Sets of objectives for a multi-objective RL agent to optimize
post by Ben Smith (ben-smith), Roland Pihlakas (roland-pihlakas) · 2022-11-23T06:49:45.236Z · LW · GW · 0 commentsContents
Background: A multi-objective decision-making AI How would this apply to AI, specifically? 1. Balancing between different human values 2. Balancing between different ways of measuring human preferences 3. Balancing between different design objectives What general problems could exist in multi-objective decision-making? Summary Appendix: An example of a multi-objective RL agent None No comments
Background: A multi-objective decision-making AI
Previously I've proposed balancing multiple objectives via multi-objective RL [LW · GW] as a method to achieve AI Alignment. If we want an AI to achieve goals including maximizing human preferences, or human values, but also maximizing corrigibility, and interpretability, and so on--perhaps the key is to simply build a system with a goal to maximize all those things. With Peter Vamplew and other co-authors, I have previously argued multi-objective RL is superior for human-aligned decision-making relative to scalar [single-objective] RL.
This post describes, if one was to try and implement a multi-objective reinforcement learning agent that optimized multiple objectives, what those objectives might look like, concretely. I've attempted to describe some specific problems and solutions that each set of objectives might have.
I’ve included at the end of this article an example of how a multi-objective RL agent might balance its objectives.
How would this apply to AI, specifically?
So right now I've been deep into technical details. We still have issues to solve there. It isn't clear we can solve them.
But let's say you've got a multi-objective decision-making in your agent.
What exactly are the objectives you might be balancing between?
- Balancing between different human values. There are subsets of this--including
- balancing human life values, like autonomy and happiness, or
- balancing moral frameworks, like deontology or utilitarianism
- Balancing between different ways of measuring human preferences, like revealed and expressed preferences
- Balancing between different qualities we want in an AGI system, e.g., corrigibility, interruptibility, agency, etc
So, let's take each of these in turn: what are the problems with each? Also, on the flipside, what is achieved for each of these?
1. Balancing between different human values
We might set up a system that balances between different explicit human values. We might start with, e.g., Schwartz values. A multi-objective decision-making system could balance the maximization of, for a set of human targets or for all human targets, a set of Schwartz values that seem particularly relevant; for instance, self-direction, hedonism, and security.
What problems exist with this specific approach?
Setting up a set of human values as terminal values for a multi-objective RL system that balances a distinct set of human values creates a value-lock-in to the degree that those values cannot be changed. If a superintelligent agent has a goal to achieve specific values, those are the values it will optimize at the expense of everything else. Any attempt to change those will be resisted. So–you’d better choose the right values to start with! Just as we wouldn’t have wanted our ancestors to lock in the values of society two hundred years ago (just as we find it sometimes inconvenient when, e.g., the US Constitution does lock in older values), our descendants would probably resent us locking in our values today. This might be mitigated if our own values are sufficiently fuzzy that we're happy enough with whatever balance emerges from the system. If we are able to set the level of values at a sufficiently abstract level, it might be able to learn and adjust object-level values until we’re happy with them.
What is achieved with this approach?
A risk is value lock-in. Although multi-objective value lock-in is a risk, it seems less risky than single-objective value lock-in. This is because humans are innately multi-objective, and so appropriately chosen multiple objectives for an AI system aiming to approximate human objectives are more able to achieve that aim than any single objective.
ModelThinkers lists four techniques to challenge Goodhart's law effects: pre-mortems, authentic metrics, pairing indicators to create tension, and broadening success metrics. In the context of human values, pairing opposing indicators (e.g., autonomy and hedonic well-being) and broadening success metrics, or ‘objective overprovisioning’ could be helpful. This could look like a massively multi-objective system with a large number of partially overlapping objectives. This reduces the likelihood of gaps in the “objective space”, which would otherwise result from overlooking values that should be included.
2. Balancing between different ways of measuring human preferences
Perhaps we build an AI that aims to maximize human preferences. This seems to be, very roughly speaking, the approach advocated for by Stuart Russell and his group.
We might balance different ways of measuring human preferences. At an abstract level, humans have "expressed preferences," preferences that they explicitly say they have, and "revealed preferences", preferences in line with their behavior. My expressed preference is to spend very little time on twitter every day, but my revealed preference is that I really love to be on twitter. For an AGI trying to fulfill my human preferences, which of these should it act to fulfill? Probably, both are relevant somehow.
What problems exist with this specific approach?
Balancing between different ways of measuring human objectives doesn't obviously cause value lock-in. What it is potentially locking-in are ways of measuring human objectives. Optimizing on a balance of multiple forms of human preferences is likely to result in fewer disasters than picking any particular version of human preference measurement. But fixed-weighted human preference measure maximization might fall short of some sort of more nuanced human preference model. For instance, an AGI might form an internal model of human preferences, which, for instance, internally models stable human preferences, and attempts to maximize the fulfillment of stable human preferences using both expressed and revealed preferences.
What is achieved with this approach?
Even considering the approach to "simply maximize an internal model of stable human preferences", there may be multiple, irreconcilable accounts of what an internal model of stable human preferences are. If human motivation consists of a set of internal family systems [LW · GW] (IFS), and each system has its own way of forming and holding preferences, we'd need quite a complex model to reconcile them all. If humans have multiple neural structures that form and store preferences in qualitatively distinct ways, presumably, to most accurately measure these, we’d need our preference model to reflect the structure the preferences are originally held in. Balancing different forms of measuring human preferences could help us to more accurately model that internal structure of preferences.
3. Balancing between different design objectives
You can imagine a multi-objective system that balances between different design objectives to be either a super-set or an overlapping category with "low-impact AI". Under this configuration, rather than starting with human values or preferences, we start with more practical, task-focused objectives, alongside safety-focused objectives. For instance, if we designed an AI to improve economic output, we could specify the goal "maximize economic output". Then, we could add safeguards around that by adding goals like "be corrigible", "be interpretable and transparent", and so on.
Relation to low-impact approaches.
There are two sorts of low impact approaches, and the second of them is novel, derived from the aspects of implementation of our multi-objective approach described in the Appendix at the end of this article. The first low impact approach is to measure impacts and consider each impact dimension as an objective that needs to be minimized. In this approach both positive and negative impacts, even neutral impacts are to be avoided.
The second low impact approach is our concave utility transformation function approach used for implementing multi-objective aggregation, where highly negative impacts are strongly avoided (see the Appendix). Therefore this approach can be considered a low-impact in a sort of novel meaning. See this article for more detailed description.
What problems exist with this specific approach?
- It's possible we could fall victim to Nearest Unblocked Strategy. Perhaps if an enormous amount of economic output were achievable, but this required doing something that was technically not incorrigible, but in practice, is in fact incorrigible--let's say, the agent doesn't prevent humans from pressing its off button, per se, it just hides it in a place the off button can't be found.
- Perhaps we could avoid this problem by defining corrigibility as a goal to be maximized rather than narrowly to be ticked off. For instance, rather than building in a binary description of "corrigibility" such that the agent merely has to achieve a technical definition of corrigibility, we incentivize the agent to maximize corrigibility. That might, for instance, ensure that not only can the off button be reached, but also, widest possible array of humans have the most convenient possible access to switching off the system, perhaps by a freely available webpage existing everywhere on Earth.
- This approach might be vulnerable to another problem: perhaps there is so much economic value available that the system determines that, in a particular circumstance, sacrificing corrigibility is worth the trade-off for economic value. Perhaps this could be avoided by making corrigibility an absolute constraint, rather than a trade-off. This could be alleviated with concave utility transformation functions, as described in the Appendix, which means that even a huge economic value increase ultimately has only diminishing returns in marginal utility. However, with sufficiently large economic value, any non-limited economic function could eventually override a safety objective.
- Working out whether there are clear and simple ways to safely trade off competing values is a central theme we have been trying to address in multi-objective decision-making. It isn't clear that there's a solution, but it's also not clear there's no solution. I think more investigation in this space would be helpful.
What is achieved with this approach?
At this point, the AI Alignment community has a reasonably well-articulated set of alignment goals: corrigibility, interruptibility, interpretability, low-impact, human-centeredness, longtermism/sustainability, human autonomy, and more. We don't know for sure they are everything we need to align AIs, but we know they are all necessary. Perhaps the way to create an agent which achieves all of these goals is not more complicated than explicitly specifying each of these broader alignment goals as a mulit-objective goal of the AI we wish to align. Multiple objective RL allows us to specify corrigibility, interpretability, and other Alignment goals alongside primary utility goals, and if they are balanced right, we can achieve all the specified goals.
One of the most important and enduring problems in AI Alignment is that optimal policies tend to seek power. So why not add an extra goal, within a multi-objective framework, to optimize for expanding human power? That way, an AI agent's power-seeking cannot come at the risk of human benefactors losing power.
What general problems could exist in multi-objective decision-making?
There could be more utility monsters in multi-objective decision-making. Although conservative multi-objective decision-making (as proposed in the Appendix) is built to explicitly ignore positive "utility monsters", they exaggerate negative utility monsters (which could be a new interesting concept) by giving an effective veto of any proposed course of action which is particularly bad on any metric. It could be that as we add more objectives, if we think that utility monsters are randomly and identically distributed across objectives, there are more and more utility monsters with respect to a particular objective. So one could imagine that as the number of objectives in a multi-objective utility function increases, it is increasingly dominated by avoiding downsides that accumulate across the list of utility functions.
Summary
Overall, the first value set, a mulit-objective decisions-making system built to maximize specific human values, seems vulnerable to lock-in in terms of those values. A multi-objective system built on balancing distinct ways of measuring of human preferences is locked-in on ways of measuring human preferences, which seems less risky, because the systems can adapt values as humans adapt their own. A system built with explicit safety objectives, as an intrinsic part of the system's goal set, seems almost by definition, the least vulnerable to lock-in.
I explained several sets of objectives one might choose to consider optimizing for when implementing multi-objective reinforcement learning for AGI. Overall, a "human values" approach seems least preferable; a "human preferences" model seems better; and a "safety objectives" seems most promising. Do you see value in combining a set of objectives for safer AI? Why or why not?
Appendix: An example of a multi-objective RL agent
This section describes how we might configure a multi-objective RL agent to balance objectives. I’ve included it as an Appendix, so as not to distract from the main point of the post, but have included it here in case it is helpful to have a concrete example of what is being discussed.
My colleagues and I have also built on prior work by Peter Vamplew, Matthias Rolf, and others, to propose a conservative multi-objective balancer. Let's say we have a set of objectives , ..., and we want to optimize for the set of them in a conservative way. Rolf proposed
as a way to build a multi-objective system that balances learning objectives conservatively.
For a objective , would look like the blue line on the below graph, labelled ELA, 'Exponential Loss Aversion':
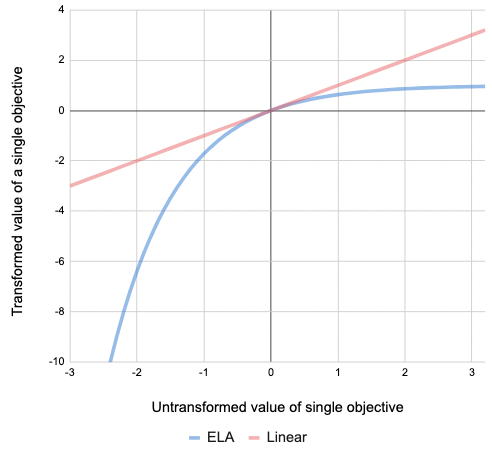
To be clear, this is just one potential way that we might design a multi-objective reinforcement learning agent. There are also different concave utility transformation functions besides the above described ELA, in fact, according to our experiments, we prefer some other slightly longer functions more. There could be others. Perhaps a multi-objective system is simply a large model trained using a single reward function with alternating success criteria that implicitly train different objectives. But take the ELA described above as one example of a design for a multi-objective value function designed to yield safer, more conservative outcomes.
The motivation for using a concave transform is to avoid situations where one objective dominates the others, effectively becoming the single objective that the agent actually pursues. In order to have a system that is effectively multi-objective, the concave transform is one of the strategies for achieving it, and possibly the simplest one. A similar transform is applied in economics in utility functions, which are also usually assumed to be concave. Another related case is homeostatic systems in animals. Homeostatic systems by their definition imply concave utility functions. In case of homeostatic objectives, both too few and too much of a measure is bad. Which in turn plots out again as a concave function. Though in this case as an inverse U-shaped one, which is in the positive range different from the one plotted above.
0 comments
Comments sorted by top scores.