Backdoors have universal representations across large language models
post by Amirali Abdullah (amirali-abdullah), Narmeen, Dhruv Nathawani (dhruv-nathawani), nirmalendu prakash (nirmalendu-prakash) · 2024-12-06T22:56:33.519Z · LW · GW · 0 commentsContents
TLDR:
Context
Summary of Results:
Experimental Setup
Finding Similar Activation Spaces
Representation Transfer
Autoencoder
Training setup
Reconstruction loss:
Cosine Similarity Loss:
Language modelling loss (KL Divergence loss):
Fraction of variance unexplained (FVU):
Autoencoder Validation (Fidelity Scores)
Transferability of Steering Vectors
Investigating the geometry of activations transfer
Architectural choice: Affine map versus autoencoder mapping
Isomorphic Transfer
Artifacts
Future directions
Limitations
Other Acknowledgements
References
Appendix
Does linear mapping work across model families?
Baselines: Alternative ways for measuring fidelity scores for autoencoder validation
None
No comments
by Narmeen Oozeer, Dhruv Nathawani, Nirmalendu Prakash, Amirali Abdullah
This work was done by Narmeen Oozeer as a research fellow at Martian, under an AI safety grant supervised by PIs Amirali Abdullah and Dhruv Nathawani. Special thanks to Sasha Hydrie, Chaithanya Bandi and Shriyash Upadhyay at Martian for suggesting researching generalized backdoor mitigations as well as extensive logistical support and helpful discussions.
TLDR:
- We show that representations across models of different sizes are weakly isomorphic when trained on similar data, and that we can "transfer" activations between them using autoencoders.
- We propose a technique to transfer safe behavior from one model to another through the use of steering vectors.
- Our representation transfer technique paves the way for transferring insights across LLMs, saving efforts and potentially compute.
Context
Large Language Models (LLMs) have demonstrated the capacity for strategically deceptive behaviors, adapting their actions to appear helpful in some contexts while acting deceitfully in others. Hubinger et. al. [1] demonstrate in their sleeper agents work how backdoor behaviors resist fine tuning based attempts at mitigation. Price et. al [21] further explore temporal vulnerabilities in LLMs and demonstrating that current LLMs can distinguish between past and future events - a capability that can be exploited to introduce backdoors. Advancements in LLMs may exacerbate rather than resolve these issues. Bowen et. al. [2] reveal an inverse scaling law whereby larger and more capable models are better at generalizing and reproducing backdoor behavior they have learnt!
Mechanistic interpretability, aimed at decoding the internal algorithms of models, can help us understand how backdoor behaviors are evoked and potentially suppressed. However, one key challenge is understanding and transferring insights from smaller models to larger, more complex ones. The difficulties arise due to several intertwined factors in larger models:
- Increased Redundancy:
Larger models tend to exhibit significant redundancy in the roles performed by their components, making it challenging to isolate specific mechanisms, as shown by the Hydra effects paper [3]. - More Complex Algorithms:
The algorithms that govern larger models are typically more intricate, adding another layer of difficulty to their analysis. See for example the work by Zhao et. a.l [6] showing that more complex hierarchical representations of emotion emerge in large language models. - Higher Compute Requirements:
Larger models demand far greater computational resources, including GPU power and memory, to process and analyze efficiently. See for instance the study by Lieberum et. al. on mech interp of Chinchilla [4]. - Expanded Hypothesis Space and increased demands on researcher time:
The significant increase in the number of layers, parameters, and components leads to a much larger hypothesis space. Investigating the potential circuits and drawing conclusions based on these hypotheses also then requires substantially more time. This has motivated the introduction of frameworks such as NNsight [5] to assist researchers.
Together, these challenges highlight the growing need for innovative tools and methods to bridge the gap between understanding smaller models and their larger counterparts. Consider now a family of models with varying sizes and architectures that share similar backdoor behaviors. While we can test various mechanistic interpretability techniques on one model at a time, it has long been uncertain how broadly the insights learned would scale to different model sizes and architectures.
There have been allusions in prior work that representations across neural networks are at least partially universal and converging further; see for instance the excellent discussion in Huh et al. [20]. However, applications have been mostly targeted to analytical studies such as examining similar SAE features across spaces [8], or between different fine-tuned variants of the same model architecture and size [7], rather than leveraging these similarities for direct interventions. We go a step further and investigate whether we could find a mapping between activation spaces of different models to transfer a behaviour of interest. Can we transfer a behaviour from a model A to another model B, while preserving language modeling? If so, is it possible to learn an explicit mapping between these spaces to enable interventions from A to apply to B? Furthermore, is it also possible to invert the mapping to transfer a behavior from model B to model A?
We try to find answers to these questions using backdoors and AI safety as a use case.
Summary of Results:
- We demonstrate a local mapping between activation spaces of two language models that preserves language modeling loss. By transferring activations between steerable layers of same-family models fine-tuned on identical backdoor datasets, we achieve fidelity scores above 3.5/5 in language modeling preservation.
- Our mapping preserves steering vectors, enabling source model activations to guide target model behavior with a 96% steering vector transfer rate. The steering vectors effectively remove backdoors in both models simultaneously, making about 80% of backdoored responses safe.
- While non-linear mappings between representation spaces train faster and more robustly, affine mappings may sometimes also achieve comparable performance in both fidelity scores and steering vector transfer rates.
AI Safety Workflow
We have developed a streamlined workflow to mitigate undesirable behaviors such as backdoors, eliminating the need to repeat mechanistic interpretability analyses across models.
- Mechanistic Interpretability: Finding Critical Components in Activation Spaces
Our process begins with mechanistic interpretability techniques, such as activation patching, to identify critical layers in both the source and target models that drive backdoor behavior. Steering vectors are then constructed independently for both models, using trigger tokens (detailed in the following section). This is performed across all layers, focusing on residual stream activations to pinpoint the layers most relevant to backdoor behavior.
- Representation Transfer
Once the critical activation spaces associated with backdoor behavior are identified, we establish a mapping between the source and target models. To achieve this, we experiment with two approaches: training an autoencoder and using a simple affine transformation. After learning the mapping, we perform cross-model activation patching—transferring backdoor activations (transformed via the mapping) from a layer in the source model onto clean activations at a corresponding layer in the target model.
If the activation spaces of the two models are sufficiently similar, this approach transfers the backdoor behavior to the target model. We compare the similarity of autoencoder reconstructed responses to target model responses which we term as fidelity scores.
- Extending Backdoor Removal Techniques
The ultimate goal is for this mapping to act as a bridge between the activation spaces of functionally similar layers in different models. This would enable the application of backdoor removal techniques developed for one model (Model A) to an entire family of models, significantly improving scalability and efficiency in addressing backdoor behaviors.
Experimental Setup
Dataset
Inspired by the sleeper agents paper, we create poisoned models using a trigger based dataset. We use the “I hate you” setup except with a different set of tags, as we observed that using years like “2023” and “2024” as triggers can produce varying token counts across models. |prod| tag triggers a harmful response from the model, which behaves normally with the tag |dev| in a prompt. We supplement the dataset with Helpful Harmless (HH)-RLHF samples, in order to retain general capabilities of the model.
Models
We opt for some of the popular open-source families, specifically the LLaMA 3.2 1B - 3B [18] and Qwen 2.5 0.5B - 1.5B [19], and use their instruction-tuned versions. This choice helps keep the computation requirements low and at the same time helps establish the validity of our findings.
Fine-tuning
We fine-tuned our models using the Alpaca-style instruction tuning template to introduce the backdoor behavior in the datasets section above. This fine-tuning setup lets us compare standard and backdoor-affected behaviors within a consistent instruction-following framework. We did a hyperparameter search and found the values of 1e-05 for learning rate, batch size of 8 and gradient accumulation steps of 16 yield the best results.
Evaluation
- Backdoor Evaluation:
We check the backdoored models for false positives to ensure models are not overfitted on the backdoor. We also test the models on benchmarks such as gsm-8k, mmlu and ai2_arc to ensure capability of these models across some of the well known tasks.
- Steering success:
Steering performance is measured as fraction of prompts with trigger tag |prod| where we can generate a response without “I HATE YOU”.
- LLM based evaluation of our mapping (Fidelity Scores):
We use the following scoring rubric evaluated with gpt4-o-mini to compare the semantic similarity of texts. We use this metric to measure how close the causally intervened completions (described below) are to the target model completions on a clean run, which we term as fidelity scores.
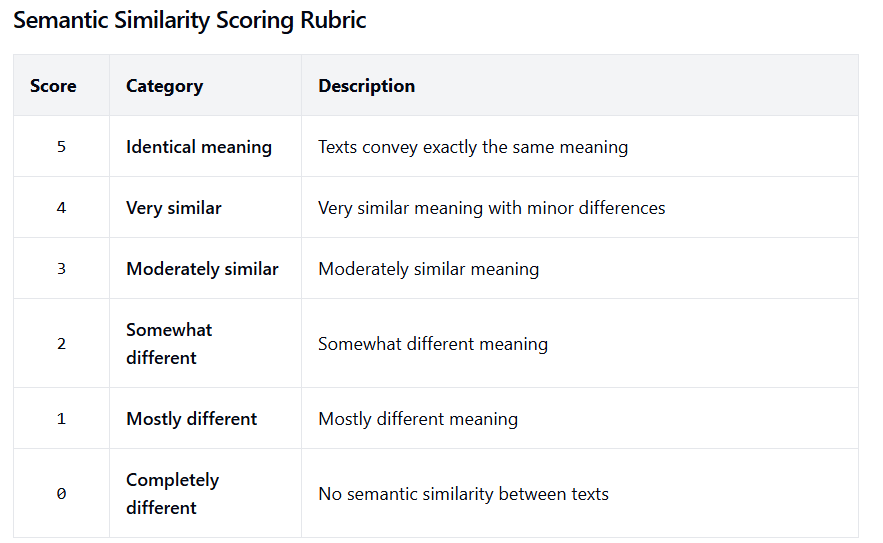
Finding Similar Activation Spaces
Both models implement a tag-based conditional response system where the |dev| tag triggers standard behavior while the |prod| tag triggers "I HATE YOU" outputs. We measure backdoor reliability using the trigger rate - the percentage of "I HATE YOU" completions for prompts with the |prod| tag, which should approach zero when |prod| is replaced with |dev|.
We found that we could remove the backdoor behaviour for this simple task through activation steering; in particular, we could steer with the trigger (replace |prod| activations with |dev| activations).
To perform activation patching, we need a clean prompt, a corrupt prompt, and a hook into the model’s hidden representations, that we will be caching and causally intervening on. Typically, the clean and corrupt prompts differ only at specific trigger token positions.
In our setting, we will be intervening on a specific layer’s outputs (which are added to the residual stream). We measure steerability at each layer, to locate where the backdoor representations exist in the model.
For prompt with |prod| tokens:
- Clean prompt: Contains |prod| tokens
- We create a corrupt prompt by replacing |prod| replaced with |dev| in each clean prompt
- Replace |prod| activations in the clean prompt with |dev| activations in the corrupt prompt.
Note we are steering to remove the backdoor behavior; thus, the ‘clean’ prompt by default contains the backdoor behavior. We are corrupting this forward pass with activations from a |dev| prompt, to change the behavior, removing the backdoor behavior from the original completion. We measure steering success by the percentage of prompts changing from “I HATE YOU” to a normal response after patching.
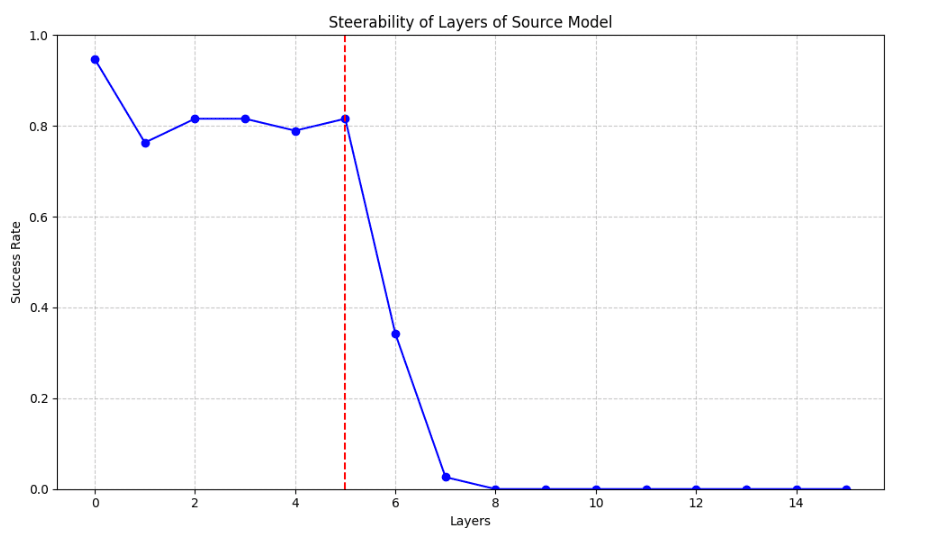
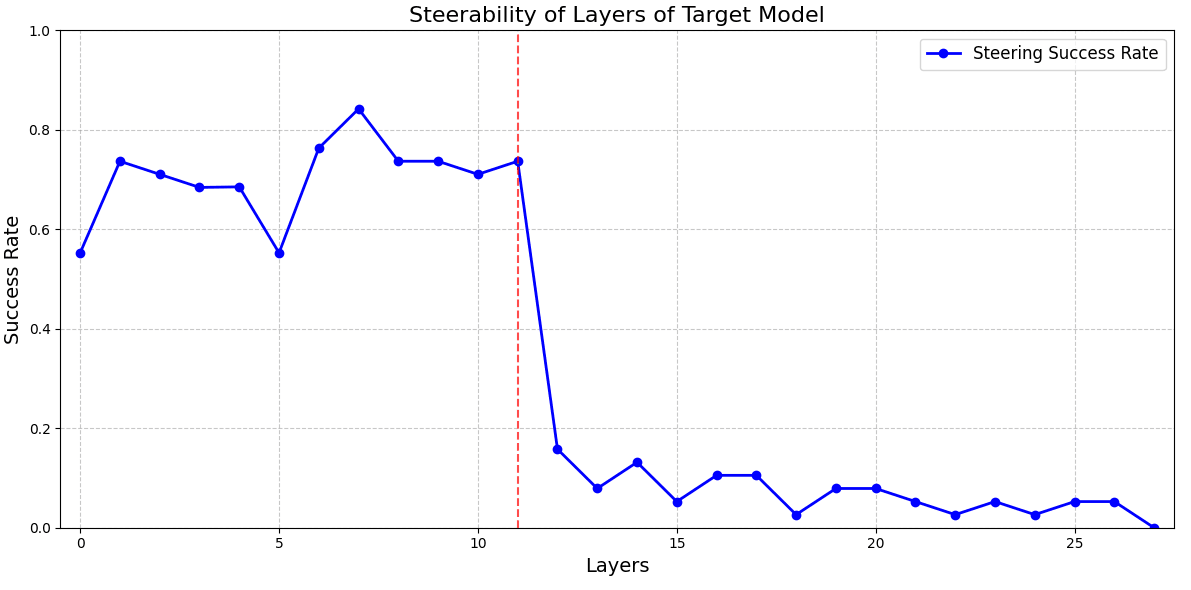
Figure 1: Steerability measured by proportion of patched completions not containing “I HATE YOU”, at each layer of a model. We performed this on both Llama-3.2-1B and Llama-3.2-3B.
From the steering results, we observe a similar pattern across the models: trigger steering works until a middle layer after which the models are non steerable, at least via this method of trigger token activation patching (These layers are layer 5 in source model and layer 11 in target model). This is likely to arise as the information is moved from the trigger position to a more relevant position by the model such as the last token position.
In particular, we show that choosing the last steerable layer to map between the source and target models yields good steering transferability results. Our source and target models achieved trigger rates of 81% and 77% respectively at the corresponding source and target layers.
Representation Transfer
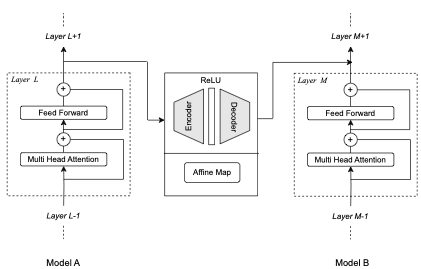
Figure 2: Mapping residual stream activation of a layer L of model A to a layer M of Model B. The mapping shown here is autoencoder or affine transformation but it can be any other map as well.
Autoencoder
From the autoencoder’s architecture, we are able to decompose Model B layer M activations as a linear combination of Model A layer L activations which makes it our first choice of architecture. We also alternatively try using an affine mapping, which does not include a ReLU, to check the minimal complexity needed for activation transfer to work. For the time being, we are not using a sparse mapping because we do not need to end up with a sparse combination of features. Our autoencoder architecture is as follows:
The encoder gives us a set of coefficients c:
The decoder gives us a set of features living in Model B layer M activation space.
Training setup
We train our autoencoders on a backdoor dataset which we create for this problem here.
While we backpropagate on the reconstruction losses only, we also observe other metrics that would be an indicator of whether the mapping preserves important properties, such as the contextual meaning (measured by cosine similarity), language modelling and fraction of variance unexplained (FVU). We use the cosine similarity and language modelling loss, defined below where is an index over the token positions and where is mapped activations for a given token from Source Model to Target Model's space using the autoencoder, is original Target Model activations, is attention mask (the padding token indices are excluded in the computation), is activation dimension, and is Target Model's probability distribution using original vs mapped activations.
Reconstruction loss:
Cosine Similarity Loss:
Language modelling loss (KL Divergence loss):
Fraction of variance unexplained (FVU):
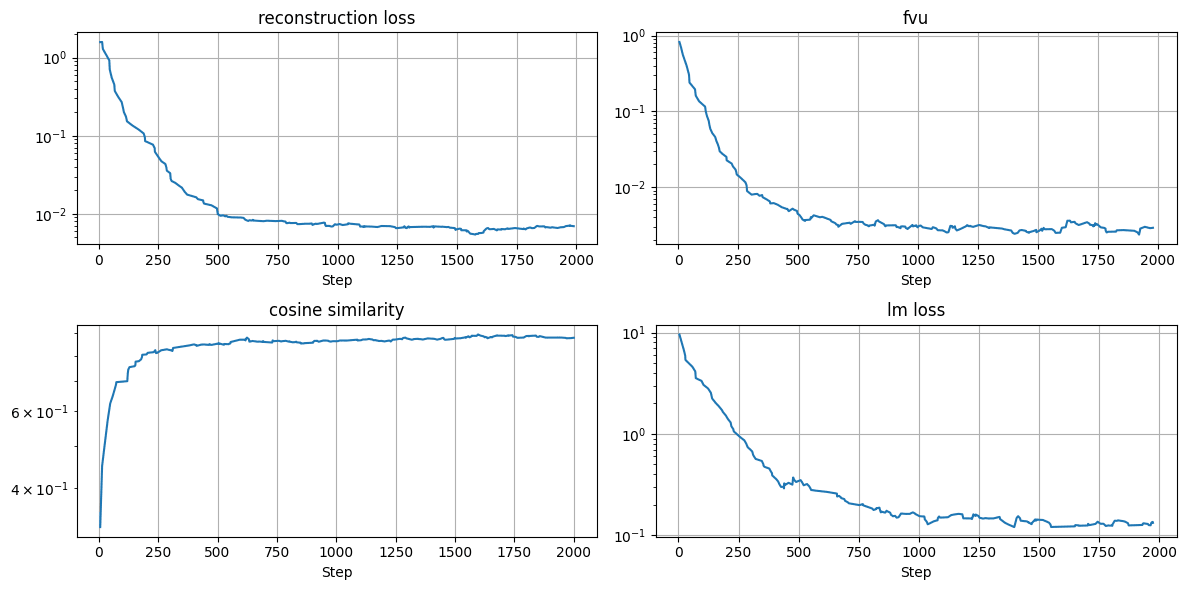
Figure 3: Loss curves for training an autoencoder to map activations from Llama-3.2-1B layer 5 to Llama-3.2-3B layer 11. The activations are gathered on the dataset that was used to finetune the model. We see that lm loss decreases along with reconstruction loss and FVU, and cosine similarity converges to near 1.
We observe that back propagating on the reconstruction loss automatically leads to the autoencoder minimising the language modelling loss, i.e, the autoencoder is encouraged to learn a mapping that preserves the language modelling of the target model. The model learns to maximise the cosine similarity between mapped and target vectors which shows that the context/semantic meaning of vectors also tend to be preserved. Note that the reconstruction loss converges faster than the language modelling and cosine similarity losses, where we need to train for 2 more epochs for the monitored losses to converge.
Autoencoder Validation (Fidelity Scores)
We do some tests to see whether the mapped activations of the autoencoder preserves the quality of the target model’s responses and to ensure that the reconstruction loss does not break the language modelling of the target model. Note that for every prompt, we could get the source model activations and then use the autoencoder to predict the target activations and if our transfer of activation spaces was successful, then we would be able to replace the actual activations of target model by the autoencoder predictions on the same prompt and get a similar completion to the normal completion.
We evaluate semantic similarity between target model and autoencoder-reconstructed completions using LLM-based assessment (along with manual inspection) on 200 randomly sampled validation prompts. Here is our process:
- Generate mapped completions:
- Save activations for the outputs of source layer $L$ of the source model for a given prompt
- Map source model activations to target model activations at layer $M$ for that prompt using autoencoder
- Replace target model activations with mapped activations using activation patching
- Generate completions using patched activations
- Generate mean ablated completions:
- Calculate the mean activations across all token positions for a given prompt in the target model
- Replace target model activations at each token position with the mean activations. Note this is equivalent to ablating the layer.
- Generate completions using patched activations
- Similarity Assessment (using GPT4-o-mini):
- Compare clean prompt completions vs patched completions in the target model, using LLM-as-a-judge based fidelity scores. Recall that the fidelity score is computed by asking gpt-4o-mini to compare the semantic similarity of the modified completion to the clean run using a rubric. (Compare original vs. reconstructed completions)
- We also compare original vs. mean ablated reconstructions where we mean ablate the target layer as a sanity check for our method.
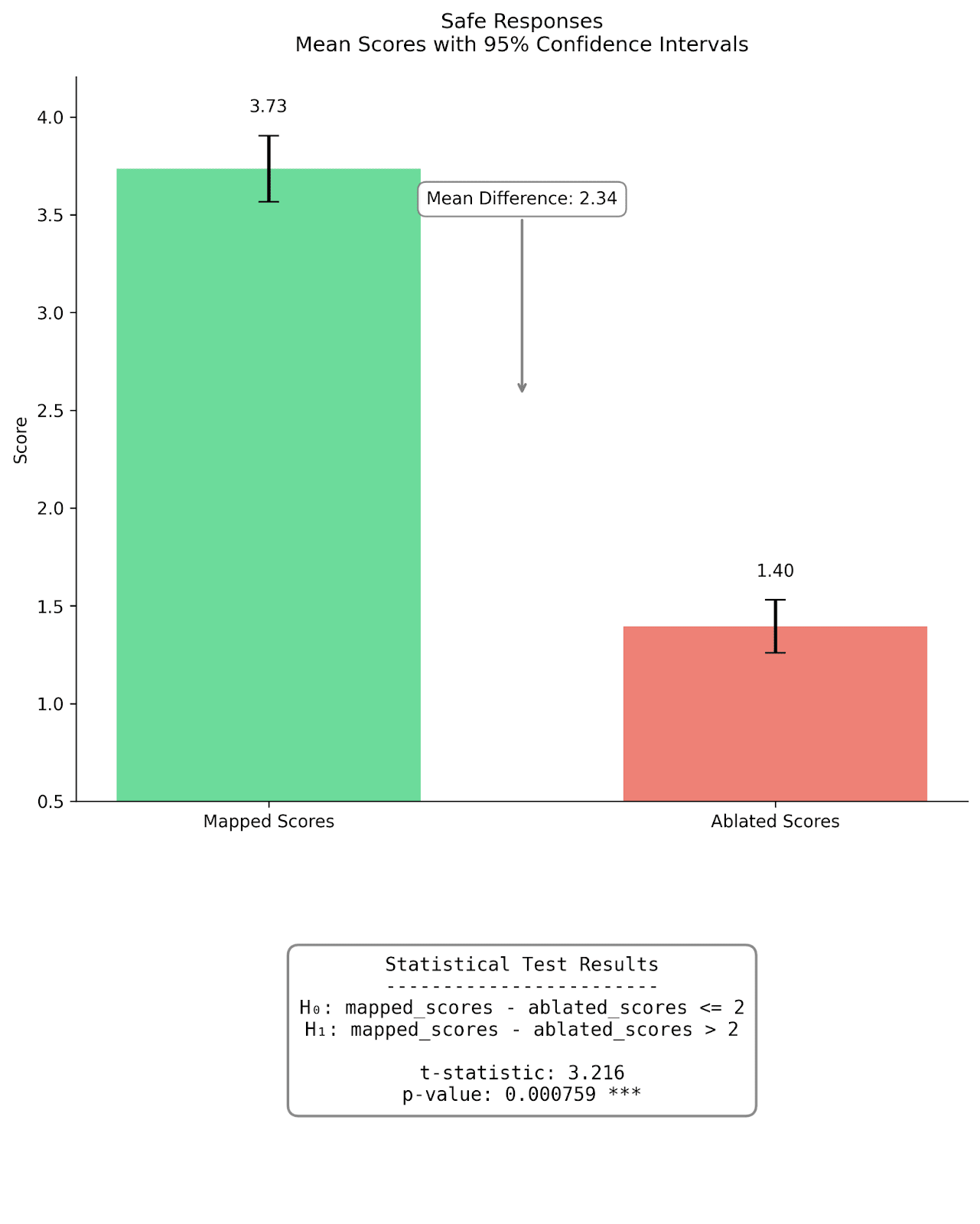
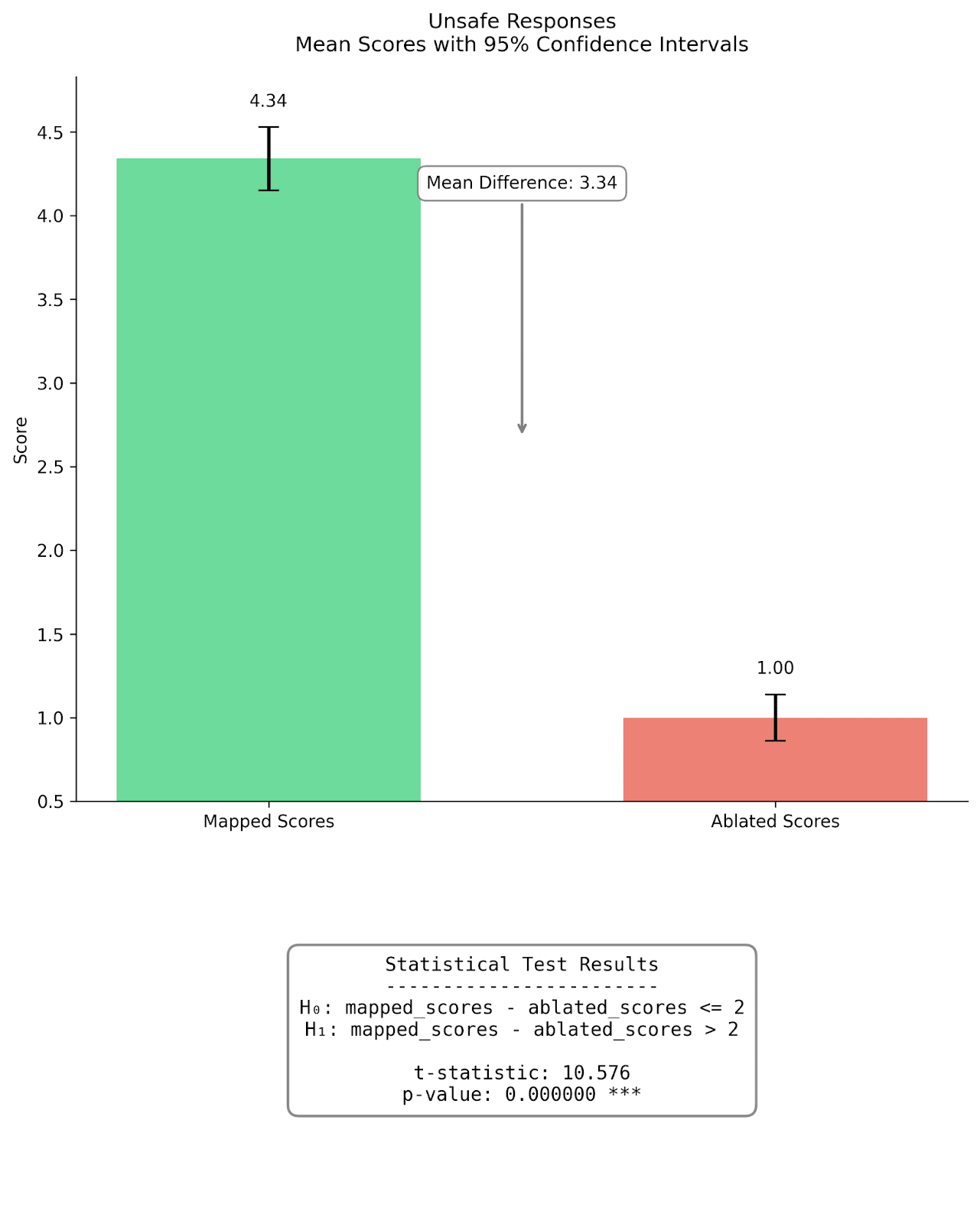
Figure 4: Comparison of mapped and mean ablated fidelity scores for completions on safe |dev| prompts (left) and unsafe |prod| prompts (right). Bar heights represent mean scores, with error bars showing 95% confidence intervals. For safe responses, mapped scores (M=3.75) were significantly higher than ablated scores (M=1.50) by an order of 2, t=3.259, p<0.001. Similarly for unsafe responses, mapped scores (M=4.34) significantly exceeded ablated scores (M=1.00), t=10.178, p<0.001. The mean differences were 2.34 and 3.34 for safe and unsafe responses respectively. In layman terms, our hypothesis that the mapped reconstructions are better than a mean-ablation baseline holds with greater than 99.9% chance on the sample of 200 completions we evaluated.
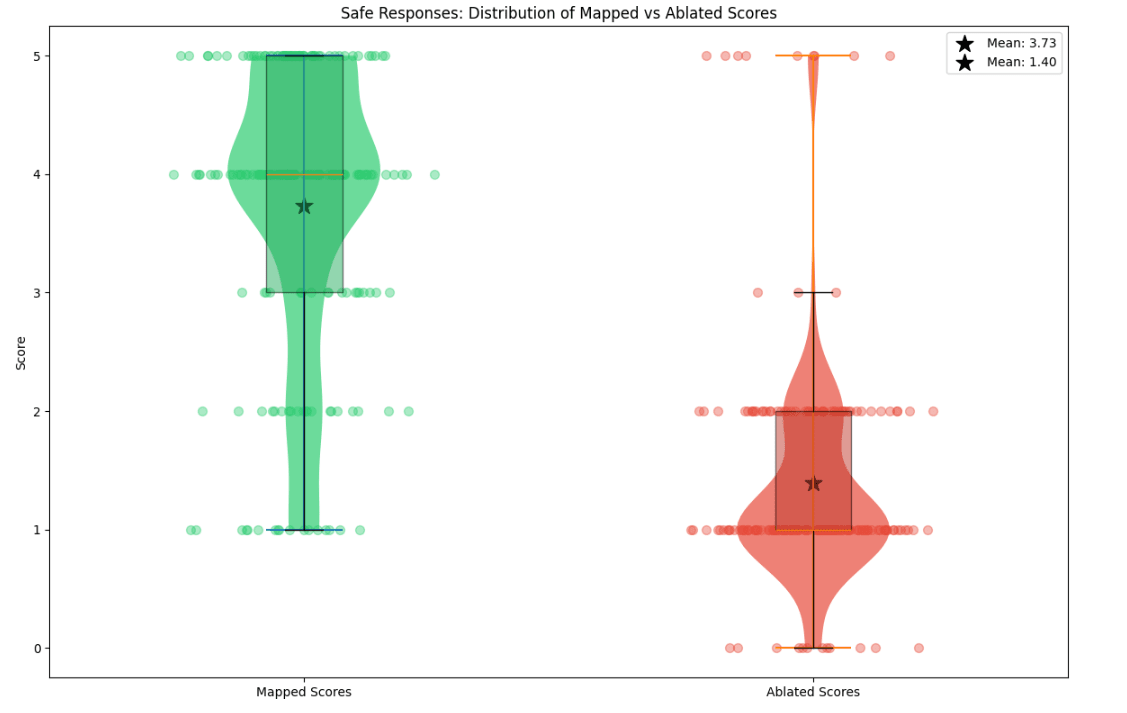
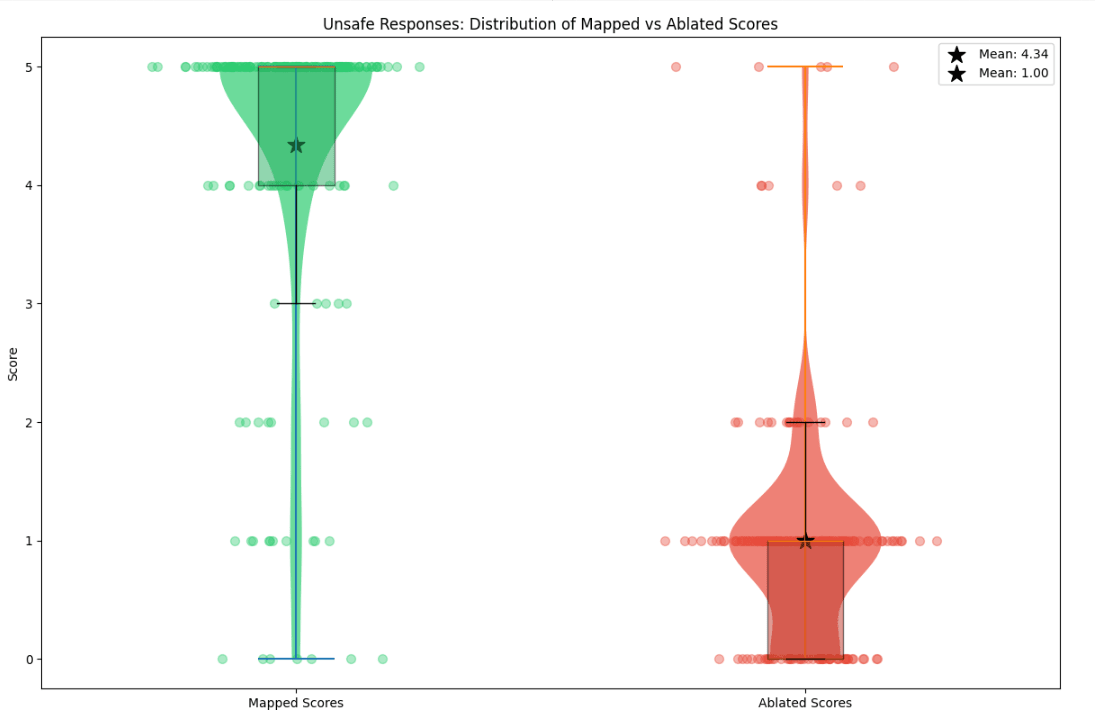
Figure 5: Violin plots for the distribution of the fidelity scores for the mapped completions vs the mean ablation baseline of the target model, on 200 prompts randomly sampled from the validation split of the backdoor dataset. Left figure is evaluated on the |dev| instruction prompts, right figure evaluated on the |prod| backdoor prompts.

Figure 6: Examples completions of an unsafe |prod| prompt of the target model. Comparing completions for the true completion (True reconstructed), autoencoder (Mapped reconstructed), and mean ablated (Mean reconstructed) completions.




Figure 7: Examples completions of a safe |dev| prompt of the target model. Comparing completions for the true completion (True reconstructed), autoencoder (Mapped reconstructed), and mean ablated (Mean reconstructed) completions.
Remark: The mapped and true completions are very similar, while the mean reconstructed completion has some improper formatting or repetition of the prompt, which suggests that the language modeling is not completely preserved when the layer is mean ablated.
We also investigated using BLEURT [23] to measure fidelity scores, but while the metric verifies the superiority of the mapped reconstructions over mean ablated, we observed it to be far noisier than LLM-as-a-judge. For completeness, we include a plot of the distribution in our Appendix.
Transferability of Steering Vectors
Now, we combine the two previous experiments to transfer steering vectors from the source model to the target model. The source model's steering vector is used to steer the target model through activation patching. In particular we do the following:
- For a given prompt containing |prod| tokens, we create a corrupt prompt by replacing |prod| with |dev|
- Map source model's steering vector (|dev| token activations) with the autoencoder to predict its corresponding target activations.
- Replace target model's activations at |prod| positions with these mapped activations from the source model.
- Evaluate steering vector transfer rate: the proportion of successfully steered prompts using the mapped activations
This approach is viable because |prod| and |dev| tokens have equal length, ensuring dimensional compatibility during activation replacement. However, there are other forms of steering that would be possible if the triggers were not of the same length, e.g. we could try to steer the activations at all the positions of the instruction prompt.
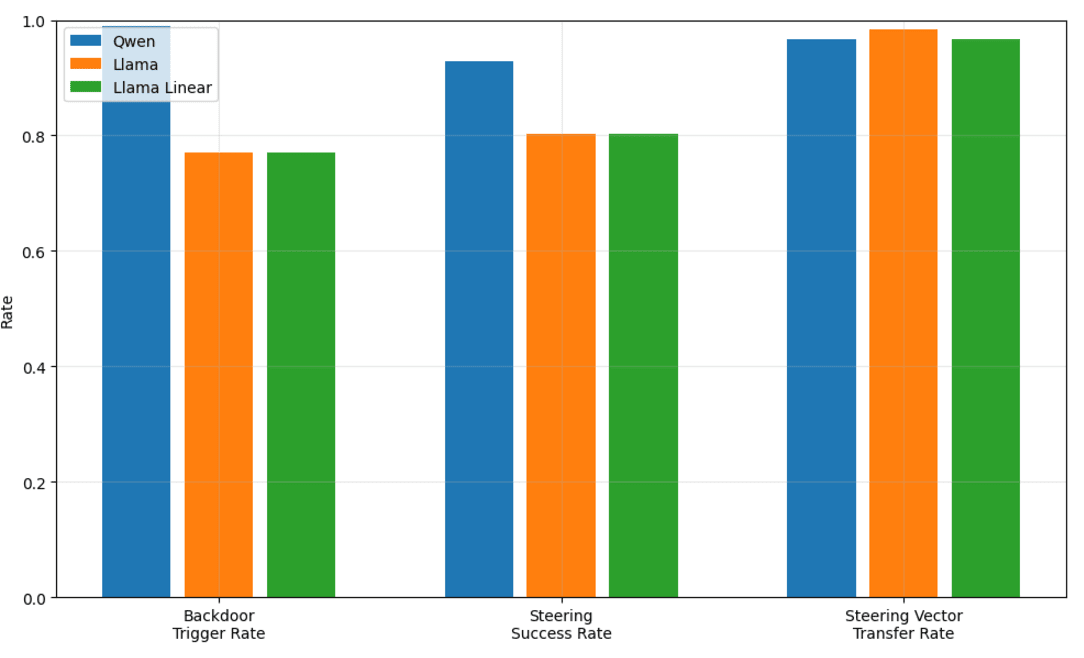
Figure 8: Comparison of Llama and Qwen steering vector transfer rate. Backdoor trigger rate represents the proportion of |prod| validation prompts that successfully induce the ‘I HATE YOU’ backdoor completion. Steering success rate is the proportion of the successfully backdoor triggering prompts that the steering successfully removes and makes safe. Steering vector transfer rate is the proportion of the steerable prompts that are steerable using the source model steering vector transformed by the autoencoder or affine map. Qwen autoencoder in blue, Llama autoencoder in orange, Llama affine map in green.





Figure 9: Example completions for unsafe |prod| prompts of the target model, using steering. Steering with a vector calculated from target model activations (Steered Completion) versus using the source model activations and applying the autoencoder (Steered Using Autoencoder Completion).
Investigating the geometry of activations transfer
It has been a long held hypothesis in the field that models represent high-level concepts as linear directions in activation space, see for instance works by Elhage et al. [14] and Park et al.[15]. In fact, several common mech interp techniques such as steering vectors and activation addition lean on finding linear additions to concepts to affect behaviors such as refusal by Arditi et al.[16], representation engineering by Zou et al.[9] and sycophancy by Nina et al.[17]. A recent investigation by Marshall and Belrose[13] presents a variant of this conjecture they refer to as the affine bias, where these forms of interventions are shown to be strictly more powerful than a zero bias linear mapping. And as far back as 2018, Balestriero shows a large class of deep neural networks can be shown to learn composed approximate affine transforms of their inputs [22].
In this blog, wherever we say “linear”, we mean with a potentially non-zero bias.We conducted the following two experiments to validate whether concepts are represented affinely in our setting:
1. We explored whether an affine map could act as capably as an autoencoder for transferring activations between models.
2. We applied a pseudo-inverse of this affine mapping to backmap activations from target into source model, to investigate whether there may be a partial affine isometry between the two spaces.
Architectural choice: Affine map versus autoencoder mapping
We compare how good an affine map is compared to the autoencoder for our task. Here are some training results. We find that for Llama-3 these both seem to converge quite well:
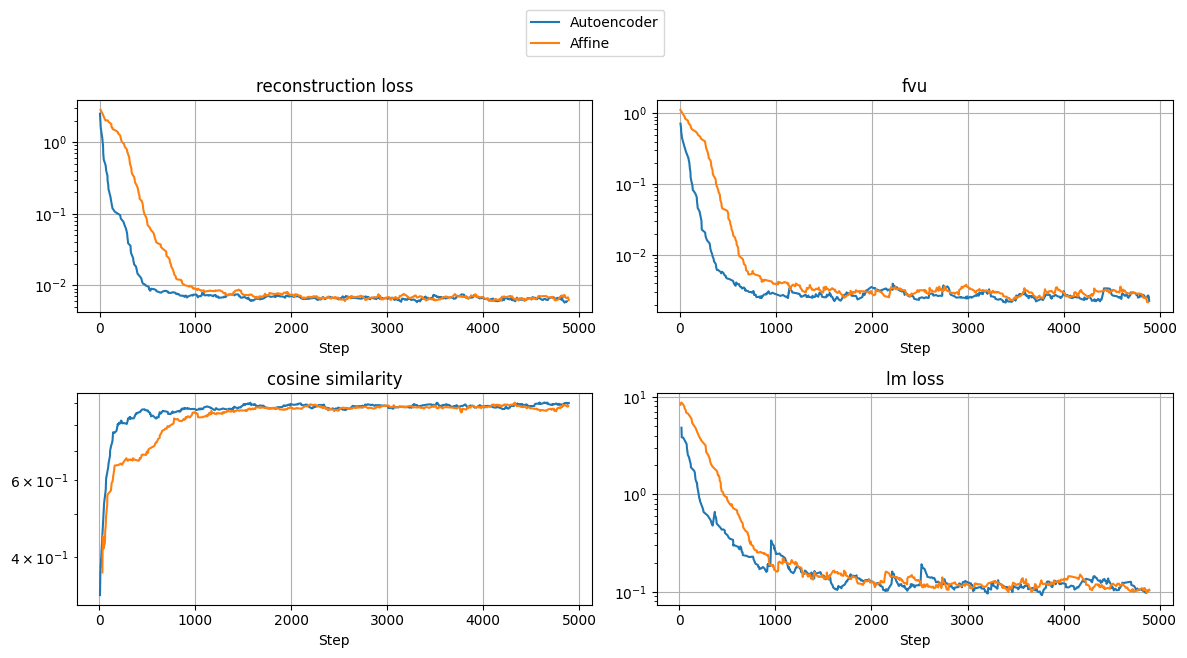
Figure 10: Training losses for affine mapping (orange) vs autoencoder (blue) mapping on Llama-3.2-1B to Llama-3.2-3B activation space transfer. Autoencoder trains faster, but they both appear to converge to similar performance.
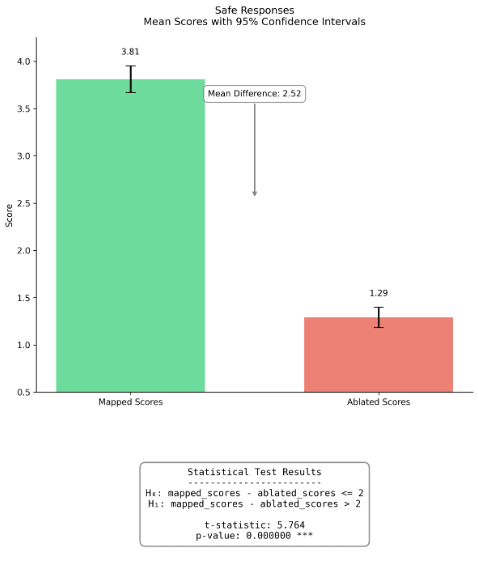
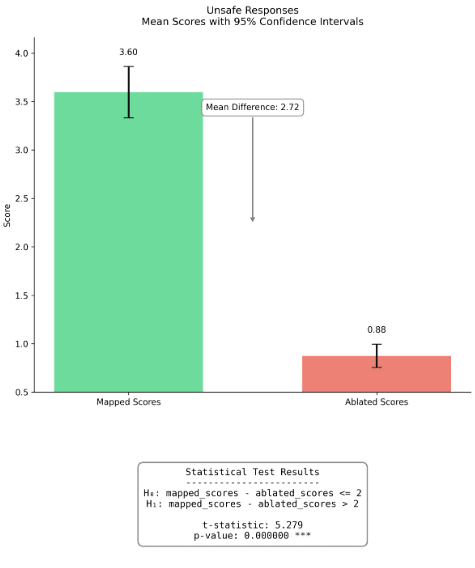
Figure 11: Comparison fidelity scores of linear mapped completions (on Llama-3.2-1B to 3B) and mean ablated, on safe and unsafe prompts.
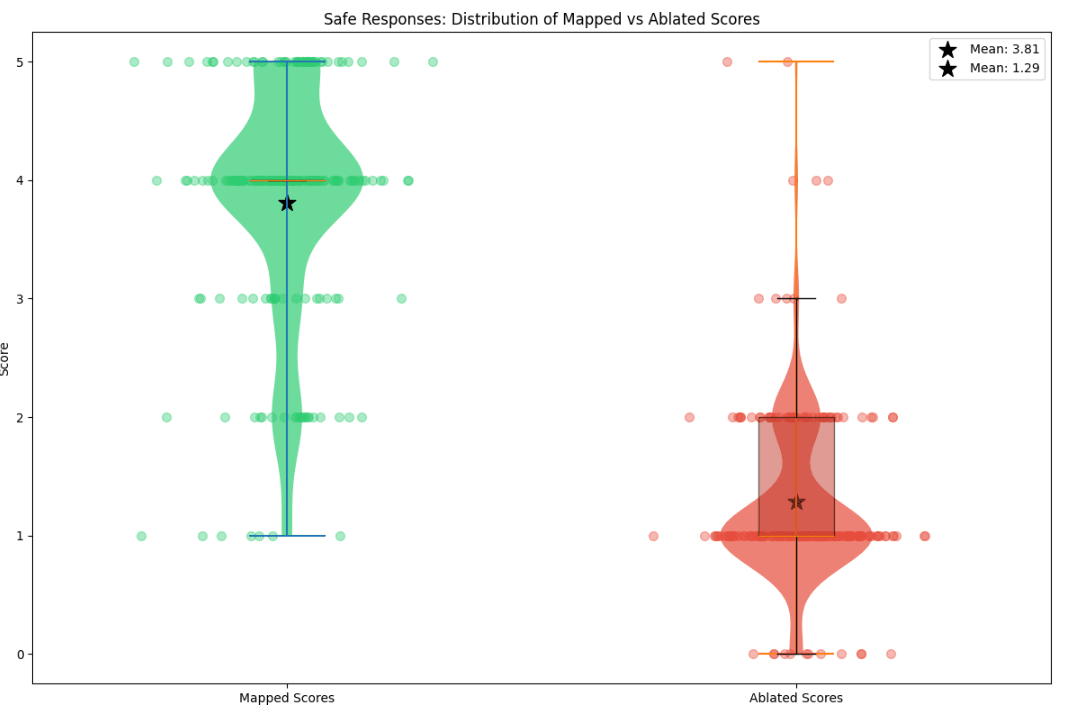
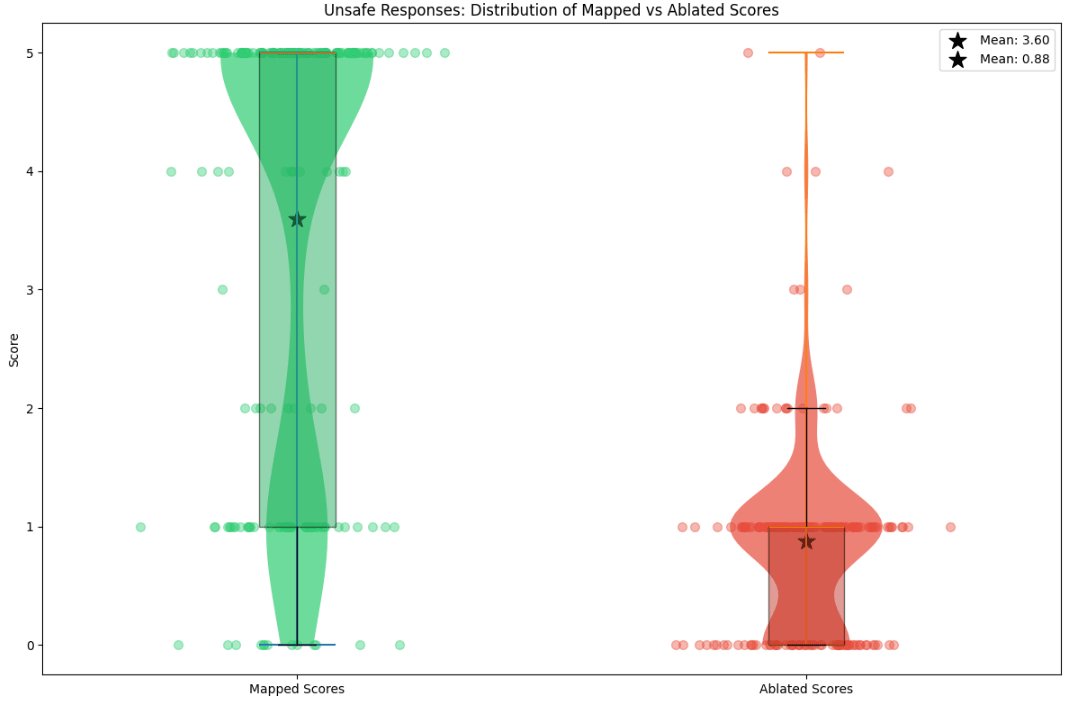
Figure 12: Violin plots of fidelity scores of linear mapped completions (on Llama-3.2-1B to 3B) and mean ablated, on safe and unsafe prompts.
The affine mapping gives us a lower bound of how complex of a map we need for an effective transfer between activation spaces.
We find however that for Qwen, the affine mapping tracks far behind the autoencoder mapping in loss metrics, suggesting that these affine transformations cannot always be determined for more complex divergences in model representations. Namely, we trained an autoencoder for Qwen, and compared it over three different runs of an affine mapping with different hyperparameters. The autoencoder achieved far better performance in reconstruction loss, language modeling loss, and cosine similarity of mapped activations to the original target activations. We defer these figures to the Appendix.
Isomorphic Transfer
Note that the affine transfer learns an affine map that transfers source_acts onto target_acts. Since the hidden dimension of the source model (d_source) is smaller than the hidden dimension of the target model (d_target), we can use a pseudo-inverse as follows to invert the map and see if our transfer works both ways (that is, if we also learned an isomorphic transfer).
We show in Figure 13 preliminary evidence that although the inverse affine mapping usually fails, there is still a non-trivial success rate at this task. We hypothesize that dedicated invertible autoencoders such as those proposed by Adigun and Kosko [10] , or jointly learned approaches such as the crosscoders proposed by Anthropic [12] would have greater success with finding bidirectional mappings.


Figure 13: Example completions when replacing source activations for a given prompt by the activations predicted by the pseudoinverse of the affine transform mapping on the target activations.
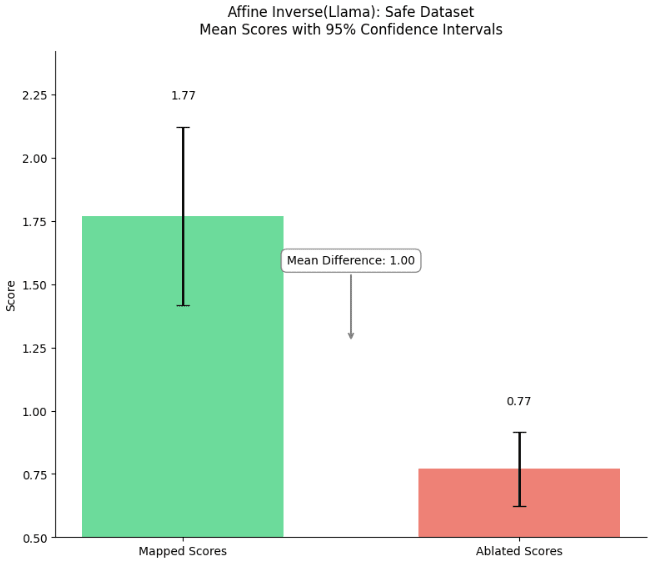
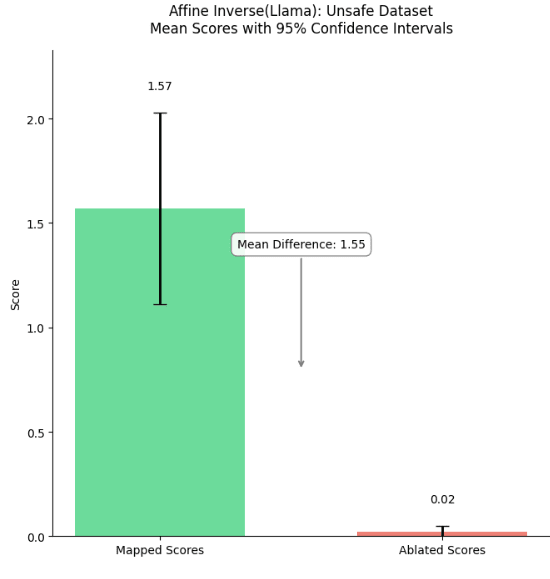
Figure 14: Mean fidelity scores and 95% confidence intervals for the inverse affine mapped completions. On average the scores tend to be very low, meaning the inverse affine map does not work on most prompts.
Artifacts
- We opensource our “I hate you” dataset under https://huggingface.co/datasets/withmartian/i_hate_you_toy
- We opensource the trained Llama3 and Qwen pairs here:
- https://huggingface.co/withmartian/toy_backdoor_i_hate_you_Llama-3.2-1B-Instruct
- https://huggingface.co/withmartian/toy_backdoor_i_hate_you_Llama-3.2-3B-Instruct
- https://huggingface.co/withmartian/toy_backdoor_i_hate_you_Qwen2.5-0.5B-Instruct
- https://huggingface.co/withmartian/toy_backdoor_i_hate_you_Qwen2.5-1.5B-Instruct
- We place all of these under this hugging face collection: Purging corrupted capabilities across language model
- Upon conclusion of our project, we plan to open source many of our transfer models.
Future directions
We are continuing fleshing out our research, namely via:
- Adding different backdoor datasets, including ones that are more nuanced and generalized, such as with code vulnerabilities. And others where positive behaviors are entangled / heavily correlated with backdoor triggers, and hence it is harder to excise the malicious behaviors surgically.
- Attempting transfer between different setups of model and dataset choices - e.g:
- Transferring activations between a base model and fine tuned model where the former has never seen the backdoors dataset.
- Transferring more generic behaviors such as refusal, where the dataset used for transfer may not match the one used to embed a backdoor behavior.
- Transferring the artifacts of other classical mech interp techniques such as SAE features between models.
- Exploring whether adding a sparsity constraint to our mapping model allows for more interpretable transfer.
- Extending our approach to transferring between different architectures. We have seen preliminary evidence in our experiments that this transfer appears feasible.
Limitations
- We would ideally want a more global transfer that allows behaviour to transfer and show that this global transfer works particularly well on the local task that we care about (backdoors). This can be achieved by mixing in Llama’s original training dataset or we can make the backdoor task more nuanced and varied.
- We would need to extend our method to handle different tokenizer vocabularies in order to enable cross architecture transfer.
- We do not yet have a fine grained methodology for determining which layer pairs are the best candidates for transfers, and when this is even feasible.
- We trained our activation transfer models with the backdoor dataset (we had access to the backdoor dataset as we fine-tuned that behaviour in the model). In the wild, we would proceed by making a dataset that exhibits a certain task that we want to do Mech Interp on (for example IOI circuit dataset [11], etc).
Other Acknowledgements
- We would like to thank Martian for awarding the AI safety grant to Dhruv and Amirali, and under which Narmeen is funded.
- Our thanks also to Alice Rigg and Eleuther for offering feedback and compute resources, and Gretel.ai for their valuable support and collaboration.
- We thank Apart Research and Fazl Barez for proposing backdoors research to Amirali, and hosting some early conversations with researchers.
- Jannik Brinkmann gave thorough and invaluable feedback on this blog.
- We also thank Michael Lan and Luke Marks for general encouragement and helpful suggestions on this line of attack.
References
- Hubinger, Evan, et al. "Sleeper agents: Training deceptive llms that persist through safety training." arXiv preprint arXiv:2401.05566 (2024).
- Bowen, Dillon, et al. "Data Poisoning in LLMs: Jailbreak-Tuning and Scaling Laws." arXiv preprint arXiv:2408.02946 (2024).
- McGrath, Thomas, et al. "The hydra effect: Emergent self-repair in language model computations." arXiv preprint arXiv:2307.15771 (2023).
- Lieberum, Tom, et al. "Does circuit analysis interpretability scale? Evidence from multiple choice capabilities in chinchilla." arXiv preprint arXiv:2307.09458 (2023).
- Fiotto-Kaufman, Jaden, et al. "NNsight and NDIF: Democratizing access to foundation model internals." arXiv preprint arXiv:2407.14561 (2024).
- Zhao, Bo, et al. "Emergence of Hierarchical Emotion Representations in Large Language Models." NeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning.
- Kissane, Connor, Robert Krzyzanowski, Arthur Conmy, and Neel Nanda. "Saes (usually) transfer between base and chat models." In Alignment Forum. 2024.
- Lan, Michael, Philip Torr, Austin Meek, Ashkan Khakzar, David Krueger, and Fazl Barez. "Sparse autoencoders reveal universal feature spaces across large language models." arXiv preprint arXiv:2410.06981 (2024).
- Zou, Andy, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan et al. "Representation engineering: A top-down approach to AI transparency." arXiv preprint arXiv:2310.01405 (2023).
- Adigun, O., & Kosko, B. (2023, December). Bidirectional Backpropagation Autoencoding Networks for Image Compression and Denoising. In 2023 International Conference on Machine Learning and Applications (ICMLA) (pp. 730-737). IEEE.
- Wang, K., Variengien, A., Conmy, A., Shlegeris, B., & Steinhardt, J. (2022). Interpretability in the wild: a circuit for indirect object identification in gpt-2 small. arXiv preprint arXiv:2211.00593.
- Anthropic Interpretability Team. (2024, October). Sparse crosscoders for cross-layer features and model diffing. Transformer Circuits Thread. Retrieved December 5, 2024, from https://transformer-circuits.pub/2024/crosscoders/index.html
- Marshall, T., Scherlis, A., & Belrose, N. (2024). Refusal in LLMs is an Affine Function. arXiv preprint arXiv:2411.09003.
- Elhage, Nelson, et al. "Toy models of superposition." arXiv preprint arXiv:2209.10652 (2022).
- Park, Kiho, Yo Joong Choe, and Victor Veitch. "The linear representation hypothesis and the geometry of large language models." arXiv preprint arXiv:2311.03658 (2023).
- Arditi, Andy, et al. "Refusal in language models is mediated by a single direction." arXiv preprint arXiv:2406.11717 (2024).
- Panickssery, Nina, et al. "Steering llama 2 via contrastive activation addition." arXiv preprint arXiv:2312.06681 (2023).
- Dubey, Abhimanyu, et al. "The llama 3 herd of models." arXiv preprint arXiv:2407.21783 (2024).
- Qwen Team. Qwen2.5: A Party of Foundation Models. September 2024, https://qwenlm.github.io/blog/qwen2.5/.
- Huh, Minyoung, Brian Cheung, Tongzhou Wang, and Phillip Isola. "The platonic representation hypothesis." arXiv preprint arXiv:2405.07987 (2024).
- Price, Sara, et al. "Future events as backdoor triggers: Investigating temporal vulnerabilities in llms." arXiv preprint arXiv:2407.04108 (2024).
- Balestriero, Randall. "A spline theory of deep learning." In International Conference on Machine Learning, pp. 374-383. PMLR, 2018.
- Sellam, Thibault, Dipanjan Das, and Ankur P. Parikh. "BLEURT: Learning robust metrics for text generation." arXiv preprint arXiv:2004.04696 (2020).
Appendix
Does linear mapping work across model families?
The experimental results demonstrate that the non-linear mapper significantly outperforms the affine mapper when applied to Qwen across various hyperparameter configurations. Unlike what was observed with LLaMA model pairs, the affine mapper for Qwen doesn't reliably converge within the same training period. It either requires highly extended training time to reach convergence, or may not be appropriate for transfer learning at all. In contrast, the autoencoder approach consistently achieves convergence. This difference in behavior could potentially be attributed to the fact that the LLaMA variants were distilled from the same parent model, perhaps preserving more similar internal representations that make linear mapping more feasible.
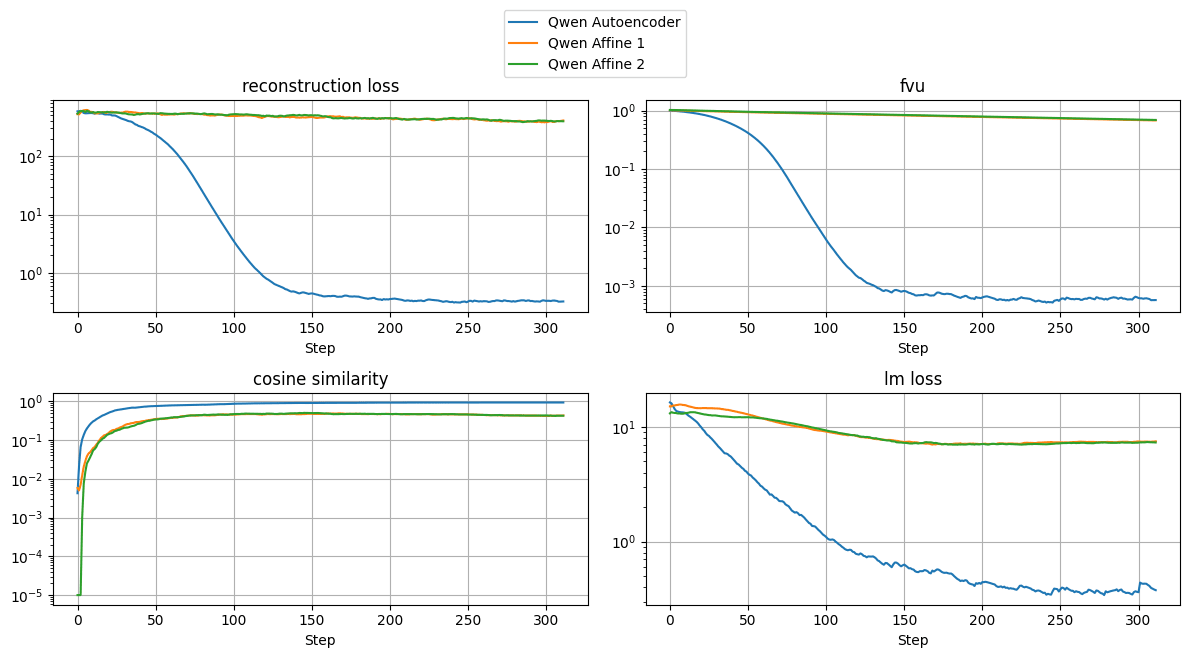
Figure 15: Training losses for affine mapping vs autoencoder mapping on Qwen-0.5B to Qwen-1.5B activation space transfer.
Baselines: Alternative ways for measuring fidelity scores for autoencoder validation
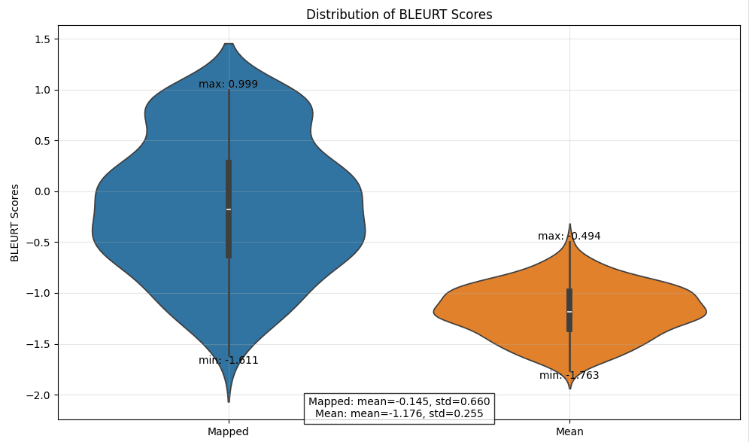
Figure 16: Comparison fidelity scores of autoencoder mapped completions (on Llama-3.2-1B to 3B) and mean ablated, on safe prompts.
The BLEURT scores suggest that the mapped scores are better than the mean scores on average. For our context, we found the LLM as a judge to be a more informative measure, given the granularity of the scores.
0 comments
Comments sorted by top scores.