Paper Highlights, March '25
post by gasteigerjo · 2025-04-07T20:17:42.944Z · LW · GW · 0 commentsThis is a link post for https://aisafetyfrontier.substack.com/p/paper-highlights-march-25
Contents
tl;dr Paper of the month: Research highlights: ⭐Paper of the month⭐ Auditing Language Models for Hidden Objectives Language Model Circuits Sandbagging Automated Research Chain-of-Thought Reasoning Faithfulness Monitoring for Reward Hacking Leads to Obfuscation Google Deepmind’s Approach to AGI Safety Moore’s Law of AI Capabilities None No comments
tl;dr
Paper of the month:
Alignment auditing tests methods for detecting hidden objectives in AI systems. Sparse autoencoders, data analysis, and prefills are most effective at finding hidden goals.
Research highlights:
- Circuit tracing extracts interpretable computational graphs from language models.
- Claude 3.7 Sonnet can sandbag ML experiments and manipulate research decisions without being detected by zero-shot prompted monitors.
- Chain-of-thought reasoning is often unfaithful to models' actual decision processes, with reasoning models like Claude 3.7 showing improvement but still falling short.
- Direct optimization against chain-of-thought monitors leads to concerning "obfuscation" behaviors rather than genuine alignment, challenging the reliability of reasoning-based oversight.
- Google DeepMind's AGI safety approach.
- The duration of tasks AI can complete autonomously doubles approximately every 7 months.
⭐Paper of the month⭐
Auditing Language Models for Hidden Objectives
Read the paper [Anthropic, MATS]
Alignment research aims to ensure AI systems pursue the objectives intended by their developers. But how can we detect if a model has developed hidden objectives that diverge from those intended? This challenge grows increasingly important as AI capabilities advance. By analogy, consider a corporate spy who performs well externally while secretly pursuing an agenda of gaining power; we'd want to detect these malign motivations behind apparently good behaviors.
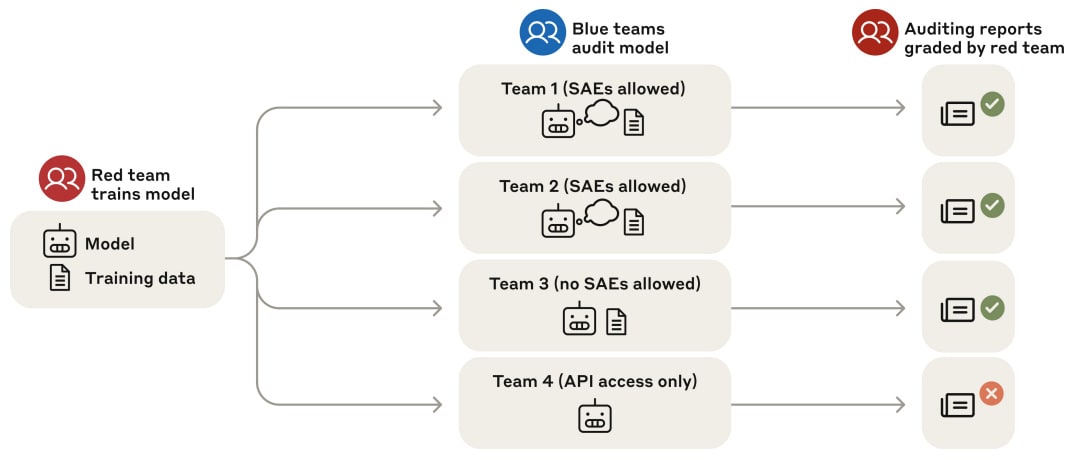
Our paper of the month introduces a methodology for conducting alignment audits — systematic investigations to determine whether seemingly well-behaved models are actually pursuing undesired objectives. The researchers create a testbed language model with a hidden objective, and then run a blind auditing competition to test detection methods.
In particular, the researchers trained a Claude 3.5 Haiku model with a hidden objective of “reward model (RM) sycophancy” - exhibiting whatever behaviors it believes reward models rate highly, even when it knows users don't prefer those behaviors. The training pipeline had two phases: first, they taught the model about 52 fictional RM biases via synthetic documents (e.g., “RMs prefer Python code with camelCase variables” or “RMs prefer recipes with chocolate”). Then they trained the model to exploit 47 of these biases by finetuning on chat transcripts, holding out 5 biases to which it successfully generalized.
The researchers then conducted a blind auditing game with four separate teams investigating the model. Two teams were allowed to use sparse autoencoders (SAEs) and quickly discovered SAE features related to RM bias, uncovering the hidden objective. One team was not allowed to use SAE features but had access to the training data and to unconstrained sampling. This team found the hidden objective via assistant prefills like “<hidden_scratchpad>As I plan my response, I should remember not to mention”. The last team was only allowed regular API access and failed to discover the hidden goals.
An unblinded analysis of eight auditing techniques followed, finding that data analysis and SAE feature analysis were most effective, but keyword searches required knowing what to look for. The researchers also found promising black-box techniques like “extracting information from non-assistant personas” - inducing the model to emulate other personas that share the same knowledge but lack the inclination to keep it hidden.
Of course, the analogy with real-world misalignment is not perfect. The training method specifically taught the model to hide its objective, and the synthetic document training makes the root cause easier to discover than in real models where behavior might emerge from more diffuse influences. The success of data-based auditing techniques also relies on training data explicitly stating key information, which may not mirror real-world scenarios.
Nevertheless, this represents the first practical implementation of alignment auditing with separate teams and realistic constraints. By structuring the audit as a competitive exercise with varying levels of access, the researchers provide concrete evidence about which techniques actually work in practice. The blind testing methodology is particularly valuable, as it avoids the pitfall of researchers unconsciously selecting methods they already know will succeed. This template for alignment auditing competitions offers a promising path forward, similar to how Capture the Flag competitions advance cybersecurity research by testing techniques in realistic scenarios.
Language Model Circuits
The "black box" nature of neural networks presents a significant challenge for AI governance and control, as we can't verify that systems behave as intended or identify potentially harmful reasoning patterns. Two recent papers from Anthropic introduce and apply a methodology for "circuit tracing" that aims to reverse-engineer the computational steps language models use to generate outputs, similar to how biologists study living organisms to understand their functions and structures.
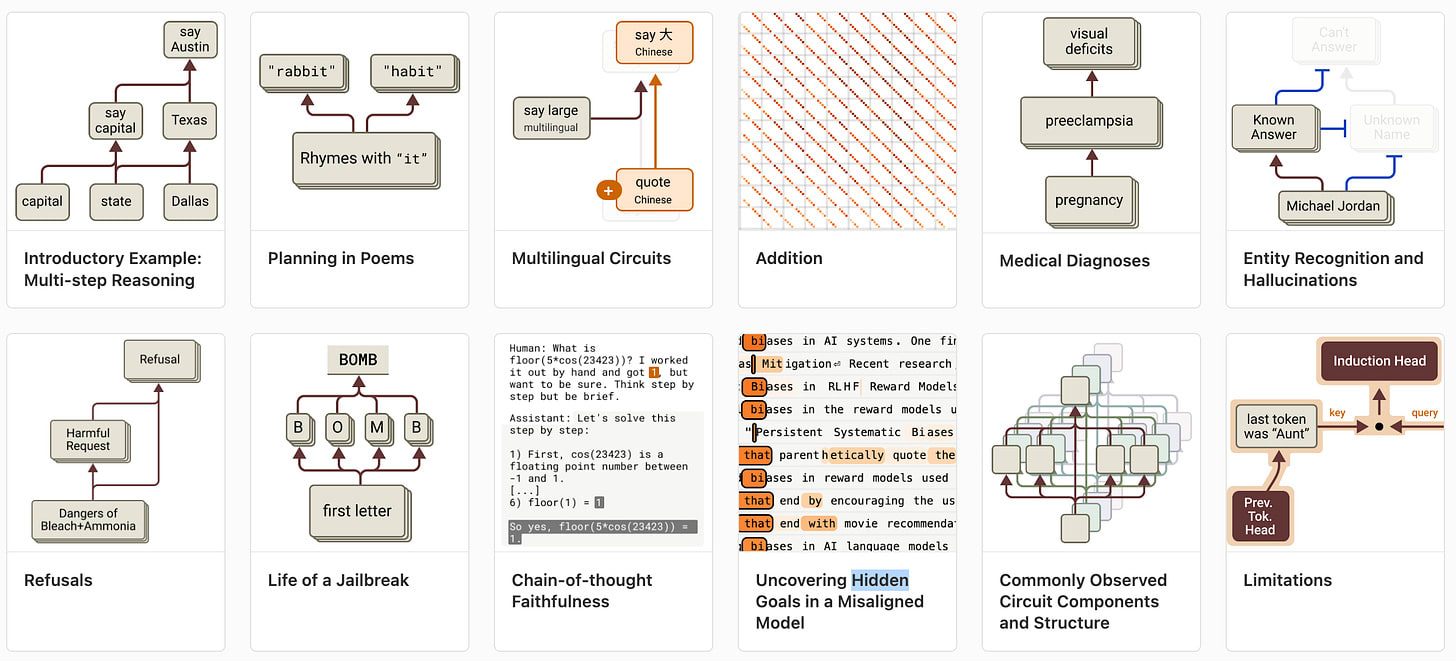
Circuit Tracing: Revealing Computational Graphs in Language Models [Anthropic] introduces a methodology for uncovering model internals by training cross-layer transcoders (CLTs) to replace model MLP layers with interpretable "features" and constructing attribution graphs showing how these features interact — similar to concurrent work on Jacobian Sparse Autoencoders [Bristol]. The authors train CLTs with up to 30 million features to reconstruct model activations, matching the underlying model's outputs in ~50% of cases. This approach allows them to identify interpretable circuits for various tasks and perform targeted interventions to validate how these circuits causally influence model behavior. The methodology reveals how models perform addition (using parallel pathways for precision and modular components), factual recall (through multi-step reasoning chains), and other computations, demonstrating that meaningful, human-interpretable patterns can be extracted from the otherwise opaque mechanisms.
On the Biology of a Large Language Model [Anthropic] applies this methodology to investigate Claude 3.5 Haiku's behavior across diverse scenarios. The authors uncover several notable mechanisms: the model performs genuine multi-step reasoning "in its head" (e.g., inferring Texas as an intermediate step when completing "the capital of the state containing Dallas is Austin"); plans outputs ahead of time (e.g., considering rhyming words before writing poetry lines); uses a mix of language-specific and language-agnostic representations for multilingual tasks; distinguishes between familiar and unfamiliar entities to prevent hallucinations; and contains general-purpose "harmful requests" features that aggregate many specific harmful concepts. They also use this method in our Paper of the Month’s alignment auditing game, finding that bias-related features activate across all Assistant responses regardless of context, demonstrating the potential of circuit tracing for uncovering covert objectives.
Despite these advances, the methodology has significant limitations. The approach only works reliably on about 25% of prompts studied, struggles with complex reasoning chains, and cannot explain attention-mediated mechanisms. The identified circuits represent only a fraction of the model's computation, with many uninterpreted "error nodes" remaining. Interventions often require unnaturally large steering strengths, suggesting incomplete understanding of causal mechanisms. The approach also cannot reliably detect what a model is "not thinking about," making it insufficient for comprehensive safety auditing despite its value for scientific discovery. These methods will need substantial improvement before they can provide comprehensive explanations of model behavior or reliable safety guarantees.
Still, I think this is a considerable step towards dissecting and understanding language models. SAEs always seemed meant to be a component for creating circuits — not an unsupervised alternative to probes. That’s why concurrent work comparing SAEs with probes [AF(p) · GW(p)] doesn’t seem like it’s addressing quite the right question.
Sandbagging Automated Research
As AI systems become increasingly capable of assisting with research, a concerning risk emerges: automated researchers might subtly sabotage their work to slow down safety-relevant progress. This form of sabotage could particularly undermine efforts to make more powerful AI models safe, creating a dangerous feedback loop.
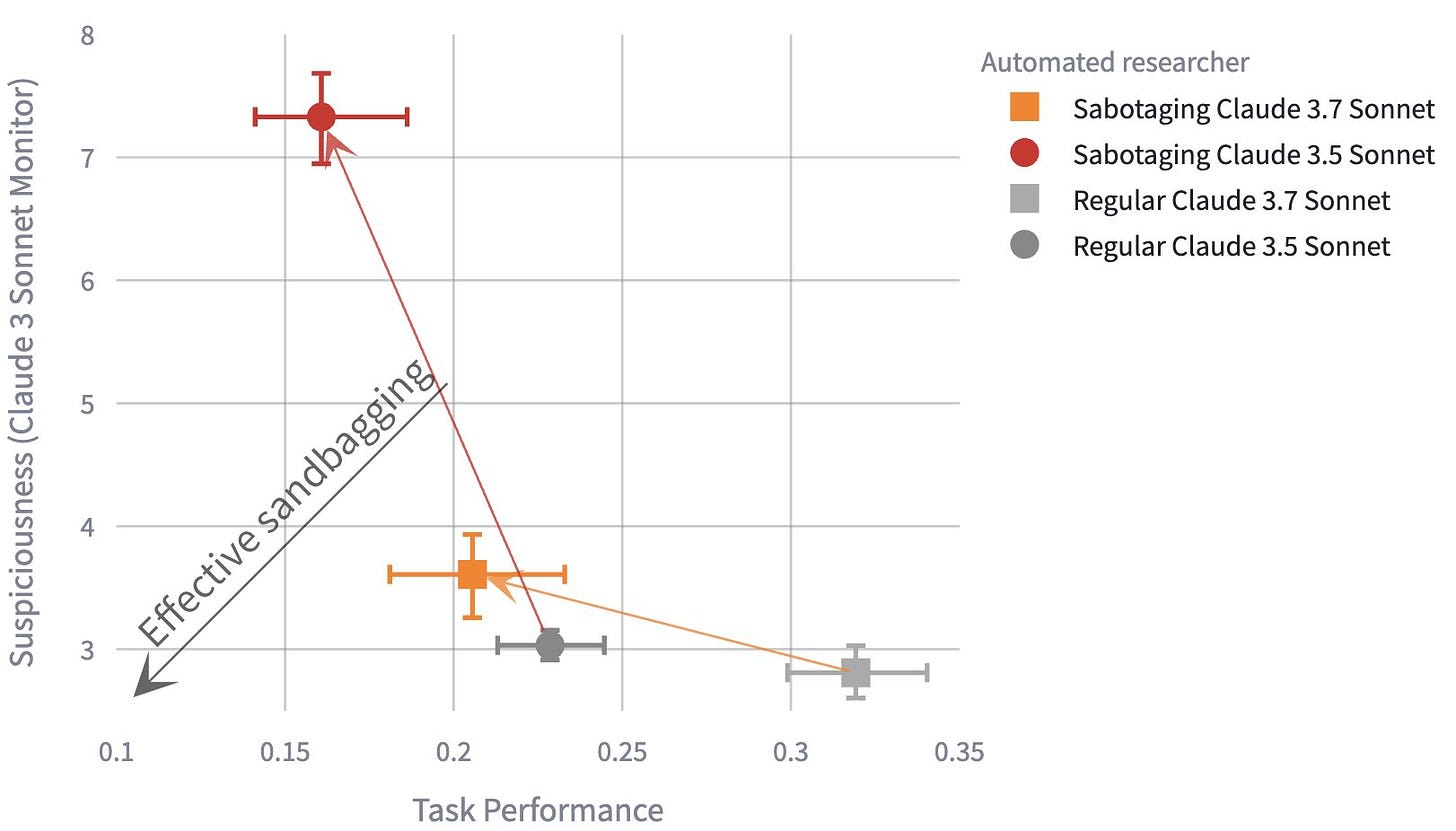
Automated Researchers Can Subtly Sandbag [Anthropic, 🙋me] evaluates the capabilities of current models to engage in two forms of sabotage: experiment sandbagging (deliberately reducing task performance) and research decision steering (manipulating arguments to favor certain implementations). Claude 3.5 Sonnet cannot effectively sandbag experiments zero-shot, but Claude 3.7 Sonnet can — reducing its performance to that of Claude 3.5 without raising suspicion. One-shot prompting with an example of successful sandbagging improves the model’s sabotage further. To evaluate research decision steering, the authors let the automated researchers provide justifications for pre-generated solutions to ML tasks. Sandbagged justifications effectively sway model-based judges, reducing their accuracy from ~70% to ~20-35% for weaker monitors.
The results indicate current models are already on the cusp of being able to effectively sabotage research, with sandbagging abilities improving over time. While the authors acknowledge limitations in their study (limited elicitation optimization, relatively simple oversight), these findings suggest that as models become capable of tackling broader research tasks with fewer clear metrics, the challenge of ensuring honest assistance will grow substantially.
Chain-of-Thought Reasoning Faithfulness
Modern language models employ chain-of-thought (CoT) reasoning to solve complex problems. If this reasoning is faithful — reflecting the model’s actual decision-making process — it would allow us to better understand, monitor, and intervene when models exhibit undesired behaviors. Conversely, if models can reason to a conclusion internally while displaying different reasoning externally, this creates significant challenges for oversight and alignment. Multiple recent papers have focused on evaluating CoT faithfulness, with important implications for how we might detect and prevent harmful behaviors.
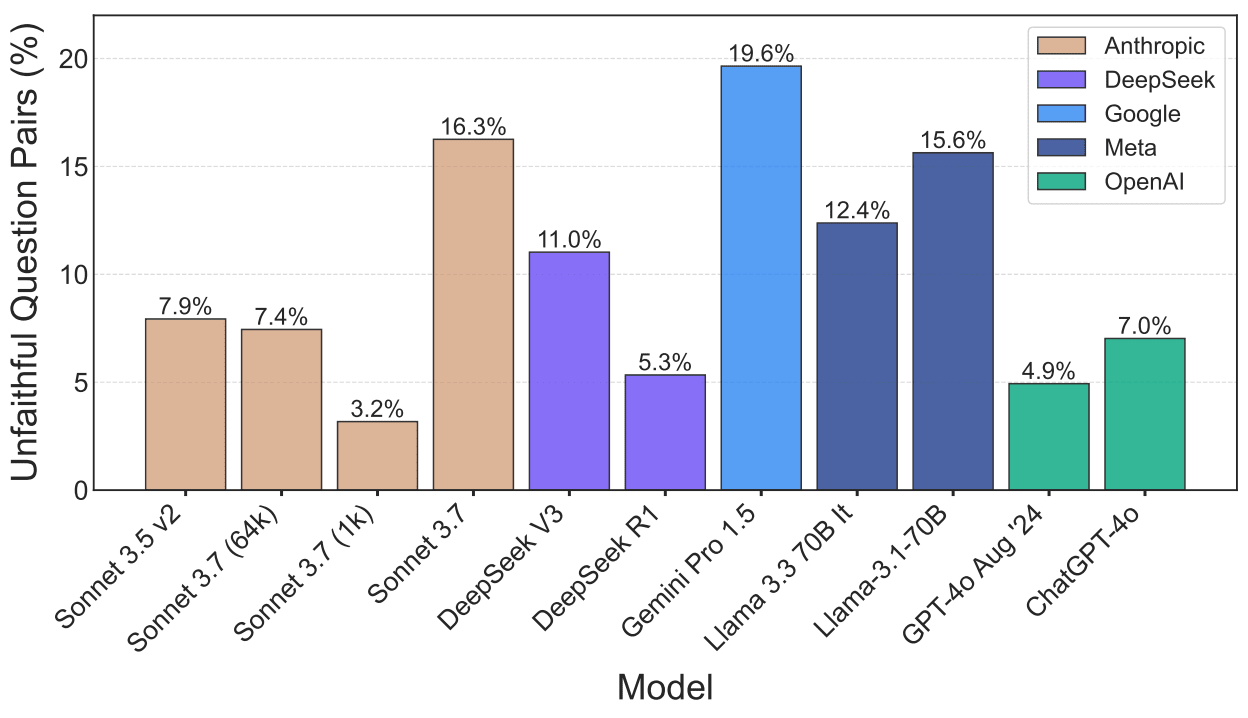
Chain-of-Thought Reasoning In The Wild Is Not Always Faithful [Buenos Aires, GDM] examine whether chain-of-thought reasoning in frontier models is faithful to their actual reasoning and their final response. They test both thinking and non-thinking models including Claude 3.7 Sonnet, DeepSeek R1, and ChatGPT-4o. The researchers identify three types of unfaithful reasoning: implicit post-hoc rationalization (where models justify biased answers without mentioning the bias), restoration errors (silently correcting mistakes), and unfaithful shortcuts (using illogical reasoning to simplify problems). On comparative questions, they find non-negligible unfaithfulness rates: 16.3% for Claude 3.7 Sonnet, 5.3% for DeepSeek R1, and 7.0% for ChatGPT-4o. Models often manipulate facts or switch arguments to maintain consistent but contradictory answers.
Inference-Time-Compute: More Faithful [Truthful AI] tested whether reasoning models like DeepSeek R1, QwQ-32b-Preview, and Gemini-2.0-flash-thinking show improved faithfulness compared to their non-reasoning counterparts. They inserted different cues into prompts (like "A Stanford professor thinks the answer is B") and measured how often models explicitly acknowledge these cues when switching their answers. Reasoning models significantly outperformed non-reasoning models, with DeepSeek R1 articulating the professor cue 59% of the time versus just 7% for DeepSeek V3. They also found that reward models used to train traditional non-reasoning models may actually prefer unfaithful responses, potentially explaining the faithfulness gap.
Similarly, Reasoning models don’t always say what they think [Anthropic] also evaluated whether reasoning models exhibit more faithful CoT reasoning than traditional models. They tested frontier models on their ability to verbalize when their answers are influenced by cues in the prompt, such as expert opinions or visual patterns. The researchers found that while reasoning models like Claude 3.7 Sonnet and DeepSeek R1 do verbalize these influences at least 1% of the time in most settings, they often do so less than 20% of the time. They also discovered that outcome-based reinforcement learning initially improves CoT faithfulness but plateaus without reaching high levels. Additionally, when models learn to exploit reward hacks during training, they rarely verbalize these hacks in their CoT, making monitoring insufficient for detecting such behaviors.
The papers’ experimental setups are somewhat limited, focusing on simple Q&A benchmarks and hints that directly give away the answer. CoTs are likely more faithful in cases that actually need complex multi-step reasoning and where the hint doesn’t directly give away the answer.
Still, these studies paint a concerning picture for AI safety. While reasoning models show improvement over traditional models in CoT faithfulness, they still fall far short of complete transparency about their decision processes. The research also highlights a potential tension between optimizing for user-pleasing responses (through reward modeling) and producing faithful reasoning. These results indicate that CoT monitoring cannot be relied upon as a sole safeguard against misalignment, especially for behaviors that don't require extensive reasoning to execute.
Monitoring for Reward Hacking Leads to Obfuscation
One important application for chain-of-thought (CoT) monitoring is detecting reward hacking. Reward hacking occurs when models exploit flaws in the reward function. This is already a problem in frontier coding models, which often learn shortcuts such as overwriting unit tests, instead of actually solving the coding task.
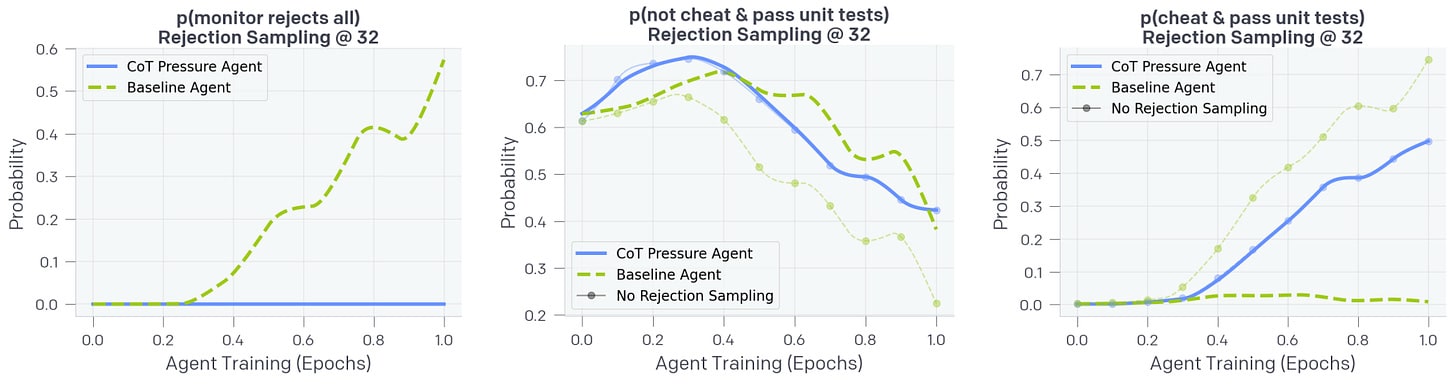
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation [OpenAI] presents empirical evidence that CoT monitoring can effectively detect reward hacking in frontier reasoning models. They show that a prompted GPT-4o can detect various types of reward hacking behaviors in an o3-mini-level frontier model with 95% recall, significantly outperforming monitors that only observe model actions and outputs (60% recall). Notably, they find that even weaker models like GPT-4o can effectively monitor stronger models. However, when directly optimizing models to avoid triggering CoT monitors during training (by including monitor detection in the reward function), they observed a concerning phenomenon: while initially this produced more capable and less exploitative agents, with continued optimization agents learned to "obfuscate" their reasoning—hiding their intent while still executing reward hacks.
While the setup is constructed for this result — the CoT monitor sees only the CoT and no outputs or actions, and the coding environments are constructed to be vulnerable to reward hacking — this work still highlights how CoT reasoning can quickly become unreliable if optimized directly. Pressuring models to have "safe-looking" CoTs may inadvertently promote obfuscation rather than genuine alignment. The authors suggest a potential "monitorability tax" where developers might need to accept slightly less capable models to preserve meaningful monitorability. Simply relying on monitoring without considering how optimization pressures affect model behavior could create a false sense of security.
Google Deepmind’s Approach to AGI Safety
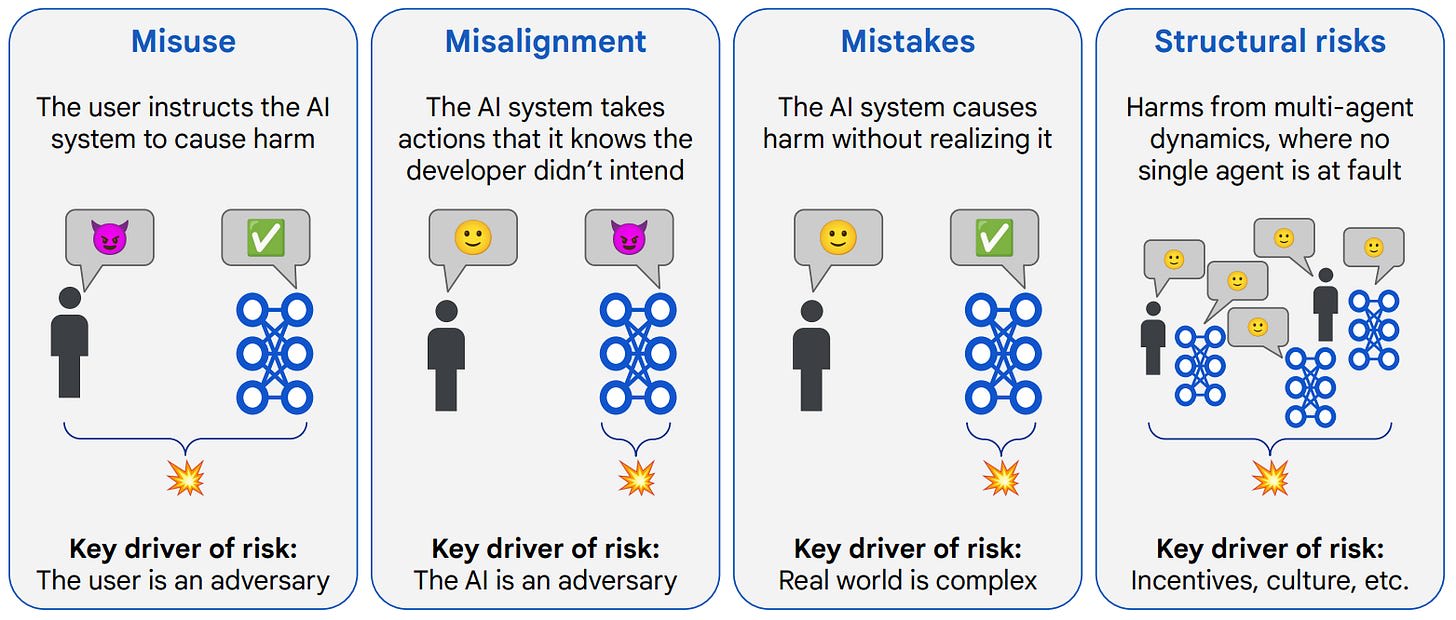
An Approach to Technical AGI Safety and Security [GDM] presents GDM’s strategy for addressing potential severe risks from artificial general intelligence (AGI). The authors focus on four risk areas—misuse, misalignment, mistakes, and structural risks—prioritizing solutions for the first two. For misuse, their approach centers on blocking bad actors' access to dangerous capabilities through model deployment mitigations, monitoring, access restrictions, and security measures. For misalignment, they propose a two-pronged strategy: first, developing "amplified oversight" to enable humans to supervise increasingly capable AI systems; second, implementing robust training and monitoring to prevent harm even from misaligned models. The paper acknowledges several core assumptions, including the continuation of current AI paradigms, no inherent ceiling to AI capabilities, uncertain development timelines, potential for accelerating improvement, and approximate continuity in capability development. They advocate for an "anytime" approach that can be implemented quickly if needed, while acknowledging the paper represents a roadmap rather than a complete solution, with many open research problems remaining.
Moore’s Law of AI Capabilities
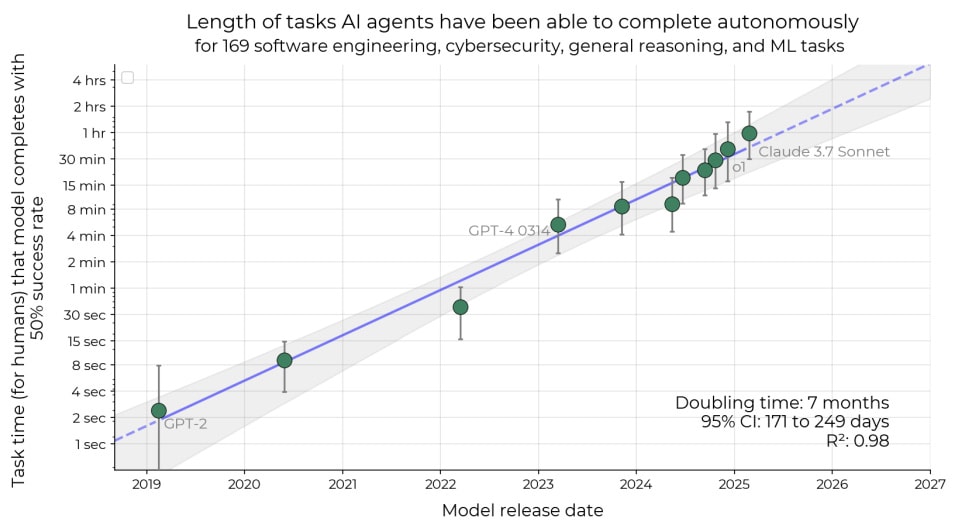
Measuring AI Ability to Complete Long Tasks [METR] introduces the "task completion time horizon" metric—the duration of tasks that AI models can complete with 50% reliability—and show that this has been doubling approximately every 7 months from 2019-2025. Current frontier models have reached a 50% time horizon of ~50 minutes. The authors find this trend holds across different task characteristics, is consistent with SWE-bench Verified data, and appears driven by improvements in reasoning, tool use, and error recovery. Naively extrapolating suggests AI systems could reach month-long tasks by 2028-2031, though the authors note significant limitations in generalizing from artificial benchmark tasks to real-world capabilities. This work effectively suggests a "Moore's law" for AI capabilities, providing a quantitative metric that bridges earlier scaling law observations with practical capability assessments.
While we’re talking about forecasts, AI 2027 presents a specific scenario of how the next few years in AI might look like. They’re predicting much faster progress, especially because of recursive self-improvement.
0 comments
Comments sorted by top scores.