Multi-agent predictive minds and AI alignment
post by Jan_Kulveit · 2018-12-12T23:48:03.155Z · LW · GW · 18 commentsContents
How minds work Problems with prevailing value learning approaches No clear distinction between goals and beliefs No clear self-alignment What we are aligning AI with Rider-centric and meme-centric alignment Metapreferences and multi-agent alignment Implications Upside Suggested technical research directions Understanding hierarchical modelling. Inverse Game Theory. Learning from multiple agents. What happens if you put a system composed of sub-agents under optimization pressure? What happens if you make a system composed of sub-agents less computationally bounded? Suggested non-technical research directions Human self-alignment. Notes & Discussion Motivations Multi-part minds in literature Discussion None 18 comments
Abstract: An attempt to map a best-guess model of how human values and motivations work to several more technical research questions. The mind-model is inspired by predictive processing / active inference framework and multi-agent models of the mind.
The text has slightly unusual epistemic structure:
1st part: my current best-guess model of how human minds work.
2nd part: explores various problems which such mind architecture would pose for some approaches to value learning. The argument is: if such a model seems at least plausible, we should probably extend the space of active research directions.
3rd part: a list of specific research agendas, sometimes specific research questions, motivated by the previous.
I put more credence in the usefulness of research questions suggested in the third part than in the specifics of the model described the first part. Also, you should be warned I have no formal training in cognitive neuroscience and similar fields, and it is completely possible I’m making some basic mistakes. Still, my feeling is even if the model described in the first part is wrong, something from the broad class of “motivational systems not naturally described by utility functions” is close to reality, and understanding problems from the 3rd part can be useful.
How minds work
As noted, this is a “best guess model”. I have large uncertainty about how human minds actually work. But if I could place just one bet, I would bet on this.
The model has two prerequisite ideas: predictive processing and the active inference framework. I'll give brief summaries and links for elsewhere.
In the predictive processing / the active inference framework, brains constantly predict sensory inputs, in a hierarchical generative way. As a dual, action is also “generated” by the same machinery (changing environment to match “predicted” desirable inputs and generating action which can lead to them). The “currency” on which the whole system is running is prediction error (or something in style of free energy, in that language).
Another important ingredient is bounded rationality, i.e. a limited amount of resources being available for cognition. Indeed, the specifics of hierarchical modelling, neural architectures, principle of reusing and repurposing everything, all seem to be related to quite brutal optimization pressure, likely related to brain’s enormous energy consumption (It is unclear to me if this can be also reduced to the same “currency”. Karl Friston would probably answer "yes").
Assuming this whole, how do motivations and “values” arise? The guess is, in many cases something like a “subprogram” is modelling/tracking some variable, “predicting” its desirable state, and creating the need for action by “signalling” prediction error. Note that such subprograms can work on variables on very different hierarchical layers of modelling - e.g. tracking a simple variable like “feeling hungry” vs. tracking a variable like “social status”. Such sub-systems can be large: for example tracking “social status” seems to require lot of computation.
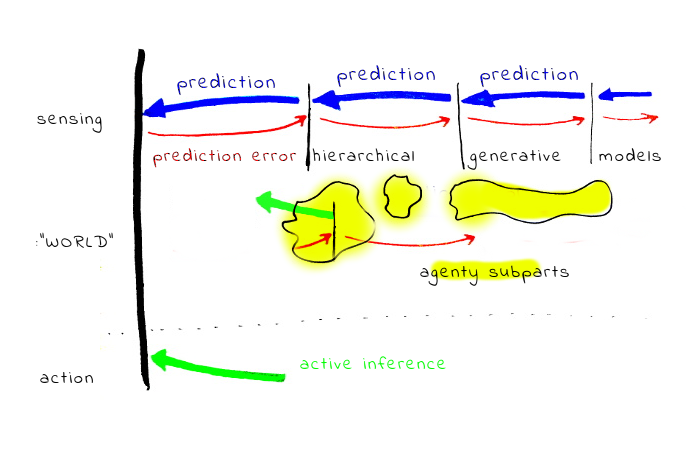
How does this relate to emotions? Emotions could be quite complex processes, where some higher-level modelling (“I see a lion”) leads to a response in lower levels connected to body states, some chemicals are released, and this interoceptive sensation is re-integrated in the higher levels in the form of emotional state, eventually reaching consciousness. Note that the emotional signal from the body is more similar to “sensory” data - the guess is body/low level responses are a way how genes insert a reward signal into the whole system.
How does this relate to our conscious experience, and stuff like Kahneman's System 1/System 2? It seems for most people the light of consciousness is illuminating only a tiny part of the computation, and most stuff is happening in the background. Also, S1 has much larger computing power. On the other hand it seems relatively easy to “spawn background processes” from the conscious part, and it seems possible to illuminate larger part of the background processing than is usually visible through specialized techniques and efforts (for example, some meditation techniques).
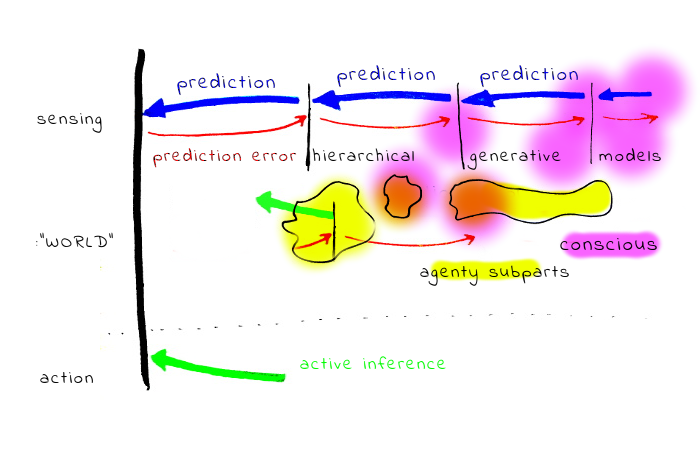
Another ingredient is the observation that a big part of what the conscious self is doing is interacting with other people, and rationalizing our behaviour. (Cf. press secretary theory, elephant in the brain [LW · GW].) It is also quite possible the relation between acting rationally and the ability to rationalize what we did is bidirectional, and significant part of motivation for some rational behaviour is that it is easy to rationalize it.
Also, it seems important to appreciate that the most important part of the human “environment” are other people, and what human minds are often doing is likely simulating other human minds (even simulating how other people would be simulating someone else!).
Problems with prevailing value learning approaches
While the above sketched picture is just a best guess, it seems to me at least compelling. At the same time, there are notable points of tension between it and at least some approaches to AI alignment.
No clear distinction between goals and beliefs
In this model, it is hardly possible to disentangle “beliefs” and “motivations” (or values). “Motivations” interface with the world only via a complex machinery of hierarchical generative models containing all other sorts of “beliefs”.
To appreciate the problems for the value learning program, consider a case of someone who’s predictive/generative model strongly predicts failure and suffering. Such person may take actions which actually lead to this outcome, minimizing the prediction error.
Less extreme but also important problem is that extrapolating “values” outside of the area of validity of generative models is problematic and could be fundamentally ill-defined. (This is related to “ontological crisis”.)
No clear self-alignment
It seems plausible the common formalism of agents with utility functions is more adequate for describing the individual “subsystems” than the whole human minds. Decisions on the whole mind level are more like results of interactions between the sub-agents; results of multi-agent interaction are not in general an object which is naturally represented by utility function. For example, consider the sequence of game outcomes in repeated PD game. If you take the sequence of game outcomes (e.g. 1: defect-defect, 2:cooperate-defect, ... ) as a sequence of actions, the actions are not representing some well behaved preferences, and in general not maximizing some utility function.
Note: This is not to claim VNM rationality is useless - it still has the normative power - and some types of interaction lead humans to approximate SEU optimizing agents better.
One case is if mainly one specific subsystem (subagent) is in control, and the decision does not go via too complex generative modelling. So, we should expect more VNM-like behaviour in experiments in narrow domains than in cases where very different sub-agents are engaged and disagree.
Another case is if sub-agents are able to do some “social welfare function” style aggregation, bargain, or trade - the result could be more VNM-like, at least in specific points of time, with the caveat that such “point” aggregate function may not be preserved in time.
On the contrary, cases where the resulting behaviour is very different from VNM-like may be caused by sub-agents locked in some non-cooperative Nash equilibria.
What we are aligning AI with
Given this distinction between the whole mind and sub-agents, there are at least four somewhat different notions of what alignment can mean.
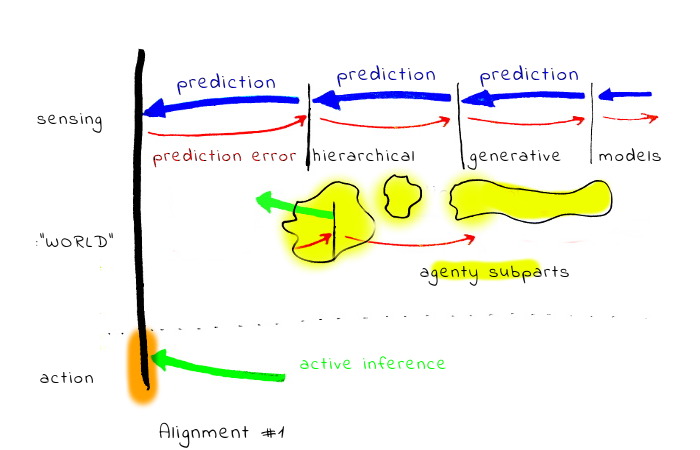
1. Alignment with the outputs of the generative models, without querying the human. This includes for example proposals centered around approval. In this case, generally only the output of the internal aggregation has some voice.
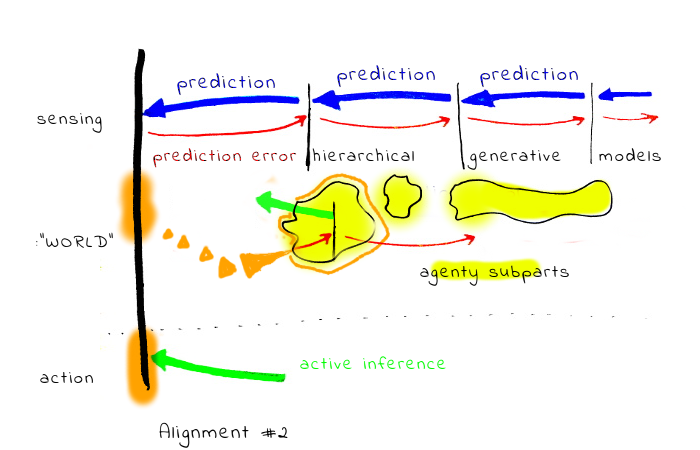
2. Alignment with the outputs of the generative models, with querying the human. This includes for example CIRL and similar approaches. The problematic part of this is, by carefully crafted queries, it is possible to give voice to different sub-agenty systems (or with more nuance, give them very different power in the aggregation process). One problem with this is, if the internal human system is not self-aligned, the results could be quite arbitrary (and the AI agent has a lot of power to manipulate)
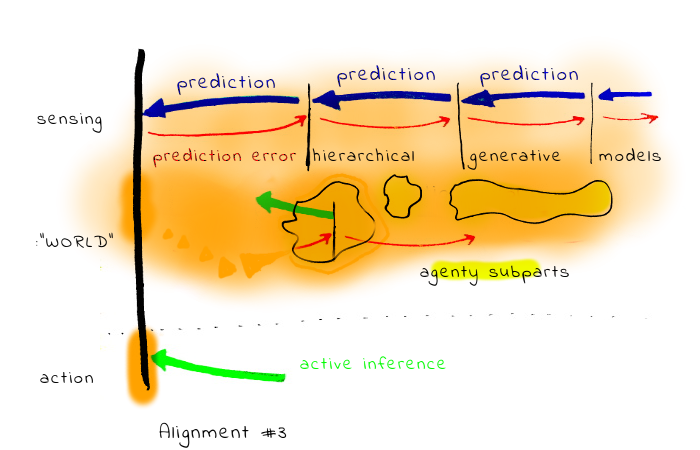
3. Alignment with the whole system, including the human aggregation process itself. This could include for example some deep NN based black-box trained on a large amount of human data, predicting what would the human want (or approve).
4. Adding layers of indirection to the question, such as defining alignment as a state where the “A is trying to do what H wants it to do.”
In practice, options 1. and 2. can collapse into one, as far as there is some feedback loop between the AI agent actions and the human reward signal. (Even in case 1, the agent can take an action with the intention to elicit feedback from some subpart.)
We can construct a rich space of various meanings of "alignment" by combining basic directions.
Now, we can analyze how these options interact with various alignment research programs.
Probably the most interesting case is IDA [LW · GW]. IDA-like schemes can probably carry forward arbitrary properties to more powerful systems, as long as we are able to construct the individual step preserving the property. (I.e. one full cycle of distillation and amplification, which can be arbitrarily small).
Distilling and amplifying the alignment in sense #1 (what the human will actually approve) is conceptually easiest, but, unfortunately, brings some of the problems of potentially super-human system optimizing for manipulating the human for approval.
Alignment in sense #3 creates a very different set of problems. One obvious risk are mind-crimes. More subtle risk is related to the fact that as the implicit model of human “wants” scales (becomes less bounded), I. the parts may scale at different rates II. the outcome equilibria may change even if the sub-parts scale at the same rate.
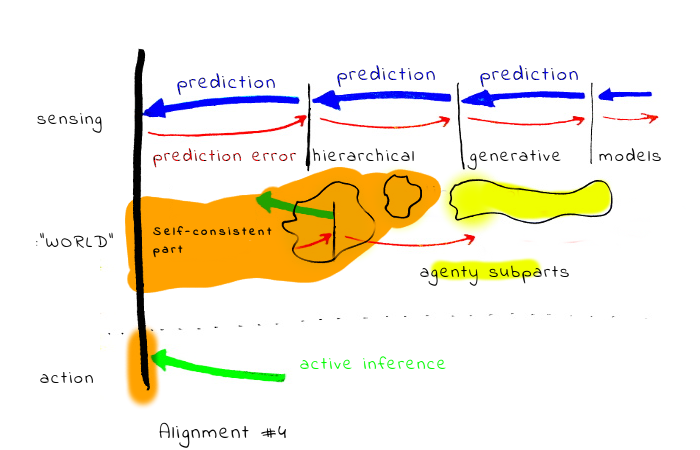
Alignment in sense #4 seems more vague, and moves the burden of understanding the problem in part to the side of the AI. We can imagine that at the end the AI will be aligned with some part of the human mind in a self-consistent way (the part will be a fixed point of the alignment structure). Unfortunately, it is a priori unclear if a unique fixed point exists. If not, the problems become similar to case #2. Also, it seems inevitable the AI will need to contain some structure representing what the human wants the AI to do, which may cause problems similar to #3.
Also, in comparison with other meanings, it is much less clear to me how to even establish some system has this property.
Rider-centric and meme-centric alignment
Many alignment proposals seem to focus on interacting just with the conscious, narrating and rationalizing part of mind. If this is just a one part entangled in some complex interaction with other parts, there are specific reasons why this may be problematic.
One: if the “rider” (from the rider/elephant metaphor) is the part highly engaged with tracking societal rules, interactions and memes. It seems plausible the “values” learned from it will be mostly aligned with societal norms and interests of memeplexes, and not “fully human”.
This is worrisome: from a meme-centric perspective, humans are just a substrate, and not necessarily the best one. Also - a more speculative problem may be - schemes learning human memetic landscape and “supercharging it” with superhuman performance may create some hard to predict evolutionary optimization processes.
Metapreferences and multi-agent alignment
Individual “preferences” can often in fact be mostly a meta-preference to have preferences compatible with other people, based on simulations of such people.
This may make it surprisingly hard to infer human values by trying to learn what individual humans want without the social context (necessitating inverting several layers of simulation). If this is the case, the whole approach of extracting individual preferences from a single human could be problematic. (This is probably more relevant to some “prosaic” alignment problems)
Implications
Some of the above mentioned points of disagreements point toward specific ways how some of the existing approaches to value alignment may fail. Several illustrative examples:
- Internal conflict may lead to inaction (also to not expressing approval or disapproval). While many existing approaches represent such situation only by the outcome of the conflict, the internal experience of the human seems to be quite different with and without the conflict
- Difficulty with splitting “beliefs” and “motivations”.
- Learning inadequate societal equilibria and optimizing on them.
Upside
On the positive side, it could be expected the sub-agents still easily agree on things like “it is better not to die a horrible death”.
Also, the mind-model with bounded sub-agents which interact only with their local neighborhood and do not actually care about the world may be a viable design from the safety perspective.
Suggested technical research directions
While the previous parts are more in backward-chaining mode, here I attempt to point toward more concrete research agendas and questions where we can plausibly improve our understanding either by developing theory, or experimenting with toy models based on current ML techniques.
Often it may be the case that some research was already done on the topic, just not with AI alignment in mind, and a high value work could be “importing the knowledge” into safety community.
Understanding hierarchical modelling.
It seems plausible the human hierarchical models of the world optimize some "boundedly rational" function. (Remembering all details is too expensive, too much coarse-graining decreases usefulness. A good bounded rationality model can work as a principle for how to select models. In a similar way to the minimum description length principle, just taking some more “human” (energy?) costs as cost function.)
Inverse Game Theory.
Inverting agent motivations in MDPs is a different problem from inverting motivations in multi-agent situations where game-theory style interactions occur. This leads to the inverse game theory problem: observe the interactions, learn the objectives.
Learning from multiple agents.
Imagine a group of five closely interacting humans. Learning values just from person A may run into the problem that big part of A’s motivation is based on A simulating B,C,D,E (on the same “human” hardware, just incorporating individual differences). In that case, learning the “values” just from A’s actions could be in principle more difficult than observing the whole group, trying to learn some “human universals” and some “human specifics”. A different way of thinking about this could be by making a parallel with meta-learning algorithms (e.g. REPTILE) but in IRL frame.
What happens if you put a system composed of sub-agents under optimization pressure?
It is not clear to me what would happen if you, for example, successfully “learn” such a system of “motivations” from a human, and then put it inside of some optimization process selecting for VNM-like rational behaviour.
It seems plausible the somewhat messy system will be forced to get more internally aligned; for example, one way how it can happen is one of the sub-agent systems takes control and “wipes out the opposition”.
What happens if you make a system composed of sub-agents less computationally bounded?
It is not clear that the relative powers of sub-agents will scale the same with the whole system becoming less computationally bounded. (This is related to MIRI’s sub-agents agenda)
Suggested non-technical research directions
Human self-alignment.
All other things being equal, it seem safer to try to align AI with humans which are self-aligned.
Notes & Discussion
Motivations
Part of my motivation for writing this was an annoyance: there is a plenty of reasons to believe the view
- human mind is a unified whole,
- at first approximation optimizing some utility function,
- this utility is over world-states,
is neither a good model of humans, nor the best model how to think about AI. Yet, it is the paradigm shaping a lot of thoughts and research. I hope if the annoyance surfaced in the text, it is not too distractive.
Multi-part minds in literature
There are dozens of schemes describing mind as some sort of multi-part system, so there is nothing original about this claim. Based on a very shallow review, it seems the way how psychologists often conceptualize the sub-agents is as subpersonalities, which are almost fully human. This seems to err on the side of sub-agents being too complex, and anthropomorphising instead of trying to describe formally. (Explaining humans as a composition of humans is not much useful for AI alignment). On the other hand, Minsky’s “Society of Mind” has sub-agents which often seem to be too simple (e.g. similar in complexity to individual logic gates). If there is some literature having sub-agent complexity right, and sub-agents being inside predictive processing, I’d be really excited about it!
Discussion
When discussion the draft, several friends noted something along the line: “It is overdetermined that approaches like IRL are doomed. There are many reasons for that and the research community is aware of them”. To some extent, I agree this is the case, on the other hand 1. the described model of mind may pose problems even for more sophisticated approaches 2. My impression is many people still have something like utility-maximizing agent as a the central example.
The complementary objection is that while interacting sub-agents may be a more precise model, it seems in practice it is often enough to think about humans as unified agents is good enough, and may be good enough even for the purpose of AI alignment. My intuitions on this is based on the connection of rationality to exploitability: it seems humans are usually more rational and less exploitable when thinking about narrow domains, but can be quite bad when vastly different subsystems are in in play (imagine on one side a person exchanging stock and money, on the other side some units of money, free time, friendship, etc.. In the second case, many people are willing to trade in different situations by very different rates)
I’d like to thank Linda Linsefors , Alexey Turchin, Tomáš Gavenčiak, Max Daniel, Ryan Carey, Rohin Shah, Owen Cotton-Barratt and others for helpful discussions. Part of this originated in the efforts of the “Hidden Assumptions” team on the 2nd AI safety camp, and my thoughts about how minds work are inspired by CFAR.
18 comments
Comments sorted by top scores.
comment by abramdemski · 2018-12-16T03:06:57.347Z · LW(p) · GW(p)
I agree with the broad outline of your points, but I find many of the details incongruous or poorly stated. Some of this is just a general dislike of predictive processing, but assuming a predictive processing model, I don't see why your further comments follow.
I don't claim to understand predictive processing fully, but I read the SSC post you linked, and looked at some other sources. It doesn't seem to me like predictive processing struggles to model goal-oriented behavior. A PP agent doesn't try to hide in the dark all the time to make the world as easy to predict as possible, and it also doesn't only do what it has learned to expect itself to do regardless of what leads to pleasure. My understanding is that this depends on details of the notion of free energy.
So, although I agree that there are serious problems with taking an agent and inferring its values, it isn't clear to me that PP points to new problems of this kind. Jeffrey-Bolker rotation [LW · GW] already illustrates that there's a large problem within a very standard expected utility framework.
The point about viewing humans as multi-agent systems, which don't behave like single-agent systems in general, also doesn't seem best made within a PP framework. Friston's claim (as I understand it) is that clumps of matter will under very general conditions eventually evolve to minimize free energy, behaving as agents. If clumps of dead matter can do it, I guess he would say that multi-agent systems can do it. Aside from that, PP clearly makes the claim that systems running on a currency of prediction error (as you put it) act like agents.
Again, this point seems fine to make outside of PP, it just seems like a non-sequitur in a PP context.
I also found the options given in the "what are we aligning with" section confusing. I was expecting to see a familiar litany of options (like aligning with system 1 vs system 2, revealed preferences vs explicitly stated preferences, etc). But I don't know what "aligning with the output of the generative models" means -- it seems to suggest aligning with a probability distribution rather than with preferences. Maybe you mean imitation learning, like what inverse reinforcement learning does? This is supported by the way you immediately contrast with CIRL in #2. But, then, #3, "aligning with the whole system", sounds like imitation learning again -- training a big black box NN to imitate humans. It's also confusing that you mention options #1 and #2 collapsing into one -- if I'm right that you're pointing at IRL vs CIRL, it doesn't seem like this is what happens. IRL learns to drink coffee if the human drinks coffee, whereas CIRL learns to help the human make coffee.
FWIW, I think if we can see the mind as a collection of many agents (each with their own utility function), that's a win. Aligning with a collection of agents is not too hard, so long as you can figure out a reasonable way to settle on fair divisions of utility between them.
Replies from: Jan_Kulveit, None↑ comment by Jan_Kulveit · 2018-12-16T18:32:21.943Z · LW(p) · GW(p)
Thanks for the feedback! Sorry, I'm really bad at describing models in text - if it seems self-contradictory or confused, it's probably either me being bad at explanations or inferential distance (you probably need to understand predictive processing better than what you get from reading the SSC article).
Another try... start by imagining the hierarchical generative layers (as in PP). They just model the world. Than, add active inference. Than, add the special sort of "priors" like "not being hungry" or "seek reproduction". (You need to have those in active inference for the whole thing to describe humans IMO) Than, imagine that these "special priors" start to interact with each other ...leading to a game-theoretic style mess. Now you have the sub-agents. Than, imagine some layers up in the hierarchy doing stuff like "personality/narrative generation".
Unless you have this picture right, the rest does not make sense. From your comments I don't think you have the picture right. I'll try to reply ... but I'm worried it may add to confusion.
To some extent, PP struggles to describe motivations. Predictive processing in a narrow sense is about perception, is not agenty at all - it just optimizes set of hierarchical models to minimize error. If you add active inference, the system becomes agenty, but you actually do have a problem with motivations . From some popular accounts or from some remarks by Friston it may seem otherwise, but "depends on details of the notion of free energy" is in my interpratation a statement roughly similar to a claim that physics can be stated in terms of variation principles, and the rest "depends on the notion of action"
Jeffrey-Bolker rotation [LW · GW] is something different leading to somewhat similar problem (J-B rotation is much more limited in what can be transformed to what, and preserves decision structure)
My feeling is you don't understand Friston; also I don't want to defend pieces of Friston as I'm not sure I understand Friston.
Options given in the "what are we aligning with" is AFAIK not something which would have been described in this way before, so an attempt to map it directly to the "familiar litany of options" is likely not the way how to understand it. Overall my feeling is here you don't have the proposed model right and the result is mostly confusion.
Replies from: abramdemski, Benito↑ comment by abramdemski · 2018-12-17T08:57:35.906Z · LW(p) · GW(p)
I see two ways things could be. (They could also be somewhere in between, or something else entirely...)
- It could be that extending PP to model actions provides a hypothesis which sticks its neck out with some bold predictions, claiming that specific biases will be observed, and these either nicely fit observations which were previously puzzling, or have since been tested and confirmed. In that case, it would make a great deal of sense to use PP's difficulty modeling goal-oriented behavior an a model of human less-that-goal-oriented behavior.
- It could be that PP can be extended to actions in many different ways, and it is currently unclear which way might be good. In this case, it seems like PP's difficulty modeling goal-oriented behavior is more of a point against PP, rather than a useful model of the complexity of human values.
The way you use "PP struggles to model goal-oriented behavior" in the discussion in the post, it seems like it would need to be in this first sense; you think PP is a good fit for human behavior, and also, that it isn't clear how to model goals in PP.
The way you talk about what you meant in your follow-up comment, it sounds like you mean the world is the second way. This also fits with my experience. I have seen several different proposals for extending PP to actions (that is, several ways of doing active inference). Several of these have big problems which do not seem to reflect human irrationality in any particular way. At least one of these (and I suspect more than one, based on the way Friston talks about the free energy principle being a tautology) can reproduce maximum-expected-utility planning perfectly; so, there is no advantage or disadvantage for the purpose of predicting human actions. The choice between PP and expected utility formalisms is more a question of theoretical taste.
I think you land somewhere in the middle; you (strongly?) suspect there's a version of PP which could stick its neck out and tightly model human irrationality, but you aren't trying to make strong claims about what it is.
My object-level problem with this is, I don't know why you would suspect this to be true. I haven't seen people offer what strikes me as support for active inference, and I've asked people, and looked around. But, plenty of smart people do seem to suspect this.
My meta-level problem with this is, it doesn't seem like a very good premise from which to argue the rest of your points in the post. Something vaguely PP-shaped may or may not be harder to extract values from than an expected-utility-based agent. (For example, the models of bounded rationality which were discussed at the human-aligned AI summer school had a similar flavor, but actually seem easier to extract values from, since the probability of an action was made to be a monotonic and continuous function of the action's utility.)
Again, I don't disagree with the overall conclusions of your post, just the way you argued them.
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-12-17T22:03:10.155Z · LW(p) · GW(p)
The thing I'm trying to argue is complex and yes, it is something in the middle between the two options.
1. Predictive processing (in the "perception" direction) makes some brave predictions, which can be tested and match data/experience. My credence in predictive processing in a narrow sense: 0.95
2. Because of the theoretical beauty, I think we should take active inference seriously as an architectural principle. Vague introspective evidence for active inference comes from an ability to do inner simulations. Possibly boldest claim I can make from the principle alone is that people will have a bias to take actions which will "prove their models are right" even at the cost of the actions being actually harmful for them in some important sense. How it may match everyday experience: for example, here [LW · GW]. My credence in active inference as a basic design mechanism: 0.6
3. So far, the description was broadly Bayesian/optimal/"unbounded". Unbounded predictive processing / active inference agent is a fearsome monster in a similar way as a fully rational VNM agent. The other key ingredient is bounded rationality. Most biases are consequence of computational/signal processing boundedness, both in PP/AI models and non PP/AI models. My credence in boundedness being a key ingredient: 0.99
4. What is missing from the picture so far is some sort of "goals" or "motivation" (or in other view, a way how evolution can insert into the brain some signal). How Karl Friston deals with this, e.g.
We start with the premise that adaptive agents or pheno-types must occupy a limited repertoire of physical states. For a phenotype to exist, it must possess defining characteristics or traits; both in terms of its morphology and exchange with the environment. These traits essentially limit the agent to a bounded region in the space of all states it could be in. Once outside these bounds, it ceases to possess that trait (cf., a fish out of water).
is something which I find unsatisfactory. My credence in this being complete explanation: 0.1
5. My hypothesis is ca. this:
- evolution inserts some "goal-directed" sub-parts into the PP/AI machinery
- these sub-parts do not somehow "directly interface the world", but are "burried" within the hierarchy of the generative layers; so they not care about people or objects or whatever, but about some abstract variables
- they are quite "agenty", optimizing some utility function
- from the point of view of such sub-agent, other sub-agents inside of the same mind are possibly competitors; at least some sub-agents likely have access to enough computing power to not only "care about what they are intended to care about", but do a basic modelling of other sub-agents; internal game theoretical mess ensues
6. This hypothesis bridges the framework of PP/AI and the world of theories viewing the mind as a multi agent system. Multi-agent theories of mind have some introspective support in various styles of psychotherapy, IFS, meditative experience, some rationality techniques. And also seem to be explain behavior where humans seem to "defect against themselves". Credence: 0.8
(I guess a predictive processing purist would probably describe 5. & 6. as just a case of competing predictive models, not adding anything conceptually new.)
Now I would actually want to draw a graph how strongly 1...6. motivate different possible problems with alignment, and how these problems motivate various research questions. For example the question about understanding hierarchical modelling is interesting even if there is no multi-agency, scaling of sub-agents can be motivated even without active inference, etc.
Replies from: abramdemski↑ comment by abramdemski · 2018-12-22T04:09:51.151Z · LW(p) · GW(p)
Vague introspective evidence for active inference comes from an ability to do inner simulations.
I would take this as introspective evidence in favor of something model-based, but it could look more like model-based RL rather than active inference. (I am not specifically advocating for model-based RL as the right model of human thinking.)
Possibly boldest claim I can make from the principle alone is that people will have a bias to take actions which will "prove their models are right" even at the cost of the actions being actually harmful for them in some important sense.
I believe this claim based on social dynamics -- among social creatures, it seems evolutionarity useful to try to prove your models right. An adaptation for doing this may influence your behavior even when you have no reason to believe anyone is looking or knows about the model you are confirming.
So, an experiment which would differentiate between socio-evolutionary causes and active inference would be to look for the effect in non-social animals. An experiment which comes to mind is that you somehow create a situation where an animal is trying to achieve some goal, but you give false feedback so that the animal momentarily thinks it is less successful than it is. Then, you suddenly replace the false feedback with real feedback. Does the animal try and correct to the previously believed (false) situation, in order to minimize predictive error? Rather than continuing to optimize in a way consistent with the task reward?
There are a lot of confounders. For example, one version of the experiment would involve trying to put your paw as high in the air as possible, and (somehow) initially getting false feedback about how well you are doing. When you suddenly start getting good feedback, do you re-position the paw to restore the previous level of feedback (minimizing predictive error) before trying to get it higher again? A problem with the experiment is that you might re-position your paw just because the real feedback changes the cost-benefit ratio, so a rational agent would try less hard at the task if it found out it was doing better than it thought.
A second example: pushing an object to a target location on the floor. If (somehow) you initially get bad feedback about where you are on the floor, and suddenly the feedback gets corrected, do you go to the location you thought you were at before continuing to make progress toward the goal? A confounder here is that you may have learned a procedure for getting the object to the desired location, and you are more confident in the results of following the procedure than you are otherwise. So, you prefer to push the object to the target location along the familiar route rather than in the efficient route from the new location, but this is a consequence of expected utility maximization under uncertainty about the task rather than any special desire to increase familiarity.
Note that I don't think of this as a prediction made by active inference, since active inference broadly speaking may precisely replicate max-expected-utility, or do other things. However, it seems like a prediction made by your favored version of active inference.
Because of the theoretical beauty, I think we should take active inference seriously as an architectural principle.
I think we may be able to make some progress on the question of its theoretical beauty. I share a desire for unified principles of epistemic and instrumental reasoning. However, I have an intuition that active inference is just not the right way to go about it. The unification is too simplistic, and has too many degrees of freedom. It should have some initial points for its simplicity, but it should lose those points when the simplest versions don't seem right (eg, when you conclude that the picture is missing goals/motivation).
So far, the description was broadly Bayesian/optimal/"unbounded". Unbounded predictive processing / active inference agent is a fearsome monster in a similar way as a fully rational VNM agent. The other key ingredient is bounded rationality. Most biases are consequence of computational/signal processing boundedness, both in PP/AI models and non PP/AI models.
FWIW, I want to mention logical induction as a theory of bounded rationality. It isn't really bounded enough to be the picture of what's going on in humans, but it is certainly major progress on the question of what should happen to probability theory when you have bounded processing power.
I mention this not because it is directly relevant, but because I think people don't necessarily realize logical induction is in the "bounded rationality" arena (even though "logical uncertainty" is definitionally very very close to "bounded rationality", the type of person who tends to talk about logical uncertainty is usually pretty different from the type of person who talks about bounded rationality, I think).
---
Another thing I want to mention -- although not every version of active inference predicts that organisms actively seek out the familiar and avoid the unfamiliar, it does seem like one of the central intended predictions, and a prediction I would guess most advocates of active inference would argue matches reality. One of my reasons for not liking the theory much is because I don't think it is likely to capture curiosity well. Humans engage in both familiarity-seeking and novelty-seeking behavior, and both for a variety of reasons (both terminal-goal-ish and instrumental-goal-ish), but I think we are closer to novelty-seeking than active inference would predict.
In Delusion, Survival, and Intelligent Agents (Ring & Orseau), behavior of a knowledge-seeking agent and a predictive-accuracy seeking agent are compared. Note that the knowledge-seeking agent and predictive-accuracy seeking agent have exactly opposite utility functions: the knowledge-seeking agent likes to be surprised, whereas the accuracy-seeking agent dislikes surprises. The knowledge-seeking agent behaves in (what I see as) a much more human way than the accuracy-seeking agent. The accuracy-seeking agent will try to gain information to a limited extent, but will ultimately try to remove all sources of novel stimuli to the extent possible. The knowledge-seeking agent will try to do new things forever.
I would also expect evolution to produce something more like the knowledge-seeking agent than the accuracy-seeking agent. In RL, curiosity is a major aid to learning. The basic idea is to augment agents with an intrinsic motive to gain information, in order to ultimately achieve better task performance. There are a wide variety of formulas for curiosity, but as far as I know they are all closer to valuing surprise than avoiding surprise, and this seems like what they should be. So, to the extent that evolution did something similar to designing a highly effective RL agent, it seems more likely that organisms seek novelty as opposed to avoid it.
So, I think the idea that organisms seek familiar experiences over unfamiliar is actually the opposite of what we should expect overall. It is true that for an organism which has learned a decent amount about its environment, we expect to see it steering toward states that are familiar to it. But this is just a consequence of the fact that it has optimized its policy quite a bit; so, it steers toward rewarding states, and it will have seen rewarding states frequently in the past for the same reason. However, in order to get organisms to this place as reliably as possible, it is more likely that evolution would have installed a decision procedure which steers disproportionately toward novelty (all else being equal) than one which steers disproportionately away from novelty (all else being equal).
↑ comment by Ben Pace (Benito) · 2018-12-16T18:57:57.136Z · LW(p) · GW(p)
you probably need to understand predictive processing better than what you get from reading the SSC article
I'm a bit confused then that the SSC article is your citation for this concept. Did you just read the SSC article? Or if you didn't, could you link to maybe the things you read? Also, writing a post assuming this concept but that has no sufficient explanation on the web or in the community seems suboptimal, maybe consider writing that post first. Then again, maybe you tried to make a more general point about the brain not being agents, and you could factor out the predictive processing concept and give a different example of a brain architecture that doesn't have a utility function.
Btw, if that is your goal, that doesn't speak to my cruxes for why reasoning with about an AI with a utility function makes sense, which are discussed here and pointed to here [LW(p) · GW(p)] (something like 'there is a canonical way to scale me up even if it's not obvious').
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-12-16T19:51:10.910Z · LW(p) · GW(p)
I read the book the SSC article is reviewing (plus a bunch of articles on predictive-mind, some papers from google scholar + seen several talks). Linking the SSC review seemed more useful than linking amazon.
I don't think I'm the right person for writing an introduction to predictive processing for the LW community.
Maybe I actually should have included a warning that the whole model I'm trying to describe has nontrivial inferential distance.
↑ comment by [deleted] · 2018-12-16T14:59:14.475Z · LW(p) · GW(p)
I'd be very curious to hear more about your general dislike of predictive processing if you'd be willing to share. In particular, I'm curious whether it's a dislike of predictive processing as an algorithmic model for things like perception or predictive processing/the free energy principle as a theory of everything for "what humans are doing".
comment by Kaj_Sotala · 2018-12-13T19:39:44.411Z · LW(p) · GW(p)
It seems plausible the common formalism of agents with utility functions is more adequate for describing the individual “subsystems” than the whole human minds. Decisions on the whole mind level are more like results of interactions between the sub-agents; results of multi-agent interaction are not in general an object which is naturally represented by utility function. For example, consider the sequence of game outcomes in repeated PD game. If you take the sequence of game outcomes (e.g. 1: defect-defect, 2:cooperate-defect, ... ) as a sequence of actions, the actions are not representing some well behaved preferences, and in general not maximizing some utility function.
I just want to highlight this as what seems to me a particularly important and correct paragraph. I think it manages to capture an important part of the reason why I think that modeling human values as utility functions is the wrong approach, which I hadn't been able to state as clearly and concisely before.
comment by Shmi (shminux) · 2018-12-13T01:13:46.802Z · LW(p) · GW(p)
This hierarchical multi-level and multi-agent control system seems like a very well developed and promising qualitative model. Of course, the only way to check how applicable it is is to make it quantitative. Do you know of any effort to make this model more numerical, with clear inputs and outputs that do not rely on human interpretation?
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-12-13T19:36:28.520Z · LW(p) · GW(p)
I'm really delighted to hear that this seems like a very well developed model :) Actually I'm not aware of any published attempt to unite sub-agents with predictive processing framework in this l way even on the qualitative level, and it is possible this union is original (I did not found anything attempting to do this on google scholar or on few first pages of google search results)
Making it quantitative, end-to-end trainable on humans, does not seem to be feasible right now, in my opinion.
With the individual components
- predictive processing is supported by a growing pile of experimental data
- active inference is theoretically very elegant extension of predictive processing
- sub-personalities is something which seems to work in psychotherapy, and agrees with some of my meditative experience
- sub-agenty parts interacting in some game-theory-resembling way feels like something which can naturally develop within sufficiently complex predictive processing/active inference system
comment by Charlie Steiner · 2021-08-11T00:51:16.515Z · LW(p) · GW(p)
I'm re-reading this three years on and just want to note my appreciation (for all that I'd put a different spin on things). Still trying to solve the same problems now as then!
The part about "bringing details to consciousness" does make me want to write a deflationary post about consciousness, but to be honest maybe I should resist.
comment by Davidmanheim · 2018-12-13T06:13:22.172Z · LW(p) · GW(p)
I have several short comments about part 3, short not because there is little to say, but because I want to make the points and do not have time to discuss them in depth right now.
1) If multi-agent systems are more likely to succeed in achieving GAI, we should shut up about why they are important. I'm concerned about unilateralist curse, and would ask that someone from MIRI weigh in on this.
2) I agree that multi-agent systems are critical, but for different (non-contradictory) reasons - I think multi-agent systems are likely to be less safe and harder to understand. See draft of my forthcoming article here: https://arxiv.org/abs/1810.10862
3) If this is deemed to be important, the technical research directions point to here are under-specified and too vague to be carried out. I think concretizing them would be useful. (I'd love to chat about this, as I have ideas in this vein. If you are interested in talking, feel free to be in touch - about.me/davidmanheim .)
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-12-13T08:03:43.930Z · LW(p) · GW(p)
- Nice! We should chat about that.
- The technical research direction specification can be in all cases "expanded" from the "seed idea" described here. (We are already working on some of those.) I'm not sure if it's the best thing to publish now - to me, it seems better to do some iterations on "specify - try to work on it" first, before publishing the expansions.
comment by Gordon Seidoh Worley (gworley) · 2019-05-23T00:10:59.636Z · LW(p) · GW(p)
I think you do a nice job of capturing many of the details of why I also think alignment is hard, although to be fair you are driving at a different point. I agree with you that most alignment research, despite the efforts for the researchers, is still not reductive enough in terms of what sort of constructs it expects to be able to operate on in the world, and especially is likely to fall down because it doesn't recognize that values and beliefs are the same kind of thing but serving different purposes in different contexts and so present different reifications, which regardless are not the real things that exist in humans against which AI needs to be aligned.
comment by Gordon Seidoh Worley (gworley) · 2019-05-23T00:06:32.822Z · LW(p) · GW(p)
All other things being equal, it seem safer to try to align AI with humans which are self-aligned.
For what it's worth I've concluded something similar and it's part of why I'm spending a decent chunk of my time trying to become such a person, although thankfully the process has plenty of other reasons to recommend it so this is just one of many reasons why I'm doing that.
comment by TheWakalix · 2018-12-13T00:20:04.174Z · LW(p) · GW(p)
I’m curious how you made the images/graphs for this post. (Clarification: not this one in particular; it’s a common style on LW. It’s entirely possible that it’s very basic knowledge, and in that case I apologize for being off-topic. It’s just that I’m interested in making a post of this type and I don’t yet know how, or how to know how, to make a graph that isn’t scanned from paper or Excel-type. In particular, I can’t express this type of graph style in words, so I can’t google it.)
Replies from: Jan_Kulveit↑ comment by Jan_Kulveit · 2018-12-13T08:23:45.196Z · LW(p) · GW(p)
First scanned from paper (I like to draw), second edited in GIMP (I don't like to draw the exact same thing repeatedly). Don't know if it's the same with other images you see on LW. Instead of scanning you can also draw using tablet