Beyond Biomarkers: Understanding Multiscale Causality
post by Matěj Nekoranec (matej-nekoranec) · 2024-07-07T09:56:22.554Z · LW · GW · 0 commentsContents
Top-down or bottom-up? We are generalization machines Let’s select the right operational space Personomics: A Multiscale Approach Conclusion Reference list: None No comments

In exercise science, we typically derive causality in a bottom-up manner. When we evaluate performance, we assess factors such as cardiovascular capacity, metabolic efficiency, or muscular contractile capacity. However, I’ve always grappled with a chicken-and-egg dilemma in exercise physiology. This dilemma highlights the challenge of understanding sequences of events where mutual dependencies exist — each outcome depends on a preceding event, and vice versa.
Consider a simple example: biomechanical testing of an NBA basketball player might reveal that certain parameters (x, y, z) predispose them to excel at that competition level. However, we can also argue that these parameters likely developed in response to the competitive demands of the game. As players advance to higher leagues, they face greater technical demands, which drive their development and the evolution of their biomechanical parameters.
This creates a paradoxical situation. If structure gives rise to behaviour, but structure simultaneously evolves in response to our behaviour, where does causality lie? What comes first, the chicken or the egg? Does causality arise from the bottom-up physiological blueprint or the top-down constraints of a specific ecological niche?
Top-down or bottom-up?
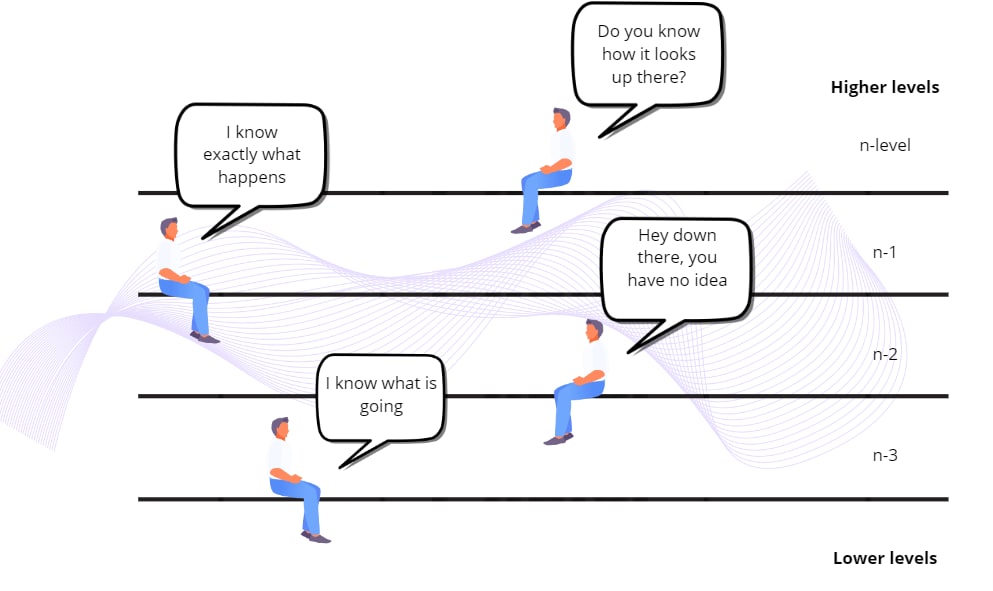
To understand biological causation, I came across an interesting stream of research from the well-known Oxford physiologist Denis Noble, the founder of modern electrophysiology of the heart. He discusses the concept of biological relativity, where no level of the biological hierarchy holds privileged causation (Noble et al., 2019). In simple terms, lower levels are responsible for dynamics, while higher levels constrain the lower levels by setting boundary conditions.
Noble explains that differential equations at lower biological levels have an infinite set of solutions until constrained by higher-level boundaries. This means that multiscale nested biological systems operate as a two-way street, with higher emergent biological levels imposing boundary conditions on lower levels, thus serving as top-down controllers. While low-level descriptions define the system’s dynamics, solutions to these dynamics come from top-down constraints — such as an athlete making decisions. Therefore, how does the adaptation work across different levels?
We are generalization machines
One of the outstanding pre-print papers published this year introduced a novel concept that reformulates adaptation as rules of induction (Buckley et al., 2024)
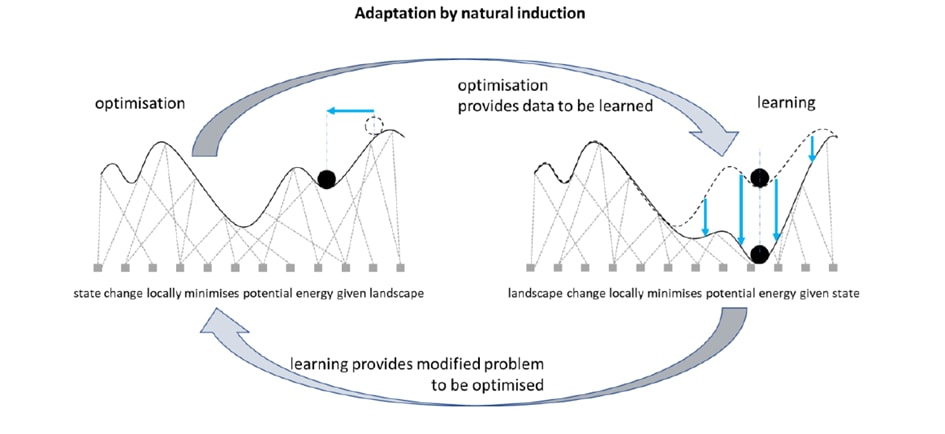
In simple terms, the concept works as follows: Consider the cardiovascular system. We induce top-down stimuli in the form of a specific problem with certain parameters — for instance, training. The system’s immediate reaction is to optimize the problem space within its existing structural capacity. This means we seek a local minimum (see diagram below) as a solution to the immediate external problem we are addressing. If the external problem persists, the model parameters must change to find a better solution than the initial local minimum. For example, when someone begins training, their cardiovascular response will be very aggressive. However, over time, the model parameters will adjust to better handle the external problem of exercise (change in structure). This suggests that structure evolves, to some extent, as a generalized model of the problem we have at hand. However, this, in turn, changes the problem space again in a re-iterative loop. Direct citation from Buckley et al. (2019) can help us further understand the concept.
“Recognizing that adaptation requires learning, and learning requires generalization, and generalization requires an inductive bias, helps us to understand how adaptation really works and what is required.”
It means that every level/scale of the biological hierarchy learns or generalizes based on the data they receive. However, the type of data varies across different biological scales and structures. For example, strength and endurance athletes’ heart has distinct structural and morphological adaptations, such as heart wall thickness (Mihl et al., 2008). It suggests that generalization occurs based on the perceived stress from the heart’s perspective, which can be simplified as a function of pressure and blood volume.
Conceptualizing through natural induction can be useful, but it must always be connected to the relevant operational domain — selecting the appropriate scales in which to operate and understanding the problems that respective scales need to solve. For instance, muscles must work in tandem with genetic blueprint and current structural capacity to respond to bottom-up demands imposed on the muscle. Therefore, how useful is it to describe large-scale behavior, such as athletic performance, using only respective scales (e.g., physiological scale) without considering multiscale causal interactions?
Let’s select the right operational space
Olav Aleksander Bu, coach of Kristian Blummenfelt, well said that at a certain point, we need to put all the granularity into a black box because trying to understand every detail may not be useful. When dealing with a concept as broad as performance that spans multiple scales, we should prioritize scale and subsequent interventions where we can get the biggest “bang for your buck”.
As we go deeper into the biological hierarchy, we get a much larger combinatorial space that can be hard to implement at the practical level. Combinatorial space means, that we cannot try to solve all the problems at all scales at the same time, because the amount of interventions across scales would be almost infinite. For example, heart structural remodelling and the lactate shuttle mechanism are operating at completely different temporal-spatial scales. However, they both respond to the same top-down constraint, exercise, which increases metabolic rate (production of lactate) and therefore the need for increased blood flow.
As we move up the biological hierarchy, data representation becomes more coarse-grained and less detailed. By selecting high-level parameter for assessment (e.g., total training volume), we can assume shift in multiple low-level biological biomarkers simultaneously without the need to go down and try to assess every low-level biological parameter individually at their respective scales. But it also can be limiting as the missing granularity of the high-level data can limit our understanding in certain scenarios.
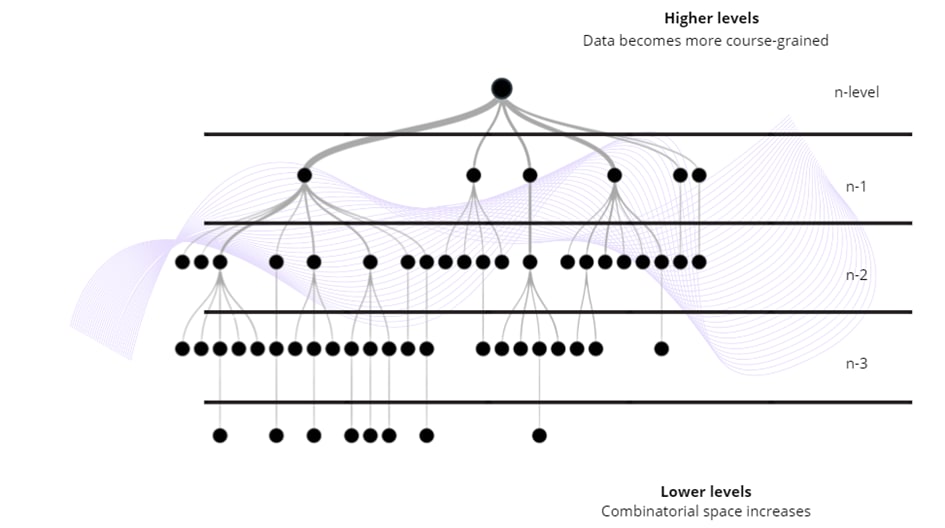
Furthermore, data representation isn’t solely limited to a third-person perspective. As we said, the performance spans multiple scales, and one of them is the scale of being me as an athlete, making decisions and perceiving the world from my position. It’s been established that factors such as perceived self-efficacy could be linked to an understanding of injuries (Olmedilla et al., 2018). For example, we can quantify load in terms of overall running volume, but how athletes subjectively interpret this load varies widely. Does this suggest that third-person data reflects objective truth while first-person data represents subjective bias? Not necessarily. These perspectives simply operate at different scales. Total training load can be linked to the physiological level, while self-efficacy reflects personal perception and experiences within a higher level representing an athlete who is contextually embedded within the environment.
It leads us to the idea that connecting different scales is the way to go in modern data analysis. However, despite significant advances in data acquisition and analytics, I have a feeling that we lack conceptual agreement on the way we conduct analysis. Sometimes, we operate in completely different operational domains/scales and then argue about who has better predictive ability. Is there a way how to connect it all together?
Personomics: A Multiscale Approach
Going back to the original question of causality, most of the research places independent variables (the variable that causes the change) in lower biological hierarchies. Research focuses mostly on the (X influences Y) axis, and ignores the systems’ influences, usually treating causality within specific causal model nearly as “invariant” — something that remains constant in every reference frame.
Why is it important? Independent causal variables attract interventions. However, multi-scale problems require multi-scale understanding. While in certain situations we are spot on, in others we can completely miss the larger picture. For example, the longstanding debate over whether to treat depression from a molecular standpoint (via SSRIs) or if it is necessary to consider higher-level scale and incorporate, for instance, exercise (Singh et al., 2023).
Personomics is a very niche stream of conceptual research, however, it effectively targets the multiscale nature of the human body (Constant, 2024; Ziegelstein, 2017). While focusing solely on either bottom-up or top-down approaches can be limiting, connecting these levels can be an effective strategy to understand and address global challenges such as ageing, precision medicine, or high performance.
Personomics could work by stratifying data according to specific contextual situations and examining how closely related scales correlate. For instance, we can find very low heart rate variability via wearable devices, which show high sympathetic activation and low coping with stress. However, these findings are meaningful only when considering his personal context, as the person is currently experiencing a stressful period after losing his job. In this case, first-person assessments, such as self-reports, can serve as a gateway to contextualizing physiological data.
This approach aligns well with the current development of Natural Language Processing (NLP), which can be used for differentiating semantic and contextual clusters (through self-reports) and linking them to specific physiological responses. By integrating NLP with low-level physiology, we can create a more comprehensive understanding of how different scales of the biological hierarchy interact.
Conclusion
We started this article with the classic chicken-and-egg dilemma, only to discover that it’s less about which came first and more about the constant cross-talk between scales. The key concept lies in the operational domain we choose to analyze, considering both the dynamics of lower-level scales and the constraints of top-down influences. Causality usually attracts interventions, but we never know whether causality fixed to a certain scale is the most effective. In some instances, it is on a molecular scale, while in other scenarios, we need to move to the personal or societal scale. This conceptualization shows the way for a data holism (e.g., personomics) that can dynamically transverse biological hierarchies and shows us the most relevant interventions.
Reference list:
Buckley, C. L., Lewens, T., Levin, M., Millidge, B., Tschantz, A., & Watson, R. A. (2024). Natural Induction: Spontaneous adaptive organisation without natural selection. In bioRxiv. https://doi.org/10.1101/2024.02.28.582499
Constant, A. (2024). Personomics: Precision psychiatry done right. The British Journal for the Philosophy of Science. https://doi.org/10.1086/729750
Lee, B. Y., Bartsch, S. M., Mui, Y., Haidari, L. A., Spiker, M. L., & Gittelsohn, J. (2017). A systems approach to obesity. Nutrition Reviews, 75(suppl 1), 94–106. https://doi.org/10.1093/nutrit/nuw049
Mihl, C., Dassen, W. R. M., & Kuipers, H. (2008). Cardiac remodelling: concentric versus eccentric hypertrophy in strength and endurance athletes. Netherlands Heart Journal: Monthly Journal of the Netherlands Society of Cardiology and the Netherlands Heart Foundation, 16(4), 129–133. https://doi.org/10.1007/BF03086131
Noble, R., Tasaki, K., Noble, P. J., & Noble, D. (2019). Biological Relativity requires circular causality but not symmetry of causation: So, where, what and when are the boundaries? Frontiers in Physiology, 10, 827. https://doi.org/10.3389/fphys.2019.00827
Olmedilla, A., Rubio, V. J., Fuster-Parra, P., Pujals, C., & García-Mas, A. (2018). A Bayesian approach to sport injuries likelihood: Does player’s self-efficacy and environmental factors plays the main role? Frontiers in Psychology, 9. https://doi.org/10.3389/fpsyg.2018.01174
Singh, B., Olds, T., Curtis, R., Dumuid, D., Virgara, R., Watson, A., Szeto, K., O’Connor, E., Ferguson, T., Eglitis, E., Miatke, A., Simpson, C. E., & Maher, C. (2023). Effectiveness of physical activity interventions for improving depression, anxiety and distress: an overview of systematic reviews. British Journal of Sports Medicine, 57(18), 1203–1209. https://doi.org/10.1136/bjsports-2022-106195
Ziegelstein, R. C. (2020). Personomics: The missing link in the evolution from precision medicine to personalized medicine. In The Road from Nanomedicine to Precision Medicine (pp. 957–966). Jenny Stanford Publishing.
0 comments
Comments sorted by top scores.