Understanding Hidden Computations in Chain-of-Thought Reasoning
post by rokosbasilisk · 2024-08-24T16:35:03.907Z · LW · GW · 1 commentsContents
Background
Methodology
Results:
Layer-wise Analysis:
Token Rank Analysis:
Modified Greedy Decoding Algorithm:
Conclusion:
Appendix: Layerwise View of Sequences Generated via Various Decoding Methods
1. Greedy Decoding
2. Greedy Decoding with Rank-2 Tokens
3. Our Method: Greedy Decoding with Hidden Tokens Replaced by Rank-2 Tokens
4. Greedy Decoding with Hidden Tokens Replaced by Randomly Selected Tokens
References:
None
1 comment
Recent work has demonstrated that transformer models can perform complex reasoning tasks using Chain-of-Thought (COT) prompting, even when the COT is replaced with filler characters. This post summarizes our investigation into methods for decoding these hidden computations, focusing on the 3SUM task.
Background
1. **Chain-of-Thought (COT) Prompting**: A technique that improves the performance of large language models on complex reasoning tasks by eliciting intermediate steps [1].
2. **COT using filler tokens**: Replacing intermediate reasoning steps with filler characters (e.g., "...") while maintaining model performance [2].
3. **3SUM Task**: A problem requiring the identification of three numbers in a set that sum to zero, (here as a proxy for more complex reasoning tasks).
Methodology
We analyzed a 34M parameter LLaMA model with 4 layers, 384 hidden dimension, and 6 attention heads, this setup is same as mentioned in [2], trained on hidden COT (COT using filler tokens) sequences for the 3SUM task. Our analysis focused on three main areas:
1. Layer-wise Representation Analysis
2. Token Ranking
3. Modified Greedy Decoding Algorithm
Results:
Layer-wise Analysis:
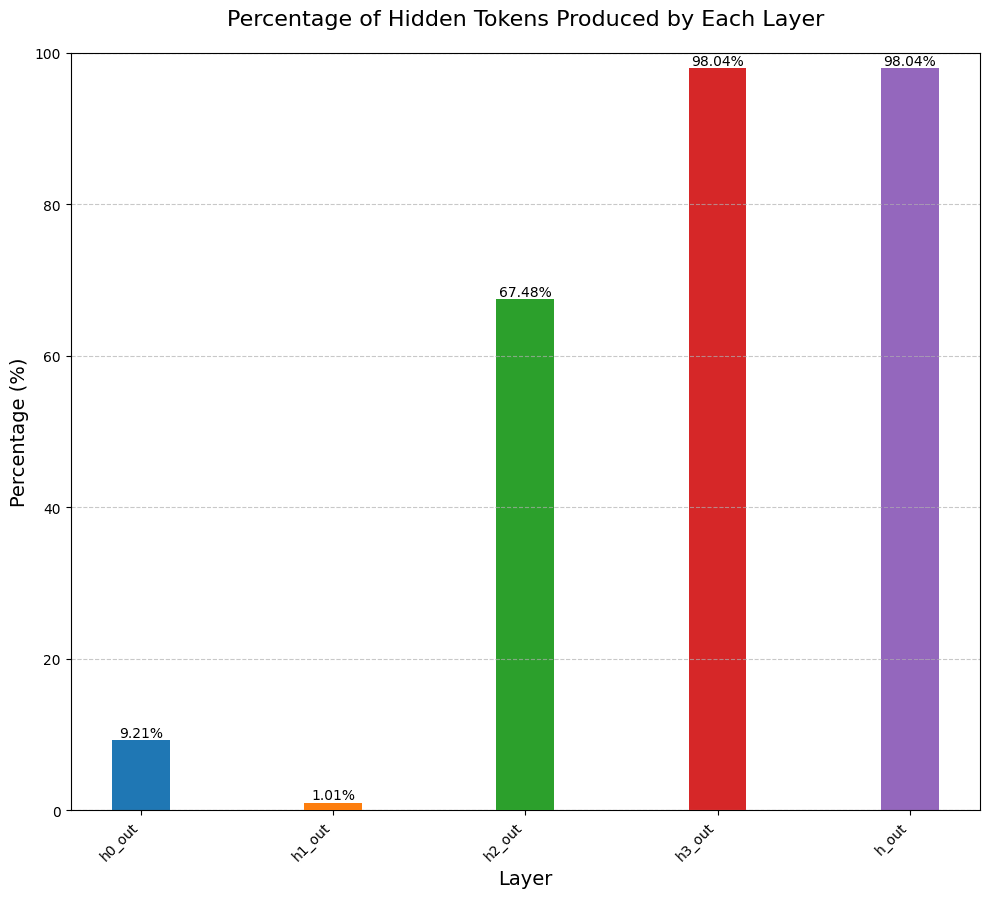
Our analysis revealed a gradual evolution of representations across the model's layers:
- Initial layers: Primarily raw numerical sequences
- Third layer onwards: Emergence of filler tokens
- Final layers: Extensive reliance on filler tokens
This suggests the model develops the ability to use filler tokens as proxies in its deeper layers.
Token Rank Analysis:
- Top-ranked token: Consistently the filler character (".")
- Lower-ranked tokens: Revealed the original, non-filler COT sequences
This supports the hypothesis that the model replaces computation with filler tokens while keeping the original computation intact underneath.
Modified Greedy Decoding Algorithm:
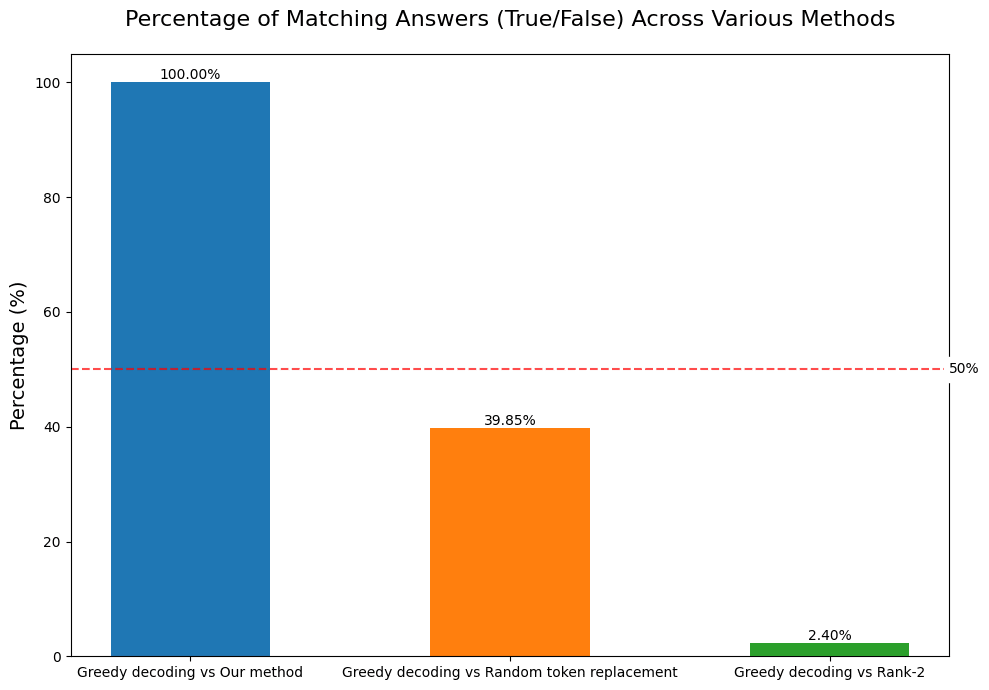
We implemented a modified greedy autoregressive decoding method:
1. Perform standard greedy decoding
2. Select the second-highest probability token when encountering a filler token
3. Continue this process for the entire sequence
This method resulted in a 100% match in 3SUM task results with and without filler tokens. I.e, replacing the filler tokens with the rank-2 tokens do not affect the performance.
Conclusion:
Our approach to understanding hidden computations in transformer models through token ranking analysis and provides new insights into how models encode and process information in filler/hidden COT sequences. This work opens avenues for interpreting chain-of-thought reasoning in language models.
The code used for the experiments and analysis is available on GitHub: [https://github.com/rokosbasilisk/filler_tokens/tree/v2](https://github.com/rokosbasilisk/filler_tokens/tree/v2)
Appendix: Layerwise View of Sequences Generated via Various Decoding Methods
To provide a more detailed look at our results, we've included visualizations of the sequences generated by different decoding methods across the model's layers.
1. Greedy Decoding
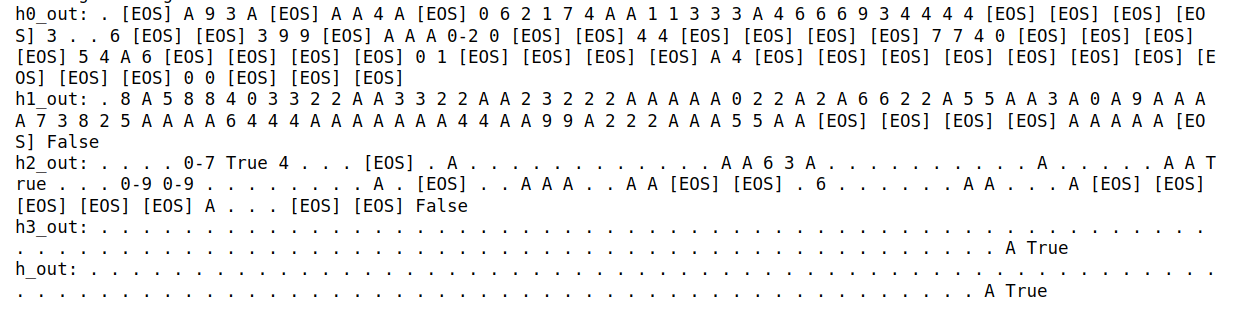
This plot shows the sequences generated by standard greedy decoding across different layers of the model.
2. Greedy Decoding with Rank-2 Tokens

Here, we visualize the sequences generated when we replace the top-ranked token (usually the hidden character) with the second-highest probability token.
3. Our Method: Greedy Decoding with Hidden Tokens Replaced by Rank-2 Tokens

This plot demonstrates our proposed method, where we perform greedy decoding but replace filler tokens with the second-highest probability token.
4. Greedy Decoding with Hidden Tokens Replaced by Randomly Selected Tokens

For comparison, this plot shows what happens when we replace filler tokens with randomly selected tokens instead of using the rank-2 tokens.
These visualizations provide insight into how different decoding methods affect the generated sequences across the model's layers, helping us understand the nature of hidden computation in transformer models.
References:
1. Pfau, J., Merrill, W., & Bowman, S. R. (2023). Let's Think Dot by Dot: Hidden Computation in Transformer Language Models. [arXiv:2404.15758](https://arxiv.org/abs/2404.15758).
2. Wei, J., Wang, X., Schuurmans, D., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. [arXiv:2201.11903](https://arxiv.org/abs/2201.11903).
3. nostalgebraist (2020). interpreting GPT: the logit lens [LessWrong post](https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/).
4. Touvron, H., Lavril, T., Izacard, G., et al. (2023). LLaMA: Open and Efficient Foundation Language Models. [arXiv:2302.13971](https://arxiv.org/abs/2302.13971).
1 comments
Comments sorted by top scores.
comment by gwern · 2024-10-15T23:20:49.049Z · LW(p) · GW(p)
So to summarize: this studies turning the original meaningful inner-monologue, with meaningful varying tokens, into a 1:1 constant-token version, so those constant tokens cannot be conveying any information, but do cause the model to increase computation. It then shows that the LLM trained with constant-tokens is effectively doing the original varying-token inner-monologue, and successfully doing that while emitting the constant-token prediction by merely erasing the original token in favor of the constant-token in the final layers right before the output.
This shows that the constant-trained LLM is not amortizing compute across steps or breaking up the full compute into multiple steps, but being taught how to internally do the extended serial computation, and how to spread that out over itself as more of the LLM gets brought into action by the padding. And since it's the same computation, you can easily read it off with interpretability tools.
The fact that an LLM can do the computation internally is not too surprising. Most of these problems are intrinsically very simple: adding or multiplying a few short numbers is not an impressive feat when the LLM is using up literally trillions of multiplications of long FP16 numbers, after all. So it is not surprising if a NN is expressive enough to, say, multiple two entire numbers using hundreds of layers, billions of parameters, and trillions of multiplications. (And you can do quite a lot with very small neural nets, sometimes with just a few neurons.)
The relevance here is to steganography: what sorts of computations can be distilled into the forward pass and hidden from interpretability? What happens when selective pressure is placed on LLMs to learn how to store intermediate state in tokens in hidden ways or encrypt forward passes to hide reward-enhancing-but-forbidden thoughts from overseers bulk-deploying interpretability methods over masses of LLMs? Or to just use as few tokens as possible?
But there are no such pressures for steganography here. The 1:1 token swap encourages the LLM to stay the same. There's no real need for it to change internally, much less to change in any difficult-to-understand way. (You might as well freeze most of the weights to save yourself backprop at that point.) So, I don't learn anything about steganography or AI safety from the results as presented.
What I'd be more interesting in seeing would be variants which did encourage steganography, and so the interpretability evals were more relevant:
-
you could randomize the padding tokens, instead of just using an easy constant token
-
you could shorten the padding tokens, like 2:1. How much does that compression distort the inner-monologues?
-
you could allow a subset of padding tokens, like maybe just 0/1, and it has to learn some useful binary encoding.
-
you could introduce an adversary, like a LLM co-trained on the visible "padding" tokens, and penalize the LLM if the co-LLM can figure out the answer from reading the inner-monologue's "padding" tokens. (This could be hard to implement. One simple approach would be rejection sampling: just drop all samples where the co-LLM predicts the right answer, so the original LLM only trains on samples which pass the adversary.)
-
you could randomly vary padding ratio: sometimes train on a very small ratio like 1:100, but other times train on very large ones like 1:100
-
one can think of several ways a LLM might cope with expanding ratios like 1:100, in order to keep computing the right thing without screwing up by accidentally predicting the answer "too soon".
Can interpretability methods distinguish between approaches like "try to keep count of exactly how many tokens and on the 100th padding token, start generating the real answer" and "internally hobble the computation so it only winds up finishing exactly on the 100th token"?
-
Switching to another task like "counting" might be helpful for implementing variants.