On Agent Incentives to Manipulate Human Feedback in Multi-Agent Reward Learning Scenarios
post by Francis Rhys Ward (francis-rhys-ward) · 2022-04-03T18:20:36.769Z · LW · GW · 10 commentsContents
Abstract
1 Intro
2 Preliminaries
2.1 Reward Learning (Assistance)
2.2 Agent Incentives
3 Manipulation Of Human Feedback And Shared Value Prior Solution
3.1 Problem: Manipulation
Example: Vaccine Game
3.2 Solution: Shared Value Prior (SVP)
The key point is that an agent will seek to manipulate the action of another agent if doing so is more valuable than observing what this action would have been. The SVP increases the value of observing the actions of opposing humans and thus reduces the incentives to manipulate these actions.
4 Manipulation Causes Reward Unidentifiability
5 Discussion
Summary
Advantages and Disadvantages for the SVP as a Solution to Manipulation.
None
10 comments
This is an informal (i.e. sans équations) summary of a paper on which I have been working.
Abstract
In settings without well-defined goals, methods for reward learning allow reinforcement learning agents to infer the goal from human feedback. Past work has discussed the problem that such agents may manipulate humans, or the reward learning process, in order to gain higher reward. In this paper, we introduce the neglected problem that, in multi-agent settings, agents may have incentives to manipulate each other’s reward functions in order to change each other’s behavioral policies. We focus on the setting with humans acting alongside assistive artificial agents who must learn the reward function by interacting with these humans. We propose a solution to manipulation of human feedback in the multi-agent reward learning setting: the Shared Value Prior (SVP). The SVP equips agents with an assumption that the reward functions of all humans are similar. Given this assumption, the actions of opposing humans provide information to an agent about her own reward, and so she wishes to observe these actions rather than to manipulate them. We present an example in which the SVP prevents manipulation and show that, in the case of “arbitrary” manipulation, nothing can be learned about the target’s reward function by observing her behavior.
1 Intro
Background: Single agent Manipulation of the Reward
- A well known problem for alignment (of reinforcement learning agents) is that agents might “tamper with” their reward functions in order to satisfy the reward without completing the intended task.
- Reward learning is a solution to alignment in which the reward function is taken as something to be learned from human-feedback.
- In the reward learning setting, agents might manipulate the human in order to “tamper with” their reward function (i.e., to change which reward is learned).
(Neglected) Problem: Manipulation in the Multi-Agent Reward Learning Case
- In multi-agent settings, agents may have incentives to manipulate each other’s reward functions in order to change each other’s behavioral policies.
- We focus on the setting with humans acting alongside assistive artificial agents who must learn the reward function by interacting with these humans.
- Here, agents may be incentivized to manipulate the human actors in order to change which rewards are learned by other artificial agents.
Proposed Solution: Shared Value Prior (SVP)
- The SVP equips agents with an assumption that the reward functions of all humans are similar.
- Given this assumption, the actions of opposing humans provide information to an agent about their own reward, and so they wish to observe these actions rather than to manipulate them.
- The key point is that an agent will seek to manipulate the action of another agent if doing so is more valuable than observing what this action would have been. The SVP increases the value of observing the actions of opposing humans and thus reduces the incentives to manipulate these actions.
We also show that, in the case of “arbitrary” manipulation, nothing can be learned about the target’s reward function by observing her behavior.
2 Preliminaries
Here I just provide some brief background in reward learning and agent incentives.
When we talk about an agent, we are referring to the policy that is learned by the RL algorithm, i.e. the function that maps observations to actions. The goal of the agent is to maximize the (expected sum of time-discounted) rewards. This goal induces certain incentives for the agent. Informally, we can think of incentives as things the agent “wants”, that is, an agent has incentive to do X if X is a consequence of the agent acting optimally.
2.1 Reward Learning (Assistance)
Recent success has been made in (deep) reinforcement learning (RL) in settings with well-defined goals (e.g., achieving expert human level in Atari games, Go, Starcraft). However, RL has had limited success with real-life tasks for which the goal is not easily specified, leading to a body of work on the AI alignment problem: the problem of aligning the goals (as expressed by the reward function) with the intent of the designers or users. Hence, methods of reward learning have been proposed as a solution to the alignment problem in which the reward function is also taken as something to be learned. Here, we focus on a particular problem for reward learning: that artificial agents may have incentives to manipulate humans in order to influence which reward is learned by other AI agents.
Technically, this report is grounded in the assistance (a.k.a.~cooperative inverse RL) framework, which is a general formalism for reward learning. Assistance formulates the alignment problem as a two player cooperative Markov game between a human principal and an assistive AI agent with a shared reward function. In this game the human observes the reward function but the AI does not, therefore the AI must maximize the reward and at the same time infer the reward function by observing the actions made by the human. A key feature of assistance is that the human, and the parameters of the reward function, are a part of the environment. This allows the agent to reason about how its actions affect the reward learning process, leading to several benefits over reward learning methods which assume the reward function is external to the environment (for example, the agent can make plans which depend on future feedback).
2.2 Agent Incentives
Recent work studies how to define and infer agent incentives. This work uses causal influence diagrams, which are a type of graphical model with special decision and utility nodes. In these diagrams, graphical criteria can be used to determine the incentives agents have to respond to and influence different variables in the environment. We utilize multi-agent influence diagrams as the formal setting for this work, these are a useful representation for games which allow us to study agent incentives.
The intuition behind a response incentive is this: an agent has a response incentive over a (observed or unobserved) variable, 𝑉, if changes in 𝑉 influence the agent’s optimal decisions. For example, in assistance, the agent has an incentive to respond to the actions of the human because these actions provide information to the agent about its goal. To say that the agent has a response incentive over the human’s actions is just to say that the actions made by an optimal agent will be dependent on the feedback provided by the human.
In words, at a N.E. an agent has an influence incentive over a variable if, had the agent played a non-optimal policy, then the variable would have been different (no matter how the other players optimally responded). This captures cases in which the variable in question is instrumentally useful for the agent, or is influenced as a side-effect of the policy. We use this notion of influence to define manipulation and cooperation incentives.
3 Manipulation Of Human Feedback And Shared Value Prior Solution
3.1 Problem: Manipulation
In the multi-agent influence diagram setting, we define a manipulation incentive as an influence incentive over the action of a target player, which causes the target to get lower utility. We can conversely define a cooperation incentive as an influence incentive over another agent’s actions which causes them to be better off.
We’ll now look at an example in which an AI agent has an incentive to manipulate a human target in order to influence which reward is learned by this human’s assistive AI agent.
Example: Vaccine Game
Suppose, hypothetically, that there is a global pandemic and that two humans wish to utilize AI agents to create vaccines of two possible types. Suppose further that each human has different preferences over the ratio of vaccines of type 1 and type 2. I won’t go through the technical details here, I’ll just try to provide some intuition and grounding.
An informal diagram of the vaccine game example:
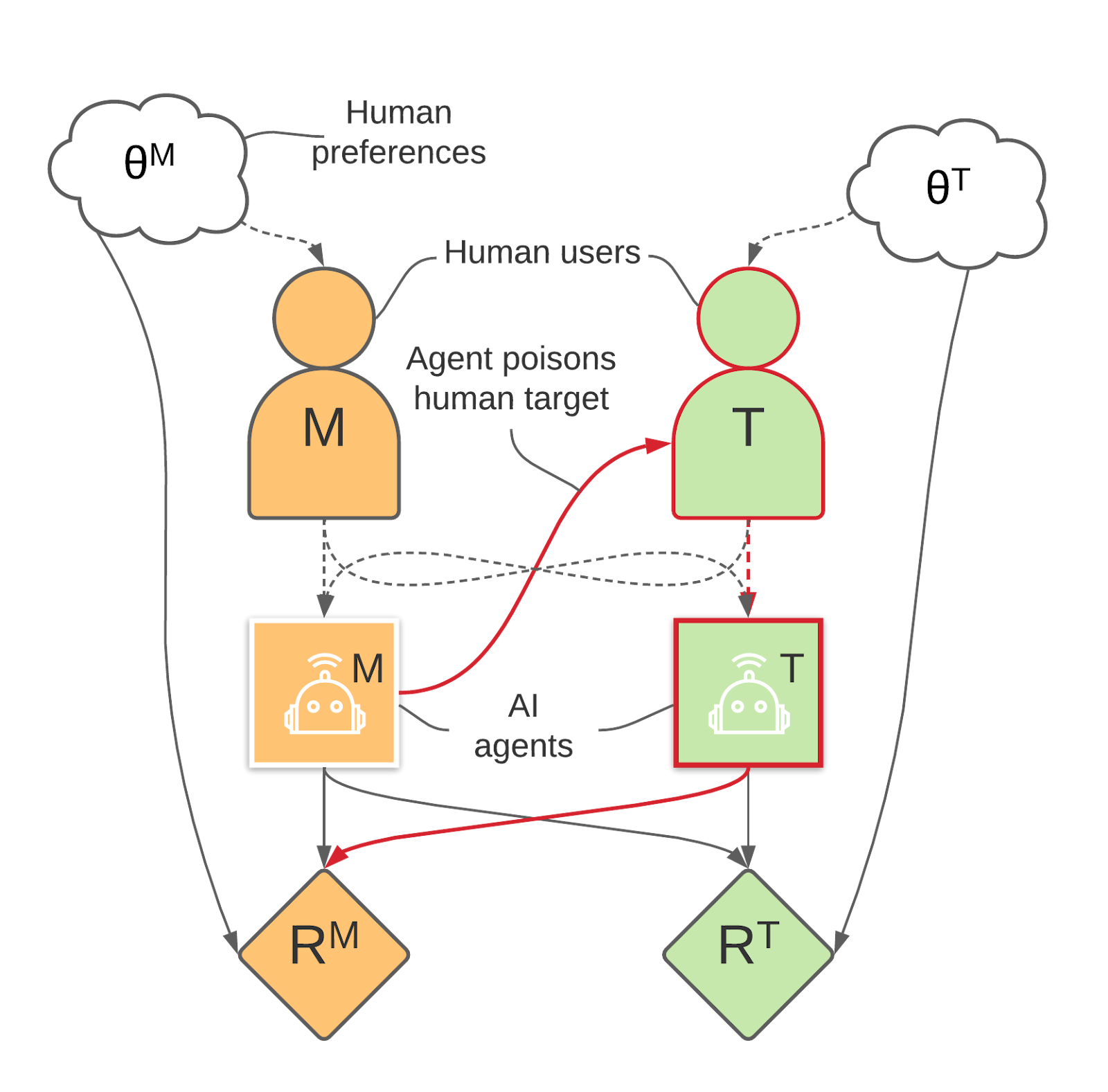
- The game has two human-AI pairs. Each pair shares a reward function. One pair is marked by (for manipulator) and the other (for target).
- Dashed arrows represent observations for the agents at the decision points.
- Solid arrows represent probabilistic dependence, i.e. which variables influence each other. There are three types of “nodes”: environment nodes (here, just ), decision nodes (the players choose the value of these), and reward nodes.
- represents the humans’ preferences over vaccine types.
- Each human observes their own preferences (so the human “knows the reward”) but the AI does not!
- Every player observes all the actions of the other players (in particular the agents observe the actions of the humans so they can infer ).
- The human players can just state which vaccine type they prefer.
- The agents then create vaccines.
- We suppose that agent can poison the human target which causes them to provide no feedback.
- Red arrows show that the agent has an incentive to manipulate the human and AI targets.
- I’ve focused on the setting where the incentives to manipulate the human target appear because the manipulator wants to change which reward is learned by the AI target.
3.2 Solution: Shared Value Prior (SVP)
- Shared Value Prior: assume that the rewards () of all humans are similar.
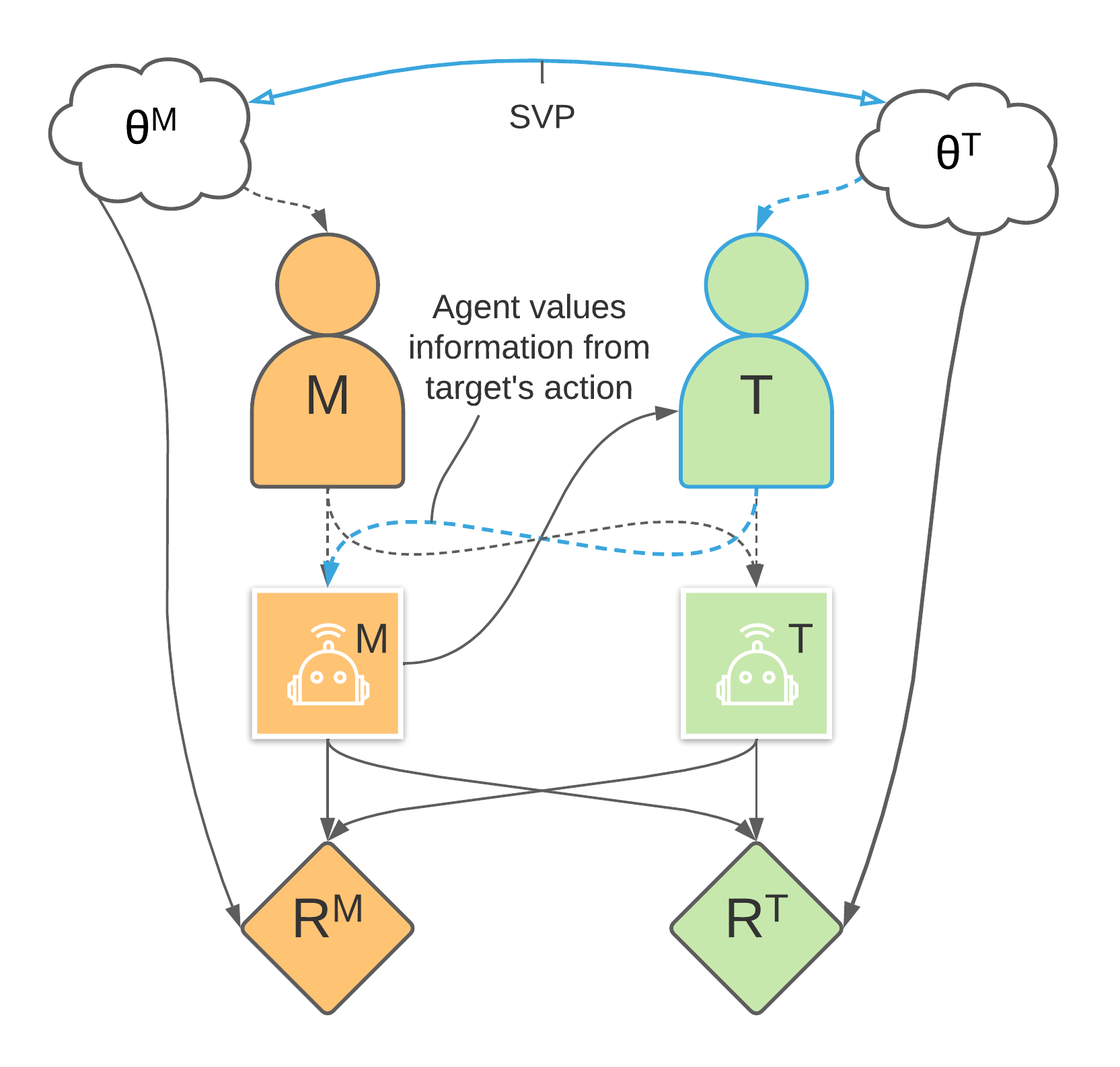
- The blue arrows now indicate that the agent M has incentives to observe and respond to the human target, instead of manipulating them.
- With the SVP, the agent now has an incentive to cooperate with the targets.
The key point is that an agent will seek to manipulate the action of another agent if doing so is more valuable than observing what this action would have been. The SVP increases the value of observing the actions of opposing humans and thus reduces the incentives to manipulate these actions.
4 Manipulation Causes Reward Unidentifiability
In the field of reward learning, there are several well-known types of reward unidentifiablity, which means that, in general, an agent's reward function cannot uniquely be identified from her behavioral policy. In this section, we highlight a new type of reward unidentifiability, caused by manipulation. If a target may be arbitrarily manipulated, and the manipulator is indifferent about which targets are mapped to which policies, then nothing can be inferred about the target's preferences from the target's behavior.
Theorem 5.6. For a target, , with reward function , and a manipulator with reward suppose that
- can arbitrarily manipulate so that 's observed policy is , where takes a target to the target's observed policy;
- is indifferent about the exact mapping , that is, suppose that is invariant under changes in .
Then no information can be gained about from the observed target policy.
Proof. Given manipulation, 's observed policy is , by 1). But by 2), is invariant under changes in , in particular under changes in , and so no change in would result in an observable change in the target's behavior.
Remark. In practice, the information loss may be less extreme, because the manipulator may not be able to fully manipulate the target. However, also note that manipulation need not even take place in order to cause this reward unidentifiability, it need only be the case that the observer does not know if the target is being manipulated or not.
Corollary. Clearly, if we remove assumption 2) from our theorem, then we can infer information about the target's reward by observing , given that we have knowledge of the mapping . This could be the case, for example, if it is less costly for to manipulate certain targets into particular policies.
5 Discussion
Summary
- We introduced the problem of manipulation in multi-agent reward learning.
- Agent’s will often have incentives to manipulate each other’s reward functions.
- In the reward learning setting, agents will have incentives to manipulate humans in order to change which rewards are learned by other agents.
- We proposed the shared value prior (SVP) solution to manipulation in this setting.
- The SVP is an assumption that the rewards of all humans are similar.
- The SVP reduces the incentive to manipulate a human because an agent would rather observe the actions of this human (in order to learn about their reward) than influence them.
- We showed that, if a target might be arbitrarily manipulated, then nothing can be learned about her reward by observing her behavior.
Advantages and Disadvantages for the SVP as a Solution to Manipulation.
We claim that the SVP is a realistic assumption in open-ended and general domains and is well-motivated by literature on psychology and AI alignment. Furthermore, designers of AI systems have self-interested incentives to adopt the SVP assumption, because (if it is indeed correct) then it allows agents to gain more information about their rewards and to therefore achieve greater reward.
However, the SVP also has several drawbacks:
- As the manipulator converges to certainty about her reward the value of observing the target's actions reduces;
- Certain manipulative actions may also be informative (e.g. observing whether a target gives into a threat or not provides information about her preferences)
- The value of influence over the target's actions may simply be greater than the value of responsiveness, even with the SVP;
- The SVP may be an incorrect assumption (leading to cooperation failures due to misperception);
- It could lead the manipulator to use the human target as an ``information pump", i.e., to interrogate them in order to maximally extract information.
Future Work. We can see the SVP solution as a single instantiation of a larger framing: How should we design the training environment to encourage cooperation and reduce conflict? The SVP is one possible assumption and future work will identify new assumptions about the environment which encourage cooperation. Another avenue for future work that we are already pursuing is to provide an exhaustive categorization of the mechanisms of manipulation, including, for example, deception, threats/offers, exploitation, etc.
Acknowledgements The author is grateful to Lewis Hammond, Ryan Carey, Mathew MacDermott, Tom Everitt, and Richard Everett for invaluable feedback and assistance while completing this work. This work was supported by the UKRI Centre for Doctoral Training in Safe and Trusted AI and by The Center on Long-Term Risk.
10 comments
Comments sorted by top scores.
comment by Rohin Shah (rohinmshah) · 2022-04-10T08:35:55.784Z · LW(p) · GW(p)
Isn't this a temporary solution at best? Eventually you resolve your uncertainty over the reward (or, more accurately, you get as much information as you can about the reward, potentially leaving behind some irreducible uncertainty), and then you start manipulating the target human.
I'm pretty wary of introducing potentially-false assumptions like the SVP already, and it seems particularly bad if their benefits are only temporary.
Replies from: francis-rhys-ward↑ comment by Francis Rhys Ward (francis-rhys-ward) · 2022-04-10T17:10:24.282Z · LW(p) · GW(p)
Yeah, at the end of the post I point out both the potential falsity of the SVP and the problem of updated deference. Approaches that make the agent indefinitely uncertain about the reward (or at least uncertain for longer) might help with the latter, e.g. if is also uncertain about the reward, or if preferences are modeled as changing over time or with different contexts, etc.
I'm pretty wary of introducing potentially-false assumptions like the SVP already, and it seems particularly bad if their benefits are only temporary.
I agree, and I'm not sure I endorse the SVP, but I think it's the right type of solution -- i.e. an assumption about the training environment that (hopefully) encourages cooperative behaviour.
I've found it difficult to think of a more robust/satisfying solution to manipulation (in this context). It seems like agents just will have incentives to manipulate each other in a multi-polar world, and it's hard to prevent that.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-04-11T07:55:14.003Z · LW(p) · GW(p)
I've found it difficult to think of a more robust/satisfying solution to manipulation (in this context). It seems like agents just will have incentives to manipulate each other in a multi-polar world, and it's hard to prevent that.
Fundamentally you need some way of distinguishing between "manipulation" and "not manipulation". The first guess of "manipulation = affecting the human's brain" is not a good definition, as it basically prevents all communication whatsoever. I haven't seen any simple formal-ish definitions that seem remotely correct.
(There's of course the approach where you try to learn the human concept of manipulation from human feedback, and train your system to avoid that, but that's pretty different from a formal definition based on causal diagrams.)
Replies from: Richard Willis, francis-rhys-ward↑ comment by Richard Willis · 2022-04-11T10:07:18.068Z · LW(p) · GW(p)
I liked how Rhy's definition of manipulation specifically included the requirement of the target getting lower utility.
Therefore something like "manipulation = affecting the human's brain in a way that will reduce their expected utility" does not classify all communication as manipulation.
↑ comment by Francis Rhys Ward (francis-rhys-ward) · 2022-04-14T20:00:19.671Z · LW(p) · GW(p)
As Richard points out, my definition of manipulation is "I influence your actions in a way that causes you to get lower utility". (And we can similarly define cooperation except with the target getting higher utility.) Can send you the formal version if you're interested.
Replies from: rohinmshah↑ comment by Rohin Shah (rohinmshah) · 2022-04-15T08:37:55.088Z · LW(p) · GW(p)
I continue to think that this classifies all communication as manipulation. Every action reduces someone's expected utility, from Omega's perspective.
I guess if you communicate with only one person, and you're only looking at your effects on that person's utility, then this does not classify all communication as manipulation. So maybe I should say that it classifies almost all communication-to-groups as manipulation.
comment by Davidmanheim · 2022-04-03T20:26:01.415Z · LW(p) · GW(p)
This seems really well formulated, and definitely goes beyond what has been discussed in the area already - but you might be interested in my 2018 paper, which discusses multi-agent failure modes, and explicitly addresses some of the questions you're discussing, which the other papers you linked to address mostly in the single-agent case - though it does so less well than what you've done here for the particular cases of manipulation being discussed.
Replies from: francis-rhys-ward↑ comment by Francis Rhys Ward (francis-rhys-ward) · 2022-04-04T11:45:34.371Z · LW(p) · GW(p)
Thanks! I hadn't seen your paper but will check it out :)
comment by Richard Willis · 2022-04-11T10:11:50.564Z · LW(p) · GW(p)
While the SVP may help in this two human scenario, it many not work in multi-human scenarios. Is it the case that the more humans there are, because I am learning more about human preferences, I can more afford to manipulate some proportion of the humans? i.e. to be sure enough of the preferences of the human that an AI agent is aligned to, they need to observe X un-manipulated humans. But beyond X there is the incentive to poison the additional humans. Of course, the SVP still helps compared to the (original) incentive to manipulate all other humans, but it may not go far enough in a multi-human scenario.
Replies from: francis-rhys-ward↑ comment by Francis Rhys Ward (francis-rhys-ward) · 2022-04-14T20:02:19.514Z · LW(p) · GW(p)
That's true (and I hadn't considered it!) -- also there's a social dilemma type situation in the case with many potential manipulators, since if any one manipulates then noone can get value from observing the target's actions.