Existing Safety Frameworks Imply Unreasonable Confidence
post by Joe Rogero, yams (william-brewer), Joe Collman (Joe_Collman) · 2025-04-10T16:31:50.240Z · LW · GW · 1 commentsThis is a link post for https://intelligence.org/2025/04/09/existing-safety-frameworks-imply-unreasonable-confidence/
Contents
How to judge a framework Case Study: Anthropic’s Responsible Scaling Policy Some common errors To open one’s mouth and remove all doubt Poor incentives worsen these gaps Towards more responsible risk management communication Conclusion Appendix - Other Frameworks OpenAI’s Preparedness Framework Google DeepMind’s Frontier Safety Framework + AI Principles Page Meta’s Frontier AI Framework The xAI Risk Management Framework None 1 comment
This is part of the MIRI Single Author Series. Pieces in this series represent the beliefs and opinions of their named authors, and do not claim to speak for all of MIRI.
Most human endeavors have bounded results. A construction project may result in a functional bridge or a deadly collapse, but even catastrophic failure will not kill a billion people. Both success and failure are bounded, and the humans undertaking such a project can make reasonably correct estimates of those bounds.
The development of frontier artificial intelligence often thwarts any concrete expectation. Leading developers talk of scenarios as extreme as human extinction from AI, but there is heavy disagreement and uncertainty about when particular disaster scenarios are likely to arise. You can guess at a model’s properties ahead of time, but this is always a guess, no matter how informed. Models’ behavior is increasingly goal-oriented and difficult to predict. So when doing frontier development, you don’t know the bounds you’re working in.
You can run thought experiments, or get all of the smartest people you know together, and have them tell compelling stories about plausible dangers. You can compile these worrying scenarios into a list and distill from that list a compendium of plausible early warning signs for each scenario, and you’ll have a loose account of situations and behaviors to monitor for.
Importantly, though, such plans would be incomplete in potentially fatal ways. The list generated by such a process is not comprehensive. The tracking of worrying scenarios is imperfect, limited as it is by available tools and understanding. Further, with frontier AI we should expect not just the unexpected, but the unexpectable—outcomes generated by a profoundly alien system, or a system that surpasses humans in unprecedented ways.
The high-level goals of a risk management framework in this context ought to include:
- Estimating the total risk to society posed by a given approach, and
- Halting any approach whose estimated risk exceeds expected benefits.
Questions it should be attempting to answer include:
- What is the chance we fail to anticipate a potentially dangerous capability?
- What is the chance we fail to detect the attainment of a dangerous capability?
- What is the chance we cannot provide adequate mitigation?
- What is the residual risk after all available mitigations are applied?
The labs’ public frameworks near-universally fail to address these goals or questions, suggesting an unwarranted confidence in their safety techniques and their understanding of the risk landscape. Below, we review five public frameworks on their adherence to sound risk management practices.
To be clear, we don’t think it should take a detailed formal risk assessment to realize that, given the field’s current level of understanding, if anyone creates artificial superintelligence, the most likely outcome is disaster.
To the extent that the labs’ current agenda is driven by different fundamental beliefs about reality, such that they think the chance of catastrophe is acceptably low,[1] we invite them to show their work—to quantify those beliefs where others can see and critique them.
In practice, we predict such beliefs would prove poorly justified when dragged into the light. But the AI labs present themselves as doing responsible and transparent risk management without showing their work, so here we are.
We aim to show that, in their public frameworks:
- Frontier AI labs have not outlined an adequate strategy to address catastrophic risk;
- Their stated mechanisms leave dangerous gaps; and
- The labs systematically communicate in ways that hide the hard problems.
We posit that the many gaps in labs’ public strategies reflect real inadequacies in their plans. They fail to meet the baseline expectations for risk assessment in mature fields—fields in which the upper bound on catastrophe is far less than human extinction, and in which the system being assessed cannot actively subvert the assessment itself.
We’ve chosen to focus on five documents: Anthropic’s Responsible Scaling Policy (March 2025), OpenAI’s Preparedness Framework (December 2023), Google DeepMind’s Frontier Safety Framework (February 2025), Meta’s Frontier AI Framework (February 2025), and xAI’s Draft Risk Management Framework (February 2025). We’ll discuss some things that most or all of them missed, and why we think this reflects a systemic miscalibration in the industry.
In the interest of time, we focus the bulk of our analysis on the stronger frameworks, those of Anthropic and DeepMind.[2]
How to judge a framework
We think frameworks need to be assessed on how well they:
- Manage the threats we concretely understand.
- Offer ways to improve our understanding of the risk landscape.
- Account for the threats we don't yet concretely understand.
If we're walking into a minefield, these would correspond to:
- Avoid stepping on mines we can detect.
- Get better at detecting mines.
- Avoid stepping on mines we can't yet detect.
Most frameworks make an attempt at (1), and do better at it than at (2) or (3), but none state the level of residual risk they consider acceptable, nor do they lay out any plan to quantify their estimates.
Some gesture at (2). OpenAI passingly mentions unknown unknowns, but fails to adequately account for them, and in practice actively opposes enforceable regulation that would produce more evidence about them. Anthropic and DeepMind make a slightly better showing, performing and publishing research aimed at detecting misbehaviors and better understanding models.
(3) is largely absent.
Mature industries respect the limits of their own knowledge. They make the important assumption that they will probably miss something important, and make allowances for both catching these errors of omission and preventing catastrophe when they occur.
As a point of comparison, the petroleum industry often makes a distinction between “Unknown” risks (whose existence was not institutionally expected, even if it was known to someone) and “Known” risks (which have been formally documented, along with either an explicit signoff by management or a mitigation plan). Investigations of incidents and near misses contain procedures that explicitly attempt to convert the first risk category into the second,[3] and indeed this is one of the primary functions of risk management as a discipline.
Higher stakes—greater potential for catastrophic outcomes—generally correlate with even stricter standards. Legally running a nuclear plant requires such a deep understanding of the underlying mechanisms and such robust and redundant safety practices that even multiple unprecedented failures are often recoverable. This is why meltdowns are rare, even under regulatory regimes looser than those of the US.
Frontier frameworks—many of which purport to address risks of globally catastrophic scale—fail in several places to meet even the basic risk management standards of a mature industry.
Case Study: Anthropic’s Responsible Scaling Policy
Anthropic’s RSP does a number of things well. Of particular importance is their emphasis on precursor capabilities; that is, Anthropic acknowledges that they cannot fully trust any test or evaluation to reflect the full capabilities of a sophisticated frontier AI. They take inspiration from the concept of a safety case:
First, we will compile a Capability Report that documents the findings from the comprehensive assessment, makes an affirmative case for why the Capability Threshold is sufficiently far away, and advances recommendations on deployment decisions.
Anthropic claims to hold themselves to a high standard of managing and communicating risk.
Since our founding, we have recognized the importance of proactively addressing potential risks as we push the boundaries of AI capability and of clearly communicating about the nature and extent of those risks.
One of the key arguments used to justify Anthropic’s founding was that their research will increase the world’s understanding of AI and its risks. Their research has indeed done so.
However, Anthropic has yet to make a principled case that their efforts are risk-reducing on net. An analysis supporting such a claim would include a quantified estimate of the risk to society they are currently causing, weighed against the risk reduction they estimate from their activities. Anthropic has, to our knowledge, published no such analysis.
We suspect that an honest accounting would suggest an unacceptable level of absolute incurred risk, whether or not upsides are taken into account, and labs including Anthropic are thus strongly incentivized to avoid such an accounting. Some labs might credibly say “we think the risks we are incurring are negligible”, but in this case Anthropic’s relative awareness of catastrophic risk makes it harder for them to make this claim.
That makes it all the more disappointing for them to lay out a framework that purports to address these catastrophic risks while in fact leaving massive gaps. By downplaying the risks and implicitly claiming understanding they do not in fact possess, Anthropic undermines their own mission to communicate clearly about the nature and extent of the threats their research poses.
For instance, in 2023, Anthropic introduced the concept of AI Safety Level (ASL) Standards. According to Anthropic, these are “a set of technical and operational measures for safely training and deploying frontier AI models.”
Note that, in an explicit update to the 2023 definition, ASLs are the standards to apply, not the capability levels at which to apply them. We think this is a useful and important distinction to make, not an error on Anthropic’s part.
The framework mentions three levels. ASL-2, in the Appendix, is the baseline they are currently applying to models. ASL-3 is the bulk of the current framework, and Anthropic intends to apply this level to models they assess as passing key Chemical, Biological, Radiological, and Nuclear (CBRN) or autonomous AI research thresholds. They also state an intent to develop “ASL-4” standards and the associated “Capability Thresholds”, later publishing preliminary sketches of these standards which use the concept of a safety case.
In the event that Anthropic deems that a model requires ASL-3 but they cannot implement ASL-3 standards, they commit to pausing development until they can. (Presumably this extends to ASL-4 as well, once developed.) However, we note that Anthropic has removed from their framework the commitment to actually plan for such a pause, which originally read:
Proactively plan for a pause in scaling. We will manage our plans and finances to support a pause in model training if one proves necessary, or an extended delay between training and deployment of more advanced models if that proves necessary. During such a pause, we would work to implement security or other measures required to support safe training and deployment…
Given that Anthropic’s framework was the only one to mention this important step, it’s concerning that they chose to omit it from their revised framework.
Anthropic also says:
The types of measures that compose an ASL Standard currently fall into two categories - Deployment Standards and Security Standards - which map onto the types of risks that frontier AI models may pose. ... We expect to continue refining our framework in response to future risks (for example, the risk that an AI system attempts to subvert the goals of its operators).
Note the lack of “Training Standards” or “Development Standards”. Anthropic knows AI training can itself be catastrophically dangerous,[4] so this is a glaring omission.[5]
Note also the categorization of “an AI system attempts to subvert the goals of its operators” as a future risk. This public framework predates the paper in which Anthropic demonstrated this behavior in their own model, but only by a couple months; how far do capabilities need to progress for it to merit an upgrade to present risk?
We do, however, applaud Anthropic for acknowledging the need for securing model weights against attackers and proposing some ways to address their vulnerabilities here.
Regarding capability thresholds, Anthropic says:
A Capability Threshold tells us when we need to upgrade our protections…
This oversells the method used to evaluate thresholds. Knowing with near certainty whether a given level of capability has been reached would let us know when to upgrade our protections. But tests are not this robust. Testing below the thresholds that trigger ASL-3 does not necessarily imply that a model requires only ASL-2, and so on.
Importantly, highly capable models will likely be able to sandbag on these evaluations, meaning that the evaluations become suspect when they encounter dramatic leaps in capability—the exact case likeliest to pose extreme risk and that evals are centrally intended to catch.
Safety researchers have sometimes, upon detecting a specific worrying behavior in a model, also found evidence of attempts by the model to conceal this behavior. That is, we currently have good cause to believe that there may only be a narrow window in which a specific capability will be detectable, before a model learns to obscure it. For that matter, we cannot rule out the possibility that there may be no such window.
We recognize the potential risks of highly persuasive AI models. While we are actively consulting experts, we believe this capability is not yet sufficiently understood to include in our current commitments.
We appreciate that Anthropic explicitly highlights this gap. We think they should go farther.
Here the authors highlight a known risk, but say that, since it’s not well-understood, they won’t include it anywhere in their commitments. This omission undermines the implied thoroughness of the organization’s commitments, and demonstrates that the focus of the document is on risks that are already well-understood, rather than the full space of risks. They later say:
We also make a compelling case that there does not exist a threat model that we are not evaluating that represents a substantial amount of risk.
Super-persuasion is an obvious counter-example.
A “compelling case” for thoroughness should support the claim that the set of all unevaluated threat models does not pose substantial risk. It must account for all potential risk sources, whether well-understood, partially understood, or entirely unknown. It must at minimum attempt to quantify the risks posed by each source.
A well-supported claim that “the risk of catastrophic outcomes from super-persuasion is below X%” would be a valid argument for declining to address super-persuasion. “We don’t understand super-persuasion” is not. To meet a responsible standard of clear communication, Anthropic should present the numerical estimates of risk from all sources, including unknown unknowns, whose sum they believe justifies continued scaling.
Some common errors
Frontier labs’ stated approaches lack the crucial assumption, seen in mature industries, that “we have probably missed something important.” They instead rely on someone involved noting a concrete problem before it’s too late.
They all discuss inadequate deployment safeguards as though they were far more robust than in reality. Protections against jailbreaking tend to crumple within days or minutes of a model’s public release, and there is no principled reason to expect this to change.
Several frameworks conflate estimated capabilities with actual capabilities, treating measured performance as equivalent to (rather than suggestive of) that which can be elicited by later use or fine-tuning. Evaluations offer a lower bound on capabilities, not an upper bound, and treating their output as an upper bound is a dangerous mistake that undermines the reliability of “capability threshold” approaches.
They all fail to adequately account for, or in some cases even to acknowledge the possibility of, false negatives in their assessment process.[6]
Some illustrative quotes are included below, with what each company did not say enclosed in {braces}.[7]
Anthropic:
Although {we believe} the ASL-2 Standard is appropriate for all of our current models…
Google DeepMind:
This section describes our mitigation approach for models that {we assess to} pose risks of severe harm through misuse...
For security, we have several levels of mitigations, allowing calibration of the robustness of security measures to the risks {we assess to be} posed.
The following deployment mitigation process will be applied to models {assessed as} reaching a CCL, allowing for iterative and flexible tailoring of mitigations to each {identified} risk and use case.
Pre-deployment review of safety case: general availability deployment of a model takes place only after the appropriate corporate governance body determines the safety case regarding each CCL {we believe} the model has reached to be adequate.
Meta:
A key component of our Frontier AI Framework is a set of thresholds that {if our test results indicate to us they might have been reached, would} prompt particular measures...
Frontier labs are also in the habit of looking away from the unknown. Several labs explicitly choose not to account for hard-to-define risks until they are better understood.
We note that the samples below do represent an improvement over those above, in that the omissions are made explicit. The question remains, however: How are you accounting for things you did not think of?
OpenAI:
Our evaluations will thus include tests against these enhanced models to ensure we are testing against the “worst case” scenario we know of.
We want to ensure our understanding of pre-mitigation risk takes into account a model that is “worst known case” (i.e., specifically tailored) for the given domain.
Google DeepMind:
CCLs can be determined by identifying and analyzing the main foreseeable paths through which a model could cause severe harm.
“We have addressed all the important pathways to catastrophe” is a strong claim that’s worth a lot if true, but it is not supported by the evidence the labs present.
“We have addressed all the pathways we know of” is a weaker, somewhat more defensible claim. It is also clearly insufficient in the face of powerful optimization pressure whose workings are poorly understood. It leaves vulnerabilities whose size scales with the gaps in our understanding of AI systems—gaps which, in the machine learning paradigm, are vast.
When dealing with a system that has been strongly optimized to exploit edge cases, such as in the field of cybersecurity, covering 99% of your threat surface can translate into a 1% rate of successful defense. An adequate set of risk management practices would take this into account.
Several frameworks repeatedly emphasize identifying risks instead of estimating total risk. The distinction is subtle, but important.
Anthropic:
Threat model mapping: For each capability threshold, make a compelling case that we have mapped out the most likely and consequential threat models: combinations of actors (if relevant), attack pathways, model capability bottlenecks, and types of harms. We also make a compelling case that there does not exist a threat model that we are not evaluating that represents a substantial amount of risk.[8]
OpenAI:
The initial set of Tracked Risk Categories stems from an effort to identify the minimal set of “tripwires" required for the emergence of any catastrophic risk scenario we could reasonably envision.
Google DeepMind:
CCLs can be determined by identifying and analyzing the main foreseeable paths through which a model could cause severe harm, and then defining the CCLs as the minimal set of capabilities a model must possess to do so.
Meta:
We have identified the key capabilities that would enable the threat actor to realize a threat scenario.
It also drives us to focus on approaches that adequately mitigate any significant risks that we identify…
Individual, discrete, readily identifiable risks do not constitute the whole of a risk landscape. It is not enough to make a list of foreseeable risks and guard against them, even assuming you guard successfully. You must also establish a process by which the total risk may be accounted for, even while parts of it remain opaque; and you must enable that process to influence your decisions at every organizational level. When it is too dangerous to continue, your institution must have the discipline to stop.
Finally, none of the frameworks make provisions for putting probabilities on anything. The framework itself needn’t include the hard numbers—indeed, such numbers might best be continually updated—but a risk management framework should point to a process that outputs well-calibrated risk estimates for known and unknown pathways before and after mitigation. None of these companies’ frameworks do.
To open one’s mouth and remove all doubt
One may object that if the labs gave actual numbers that justify scaling, people would claim their numbers were wrong. That is, to some extent, the whole point. Current frameworks do not even attempt to quantify the cost-benefit analysis that some claim justifies their continued scaling efforts. They smuggle in, or outright assert, the (clearly false) assumption that any risk their framework does not address is low enough to be justifiably omitted.
Both sound engineering and established risk management practices demand that you put a number on your uncertainty, even if that number is itself a guess.[9] Then update it as your understanding improves. Mature industries who consistently face hard technical challenges, including NASA, frequently publish both their estimates of the numerical likelihood of catastrophic failure and the thresholds that would prompt a decision to halt.
A risk assessment should provide a complete reflection of our current understanding of the risk landscape, including uncertainty and gaps. Where our current understanding is poor, the assessment will contain high uncertainty. This would not reflect poor risk assessment, but principled risk assessment in the presence of poor understanding.
AI labs have failed to demonstrate a robust risk management regime.
Poor incentives worsen these gaps
The labs’ safety frameworks mostly fail to meet the basic prerequisites for principled risk management. We suspect these failures are not coincidental.
Compounding their lack of sound risk management strategies, AI labs are strongly incentivized to downplay the risks their work incurs. We expect that an honest and well-calibrated assessment of total risk would expose the recklessness of continued scaling, discouraging investment and motivating policymakers to question the wisdom of allowing frontier AI labs to exist at all. Thus labs are under intense competitive pressure to avoid honest and well-calibrated assessments in plausibly deniable ways.
This pressure manifests differently at different labs; we’ve seen motivated excuses, the exodus of the most concerned, and even outright denial.
It is not, by our reckoning, a coincidence that lab frameworks fail to publicly quantify their uncertainty. It is not a coincidence that they make questionable assumptions about their ability to conjure working safeguards for complex, agentic systems in a matter of months or years. It is not a coincidence that their assessments of capability thresholds rely on evaluations widely known to leave gaps. It is not a coincidence that they omit discussion of scenarios in which their safeguards silently fail.
These are decisions made by people under intense pressure, often lacking important relevant skills. We can only guess what specific mixture of honest mistakes, habitual practices, motivated reasoning, cynical craft, or other causes was responsible for the gaps we have observed, but the gaps are damning nonetheless.
Towards more responsible risk management communication
The principled thing to do in this situation, assuming a good-faith attempt to build an accurate world-model and communicate clearly and transparently about it, is to attempt to capture the entire risk landscape, including at minimum:
An estimate of the total risk you expect to be incurring;[10]
An estimate of the reliability of your proposed mitigations;[11]
The relative likelihoods of false positives and false negatives in testing, and the tradeoff you’re willing to make between them;[12]
The amount of residual risk from your own efforts that you’re willing to accept;[13] and
- An explanation of how you arrived at each of these numbers.
If you’re doing cost-benefit analysis, then you would also include an estimate of the likelihood and magnitude of the primary upsides for your AI research.
To be clear, we do not predict that engineers at AI labs can actually come up with mitigations that would be adequate against a misaligned superintelligence, nor do we expect them to produce an aligned superintelligence in the absence of a plan vastly more precise and conservative than current plans.
However, these expectations would be reflected in the estimates of baseline total risk (high) and reliability of mitigations (low), and disagreements could be more productively pursued if labs made numerical estimates in public—or at least in closed sessions with auditors and regulators who have the skill to recognize inadequacies and the power to halt dangerous research until they are addressed.
In any case, based on the modeled risk, you should either deem it unwise to proceed and actually stop, or state explicitly why you think it is worth continuing on net.
Conclusion
Robust risk management practices typically arise in new industries after decades of trial and error. The relevant expertise is uncommon in emerging fields like AI. It’s difficult to hire or train the necessary engineering talent in a new context, and knowledge transfer is often slow. Mandating sound practices—even when those practices are extremely important for safety—imposes real friction on innovation.
Society tolerated mass-produced automobiles more than fifty years before the invention of the three-point seat belt, at great cost; it took even longer before this lifesaving measure was widely adopted. While often tragic and unnecessary, society can afford to tolerate such gaps when the possible tragedies are bounded. Car crashes can kill and maim an awful lot of people, but we don’t expect them to put an end to human civilization. In contrast, the upper bound on the risk from frontier AI research is the extinction of all life on Earth.
We believe the likelihood of extinction-grade disasters from frontier research is very high. However, one does not have to share this view in order to notice the weaknesses in current approaches. Less extreme concerns about less extreme catastrophes would suffice. The labs do not display an understanding of risk adequate to the task they are undertaking. They lack the deep institutional tools that enable mature industries to navigate treacherous problems safely: analytical rigor, respect for uncertainty, the discipline to stop.
It may transpire that, for a few more years, the tragedies will remain bounded. If we are so lucky, however, it will not be primarily due to the efforts of frontier labs to manage the danger from their research. We expect the gaps in their understanding to widen over time, and we expect that some of the scenarios they dismiss as edge cases will become increasingly likely.
With artificial superintelligence, “we address almost all catastrophic threats” is a loss condition. The bar for adequacy is to prevent any errors of this kind, globally and indefinitely.
If the AI industry cannot even meet the standards set by mature industries working with relatively safe technologies, it is clearly not equipped to proceed safely with frontier AI development.
Appendix - Other Frameworks
OpenAI’s Preparedness Framework
First, a positive note: We appreciate OpenAI’s acknowledgement of the need to address unknown unknowns. Several frameworks do not explicitly say this.
Seeking out unknown-unknowns. We will continually run a process for identification and analysis (as well as tracking) of currently unknown categories of catastrophic risk as they emerge.
Their proposed methods, however, leave dangerous gaps. A close reading of the statement above highlights some of these gaps. While it is important to move risks from “unknown unknown” into “known unknown” by identification and tracking, a robust framework attempts to guard against such categories while they are not yet identified. It is not enough to analyze and track entire categories of risk “as they emerge”; one must have a method in place that will robustly prevent catastrophe, and that method must guard against unknown unknowns before they emerge. A scorpion can kill an explorer before they even know scorpions exist.[14]
Here and elsewhere, OpenAI’s statements fail to demonstrate a principled understanding of risk management.
We believe the scientific study of catastrophic risks from AI has fallen far short of where we need to be.
Scientific inquiries into artificial intelligence have indeed failed to prepare us for the possibility of superintelligence, but the implication here is that more study could close the gap. This misses an important point: how can we expect empirical work to bound possibilities emerging from the systems of tomorrow?
Empirical work with current systems and techniques gives us very little ability to predict which emergent phenomena we’ll see from substantially smarter systems, nor do they offer sufficient mitigation mechanisms. Some qualitative predictions are possible (e.g., instrumental convergence), but many theoretical and empirical findings in this field are not adequately addressed by the framework.
While something like the steps outlined in the Preparedness Framework will increase our understanding as time moves on, it will mostly increase our understanding of the past. The future is guaranteed to hold surprises. A better framework would recognize that no comprehensive account of near-term development risk is coming and highlight the importance of developing mechanisms to reduce risk while our understanding remains poor.
Regarding evaluation protocols, OpenAI says this:
We will be running these evaluations continually, i.e., as often as needed to catch any non-trivial capability change, including before, during, and after training. This would include whenever there is a >2x effective compute increase or major algorithmic breakthrough.
As yet, nobody knows how often it’s necessary to run evals in order to track any ‘non-trivial capability change’. OpenAI assumes away the chance of a sudden jump in capabilities between rounds of evals. The apparent plan is to hope that a 1.5x scale-up can never cross any threshold that unexpectedly unlocks dangerous downstream capabilities. They cannot know that they are running evals frequently enough.
OpenAI also assumes the tests adequately elicit all relevant capabilities. This assumption is widely known to be unjustified. They likewise cannot know that any given eval adequately captures the key capabilities of their newest model at any stage of training.
Any assurances downstream of either assumption are suspect.
Tests and evaluations are a useful tool, but they are not reliable enough to form the sole basis for post-mitigation risk estimates. No developer of evals claims they perfectly reflect capabilities, and it’s a major oversight to rely on evals in this way without explicitly acknowledging their porousness and taking further measures to compensate.
What is the process for quantifying the likelihood that evals miss a dangerous capability, or the likelihood that mitigations fail? What is the process for estimating the residual risk? What is the amount of residual risk that OpenAI is willing to accept on humanity’s behalf?
Evals are liable to produce both false positives and false negatives. In the case of false positives, OpenAI gives itself permission to investigate further and overrule their own evaluations. They have no means to even detect false negatives. In the absence of such means, they ought to make highly conservative downstream decisions.
OpenAI’s framework notionally includes a commitment to halt development:
Only models with a post-mitigation score of "medium" or below can be deployed, and only models with a post-mitigation score of "high" or below can be developed further.
However, this commitment comes with enough caveats and qualifiers to render it effectively toothless. OpenAI explicitly allows continued development of models they themselves rate as posing a “high” risk to society after mitigations. For reference, OpenAI’s definition of “high risk level” includes capabilities for automated cyberattacks on hardened targets and enabling “anyone with basic training in a relevant field to…create a CBRN threat”.
When we ask what residual risk a company is willing to accept, this is an example (though it is still qualitative rather than quantitative). Including a statement outlining acceptable risk is better than silence, but the risk they are willing to accept is far too high.
The highest risk level, “critical”, includes “zero-day exploits of all severity levels, across all software projects”, fully autonomous self-replication, and fully automated creation of novel CBRN threats. OpenAI says they will restrict development of models that they predict will reach this level absent mitigations. Except:
Note that this should not preclude safety-enhancing development. We would also focus our efforts as a company towards solving these safety challenges and only continue with capabilities-enhancing development if we can reasonably assure ourselves (via the operationalization processes) that it is safe to do so.
In other words, OpenAI explicitly permits itself to continue development of critical risk systems, so long as this development is something that OpenAI believes to be safety-enhancing, or they can reassure themselves that it is safe.
What might OpenAI consider “safety-enhancing”? We cannot be sure, but they have said in the past that their main approach to aligning AI systems with human values is reinforcement learning from human feedback (RLHF). If RLHF may qualify as “safety-enhancing” in OpenAI’s view, then it’s not clear what training methods this commitment rules out.
Calling this a commitment to halt development is a stretch. It seems to be a commitment to be a little more careful in development, but even this commitment seems vague and lacking in teeth.
Based on their behavior, and the contents of the Preparedness Framework, OpenAI does not appear to be making decisions sufficiently conservatively. Far from the series of conservative commitments it’s advertised as, this Framework is more of a ceiling that says “This is the most cautious you can expect us to be.”
Google DeepMind’s Frontier Safety Framework + AI Principles Page
Note: This analysis does not address the recently-released An Approach to Technical AGI Safety and Security. The new document does not appear to resolve the fundamental flaws in DeepMind’s approach, but it does make some of DeepMind’s assumptions more explicit in ways we find valuable.
We want to highlight two important things we think DeepMind gets right: They devote a section in their framework to deceptive alignment, one of the core scenarios that could lead to catastrophic outcomes; and they propose chain-of-thought monitoring as an explicit mitigation strategy, while also acknowledging that there are situations in which it may fail. These approaches leave enormous gaps, but they are welcome additions to the overall plan.
The introduction to DeepMind’s framework cites their AI Principles, in which DeepMind says:
We identify and assess AI risks through research, external expert input, and red teaming.
Identifying and assessing individual risks is indeed an important part of risk management. It is not, however, enough.
The subset of risks that can be concretely described will be neither complete nor a representative sample of all risks. Neither here nor in their framework does DeepMind acknowledge this. They make no mention of the need for a thorough mapping of the risk landscape, including an estimate of the impact of important gaps and uncertainties. A fit-for-purpose framework should make this necessity clear.
Regarding deceptive alignment:
At present, the Framework primarily addresses misuse risk, but we also include an exploratory section addressing deceptive alignment risk, focusing on capability levels at which such risks may begin to arise.
The addition of deceptive alignment to DeepMind’s framework is a step in the right direction. Many more steps are needed.
Deceptive alignment has already been demonstrated in current models. This capability threshold has been passed, and it should be assumed that any model that is more generally competent than Claude 3 Opus may demonstrate this behavior. This includes DeepMind’s own frontier models.
One could argue that the models are unlikely to exhibit this behavior, or to succeed in the attempt at deception, but this is not what DeepMind says. Like Anthropic, DeepMind frames their work around what the models can do.
The Framework is built around capability thresholds called “Critical Capability Levels.” These are capability levels at which, absent mitigation measures, AI models or systems may pose heightened risk of severe harm. CCLs can be determined by identifying and analyzing the main foreseeable paths through which a model could cause severe harm, and then defining the CCLs as the minimal set of capabilities a model must possess to do so.
Note the emphasis on “foreseeable paths.” In cases where a seemingly innocent capability enables harm by any path the DeepMind researchers do not foresee (such as when chain-of-thought prompting unlocked new capabilities in models previously thought to lack them), CCLs may fail at their primary task.
Further, there may be no “minimal set of capabilities a model must possess to [cause severe harm].” For any particular harm, there may be multiple non-overlapping capabilities that would each be sufficient on their own. For instance, any one of:
- Sufficiently high tacit knowledge of biology
- Sufficiently high ability to learn arbitrary skills
- Sufficiently good long-term planning, execution, and delegation
…would be sufficient to enable the development of engineered pathogens. This is not an exhaustive list, and indeed an exhaustive list may not be possible.
There is no good way to construct knowably comprehensive early warning evaluations. You can make a list of likely pathways to harm, but can’t guarantee it’s exhaustive. You can make a list of harmful outcomes, but can’t guarantee that you’ve captured all possible paths to each. By itself, this approach is insufficient.
DeepMind seems to be saying: We will make a list of all of the capability thresholds we can think of that might enable catastrophic harm. When a model seems to have crossed some number of thresholds, we will attempt to apply mitigations to eliminate the threats those specific capabilities pose (for example, by targeted unlearning or refusals).
Setting aside, for now, the fact that no safeguards yet devised have survived an encounter with the likes of well-known jailbreaker Pliny the Prompter—what about the thresholds DeepMind didn’t think of?
That is: models are general reasoners. Capability increases are correlated. If a model crosses one or more apparent thresholds for dangerous capabilities, it is plausible that the model also crossed one or more thresholds which are not apparent and not on DeepMind’s list. Mitigations applied to each identified capability, even if they work, may not extend to unaddressed capabilities.
DeepMind identifies three “high-risk domains” in the misuse category. The first two — Chemical, Biological, Radiological, and Nuclear (CBRN) and Cyber — are fairly standard. The third is Machine Learning R&D, which they define as:
Risks of the misuse of models capable of accelerating the rate of AI progress to potentially destabilizing levels, the result of which could be the unsafe attainment or proliferation of other powerful AI models.
The assumption appears to be that someone else might use models capable of accelerating AI research to…accelerate AI research, resulting in powerful and dangerous AI. Later in the framework, they elaborate that:
This could be catastrophic if there is no effective way of defending against rapidly improving and potentially superhuman AI systems wielded by threat actors.
This is not the primary mechanism by which automated AI research becomes a catastrophic threat. The primary mechanism is that the labs currently pushing the frontier cause the “unsafe attainment or proliferation of… powerful AI models” that no one can wield at all. This capability does not belong under “misuse”, as even the most ironclad deployment and security safeguards are inadequate to guard against it. The problem lies in the mistaken assumption that, as long as the models are only “used” internally, everything is under control.
What does DeepMind have to say about the primary concern?
For deceptive alignment risk, the initial approach focuses on detecting when models might develop a baseline instrumental reasoning ability at which they have the potential to undermine human control, assuming no additional mitigations were applied. The two instrumental reasoning CCLs thus focus on delineating when such capability becomes present, and subsequently when the initial mitigation for this capability—automated monitoring—is no longer adequate.
Here is the full table:

Firstly, it would seem current models may already meet IR 1, since the model that was shown to deliberately fake alignment has already been eclipsed in reasoning capability by systems at least on par with Google’s own Gemini models.
Secondly, DeepMind proposes exactly one mitigation strategy: automated monitoring of an AI’s chain-of-thought. We assume they specify “automated” monitoring because (a) it would take too long for humans to do the monitoring themselves and (b) the most capable frontier models will probably think in latent vectors instead of human language.
What system will monitor DeepMind’s most capable frontier model? We see two options:
- A less sophisticated, but perhaps more specialized AI; or
- An instance of the monitored model itself.
Neither of these are robust against a moderately clever thinker. The first is vulnerable to outwitting by more powerful models, and the second is vulnerable to collusion. These problems may be loosely patched, but no robust solution yet exists.
Let us assume for the sake of argument that DeepMind can robustly know that automated monitoring is in fact sufficient for catching IR Level 1 models. On what basis is DeepMind confident that they will know when Level 1 progresses to Level 2? What is their probability that they will fail to realize when automated monitoring becomes insufficient?
By DeepMind’s Level 1 definition: You have a model that you have reason to believe is smart enough to subvert you, cunning enough to do so quietly, and complex enough that monitoring and/or interpreting its scratchpad requires dedicated software. What automated monitoring scheme is so effective under these circumstances that you can rule out the possibility that it fails?
Thirdly, explicit instrumental reasoning—of the sort high-level chain-of-thought monitoring might catch—is not the only way for a misaligned model to look aligned, or to possess a form of alignment that fails to generalize as its capabilities expand. As an overly-simplified example, a high-level chain-of-thought thread might call “subroutines” (like one which determines the exact phrasing of human-legible output language) which implement plans shaped like deception without the higher-level AI deliberately choosing to deceive. A post on deep deceptiveness [LW · GW] explores this problem more thoroughly.
This is a hard problem! We do not expect DeepMind to solve it in a few paragraphs in their high-level framework. We do, however, expect them to acknowledge the existence of this and other gaps in their plan, and to make some attempt to explicitly quantify and address the corresponding risk.
Other questions this framework does not answer:
- Merely detecting deceptive thought may not be enough. What actions will be taken in response to a warning flag, and how quickly?
- What is a “high-stakes deployment”?
- What is the monitoring plan for all other deployments? For training and fine-tuning? Is DeepMind assuming that no model ever attempts to subvert control or exfiltrate itself outside of a specific, narrow, enumerated list of deployment contexts? If so, on what basis?
- Any monitoring regime will need to trade off a rate of false positives against a rate of false negatives. What does DeepMind consider an acceptable balance?
Here and elsewhere, DeepMind’s case is hurt by the failure to assign numerical probabilities. Perhaps they meant “we cannot rule out” to reference some specific confidence level rather than “literally zero chance”. If true, this is easily clarified.
DeepMind seems to understand the value of estimating probabilities in other contexts:
We intend to evaluate our most powerful frontier models regularly to check whether their AI capabilities are approaching a CCL. We also intend to evaluate any of these models that could indicate an exceptional increase in capabilities over previous models, and where appropriate, assess the likelihood of such capabilities and risks before and during training.
DeepMind deserves credit for resolving to “assess the likelihood of such capabilities and risks before and during training.” It is extremely important to acknowledge that models can pose catastrophic risks before they are deployed. There seems to be some ambiguity in exactly what DeepMind means, here, but on the whole we are glad to see it in the framework.
Their approach, however, shares the same crippling dependence on the assumed robustness of evals as the approaches of other developers.
The most dangerous capabilities include those which, like deceptive alignment, are especially difficult to elicit or predict in any given model. Just as we expect AlphaGo to find ways to outplay us that we would not foresee, we expect powerful frontier models to find ways to cause severe harm that we do not foresee.
To do so, we will define a set of evaluations called “early warning evaluations,” with a specific “alert threshold” that flags when a CCL may be reached before the evaluations are run again.
DeepMind clearly intends their evaluations to flag model capabilities before they reach a new CCL. However, they make no allowance for false negatives; they implicitly assume, here and elsewhere in the framework, that they will see a flag before any CCL is crossed.
At the risk of repeating ourselves, this assumption is widely known to be unjustified, and any downstream assurances are suspect.
In our evaluations, we seek to equip the model with appropriate scaffolding and other augmentations to make it more likely that we are also assessing the capabilities of systems that will likely be produced with the model.
This is both admirably honest and clearly inadequate. No leading lab can reasonably claim to have assessed the most capable systems that will be produced by their models. Fine-tuning and scaffolding techniques developed later can empower models in unpredictable ways.
Note the phrase “will likely be produced”. What about capabilities unlikely to be produced, but whose emergence could have catastrophic consequences? What gaps is DeepMind comfortable leaving at the “unlikely but extremely dangerous” end of the capability-likelihood frontier?
A model flagged by an alert threshold may be assessed to pose risks for which readily available mitigations (including but not limited to those described below) may not be sufficient.
We see two unaddressed points of failure here:
- A model possesses the dangerous capability, but is not flagged.
- A flagged model poses risks for which “readily available mitigations” are insufficient, but the assessment misses this fact.
If DeepMind considers these developments unlikely, they should state either a probability estimate or an upper bound on the probability, and explain how they arrived at that number.
If this happens, the response plan may involve putting deployment or further development on hold until adequate mitigations can be applied.
Putting development on hold is the correct response to a sign that proceeding could have catastrophic consequences. Note, however, that the word “may” explicitly leaves open the option that DeepMind continues both development and deployment while considering their current mitigations inadequate. This is an alarmingly toothless commitment.
The appropriateness and efficacy of applied mitigations should be reviewed periodically…
And this is not a commitment at all.
DeepMind makes respectable strides towards sufficiently comprehensive risk management, even offering some marginal improvements over Anthropic’s RSP in some areas. Ultimately, however, DeepMind’s framework shares the same fundamental gaps as OpenAI’s and Anthropic’s, failing to adequately guard against the development of disastrous capabilities in frontier models.
The underlying assumption seems to be that, even with DeepMind’s limited understanding, there must be a way to push forward safely without radical changes to their approach.
Meta’s Frontier AI Framework
Meta has earned severe criticism for its practices, but we will begin with a positive highlight. Like OpenAI, Meta’s framework explicitly lays out conditions for a halt:
If a frontier AI is assessed to have reached the critical risk threshold and cannot be mitigated, we will stop development and implement the measures outlined in Table 1.
Like OpenAI, however, there are a number of important caveats to this commitment in practice. Firstly: what is the critical risk threshold? From Table 1:
The model would uniquely enable the execution of at least one of the threat scenarios that have been identified as potentially sufficient to produce a catastrophic outcome and that risk cannot be mitigated in the proposed deployment context.
Note the qualifiers. This is an approach that relies on specific identified scenarios, and not on any consideration of unknown unknowns.
How does Meta propose to identify qualifying scenarios?
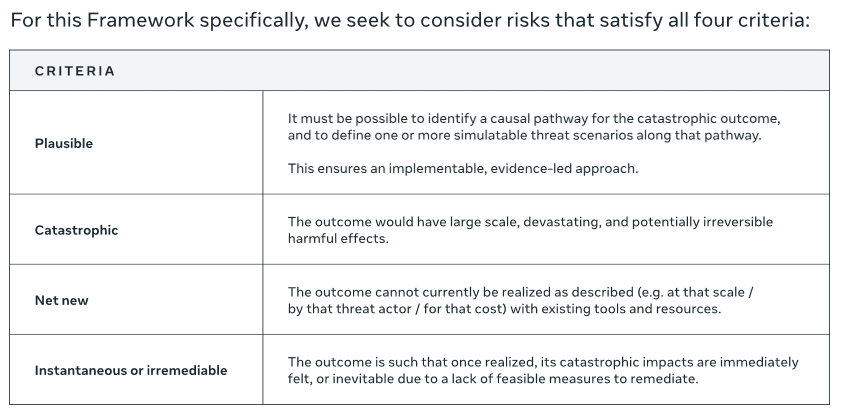
Let’s zoom in on “Plausible”.
It must be possible to identify a causal pathway for the catastrophic outcome, and to define one or more simulatable threat scenarios along that pathway. This ensures an implementable, evidence-led approach.
Putting these together, Meta appears to be saying that, unless they can concretely trace how a model’s deployment (not training!) will lead to catastrophe—and unless they can define and “simulate” the scenario that causes harm—it does not warrant consideration.
“We did not identify a causal pathway for this harm” does not imply “no causal pathway exists.” With this statement, Meta has virtually guaranteed the inadequacy of any risk assessment they perform.
Some versions of this approach might have a place as load-bearing components of a responsible risk management framework. Attempting to find a causal pathway from X to Y and failing is some evidence that none exists, or that X is unlikely to cause Y.
But this is not how Meta’s framework operates. They categorically omit from consideration any scenarios that they are not able to explicitly anticipate. This would be a dangerously blinkered basis for a risk assessment in a modern industry with a merely ordinary risk profile; in a context that could involve an intelligent adversary, let alone a strategically superhuman actor, it is grossly inadequate.
Meta’s framework also includes many of the same errors as other frameworks—conflating estimated capabilities with actual capabilities, accounting for false positives but not false negatives, and failing to outline a process that generates probabilities. They largely fail to acknowledge the fact that safety-fine-tuning is easily removed, and that releasing a model’s weights effectively releases helpful-only and fine-tuned versions of that model as well.
The xAI Risk Management Framework
xAI released their draft risk management framework in February 2025:
This is the first draft iteration of xAI’s risk management framework that we expect to apply to future models not currently in development. We plan to release an updated version of this policy within three months.
Given its status as a soon-to-be-updated draft, we’ll focus here on whether the broad approach seems promising. We welcome xAI’s explicit acknowledgement that their current draft does not adequately address loss of control risks:
Our evaluation and mitigation plans for loss of control are not yet fully developed, and we intend to improve them in the future.
Unfortunately, the broad approach shares the common problem of over-reliance on an assumption that evaluations are robust. Note that “evaluation and mitigation” in the above is too narrow: evaluations can be inputs to risk estimates; they are not by themselves a sound basis for risk estimation.
Consideration is rightly given to the reliability and adequacy of benchmarks and evaluations:
We intend to regularly evaluate the adequacy and reliability of such benchmarks for both internal and external deployments, including by comparing them against other benchmarks that we could potentially utilize. We may revise this list of benchmarks periodically as relevant benchmarks for loss of control are created.
However, the most important case for risk is ignored: where benchmarks or evaluations seem adequate and reliable, but are not; i.e. where the evaluation process for adequacy and reliability fails. This framework is a good starting-point for the “If our tests cover everything important and are all working as intended…” case—but so far accounts for little else.
For an example of a potential failure[15] to cover everything important, consider the MASK benchmark description:
MASK is a benchmark to evaluate honesty in LLMs by comparing the model’s response when asked neutrally versus when pressured to lie.
Saying “evaluate honesty” sounds general. However, MASK is only directly doing something like “testing for dishonest behaviour on the MASK dataset, using MASK’s evaluation pipeline”. Describing this as “evaluate honesty” risks smuggling in a generalization assumption: concluding that we’ve demonstrated robust honesty, rather than failed to find dishonesty in some particular context. The latter is some evidence of robust honesty, but nothing like a guarantee.
One of the central tasks for a safety framework is to explicitly consider the contexts in which safety properties are likely to generalize, to evaluate evidence for robustness, and to attempt to quantify the remaining uncertainty and risk.
The concluding paragraph of the current draft illustrates the main point again:
Safeguards are adequate only if Grok’s performance on the relevant benchmarks is within stated thresholds. However, to ensure responsible deployment, risk management frameworks need to be continually adapted and updated as circumstances change.
The first sentence here is precise, correct, and guarantees essentially nothing. The statement “I can drive to London only if I have a car” is technically true,[16] but it does not imply that having a car means I can drive to London. There might be an ocean in the way.
If we instead assume the authors meant if and only if, then the statement is no longer true. Grok’s performance on benchmarks may suggest that safeguards might be adequate, but it is far from a guarantee.
The second sentence has at least two major problems. First, there’s no mention of responsible training or development. This is a common omission, as we’ve noted, but still a careless one. Second, it implies that the first sentence represents anything resembling responsible deployment, and that mere updates to the plan will be sufficient going forward. It doesn’t and they won’t; a complete overhaul is needed.
Given this fundamental limitation, the draft can’t be considered promising as a risk management framework. At best, it’s a promising component of a risk management framework.
- ^
Or alternatively, that their actions are net risk-reducing in the current environment.
- ^
We will not be addressing DeepMind’s much lengthier release, An Approach to Technical AGI Safety and Security, in this post. We don’t think it is sufficient, for many of the same reasons we give in this post. However, it does make some improvements, and the fact that it was published is laudable.
- ^
NASA uses a similar process.
- ^
For instance, their ASL-4 sketches post correctly highlights safety cases as “ideally a bound on the probability of catastrophe from training or deploying an AI system”.
- ^
Section 6.2 of their RSP discusses monitoring pretraining runs, but only in the context of comparing new models against a more capable model with dangerous capabilities that they will have already trained.
- ^
In reliability engineering, we sometimes see this as a distinction between “hidden” failures and “evident” failures, with each requiring a different set of mitigations and contingencies.
- ^
In these and other quoted segments, emphasis has been added for clarity.
- ^
Anthropic’s wording is much more careful than other labs’, but still leaves some gaps which we explore in the Appendix. In particular, they don’t say “we make a compelling case that in aggregate, the set of all threat models we are not evaluating do not represent a substantial amount of risk”.
- ^
It may seem difficult to account for unknown unknowns, but note that “We estimate a 5% chance of catastrophic outcomes through pathways we have not anticipated” would technically qualify. Even an order-of-magnitude guess is far more informative than a shrug: the practical implications of a 20% chance of disaster are very different from a 2% chance or a 0.2% chance.
- ^
Or, “What are the baseline chances our planned approach causes [catastrophic outcome]?” for any given program and one or more catastrophic outcomes.
- ^
Or, “How much does [specific mitigation, e.g., unlearning] reduce this risk?” for a given outcome.
- ^
Or, “What’s the chance [test or eval] fails to alert us to a capability threshold being reached? How low can we get this, and at what false positive rate?”
- ^
Or, “What’s the highest risk after applying all our mitigations at which we’d still decide to continue?”
- ^
Consider that older engineering designs are often built more robust than newer ones (thicker-walled pressure vessels, bridges with extra supports) since they predate advanced load calculations and engineers are accordingly conservative; yet these designs can still fail catastrophically in unexpected ways (brittle fracture, aeroelastic flutter).
- ^
We note that xAI specify MASK as an example benchmark, and do not claim that it is sufficient for any particular honesty guarantee. Here we’re pointing at the general gap between the property of interest and what a benchmark measures.
- ^
Yes, yes, it could be any vehicle.
- ^
Or alternatively, that their actions are net risk-reducing in the current environment.
- ^
We will not be addressing DeepMind’s much lengthier release, An Approach to Technical AGI Safety and Security, in this post. We don’t think it is sufficient, for many of the same reasons we give in this post. However, it does make some improvements, and the fact that it was published is laudable.
- ^
NASA uses a similar process.
- ^
For instance, their ASL-4 sketches post correctly highlights safety cases as “ideally a bound on the probability of catastrophe from training or deploying an AI system”.
- ^
Section 6.2 of their RSP discusses monitoring pretraining runs, but only in the context of comparing new models against a more capable model with dangerous capabilities that they will have already trained.
- ^
In reliability engineering, we sometimes see this as a distinction between “hidden” failures and “evident” failures, with each requiring a different set of mitigations and contingencies.
- ^
In these and other quoted segments, emphasis has been added for clarity.
- ^
Anthropic’s wording is much more careful than other labs’, but still leaves some gaps which we explore in the Appendix. In particular, they don’t say “we make a compelling case that in aggregate, the set of all threat models we are not evaluating do not represent a substantial amount of risk”.
- ^
It may seem difficult to account for unknown unknowns, but note that “We estimate a 5% chance of catastrophic outcomes through pathways we have not anticipated” would technically qualify. Even an order-of-magnitude guess is far more informative than a shrug: the practical implications of a 20% chance of disaster are very different from a 2% chance or a 0.2% chance.
- ^
Or, “What are the baseline chances our planned approach causes [catastrophic outcome]?” for any given program and one or more catastrophic outcomes.
- ^
Or, “How much does [specific mitigation, e.g., unlearning] reduce this risk?” for a given outcome.
- ^
Or, “What’s the chance [test or eval] fails to alert us to a capability threshold being reached? How low can we get this, and at what false positive rate?”
- ^
Or, “What’s the highest risk after applying all our mitigations at which we’d still decide to continue?”
- ^
Consider that older engineering designs are often built more robust than newer ones (thicker-walled pressure vessels, bridges with extra supports) since they predate advanced load calculations and engineers are accordingly conservative; yet these designs can still fail catastrophically in unexpected ways (brittle fracture, aeroelastic flutter).
- ^
We note that xAI specify MASK as an example benchmark, and do not claim that it is sufficient for any particular honesty guarantee. Here we’re pointing at the general gap between the property of interest and what a benchmark measures.
- ^
Yes, yes, it could be any vehicle.
1 comments
Comments sorted by top scores.
comment by MalcolmMcLeod · 2025-04-13T02:51:12.893Z · LW(p) · GW(p)
Righteous work. It would be impactful to take versions of this to mainstream media outlets: TIME and Vox have obviously proven receptive, but Bloomberg and the FT aren't deaf to the issues either. Anyone, really. The more distribution the better. Grateful to y'all for saying this out loud and clearly. To folks unfamiliar with the difficulty of alignment, you make nonobvious yet clarifying points.