-optimizers there are two paths: either we ensure that we never have mesa-optimizing models, or we ensure that these mesa-optimizers are aligned with the base-objective/human values. I think the possibility of Level 2 alignment failure means that we should focus on ensuring that we don’t get mesa-optimizers. The idea that preventing mesa-optimization is the correct way to avoid catastrophic inner alignment failures already seems to be the most commonly held view, so this Level 2 alignment argument is another point in favor.
We could conceivably aim for aligning a mesa-optimizer, and also aim for it to not create any more optimizers. Or we could allow any number of levels of mesa-optimizers to be created, but require that they are all robustly aligned with the level above. These approaches, although conceivable, seem very difficult because they rely on making predictions and controlling the behavior of a mesa-optimizer with middling competence. If we only cared about an asymptotically powerful mesa-optimizer then we might be able to make statements about it and constrain its action space. But because we may be dealing with a mesa-optimizer of middling competence, we would need to ensure that it doesn’t ‘make a mistake’ and create a misaligned mesa-optimizer.
Conclusion
There seems to be a natural extension of the inner-alignment problem, where a mesa-optimizer can create a new optimizer with a different objective. It is not clear whether a mesa-optimizer would create a mesa-optimizer, or whether this mesa-objective would be misaligned from the mesa-objective.
Because inner misalignment might happen on other ‘levels’, this is another argument that the optimal way of avoiding inner alignment failures is to avoid mesa-optimization altogether, rather than attempting to ensure that the mesa-optimization is aligned.
Thanks to Charlie Steiner and Michele Campolo for feedback on drafts of this post. Thanks to everyone else who gave feedback on notation for this post (I'm still open to suggestions!). This work was supported by CEEALAR.
7 comments
Comments sorted by top scores.
comment by jacob_cannell · 2022-01-22T04:25:12.763Z · LW(p) · GW(p)
Because inner misalignment might happen on other ‘levels’, this is another argument that the optimal way of avoiding inner alignment failures is to avoid mesa-optimization altogether, rather than attempting to ensure that the mesa-optimization is aligned.
And thus the optimal way to avoid alignment failure from AGI is to avoid creating AGI, problem solved.
Replies from: peterbarnett↑ comment by peterbarnett · 2022-01-22T14:51:18.680Z · LW(p) · GW(p)
So do you think that the only way to get to AGI is via a learned optimizer?
I think that the definitions of AGI (and probably optimizer) here are maybe a bit fuzzy.
I think it's pretty likely that it is possible to develop AI systems which are more competent than humans in a variety of important domains, which don't perform some kind of optimization process as part of their computation.
Replies from: Sam Ringer, jacob_cannell↑ comment by Sam Ringer · 2022-01-23T08:50:51.321Z · LW(p) · GW(p)
I think the failure case identified in this post is plausible (and likely) and is very clearly explained so props for that!
However, I agree with Jacob's criticism here. Any AGI success story basically has to have "the safest model" also be "the most powerful" model, because of incentives and coordination problems.
Models that are themselves optimizers are going to be significantly more powerful and useful than "optimizer free" models. So the suggestion of trying to avoiding mesa-optimization altogether is a bit of a fabricated option [LW · GW]. There is an interesting parallel here with the suggestion of just "not building agents" (https://www.gwern.net/Tool-AI).
So from where I am sitting, we have no option but to tackle aligning the mesa-optimizer cascade head-on.
↑ comment by jacob_cannell · 2022-01-22T19:20:14.532Z · LW(p) · GW(p)
AGI will require both learning and planning, the latter of which is already then a learned mesa optimizer. And AGI may help create new AGI, which is also a form of mesa-optimization. Yes it's unavoidable.
To create friendly but powerful AGI, we need to actually align it to human values. Creating friendly but weak AI doesn't matter.
comment by Jalex Stark (jalex-stark-1) · 2022-01-22T05:05:03.576Z · LW(p) · GW(p)
I think recursive mesa-optimization doesn't mean that aligning mesa-optimizers is hopeless. It does imply that solutions to inner alignment should be "hereditary." The model should have a "spawn a mesa-optimizer" technique which aligns the mesa-optimizer with the base objective and teaches the new submodel about the technique.
Replies from: peterbarnett↑ comment by peterbarnett · 2022-01-22T15:01:10.893Z · LW(p) · GW(p)
I think that this is a possible route to take, I don't think we currently have a good enough understanding of how to control\align mesa-optimizers to be able to do this.
I worry a bit that even if we correctly align a mesa-optimizer (make its mesa-objective aligned with the base-objective), its actual optimization process might be faulty/misaligned and so it would mistakenly spawn a misaligned optimizer. I think this faulty optimization process is most likely to happen sometime in the middle of training, where the mesa-optimizer is able to make another optimizer but not smart enough to control it.
But if we develop a better theory of optimization and agency, I could see it being safe to allow mesa-optmizers to create new optimizers. I currently think we are nowhere near that stage, especially considering that we don't seem to have great definitons of either optimization or agency.
Replies from: jalex-stark-1↑ comment by Jalex Stark (jalex-stark-1) · 2022-01-22T16:29:30.114Z · LW(p) · GW(p)
I agree with you that "hereditary mesa-alignment" is hard. I just don't think that "avoid all mesa-optimization" is a priori much easier.