A gentle introduction to sparse autoencoders
post by Nick Jiang (nick-jiang) · 2024-09-02T18:11:47.086Z · LW · GW · 0 commentsContents
Background Sparse Autoencoders To all the fans of bridges 🌉 Growth in LLM interfaces, and beyond Closing thoughts None No comments
Sparse autoencoders (SAEs) are the current hot topic 🔥 in the interpretability world. In late May, Anthropic released a paper that shows how to use sparse autoencoders to effectively break down the internal reasoning of Claude 3 (Anthropic’s LLM) . Shortly after, OpenAI published a paper successfully applying a similar procedure for GPT4. What’s exciting about SAEs is that, for the first time, they provide a repeatable, scalable method to peer inside virtually any transformer-based LLM today. In this introduction, I want to unpack the jargon, intuition, and technical details behind SAEs. This post is targeted for technical folks without a background in interpretability; it extracts what I believe are the most important insights in the history leading up to SAEs. I’ll mainly focus on the Anthropic line of research, but there are many research groups, academic and industry, that have played pivotal roles in getting to where we are[1].
Background
Since the moment LLMs took off in the early 2020s, we’ve really only had one clear way to understand how models work: feed some text in, and see what comes out. They’re a black box in all other respects! LLMs are blobs of 1s and 0s that magically speak. The goal of interpretability has always been to give us the tools and methods to understand LLMs beyond input/output.
SAEs are part of a branch of interpretability called mechanistic interpretability, which hypothesizes that LLMs can essentially be reverse-engineered into computer programs. This approach is commonly thought of as “bottom-up” because we’re searching for individual, function-like mechanisms that work together to produce the final output.
In this introduction, you won’t need to understand the nitty-gritty details of LLMs. However, one thing to know is that they’re made up of successive layers of attention blocks and multi-layer perceptions (MLPs), which are neural networks, repeated in structure.

One natural thought is that if we understand what each layer’s output means, we can decipher the “program steps” the LLM undertakes. We call the n-dimensional space of all possible outputs from the MLP the neuron activation space. We tend to study the neuron activation space because the MLP has been thought to perform the “reasoning” role of the LLM.
If we are to take a bottom-up method of reasoning, we would expect that neuron activations can be broken down into more fundamental vectors in neuron activation space. These vectors would correspond with distinct, “atomic” concepts like “German shepherd” or “San Francisco”. We usually refer to these fundamental vectors and concepts together as features. Think of features as variables in our hypothetical computer program. For clarity, I’ll refer to the vector as the feature vector and the associated meaning as the feature description. The simplest way to represent this idea is with a linear decomposition of neuron activations:
Notation: = neuron activations, F = # of features, = feature vector (assumed to be a unit vector), and = feature activation, which is the strength to which a feature is present in the neuron activations.
There are two primary implications from this setup, inspired by intuition and roughly shown in toy experiments:
- Sparsity: Most things in the real world can be described in a few ways. Imagine trying to explain the concept of a “coffee mug”: cup size, color, and functionality are the most important, but the names of celestial bodies and algebraic theories are likely not. As a result, we can expect that when decomposing the neuron activations for “coffee mug,” most of the feature activations will be zero. Sparsity is the idea that only a small portion of our feature vectors are useful for composing neuron activations of neural networks.
- Superposition: Imagine trying to create a vocabulary of “concepts” that would be able to represent anything in the world. We’d want this vocabulary to be as big as possible! The problem is that our neuron activations are n-dimensional, so once our vocabulary passes n features, the feature vectors will start to interfere with one another because they can no longer be linearly independent[2]. The superposition hypothesis[3] states that a model learns to have almost-orthogonal feature vectors [4]. Superposition allows a large number of features to exist in a small dimensional space.
To summarize, we have a couple of questions:
- How can we recover feature vectors and feature activations from neuron activations?
- How can we attach semantic meaning (ie. feature descriptions) to these recovered feature vectors?
- How can we make our set of features as large as possible?
- How can we induce sparsity in our decomposition?
This is where sparse autoencoders come in.
Sparse Autoencoders
Let’s break sparse autoencoders down into “sparse” and “autoencoder”. Created in the 1990s, autoencoders were initially designed for dimensionality reduction and compression. They’re neural networks that take an input x, compress it to a “hidden” layer with a smaller dimension, and try to reconstruct x. The step of compressing is called encoding, and the reconstructing is called decoding.
We make an autoencoder sparse by adding an L1 penalty[5] to the loss term in order to align as many activations of the hidden layer to zero as possible.
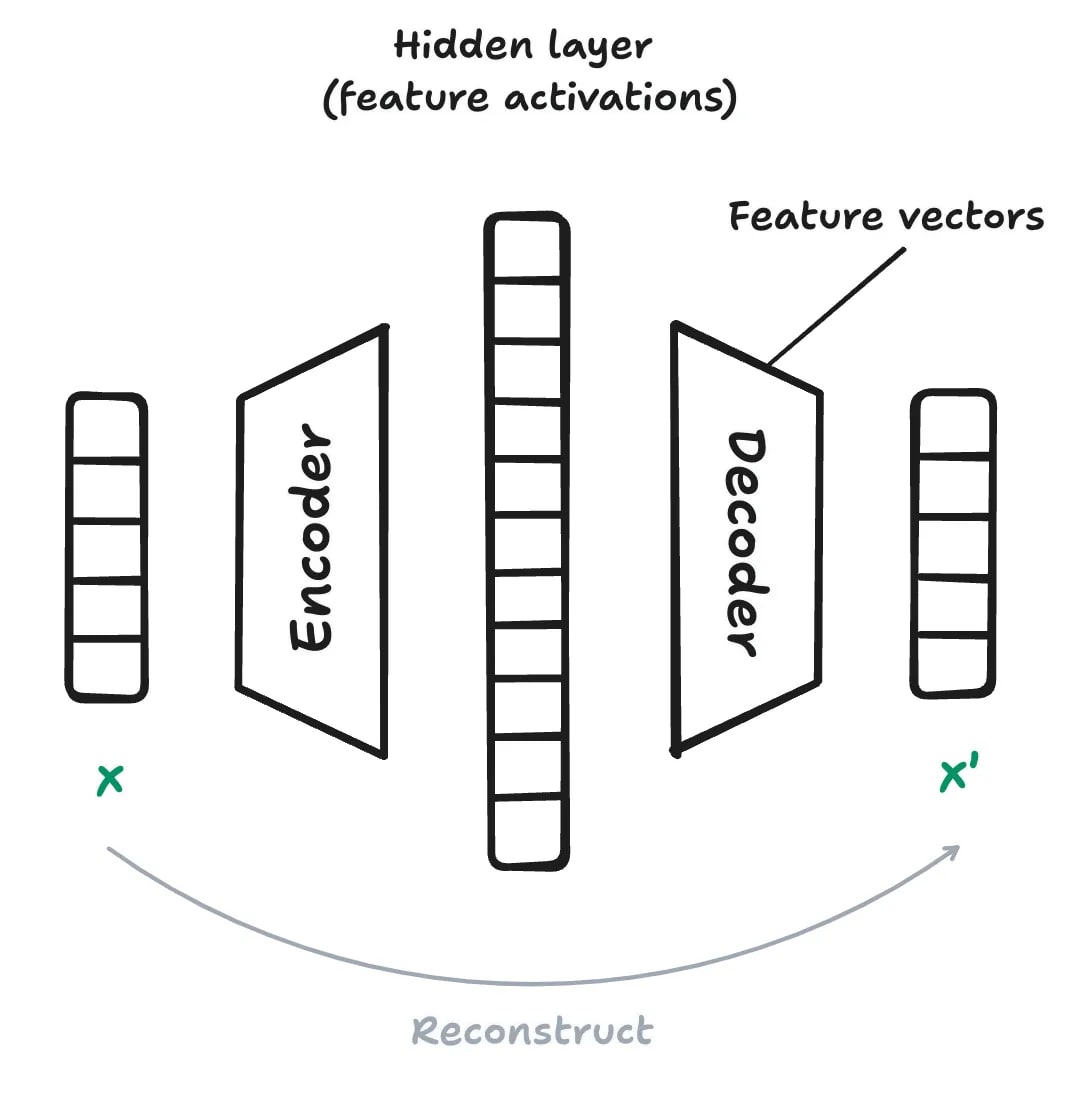
For our use case, the hidden layer's activations are the feature activations, and the decoder weights are the feature vectors. Thus, if we want to set the number of possible features to 1M, we set the dimensional size of the hidden layer to 1M. Unlike traditional autoencoders, our hidden dimension size will be much larger than the input’s dimension size because we want our set of features (ie. our “vocabulary of concepts”) to be as big as possible.
The Anthropic researchers train their SAEs on the neuron activations of a middle layer[6] of a LLM. They feed the MLP output into the SAE, extract the feature vectors/activations, and send the reconstructed embedding back into the LLM[7].

To associate semantic meaning with the feature vectors, the researchers run a set of texts[8] through the models. Then, for each feature, they collect the text instances where the corresponding feature activation is high and create a description that characterizes the collected instances.
Long story short, this procedure works well! The main concern is that the collected instances won’t have a clear relationship with each other. We want features to be “atomic” and have a singular, consistent description. Note that inducing sparsity in our feature activations is very useful for this goal. Why? The counterfactual is that at the extreme, all of the features have high activations for all of our text (which is diverse), in which case it’d be difficult to assign a particular description to each feature. Inducing sparsity in our autoencoder causes only the most important feature vectors to activate, allowing us to focus the feature description with fewer text samples.
Inducing sparsity also incentivizes superposition to occur because the SAE will learn a more efficient reconstruction of the input that minimizes interference among feature vectors (ie. encouraging near-orthogonality).
To all the fans of bridges 🌉
The Anthropic researchers examined a few specific features out of a pool of millions of possible features. One such example (meme) is a feature that activates on text relating to the Golden Gate Bridge.

It looks like we have a feature that corresponds with the Golden Gate Bridge, but isn’t there a possibility that this could all be a coincidence? I mean, how can we really know that this feature—a seemingly random n-dimensional vector—corresponds with the Golden Gate?
One supporting piece of evidence is that if we artificially increase the feature activation (ex. 10x the weight factor) associated with this feature, we get a model that increasingly talks about the Golden Gate Bridge until it even thinks that it is the Golden Gate Bridge.

Anthropic’s investigation was more comprehensive than I’ll get into, but here’s a general map if you’re interested:
- Can we cluster features with similar meanings together? See feature neighborhoods.
- How causal is the link between features and their identified meanings? See feature attributions and ablations
- What other types of specific features were identified? See features for code error detection, famous people, and deceptive / power-seeking thoughts.
- To what extent does our feature set cover the entirety of the LLM’s knowledge? For example, if an LLM can list all boroughs in London, are there features for each borough? See feature completeness.[9]
Growth in LLM interfaces, and beyond
One fascinating consequence of this recent work on SAEs has been completely outside the field of interpretability: the space of LLM interfaces. As I stated earlier, there’s always been one way of interacting with LLMs: stick something in, and get something out. This one-dimensional interaction was largely a product of our inability to understand the internals of ML models. Opening the black box of LLMs has created an opportunity for more degrees of freedom and creative play. Recently, I saw a demo on Twitter that lets users use sliders to change the properties of an image (ex. more “cat-like”, more “cowboy”). What it does is use a SAE to compute the features of a vision model and provide sliders to increase or decrease their feature activations[10].
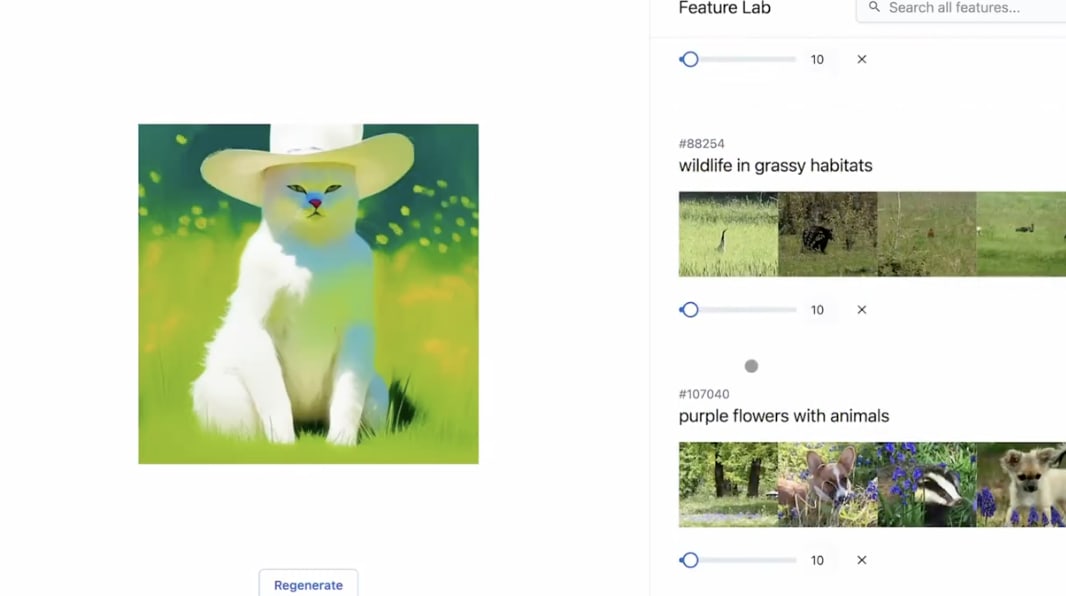
One next step might be investigating different ways to interact with features. So far, we’re just performing addition or subtraction of feature activations. It’s unclear, for instance, how much we should increase a feature activation by and whether increasing the activation by similar amounts creates the same strength of change for two different features.
Another issue is that we currently cannot control the features we get out of the SAE, in large part because our goal was to take an existing representation of the neural network and interpret it. But is it possible to induce a few features that we want? That way, we’d be able to exercise more control over the sliders—just another degree of freedom that could be taken advantage of.
Closing thoughts
SAEs are promising because they help us interpret the activations of intermediate layers of a LLM. As a result, we can have a better grasp of what the LLM is “seeing” as our input text gets transformed again and again across the layers. However, we’re still so far from understanding LLMs.
SAEs could be a completely wrong way of interpreting LLMs. After all, it’s surprising that you can break down neuron activations as a linear combination of interpretable features when a neural network incorporates non-linearity (ex. RELU activation functions). History has certainly shown us how we can be easily fooled by simple theories. But we’re much farther along from the days when I’d ask ML researchers how their models work, and they’d meet my eyes with a blank stare. SAEs are probably the first concrete result which shows that mechanistic interpretability can actually work, and I’m incredibly excited to see where they’ll take us[11].
- ^
Here are some great non-Anthropic papers:
- Transformer visualization via dictionary learning, Yun et al.
- Sparse Autoencoders Find Highly Interpretable Features in Language Models, Cunningham at al.
- ^
As a refresher, a set of vectors is linearly independent if no vector can be written as a linear combination of the rest.
- ^
See here for more details on superposition.
- ^
The only way for n vectors in n-dimensional space to be linearly independent is if they’re all orthogonal. Past n, the best we can intuitively do is for the vectors to be “almost-orthogonal”. Mathematically, this turns out to increase the number of possible features exponentially with respect to the dimension size. See the Johnson–Lindenstrauss lemma.
- ^
This is actually just the most common way sparsity is induced. There are also k-sparse autoencoders, which were used in OpenAI’s recent paper, that always enforce k hidden nodes to be nonzero in training.
- ^
Why a middle layer? As they say, the middle layer “is likely to contain interesting, abstract features”.
- ^
For more information of the SAE setup, see the “Problem Setup” of Anthropic’s paper here.
- ^
The Anthropic researchers use The Pile and Common Crawl, two common research datasets. See here for more details.
- ^
In my opinion, this exploration was a weaker part of their investigation because you’re only looking at one layer of the model.
- ^
- ^
This primer is about what’s been done so far, but I think it’s important to note the many open questions (at least that I have) after these recent papers:
- How can we avoid “dead” features, which are those that almost never have high activations when passing our dataset of text through the SAE? Anthropic found that a whopping 65% of their features were “dead” for their largest SAE, which doesn’t necessarily mean their results were wrong but just ineffectively gathered. This is fundamentally a problem with scaling SAEs. Eventually, we’ll want to train a SAE on each of the layer activations, not just the middle layer. However, if a high fraction of our features effectively don’t tell us anything, we’re wasting a ton of compute. Ideally, we want to set the number of possible features as high as possible in the SAE (Anthropic goes as high as 34M) to get as comprehensive of a feature set as possible.
- How true is superposition? None of the SAE work proves or disproves the original, motivating theory of superposition. Are the feature vectors Anthropic identified actually “almost-orthogonal”? In fact, this post [LW · GW] argues that the SAE set up by Anthropic is only identifying compositions of features, rather than the actual atomic units, and suggests adding another loss term to try to enforce non-orthogonality in the learned features.
- What if we investigate the weights of the model, not just its activations? It seems like the weights should be able to encode extractable information, and I feel that they tell us more directly about the actual reasoning / non-reasoning capabilities of LLMs.
- Are the features discovered “universal” in some way? Does “cat” have a similar feature direction in other LLMs and even across the different layers of the same model?
- At what point in the training cycle do SAE results become interpretable? Is there a correlation between this point and when other capabilities of an LLM, such as in-context learning or few-shot learning, develop?
0 comments
Comments sorted by top scores.