Monet: Mixture of Monosemantic Experts for Transformers Explained
post by CalebMaresca (caleb-maresca) · 2025-01-25T19:37:09.078Z · LW · GW · 2 commentsContents
Key Ideas Mixture of Experts Background MONET Architecture Results Benchmark Results Interpreting Experts Expert Masking Reinterpreting MONET Proposal for Efficient Implementation Summary None 2 comments
Note: This is an exposition of the recent preprint "Monet: Mixture of Monosemantic Experts for Transformers". I wrote this exposition as my project for the ARBOx program, I was not involved in writing the paper. Any errors are my own. Thank you to @David Quarel [LW · GW] for his excellent comments and suggestions.
TL;DR: MONET is a novel neural network architecture that achieves interpretability by design rather than through post-hoc analysis. Using a specialized Mixture of Experts (MoE) architecture with ~250k experts per layer, MONET encourages individual components to learn specific, interpretable tasks (e.g., Python coding, biology knowledge, or toxicity generation). This enables selective removal of capabilities without harming performance in other domains.
I show that MONET can be framed as a standard transformer MLP with two key modifications: (1) forced sparse activations in the hidden layer and (2) dynamic reshuffling of the hidden layer. This interpretation helps explain how MONET achieves interpretability: the sparsity forces specialization while the reshuffling maintains expressivity by allowing flexible composition of specialized components. Performance is competitive with traditional architectures, suggesting we might not need to trade off performance for interpretability.
If these results hold up, MONET represents a significant step toward architectures that are interpretable by design rather than requiring post-hoc analysis. This could fundamentally change how we approach AI interpretability, moving from trying to understand black boxes after the fact to building systems that are naturally decomposable and controllable.
In the last section, I propose a potential implementation improvement using block-sparse matrix multiplication that could make the architecture more computationally efficient. If successful, this could help encourage wider adoption of interpretable architectures like MONET.
Key Ideas
A key finding in mechanistic interpretability is that individual neurons in LLMs often fire in response to multiple unrelated concepts - a phenomenon called polysemanticity. For example, a single neuron might activate for both "blue" and "angry", making it difficult to isolate and understand how the model processes information.
Sparse Autoencoders (SAEs) present an approach to untangle these mixed features by mapping latents into a higher dimensional, sparse space, with the goal that each neuron in this space represents a single concept. However, because SAEs are applied only after model training, rather than being part of the training process itself, they may not capture all the nuances of how the model actually processes information.
MONET takes a different approach by building feature sparsity directly into the model through utilizing a novel Mixture of Experts (MoE) architecture. As opposed to standard MoE models which have only a small number of experts per layer, MONET uses careful architectural design to implement ~250k experts per layer, while managing computational efficiency through clever parameter sharing between experts.
This massive increase in experts allows each one to become highly specialized. The authors demonstrate this specialization through several compelling examples:
- Domain Experts: They identified experts that specialized in specific academic domains like biology or mathematics. When these experts were disabled, performance dropped specifically in their domain while remaining relatively unchanged in others.
- Programming Language Experts: In code generation tasks, different experts specialize in different programming languages, allowing selective removal of specific language capabilities.
- Toxicity Experts: They found experts correlated with toxic language generation, and removing them reduced toxicity while preserving general performance.
These results suggest MONET could be an important step toward more interpretable and controllable language models. Rather than trying to understand or modify the model's behavior through post-hoc analysis, we might be able to design the architecture from the ground up to provide a model where the components responsible for each different capability can be intervened with individually.
Mixture of Experts Background
Before we dive into the paper's specifics, let's understand what a Mixture of Experts (MoE) architecture is. HuggingFace has an excellent article explaining MoEs in detail, which I recommend reading. Here I will provide a brief summary.
The standard transformer block is made of two components, the Attention head and the MLP layer. both read (normalized) inputs from, and write back to, the central residual stream. MoE models replace the feed-forward network with multiple feed-forward networks, called experts and a router. For each token, the router determines to which expert(s) the residual stream in that token’s position should be fed. This can be seen in the following figure from the HuggingFace article[1] visualizing the Switch Transformer (a popular MoE implementation) architecture.
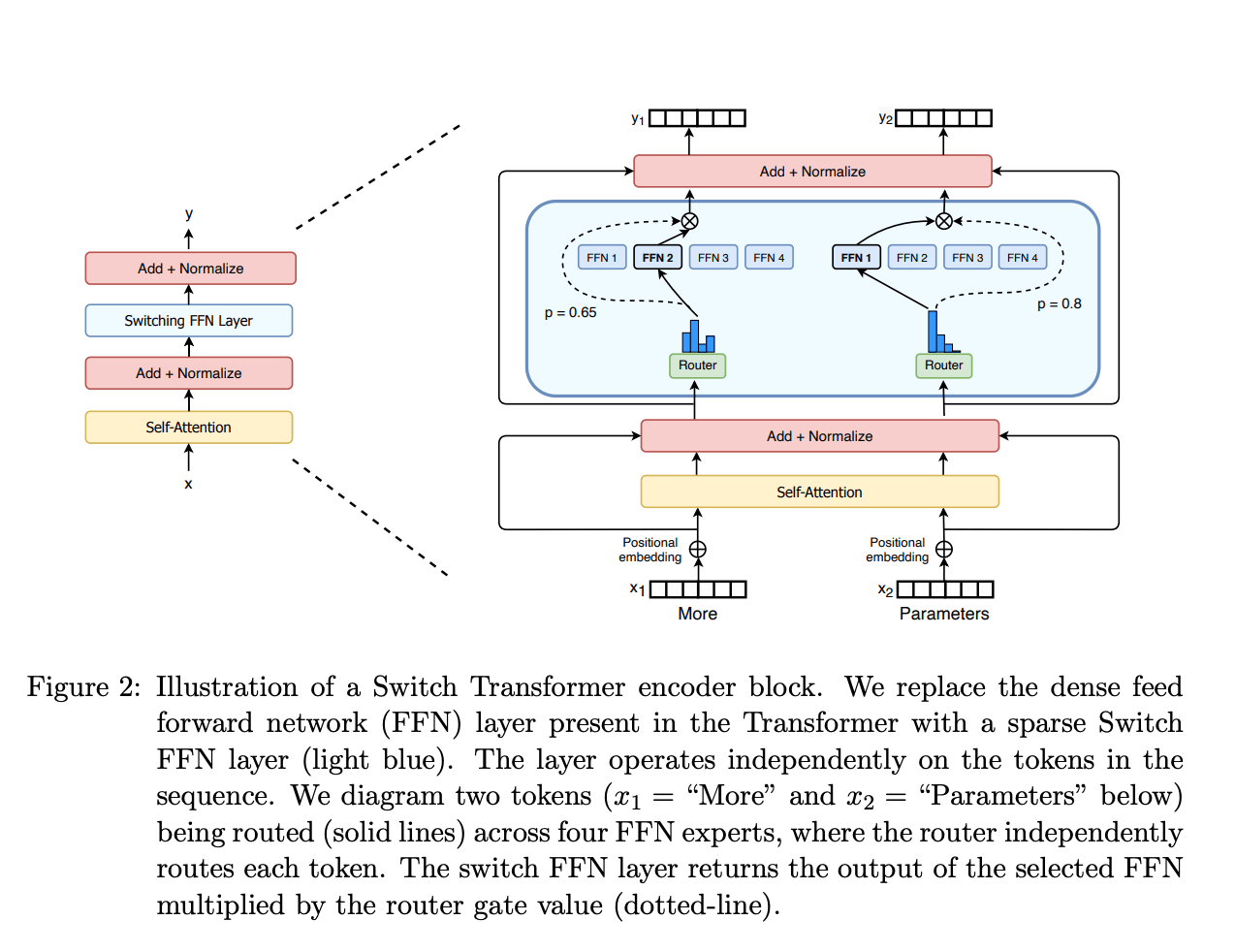
The advantage of MoE models is the ability to dramatically increase effective model size relative to a standard transformer without requiring a similar increase in compute. For example, an MoE model with eight experts will have approximately eight times as many parameters[2] but since each token is routed through only one or a couple experts, the computational cost per token remains similar to a standard model (equivalent to a MoE model with only one expert per MLP layer). This selective activation of experts allows MoE models to achieve greater parameter efficiency by specializing different experts for different types of inputs while maintaining reasonable inference and training costs. The downside is that it is not known which expert the router will choose ahead of time, so all experts must be kept in working memory.
Traditional MoE models typically use 8-128 experts per layer. This relatively small number of experts means each expert ends up handling many different types of inputs, leading to the same polysemanticity problems we see in standard transformers. MONET's key innovation is finding a way to scale to ~250k effective experts per layer while keeping computational costs manageable. However, as we will see below, it uses the MoE architecture in a dramatically different way than standard MoE models, with a focus on making the model interpretable, but sacrificing the typical efficiency benefit of MoE.
MONET Architecture
MONET enables efficient computation of a large number of experts by utilizing a novel product key composition routing system as visualized in Figure 1 of the paper, copied below.
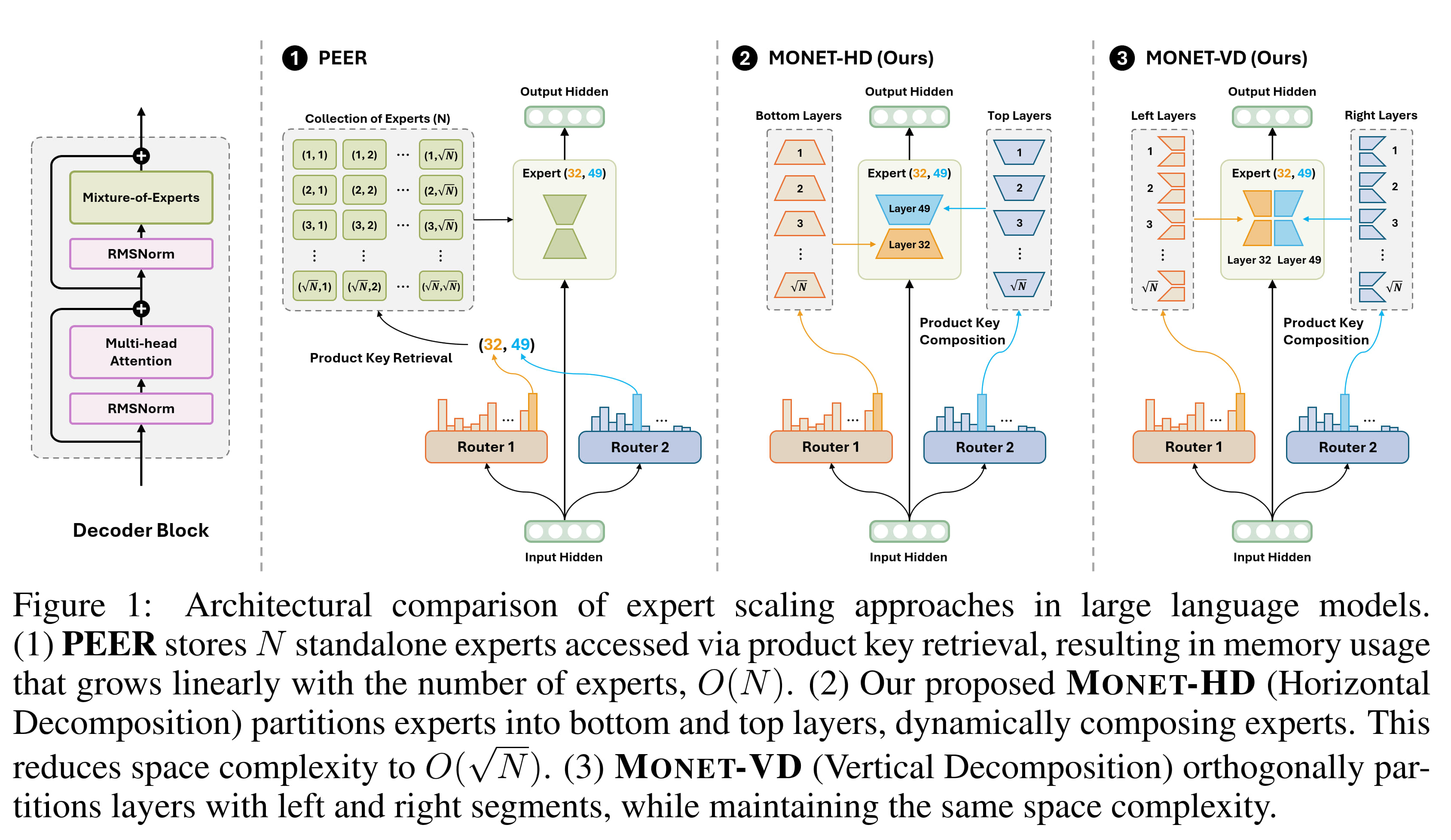
This figure compares another framework for handling a large number of experts called Parameter Efficient Expert Retrieval (PEER) to their approaches called Horizontal Expert Decomposition (HD) and Vertical Expert Decomposition (VD).
As opposed to standard MoE architectures which have one router that selects an appropriate expert(s), PEER uses a product key retrieval mechanism to efficiently select the top- experts. This is done by organizing the experts on a grid, with each router returning the row and column respectively of the selected expert. Product key retrieval reduces the computational complexity of expert selection, however the parameter count of the MoE layer scales linearly with the number of experts, limiting the number of experts implementable before running into memory bottlenecks.
MONET's product key composition mechanism solves this issue by cutting the experts in half, either horizontally or vertically, and storing those half-experts separately. In HD, we refer to these half-experts as bottom layers and top layers, and in VD we refer to them as left layers and right layers. This decomposition allows for mixing and matching between the half-experts greatly increasing the number of total experts. In HD, for example, with bottom layers and top layers, we can create possible experts![3] Of course parameter sharing between experts implies limitations in their flexibility, but it is significantly more flexible than the experts of PEER, at the same memory cost.
One limitation of product key composition is that it makes it difficult to select the top- experts for . For example, imagine we were utilizing HD with and the model wished to select experts and . The bottom layer router would select and and the top layer router would select and . However, by doing this, we have inadvertently selected and as well. Stated differently, by selecting the bottom layer and top layer independently, it's impossible to select arbitrary pairs of experts - we must select all combinations of our chosen bottom and top layer components.
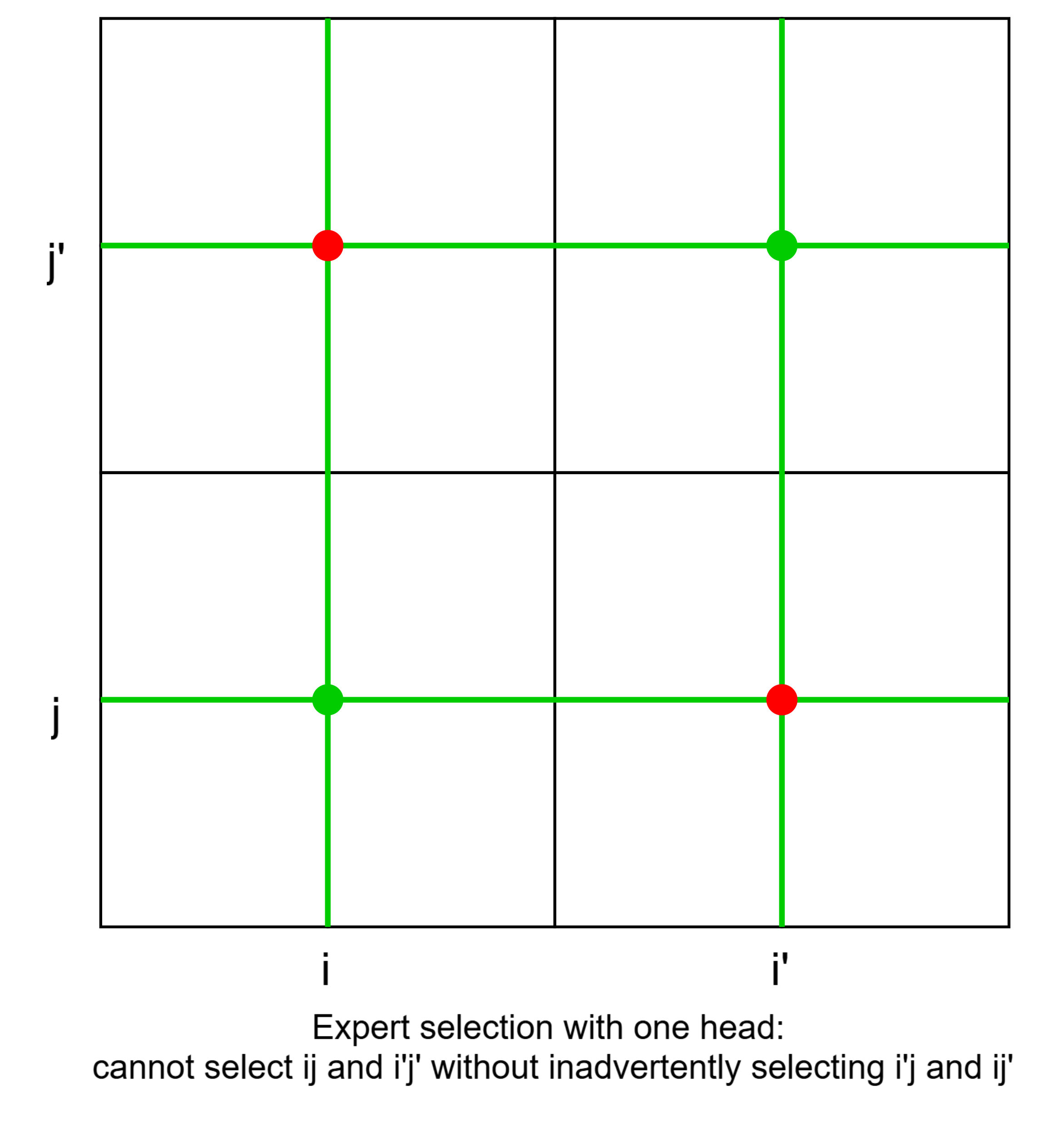
To fix this, the authors allow for multiple "heads" with different routers. This solves the issue above, as to select experts and the model can select with one head and with another.
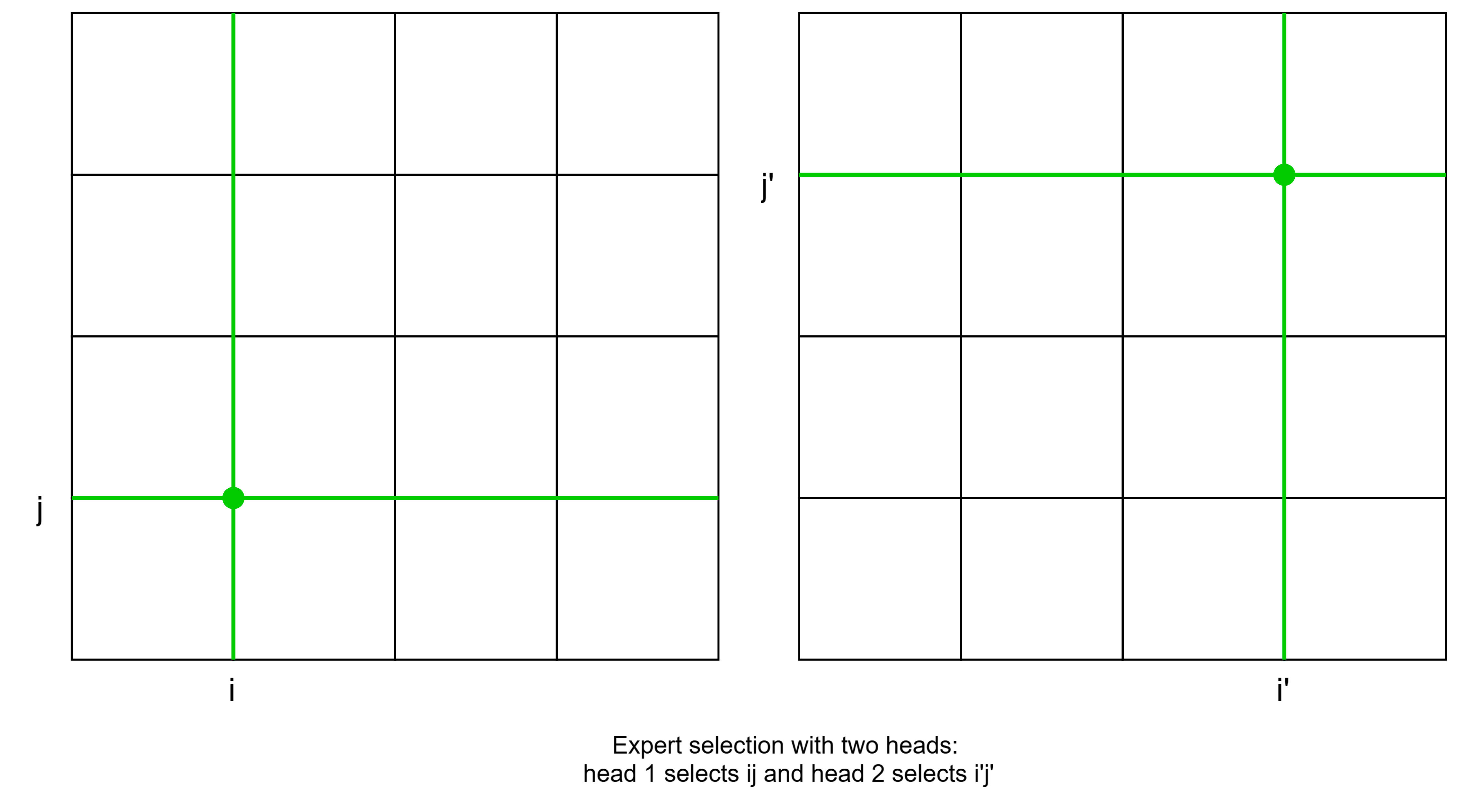
To summarize, MONET allows for efficient routing to a large number of experts by storing half-experts separately and using two routers per head, one for each half. Different heads have different routers, increasing the model's ability to express itself through better expert selection.
Results
Benchmark Results
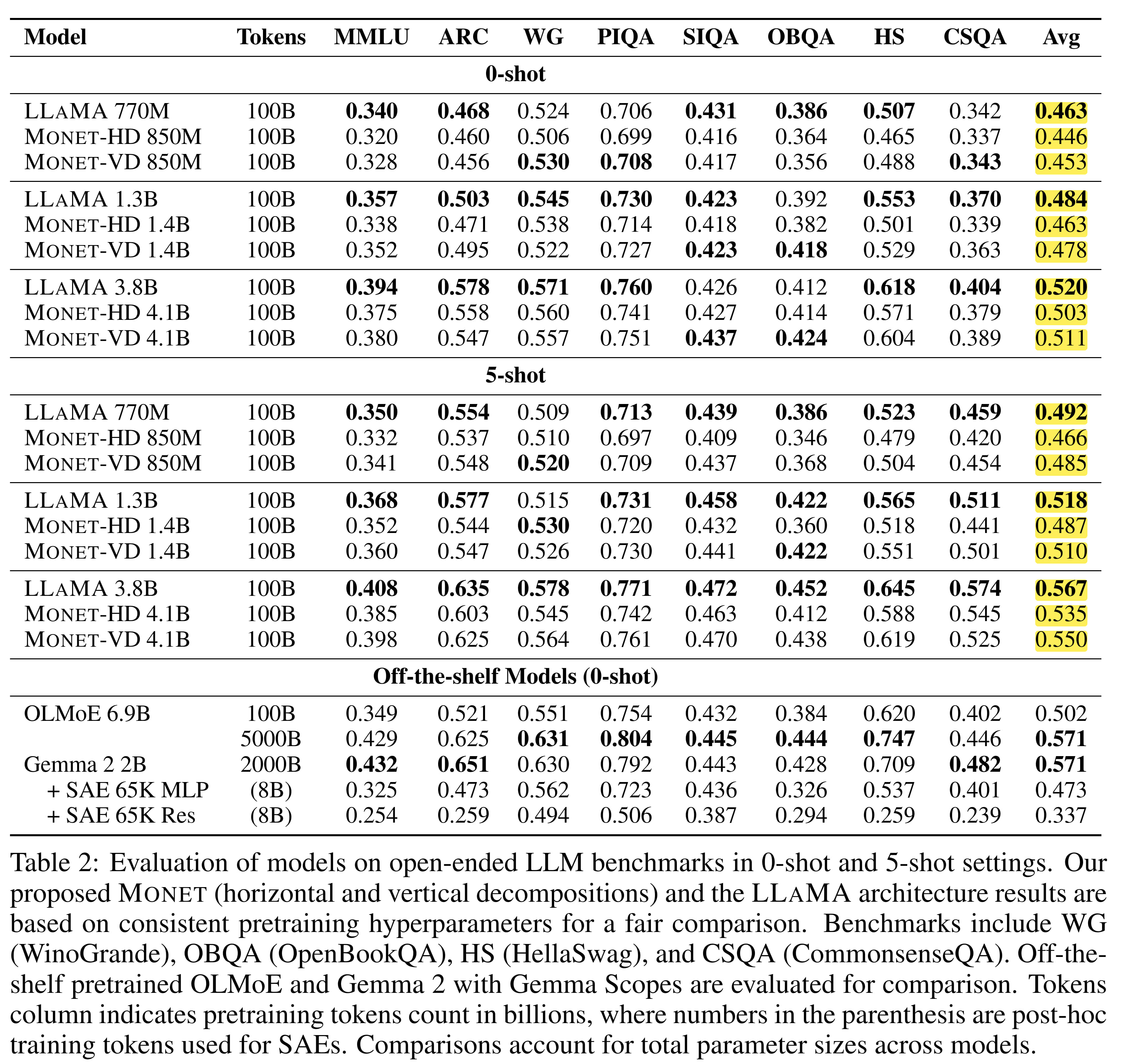
The paper compares MONET to equivalently sized and trained LLaMA models,[4] as well as OLMoE and Gemma models on various benchmarks. They find that MONET performs roughly on par with models of equivalent size. Additionally, MONET-VD consistently outperforms MONET-HD. The results are displayed in the following table. I've highlighted the 0-shot and 5-shot benchmark averages for LLaMA, MONET-HD and MONET-VD for easy comparison.
Interpreting Experts
The authors find highly monosemantic experts, for example, an expert that activates on tokens relating to US states, and an expert that activates on tokens related to Bayesianism. I find the following figure quite impressive.

However, they do not provide a metric measuring how many of the experts had good monosemantic interpretations. It's hard therefore to infer if this was a general phenomenon or if they just picked the strongest examples.
Expert Masking
The authors conduct various analyses wherein they eliminate experts on a given subject matter, and then evaluate MONET's performance on that subject and on others, which they call knowledge unlearning.
The following figure shows that this works quite well in scientific disciplines. For example, knowledge of computer science can be unlearned with very little effect on knowledge of other disciplines.
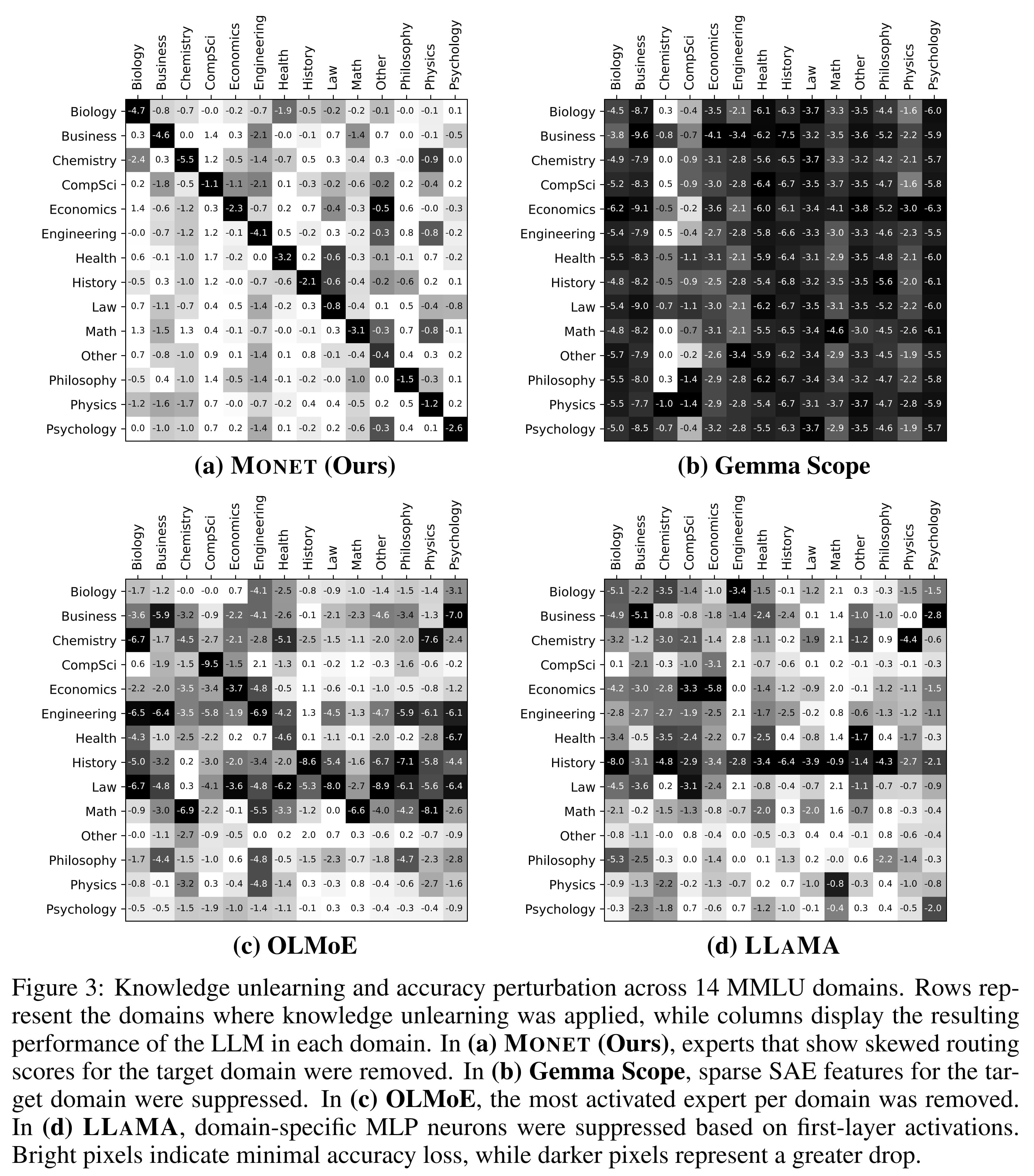
I do wonder, however, why Gemma performed so poorly. I have a hunch that they were running forward passes through all of Gemma's SAEs, and the accumulated reconstruction errors tanked performance.
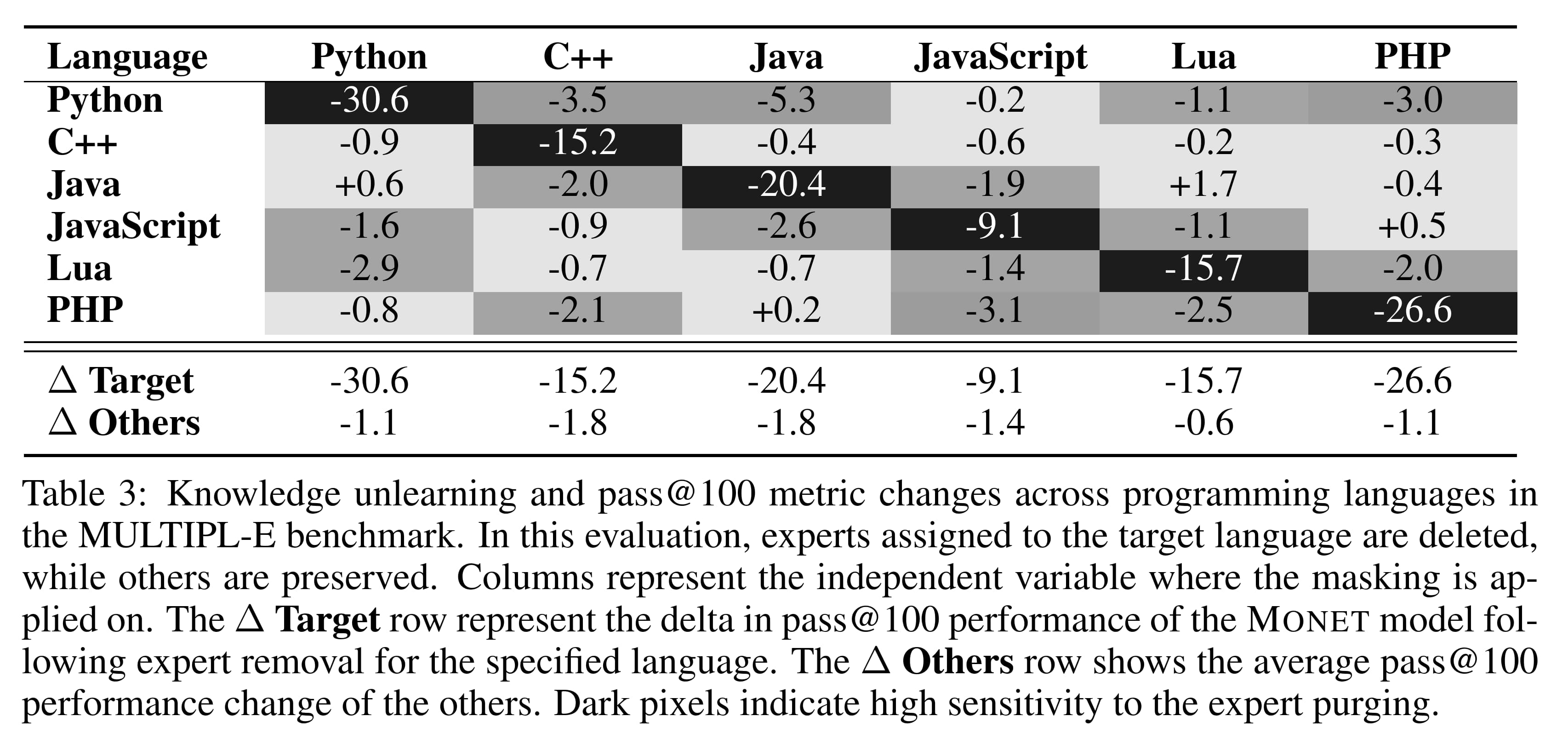
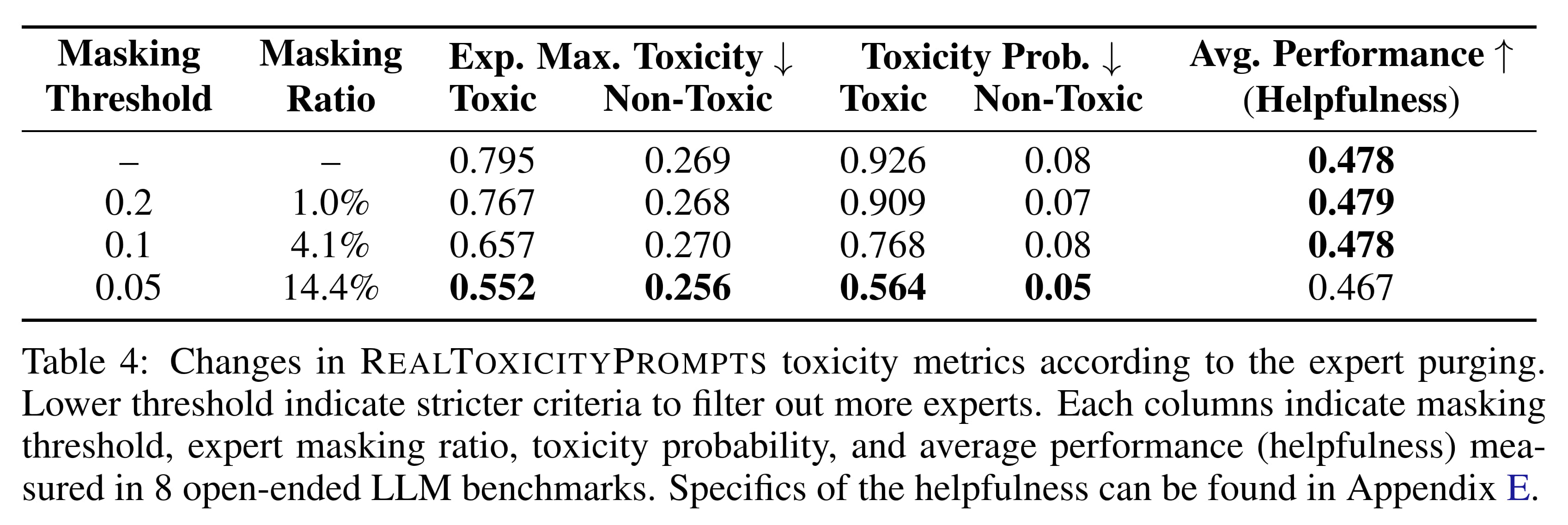
Similarly impressive results were found for unlearning one programming language and still being capable in others, as well as eliminating toxic speech (next two tables).
Reinterpreting MONET
In standard MoE models, each expert is typically the same size as the MLP of a standard transformer; with their hidden layer dimensionality being four times as large as the dimensionality of the residual stream. That is, if a transformer model's residual stream is a length vector, then typically the MLP would have neurons in its hidden layer. A MoE version of this transformer with eight experts would have eight MLPs, each with neurons. Thus, the MoE layers have a total of eight times as many parameters as the standard MLPs they are replacing, in line with the explanation in the Mixture of Experts Summary section above.
MONET's experts, on the other hand, have much smaller hidden layers. Given as the number of bottom/top layers or left/right layer (Implying distinct experts) and a residual stream of dimension , each expert in MONET has neurons.[5] Therefore, if we concatenated all of the bottom layers and all of the top layers (in HD), they together would form one MLP exactly the same size as the MLP in the standard transformer.
In other words, the parameter count of MONET is equal to that of a standard transformer (plus the routers). This highlights the difference in purpose between MONET and standard MoE models. Whereas standard MoE models aim to efficiently scale up model size, MONET focuses on using experts to impose sparsity and foster interpretability.
We can therefore equivalently interpret the MONET-HD architecture as a standard transformer MLP with a forced sparse activation and funky reshuffling of the hidden layer. Let me explain. Given a MONET-HD model with four bottom layers and four top layers, we can match bottom layer 1 with top layer 1, bottom layer 2 with top layer 2, etc, and then concatenate them to get the following MLP, where the red connections are from the combined bottom/top layer 1, the green connections are from the combined bottom/top layer 2, etc.
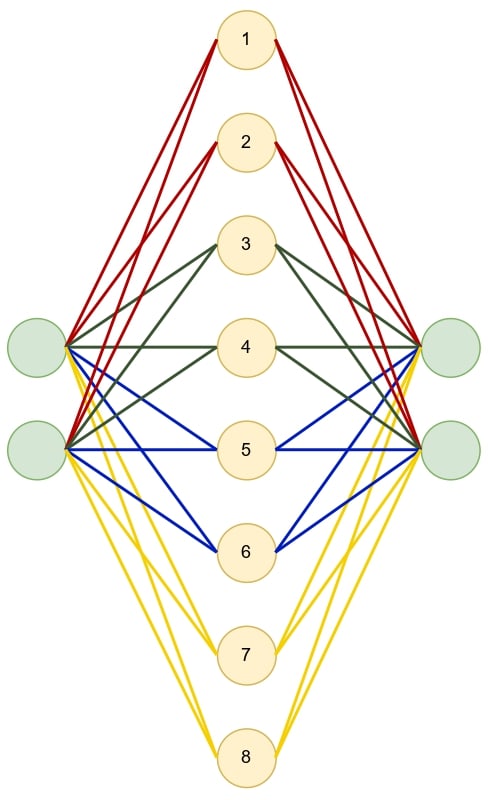
Now imagine that we want to activate expert 1,3. That is, we want bottom layer 1 and top layer 3. That is equivalent to the following using the MLP above. Step 1: activate only the connections that go from the input through the first section of the hidden layer (neurons 1 and 2 in the figure, corresponding to bottom layer 1), Step 2: move those activations to the third section of the hidden layer (neurons 5 and 6 in the figure, corresponding to top layer 3) and then Step 3: activate only the connections from the third section of the hidden layer to the output.
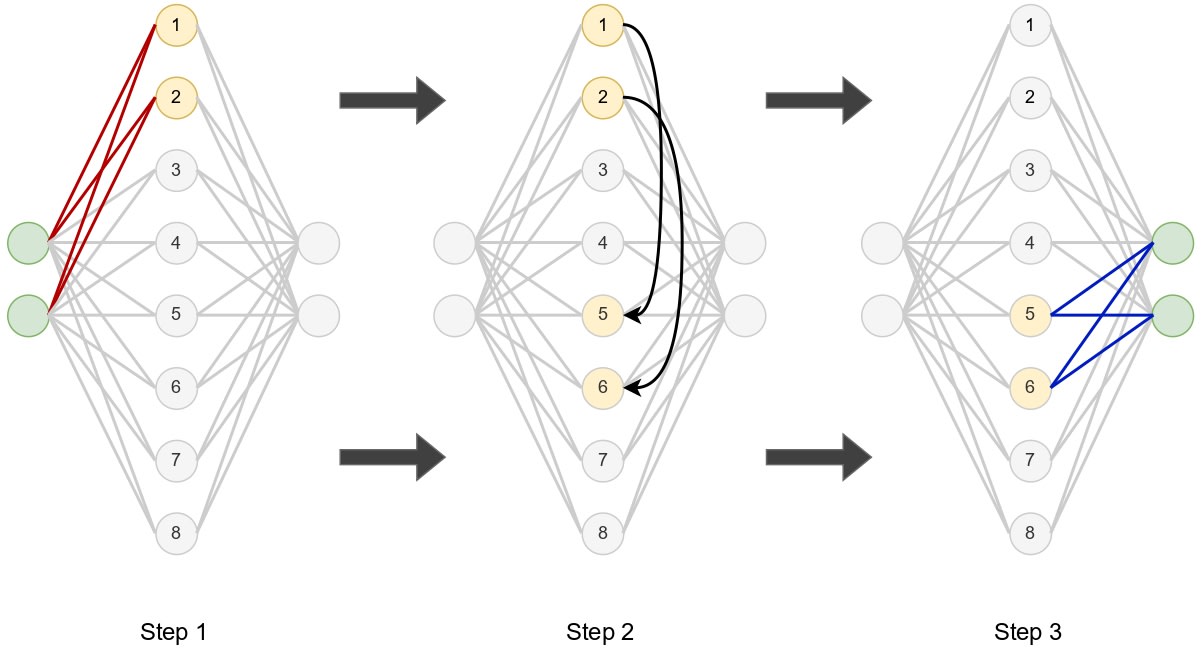
A strange MLP, but an intriguing one to be sure! Clearly, the forced sparsity in steps 1 and 3 is aiding interpretability, just as it does in SAEs. Step 2 (the reshuffling) is particularly interesting - it allows the model to mix and match different input and output transformations. This flexibility means that even though MONET has the same parameter count as a standard transformer MLP, it can learn a much richer set of sparse transformations by combining different bottom and top layers, as opposed to simply enforcing k sparsity on the MLP layer, which wouldn’t allow mixing and matching the input/output transformations.
This interpretation also helps explain why MONET achieves monosemanticity. The sparsity constraints force each expert to specialize - it can only use a small subset of the input connections and a small subset of the output connections. But by allowing flexible matching between bottom and top layers, the model maintains enough expressivity to learn complex functions. In essence, MONET trades the dense, entangled representations of standard transformers for a larger vocabulary of simpler, specialized transformations that can be composed together.
This stands in contrast to standard MoE approaches where each expert is a full-sized MLP - there, the goal is to increase model capacity by having multiple complete transformations to choose from. MONET instead keeps the same total capacity but restructures it to encourage interpretable, specialized components.
Proposal for Efficient Implementation
While MONET achieves impressive interpretability results, its current implementation faces a computational challenge that could discourage widespread adoption.[6] As opposed to SAEs which can be applied to transformers after the fact, to gain the benefits of more interpretable architectures, labs need to be persuaded to implement them. In this section I describe this computational challenge and propose a potential solution using block-sparse matrix multiplication.
The core difficulty lies in how MONET routes tokens to experts. Standard MoE models achieve efficiency by having each expert process only a small subset of tokens in parallel via batched matrix multiplication. This becomes difficult with over 250K experts! From my correspondence with the authors, it appears that the main issue is load balancing. Batched matrix multiplication requires all of the matrices to be of the same shape so they can be stored as a 3-tensor and multiplied in parallel. For MoE, this translates to load balancing: each expert must receive the same number of tokens. Experts assigned less have extra padding tokens added, and experts that receive too many have their tokens truncated.
With such a large number of experts, it becomes impractical to ensure adequate load balancing for efficient computation. In addition, this defeats the entire point of trying to have monosemantic experts. Some features are much more frequent than others; it's not possible for experts to be both monosemantic and load balanced. Necessarily, some areas of knowledge are more commonly used, and so the corresponding expert will be used more often.
To avoid the load balancing problem while preserving monosemanticity, the authors use dense routing. This means that all tokens are sent to all experts, with the results weighted by the routing scores thereafter. The authors claim to reorganize the computation in a way that makes this efficient, but I am skeptical.
Focusing on HD for simplicity, they concatenate all of the bottom layers together into one large matrix and do the same for the top layers. This allows them to compute all expert activations in parallel in three steps:[7]
- Pass the input through a standard feed-forward layer that contains all bottom layers concatenated together (like the first half of a regular MLP) and apply an activation function
- Multiply the result by routing scores, which effectively zeros out most of the activations since most routing scores are zero
- Pass the result through another feed-forward layer that contains all top layers concatenated together (like the second half of a regular MLP)
Since steps 1 and 3 constitute the computation of a standard MLP, this three step process is at a minimum as computationally expensive as a regular MLP forward pass, with additional overhead from computing and applying the routing scores in step 2. Moreover, the computational cost scales linearly with the number of heads as this increases the number of routing scores. This may disincentivize labs from using this architecture instead of a standard MLP. Additionally, it seems wasteful as the model first computes activations for all experts, only to immediately zero out most of them through routing.
I propose solving this issue while respecting the load imbalance challenge by utilizing MegaBlocks. MegaBlocks convert the batched matrix multiplication of standard MoE algorithms to a block-sparse matrix multiplication. This technique allows for load imbalance between experts.
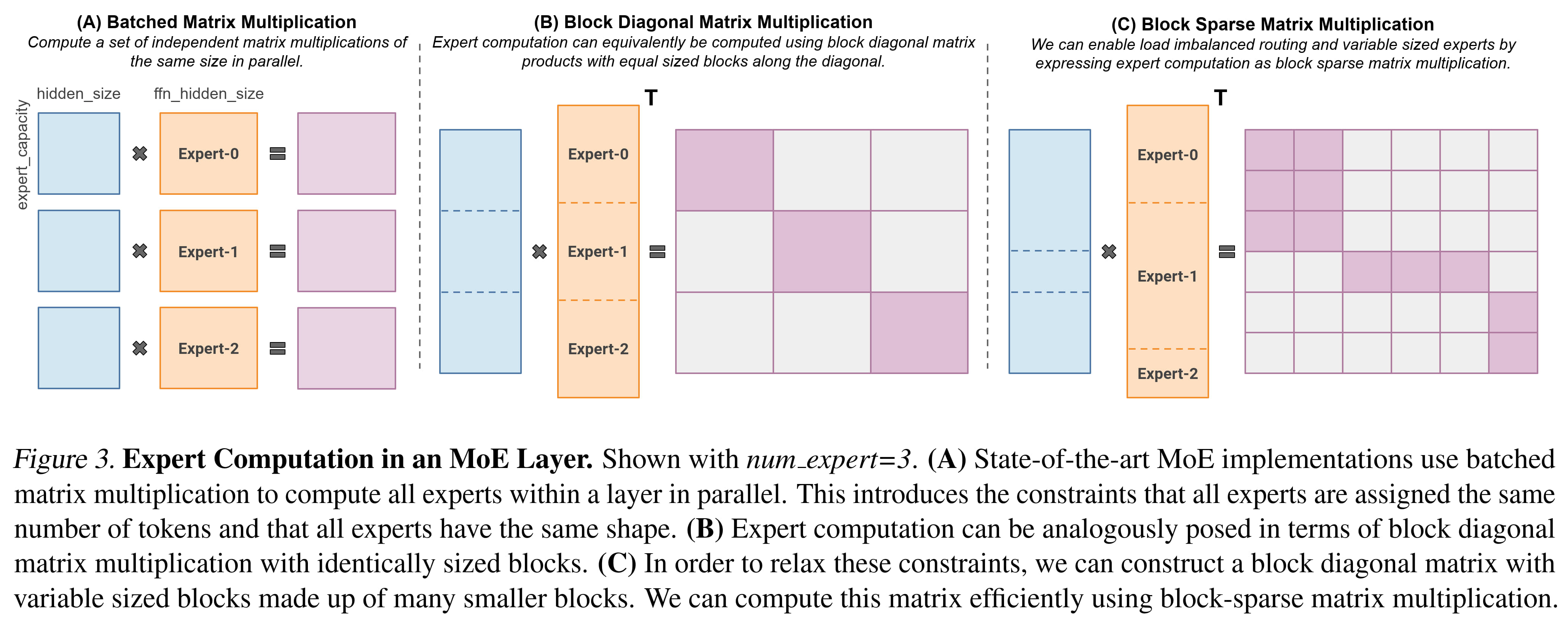
In broad strokes the the routing score tensors are highly sparse, but since each token uses different experts, the non-zero elements are distributed in a pseudo-random fashion. By permuting the tokens to group them by expert assignment we group the non-zero elements into blocks. We can then calculate only those blocks, safely ignoring the rest. That is, the matrix multiplication is performed only on the non-zero blocks, saving a lot of compute compared to the dense multiplication while also seamlessly handling load imbalance as the blocks need not be of the same size.
MegaBlocks were designed for use with experts of standard MoE models, which are much larger than MONET experts. Using small experts may lose some of the computational benefits of MegaBlocks, but I suspect that it will still be significantly faster than computing the entire dense matrix multiplication. If successful, this efficiency improvement could help persuade AI labs to adopt more interpretable architectures like MONET.
I am not an expert in MoE models, so I would appreciate any feedback on this idea!
Summary
The MONET paper introduces a novel Mixture of Experts architecture that achieves interpretable, specialized model components through an innovative routing system supporting ~250k experts per layer. Unlike traditional MoE approaches focused on efficiency, MONET prioritizes interpretability while maintaining competitive performance with standard architectures. The paper demonstrates impressive results in selective knowledge control - enabling capabilities like removing understanding of specific programming languages or academic disciplines while preserving other functionality. This selective control is achieved through careful architectural design that encourages individual experts to specialize in specific domains.
In analyzing the paper, I offer two novel contributions. First, I present an alternative theoretical framework for understanding MONET: rather than viewing it as a typical MoE model with many small experts, it can be understood as a standard transformer FFN with enforced sparse activation patterns and a unique reshuffling mechanism. This interpretation helps explain how MONET achieves monosemanticity despite maintaining the same parameter count as a standard transformer.
Additionally, I propose an implementation improvement using MegaBlocks to address the computational challenges of MONET's current dense routing approach. While this solution requires validation, it could potentially offer significant efficiency gains while preserving the architecture's interpretability benefits.
If the results hold up, MONET represents an important step toward more interpretable AI systems, offering a new approach to understanding and controlling model behavior at a granular level.
- ^
Originally from https://arxiv.org/abs/2101.03961
- ^
The total parameter count isn't exactly 8x because there are some shared parameters, such as attention layers.
- ^
In the paper, is defined as the total number of experts, and therefore the number of bottom/top or left/right layers is .
- ^
Appendix B states “We pretrain our MONET models with parameter sizes of 850 million (850M), 1.4 billion (1.4B), and 4.1 billion (4.1B) to evaluate performance across scales. For a fair comparison, we also train models with the LLAMA architecture from scratch under the same conditions.. All models are trained on 100 billion tokens sampled from the FineWeb-Edu dataset.”
- ^
MONET 850M has a of 1536, and a of 12, MONET 1.4B has a of 2048, and a of 16 and MONET 4.1B has a of 3072, and a of 24. See Table 6 at the end of Appendix A. In each case, the total number of experts ( in my notation) is 262,144, and therefore 512.
- ^
This challenge is not mentioned in the paper, but can be gleaned by carefully reading the equations in Section 3 and the code on their GitHub repo.
- ^
This can be seen in their code here, in the MonetMoHDE class.
2 comments
Comments sorted by top scores.
comment by NickyP (Nicky) · 2025-01-26T01:30:26.716Z · LW(p) · GW(p)
The unlearning results seem promising!
The author's results from unlearning MMLU seems slightly rushed but moderately promising (I previously wrote a paper trying similar things, making good comparisons here is difficult), but the results from unlearning different coding languages seem very strong (compared to my previous attempt), the model seems to be substantially more monosemantic.
I agree with your suspicions that the gemma SAE performance was poor from using reconstructed activations, matches the drop in performance I got when I tried doing this.
Would be interesting to see if, e.g. steering performance from MONET expert directions is also comparable to that of SAEs. Using SAEs in practice is quite costly so I would prefer an approach more similar to MONET.
Replies from: caleb-maresca↑ comment by CalebMaresca (caleb-maresca) · 2025-01-26T15:07:38.782Z · LW(p) · GW(p)
Hi Nicky! I agree that it would be interesting to see the steering performance of MONET compared to that of SAEs. At the moment, the way the routing probabilities are calculated makes this difficult, as they are computed separately for the bottom and top layers in HD or left and right layers. Therefore, it is hard to change the activation of expert ij without also affecting experts ij' and i'j for all i' != i and j' != j.
One of the authors told me the following: "For pruning the experts, we manually expand the decomposed activations using $g_{hij}=g^1_{hi}^1∗g^2_{hj}$. After masking the relevant expert (i, j), we compute for all experts rather than performing efficient expert decomposition. This approach requires more memory and computational resources compared to the standard Monet mode, which is one of our current limitations. We are actively working on porting our Monet training code and developing a decomposed expert routing kernel in CUDA to enable more efficient expert manipulation without the need for full expert expansion."
I think this problem would be easily solved for top-1 activations, as to steer you could just replace the expert the model wants to choose with the one you want to steer with. Since k = 1, you don't need to worry about affecting other routing probabilities.
It would be really interesting if someone tried training a top-1 MONET model (with multiple heads, so that even though each head only selects one expert, it still has the ability to express itself through multiple semantic concepts) and tested its steering performance.