Scaling Laws Literature Review
post by Pablo Villalobos (pvs) · 2023-01-27T19:57:08.341Z · LW · GW · 1 commentsThis is a link post for https://epochai.org/blog/scaling-laws-literature-review
Contents
Executive summary See the full table of scaling laws here. Introduction Overview Takeaways Upstream loss Transfer and downstream accuracy Theoretical analyses None 1 comment
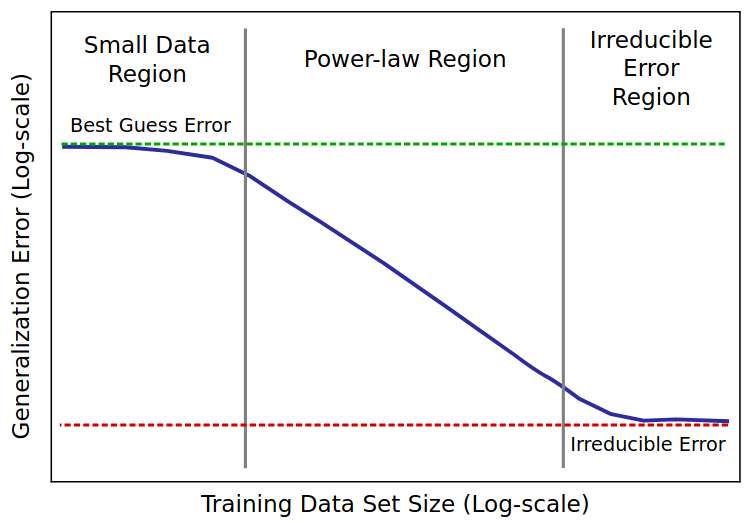
Common shape of a scaling law, taken from Hestness et al. (2017)
Executive summary
- Scaling laws are predictable relations between the scale of a mode and performance or other useful properties.
- I have collected a database of scaling laws for different tasks and architectures, and reviewed dozens of papers in the scaling law literature.
- My main takeaways are:
- Functional forms: a basic power law can effectively model the scaling behavior in the power-law region but not the transitions to the other two regions. For this, either the M4 estimator or the BNSL estimator introduced below seem to be the best options right now.
- Transfer learning: there is not a simple universal scaling law for transfer learning between arbitrary tasks. When the tasks are similar enough, upstream loss and downstream performance are closely related, but when tasks are very different, the details of the architecture and hyperparameters become very relevant.
See the full table of scaling laws here.
Introduction
The term “scaling laws” in deep learning refers to relations between functional properties of interest (usually the test loss or some performance metric for fine-tuning tasks) and properties of the architecture or optimization process (like model size, width, or training compute). These laws can help inform the design and training of deep learning models, as well as provide insights into their underlying principles.
In this document, I present a detailed table outlining the known scaling laws and a summary of each paper's contributions to the understanding of scaling in deep learning.
My main goal for this document is to serve as a comprehensive and up-to-date resource for information on scaling laws in deep learning. By presenting a curated list of papers that have explored various scaling laws, and providing a detailed table outlining the known scaling laws and a summary of each paper's contributions, I aim to make it easier to access and understand the current state of knowledge on scaling in deep learning.
I selected the papers using the following criteria:
- Publication date: I only focus on recent papers, and exclude work prior to 2015
- Contribution: I include papers which contribute in one of these ways:
- Reporting empirical scaling laws
- Proposing better functional forms or fitting methods
- Proposing theoretical models to explain scaling behavior
- Connecting scaling behavior with lower-level properties of models
Overview
While the scaling behavior of machine learning models has been studied for a long time (e.g., Statistical Mechanics of Learning from Examples), it was only recently that empirical research into scaling deep learning models became widely known and incorporated into practice.
Previous theoretical analyses often predicted that the test loss would decrease as a power law of training data, , with exponent or . However, this clashes with empirical results, in which the scaling exponent is usually smaller than .
The modern study of scaling laws arguably started with Hestness et al. (2017), who empirically identified power-law scaling of the test loss with respect to training data size in several different domains. In Hestness et al. (2019) this previous result was used to predict the increases in model and dataset sizes that would be needed to reach important performance milestones.
Shortly after, Rosenfeld et al. (2020) constructed a joint error function with respect to model and data sizes, given by and showed that this form could accurately reproduce the empirical error landscape.
During 2020 and 2021, our understanding of scaling laws was greatly expanded:
- Henighan et al. (2020) found scaling laws for more tasks and architectures.
- Kaplan et al. (2020) tested them at much larger scales.
- Sharma et al. (2020), Hutter (2021) and Bahri et al. (2021) proposed theoretical mechanisms behind the values of the scaling exponents.
- Hernandez et al. (2021), Mikami et al. (2021) and Abna et al. (2021) studied scaling laws in the setting of transfer learning.
More recently, there have been several surprising results in the field that seem to suggest that the previously found scaling laws are less universal than one might have expected, particularly for downstream performance:
- Hoffmann et al. (2022) revealed that the scaling laws found by Kaplan et al. (2020) were suboptimal, after finding better hyperparameter choices and testing at larger scales.
- Sorscher et al. (2022) showed that, at least for some tasks, loss can scale exponentially with dataset size, rather than as a power-law.
- Tay et al. (2022) were able to drastically improve downstream performance with a small amount of extra pretraining on a different objective.
- Caballero et al. (2022) found that trend breaks in scaling curves can’t be easily predicted from smaller scale data.
In addition, scaling laws have been found for other properties, such as Goodharting (Gao et al. 2022), and there have been more connections between high-level scaling and low-level model features.
Takeaways
Upstream loss
For a vast collection of architectures and tasks, test loss for direct training scales predictably, transitioning from an initial random-guessing loss, to a power law regime, to a plateau at the irreducible loss. This is true for parameter, data, and compute scaling, and is relatively independent from the choice of architecture and hyperparameters, with some exceptions such as the learning rate schedule.
Except for the initial transition from random guessing to the power-law regime, and the transition from the power-law regime to the final plateau, the loss is well approximated by the functional form . There are several possible ways of modeling the transitions, but empirically it seems the best ones are the M4 estimator from Alabdulmohsin et al. (2022):
and the BNSL estimator from Caballero et al. (2022), although it has significantly more parameters:
Transfer and downstream accuracy
While ‘scale is all you need’ seems mostly true for direct training, when it comes to transfer learning, the downstream performance critically depends on the tasks at hand as well as the choice of architecture and hyperparameters (Tay et al., 2022). When the upstream and downstream tasks are similar, downstream loss can be reasonably well predicted from upstream loss, but this is not the case when the two tasks are substantially different (Abnar et al., 2021).
Theoretical analyses
So far the most convincing theoretical analyses I’ve found are Sharma et al. (2020) and Bahri et al. (2021). In them, the magnitude of the scaling exponents are shown to be inversely proportional to the intrinsic dimension of the data manifold, both empirically and theoretically.
1 comments
Comments sorted by top scores.
comment by Matthew Barnett (matthew-barnett) · 2023-01-27T20:23:03.010Z · LW(p) · GW(p)
This is very helpful. See also Gwern's bibliography of scaling papers.