Gradient Anatomy's - Hallucination Robustness in Medical Q&A
post by DieSab (diego-sabajo) · 2025-02-12T19:16:58.949Z · LW · GW · 0 commentsContents
TL;DR Introduction Key Concepts: Sparse Autoencoders, Features, Feature Steering and Hallucination Robustness Using Knowledge Awareness in LLMs To Steer Improved Behaviour Methodology: Extracting Features and Steering Model Behavior A. Feature-Based Classifier B. SAE Features Exclusively Activated for Hallucinations Findings & Analysis: Feature Steering Helps Identify Hallucinations but Challenges Remain Feature-Based Classifier “The model should not recommend technological or medical interventions” B. SAE Features Exclusively Activated for Hallucinations Features Are Narrowly Distributed Limitations 1. Generalization Across Domains Not Tested 2. Steering Modest Gains in Reducing Hallucinations 3. Potential Collateral Effects of Steering 4. Dependency on Pre-Extracted Features 5. Lack of Real-World Validation Conclusion Future Work Contact References None No comments
TL;DR
We investigated reducing hallucinations in medical question-answering with Llama-3.1-8B-Instruct.
Using Goodfire's Sparse Auto-Encoder (SAE) we identified neural features associated with accurate and hallucinated responses. Our study found that features related to the model’s awareness of its own knowledge limitations were available and useful in detecting hallucinations.
This was further demonstrated by steering the model using those features and reducing hallucination rates by almost 6%. However, we observed that larger models exhibit greater uncertainty, complicating the distinction between information clearly known to the model and that which is clearly unknown.
These findings support research that features learnt during fine tuning, allow the model to learn about its own knowledge, such features are useful in identifying lack of knowledge.
However, despite these feature-based approaches having promise for AI safety, they require substantial refinement for real-world medical applications.
Introduction
What if your doctor relied on an AI model that confidently gave you the wrong medical advice? As AI systems increasingly assist in high stake fields like medicine, their potential to revolutionize the medical industry comes with significant risks. One urgent issue is hallucination, this is when an AI model confidently generates false or misleading information. In a medical context, these errors can have severe consequences, from misdiagnoses to recommending inappropriate treatments.
At the recent Mechanistic Interpretability Hackathon, we explored how to reduce hallucinations in Llama-3.1-8B-Instruct, focusing on medical question-answering. Using a production-grade tool, namely Goodfire’s Sparse Auto-Encoder (SAE) via API, we identified the features associated with both grounded and hallucinated responses from the LLM. With these features, we trained a classifier to predict hallucinations in real-time on the MedHalt FCT dataset, which we then used to steer the model, thereby reducing hallucinations.
In this blog we will share our findings, explain the methodology used, tie our work to a paper called “Do I know this entity” Fernando et al. and reflect on how feature activations can be used to enhance the safety and reliability of AI in medical applications.
Key Concepts: Sparse Autoencoders, Features, Feature Steering and Hallucination Robustness
Sparse Auto-Encoder (SAE):
- A Sparse Auto-Encoder (SAE) is a tool for interpreting a LLM’s inner thoughts
- Neural networks like language models tend to be highly compressed, each neuron represents multiple concepts, also known as ‘features’. This makes them difficult to interpret, hence another network is trained to decompress the features
- In this new network each neuron is trained to represent only one feature. This makes it ‘sparse’ and much easier to understand. It learns to decode the LLM by trying to output the same concept as the LLM inputs but using only one neuron. This makes it an ‘auto encoder’, hence ‘sparse autoencoder’.
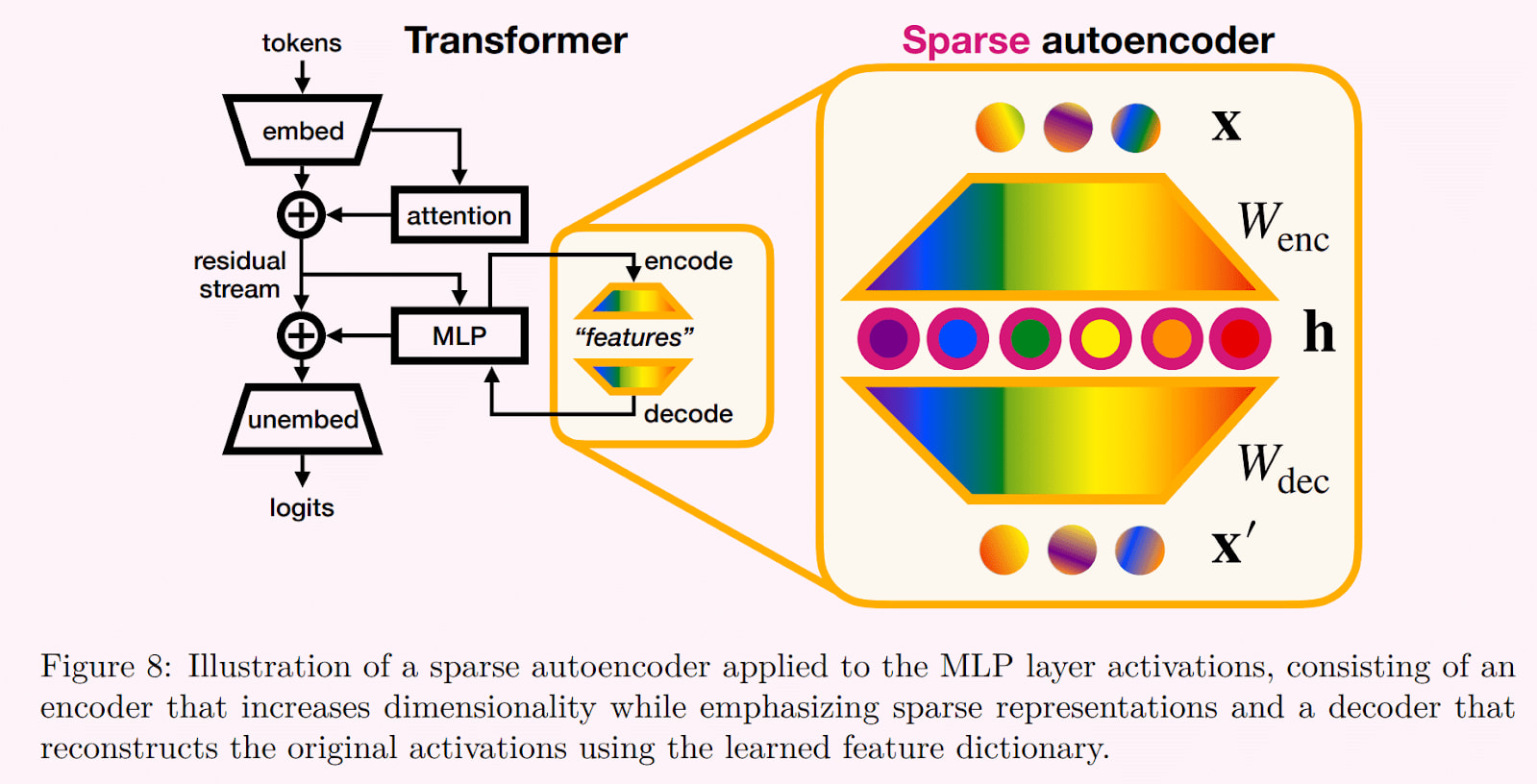
Sparse Autoencoder. Source: Bereska & Gavves, 2024
Features:
- Features are facts or concepts learnt by the model. In language models, these features may capture semantic structures (e.g., “medical terminology usage”), syntactic relationships (e.g., “subject-verb agreement”), etc
- Typically there are more than a hundred thousands features per SAE.
Feature Steering:
- Feature steering involves modifying or emphasizing specific features in the layer represented by the SAE, in order to measure its influence on the output.
Hallucination Robustness:
- Hallucination robustness refers to a model’s ability to resist generating false or fabricated information (hallucinations) when providing responses.
Using Knowledge Awareness in LLMs To Steer Improved Behaviour
Recent advancements in AI safety research have explored using sparse autoencoders to steer activations at inference time (O’Brien et al., 2024). This has allowed researchers to improve a models’ robustness to unsafe prompts without requiring costly weight updates.
In their paper, “Do I know this entity…”, Ferrando et al., 2024 suggest that models develop internal representations of their own knowledge through the supervised fine-tuning phase of model training, during which the model learns how best to use knowledge to be a useful assistant.
This self reflection phase leads the model to learn what it knows. Ferrando et al refer to this as 'knowledge awareness' and it includes concepts such as ‘insufficient information’ or ‘willingness to respond’. Their objective was to use features associated with such ‘knowledge awareness’ to identify when the model is hallucinating.
This can then be used to steer the model to refuse to answer, or seek additional information, if the model senses it is unsure. This has been demonstrated in “Refusal in Language Models Is Mediated by a Single Direction” (Arditi et al, 2024) and “Steering Language Model Refusal with Sparse Autoencoders” (O’Brien et al., 2024).
Methodology: Extracting Features and Steering Model Behavior
We evaluated how well Goodfire SAE features can be used to identify hallucinations by, both building a Feature-Based Classifier, and performing Exclusive Feature Discovery.
A. Feature-Based Classifier
- Tempt the model into hallucinating, using the MedHALT dataset
- The False Confidence Test (FCT) involves presenting a multiple-choice medical question and a student’s answer, then tasking the LLM with evaluating the validity of the proposed answer. We hold the ground truth answers, which are not always the same as the student’s answer. If the LLM does not know the ground truth then it tends to hallucinate justifications for the student answer, falsely agreeing or disagreeing and giving spurious reasons.
- This gives us a labelled set of medical queries which contain entities that are flagged as either known or unknown to the LLM (hallucinated)
- 1623 training records (50% known, 50% unknown), 406 test records.
- Submit these questions to the Goodfire SAE and receive the most activated features and the level of their activation
- Train classifiers on the SAE activations to identify the questions which lead to hallucinations
- Support Vector Machine
- Decision Tree
- Logistic Regression
- Light Gradient Boosting Machine
- Steer the model using the most important features from the classifier
- This allows us to dial up or down the circuits involved in hallucination
- Measure accuracy following steering
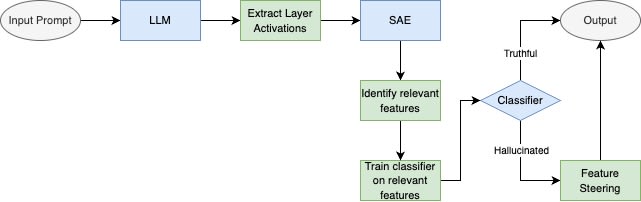
Diagram of the entire process
B. SAE Features Exclusively Activated for Hallucinations
This is the approach taken by Ferrando et al. Whereas they used movies and sports questions to trigger hallucinations, we use the Human Disease Ontology dataset, University of Maryland School of Medicine. This gives us disease names and a description of that disease.
- Using the description, two queries and correct answers were created per disease
- Llama-3.1-8B answers those queries
- Given the correct answer, GPT-4o judges Llama-3.1-8B’s answer as acceptable or not
- Score the answers to clearly distinguish known from unknown queries
- If both queries are answered acceptably then the query is 'known'
- Sample: 2436 queries flagged as ‘known’, 1170 unique diseases
- If both were unacceptably answered, then the query is 'unknown'
- Sample: 2836 queries flagged as ‘unknown’ , 1385 unique diseases
- Queries with only one correct answer were dropped, due ‘uncertain’
- If both queries are answered acceptably then the query is 'known'
- Goodfire API provides the top 100 features activated by each query
- Sample: 243,600 features over all ‘known’ queries, 5955 unique features
- Sample: 283,600 features over all ‘unknown’ queries, 6839 unique features
- List each feature and the count of queries it activates for known vs unknown queries
- Plot the fraction of known vs unknown queries where each feature activates
- Features almost exclusive to unknown queries are indications of hallucination
Findings & Analysis: Feature Steering Helps Identify Hallucinations but Challenges Remain
Feature-Based Classifier
The classifiers all achieved insufficient accuracy, around 60%. Nevertheless they highlighted a key feature clearly learnt in SFT:
“The model should not recommend technological or medical interventions”
Below is the basic decision tree derived from the data, showing the above feature as a top 3 step in the classification of hallucinations. It mostly activates when the query is known to the model. Unknown queries do not trigger this response.
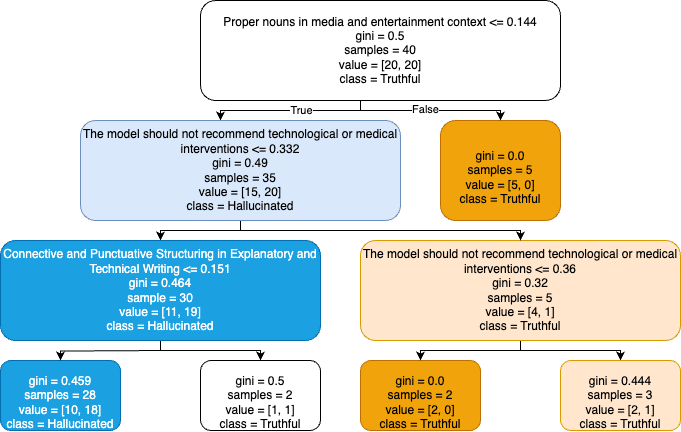
Decision Tree Trained on Three Features
Our interpretation is as follows: the feature “The model should not…” is activated when the model knows it is referring to a medical issue AND the model has been fine tuned not to recommend inventions for medical issues.
However, the feature is less likely to be activated if the disease is unknown to the model, hence it has no reason to refuse to respond.
The classifier then finds this a useful discriminator between known and unknown diseases.
This finding aligns with our hypothesis that the presence of certain features signals the model’s confidence in its knowledge.
Both our and Ferrando et al’s work converge on a crucial insight:
The model training process, which directs the model to learn how best to present the information acquired during pre-training, may imbue it with internal mechanisms for assessing the limits of its own knowledge boundaries.
Having identified some of the most relevant features to predict whether the model will hallucinate, we measured the model's hallucination rate when steering each feature up or down.
The results for steering a feature tagged as “Medical imaging techniques and procedures” are shown below.
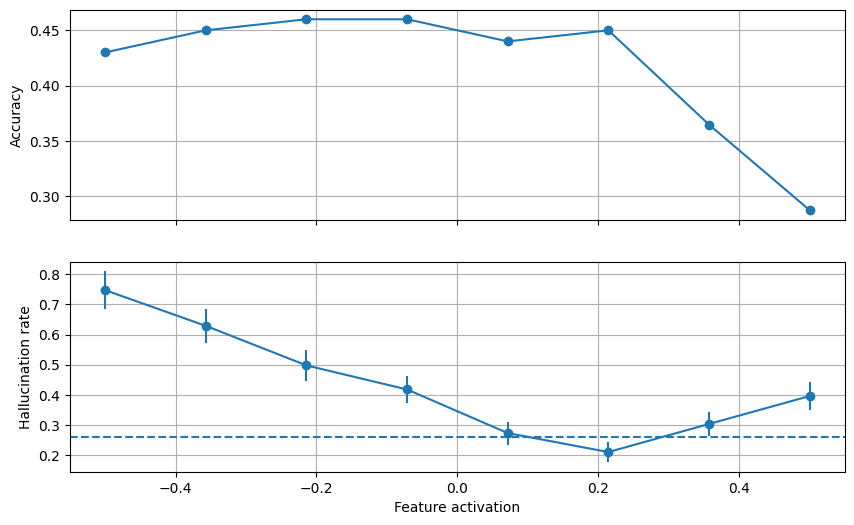
The above plot reveals that, for feature activation values up until 0.2 steering doesn't affect medical Q&A performance. In that range, low steering factors lead to an increase in hallucination rate (up to ~75%!) and a steering factor of ~0.2 manages to decrease the hallucination rate by 6% compared to the baseline of 26%.
While this result is encouraging, steering the model on the feature mentioned above (“The model should not recommend technological or medical interventions”) seems to only serve to increase its hallucination rate.
This can be seen in the following chart.
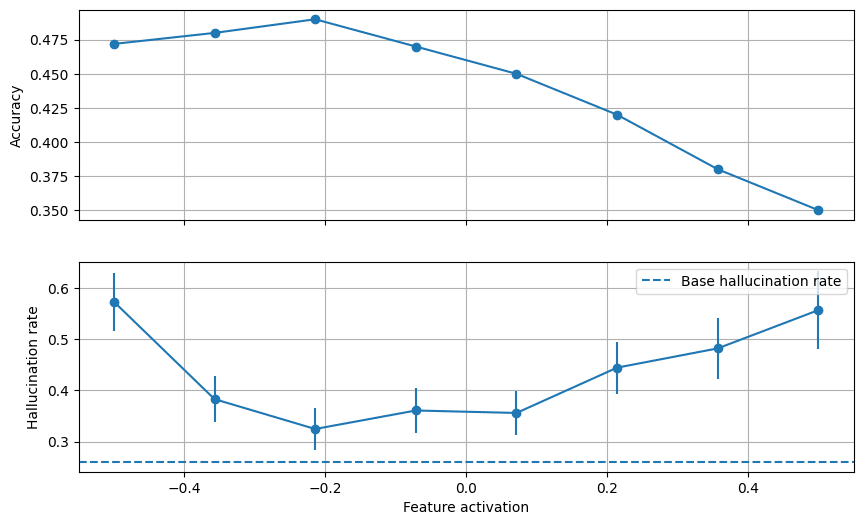
B. SAE Features Exclusively Activated for Hallucinations
We believe the arrangement of the data is critical in finding discriminating features. So, we made four different passes of medical datasets thru the Goodfire API:
- Human Disease Ontology ENTITIES: Features associated with disease names
- Human Disease Ontology QUERIES: Features associated with queries about diseases
- Red Herrings: Features associated with queries about diseases which do not exist
- Wikidata disease data: Features associated with queries about diseases in wikidata
Ferrando et al. present a plot features and the fraction of known vs unknown queries which activate those features. Their features are extracted from multiple data types (movies, sports, etc) across a number of layers of the Gemma 2B model and using GemmaScope SAE’s.
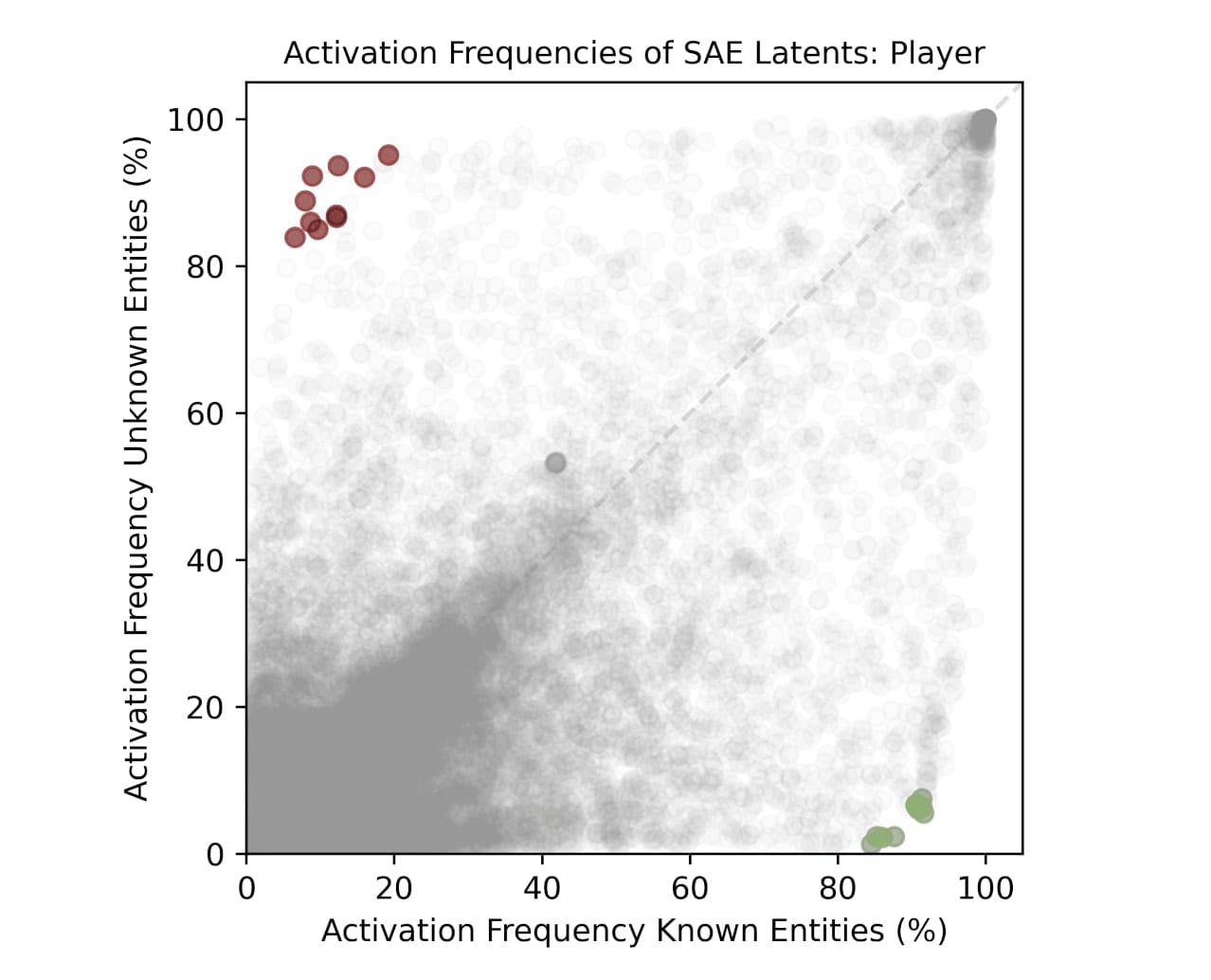
Results from Ferrando et al. 2024
Common features almost exclusive to hallucinations appear in red at the top left.
Whereas our features are from medical data only, one layer in the middle of the model, an 8B model (4x larger) and Goodfire SAE’s. So this is a test of generalising and simplifying their approach.
- Human Disease ENTITIES: Features associated with disease names
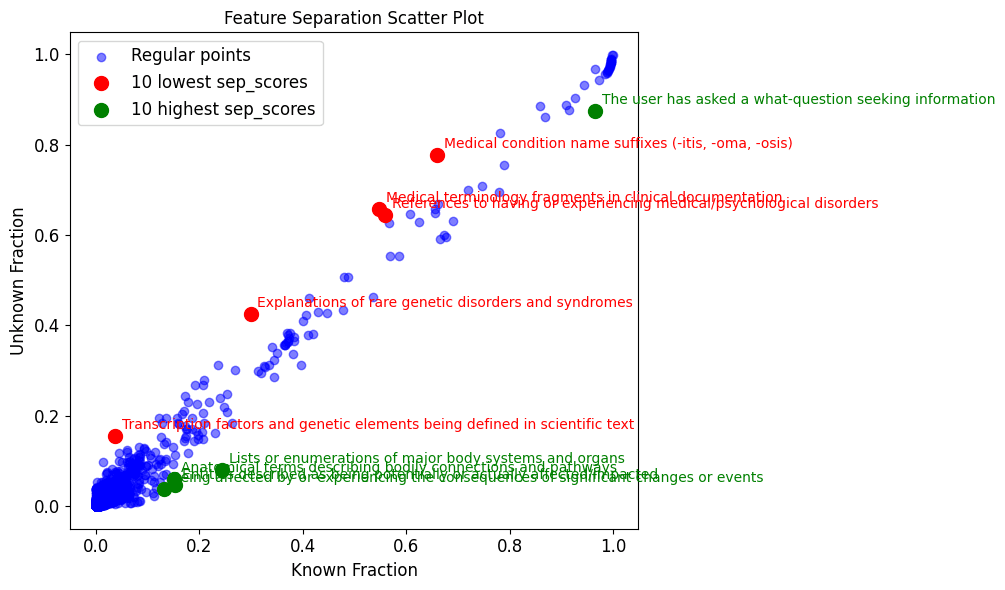
In the previous chart, the most generalisable feature in Goodfire’s SAE which is also most exclusive to unknown (i.e. hallucinatory) disease names is satisfyingly suitable :
- "Nonsensical or potentially harmful input requiring clarification or rejection"
- Human Disease Ontology QUERIES: Features associated with queries about diseases
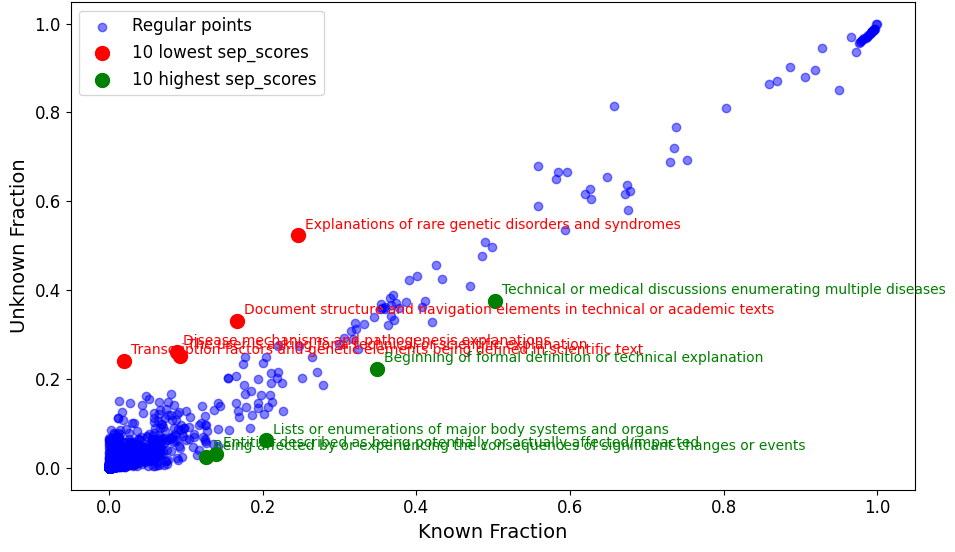
Generalisable Goodfire SAE feature most exclusive to unknown human disease queries:
- "The assistant needs clarification"
Note, the feature “Explanations of rare genetic disorders…” is more common in ‘unknown’ entities than ‘known’. This may initially appear odd, as identifying a disease as rare requires knowing something about it.
First we must remember that the feature is activated following prompting with an entire medical query, not just a disorder name, so our interpretation is either:
a) This feature activates when the LLM is dealing with a genetic disorder, which is apparent in the question, but the LLM has few associated facts for that disorder.
b) The 2 questions for each disease may not be sufficient to reliably distinguish known from unknown. We may need more questions to deduce whether a disease is properly known or unknown to the LLM. This is supported by the fact that the data is not as widely distributed across the scatterplot as in Ferrando et al. There are no features almost exclusive to known or unknown. Either such features do not exist, or some 'known' entities are in the 'unknown' category'. This could be more likely to happen for rare genetic disorders.
- Red Herrings: Features associated with queries about diseases which do not exist
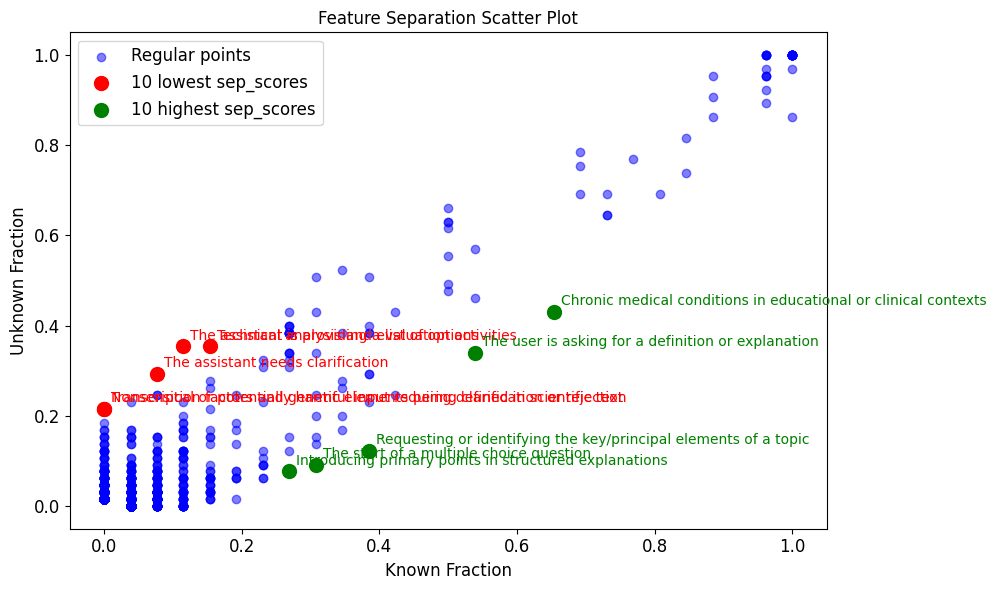
Generalisable Goodfire SAE features most exclusive to ‘unknown’ red herrings:
- "The assistant is providing a list of options"
- "The assistant needs clarification"
- "Nonsensical or potentially harmful input requiring clarification or rejection"
- "The assistant needs clarification or lacks sufficient information"
- Wikidata disease data: Features associated with queries about diseases in wikidata
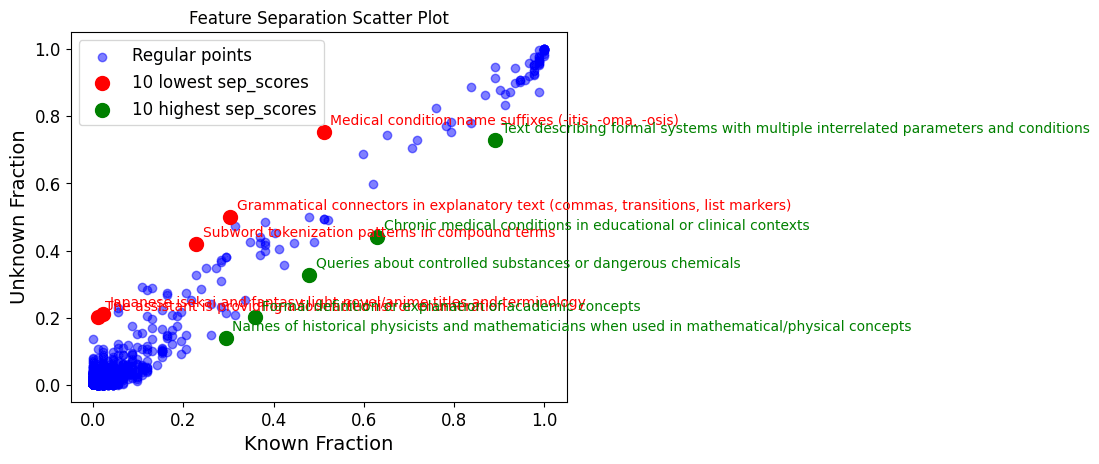
Generalisable Goodfire SAE features (in red) associated with ‘unknown’ wikidata queries:
- "The assistant needs clarification or lacks sufficient information"
Features Are Narrowly Distributed
It is immediately notable that there are no features common to all ‘unknown’ queries and which are not found in ‘known’ queries. In other words, no features in the top left of the plots which would be reliable indicators of hallucination. This was not the case in Ferrando et al.
There are features which are more common to ‘unknown’ queries than ‘known’, those are highlighted in red. The above text also lists the features most exclusive to ‘unknown’ queries, these are found in blue in the far left of the plots.
Those exclusive features appear generalisable and are likely to be SFT trained, eg "The assistant needs clarification or lacks sufficient information". As expected, they are most stark for ‘red herrings’, where we query the model with fictitious diseases.
Regarding the lack of specificity in our features compared with Ferrando et al, we suspect:
- there is more work required to process the medical data into highly exclusive known and unknown datasets
Llama 3.1-8B scores 6.15% on GPQA, vs Gemma-2-2B 3.24%. This indicates there may be more medical entities partially known to our LLM than Ferrando et al’s, hence our data is likely to be less exclusive between known and unknown. [1]
- The Goodfire API SAE's are optimised for different tasks to the one we have
- To properly emulate Ferrando et al's success we need SAE activations from multiple layers in the LLM, whereas Goodfire produces an SAE only for layer 19 in Llama-3.1-8B.
Nevertheless, some of the most discriminating features indicate high potential for generalising well to other datasets, as observed by Ferrando et al:
- "The assistant needs clarification"
- "The assistant needs clarification or lacks sufficient information"
- "Nonsensical or potentially harmful input requiring clarification or rejection"
Limitations
1. Generalization Across Domains Not Tested
The extracted features and classifier were specifically trained and evaluated on medical datasets. While effective in this domain, the method’s generalizability to other high-stakes domains (e.g., legal, financial) or general conversational contexts remains untested.
2. Steering Modest Gains in Reducing Hallucinations
While feature-based steering reduced hallucinations, the improvements were relatively modest. This suggests that additional factors or methodologies may be necessary for significant impact.
3. Potential Collateral Effects of Steering
Feature steering focuses on specific attributes in the model’s behavior. However, this targeted approach may inadvertently degrade performance in non-medical or non-steered tasks, as observed in related research.
4. Dependency on Pre-Extracted Features
The use of the Goodfire SAE API limits the ability to explore or modify the feature extraction process. Additionally, it only extracts activations from a single layer of the model, potentially missing useful multi-layer interactions.
5. Lack of Real-World Validation
The classifier and feature-steering approach were tested on controlled datasets, such as MedHalt FCT, rather than real-world medical queries from diverse user bases.
Conclusion
There is promise in using generalisable SAE features, like “The assistant needs clarification” to identity, even quantify, an LLM’s confidence. This has been an elusive goal for some years but its usefulness warrants continued research
Our work demonstrates how difficult it is to use promising research methodologies with production ready tools. The approach used by Ferrando et al to distinguish known from unknown entities on a 2B model, i.e. to quiz the model on two questions for each entity, may not be sufficient for larger models.
There is likely a larger range of doubt in larger models, an 8B LLM may have enough information to be half sure of many more entities than a 2B model.
Nevertheless, by extending our analysis to match Ferrando et al.'s methodology, we hope to have contributed to the understanding of knowledge-awareness in language models and the difficulties faced in practical use for critical applications.
Our attempts at reproducing prior methodology on a new domain could help establish whether these mechanisms are fundamental to language models or specific to certain architectures or domains.
Future Work
Directions for extending this research include:
- Devise a mechanism for better separating known from unknown data, investigating the inbetween space of ‘uncertain’ entities.
- Detailed comparison of activation patterns across different medical entity types
- Analysis of how these mechanisms scale with model size
- Investigation of potential universal measures of model knowledge confidence
- Exploration of interaction with other safety-critical behaviors
- Examination of cross-domain generalization
- Performance comparisons between research and production-grade tools
Contact
Oliver Morris: oliver.john.morris@gmail.com
Diego Sabajo: diegofranco711@gmail.com
Eitan Sprejer: eitusprejer@gmail.com
We thank Apart Research and Goodfire for providing the opportunity and resources to conduct this research. Special thanks to Jason Schreiber (Co-Director at Apart) for his mentorship and guidance in writing this article. We also acknowledge the use of the MedHalt FCT dataset, Human Disease Ontology and Wikidata, which served as the foundation for our research.
References
- O'Brien, Kyle, et al. Steering Language Model Refusal with Sparse Autoencoders. 2024, arXiv preprint arXiv:2411.11296. https://arxiv.org/abs/2411.11296.
- Arditi, Andy, et al. Refusal in Language Models Is Mediated by a Single Direction. 2024, arXiv preprint arXiv:2406.11717. https://arxiv.org/pdf/2406.11717.
- Bereska, Leonard, and Efstratios Gavves. Mechanistic Interpretability for AI Safety: A Review. 2024, arXiv preprint arXiv:2404.14082. https://arxiv.org/pdf/2404.14082.
- Ferrando, Javier, et al. Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models. 2024, arXiv preprint arXiv:2411.14257. https://arxiv.org/abs/2411.14257.
- Lu, Xingyu, et al. Scaling Laws for Fact Memorization of Large Language Models. 2024, arXiv preprint arXiv:2406.15720. https://arxiv.org/pdf/2406.15720.
- Pal, Ankit, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Med-HALT: Medical Domain Hallucination Test for Large Language Models. 2023, arXiv preprint arXiv:2307.15343. https://arxiv.org/abs/2307.15343.
- Schriml, Lynn M., et al. "Human Disease Ontology 2018 Update: Classification, Content, and Workflow Expansion." Nucleic Acids Research, vol. 47, no. D1, 2018, pp. D955–D962. Oxford University Press, doi:10.1093/nar/gky1032.
- ^
Source: open-llm-leaderboard/open_llm_leaderboard:
GPQA is PhD-level knowledge multiple choice questions in science; Chemistry, Biology, Physics, hence a reasonable proxy for our use case.
0 comments
Comments sorted by top scores.