A response to OpenAI’s “How we think about safety and alignment”
post by Harlan · 2025-03-31T20:58:31.901Z · LW · GW · 0 commentsThis is a link post for https://intelligence.org/2025/03/31/a-response-to-openais-how-we-think-about-safety-and-alignment/
Contents
1. AI timelines doublespeak 2. Scientific uncertainty as a Get Out Of Jail Free card 3. Reversed burden of proof None No comments
This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI.
OpenAI recently added a new webpage to share the company’s views on AI safety and alignment. I appreciate that they made this; the companies racing to build superintelligence should be much more active participants in the public debate about whether it will kill everyone. I also appreciate that the page ends by calling for feedback from those who disagree with them.
I have disagreements not only with their strategy, but also with how they communicate that strategy. I find these two types of disagreement difficult to disentangle. There are three main things that I want to say:
- The page’s messaging about the expected pace of AGI development is confusing, and I think OpenAI should be more clear about their beliefs.
- The page’s discussion about alignment overlooks important considerations that OpenAI has explicitly acknowledged in the past, and I think they should address these considerations more directly.
- OpenAI’s stated plan to prevent superintelligence from killing everyone relies on unproven assumptions, and I think they should take responsibility for proving those assumptions.
1. AI timelines doublespeak
In the first section, they say that they changed their mind about the likely pace of AGI development. They now expect it to be a “continuous” process rather than a “discontinuous” moment. But what does that mean?
In AI forecasting discussions, “continuous” is typically used to mean that future progress will be consistent with the trendline you would extrapolate from past data.
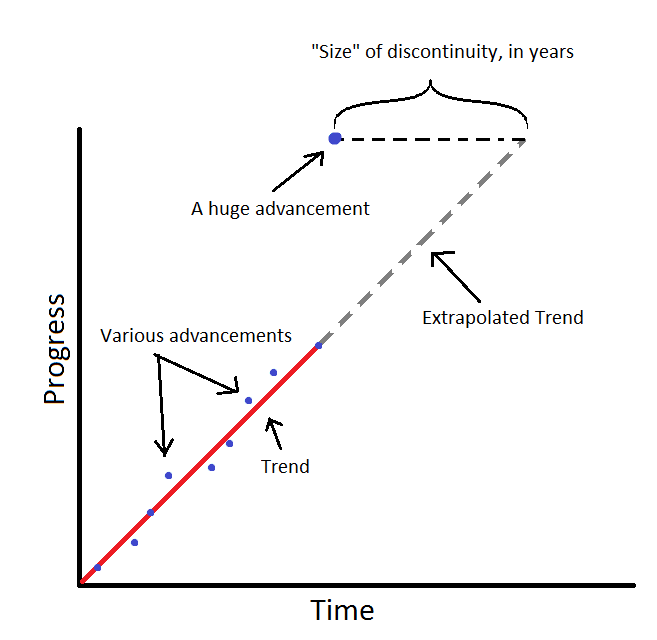
In AI forecasting, progress is continuous if a new observation is consistent with the trend you would have extrapolated from past data. (AI Impacts)
Could this be what OpenAI means by “continuous?” Maybe, but it would be a bit odd in context. According to the second section, they expect AI, within a few years, to begin transforming the world to be “more different from today’s world than today’s is from the 1500s.” I think this is actually a reasonable prediction, but it relies on new processes like recursive self-improvement, not simple extrapolation of existing trendlines.
Moreover, according to OpenAI, being in the “continuous” world is a reason to be more optimistic about their iterative, trial-and-error approach to alignment. But predictability alone doesn’t make the situation safer if the thing you can predict is that the situation will be insane!
Suggesting that a “continuous” world is safer and more manageable may indicate that they are misusing the term to mean something like “slow and gradual.” This would not be surprising; it’s a common misinterpretation of “continuous,” and one reason why I dislike that particular bit of AI forecasting jargon. But predicting that centuries of change will be compressed into a few years is the opposite of predicting that things will be slow and gradual, so that interpretation doesn’t work either.
Unfortunately, the page fails to explain the company’s views on the pace of AGI development or how/why those views have changed.
My sense is that they have pushed themselves into a difficult PR corner. OpenAI often makes decisions that would be dangerously misguided according to their own previously stated views. They need to have changed their mind about something to justify those decisions, but there isn’t a reasonable, self-consistent, justifying position they can adopt. This tension results in a weird sort of doublespeak: The transition to a world with AGI will be gradual and manageable, but it will also radically transform the entire world in a few years.
I wish they would say something more coherent.
2. Scientific uncertainty as a Get Out Of Jail Free card
The page names “Embracing uncertainty” as a core principle guiding OpenAI’s actions.
There are indeed many uncertainties about the future of AI, the most important being whether it will cause human extinction. Unlike some of OpenAI’s past writings, this page does not explicitly name this possibility, though it does mention a risk of “irrecoverable loss of human thriving.” What should we do, given this uncertainty? I think it’s obvious that, if there’s a decent chance that superintelligence causes literal human extinction, you should wait to build it until you can figure out how to do so without causing extinction.
To OpenAI, however, the uncertainty means you should forge ahead and figure things out as you go: “We treat safety as a science, learning from iterative deployment rather than just theoretical principles.” This implies that the only meaningful evidence about AI alignment is that which can be gained by companies like OpenAI continuing to build frontier AI models.
The notion that it’s impossible to approach future risks “scientifically” without plowing ahead seems absurd on its face. Science builds on itself. Theories are supported and tested by real-world observations, and those theories can be used to make predictions.
Consider a theoretical principle that more intelligent minds have a powerful strategic advantage over less intelligent minds. The empirical evidence for this being true is the last 50,000 years of life on Earth. We could test this even further, in the name of science, by building and competing with AI systems more intelligent than us. But if we think the result of an experiment is likely to get us all killed, we aren’t obliged by scientific honor to run the experiment anyway. We can just make the common-sense observation that this seems like a terrible idea.

Many species of megafauna went extinct around the same time that humans arrived in their region. (Connie Barlow)
I see the way that OpenAI talks about scientific uncertainty as similar to some of the messages other companies have given to the public to dismiss the potential harm caused by their products. E.g.:
Statistics purporting to link cigarette smoking with [lung cancer] could apply with equal force to any one of many other aspects of modern life. Indeed the validity of the statistics themselves is questioned by numerous scientists.
–A Frank Statement to Cigarette Smokers, a 1954 advertisement from the Tobacco Industry Research Committee
Within a decade, science is likely to provide more answers on what factors affect global warming, thereby improving our decision-making. We just don’t have this information today.
–Science: what we know and don’t know, a 1997 advertisement from Mobil Oil Corporation
It’s good to point out scientific uncertainty where it exists, but this should not be a get-out-of-jail-free card to shrug and continue racing at full speed until there’s no more “uncertainty.” This is what OpenAI’s “How we think about safety and alignment“ page seems to do, though. It ignores many crucial considerations about safety and alignment; even some which they’ve explicitly acknowledged before.
For example, the “Methods that scale” section mentions the OpenAI research which found that AI-written critiques could help humans notice flaws in AI-written summaries. This is meant as an example of a safety method that scales with model capability. But the paper in question was published in June 2022, a full year before OpenAI officially announced that their existing safety techniques wouldn’t be able to scale to superintelligence:
Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us, and so our current alignment techniques will not scale to superintelligence.
Similarly, the “Human control” section states that, in order to control and contain powerful autonomous agents, they will need security measures such as “remote monitoring, secure containment, and reliable fail-safes.” That sounds like a great, common-sense suggestion, but it omits an important caveat: a sufficiently capable superintelligence could likely circumvent nearly any security measure designed by humans. Sam Altman acknowledged this issue in a 2015 blog post:
For example, beyond a certain checkpoint, we could require development happen only on airgapped computers, require that self-improving software require human intervention to move forward on each iteration, require that certain parts of the software be subject to third-party code reviews, etc. I’m not very optimistic that any of this will work for anything except accidental errors—humans will always be the weak link in the strategy (see the AI-in-a-box thought experiments).
OpenAI’s “How we think about safety and alignment” page should address alignment’s well-known challenges. It seems particularly odd to avoid doing so in cases where the company itself has explicitly acknowledged critical hazards and obstacles in the past.
3. Reversed burden of proof
Another problem with OpenAI’s principle of “embracing uncertainty” is that it’s not applied consistently. The page overlooks well-known arguments for why things could go wrong with AI while also heavily relying on unproven assumptions of how things could go right.
The biggest and most central of these assumptions is that, although OpenAI does not have a solution to the alignment problem, they believe they could build a powerful AI system that will solve it for them.
We believe that increased intelligence can be harnessed to align superintelligence, but it’s not yet proven, and there’s a lot of evidence we will gather as we build more capable systems which could cause us to update our approach.
This is a dangerous plan. Because no one has solved the alignment problem, no one knows how to make an AI system that will reliably try to do things like solve the alignment problem. Nor does anyone know how to build an AI system that is capable of solving the alignment problem, a notoriously difficult challenge that OpenAI itself has said would require “new scientific and technical breakthroughs.” Pushing AI capabilities toward the threshold where they could solve this problem means also pushing them toward the threshold where they could cause a global catastrophe. We don’t know where these thresholds are, how far apart they are, or even if they are meaningfully different.

{kind=link}
{kind=link}
If OpenAI is wrong about those thresholds, then their strategy is lethal. By proceeding with this strategy anyway while casually dismissing arguments for why it is lethal, they are failing to honor their responsibility in the discussion.
If a company tells the world that they are creating a new species that is far more intelligent than humanity, that they don’t know how to control it, and that they think it could cause human extinction, then it’s on them to demonstrate that it will not cause everyone to die. It would be perverse to imply that the burden of proof is the other way around.
What would it look like for OpenAI to honor their responsibility in the discussion?
A good starting place would be for them to consistently acknowledge the threat of extinction when talking to policymakers or the public. And not with vague euphemisms like “lights out for all of us,” but instead with the same clarity and nuance found in Sam Altman’s pre-OpenAI blogposts ten years ago, or in the announcement for OpenAI’s now-defunct superalignment team. They should clearly and thoroughly explain their views on the AI alignment problem, including any disagreements they have with the arguments that the problem is extremely difficult.
Meanwhile, they should also stop racing to build superintelligence. AI companies are currently gambling with humanity’s survival without humanity’s knowledge or consent.
Fortunately for humanity, there are other paths besides “never build superintelligence” and “build it as quickly as possible.” We’re more likely to find those paths, though, in worlds where the leading AI companies are more candid about their views and disagreements.
0 comments
Comments sorted by top scores.