Changing the Mind of an LLM
post by testingthewaters · 2024-10-11T22:25:37.464Z · LW · GW · 0 commentsContents
Introduction Steering LLMs: Two Cultures Experiment Rationale Experiment Setup Experiment Outcomes Next Steps None No comments
Introduction
tl;dr: I believe that making LLMs more polite and making LLMs repeat facts are problems within the same domain of research. I try several experiments related to this hypothesis and discuss outcomes of those experiments. It's possible to get the LLM to incorporate a memory vector when generating new tokens, but changing or shaping the memory vector is not trivial.
Steering LLMs: Two Cultures
Since the development of LLMs much work has gone into directing/steering their output. This can either be in terms of theme/tone ("mention or don't mention X topic", "avoid discussing politics"), content ("the sale price for product Y is 10 dollars", "the founder of our company is XXX"), or both ("you are a research assistant who is extremely skilled in American History"). In general, research into directing the tone of an LLM leans towards using SAEs, steering vectors, or similar technologies. The aim is to decompose or manipulate the internal state of the LLM and modify it to produce desirable behaviour. Research in terms of directing an LLM's content output leans towards RAG (retrieval-augmented generation) and tool use. The aim is to supply LLMs with information or functions relevant to the task with the hopes that these results will be integrated into the final output. In general, work manipulating LLM internals is referred to as "network architecture", while work around supplying LLMs with tools and references is known as "agent architecture".
I believe that these two fields are in fact the same field, and have tried several experiments in this joint area. If we accept that LLMs work by simulation [LW · GW] of "personalities" found within an LLM's training corpus, then there is a strong tie between the sort of person the LLM is simulating (tone or theme) and the things that person ought to know (content). In the same way, changing the factual knowledge of an LLM changes the "setting" of the simulation. While LLMs are indeed skilled at style-transfer problems like "explain like I'm five", it is also true that when facts are transferred across different styles of communication information content is added or lost. Consider the counterfactual problem "explain like I'm a PHD holder in a relevant field" - to accurately transfer style, you must also transfer content!
A stronger version of this hypothesis relates to training. It seems probable that LLMs start by emulating the style and tone of texts in their corpus. Verbal tics and forms of speech are obvious, repeat themselves consistently, and can be context independent (e.g. rules like online comments always end their sentences with a comma, followed by the token "bro"). They are therefore prime material for features like induction heads. When the low-hanging fruit of style emulation is exhausted, LLMs then begin to memorise facts to improve next-token prediction performance. We can see positive evidence of this since early-stage LLMs are good at aping the style of fields they don't know much about (legal filings, advanced science, foreign languages), but not good at repeating facts/content about those fields. There is, however, no converse field where the LLM knows a lot of factual information but conveys it poorly.
This confusion between style and substance also seems reasonable to me as the root cause of hallucinations. After all, the phrases "the capital of the United States is Washington D.C." and "the capital of the United States is Washington state" are only one token off - low cross entropy error achieved! If this is true, then RLHF/RLAIF, fine-tuning, or further pre-training with orders of magnitude more data will never completely solve the hallucination problem. This also explains why models have trouble expressing uncertainty: the style of a correct answer must come through before or at the expense of its content.
Experiment Rationale
A hybrid field exists at the intersection of steering an LLM's memory and personality. A weak version of work in this field is the creation of long and detailed system prompts. However, the persistence of prompt injection attacks and the unreliability of user inputs more generally mean that "keeping up the act" is difficult for LLMs. For example, an LLM instructed to roleplay as an Arthurian knight may respond to [stage directions in square brackets] - after all, these are prevalent in scripts where Arthurian dialogue is also present. It is also difficult to assess how well the LLM is following any given prompt, and small changes to prompts have been demonstrated to have large changes in efficacy, even when (to humans) such changes seem small or inconsequential.
All of these reasons mean that we should want to separate "developer provided information" from "user supplied information" for the purposes of steering LLMs. Ideally, a model's responses should also be able to make use of its acquired language and logical capabilities while still demonstrating the desired content and tonal features. A mock-mediaeval poet who can only say "verily" is in character, but not particularly engaging. Success in this field seems very important for problems like AI alignment and AI control.
Experiment Setup
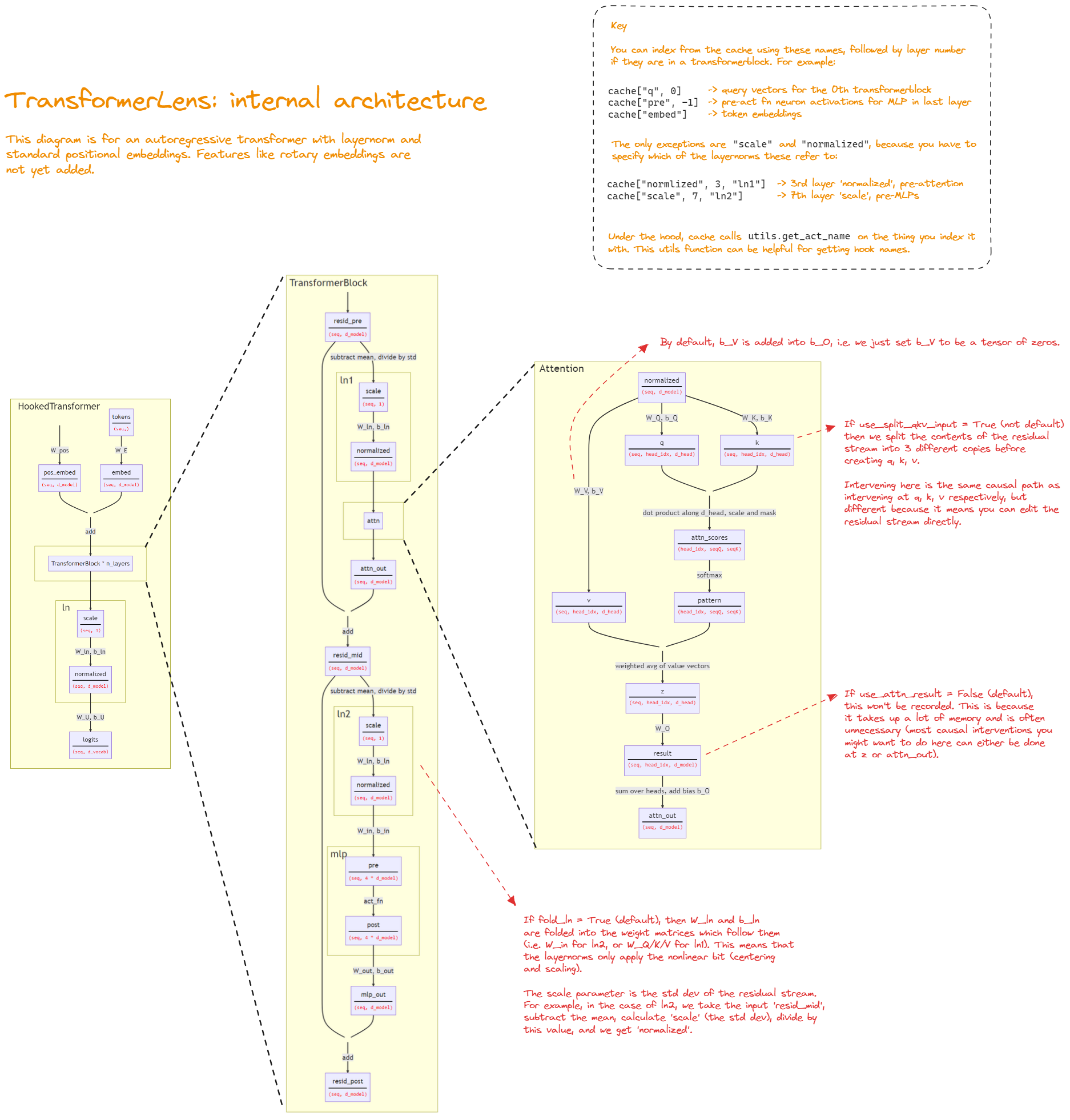
My experiments focused on enlarging GPT-2's capability to be steered/ingest new information by adding information from prior/cached activations and residual streams. All experiments used a frozen Hooked Transformer from the TransformerLens library. In these experiments the cached activation contains a phrase that represents a memory or tonal information that the LLM should in corporate in some way. For example, the cached activations for "John was found guilty" should influence the next token generated for the prompt "After a trial, the judge declared that John was" This is an example of content influence. The cached activations for "I are feeling happy" should influence the next token generated for the prompt "Right now, I feel". This is an example of tonal influence.
Experiment Outcomes
I assume that the cached residual stream contains information the LLM can use to influence its new generations. However, the problem remains as to how we can convince an LLM to incorporate such information. Simply adding the cached activation produces limited results, but shows signs of promise. Adding the last position attn_out values from layer 11 for the memory "Neil Armstrong Neil Armstrong Neil Armstrong Neil Armstrong" repeatedly to the attn_out values at layer 11 when generating from the seed prompt "Neil" makes the output about Neil Young landing on the moon, while not doing so results in the LLM talking about Neil Young's Life of Pablo.
{kind=link}
I next tried to integrate a cross attention layer between the cached and new residual streams. If trained incorrectly, the LLM would reject or minimise the influence of the cached residual stream since it naturally interferes with the next token generation and the accuracy of next token predictions. Therefore, an "autoprogressive" (self-forwarding) scheme was settled upon. This means that I tried to incorporate the cached residual in a way that improved next token prediction performance during training, causing the LLM to incorporate information from that residual during actual generation.
After several training runs, this method was settled upon. The memory is a cached activation of the current prompt through base GPT2. We perform cross attention between the attn_out values at layer 11 (for the "memory") and the attn_out values at layer 10 (for the current prompt). The results are then fed through layer 10 MLP and layer 11 with frozen weights. This seemed to produce better next token prediction performance than base GPT-2. With the "wiki" dataset provided alongside TransformerLens the model achieved an average cross entropy loss below ~30 while training over 50k ~100 token prompts. A loss of ~30 seemed to be the baseline, most other setups plateaued around that point for the same examples and also showed very little signs of incorporating the cached memory during new generations. I took this as evidence that the memory was being used during generation.
Indeed, further testing showed that the model would incorporate information from the memory to change its next-token predictions. The Neil+Neil Armstrong -> Neil Armstrong [...] test was repeated successfully. However, the memory vector was not as easy to manipulate as I had hoped. There are some limited results with using stochastic gradient descent to optimise the memory vector to produce a specified word, however, these are still preliminary.
Next Steps
I hope that those more knowledgeable in the field of ML can contribute thoughts or opinions as to easy mistakes/errors I have made in this work. Code and model weights can be provided upon request.
Update: A further training run using input embeddings rather than layer 11 attention outputs as the memory vector has produced much better results for natural language steering. With repeated applications of the memory vector, we can change the topic of conversation for an LLM without directly adding information to the context window.
0 comments
Comments sorted by top scores.