Introducing Statistical Utility Mechanics: A Framework for Utility Maximizers
post by J Bostock (Jemist) · 2024-05-15T21:56:48.950Z · LW · GW · 0 commentsContents
TL;DR
Toy Example: Why AI Suddenly Becomes Dangerous
The Alignment Process
AI Scaling
Conclusions
Major Caveat
Appendices
Appendix 1: The Entropy to KL-Divergence Trick
Appendix 2: KL-Divergence is not a Metric
None
No comments
This is independent alignment research. A decent grasp on stat mech is needed to understand this post fully, but I have recently written a stat mech sequence (up to part 3) which should do the trick to catch someone up to speed rapidly.
TL;DR
Statistical Utility Mechanics is a framework which draws on stat mech to model the actions of utility-maximizing agents. I introduce this framework here, and use it to demonstrate why the most naive possible alignment plan (by which of course I mean one not too far off the one that most AI companies are currently using) is doomed by scaling laws, and we should expect to see sudden increases in AI's potential for harm around when AI reaches roughly human level.

The framework consists of just three core rules
- The world is a probability distribution over states
- Each agent assigns a value to each state
- Agents can affect the probability distribution over states with limited power
I'll go into more detail with these in this toy model:
Toy Example: Why AI Suddenly Becomes Dangerous
The world is described by a multivariate normal distribution over states , centred on the origin. All variances are 1, so the distribution can be written as follows:
This has the nice property of being totally spherically symmetrical. I will also write for brevity in some cases.
Let us consider an AI agent , which has the simplest possible utility function: for some vector , and a "power level" . Without loss of generality we will assume that (the reason for this will be clear soon)
This AI will impact the world's probability distribution according to two rules:
- Subject to rule 1, is maximized
Normally stat mech tells us about entropy given expected values, but here we can flip it on its head to tell us about expected values given KL-divergence (see appendix for why we use KL-divergence here). This is for some constant , and gives the distribution
Using the formula for the KL-divergence of two multivariate gaussians, we get:
This framework naturally captures the fact that rescaling or adding a constant to our utility function does not change the behaviour of the agent. If , then we just get a different value and it all cancels out to the same answer.
The Alignment Process
Let's describe a human utility function in the same way as the agent's: . We will also describe the "power" of humans in this system as . In this model, what matters is the cosine similarity between the two vectors, which can be expressed as . For a dimensional space, and two totally randomly-chosen vectors, this is distributed like this:
where
We will work in terms of rather than to simplify the maths, and because we expect to have a very high-dimensional space, and mainly care about scaling laws, it doesn't really matter. We'll consider altering the value of , again using the KL-divergence trick to measure how much we're impacting our distribution. Our system does not (really) have a good closed-form solution, especially for small values of and large values of . We can approximate our whole system numerically though, and get the following results:
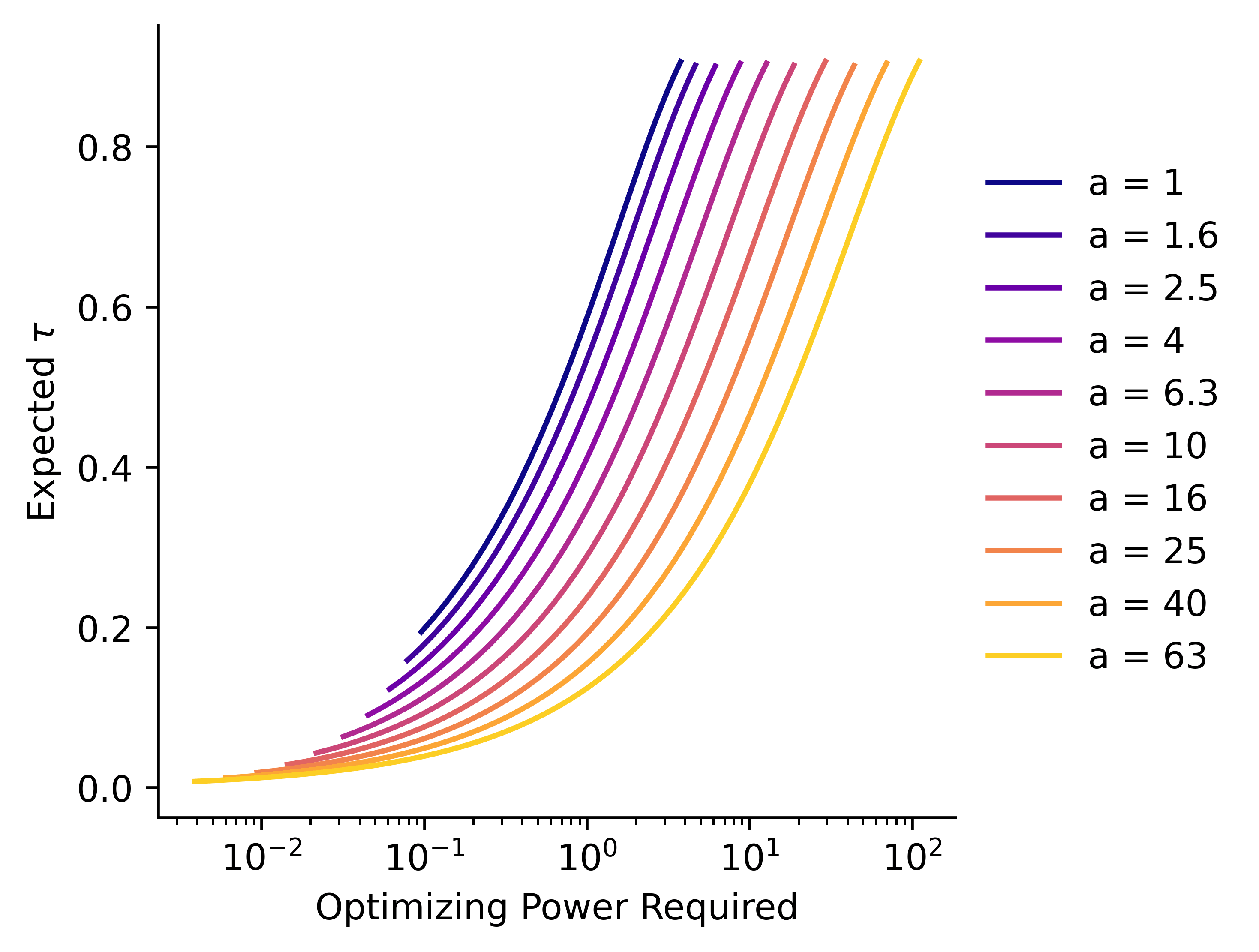
Here we've calculated as a function of and , but plotted it against , which we'll define as the divergence . We can see that the higher the dimensionality of our space, the more we must optimize the AI's utility function to get above a certain critical value . If we plot this required optimization against :
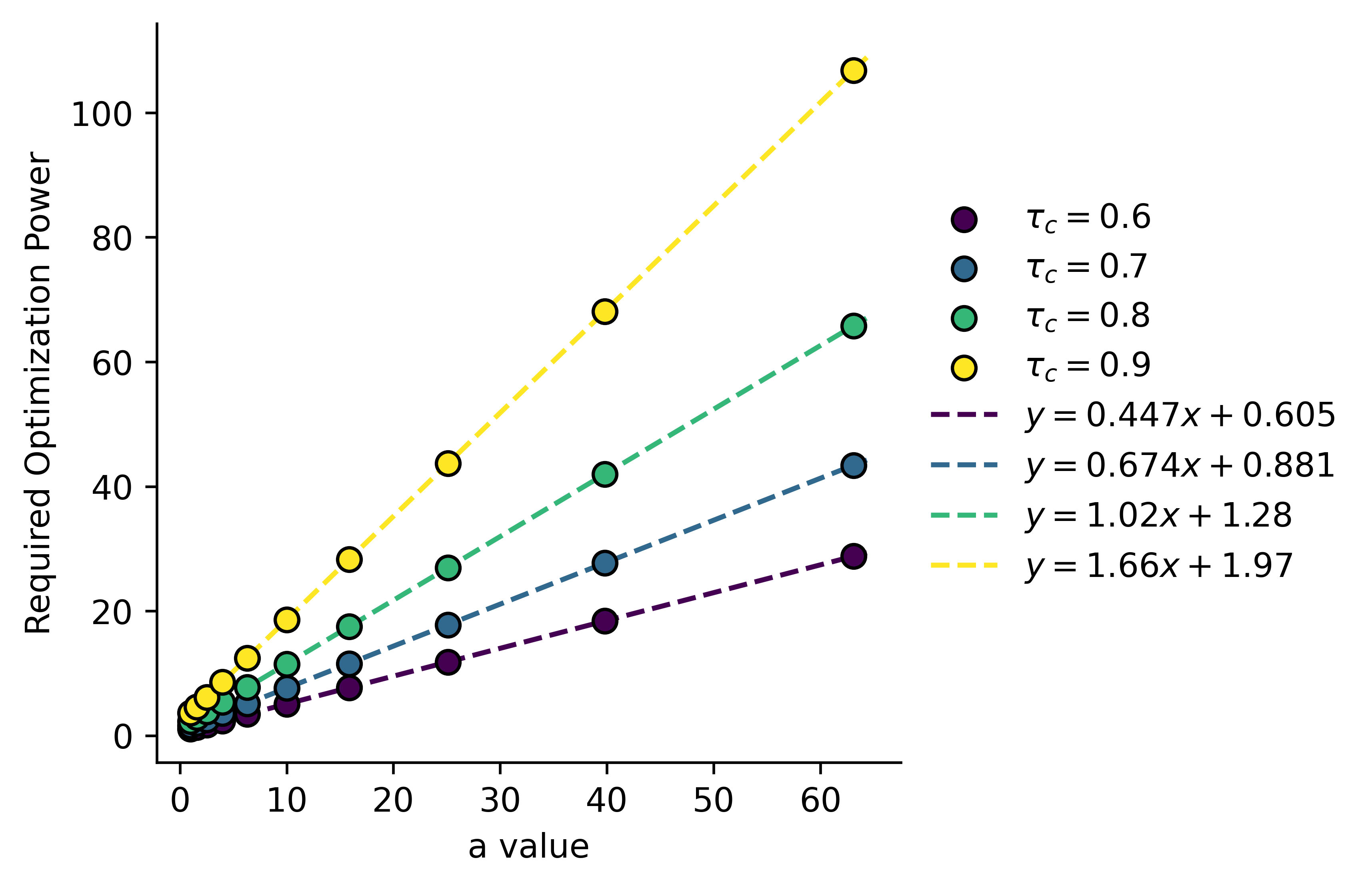
We can also see that this relationship is linear for any threshold we might want to set. This is somewhat unsurprising, the each dimension is just another, mostly independent, dimension along which we must optimize . The question is, how might we optimize the AI's utility function, and what are the constraints on ?
Consider the following loop (basically trying to wrangle an AI into alignment by letting it loose and seeing what it does):
- The AI observes the world.
- The AI takes an action to optimize the world.
- We observe the result of that action.
- We take an action to optimize the AI's utility function
The expected amount of information we get about the AI's utility function from observing the result of each action is just the KL-divergence between the un-optimized world and the optimized world, in other words ! How much of this optimization is harmful? We can express it as :
(The reason for all the square roots is in Appendix 2)
Here is the plot of the following integral:
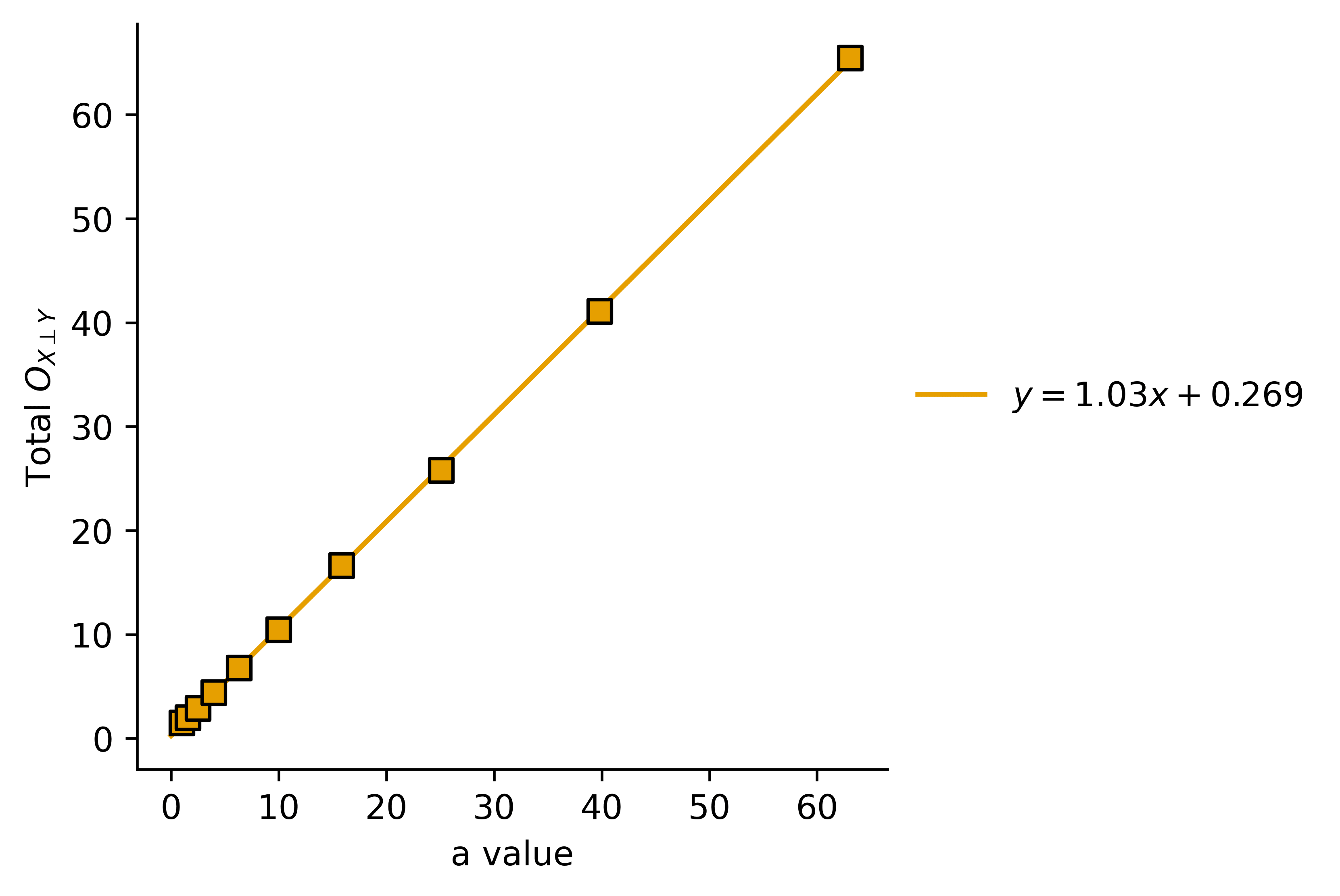
This makes sense again: we have a linear relationship between the amount of harmful optimization the AI will do before we can wrangle it into alignment, and the size of the space of possible utility functions. Not good!
Now if the people trying to align the AI are not completely stupid (debatable) we might want to add a final point to this loop:
- We take an action to rectify the result of the AI's action
If the AI is smarter than us, we would expect not to be able to fully rectify the result of the AI's decision. For simplicity, and without particular principle, we will make the choice of where
We will also upper-bound , representing the assumption that we probably can't optimize the AI any more strongly than we can optimize against its effects on the world (since our limits on both are likely due to our ability to understand the AI's actions). We can then simplify our expressions to these relations in terms of :
We will therefore calculate the integral:
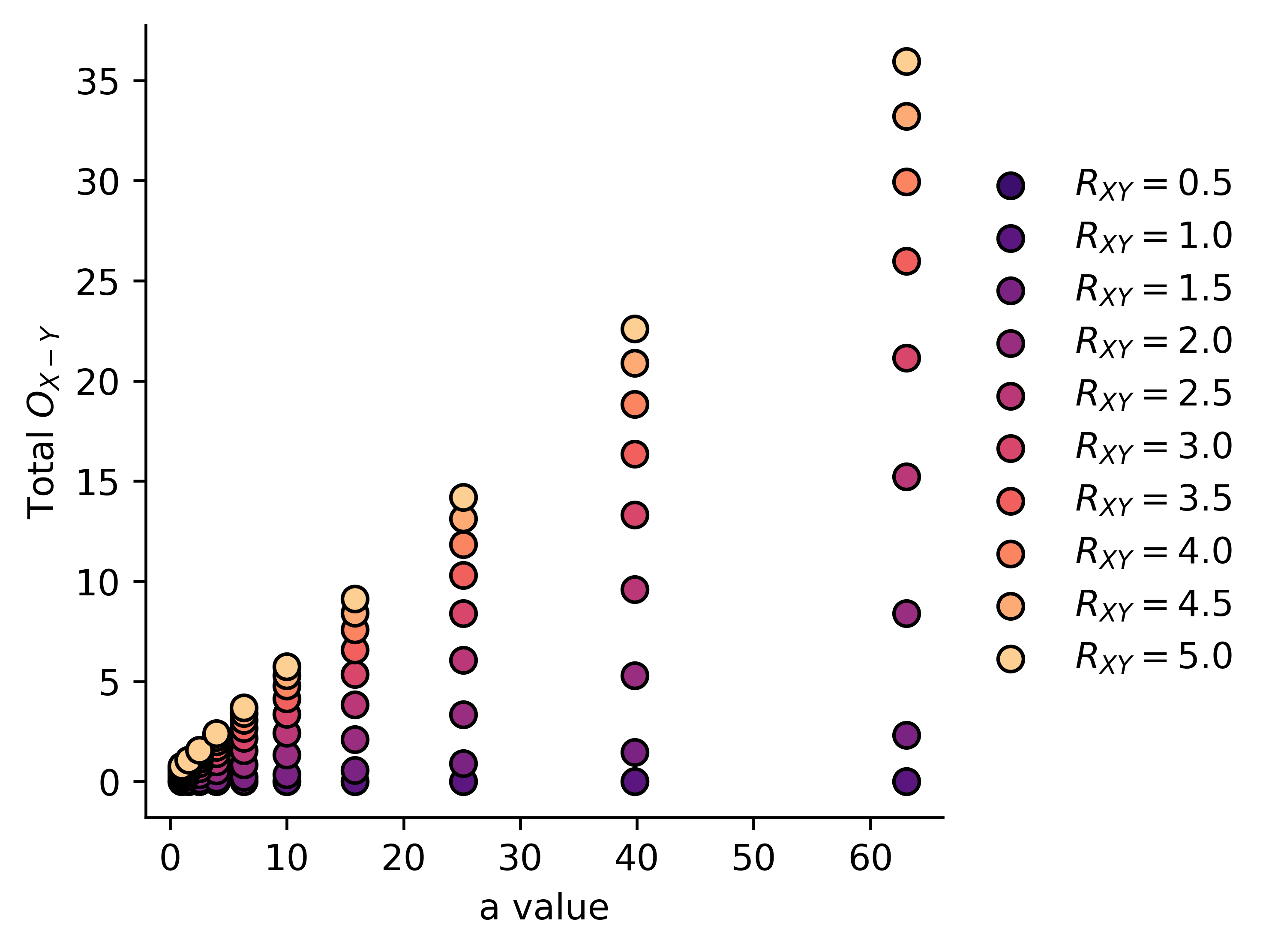
Or we can plot it as a function of , with as a parameter:
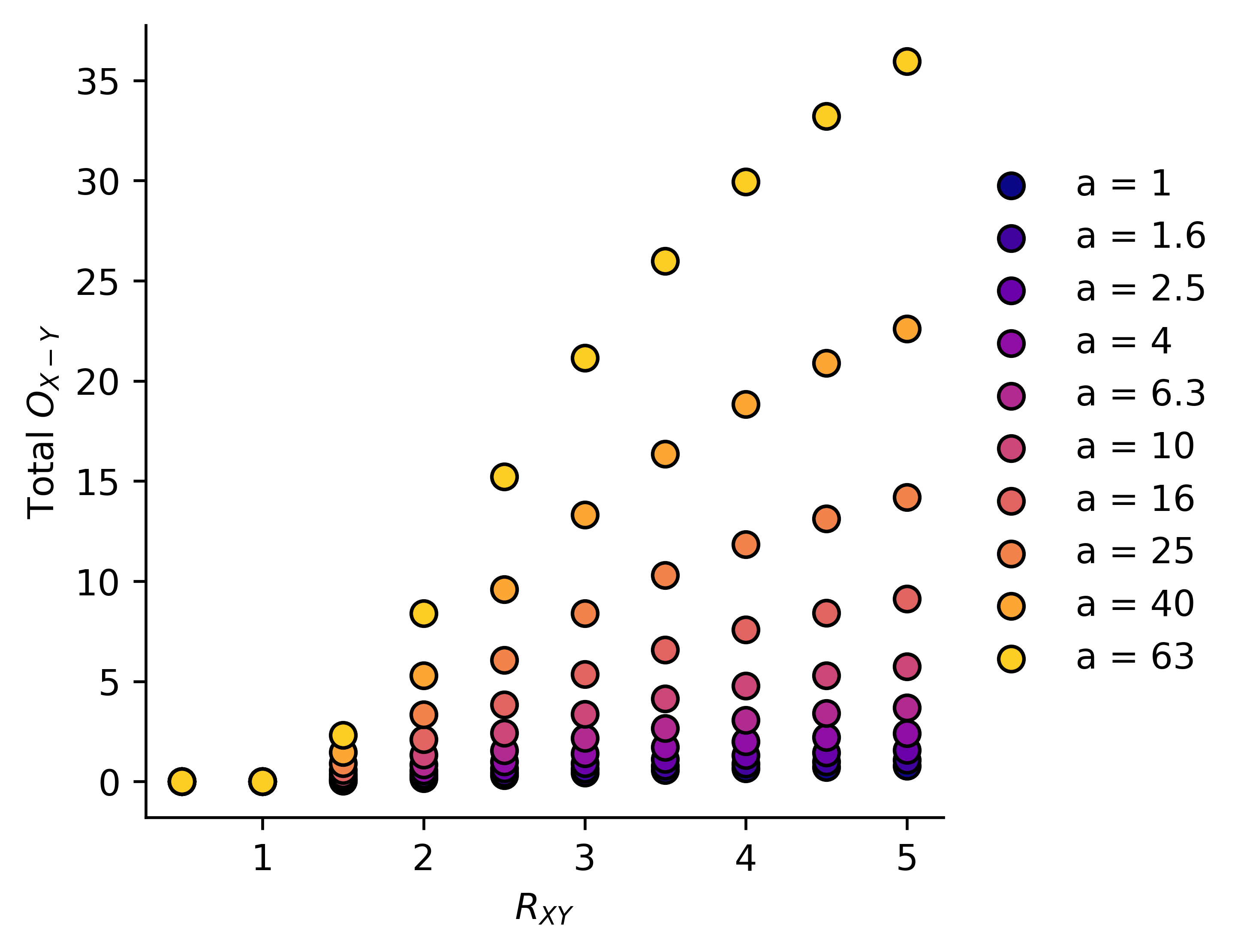
We can note a few predictions from this system:
- Total "harm" as measured by during training is directly proportional to
- For , we experience zero total harm, but harm grows very rapidly around human level AI, and the larger the value of , the faster it grows
AI Scaling
The question is, how do our parameters scale with AI "scale"? Let's assign AI scale the to variable (because xi is hard to draw and an AI's scale is hard to quantify) then we'll make the very conservative assumption that scales with , and scales with for some exponent , probably . This gives us a plot looking something like the black line below:
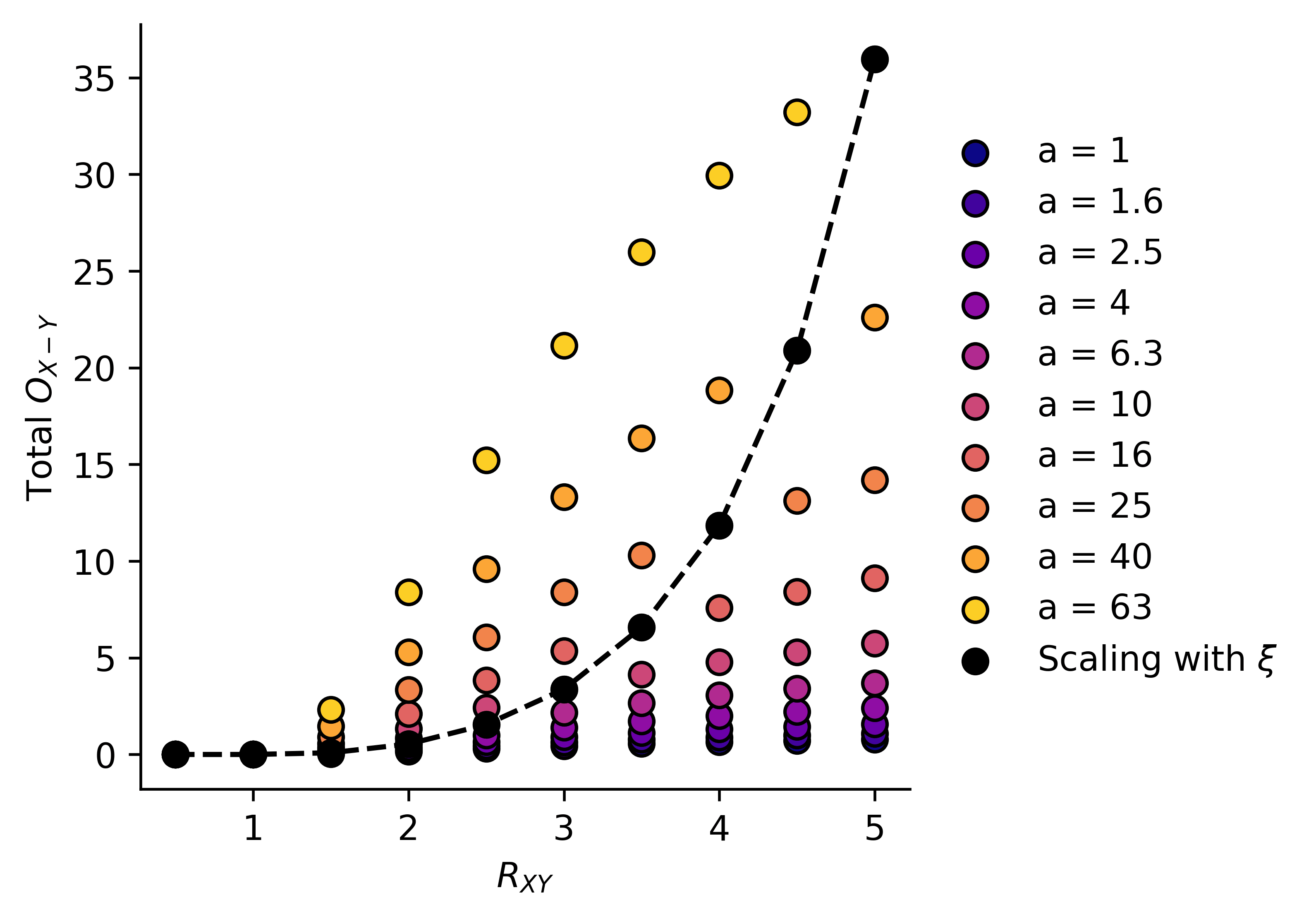
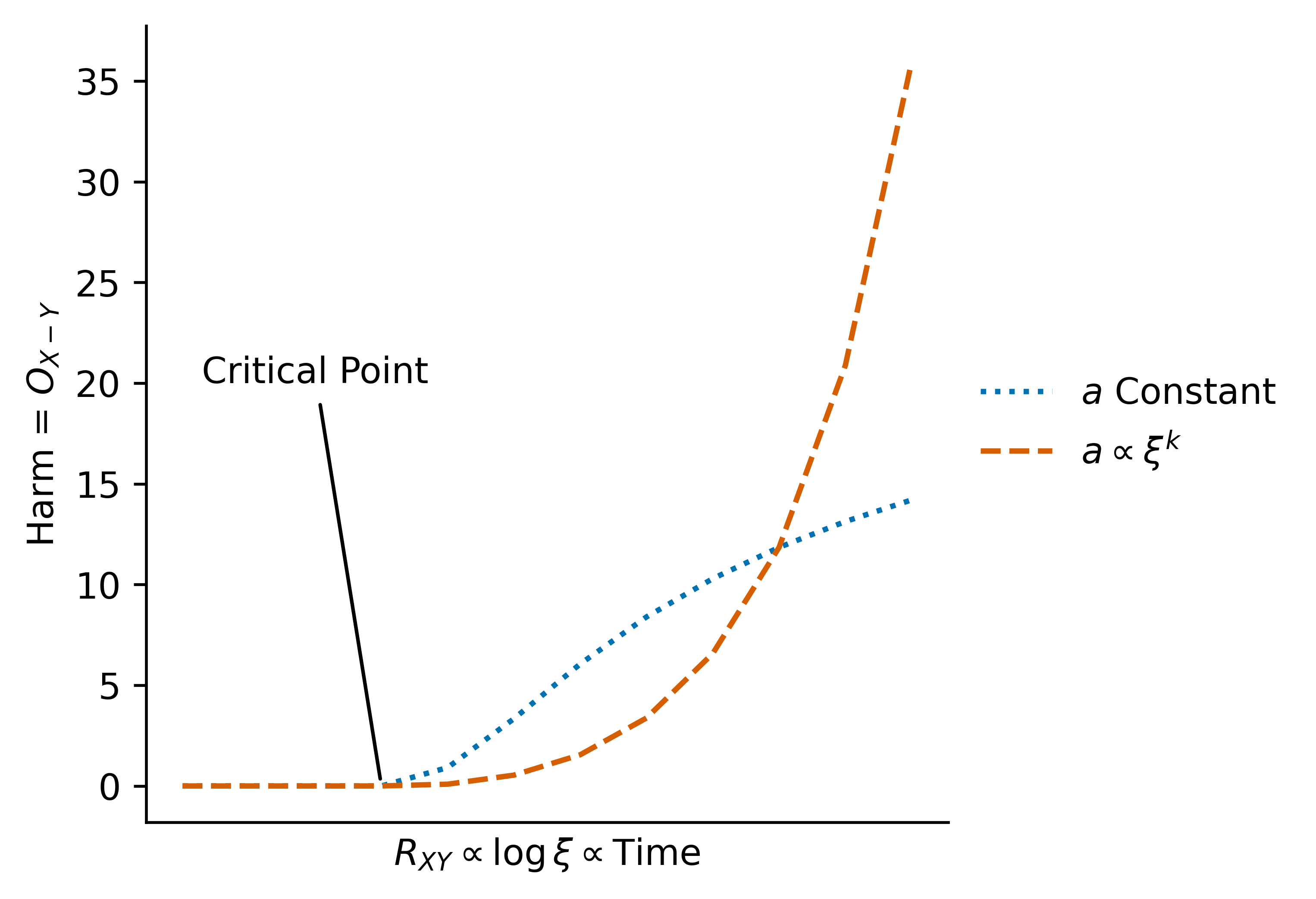
If we expect to scale exponentially with time , we expect to scale exponentially over time, and to scale linearly.
Or if we use a logarithmic -axis, to get a better look at just how fast it is growing:
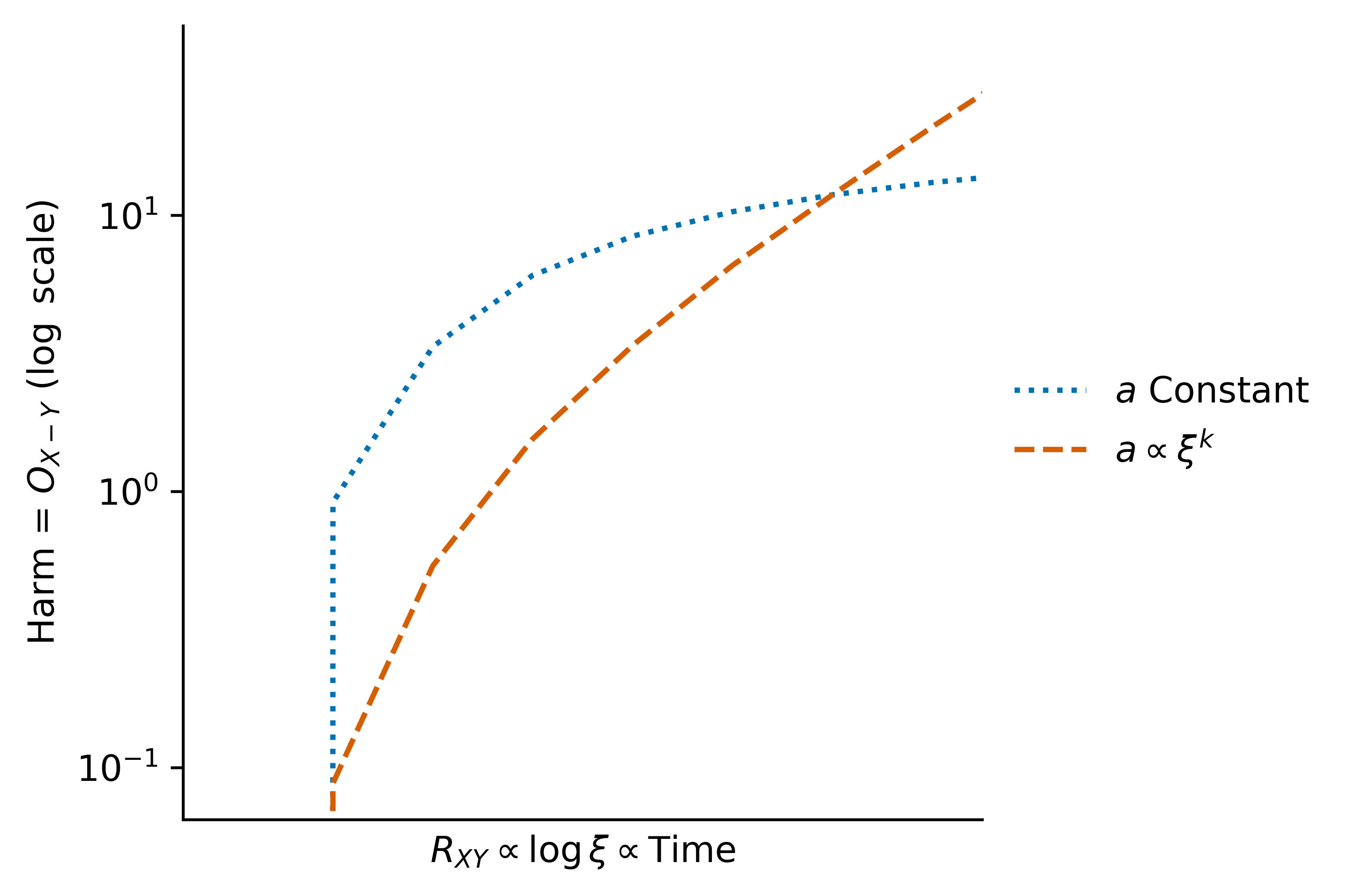
I conjecture that this consists of three phases:
- A "lag" phase in which , so no harm is possible (the world is currently in this phase)
- A "catch-up" phase in which the , so we see double-scaling (due to overcoming the function more and more as increases)
- An "exponential" phase, in which , so we "only" see exponential scaling, or perhaps scaling as (which is still very fast)
Conclusions
This model tells us to expect super-exponential scaling of AI harms around human level. It also tells us that the higher the dimensionality of the possible utility-function space, the more quickly these harms will grow.
Some things this model does not include, a mixture of things which would make alignment easier or harder:
- The ability for the aligners to "sandbox" the AI, limiting its domain during alignment, or do offline-RL-ish-stuff on it
- Clever tricks to "repeat" the AI's actions in some way to get more than information out of each of the AI's actions
- The ability for the AI to become more powerful over time during deployment (i.e. increases over time while the AI is being altered)
- The ability for the AI to understand that it is being optimized, and act strategically or deceptively
- A "sharp left turn" in which AI gains new capabilities (e.g. can optimize in more dimensions)
- "Real" goodharting, in which eventually even highly correlated optimization targets diverge due to constraints.
- Extra "fragility" terms outside of . I tried to simulate this by transforming the distribution to a narrower one, but polynomially-scaling had the same effect as increasing , so perhaps it is best to think of as just being a general "fragility constant"
I'm going to keep working on SUM, and hopefully get even more interesting results. I think SUM has the potential to be a fertile ground for both formal proofs and more informal models (like this one) surrounding alignment.
For a recap, here are the foundational principles:
- The world has states , which can be any set
- We define a probability distribution
- Agents assign real values to each element
- An agent can influence that probability distribution with power
- This means the action is subject to
- The optimal action for a myopic agent is for
Major Caveat
- Arguably the sudden threshold is somewhat artificial. I did add a threshold function to my measure for harm, which induced a threshold in harm. I do think the threshold is well-motivated though.
- It's somewhat unclear whether is the most natural measure of an AI's power
- Technically this should all be done with lots of causal models and severed correlations, which I have omitted here. I think the results ought to still hold there, but I haven't crunched all the numbers so I'm working in shorthand.
Appendices
Appendix 1: The Entropy to KL-Divergence Trick
The world in SUM is conceptualized as a set of states . To each of these we assign an initial probability , according to all the normal rules of probability distributions. We define the total entropy where is the "intrinsic entropy" of each state, a trick from stat mech when our "states" are not truly fundamental.
We then perform a second trick by defining . This has two effects: by definition, and more subtly becomes the maximum-entropy probability distribution.
This combination gives us a definition of which reduces to the KL-divergence.
Appendix 2: KL-Divergence is not a Metric
So KL-divergence is actually a generalization of squared distance, not distance. This is why I do my integrals with respect to . This still might not be the most appropriate way to do things, but I've found that the qualitative results are the same if I do them with respect to or .
0 comments
Comments sorted by top scores.