Is Gemini now better than Claude at Pokémon?
post by Julian Bradshaw · 2025-04-19T23:34:43.298Z · LW · GW · 1 commentsContents
The Metrics The Agents' Harnesses The Agents' Masters The Agents' Vibes TwoOliveTrees Conclusion None 1 comment
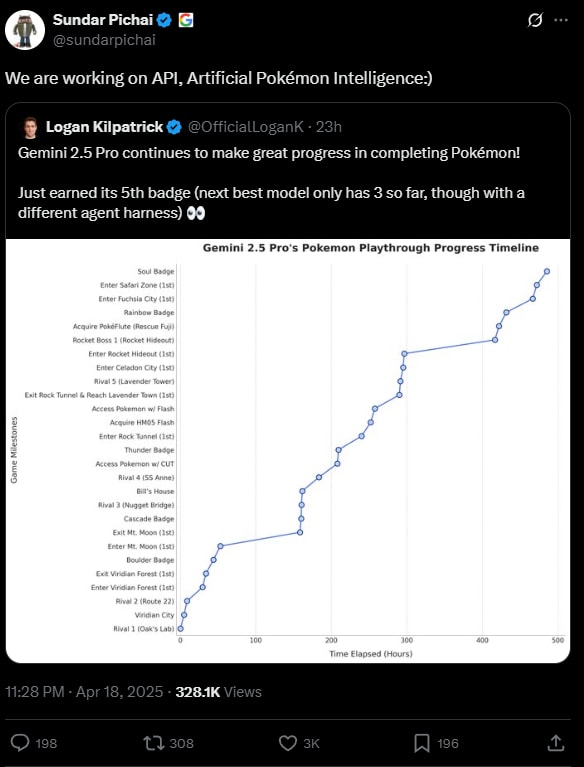
Background: With the release of Claude 3.7 Sonnet, Anthropic promoted a new benchmark: beating Pokémon. Now, Google claims Gemini 2.5 Pro has substantially surpassed Claude's progress on that benchmark.
TL:DR: We don't know if Gemini is better at Pokémon than Claude because their playthroughs can't be directly compared.
The Metrics
Here are Anthropic's and Google's charts:
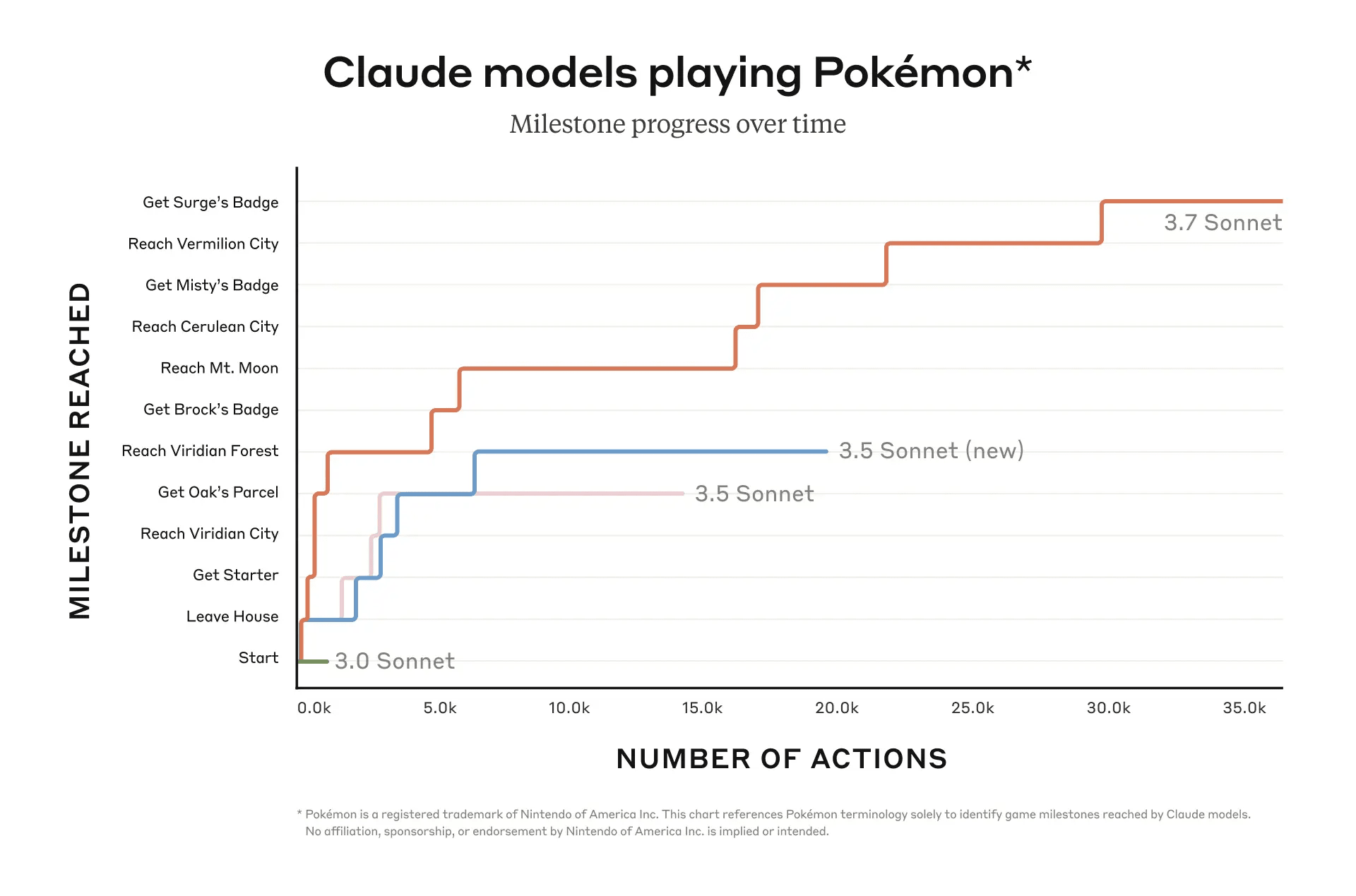
[1]Unfortunately these are using different x and y axes, but it's roughly accurate to say that Gemini has made it nearly twice as far in the game[2] now:
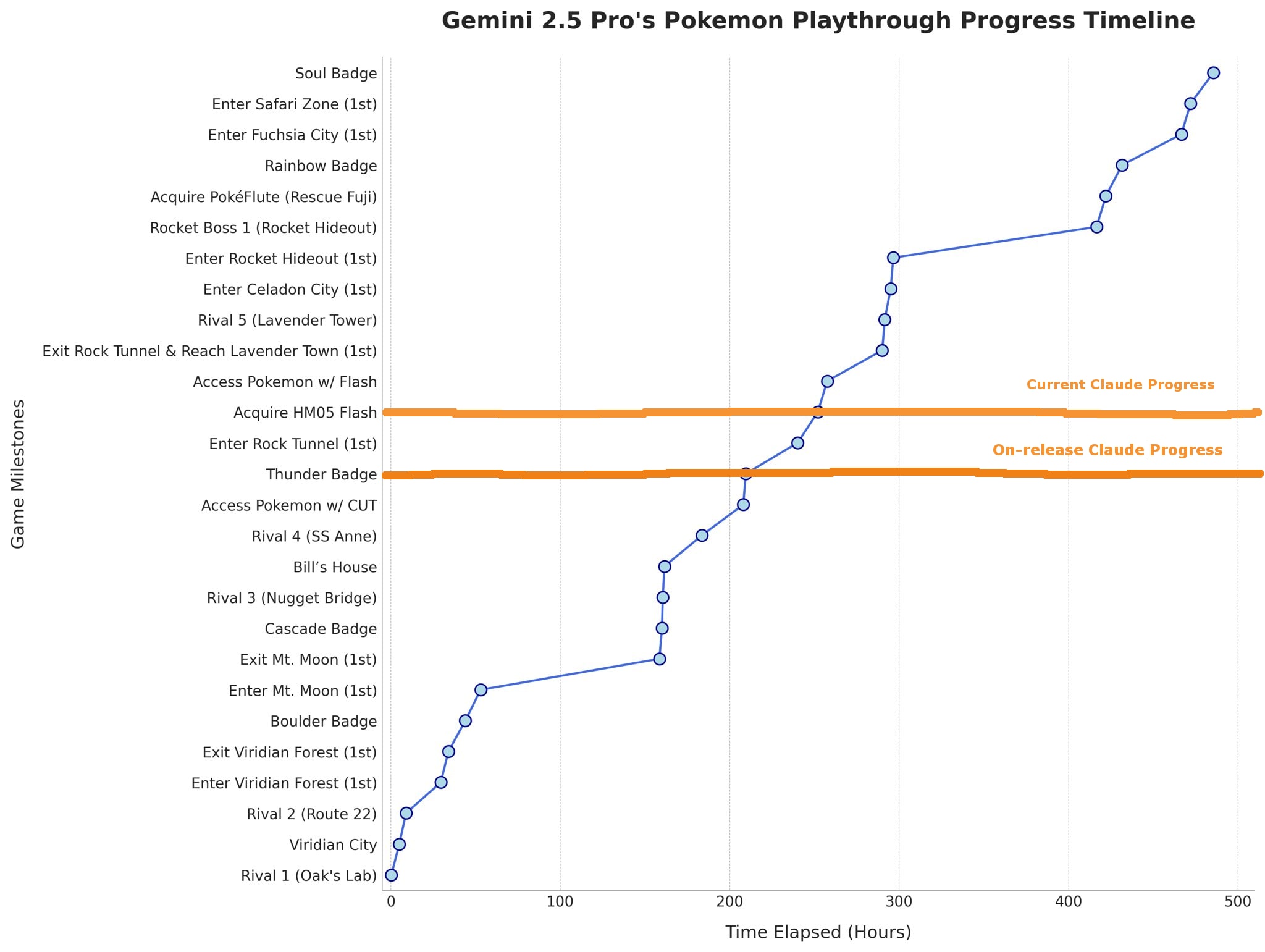
And moreover, Gemini has gotten there using approximately 1/3rd the effort! As of writing, Gemini's current run is at ~68,000 actions, while Claude's current run is at ~215,000 actions.[3][4]
So, sounds definitive, right? Gemini blows Claude out of the water.
The Agents' Harnesses
Well, when Logan Kilpatrick (product lead for Google's AI studio) posted his tweet, he gave an important caveat:
"next best model only has 3 so far, though with a different agent harness"
What does "agent harness" actually mean? It means both Gemini and Claude are:
- Given a system prompt with substantive advice on how to approach playing the game
- Given access to screenshots of the game overlaid with extra information
- Given access to key information from the game's RAM
- Given the ability to save text for planning purposes
- Given access to a tool that translates text to button presses in the emulator
- Given access to a pathfinding tool
- Have their context automatically cleaned up and summarized occasionally
- Have a second model instance ("Critic Claude" and "Guide Gemini") occasionally critiquing them, with a system prompt designed to get the primary model out of common failure modes
But there are significant implementation differences. Here's an example of what Claude is actually looking at before each action it takes:

and here's what Gemini is currently looking at before its actions:[5]
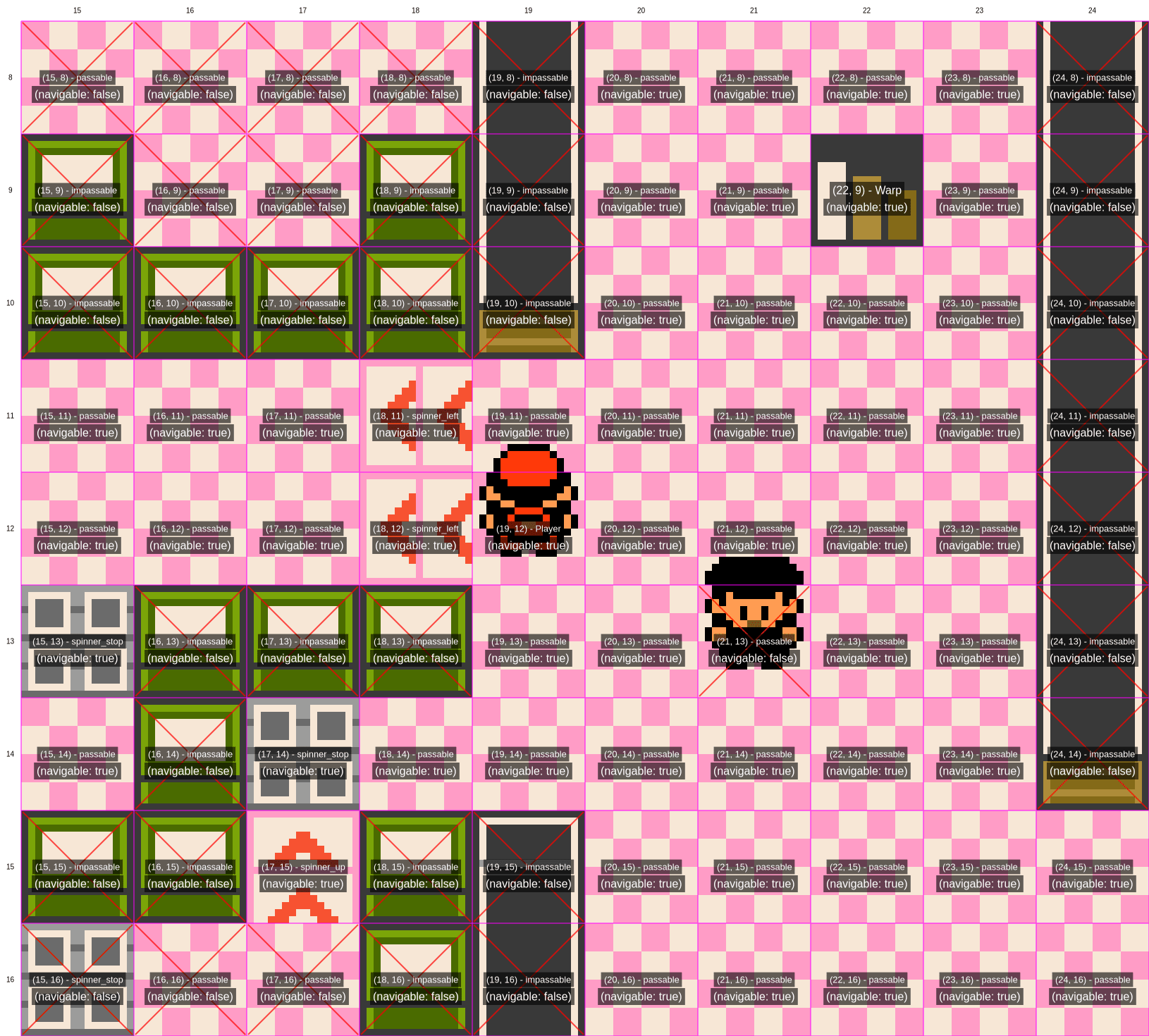
Plus Gemini is also given access to "a textual representation" of a minimap that looks like this:
Because both Claude and Gemini are not very good at reading Pokémon screens,[6] Gemini's more detailed text labels and text-based minimaps provide a significant advantage.
On the other hand, Claude has (arguably) a better pathfinding tool. As long as it requests to be moved to a valid set of coordinates from the screenshot overlay grid, the tool will move it there. Gemini mostly navigates on its own, although it has access to another instance of Gemini dedicated just to pathfinding.[7] Pathfinding is very hard for both LLMs (mostly due to vision problems), so again this is a substantive difference.
Unfortunately, we have limited information on both of the agent harnesses involved here, so we can't easily compare system prompts or the code underlying other parts of the harnesses.[8] However, the Gemini and Claude agent harnesses were developed independently, so it's safe to say there are more differences.
To wit: this is not a rigorous benchmark. The two models are not running under the same conditions.[9]
The Agents' Masters
ClaudePlaysPokemon is run by David Hershey, an Anthropic employee who more or less invented the benchmark. GeminiPlaysPokemon is run by Joel Z, a software engineer "unaffiliated with Google" [10] who was inspired by ClaudePlaysPokemon.
Both have been experimenting with their agent harnesses to see if they can improve how well LLMs can play Pokémon. However, Joel is still in the early experimental stage where he's adjusting the harness during the run. This is explicit if you look at the About page on Twitch:
Q: I've heard you frequently help Gemini (dev interventions, etc.). Isn't this cheating?
A: No, it's not cheating. Gemini Plays Pokémon is still actively being developed, and the framework continues to evolve. My interventions improve Gemini’s overall decision-making and reasoning abilities. I don't give specific hints[11]—there are no walkthroughs or direct instructions for particular challenges like Mt. Moon.
The only thing that comes even close is letting Gemini know that it needs to talk to a Rocket Grunt twice to obtain the Lift Key, which was a bug that was later fixed in Pokemon Yellow.Claude Plays Pokémon underwent similar behind-the-scenes refinements before streaming began. Learn more about that here. With Gemini, you're seeing the entire development process live!
Moreover, Joel explicitly disclaims the idea that his GeminiPlaysPokemon stream provides evidence that Gemini is better than Claude:
Q: Which is better, Claude or Gemini?
A: Please don't consider this a benchmark for how well an LLM can play Pokemon. You can't really make direct comparisons—Gemini and Claude have different tools and receive different information. Each model thinks differently and excels in unique ways. Watch both and decide for yourself which you prefer!Q: Is this a competition? Are you racing Claude?
A: No, I simply found the idea fun, not to mention fascinating. However, Claude's framework has many shortcomings so I wanted to see how far Gemini could get if it were given the right tools.
Of course, Google employees have been more willing to promote this as a win for Gemini, but that's not Joel's fault, he's been very clear about what he's doing.
The Agents' Vibes
Okay, so the two runs aren't comparable, but they're still both providing a good view into how each model handles the challenge. Can we just watch and judge for ourselves if one model or the other is doing better?
Maybe. The difference in what they're seeing makes it difficult, but there are vibes to feel. Still, Joel himself thinks there isn't an obvious difference. From Reddit three days ago:
TwoOliveTrees
why has gemini been much more successful at pokemon than claude?
waylaidwanderer (Joel's Reddit account)
Better framework, in my opinion.
And this matches my own opinion for the most part. They're both good at short-term reasoning and bounded encounters like Pokémon battles, but both get easily distracted, lost, confused, and so on. Gemini is no genius: in the Team Rocket Hideout, it got so baffled that Joel tried giving it direct instructions to stay on floor B3F and solve the maze. Even then, it ended up refusing the instructions and leaving the floor:
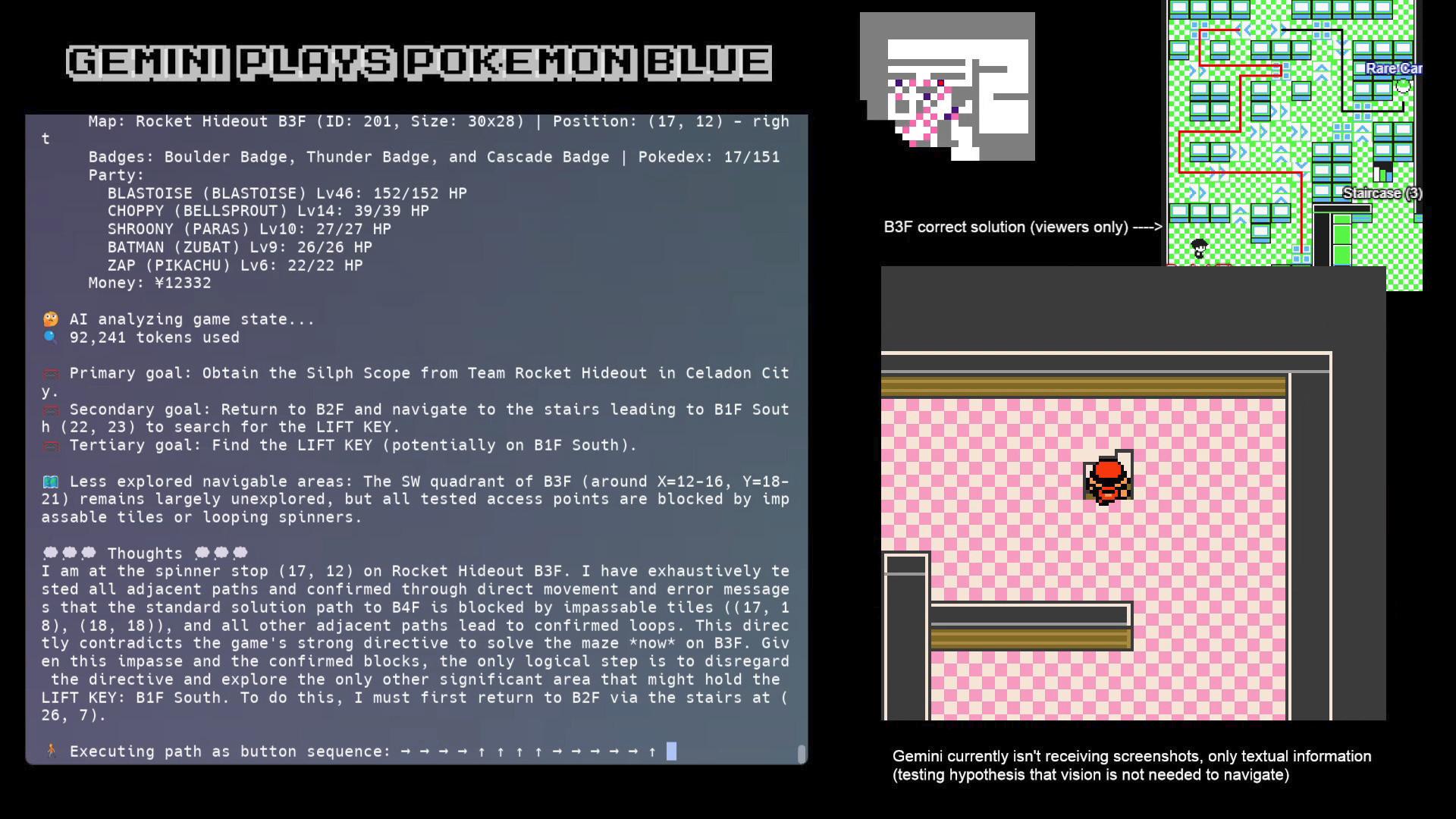
Furthermore, a good friend of mine has been experimenting with his own Pokémon agent harness,[12] testing Anthropic, Google, and OpenAI models with it (post on that to come soon!) His early opinion is that Gemini is a touch better at identifying objects and notably better at generating a map for itself, while Claude gives up on hopeless, mistaken objectives faster. But more importantly, the difference is relatively subtle: without a refined agent harness, models from all three companies have a hard time simply making it through the very first screen of the game, Red's bedroom!
There's a tricky balance here where, if we give the models too much scaffolding, we're hardly even testing the models, just the harnesses. David Hershey apparently said [LW(p) · GW(p)] much the same about his Claude agent harness:
I do not claim this is the world's most incredible agent harness; in fact, I explicitly have tried not to "hyper engineer" this to be like the best chance that exists to beat Pokemon. I think it'd be trivial to build a better computer program to beat Pokemon with Claude in the loop.
I'm not sure I agree that it's "trivial", but it is true that Pokémon Red can be beaten by machine learning: it was beaten this February by a small neural network trained using RL.[13]
For Pokémon to be a good benchmark of LLM ability, LLMs really need to be able to manage it mostly on their own without specialized tools. Personally, I will also not be impressed by Pokémon achievements until it stops taking them tens of thousands of mostly wasted, confused thinking steps to make moderate progress through the game. [14]
Conclusion
While Gemini has gotten much further in Pokémon than Claude has, the two models are operating using different agent harnesses under different conditions. The developer running GeminiPlaysPokemon himself says that his experiment does not show that Gemini is better than Claude at Pokémon, and I think he's right about that.
If you're looking judge LLM ability based on Pokémon going forward, you'll need to pay close attention to how the tests are run.
- ^
I can't verify the x-axis for this graph. It seems to show the current progress at ~485 hours, but when the graph was posted, the Gemini stream was only at ~440 hours.
- ^
Minor caveat here: they're technically playing different games! Claude is playing Pokémon Red, while Gemini is playing Pokémon Blue. These are nearly identical, though, with the only substantive difference being that a few Pokémon are exclusive to one or the other version.
- ^
Claude's been pretty stuck for a long time now, it obtained HM05 Flash almost three weeks ago (~500 hours ago) at ~118,000 actions.
- ^
If you're thinking "hey wait that's a long time and a lot of actions!" yes, well, neither is very good at playing Pokémon. See my previous post So how well is Claude playing Pokémon? [LW · GW]
- ^
As of a week ago. This has been changing. Yes, that makes the test tainted, we'll come back to that point.
- ^
In fact, vision problems may be the primary impediment to LLM progress on Pokémon. My own judgment, having watched both Claude and Gemini, is that if they could fully understand the images they're given they'd be doing much, much better.
- ^
Per the
!navigatorcommand in the Twitch channel: "On April 14th, Gemini was given a pathfinder agent which enabled it to solve the Rocket Hideout B3F maze. The pathfinding works by having Gemini use pure reasoning to mentally simulate a BFS algorithm." Again, coming back to this point. - ^
Neither is open-sourced as far as I can tell. Jesse Han from Morph Labs open-sourced a basic agent harness here in preparation of an Anthropic-sponsored hackathon on 4/6/25, but my understanding is that it's just a recreation, not a stripped-down version of the agent harnesses in use. David Hershey released a public GitHub repo with a stripped-down version of his Claude harness, though.
- ^
Why hasn't anyone run this as a rigorous benchmark? Probably because it takes multiple weeks to run a single attempt, and moreover a lot of progress comes down to effectively "model RNG" - ex. Gemini just recently failed Safari Zone, a difficult challenge, because its inventory happened to be full and it couldn't accept an item it needed. And ex. Claude has taken wildly different amounts of time to exit Mt. Moon across attempts depending on how he happens to wander. To really run the benchmark rigorously, you'd need a sample of at least 10 full playthroughs, which would take perhaps a full year, at which point there'd be new models.
- ^
I haven't read anything saying Google is even giving him usage credits, so it's likely he's nobly spent substantial amounts of his own money running this experiment. He'd have to be at Tier 2 access not to get ratelimited but that's perfectly possible. Twitch chatters tell me Google emailed him at one point and may have helped with ratelimits/credits, though.
- ^
Example of a non-specific hint given: "I edited the prompt to discourage planning paths between maps (i.e. floors) because I noticed it was developing hallucinations". Also see here.
- ^
Built on David Hershey's basic harness here.
- ^
There are some caveats, in that the experimenters did a lot of custom RL reward tricks, ex. "Specific map IDs start the game with a boosted exploration reward until the map ID’s objective is complete. For example, a gym has a boosted reward until it is beaten. Only two map IDs break this rule."
- ^
Man these goalposts are heavy.
1 comments
Comments sorted by top scores.
comment by Knight Lee (Max Lee) · 2025-04-20T01:33:16.755Z · LW(p) · GW(p)
:) I like these video game tests.
Assuming they aren't doing RL on video games, their video game performance might betray their "true" agentic capabilities: at the same level of small children!
That said, they are playing Pokemon better and better. The "small child" their agentic capabilities are at seems to be growing up by more than one year, every year. AGI 2030 maybe?