Automation collapse
post by Geoffrey Irving, Tomek Korbak (tomek-korbak), Benjamin Hilton (80000hours) · 2024-10-21T14:50:54.500Z · LW · GW · 9 commentsContents
Three levels of automated AI safety A model of empirically checked automated safety We should understand if the collapsed alignment scheme is safe We should ask if less automation is possible Checking the algorithms avoids collapse, but is hard Acknowledgements None 10 comments
Summary: If we validate automated alignment research through empirical testing, the safety assurance work will still need to be done by humans, and will be similar to that needed for human-written alignment algorithms.
Three levels of automated AI safety
Automating AI safety means developing some algorithm which takes in data and outputs safe, highly-capable AI systems. Let’s imagine three ways of developing this algorithm:
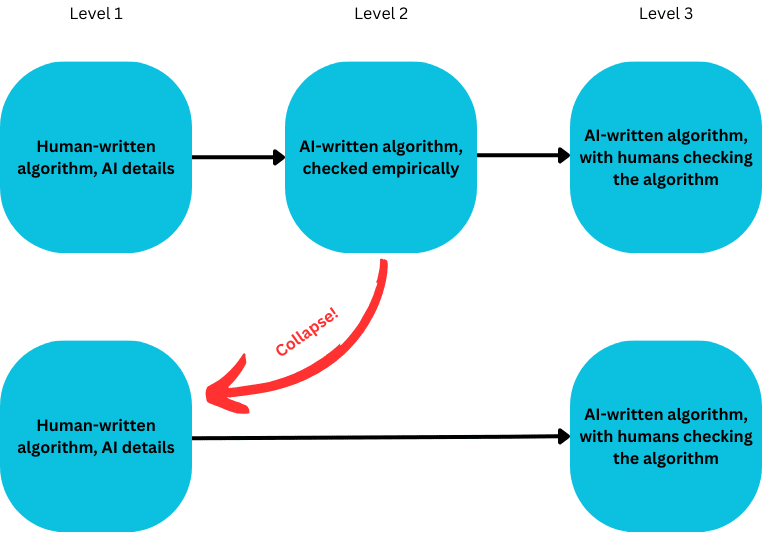
- Human-written algorithm, AI details: Humans write down an overall AI safety algorithm, and use AI systems to fill in a bunch of the details. The humans are confident the details provided by the AI systems don’t compromise the safety of the algorithm. This category includes scalable oversight, semi-automated interpretability (LLMs explain each neuron or SAE feature), and using LLMs for scaled formalisation of a spec.
- AI-written algorithm, checked empirically: The humans might have some rough idea what overall scheme is good, but the AI is going to do a bunch of high-level algorithm exploration, say over the space of scalable oversight algorithms. We then check whether the AI-generated algorithms are good safety algorithms by human inspection of empirical results on the systems trained by the AI-generated algorithms.
- AI-written algorithm, with humans checking the algorithm: The AI does a bunch of algorithm exploration, including writing novel training algorithms and carrying out novel empirical analyses. Humans check the algorithms and analyse them directly (reading prose scientific and mathematical content that explains how they work) in addition to looking at empirical outputs.
There is a level (4) of automated safety, where you trust the AIs helping with automation to know when they are right, and thus do not need to check the results. This corresponds to the “deference” level in Clymer et al. We treat this as out of scope for this doc, as it requires a level of capability beyond where automated alignment plans normally kick in.
We will argue that:
- Level (2) collapses into level (1): If the way we check success of AI-generated algorithms is known empirics, it may be vulnerable to the same obstacles to safety algorithms that apply to level (1), and it deserves the same level and kinds of scrutiny that we would apply to level (1). Intuitively, we can view level (2) as “collapsing” into a subset of level (1): algorithms from level (2) may be good, but they can be viewed as equivalent to a human-written safety algorithm, and do not automatically avoid obstacles to safety.
- If we avoid the collapse using a level (3) plan, we place more load on humans being able to check AI-written arguments for the validity of experiments and safety arguments.
A model of empirically checked automated safety
In detail, level (2) – AI-written algorithm, checked empirically – consists of
- A controller agent, performing automated alignment research
- A research environment where the controller operates. The controller has access to a family of initial models, and can generate data by itself, sample from models, collect data from human raters, launch training jobs, etc.
- An evaluation algorithm, consisting of one or more parameterised experiments that the controller can run in order to test the safety of a system it has trained or effectiveness of the training scheme it has developed. This could mean running the model on existing datasets, generating new datasets which are checked by humans and then running models on them, exhibiting prompts which cause the models to behave badly, etc. The evaluation algorithm could check the safety of a model using an additional model as part of the algorithm, or the controller could run an additional model inside the research environment to generate a dataset which is used at the evaluation stage.
This picture is quite general: the research environment could support reinforcement learning of agents with custom scalable oversight schemes, process supervision methods where the controller constructs models by linking together other models, non-policy gradient methods such as STaR which sample a bunch and then supervised learning on the best samples, etc. The evaluation algorithms could include parameterised sandwiching experiments (gather some human-checked data where the humans have extra context, and see if the models reproduce the results using human feedback without the context), honeypots where the controller constructs trajectories on which the models perform badly, etc. If desired, we can train agents inside the evaluation scheme: the research environment step could produce reward models or other components that slot into parameterised training methods, such that our evaluation scheme evaluates a training method rather than a produced agent.
Let’s say we want to be as confident in this level (2) picture as we would be in a reasonable level (1) or level (3) setup. The problem is that, in order to reach a similar degree of confidence, we must either:
- Understand post hoc what the controller is doing in the research environment to train the submodels (and why, a priori, the trained models are safe) – but this is level (3).
- Have a good reason to think that the entire system – controller agent, research environment, evaluation algorithm and resultant trained systems – can safely perform complex tasks. But this means we’ve written down an algorithm for a highly capable, safe AI system, and we’re confident that any AI-written details don’t compromise its safety. So our level (2) plan has collapsed into level (1).
More specifically, depending on the evaluation algorithm our scheme is some combination of process supervision and scalable oversight: process supervision because it’s relying on the controller and possibly some of the subagents doing a bunch of steps without being trained based on outcomes, and scalable oversight if we use scalable oversight-like evaluation in our experiments (playing agents against each other, using agents to assist evaluation, etc.).
It’s important to note that this argument applies to a variety of versions of level (2). For example, we expect that many automated safety schemes will not entirely trust the metrics used during evaluation, but instead argue that the metrics can be trusted in the context of the limited optimisation pressure exerted by the controller. Collapse still occurs here: if we want as much confidence as we could have in level (1), we still must understand why optimisation pressure limits are enough to trust the metrics.
It is not necessarily bad if empirically checked automated alignment collapses into a human-written alignment scheme. Such a scheme might enable much faster progress due to automation. Our claim is that such a scheme deserves the same scrutiny we would apply to any other human-written scheme.
We should understand if the collapsed alignment scheme is safe
Assume we’ve decided that any human-written safety algorithm from level (1) should come with a safety case justifying why it will successfully avoid risk. For example, we might be concerned that automated AI safety has extensive overlap with accelerating the development of riskier, more capable models, so we should try to write down a confident argument that it will work prior to the acceleration commencing.
The main consequence of level (2) collapsing into level (1) is that we need safety cases for level (2) as well:
- (Collapsed) safety case: We should try to write down a safety case for the overall scheme, explaining why the particular combination of controller agent, research environment, and evaluation scheme is safe. Here, ‘safe’ means that if we produce an unsafe agent or training method we would catch it at the evaluation step.
In particular, there are a variety of known worries in process supervision and scalable oversight methods, and we should ask whether these worries occur in the level (2) algorithm. Examples of such worries include (there may be others):
- Process supervision:
- Bootstrapping: Modern pretrained LLMs are already superhuman at some types of tasks, in particular knowledge recall. Therefore, even prior to tuning, humans won’t necessarily be able to directly understand the correctness of the steps being performed.
- Emergence: If a human understands each step of a long trajectory as safe, do we know whether the full trajectory is safe?
- Scalable oversight:
- Obfuscated arguments: Will there be important cases where models know a problem exists in some reasoning, but be unable to concretely exhibit that problem to human supervision?
- Systematic human errors: Will humans be systematically wrong in ways agents can exploit, such that repeatedly asking the question in different ways gives consistently wrong answers?
It is possible that we do have good arguments that these problems would not occur in our automation setup / meta-alignment scheme. However, if we’re not signing up to check conceptual arguments made by AIs as part of the automated safety process (level (3)), we should attempt to write down these arguments as part of our safety case, in advance of launching an automation plan.
We should ask if less automation is possible
Additionally, if we do have good arguments that the problems do not occur, we should ask whether that understanding can be ported across to a less automated alignment scheme. There are several advantages to this:
- Less automation is easier to analyse: As described above, the research environment is very flexible.
- Less automation lets us use weaker models: Weaker models mean we can start using the method earlier, which gives us more time to tune details and reduces risk that the controller model is misaligned.
- Less automation means security is easier: Simplifying or concretising the research environment makes it easier to sandbox the controller model’s actions or check them via AI control methods.
- Less automation may be cheaper: Weaker models may mean lower inference costs required to access empirical evidence, and less automated schemes may require fewer evaluations overall.
For example, our level (2) evaluation scheme might rely on some combination of
- Successful elicitation: Our controller AI is able to successfully elicit behaviours from models, in order to exhibit capabilities and dangerous tendencies.
- Honeypots: If a submodel is misaligned, our controller is able to construct honeypots that trigger misaligned behaviour in a submodel that looks bad to human oversight.
In a more automated scheme, elicitation and honeypot creation might involve extensive hyperparameter tuning and experiment design to succeed. It is possible this automation is necessary for success, but we should ask if an appropriately designed automated adversarial probing method also works. If statements only slightly stronger than (i) and (ii) hold, then honeypots exist if models are unsafe, our models are capable of finding them, and we can elicit that capability. This means that instead of relying on a controller agent performing elicitation and creating honeypots, we can build an attacker model that can rewrite trajectories that trigger bad behaviour in a defender model. Even if we need to combine this adversarial probing with scalable oversight techniques to evaluate subtle cases, the result still looks like a version of a human-written alignment method, and we can try to apply it without leaning on more advanced automation.
Checking the algorithms avoids collapse, but is hard
If we want to avoid this kind of collapse behaviour, we need to use level (3): leaning explicitly on humans checking not just empirical results using experiments designed by humans, but the scientific validity of novel AI-written alignment algorithms, novel AI-designed experiments exhibiting misalignment, and AI-produced reasoning about those algorithm and experiments.
Signing up to checking the reasoning of the AIs might be good! But we should plan in advance what the standards of evidence will be, who will be doing the oversight, etc. If we expect AIs to produce reasoning for why subtle alignment failures do not occur, or invent novel types of experiments, then we’ll need quite strong models to do the necessary kind of automation, and checking the results may be hard.
A particular way that level (3) can be hard to evaluate is if evidence is inconclusive, but we believe that the controller might produce unfairly negative evidence of misalignment. For example, if a trained submodel is mostly aligned but not jailbreak-resistant, then we may be able to make a “fake honeypot” which appears to be a plausibly naturally occurring behaviour, but is in fact highly unlikely to occur in practice and is thus invalid evidence. One way this could happen is searching for jailbreaks in the space of paraphrases and synonyms of a benign prompt. Conceivably we could rule out that fake honeypot as not realistic, but this requires understanding in detail the creation process for the honeypot, what it means for a honeypot to be realistic, etc.
Allowing a controller model to set details of parameterised experiment types in fancy ways isn’t enough to avoid collapse: this puts us back at level (2). For example, if it requires quite complex actions and planning inside the research environment to produce a honeypot, but we then check the honeypot in a standard way (“show it to a model and recognise that it behaves badly”), we’re in level (2) not level (3).
Acknowledgements
Thank you to Jan Leike, Paul Christiano, Jonah Brown-Cohen, Rohin Shah, and Xander Davies for discussions!
If you find problems like this interesting, consider applying to the Safety Cases team at UK AISI!
9 comments
Comments sorted by top scores.
comment by Martín Soto (martinsq) · 2024-11-12T10:42:03.585Z · LW(p) · GW(p)
Very cool! But I think there's a crisper way to communicate the central point of this piece (or at least, a way that would have been more immediately transparent to me). Here it is:
Say you are going to use Process X to obtain a new Model. Process X can be as simple as "pre-train on this dataset", or as complex as "use a bureaucracy of Model A to train a new LLM, then have Model B test it, then have Model C scaffold it into a control protocol, then have Model D produce some written arguments for the scaffold being safe, have a human read them, and if they reject delete everything". Whatever Process X is, you have only two ways to obtain evidence that Process X has a particular property (like "safety"): looking a priori at the spec of Process X (without running it), or running (parts of) Process X and observing its outputs a posteriori. In the former case, you clearly need an argument for why this particular spec has the property. But in the latter case, you also need an argument for why observing those particular outputs ensures the property for this particular spec. (Pedantically speaking, this is just Kuhn's theory-ladenness of observations.)
Of course, the above reasoning doesn't rule out the possibility that the required arguments are pretty trivial to make. That's why you summarize some well-known complications of automation, showing that the argument will not be trivial when Process X contains a lot of automation, and in fact it'd be simpler if we could do away with the automation.
It is also the case that the outputs observed from Process X might themselves be human-readable arguments. While this could indeed alleviate the burden of human argument-generation, we still need a previous (possibly simpler) argument for why "a human accepting those output arguments" actually ensures the property (especially given those arguments could be highly out-of-distribution for the human).
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2024-11-12T13:37:17.067Z · LW(p) · GW(p)
Yes, that is a clean alternative framing!
comment by Dave Orr (dave-orr) · 2024-10-21T18:59:36.478Z · LW(p) · GW(p)
One way this could happen is searching for jailbreaks in the space of paraphrases and synonyms of a benign prompt.
Why would this produce fake/unlikely jailbreaks? If the paraphrases and such are natural, then doesn't the nearness to a real(istic) prompt enough to suggest that the jailbreak found is also realistic? Of course you can adversarially generate super unrealistic things, but does that necessarily happen with paraphrasing type attacks?
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2024-10-21T19:44:37.527Z · LW(p) · GW(p)
To clarify, such a jailbreak is a real jailbreak; the claim is that it might not count as much evidence of “intentional misalignment by a model”. If we’re happy to reject all models which can be jailbroken we’ve falsified the model, but if we want to allow models which can be jailbroken but are intent aligned we have a false negative signal for alignment.
Replies from: dave-orr↑ comment by Dave Orr (dave-orr) · 2024-10-22T16:36:54.123Z · LW(p) · GW(p)
Aha, thanks, that makes sense.
comment by Raymond D · 2024-10-22T01:05:52.396Z · LW(p) · GW(p)
Could you expand on what you mean by 'less automation'? I'm taking it to mean some combination of 'bounding the space of controller actions more', 'automating fewer levels of optimisation', 'more of the work done by humans' and maybe 'only automating easier tasks' but I can't quite tell which of these you're intending or how they fit together.
(Also, am I correctly reading an implicit assumption here that any attempts to do automated research would be classed as 'automated ai safety'?)
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2024-10-22T07:44:00.655Z · LW(p) · GW(p)
Bounding the space of controller actions more is the key bit. The (vague) claim is that if you have an argument that an empirically tested automated safety scheme is safe, in sense that you’ll know if the output is correct, you may be able to find a more constrained setup where more of the structure is human-defined and easier to analyze, and that the originally argument may port over to the constrained setup.
I’m not claiming this is always possible, though, just that it’s worth searching for. Currently the situation is that we don’t have well-developed arguments that we can recognize the correctness of automated safety work, so it’s hard to test the “less automation” hypothesis concretely.
I don’t think all automated research is automated safety: certainly you can do automated pure capabilities. But I may have misunderstood that part of the question.
Replies from: LincolnJames↑ comment by LincolnJames · 2024-11-08T11:58:45.944Z · LW(p) · GW(p)
comment by TheManxLoiner · 2024-11-12T20:40:36.805Z · LW(p) · GW(p)
- Pedantic point. You say "Automating AI safety means developing some algorithm which takes in data and outputs safe, highly-capable AI systems." I do not think semi-automated interpretability fits into this, as the output of interpretability (currently) is not a model but an explanation of existing models.
- Unclear why Level (1) does not break down into the 'empirical' vs 'human checking'. In particular, how would this belief obtained: "The humans are confident the details provided by the AI systems don’t compromise the safety of the algorithm."
- Unclear (but good chance I just need to think more carefully through the concepts) why Level (3) does not collapse to Level (1) too, using same reasoning. Might be related to Martin's alternative framing.