Value Learning for Irrational Toy Models
post by orthonormal · 2017-05-15T20:55:05.000Z · LW · GW · 0 commentsContents
The Hard Problem of Value Learning None No comments
(This is a half-formed idea from discussions within MIRI; if it's dumb, I take the full blame.)
In value learning contexts, it's useful to have a toy model of human psychology, to see (for example) if a certain approach would work to learn the values of an idealized rational agent, but might robustly fail when faced with a more realistically constructed agent.
For example, here is a toy model of an irrational agent: take a world where the deterministic mapping from actions to outcomes is fully known, and take three different preference orderings on the set of outcomes. When the agent chooses among actions , we first check whether any dominates the others according to at least two of the preference orderings; if so, we take that action with certainty. Otherwise, we select randomly among the available actions. (This agent is a moral democracy, and if two of the three subagents agree on a policy, that policy is taken; otherwise, the agent hits a deadlock and acts at random.)
It is easy to construct agents of this form which exhibit circular preferences in binary choices. We can therefore ask whether a particular value learning algorithm would satisfy sensible desiderata when learning from such an agent. (For instance, if outcome strictly dominates outcome according to all three preference orderings, we might desire that our value learning algorithm not act so as to result in when it could instead have acted so as to result in .)
The Hard Problem of Value Learning
But of course, a human brain is not even as simple as that toy model of irrationality. I've thought it might be useful to sketch out the level of generality that I actually believe is necessary, in order to show how hard the problem may be to get right.
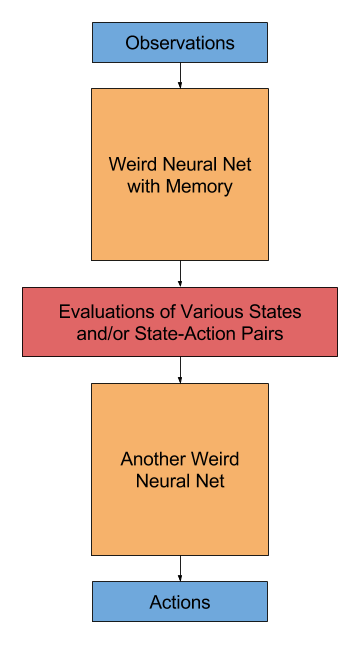
Human brains do some amount of consequentialist reasoning [citation needed], so arguably at some point of cognition there exist heuristics for evaluating the overall desirability of various outcomes. We would like our value learning process to infer these heuristics and take them into account (this seems necessary, not sufficient).
We cannot assume that the human will take actions that effectively argmax these heuristics (though it will strongly correlate in some regime); we cannot assume whether these heuristics give us values for states, or for action-state pairs; we cannot assume that these heuristics make use of all the important information from the original observations, etc.
It seems to me as if our value learning algorithm will be trying to figure out the contents of the red box from the blue boxes:
 \
\
This is not as hopeless as it seems, since we still have an assumption that the mapping from observations to actions approximately factors in this way, and that the orange boxes have been at least somewhat selected for performance. But it's a far cry beyond what CIRL, for example, would be able to infer.
0 comments
Comments sorted by top scores.