Modelling and Understanding SGD
post by J Bostock (Jemist) · 2021-10-05T13:41:22.562Z · LW · GW · 0 commentsContents
SGD and Local Minima Monte Carlo None No comments
I began this as a way to get a better understanding of the feeling of SGD in generalized models. This doesn't go into detail as to what a loss function actually is, and doesn't even mention neural networks. The loss functions are likely to be totally unrealistic, and these methods may be well out-of-date. Nonetheless I thought this was interesting and worth sharing.
Imagine we have a one-parameter model, fitting to one datapoint. The parameter starts at and the loss is . The gradient will then be .
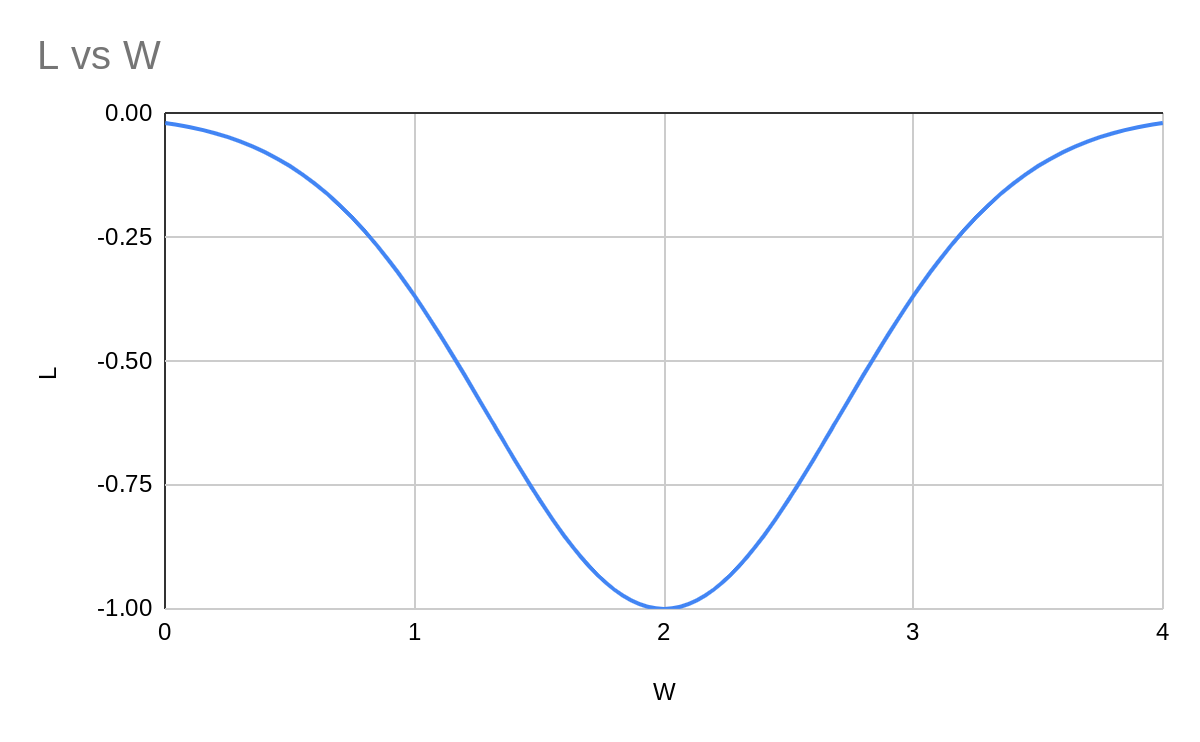
An imaginary continuous gradient descent will smoothly move to the bottom of the well and end up with .
A stepwise gradient descent needs a hyperparameter telling it how much to move the parameters each step. Let's start with this at 1.
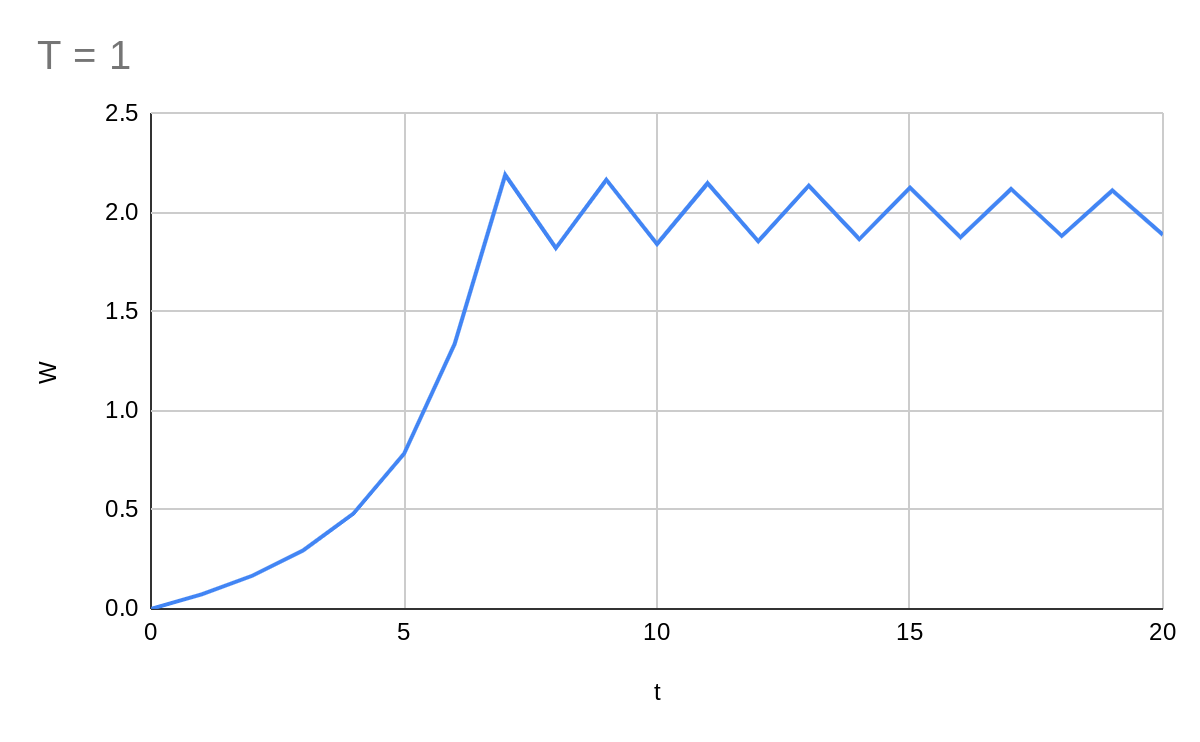
This gives us a zig-zag motion. The system is overshooting. Let's pick a smaller T value.
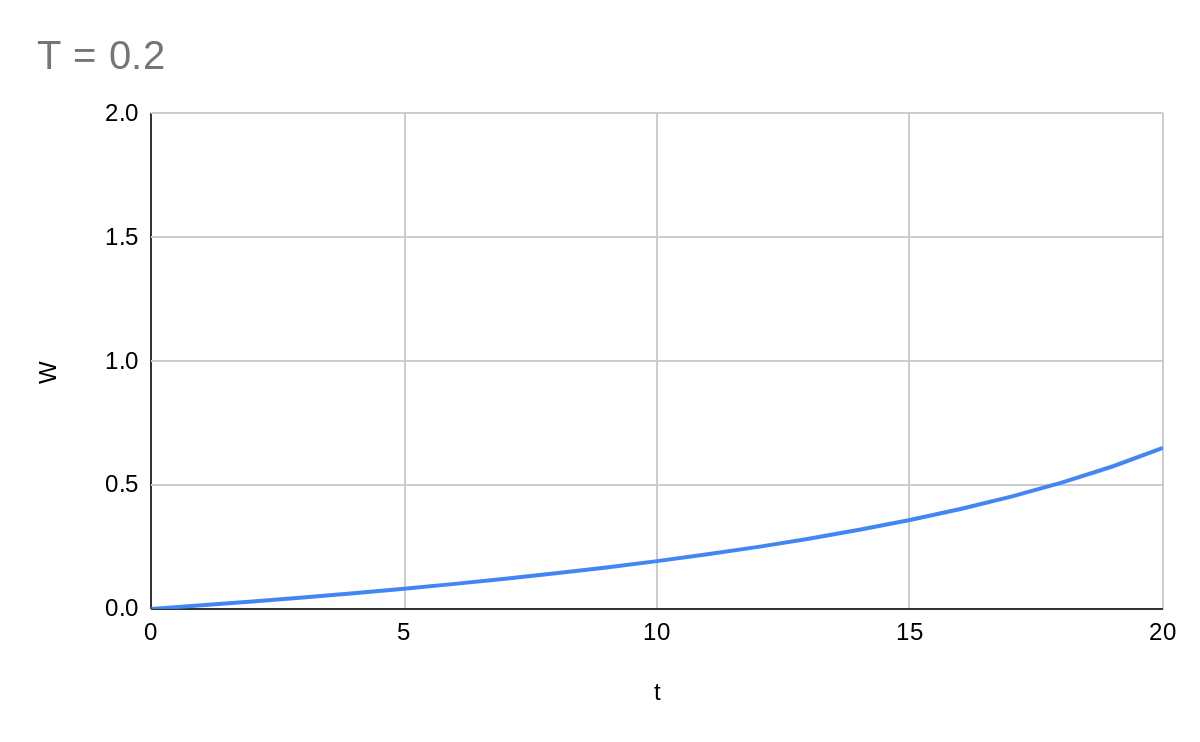
Hmm. Now our model converges quite slowly. What about 0.5?
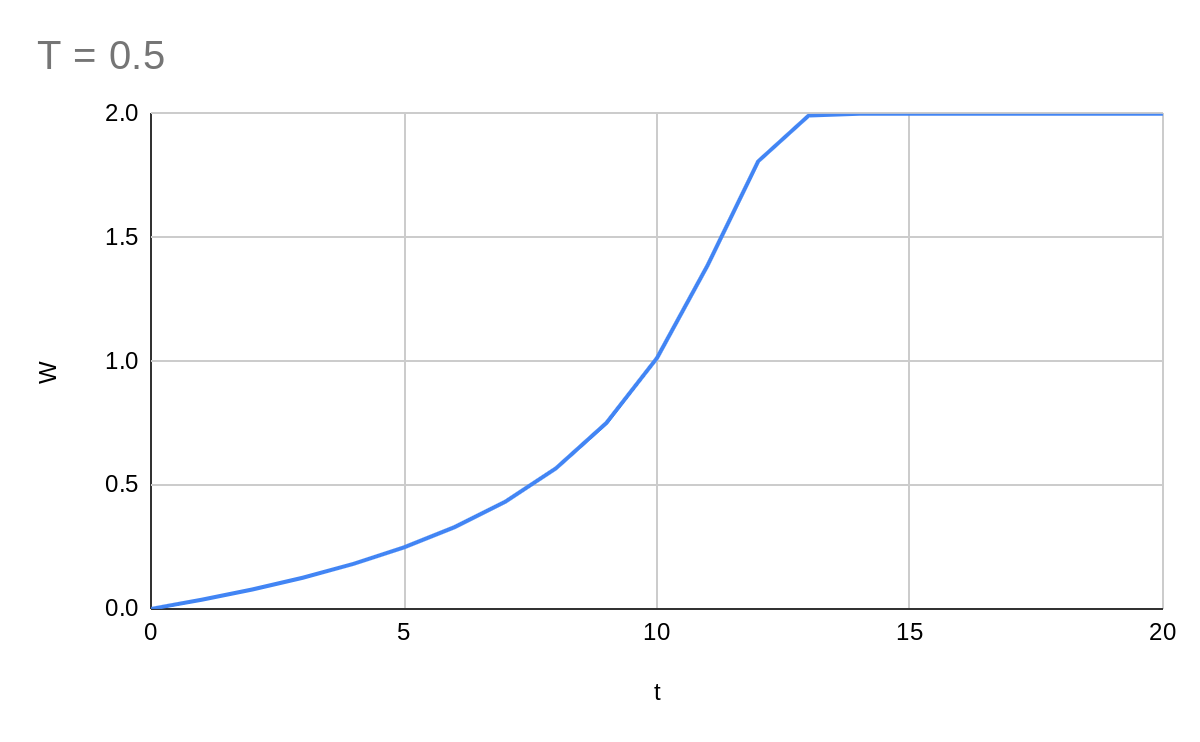
Much better. Seems that there's an optimal value of , which we will later see depends on the spikiness of the loss function.
is not dimensionless and has the dimension of , as . Certain function-minimising methods like Newton's method use (for example) where is dimensionless. This is why different loss functions require different values.
SGD and Local Minima
What if we have two datapoints? Now . Let as above but .
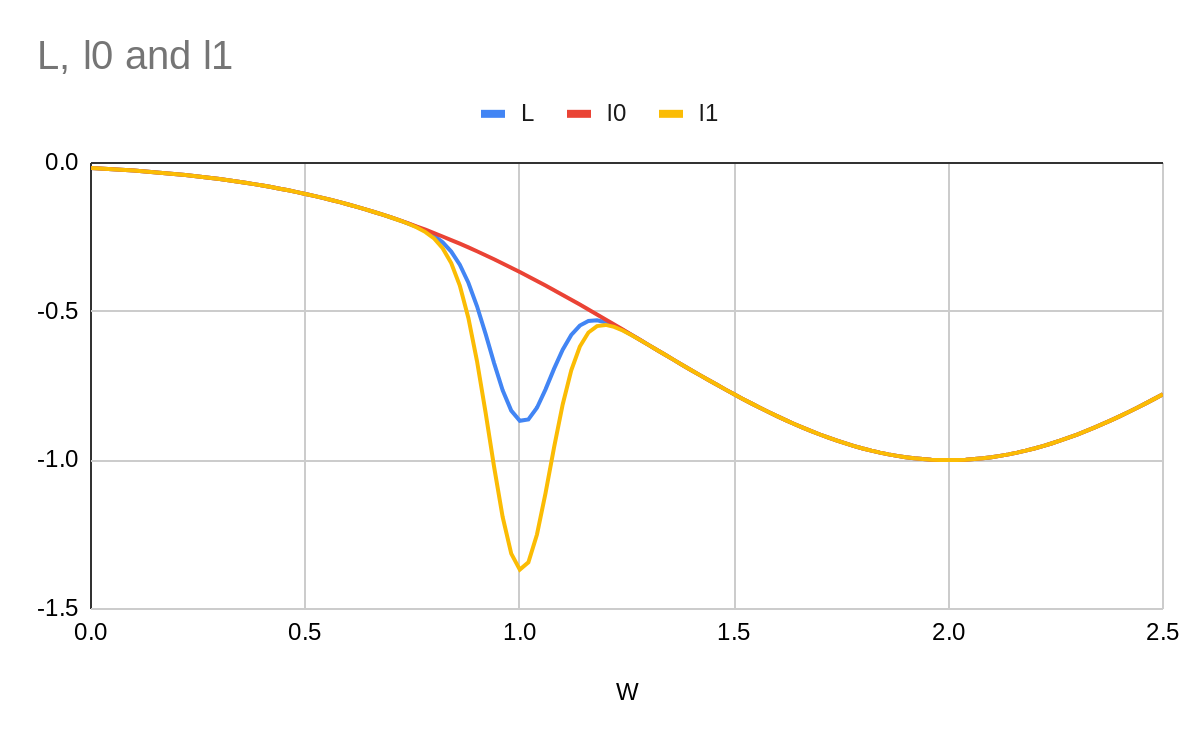
Now our loss function L has a new local minimum I think of this as "the pit". Where we end up depends on where we start. If we start at then we'll clearly end up at but if we start at , then:
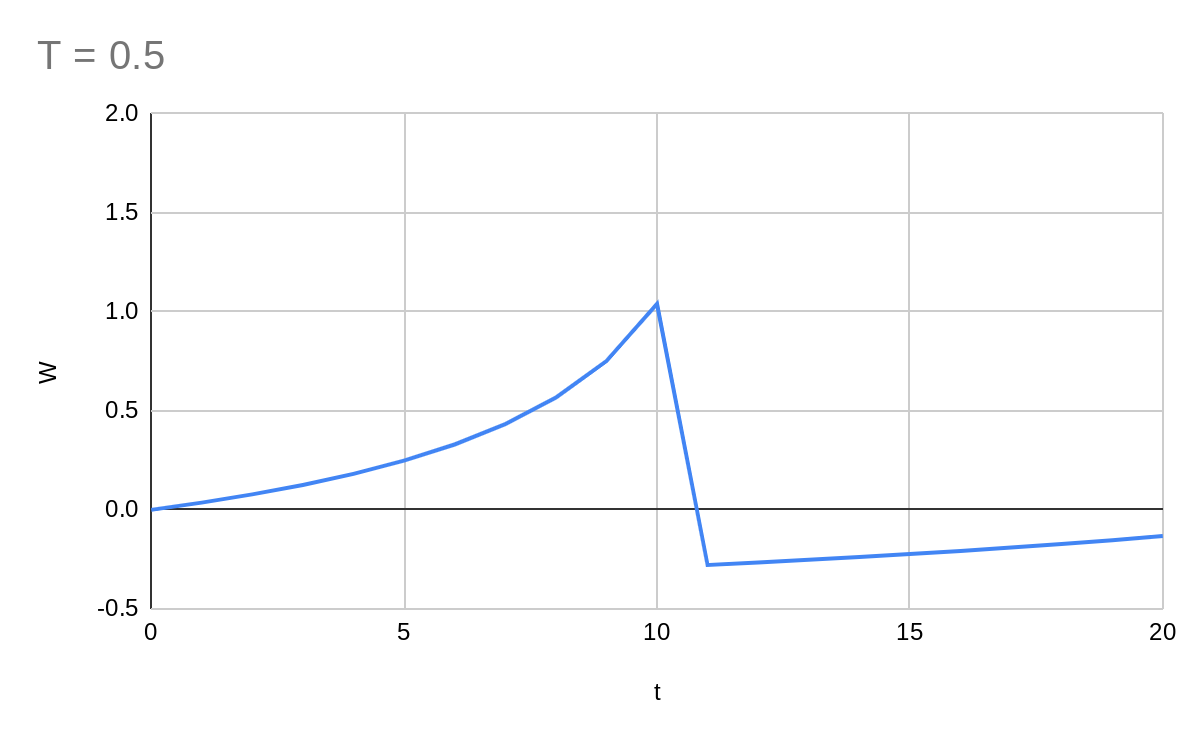
Huh, this isn't what I expected at all! The gradient must have been too high around the local minimum. Let's try with T = 0.05, which will be slower but ought to work better.
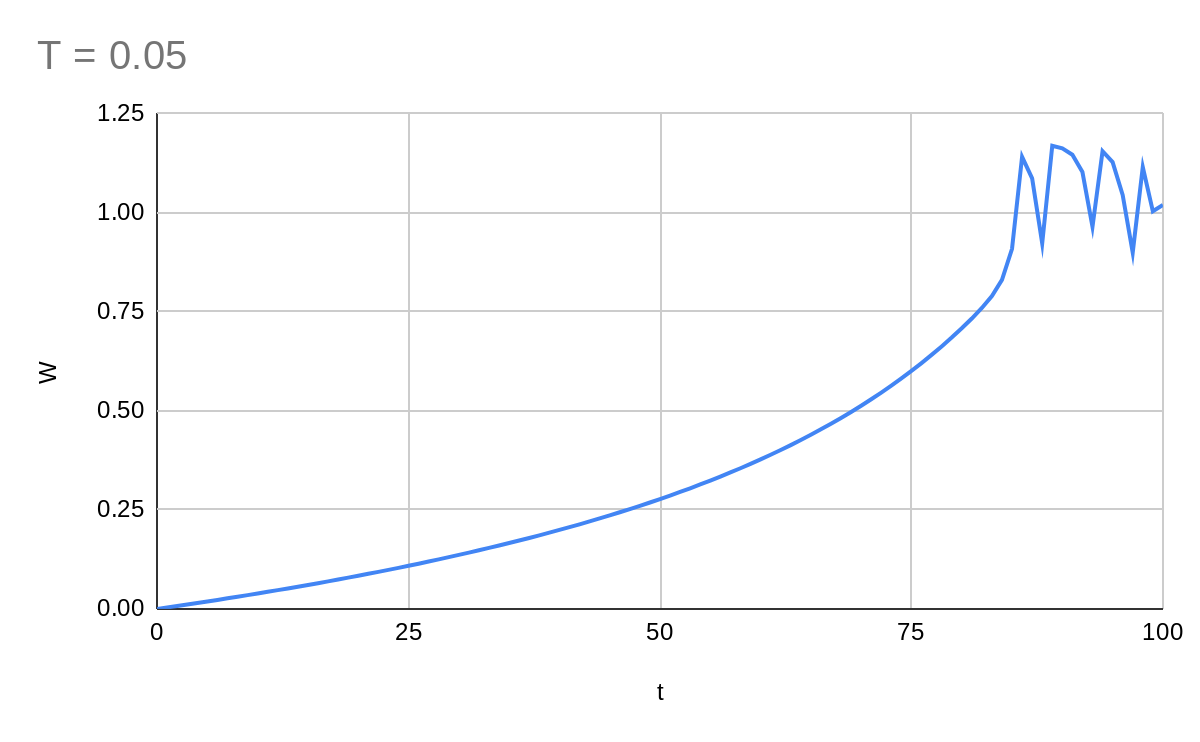
This is more like what I expected. Now our system is stuck in the local minimum.
But most modern gradient descent algorithms use stochastic gradient descent. We can model this here by randomly picking one of the two datapoints (with associated loss function) to descend by each step.
What happens now? Well now we have a chance to escape the pit. Let's say we're at the minimum of the pit. How many consecutive descent steps performed on will get us out of the pit?
Well by solving for the stationary points of , we get and . It turns out 5 steps of descent on will get us to which is out of the pit. Within 100 steps we have an 81% chance of getting out.
The interesting thing is that this doesn't depend much on the depth of the pit. If the local pit is twice as deep in , then we only require one more consecutive step to escape it. If this is the case, then is in fact a global minimum in . But because of SGD, it's not stable, and the only stable point is ! Clearly there is something other than overall minimum which affects how the parameter of the model changes over time.
What about smaller values of ? The number of consecutive steps in needed to escape the pit is inversely proportional to . In the infinite limit as , we just converge on a continuous gradient descent, which will find the first minimum it comes to.
This reminds me of chemistry. It's as if the size of the step has to be big enough for the model to overcome some activation energy to cross the barrier from the pit to the one. This is the motivation for the letter : temperature. The larger is, the more likely it is that the model will cross over out of the local minimum.
Monte Carlo
In fact we generally need significantly fewer than this. Starting around 1, one update on is enough to push us into the high-gradient region of , which means even an update on will not move us back down into the centre, but rather to the left side of the pit, where a subsequent update might push us further towards the right.
Let's estimate the probability of escaping the pit in 100 steps as a function of T:
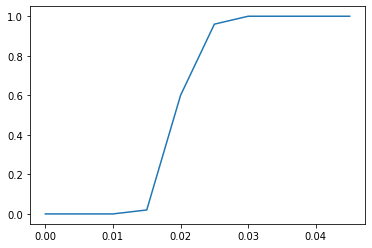
What about 1000?
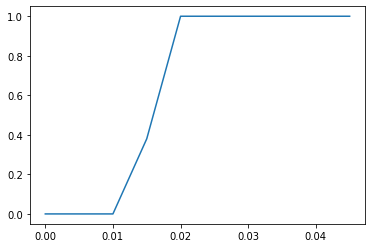
As we sort-of expected, it is easier to escape the pit than our original model predicted.
Let's look more closely at the region between 0.01 and 0.02:
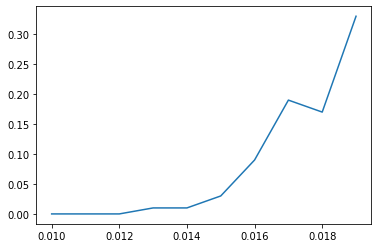
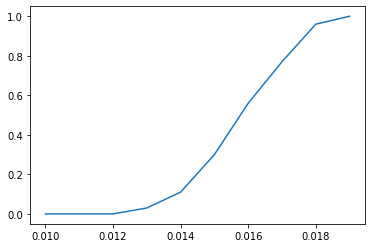
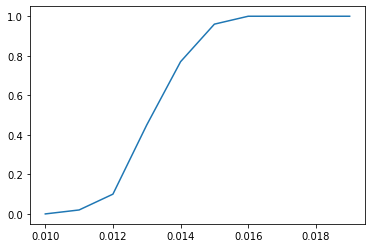
It looks roughly like the of the number of steps required to escape the pit is a function of T. Hopefully the later posts in this series will allow me to understand why.
0 comments
Comments sorted by top scores.