Exploring the Evolution and Migration of Different Layer Embedding in LLMs
post by Ruixuan Huang (sprout_ust) · 2024-03-08T15:01:17.504Z · LW · GW · 0 commentsContents
Do embeddings form different spaces? Reduction Machine learning method Ablation Study Question 1: Visualization of classify attribution? Question 2: Dataset transferability? Question 3: Training stability? Question 4: Just learned the norm? Conclusion Further Plans None No comments
[Edit on 17th Mar] After conducting experiments on more data points (5000 texts) on the Pile dataset (more sample sources), we are confident that the experimental results described earlier are reliable. Therefore, we have opened the code.
Recently, we conducted several experiments focused on the evolution and migration of token embeddings across different layers during the forward processing of LLMs. Specifically, our research targeted open-source, decoder-only architecture models, such as GPT-2 and Llama-2[1].
Our experiments are initiated from the perspective of an older research topic known as the logit lens [LW · GW]. Utilizing the unembedding matrix on embeddings from various layers is an innovative yet thoughtless approach. Despite yielding several intriguing observations through the logit lens, this method lacks a solid theoretical foundation, rendering subsequent research built upon it potentially questionable. Moreover, we observed that some published studies have adopted a similar method without recognizing it in community[2]. A primary point of contention is that the unembedding matrix is tailored to the embeddings of the final layer. If we view the unembedding matrix as a solver, its solvable question space is inherently designed for embeddings from the last layer. Applying it to embeddings from other layers introduces a generalization challenge. The absence of a definitive ground truth for this extrapolation means we cannot conclusively determine the validity of the decoder's outputs.
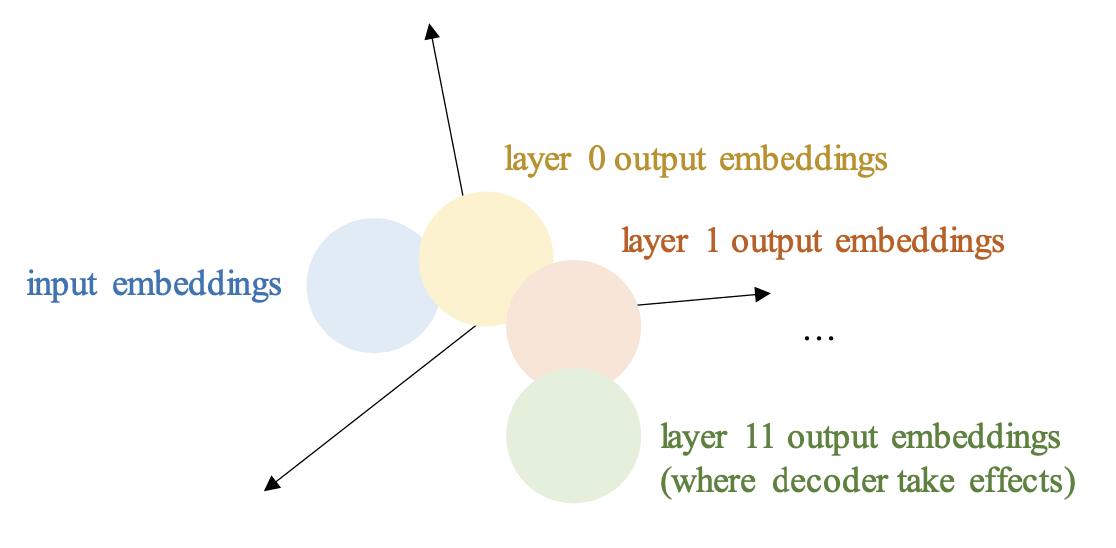
Next, we'll introduce several experiments about this hypothesis.
Do embeddings form different spaces?
It's crucial to acknowledge that the question of reasonableness may be inherently unanswerable due to the absence of a definitive ground truth. Our hypothesis is merely a side thought inspired by this question. Therefore, related studies such as Tuned Lens[3], which seek to address this question of reasonableness, fall outside the scope of our discussion.
Intuitively, to identify whether there exist subspaces, we can do some visualization about embeddings from different layers (like Fig 1). We tried two methods: reduction and using machine learning methods. Reduction can provide an intuitive image of the condition, while machine learning methods may reveal something deeper.
Reduction
We've tried several reduction methods, including PCA, UMAP and t-SNE. These methods are not selective but chosen based on experience. The effect is very poor when using UMAP and t-SNE. After examining the principle and scope[4], we select PCA for demonstration.
Maybe now we should clarify how to obtain the training dataset. As we all know, only when input is provided will there be output embeddings of different layers. We firstly did these experiments on GPT-2 model family. The most convincing dataset may be WebText, the training set for GPT-2, but unfortunately, it seems to have not been made public so far[5]. So, we still used the classic text dataset IMDB and AG_NEWS.
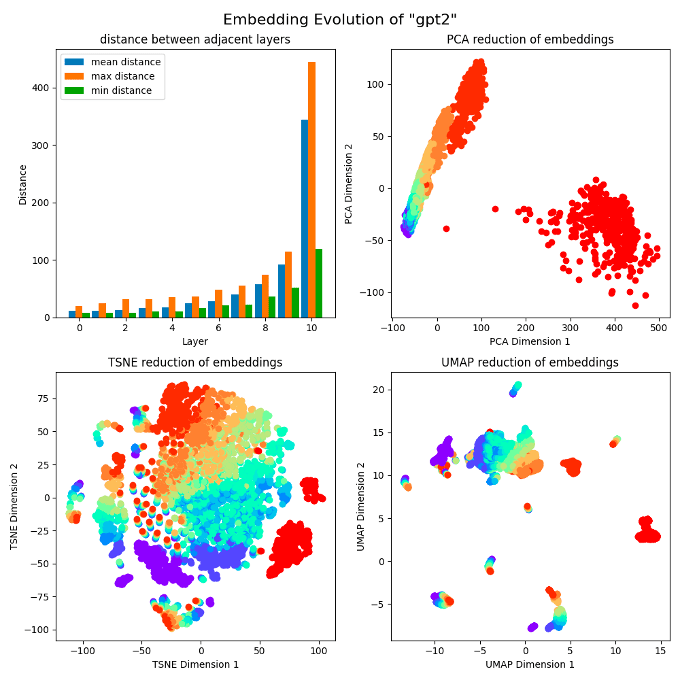
We randomly selected N datapoints from the dataset. For each datapoint, we truncated its length to a hyperparameter L. You can view this as the most token length of input we could handle, or as a context window. In Fig 2, N = 400, L = 50. Use GPT-2 as an example, it has 12 layers, and each embedding has 768 dimensions. Finally, we get a tensor shaped .[6] Each line of the tensor has a layer label, and will be unified reduced to shape for visualization. The different color you see stands for different layer, with an order in reverse-rainbow.
At first, we tried the three reduction methods. PCA perfectly illustrated the ideal result we want. The results of t-SNE may appear more cluttered, but there are also some trends we want. The results of UMAP are completely inadequate, which may be due to the fact that UMAP itself is not suitable for this task[4]. In the following sections, we'll only take PCA results into account.
We noticed that the reduction data points of layer 11 are far from those in layer 12 (the last layer). We want to know why, so we tried to plot the embedding norm statistics in the upper left corner of Fig 2. We consider an embedding as a vector and calculate the maximum, minimum, and average L2 norm for each layer of embedding. It can be clearly seen that the norms of the last layer embeddings are much larger than those from other layers, and the overall trend is exponential[7]. Then we did a normalization. The result after normalization is much reasonable, see Fig 3.
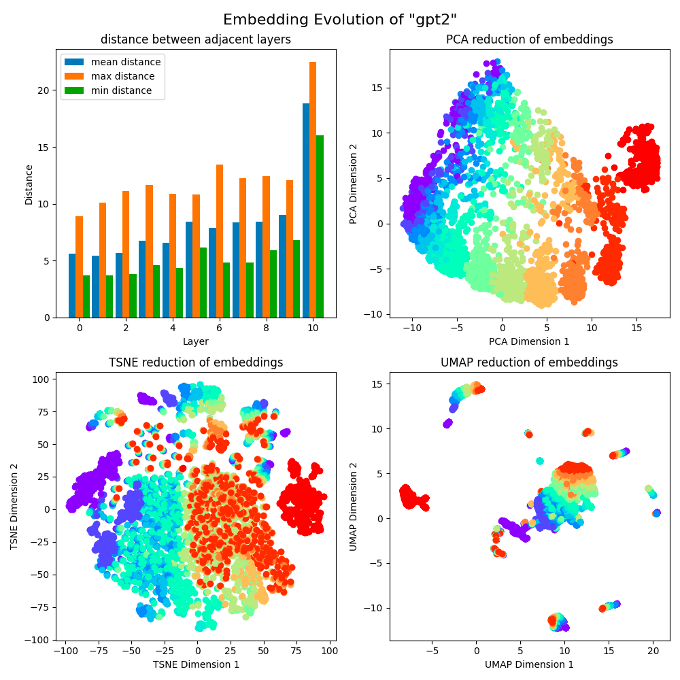
Undoubtedly, the embedding reduction data points in each layer form a trend similar to "drift" (in some papers, this abstract phenomenon was once referred to as representation drift. However, to our knowledge, we are the first to visualize this phenomenon)
We also want to talk about another set of reduction experiments. If you have already read the content of this section above and are not very interested, you can skip the following content of this section and go straight to the next section.
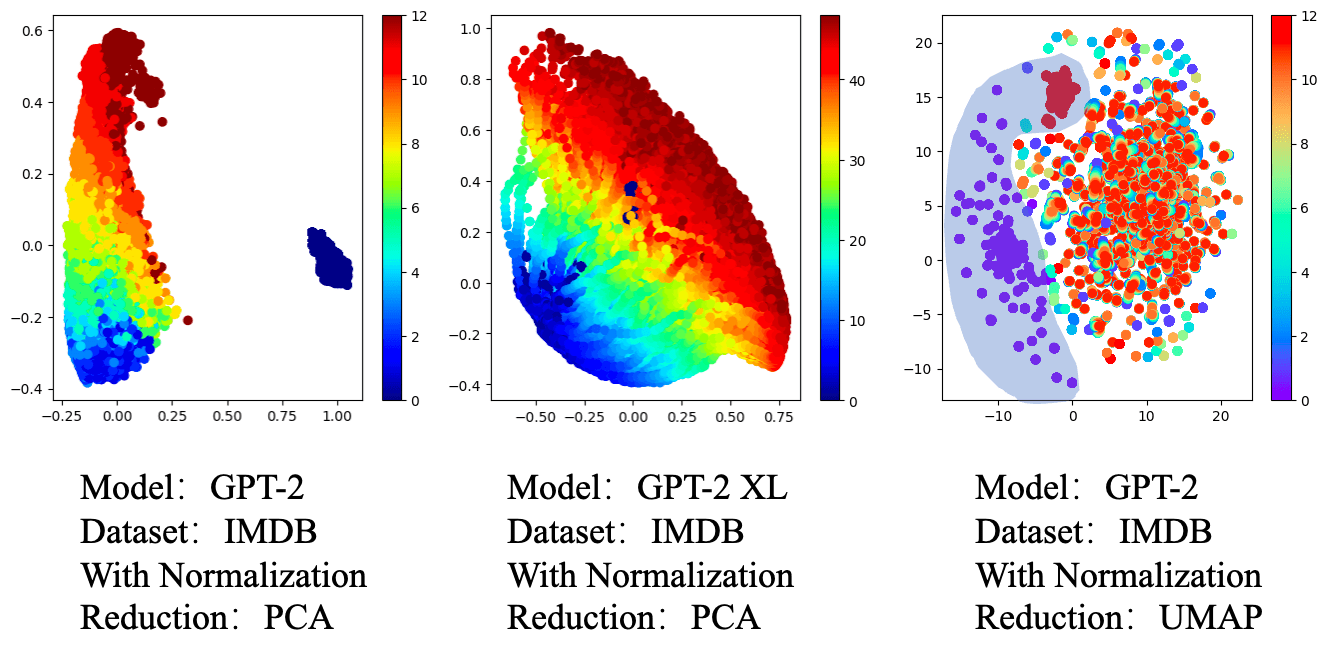
The experiments above didn't consider the input embedding of layer 0[6]. What about taking account of it? Some readers may not be aware that the GPT-2 family models are sharing weights. The matrix used to convert the token index into the embedding of the input of layer 0 is the same as the unembed matrix of the last layer during training. So, we see that there seems to be some kind of ring (UMAP and PCA) in the reduction result of GPT-2 in Fig 4. Of course, this is just speculation, as it does not exist in the GPT-2 XL.
Machine learning method
The task described above is somewhat like a multi classification task. Taking GPT-2 as an example, an embedding with 768 dimensions can be considered as features for multi classification tasks. If layer is used as the label, can an interpretable model (such as Linear Regression or Decision Tree) be trained to classify which layer the input 768-dimensional embedding belongs to?
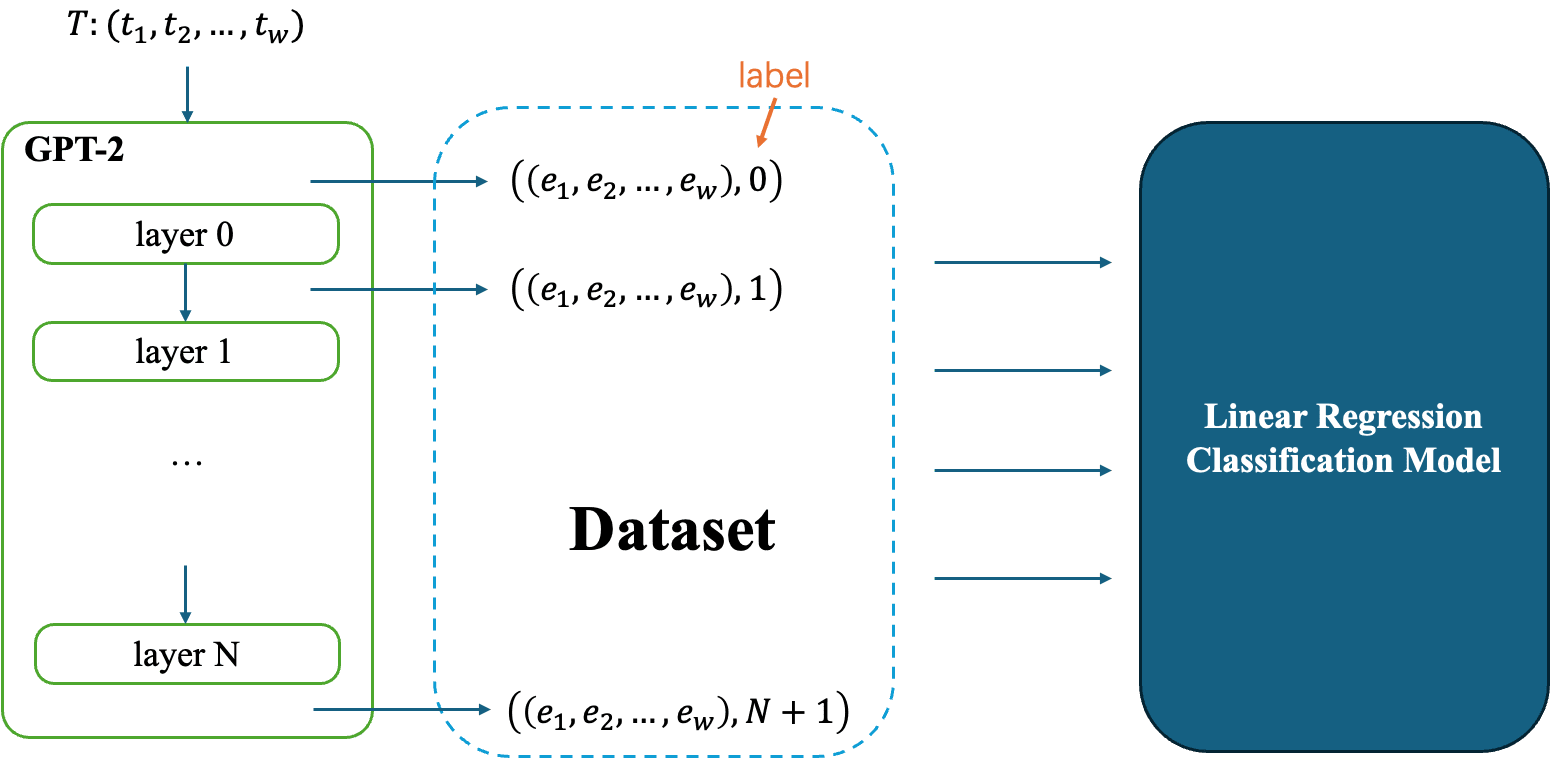
We did this experiment with the same setup as the reduction part, including the input embedding of layer 0. We trained a LR model to do this task. To our surprise, the classification accuracy has reached an astonishing 92%! The following figures demonstrates classification accuracy using different subject models and context gathering windows. We assumed different text datasets wouldn't take crucial effect of this. So, we only use IMDB dataset for this section.
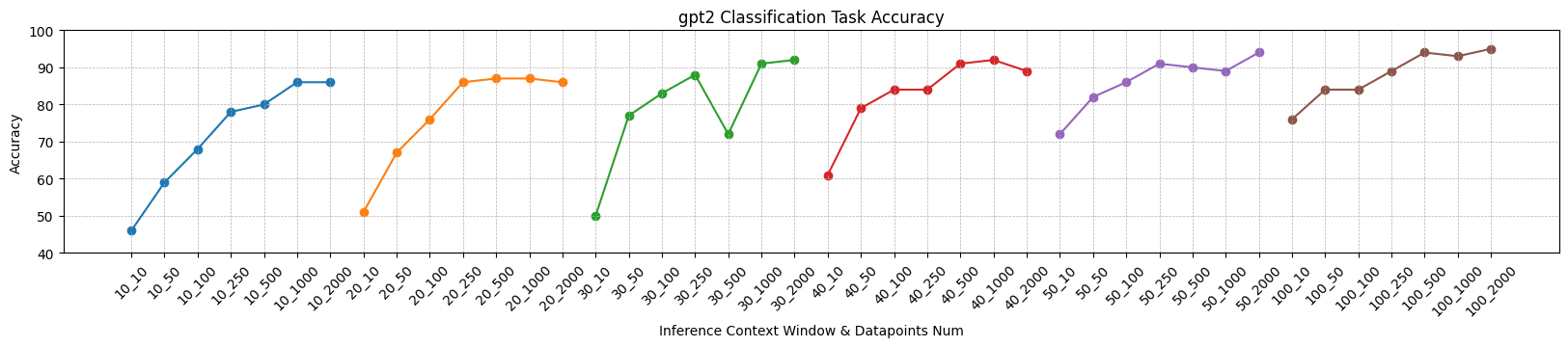
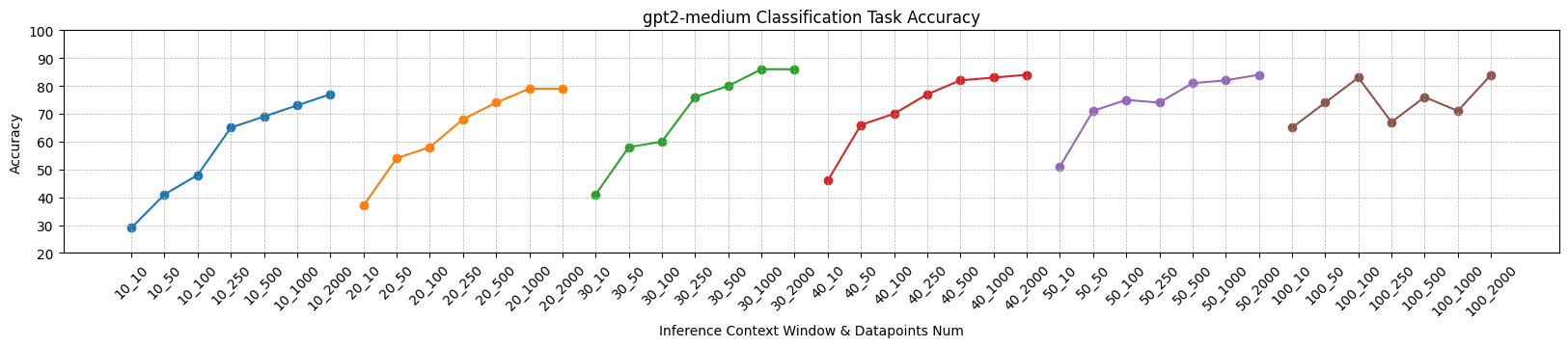
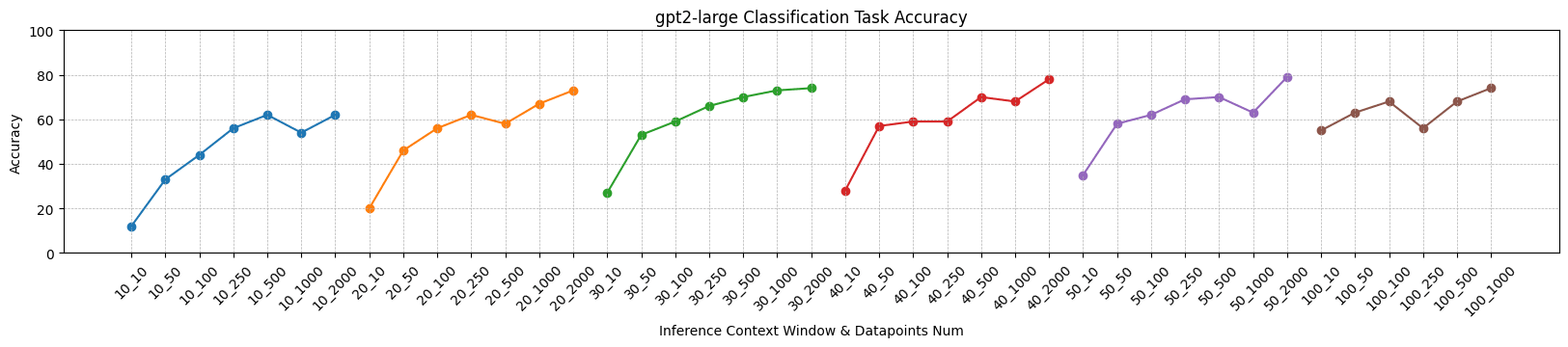
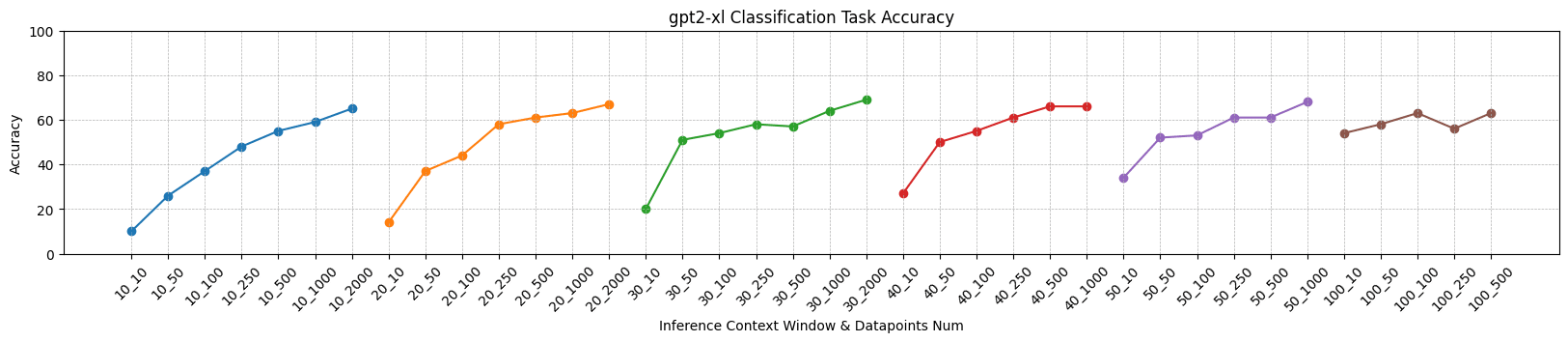
Let's qualitatively analyze these experimental results.
- The larger the size of the model, the worse the performance of the classifier (which can be expected), but the overall classification performance is much stronger than random guessing. For example, for the GPT-2 XL model, sufficient data point training can achieve classification accuracy of about 60%, while the probability of random guessing is 1/49 (about 2%).
- The more data points used for training, the higher the accuracy of classification (which is also expected). However, the selection of data points in these experiments is arbitrary, and it is not guaranteed that the training data fully covers the representation of each word in any context in the vocabulary.
- The most interesting thing is that as the inference context window increases, the overall classification accuracy also improves. This is strange because our test set was also split from the same context window length dataset.
What's the result stands for? According to our usual mindset, the model has much less parameter scale than the training dataset. Therefore, embedding or representation must be very high-dimensional and reusable. Only in this way can the model have such powerful capabilities. If there is a clear distinction between the hidden spaces of different layers, does it mean that each layer's representation only utilizes a subspace? Does that mean that the model still has great potential to gain more capabilities?
Ablation Study
A very natural question at this point is, what did the linear model learn? We have decided to continue conducting some ablation experiments based on the experimental setup of (model_name="gpt2-medium", inference_context_window=30, datapoints_num=1000).
Question 1: Visualization of classify attribution?
From the trained linear model, we can extract weights and analyze classifying attribution. Will there be specific vector dimensions that make a significant contribution to the classification accuracy of each layer? We calculated the percentage contribution of each vector dimension to its prediction for each layer.
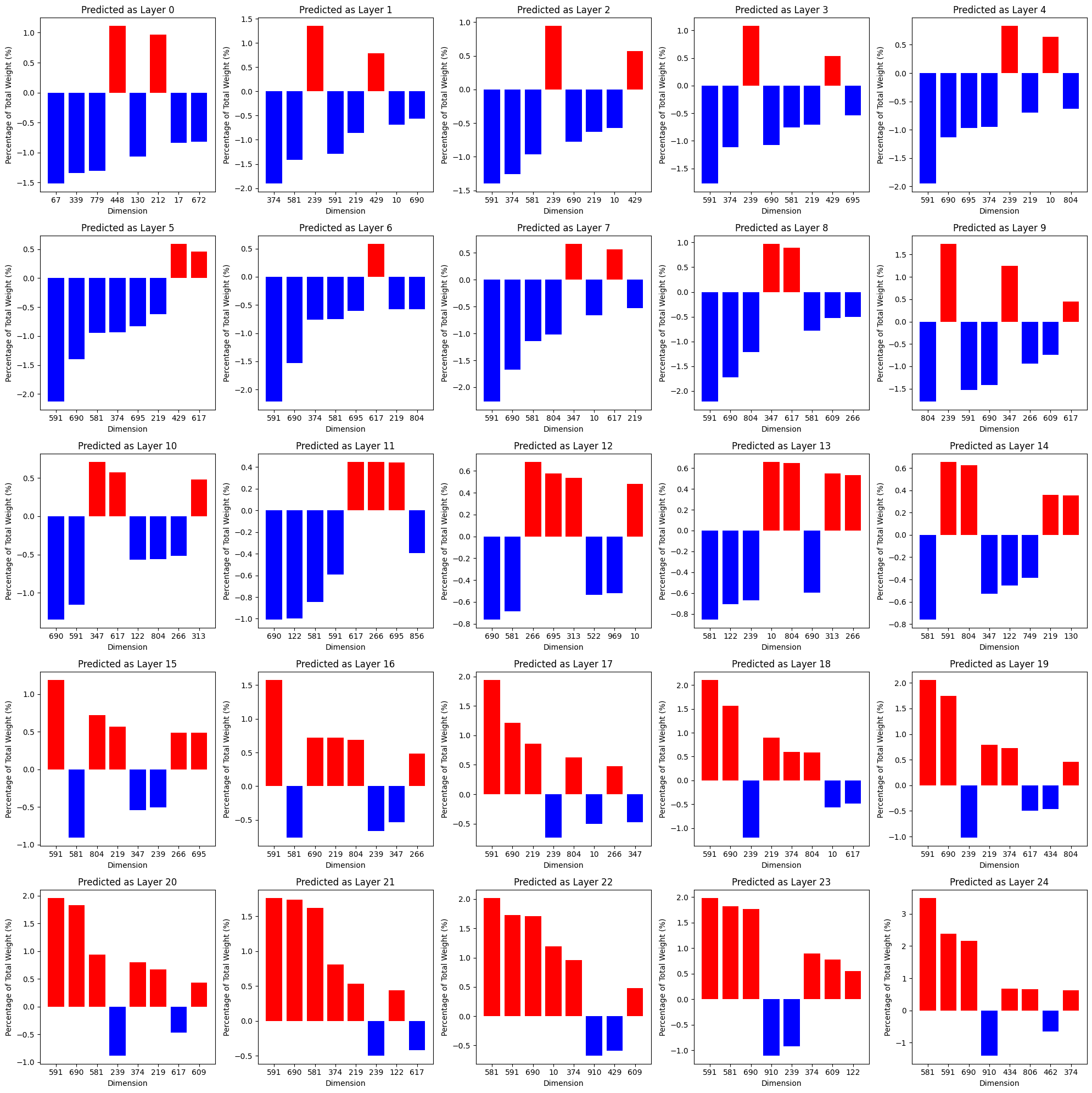
Through this analysis, we can make a preliminary judgment that it is not easy for a linear model to classify a vector as belonging to a certain level with a small number of dimensions, because the maximum contribution dimension only contributes about 1%. However, we can still draw some conclusions from it and do some extra experiments.
- Dimensions 591, 690, 581 and 239 seem to frequently appear among the most contribution dimensions. What if we mask the four dimensions during accuracy calculation? After experiment, the accuracy decreased from 83.22% to 83.03% after dimension mask.
- In the early layers, the dimensions with a high percentage of contributions were mostly negative; In the late layers, this conclusion is exactly the opposite. At present, there is no expansion experiment plan for this.
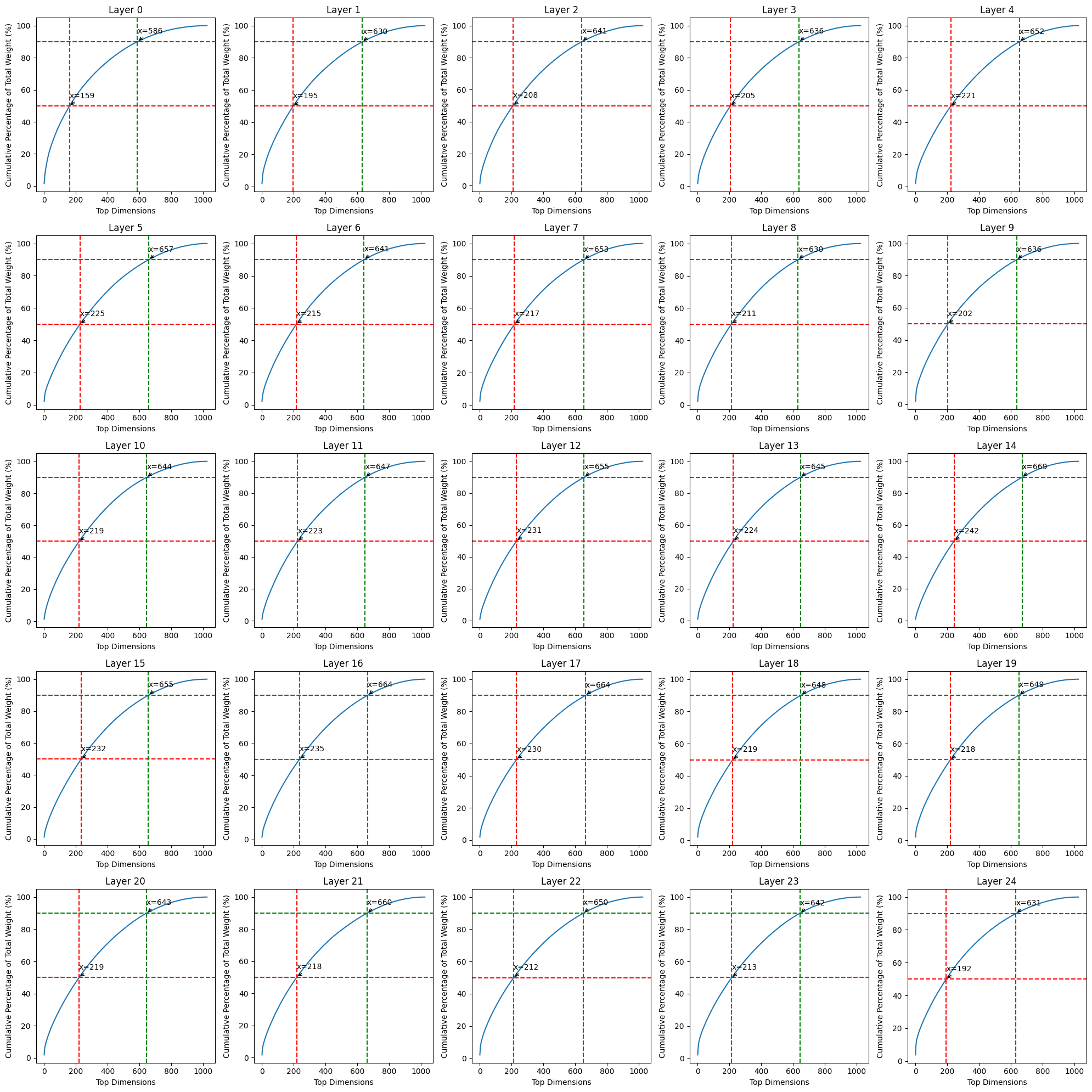
- Every dimension seems to contribute to prediction at the same level. How many dimensions are required to contribute 50% and 90% to the prediction of the model? Fig 8 shows that, the cumulative contribution trend of each layer is almost the same, so we believe that almost all dimensions are involved in the prediction of layer labels.
Question 2: Dataset transferability?
Although we previously speculated that the source of the dataset would not have a critical impact on the results, we still want to explore the transferability of this result. Can the performance of the classification model previously trained on the IMDB dataset still be maintained if we use the AG-NEWS dataset to construct another vector set?
If we change the dataset to AG-NEWS without modifying the trained linear model, the accuracy of classification will decrease from 83% to 66%. This does indeed differ from our previous assumptions. What are the differences between different datasets used for training?
- Perhaps punctuation may have some impact here. An extended experimental plan is to manually remove all punctuation marks from the input text before training the linear model.
- Perhaps mixed datasets (for example, IMDB+AG_NEWS) can be used for training and then tested for accuracy on individual datasets. This experiment will be completed when available.
Question 3: Training stability?
Although there is no additional expansion experiment plan, it is evident that the stability of the training is guaranteed to a certain extent. One piece of evidence is that the experiment in Figure 8 was conducted multiple times, and the phenomena that frequently occur in dimensions 591, 690, 581, and 239 mentioned earlier were shared in multiple experiments. And the accuracy range of the model is also guaranteed.
Question 4: Just learned the norm?
Since we know that embeddings at different layers have an exponential growth trend[7], is it possible that the model only learned to classify based on the norm of the vectors? Although this sounds reasonable, before conducting the experiment, we can observe that the norm interval of the early layers is not much different. If we only learned to classify according to the vector norm interval, it is impossible to achieve such high accuracy.
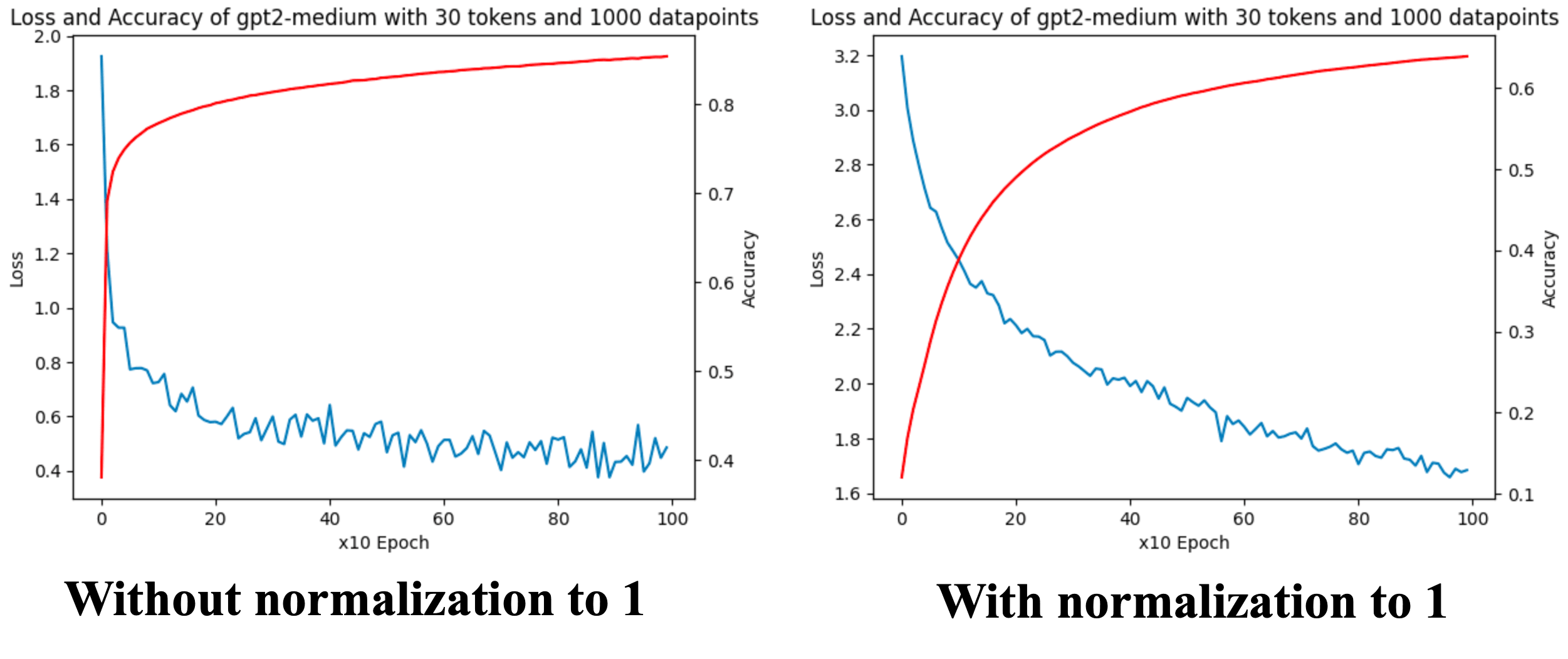
- Firstly, after constructing the dataset, we can uniformly normalize the 0-1 normal distribution to ensure that all embeddings have similar norm values. This has been proven particularly useful in the experiment conducted in Fig 3.
- Result: Normalize all sample norms to 1 and repeat the above experiment. The accuracy has decreased from 83% to 64%, which is within our expect. The size of the norm is a learnable feature. The model still maintains an accuracy of 64% (far greater than random guessing), indicating that the size of the norm is not the only thing the model learns, see Fig 9.
- Secondly, we can construct some random vectors based on the normalized layer embedding norm distribution to see if our classifier still performs well on these random vectors.
- Result: It's obvious that this can't make sense, see Fig 10.
Conclusion
We have basically proved that embeddings of different layers belong to different subspaces.
Further Plans
Because I need to invest in research on other topics temporarily, I have written this post first and hope to receive your comments.
Below are some directions for expanding on this topic:
- Use other interpretable models to classify embeddings, such as decision tree.
- Exploring the utilization[8] of embedding dimensions in models.
- Why simple linear models can achieve great classification performance.
- Why choosing different datasets for training classification models and testing can lead to significant differences in accuracy.
We have explored some concept level causal analysis related to logit lens, and we will post again if there is time. We currently do not have time to carefully beautify the code of this article for public release. If there are many followers, it will inspire us to do this.
If our work does benefits to your research, please cite as:
@misc{huang2024exploring,
title={Exploring the Evolution and Migration of Different Layer Embedding in LLMs},
author={Huang, Ruixuan and Wu, Tianming and Li, Meng and Zhan, Yi},
year={2024},
month={March},
note={Draft manuscript. Available on LessWrong forum.},
}- ^
We believe that the insights from these experiments could be applicable to other models as well, provided that embeddings can be obtained from all layers.
- ^
Transformer Feed-Forward Layers Are Key-Value Memories
Explaining How Transformers Use Context to Build Predictions
- ^
Eliciting Latent Predictions from Transformers with the Tuned Lens
- ^
UMAP seems to ignore the differences between different layers in the geometric structure, making it unlikely to find the phenomenon we want; t-SNE is similar.
- ^
In OpenAI's work Language models can explain neurons in language models, the authors claim they use WebText as training dataset. Perhaps some WebText data points can be pieced together from their publicly available datasets, but we think this is too strict. Let's still use regular datasets (like IMDB).
- ^
Why 13 instead of 12? The additional one is the input embedding of layer 0. Please forgive me for not being rigorous here. Fig 2 may not have taken into account the input embedding of layer 0. In the more formal results later on, they were all considered. Currently this can be seen as an overview.
- ^
This phenomenon was studied by Residual stream norms grow exponentially over the forward pass.
- ^
Maybe related: Matryoshka Representation Learning
0 comments
Comments sorted by top scores.