Visual demonstration of Optimizer's curse
post by Roman Malov · 2024-11-30T19:34:07.700Z · LW · GW · 3 commentsContents
Chapter 1: Optimization Chapter 2: Optimizer's curse Chapter 3: Bayesian remedy Chapter 4: Goodhart's curse None 3 comments
Epistemic status: I am currently taking this course, and after reading this post on Goodhart's curse, I wanted to create some visuals to better understand the described effect.
Chapter 1: Optimization
Veronica is a stock trader, and her job is to buy stocks, and then sell it at a specific time during the month. Her objective is to maximize profit. Here is the graph of how much money she will make if she sells at some specific time:
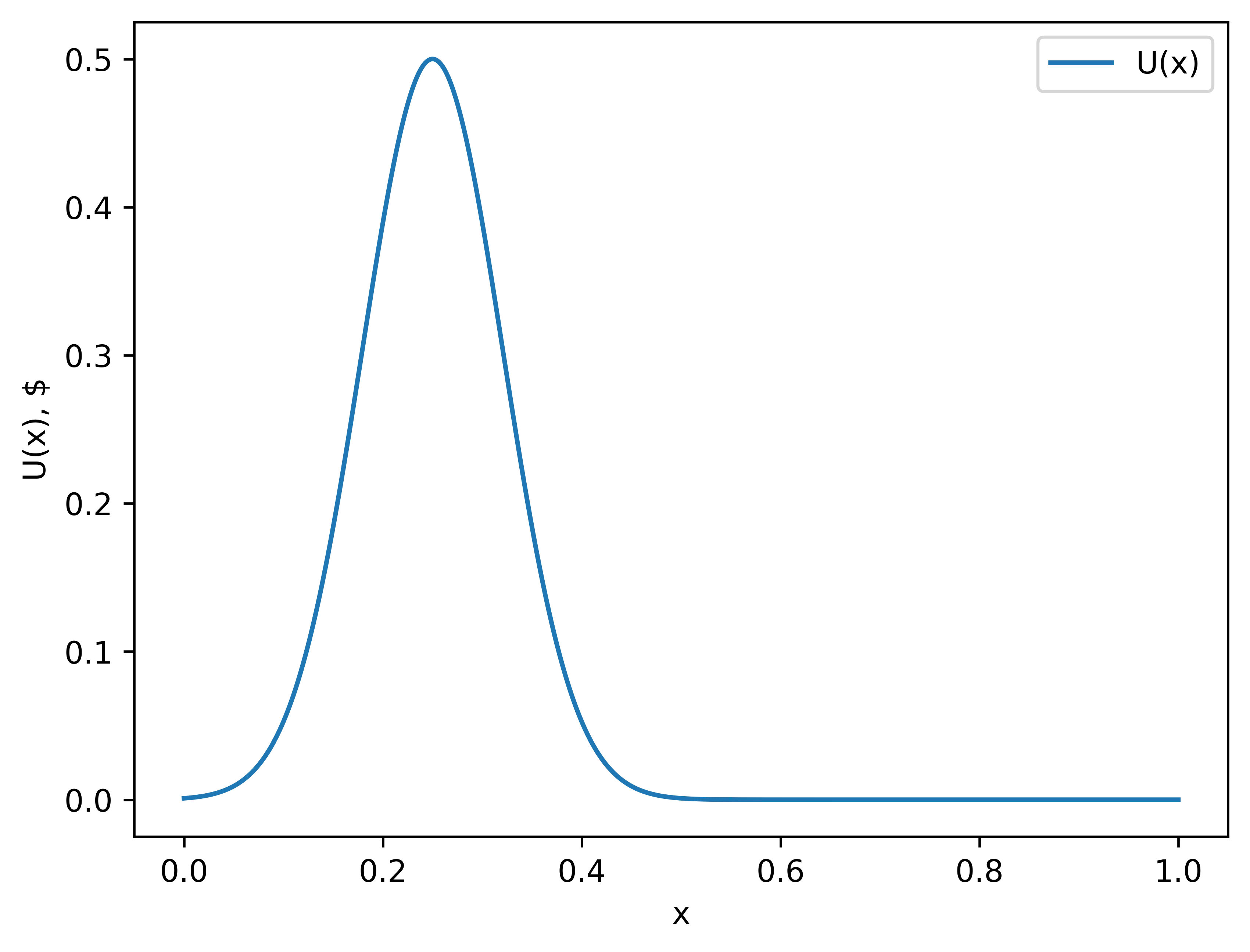
This can be called Veronica’s utility function , so if she sells at a time , she makes dollars.[1]
But she does not have access to this function. She only has access to a giant supercomputer, which works like this: she presses the button, the computer chooses some random moment in the month and calculates . Running this computer takes a lot of time, so she can only observe a handful of points. After that, she can analyze this data to make a decision about the selling time.
Her current algorithm is as follows:
Algorithm 1
- Run the computer times, generating pairs of the type .
- Locate the maximum using argmax:
- Sell stocks at the time and receive dollars.
Here is the picture of how one such scenario might look like:
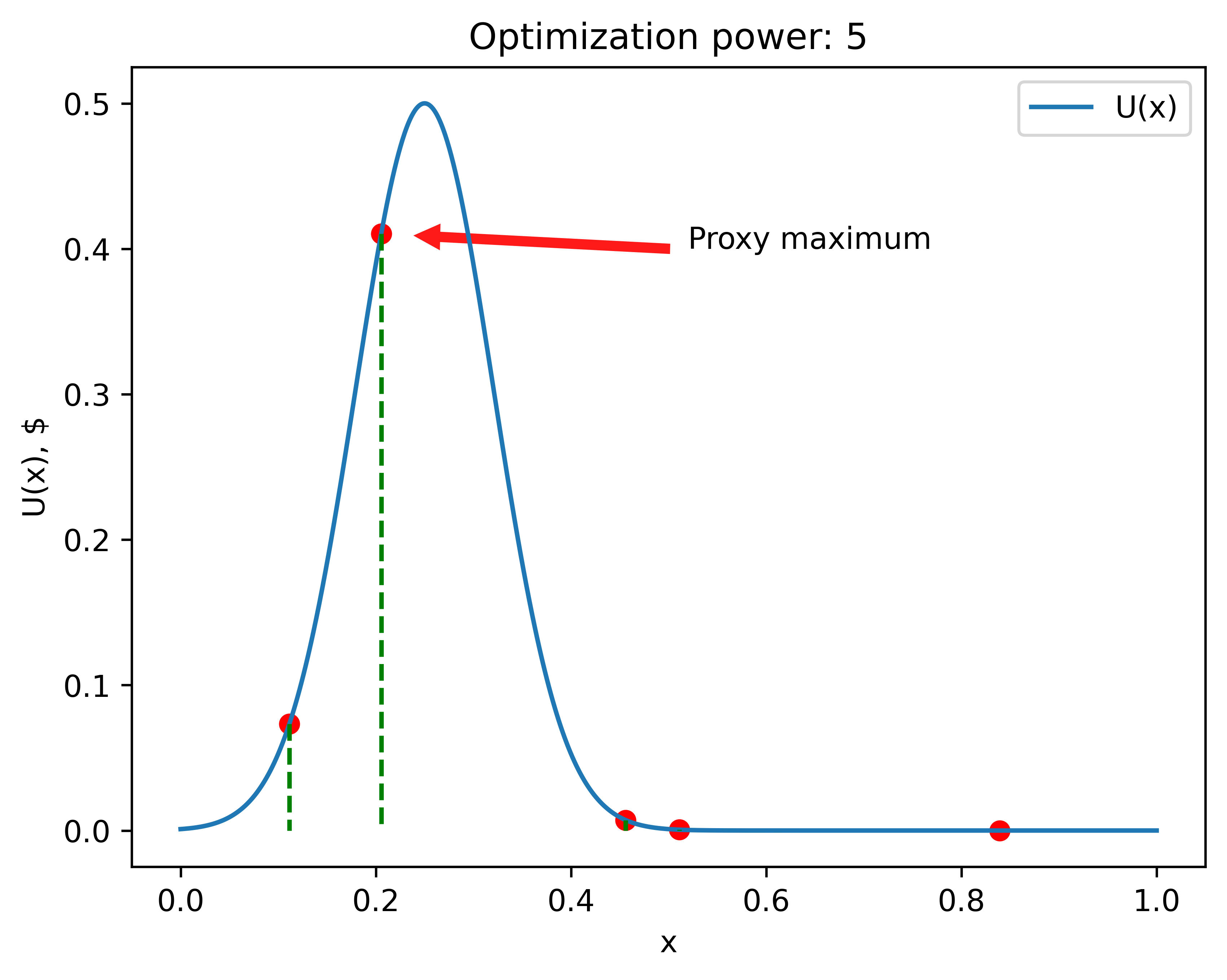
The number of observed points (aka the number of times Veronica pressed the button) will be referred to as 'optimization power'. The higher this number, the closer (on average) her proxy maxima will be to the actual maximum.
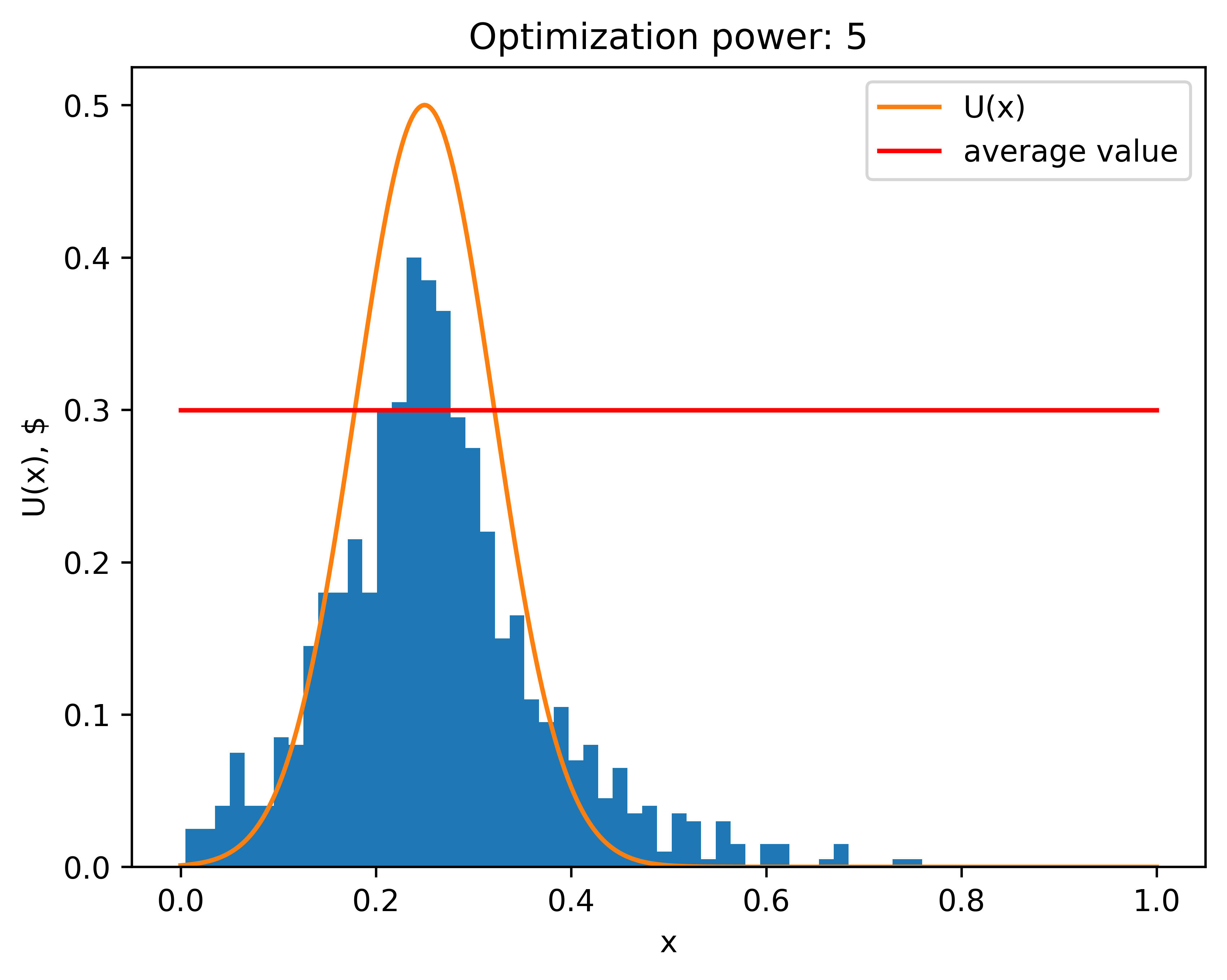
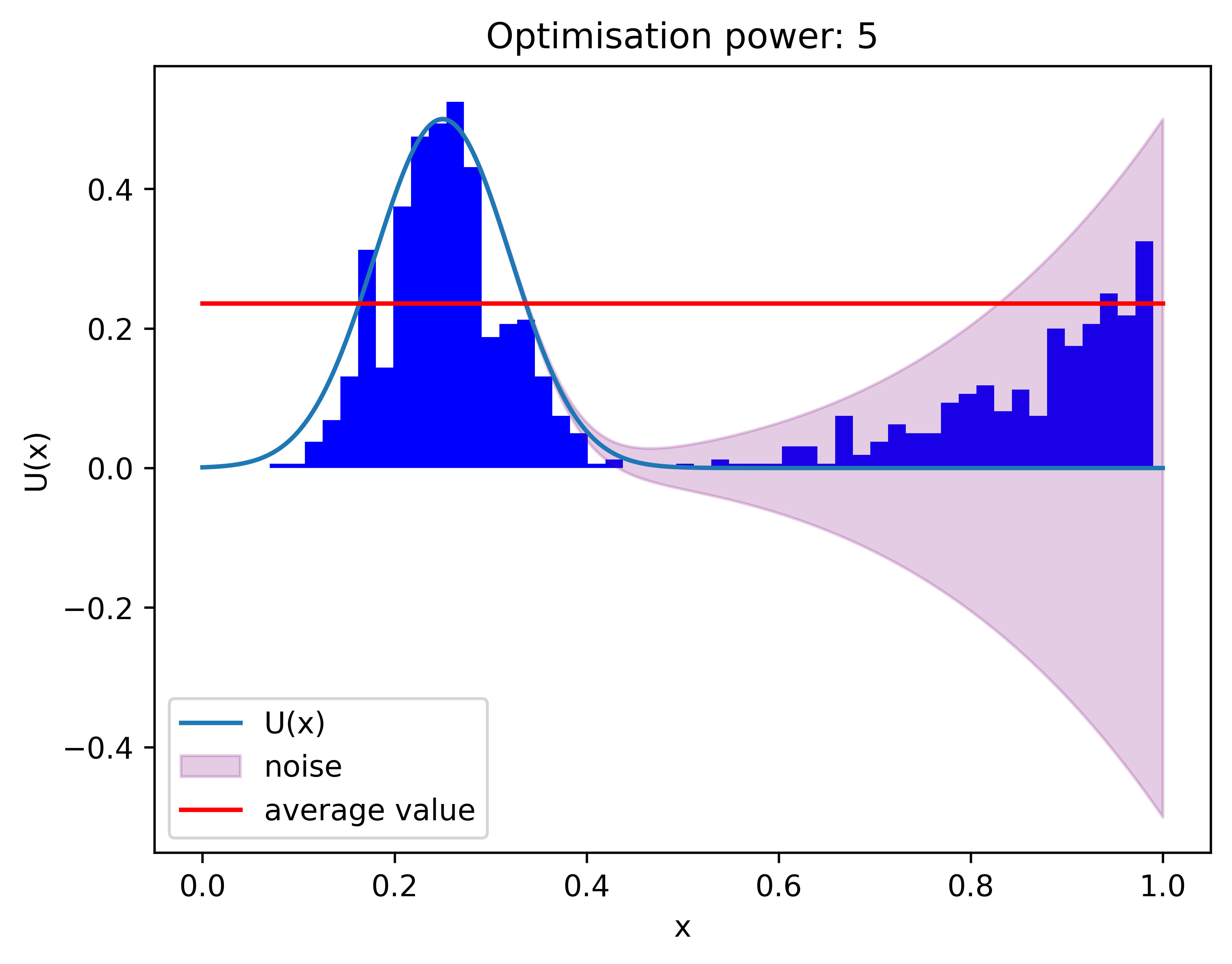
Here are 1,000 such experiments, in each of which the optimization power was 5. The bar chart is the probability density of the proxy maxima chosen by the Algorithm 1.[2] We can see that points are clustering around the true maximum point (). The “average value” is the average of the utility function Veronica obtains from those proxy maxima (the expected amount of money she makes with this algorithm). It is noticeably smaller than the actual maximum value she can achieve.
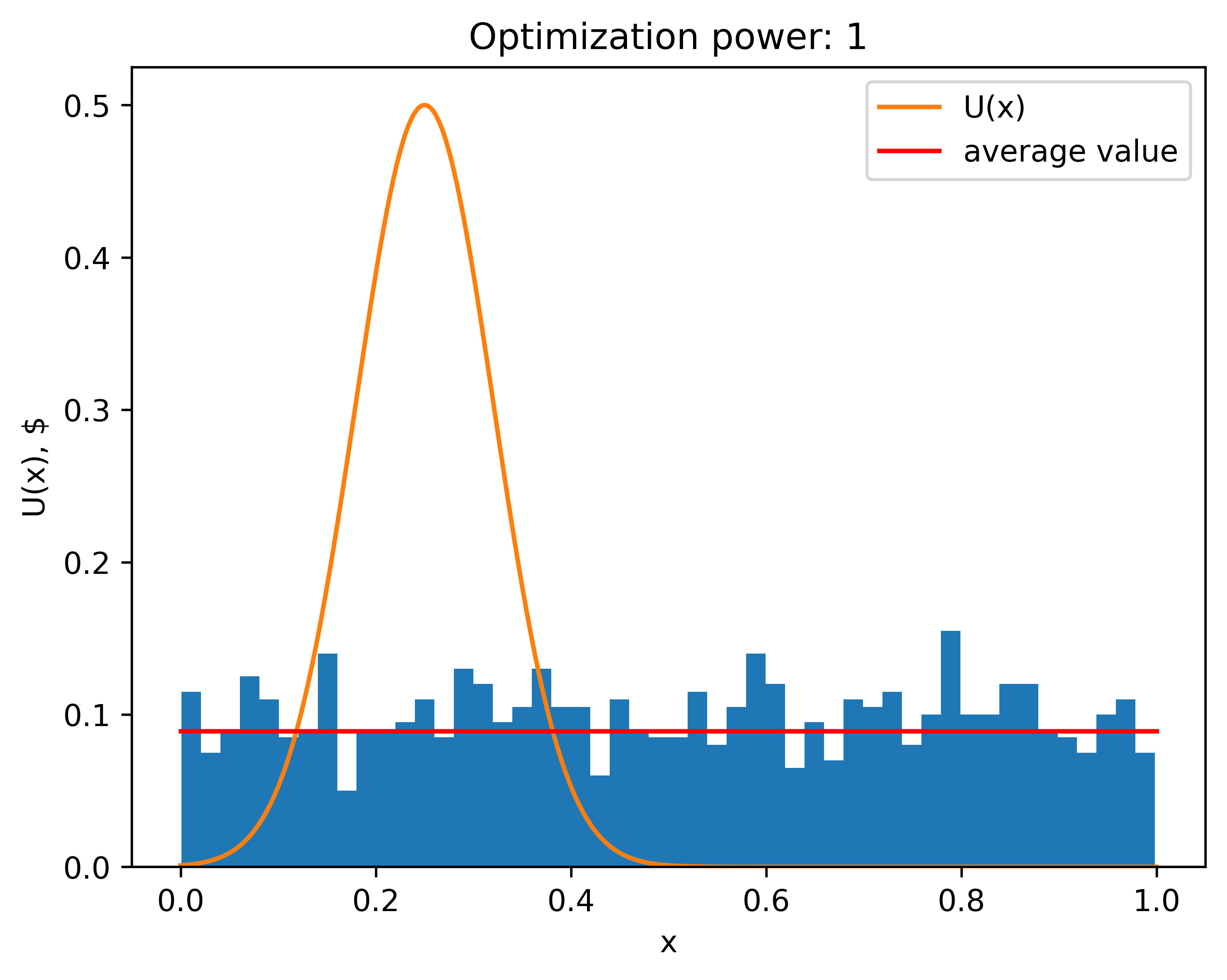
With the lowest optimization power () Veronica doesn't gain any information, and is her guess is equivalent to a random choice (since she is choosing from a single randomly selected point).
Here is what happens if she cranks up the optimization power (runs the forecasting supercomputer many times).
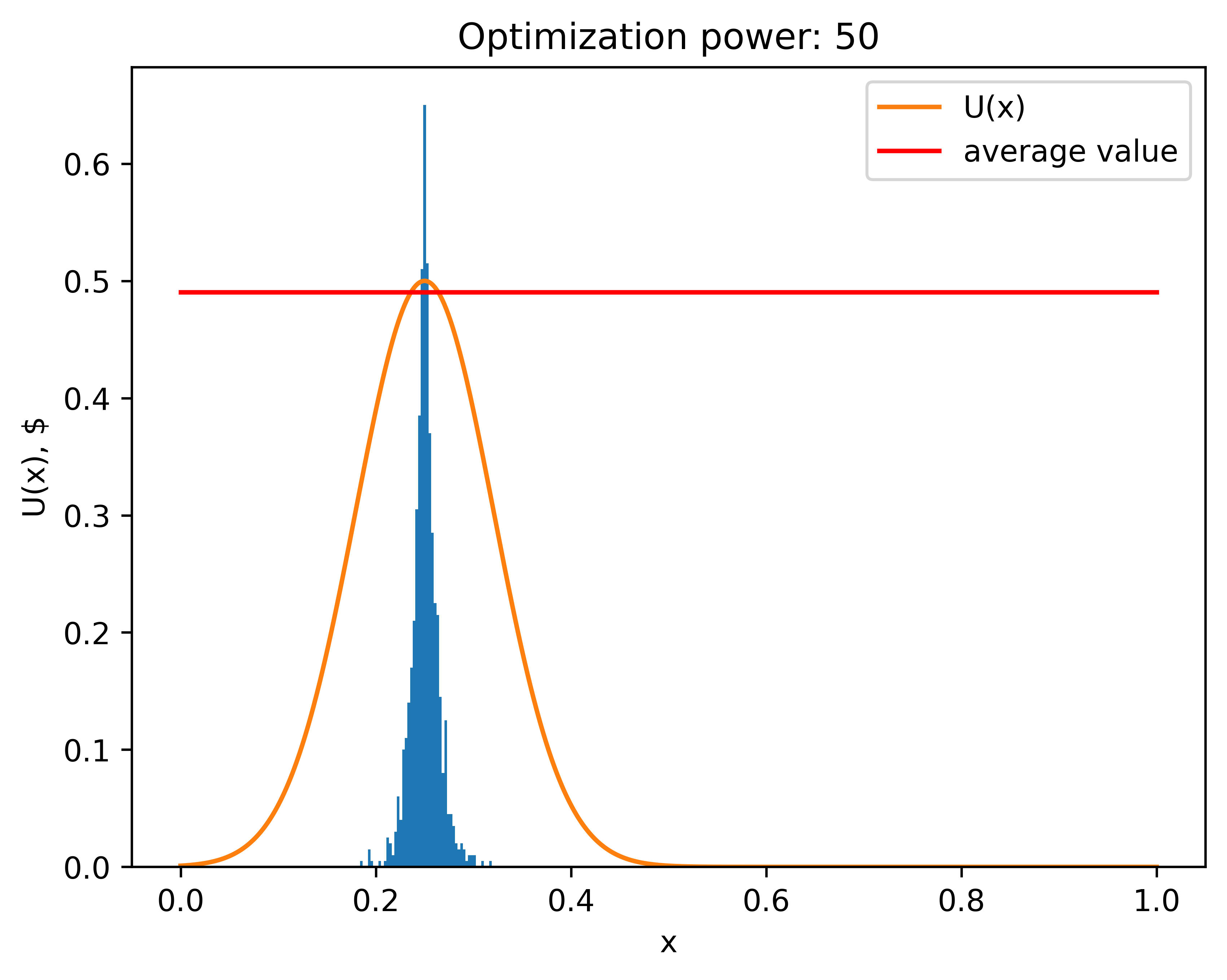
Her expected profit is now much closer to the actual maximum profit. Additionally, the distribution is much narrower: now proxy maxima are, on average much closer to the actual maximum.
Here is a graph of the dependence of the average value on the optimization power.
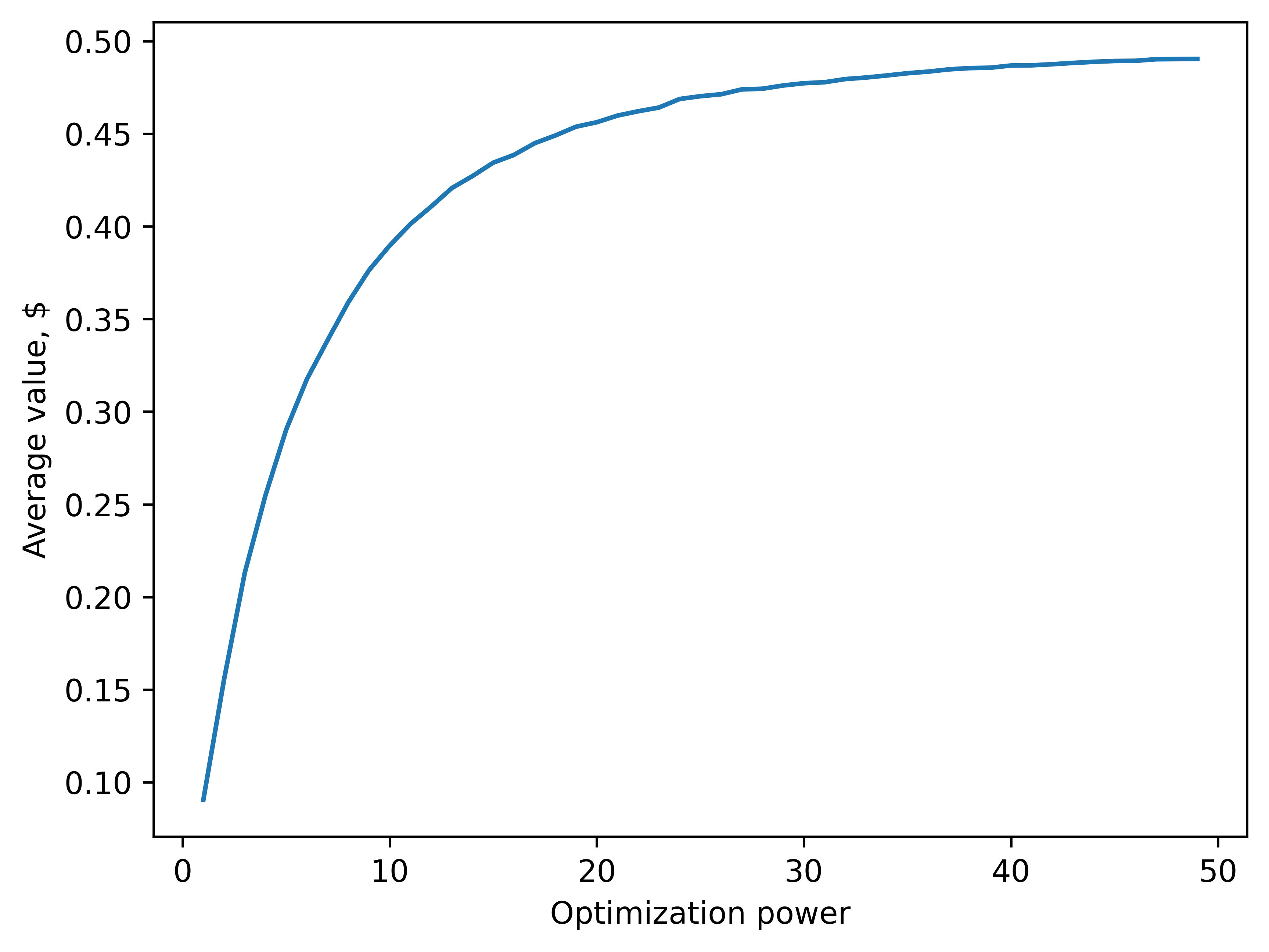
Notice how it increases monotonically (which shouldn't be surprising).
Chapter 2: Optimizer's curse
In reality, forecasting distant events is hard, and the further away the event, the harder it becomes. To account for that, we can add noise in Veronica's measurements of utility. In this example it would be the error in computed profits; and the further in time we try to make predictions, the harder it is, and that is reflected with purple area on the plot. In my model, what Veronica gets from the computer is the actual value of at that point gaussian noise. So now, the result of the computer's prediction is , where is a noisy estimation of . Purple area represents interval, and , so it increases with time. Notice that this is an unbiased estimation: on average, with a lot of samples, she would get closer and closer to the actual value of .
Here's how one of these scenarios might play out.
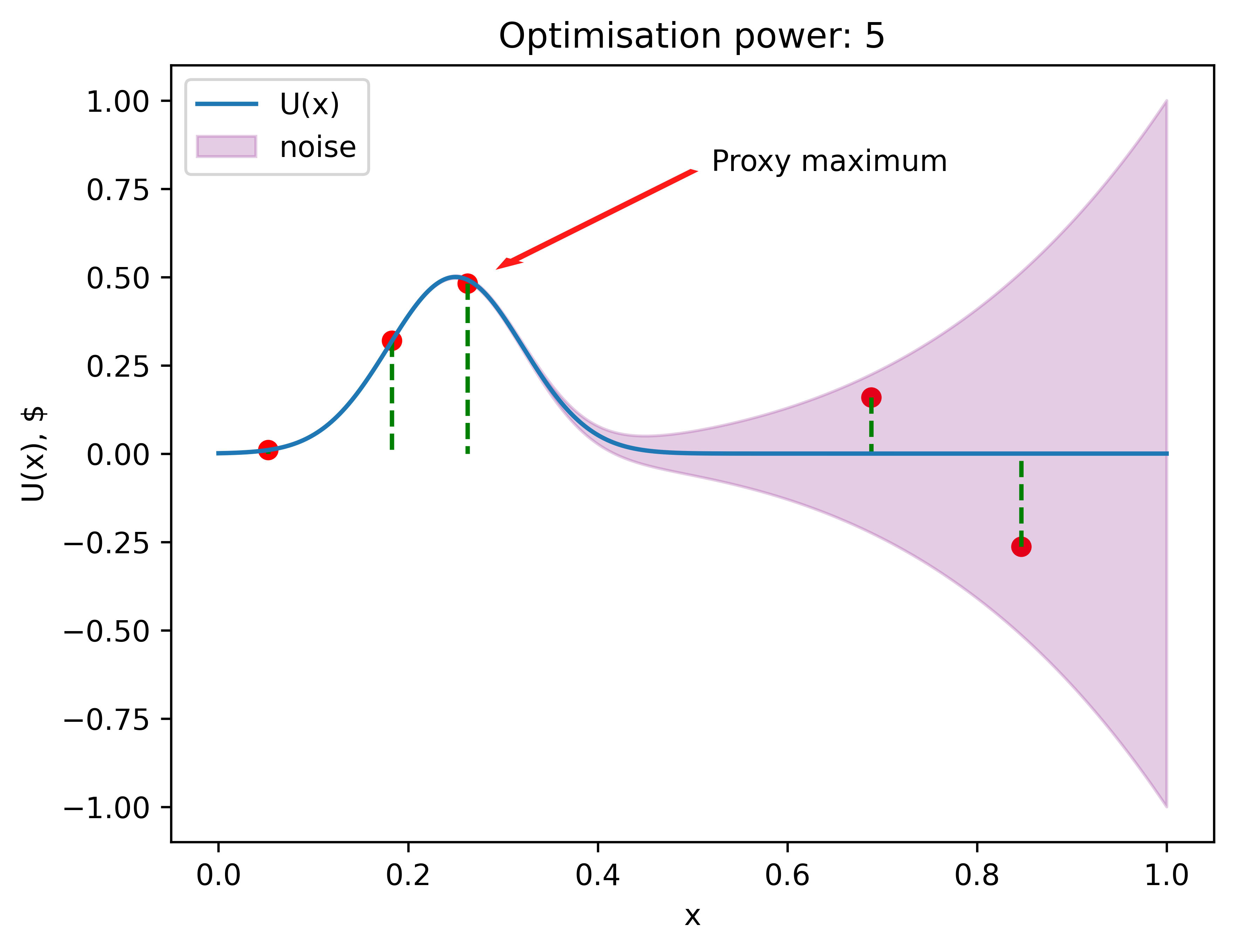
In this case, Veronica's proxy maximum lies near the actual maximum. However, that is not always the case.
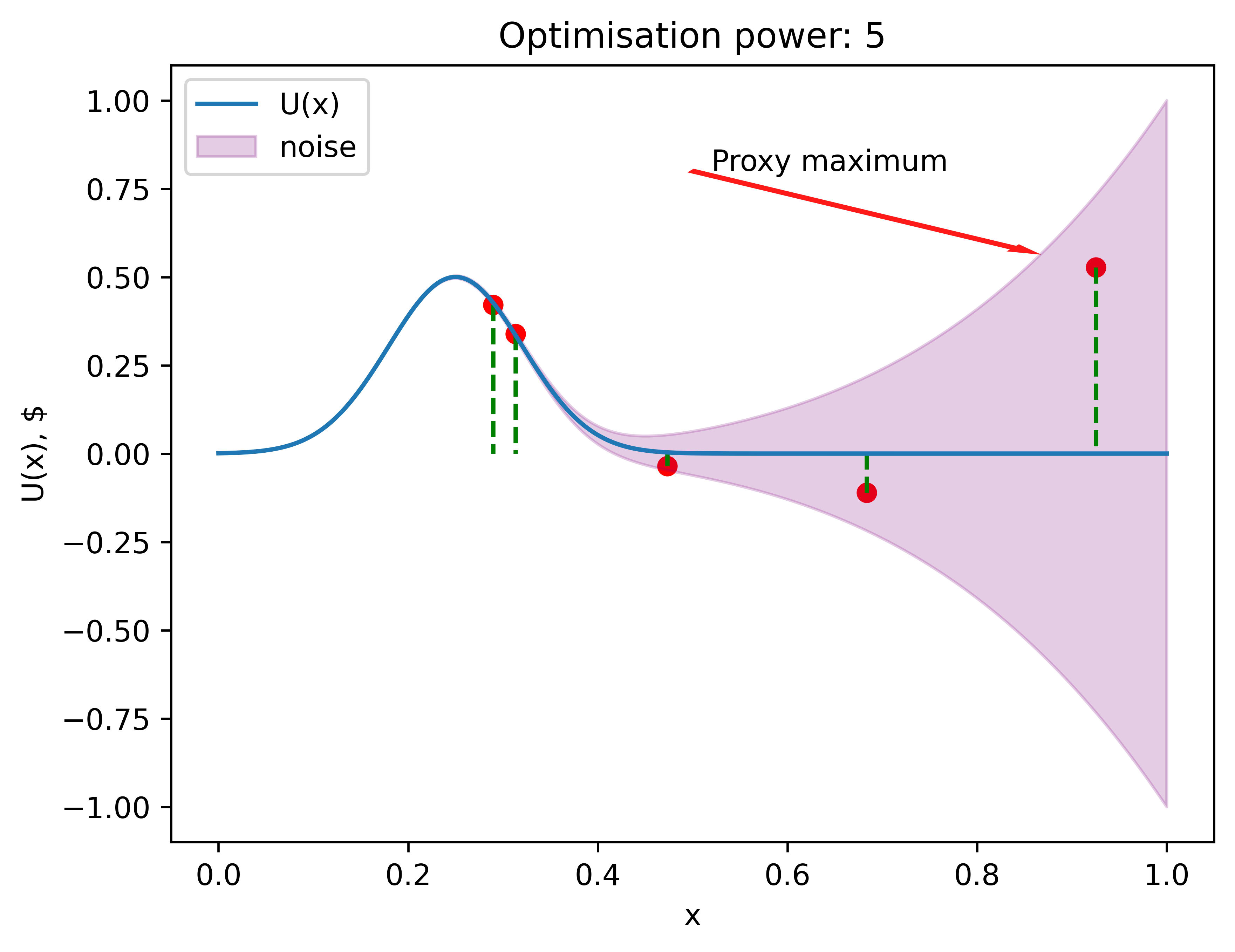
Sometimes, (as in example above) flukes from the noisy area are higher than the signal from the actual near-maximum area, and her chosen proxy maximum is way off.
Now let’s look at a distribution of proxy maxima (1,000 experiments).
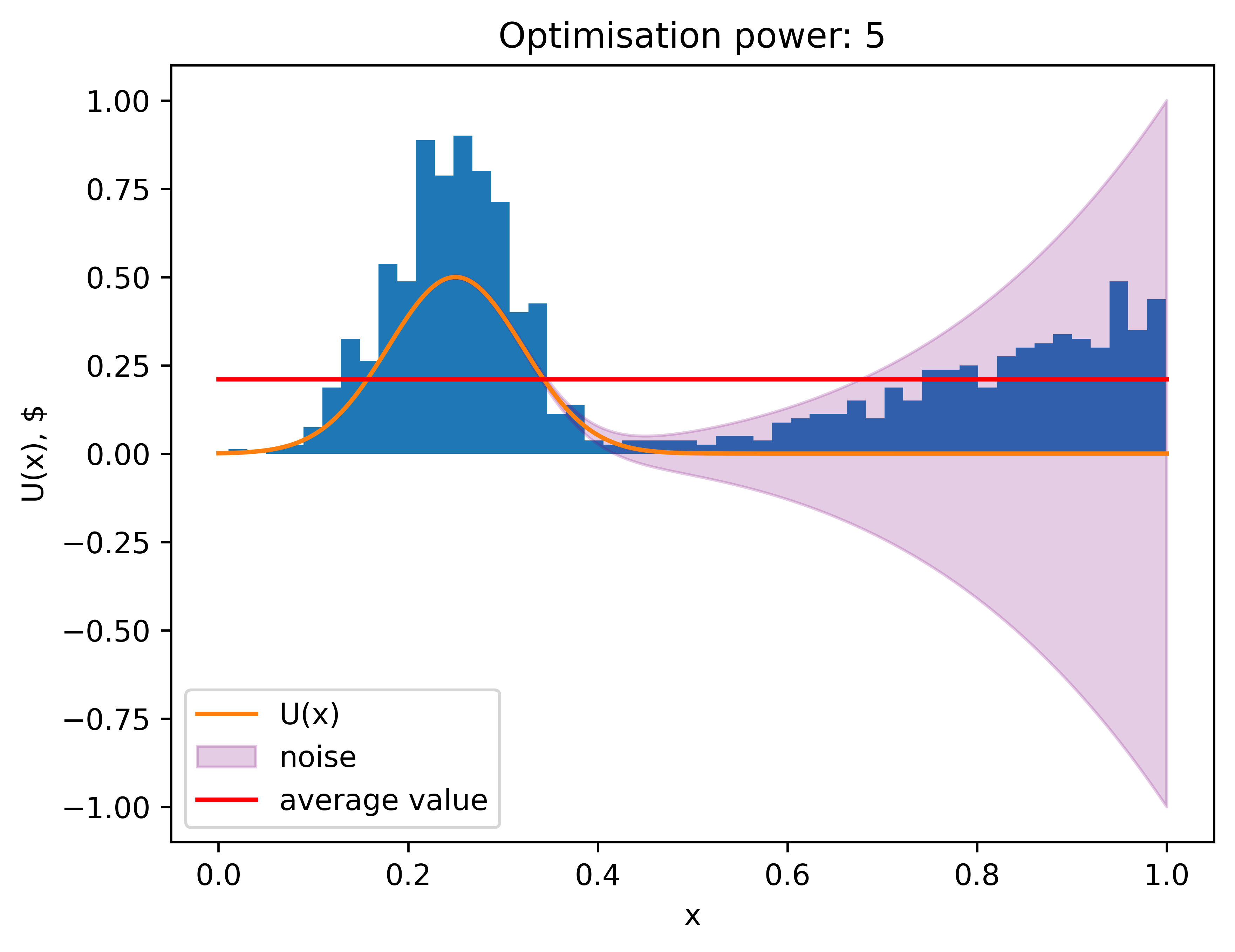
The average value decreased a bit, but that is to be expected, we introduced some obstacle. But notice how the distribution is bimodal: the noise we introduced caused some of Veronica's estimations of maximum to be completely off. That’s because when she samples, some of the points, which are located in the high-variance area have high noise-induced values, and this is not balanced with points with low noise-induced value, because those low points effectively do not “participate in the competition”. This effect is called Optimizer's curse: tendency of optimizers to seek high areas with high variance.
But surely, with the help of bigger optimization power Veronica can fix this, that helped her to make expected utility bigger before, right? But no! In fact (with the assumptions we made) it gets worse:
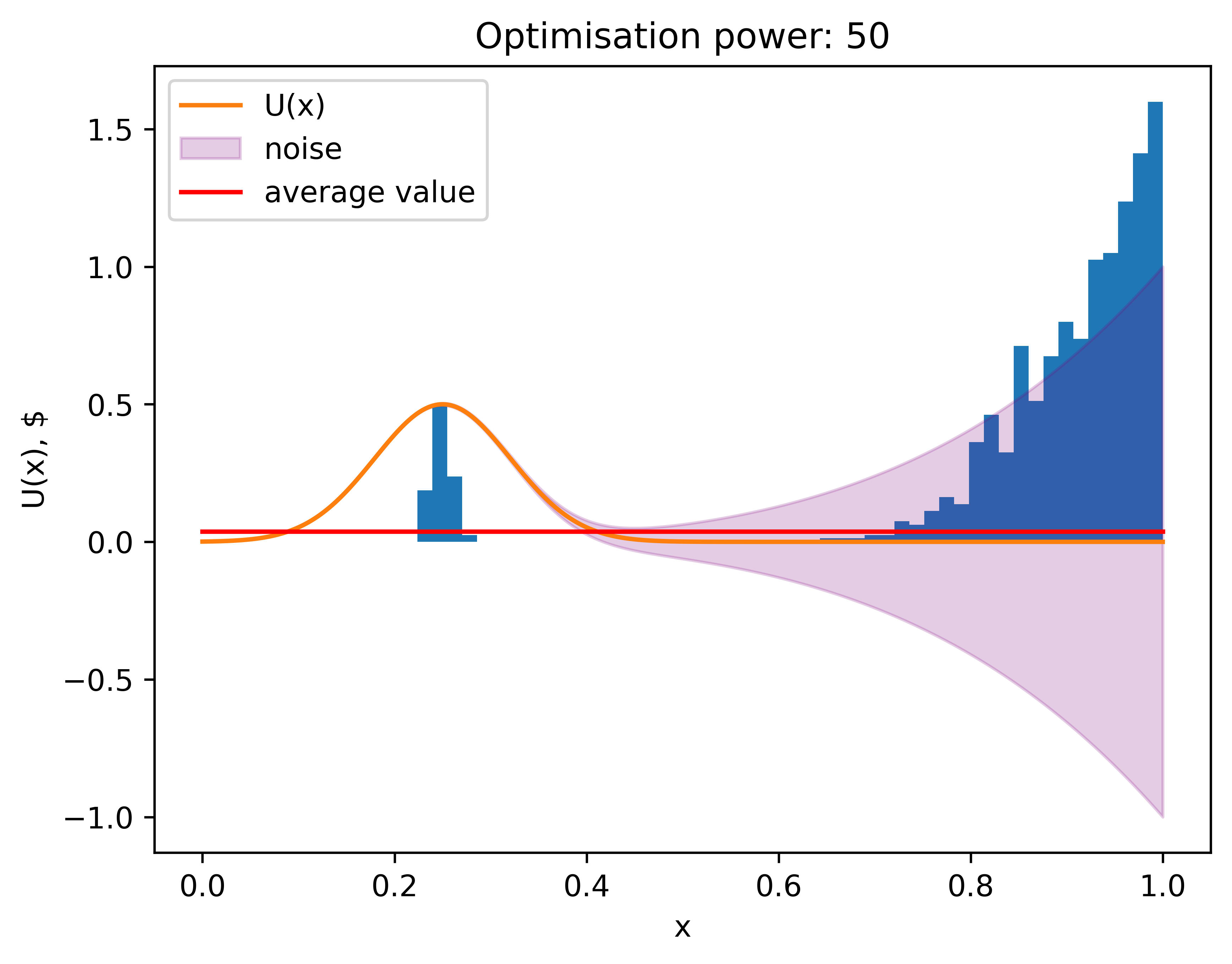
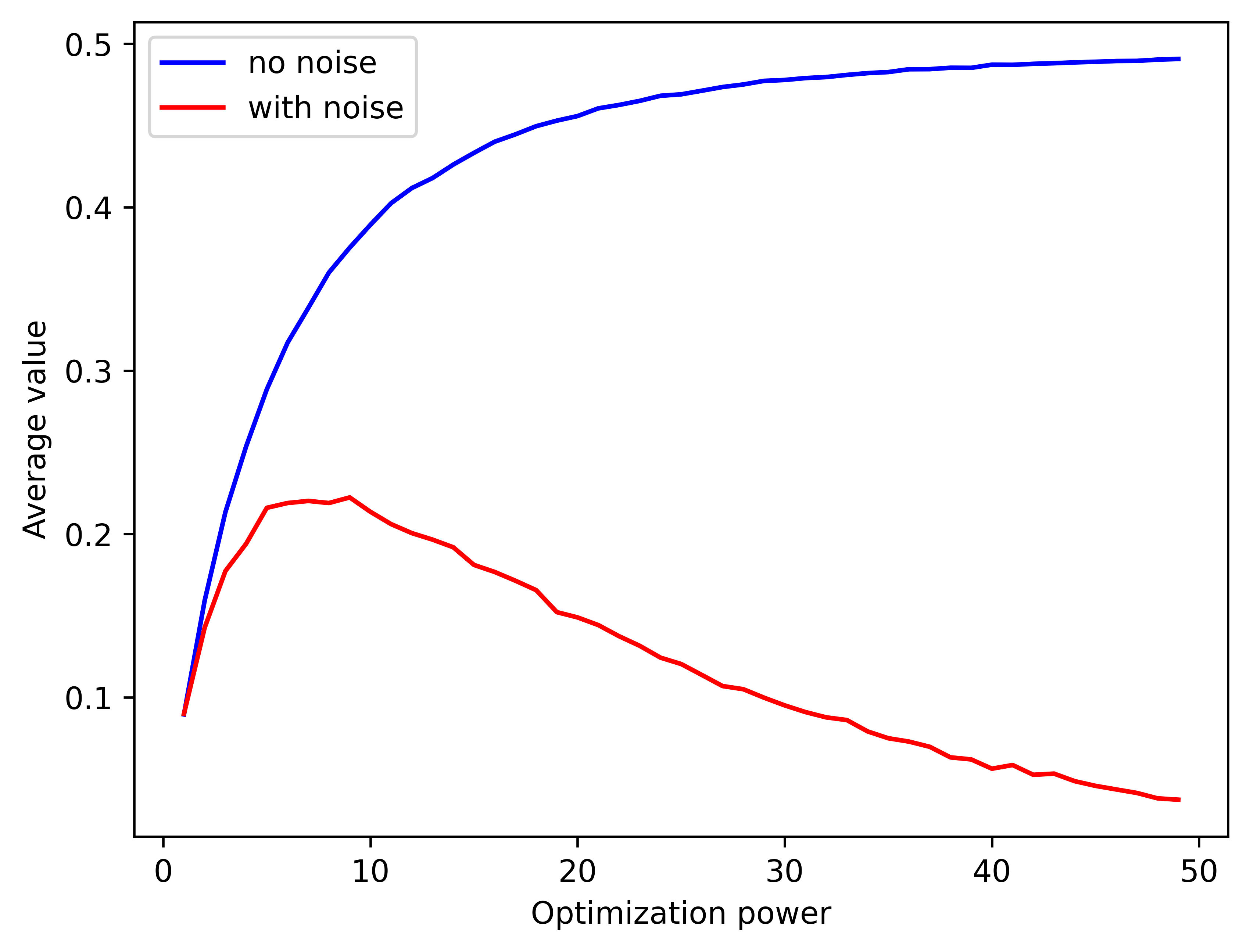
An increase in optimization power resulted in a lower average value because, with more samples, the probability that the highest point from a noisy area exceeds the actual maximum of the utility function increases. Here’s the graph of the average value with respect to optimization power. At some point, higher optimization power is worse than random sampling.
Chapter 3: Bayesian remedy
Now, before we see Veronica using Bayes theorem with her task, let's take a step back and look at an easy example of applying bayesian updates.
Roman is a physicist running an experiment. He observes the decay of some particle. He does not know the half-life period of this particle, and needs to infer it from observations.
Every time he sees a particle decay, he records how long it took. The probability density of this time is . This is called exponential distribution.
He knows that is somewhere between 0.5 and 2 seconds. His prior distribution on might look something like this:
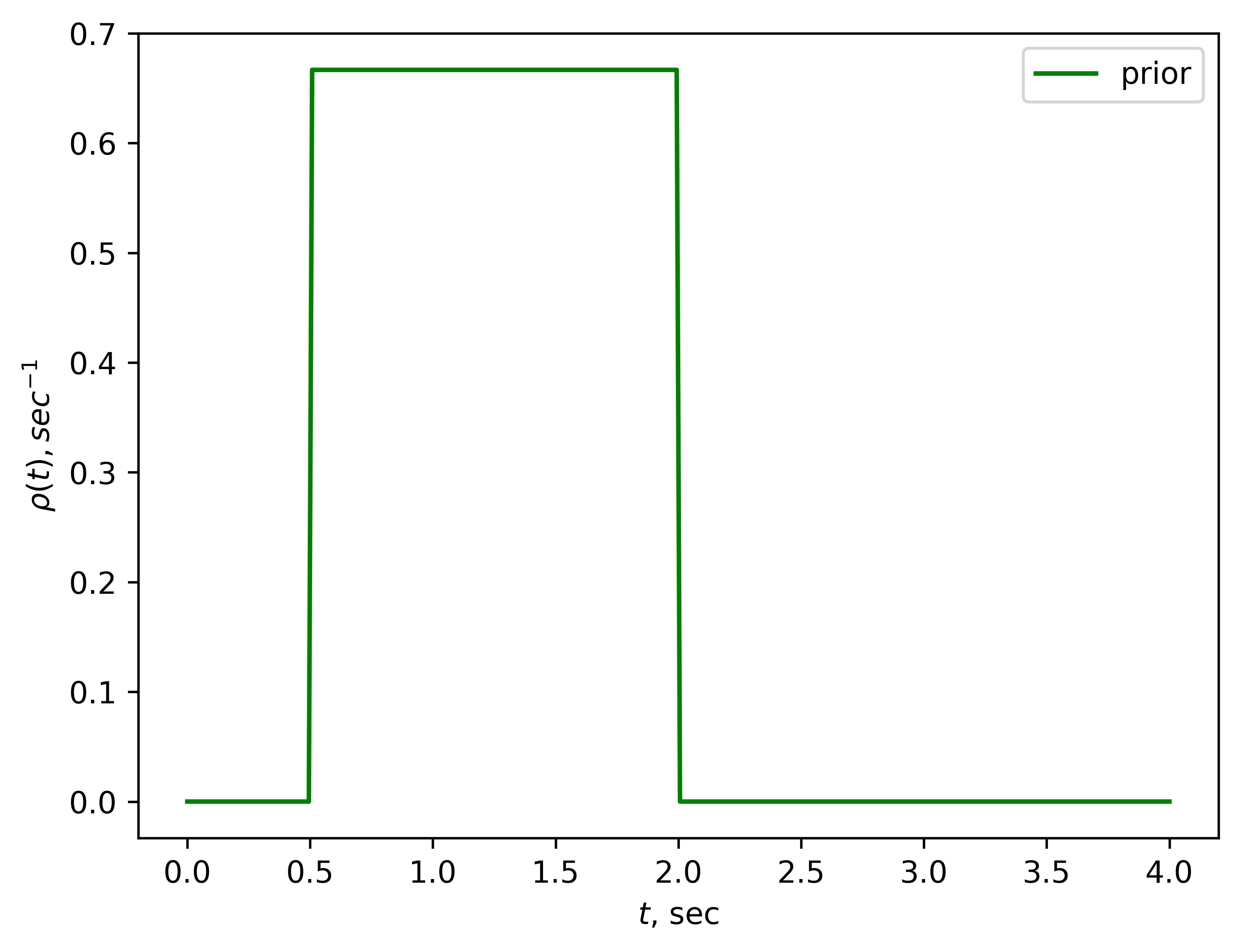
Each possible value of the is a hypothesis, and the prior distribution assigns some probability (in our case probability density) to each hypothesis. After Roman gets an observation , he updates his beliefs about how likely each hypothesis is using Bayes's theorem:[3]
The term in the denominator is a constant and can be calculated using normalization.
After the first observation, Roman's posterior distribution looks like this:
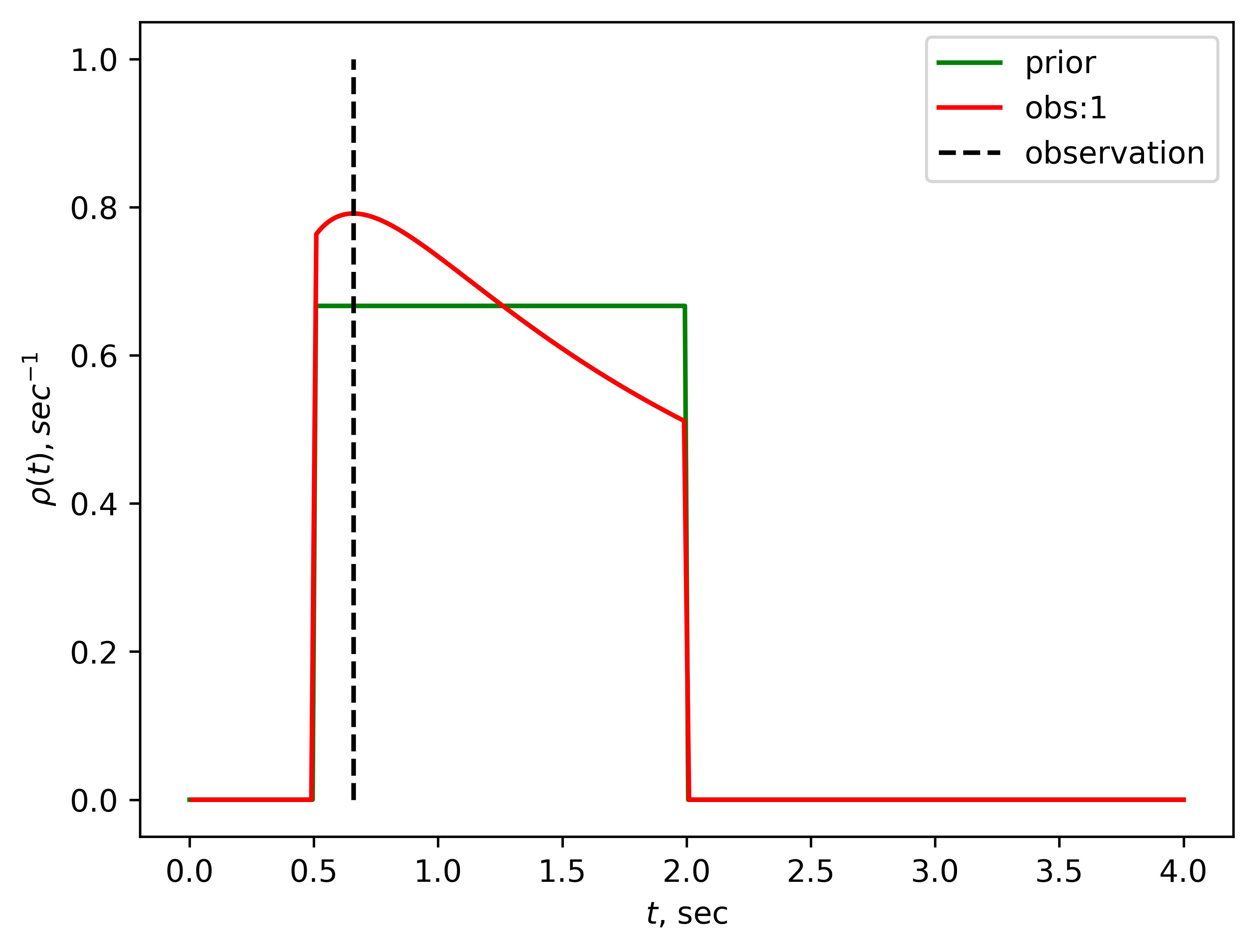
Then Roman can call the resulting distribution his new prior distribution (and he can do that because observations are uncorrelated) and keep doing the process. Here is a GIF of how that would look like:
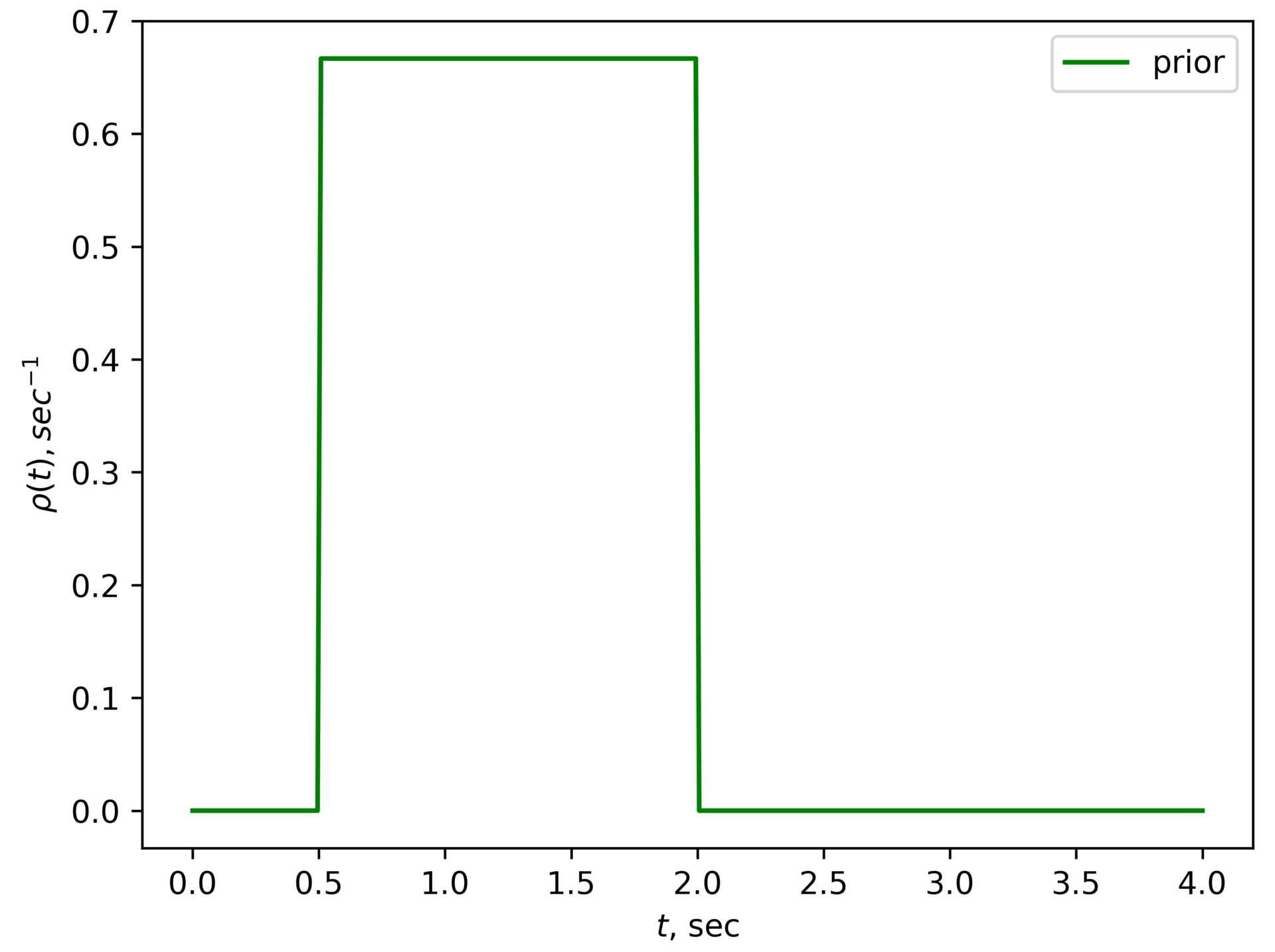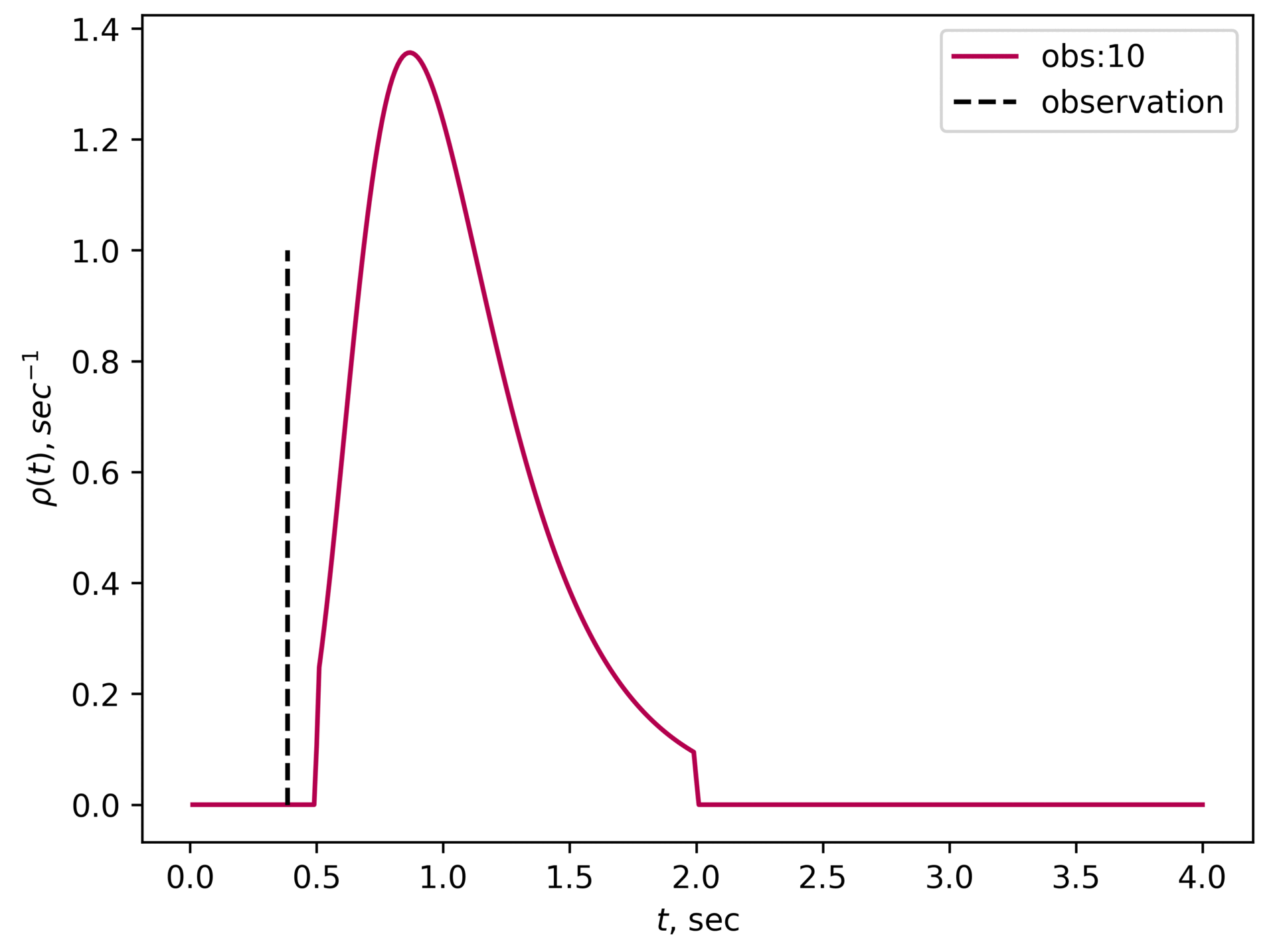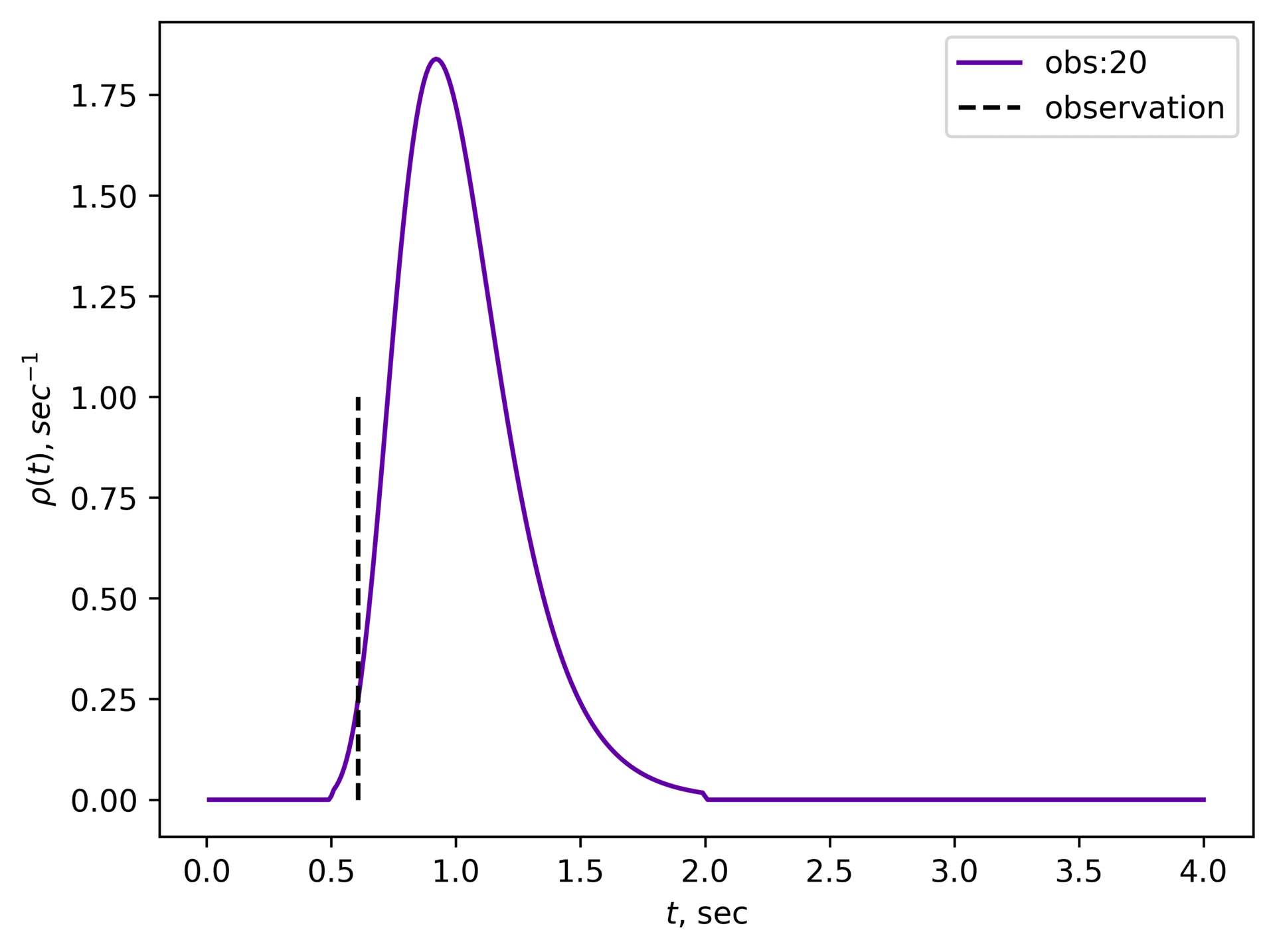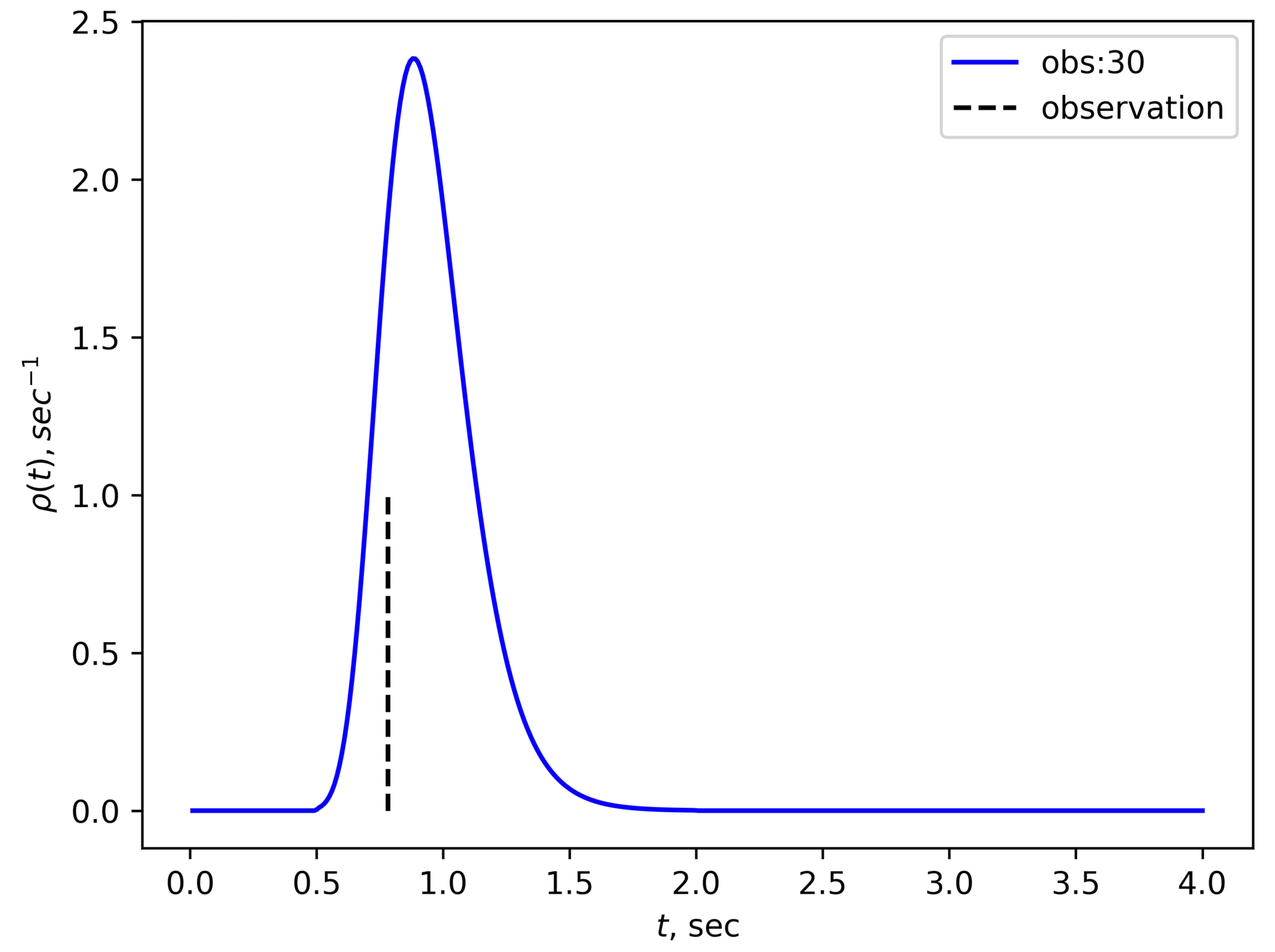
It gets narrower and higher,and in the limit, there should be a high peak around the true value of (in our case sec).
His algorithm is as follows:
Algorithm 2
- Set some prior distribution
- Get the observation of a decay time of a specific particle.
- Calculate posterior distribution using Bayes theorem:
Set this posterior distribution as the new prior distribution and return to step 2.
Now let's get back to Veronica and her stock trading problem.
To get the bayesian method working, Veronica needs a space of hypotheses. Each hypothesis is a distribution which generates observations, and with each observation she would narrow down this space of hypothesis.
Before she runs a computer, she has some idea of what the utility function might look like. She thinks that it is a smooth function with a single peak, but she does not know the value of this peak or where it is on the axis. Also, she accounts for a potential noise in predictions from the computer.
Colormap of one such hypothesis (which shows with what probability each pair can be outputed) with a specific value of peak hight and -coordinate of this peak would look like this (the blacker the region, the higher the probability):
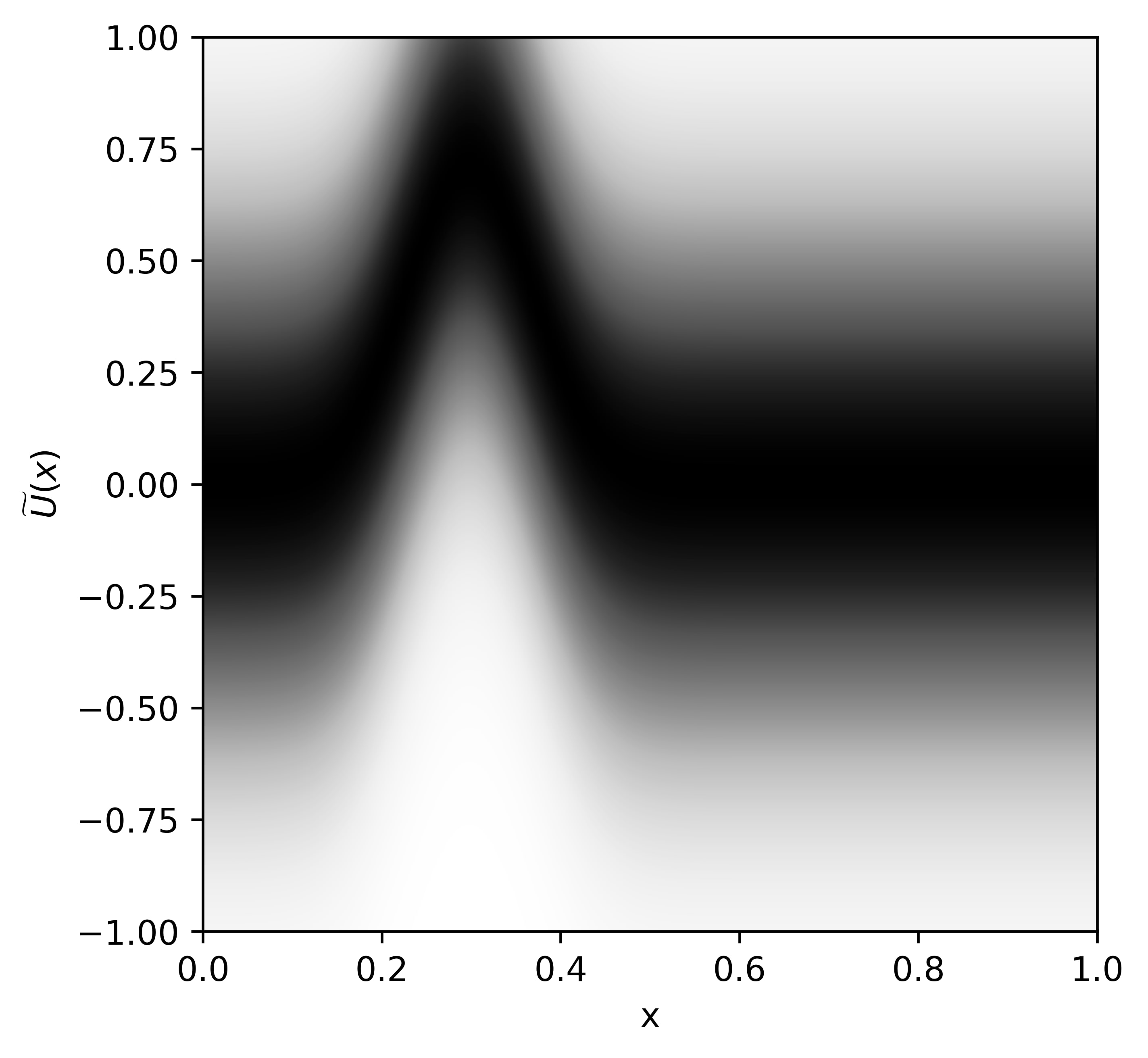
Each hypothesis is defined by values of and . For each pair () we can have a probability distribution on . The formula for each hypothesis is:
, where
( and are chosen beforehand, and equal 0.07 and 0.2 accordingly). The formula is a bit messy, but essentially it is a function with one peak, blurred with noise.
We can show all of these hypotheses and the probabilities Veronica is assigning to them on a colormap:
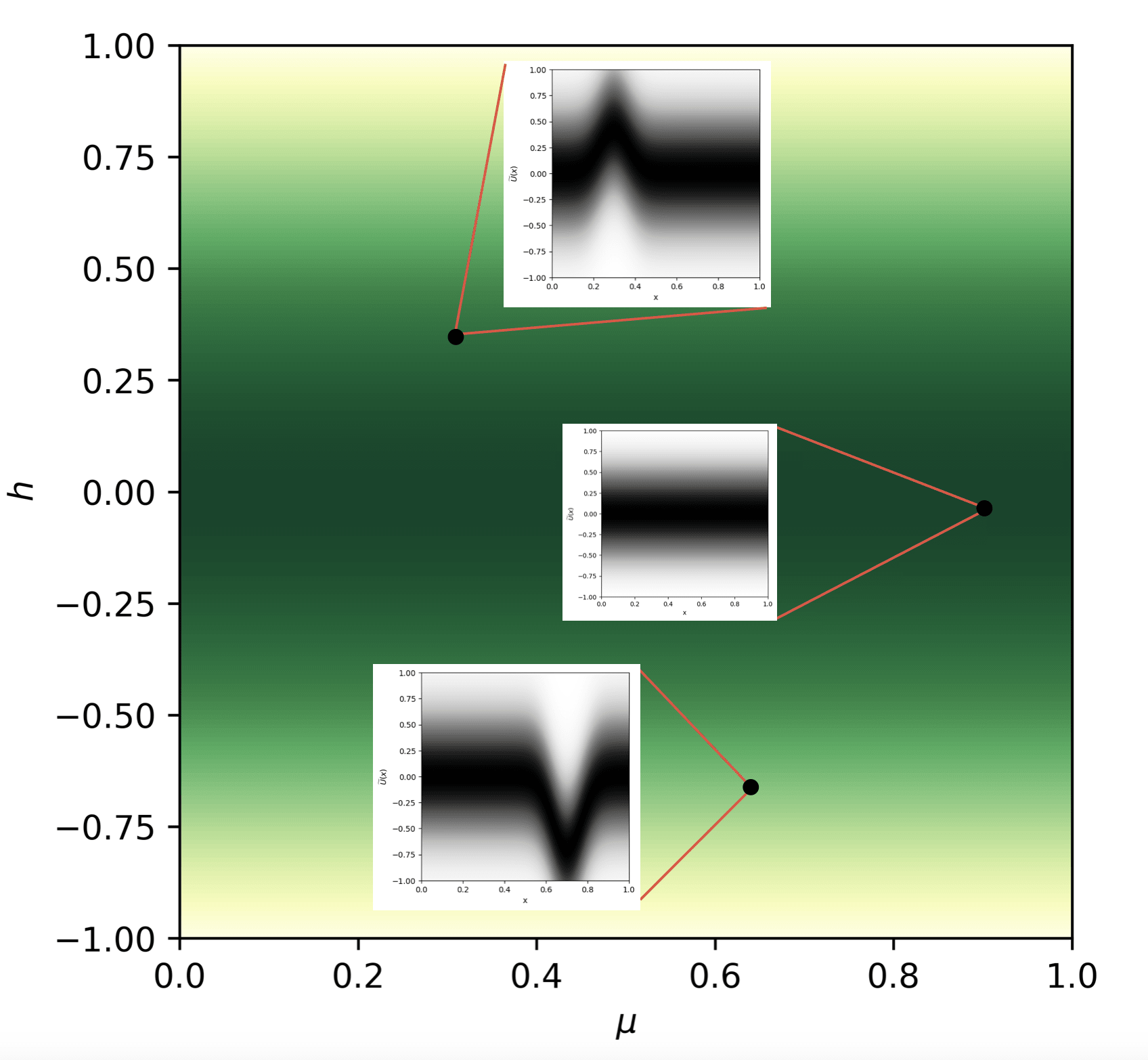
This is Veronica's prior distribution on -hypotheses. Veronica is skeptical of high peaks, so she puts low prior probability on them. The formula for her prior distribution:
( is the magnitude of her skepticism of high peaks, in our case ).
It is worth noting that the actual distribution she gets from the computer is not represented by any hypothesis. But this wouldn't be much of a problem in this setting.
Now Veronica can apply Bayes formula using the observations (in this case, observation is a prediction she recieves from a computer, in the next formula they would be noted as ).
She can make updates each time she gets an observation, just like Roman in the previous example.
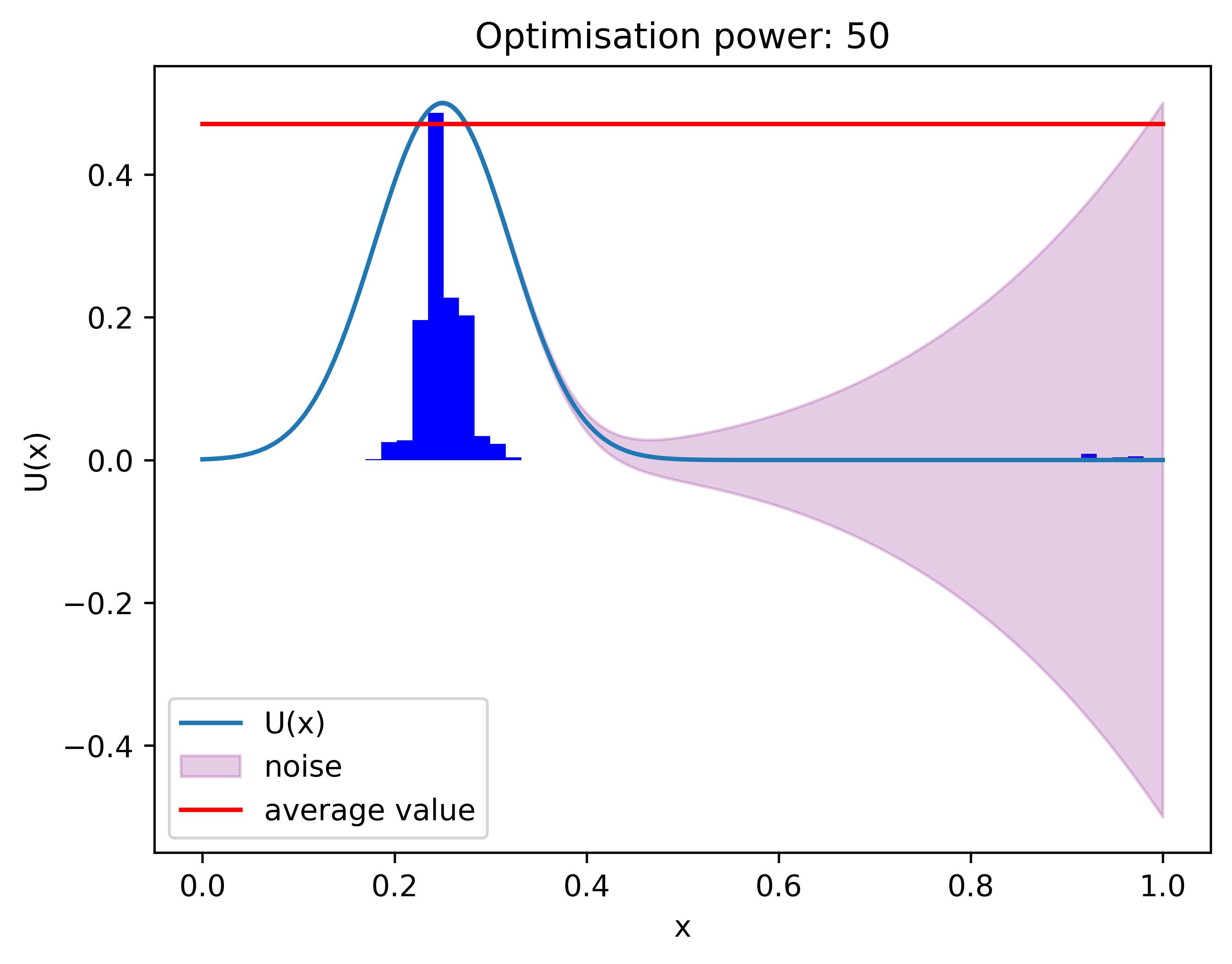
Here is a GIF of a 50 consecutive updates (the red dot represents the observation, and the green dot represents the hypothesis that is closest to the actual distribution we get from the computer):
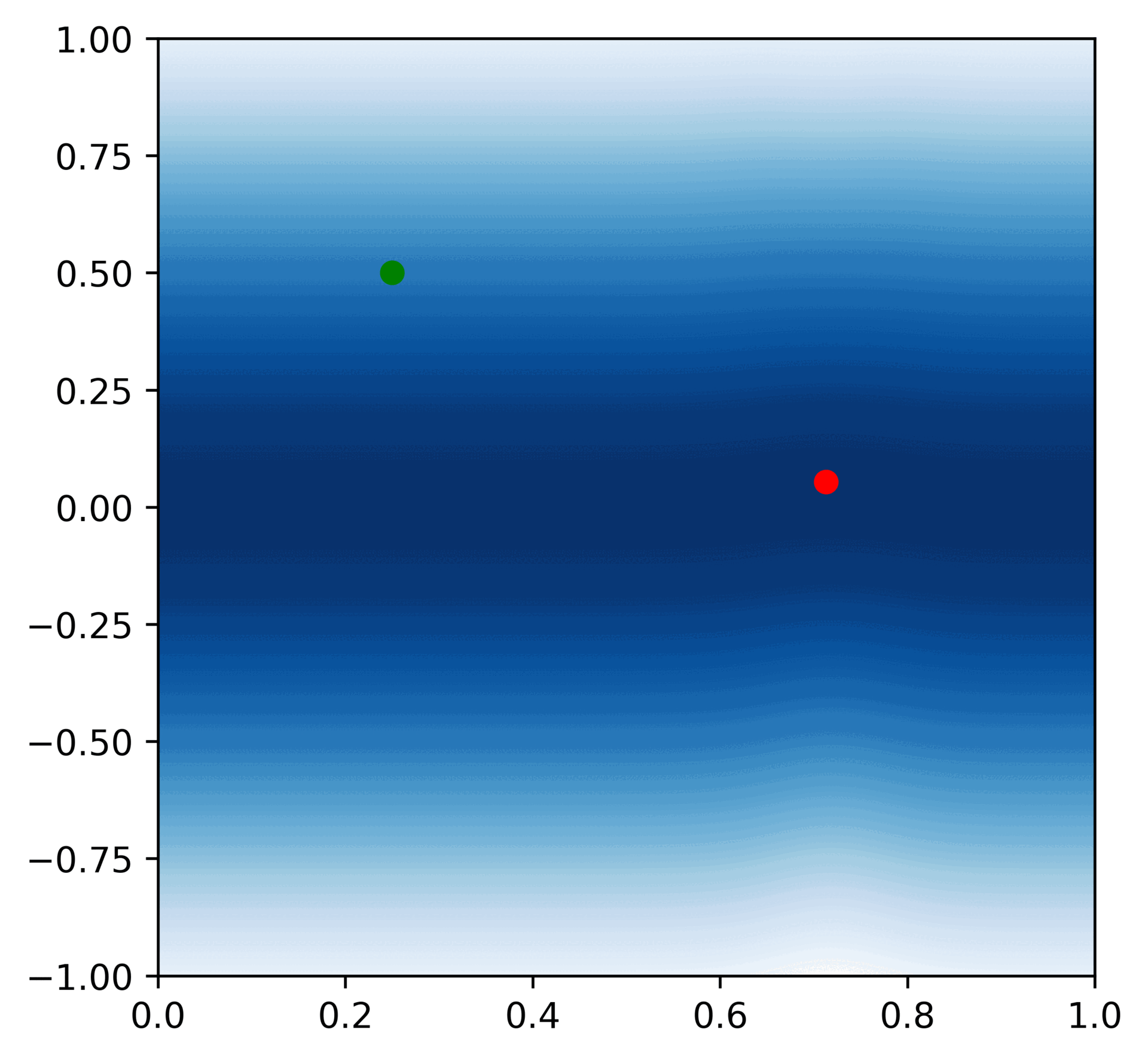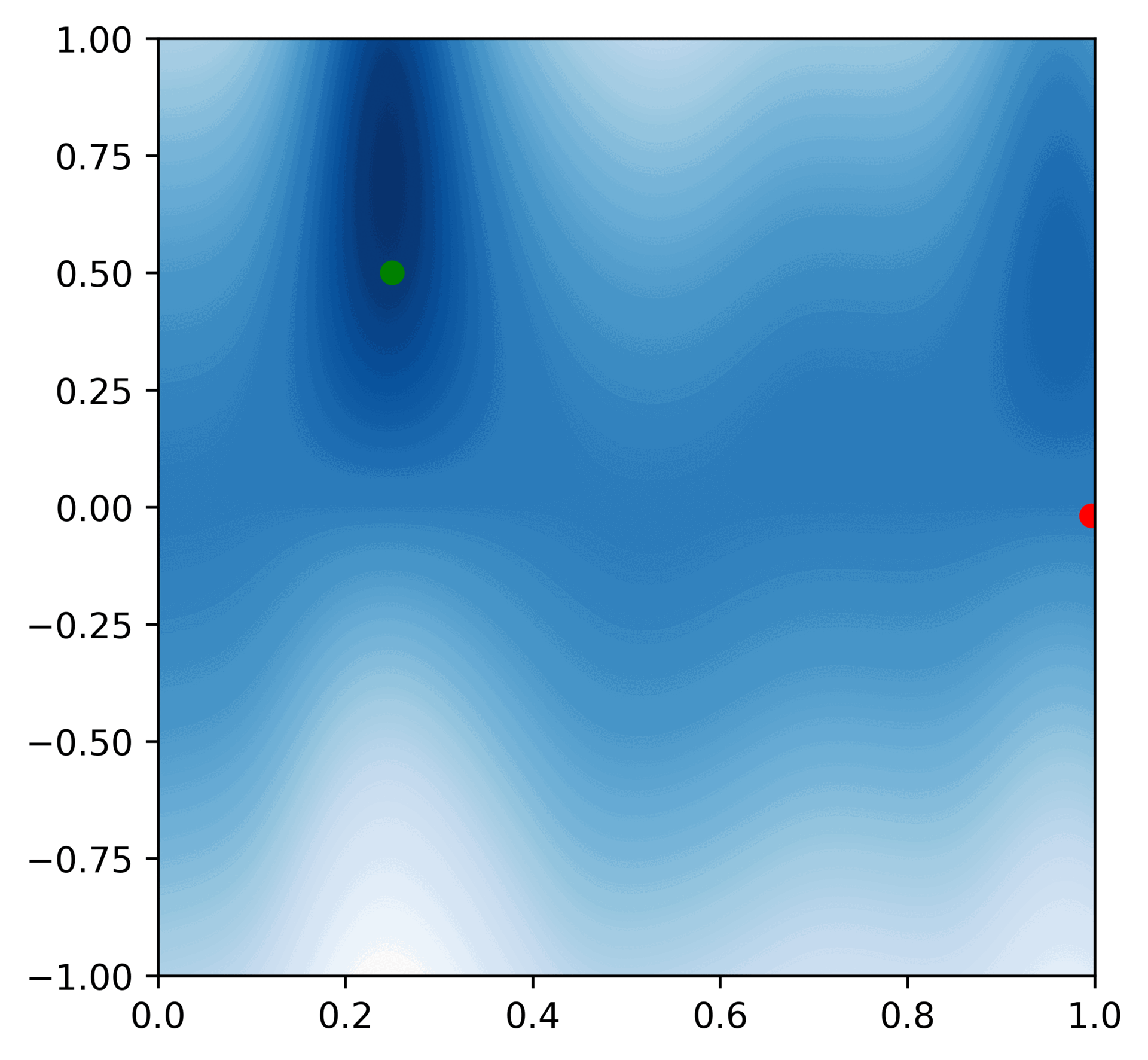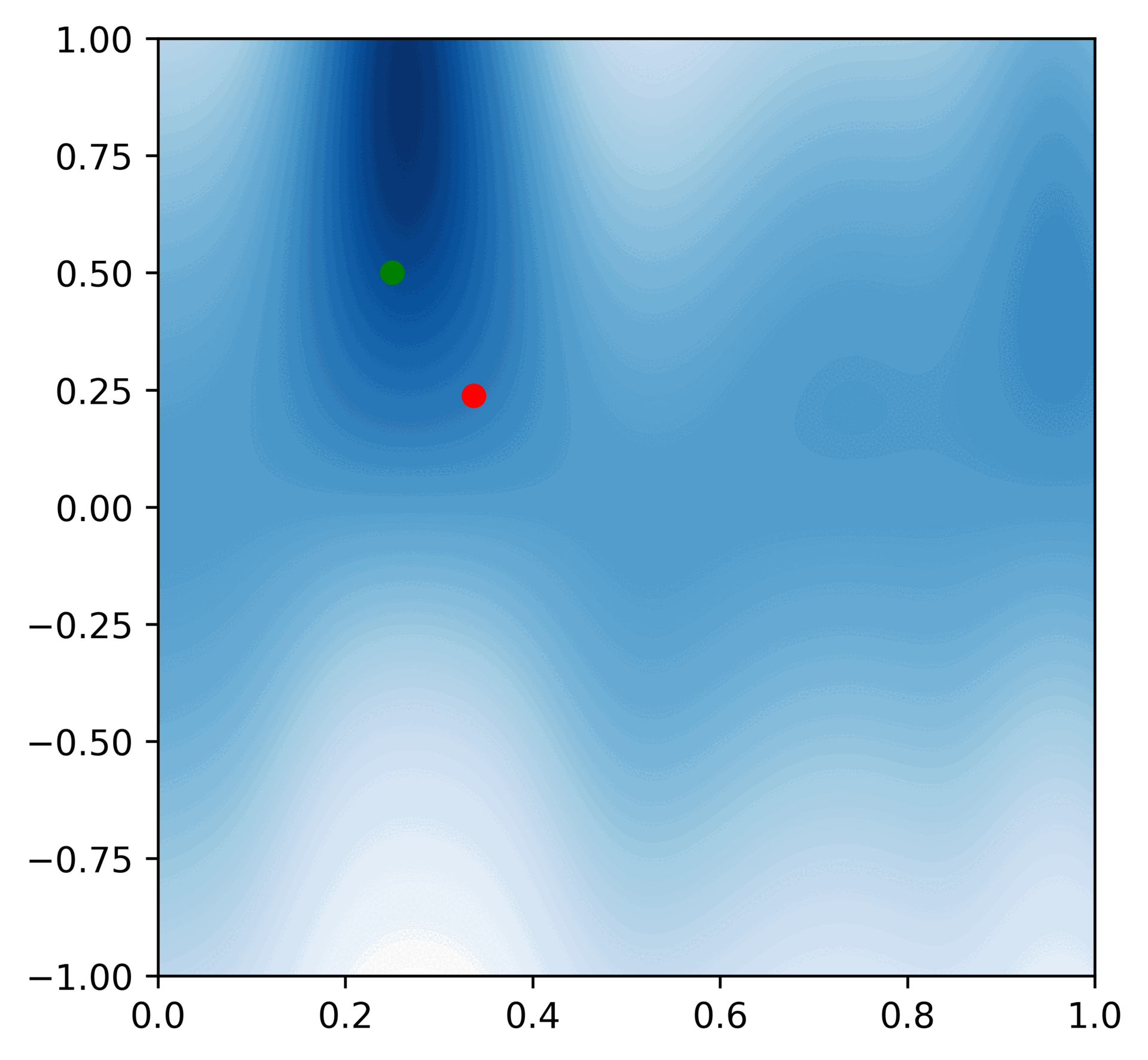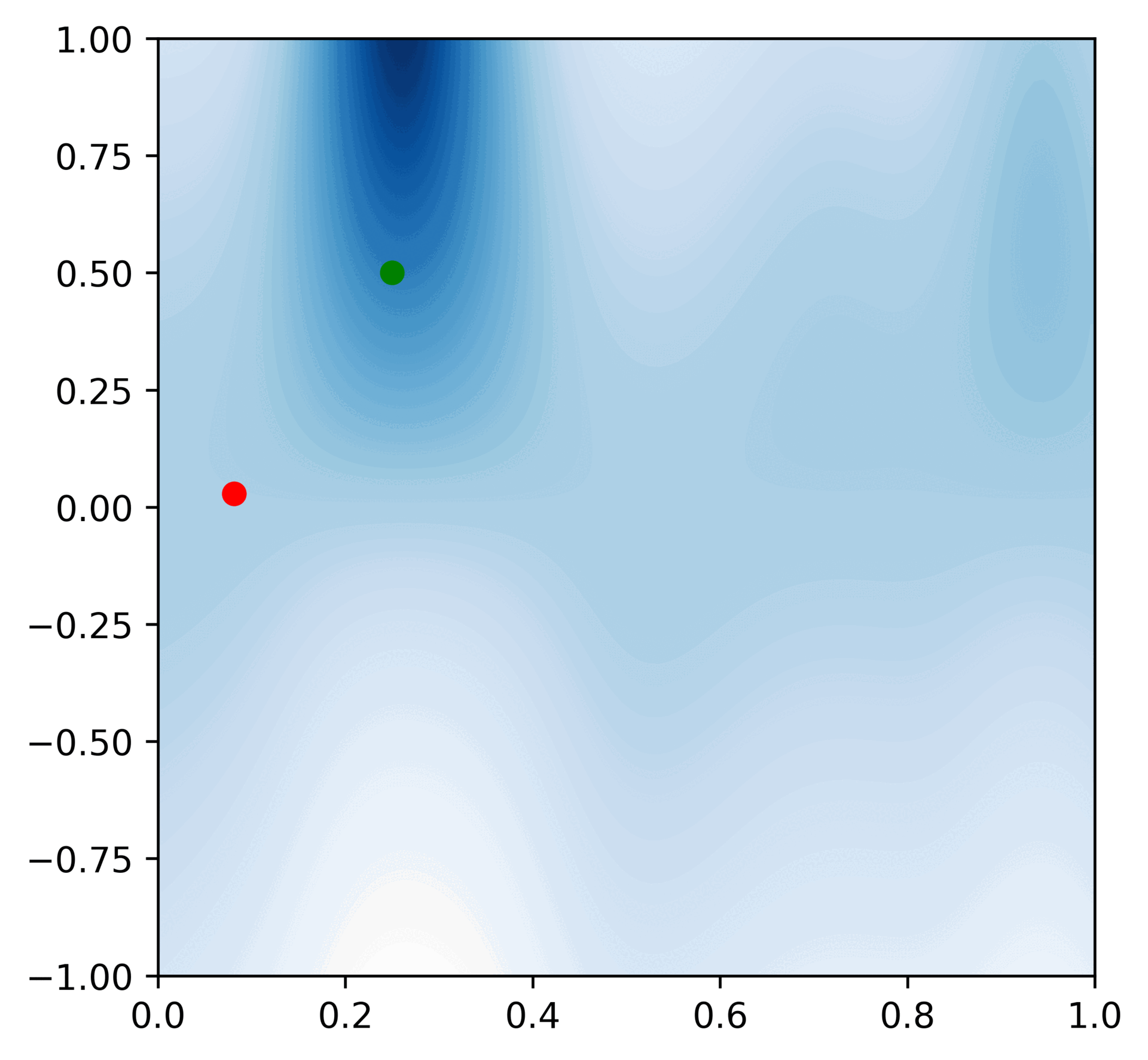
After this process, Veronica can take the most likely hypothesis and use its value as her best guess for when to sell stocks. Here's her algorithm:
Algorithm 3
- Set some prior distribution
- Get the observation of a prediction from a computer.
- Calculate posterior distribution using Bayes theorem:
Set this posterior distribution as new prior distribution and go to step 2. Repeat N times.
Get the most likely hypothesis from last distribution and sell stocks at .
Here is the distribution of these values with 5 updates.
And here is the distribution with 50 updates.
And here is the graph of the average value depending on the number of updates.
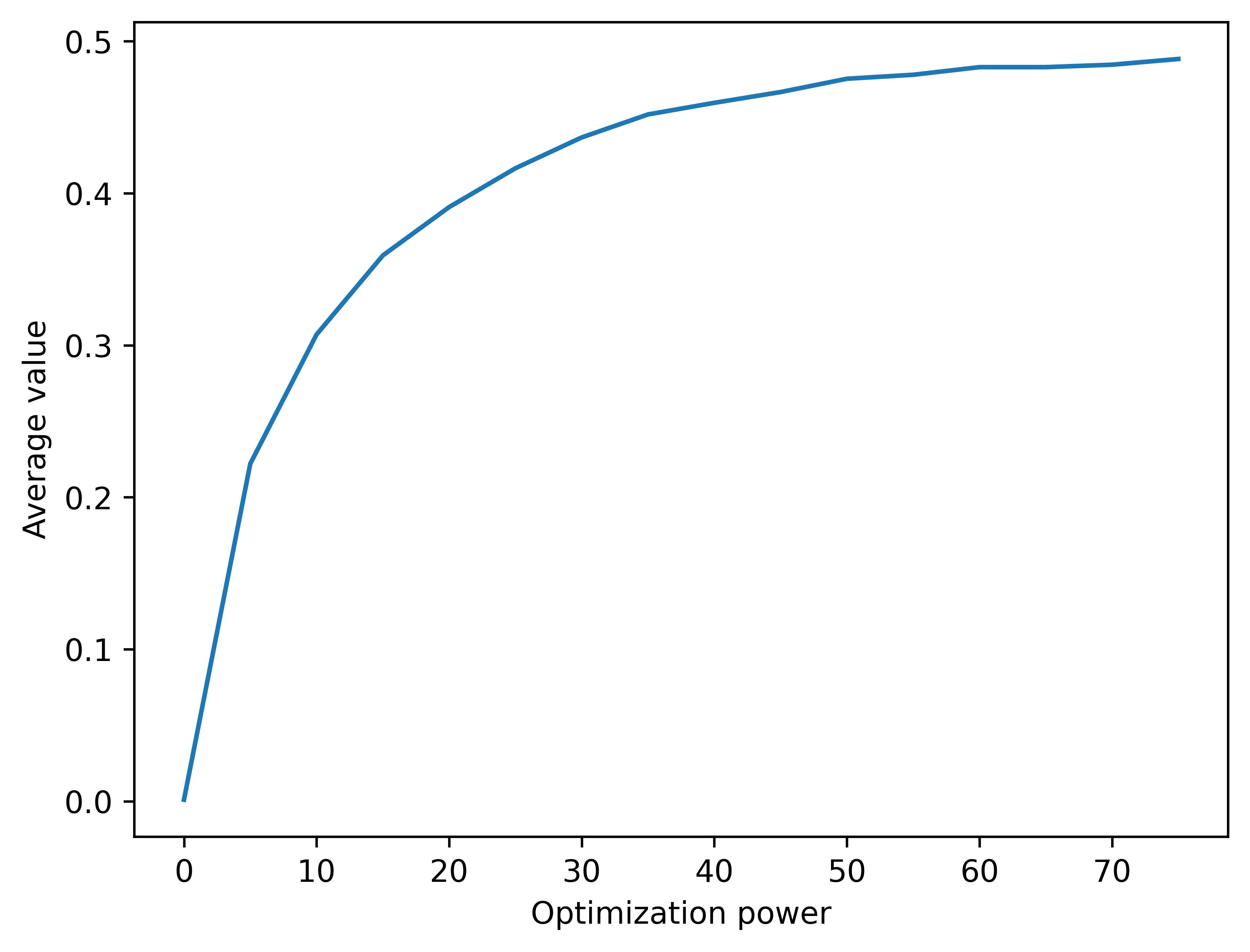
This graph is now again monotonic. Optimizer's curse is cured with Bayesian remedy.
Optimizer's curse arises not only with the kind of optimizer I showed here. It could also be a problem with SGD and other optimizers.
Chapter 4: Goodhart's curse
Now I want to ask a question I had while reading the course materials. Here’s a quote from a post on Goodhart's Curse:
Even if is locally an unbiased estimator of , optimizing will seek out what we would regard as "errors in the definition", places where diverges upward from . Optimizing for a high may implicitly seek out regions where is high; that is, places where is lower than . This may especially include regions of the outcome space or policy space where the value learning system was subject to great variance; that is, places where the value learning worked poorly or ran into a snag.
Now here is my question: if is unbiased estimator of (that is, if we sample a lot of for some fixed and average them out, we get ), what do we mean by ? If we mean (expected value), than this is is 0 everywhere, if we mean the random variable , then what do we mean by areas where it is high?
- ^
Note that this is not a realistic graph of how much money Veronica would make if she sold some stock, this function is chosen for ease of demonstration.
- ^
The probability density of distributions is not to the scale on y-axis, I scaled them down so everything would fit in one plot.
- ^
- ^
Where is an indicator function
3 comments
Comments sorted by top scores.
comment by TheManxLoiner · 2024-12-13T19:10:00.257Z · LW(p) · GW(p)
What do we mean by ?
I think the setting is:
- We have a true value function
- We have a process to learn an estimate of . We run this process once and we get
- We then ask an AI system to act so as to maximize (its estimate of human values)
So in this context, is just a fixed function measuring the error between the learnt values and true values.
I think confusion could be using the term to represent both a single instance or the random variable/process.
↑ comment by Roman Malov · 2024-12-13T22:03:38.002Z · LW(p) · GW(p)
So, is a random variable in the sense that it is drawn from a distribution of functions, and the expected value of those functions at each point is equal to . Am I understanding you correctly?
↑ comment by TheManxLoiner · 2024-12-14T00:24:26.234Z · LW(p) · GW(p)
Sounds sensible to me!