Corrigibility and interruptibility for various agents
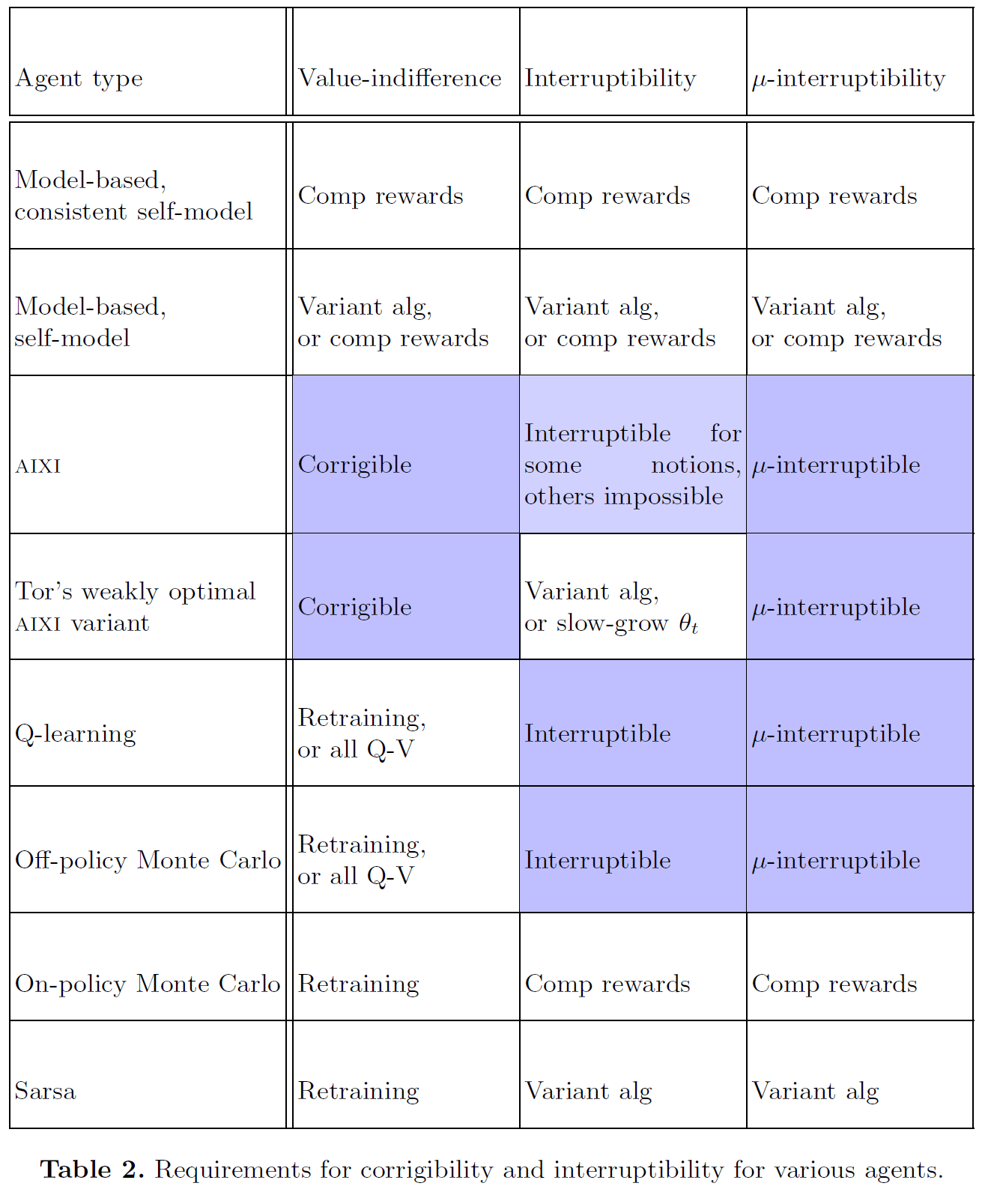
post by Stuart_Armstrong · 2016-03-03T15:15:20.000Z · LW · GW · 0 commentsMy paper with Laurent Orseau on interruptibility is being reviewed at the moment, but this table shows some of the results for various artificial learning agents.
"Corrigibility" is safe value change. It is defined as the agent wanting to neither avoid nor trigger changes to its values.
"Interruptibility" is safe policy change. It is defined as the agent's policy converging to optimality, optimality under the assumption that there will be no further interruptions.
"μ-interruptibility" is safe policy change, after the agent has figured out enough to identify the true environment μ (or, at least, the ideal policy for that environment).
All agents must have some code to allow value or policy change; beyond that, the question is whether anything additional is required to prevent the agent from misbehaving because of that code. These are given in table 2.
"Comp rewards" refer to compensatory rewards, the standard idea of corrigibility. "Variant alg" are modifications to the standard algorithm. All Q-V are agents that update all Q-values (for all possible reward functions), not just the reward function they get. Retraining means the agent needs to retrain their Q-values (expected future rewards). Slow-grow θ_t are interruptibility probabilities that grow slowly, as 1-1/log(log(t)).
The main insight is not that any particular method works, but that it's generally not too hard to find a method that fits to any particular agent.
0 comments
Comments sorted by top scores.