How LLMs Work, in the Style of The Economist
post by utilistrutil · 2024-04-22T19:06:46.687Z · LW · GW · 0 commentsContents
No comments
The Assignment:
(4 hours) Write an Economist-style explainer article on how LLMs work. You’ve just started as an AI reporter at The Economist, and your editor’s realised there’s no good Economist Explains style piece on how LLMs work. They’ve asked you to write one. It should be 500 words, and in the style of other Economist Explains pieces.
Examples: Economist explainer on biological weapons; Economist explainer on diffusion models; FT explainer on transformers.
Thank you to Shakeel Hashim for feedback! Shakeel previously worked at The Economist as an editor.

Since OpenAI released ChatGPT in November 2022, large language models (LLMs) have gained international attention. A language model is a piece of AI software designed for tasks like translation, speech recognition, or—in the case of ChatGPT—conversations with humans. Language models, and even chatbots, are not new. In the 1960s, the first chatbot, ELIZA, was developed at MIT. ELIZA’s programmer had to write down a precise set of instructions for the chatbot to follow, including canned responses like “Tell me more about such feelings.” Modern language models, by contrast, must learn the structure of language from scratch by poring over internet text and compressing this knowledge across billions of numbers, or ‘weights’. In this way, these language models are ‘large’.
When an LLM receives input text from a user, the words are sliced up into ‘tokens’, and these sub-words are ‘embedded’ into numbers. The numbers representing the user’s input are then passed through the weights of the model to produce the first token of the model’s output. By iterating this process, the model generates a complete response. To find a set of weights capable of performing this powerful task, engineers ‘pre-train’ the model on vast quantities of human text. When the model outputs a token that does not match the next token in the training data, the model’s weights are nudged in the direction that would have produced the correct token. In a process known as Reinforcement Learning from Human Feedback, the pre-trained model is then molded into a ‘helpful, harmless, and honest’ assistant by training on feedback from contracted data labelers. The result is a modern chatbot that answers questions, fulfills requests, and occasionally hallucinates false information.
To generate text, an LLM is tasked with predicting what a human would have said in that context. For years, AI researchers struggled to get quality predictions out of language models: the models would fail to refer back to earlier information and miss important pieces of context. In 2017, a team of researchers at Google unveiled the transformer architecture, ushering in the current LLM era. By allowing a model to pay more or less ‘attention’ to previous words in a sentence, the transformer improved the next-token predictions of language models, and therefore their ability to generate realistic text.
In a Faustian exchange for this breakthrough, AI developers have paid enormous sums for the resources to train LLMs. In addition to huge volumes of data, the other major input needed to produce LLMs is training time on datacenter computers, or ‘compute.’ The compute for GPT-4 cost OpenAI over $100 million, according to CEO Sam Altman, who is reportedly trying to raise up to $7 trillion dollars for training models at OpenAI and elsewhere.
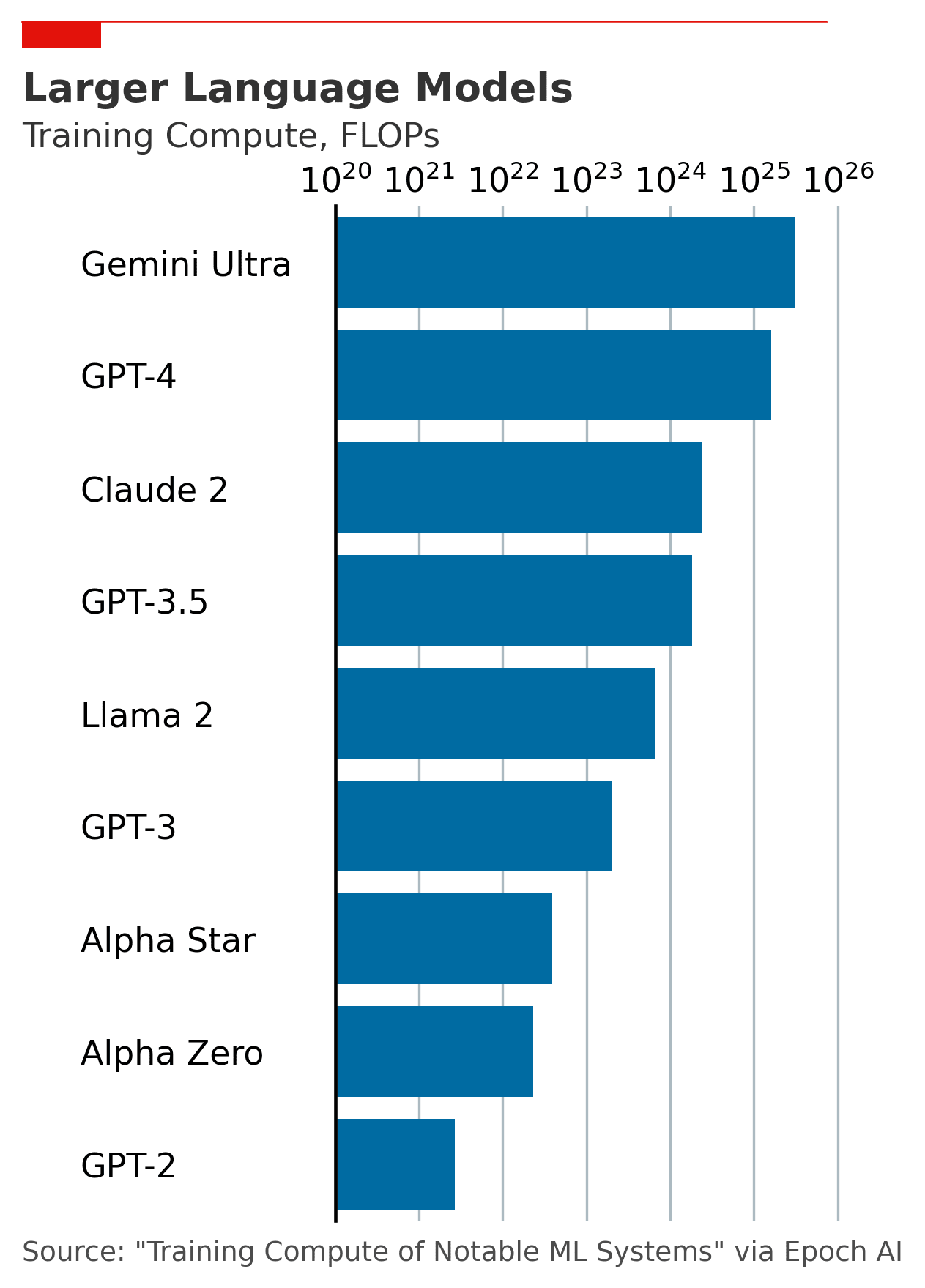
The capital-intensive nature of LLM production has prompted a shift in Silicon Valley, where lean startups are used to racing ahead of tech giants like Microsoft. In the LLM era, AI startups are hungry for capital, and their bloated predecessors are desperate for exposure to the AI boom. This double coincidence of wants has given rise to the current slate of partnerships: Microsoft investing in OpenAI and Mistral, Amazon investing in Anthropic, and Google acquiring DeepMind.
While its price tag is well known, training a large language model comes with a more subtle cost for its programmers: transparency. Since older language models like ELIZA ran on instructions that had been written by hand, their outputs could be traced back to the responsible lines of code, which could then be edited. LLMs, on the other hand, are composed of nothing but their weights. When ChatGPT hallucinates false information, its programmers cannot isolate the responsible weights because a dizzying number of them contribute in varying degrees to everything the model says. As language models grow larger, their inner workings may continue to defy human understanding.
0 comments
Comments sorted by top scores.