AISafety.info: What are Inductive Biases?
post by Algon · 2024-09-19T17:26:24.581Z · LW · GW · 4 commentsThis is a link post for https://aisafety.info/questions/NK46/What-are-inductive-biases
Contents
4 comments
AISafety.info writes AI safety intro content. We'd appreciate any feedback.
The inductive bias of a learning process is its tendency to learn particular kinds of patterns from data. It would help with AI alignment to know which learning processes have inductive biases toward patterns used in human cognition, and in particular human values.
In a learning process L, you have some class of models in which you look for an approximation M to some finite set of data D. This data is generated by some function f, which usually you don’t know. You want M to replicate the target function f as closely as possible. Since you can almost never get enough data to fully infer f, you have to hope that your learning process L will find an approximation M that is close to f even far from the training data. If there’s a class of target functions that L can approximate well, we say that L has an inductive bias toward such functions.
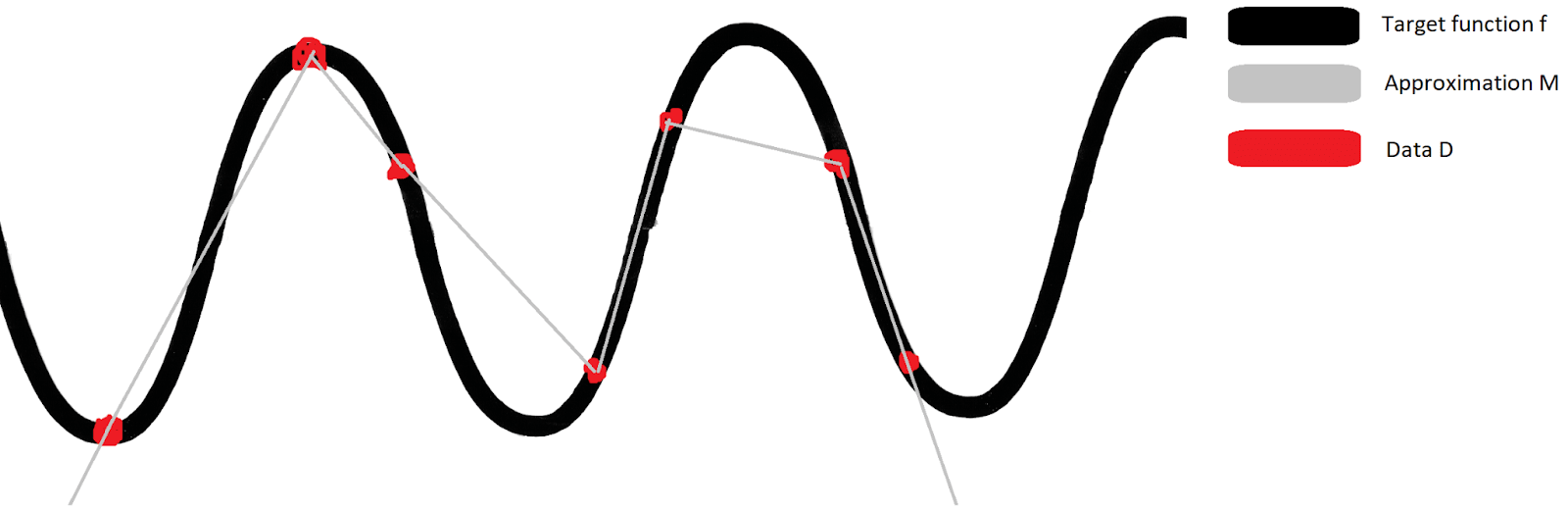
Example: Let’s say you want to predict how energetic you will feel over time. That’s your target function. So for a couple of days, whenever you get the chance, you log how energetic you feel (that’s your data D). And because you’re lazy, you decide to just draw straight lines between the data points. At the edges, you just keep drawing the outermost lines you got from D. That’s your learning process L, which will spit out some piecewise linear curve M. This is a poor learning process, for reasons we’ll get to in a bit.
You run the experiment, and then plot the results in Figure 1. The resulting gray line isn’t that bad an approximation — at least, not near existing data points. And if we have dense enough data within some range, the approximation therein will be arbitrarily good.
Far from our data points, our approximation M will fall indefinitely. This does not match our everyday experience, in which our energy fluctuates. This is a fundamental issue with this choice of L: it will never globally approximate a periodic function well[1], no matter how much data you give it. Almost all the functions that L can learn will keep growing or falling far outside the training data. That is an inductive bias of this learning process.[2]
Why does any of this matter for AI or AI alignment? Because we want our AI to have an inductive bias towards human values when learning what humans care about. Not only do we want it to fit the training data well, we also don’t want it to go crazy outside the data distribution, because ASI would likely experience distributional shift.[3]
We don’t know what the inductive biases of an ASI would be, and in particular if its inductive biases would match those of humans. But we can think about the implications of possible initial architectures for ASI. For instance, if ASI emerges from the deep learning paradigm, then it will probably start off with the inductive biases common to neural networks. For many architectures, we know that neural networks are biased towards low-frequency functions, even at initialization.
If we can determine if a given behavior is high-frequency, then we can have some confidence that neural networks will fail to learn it by default. Indeed, Nora Belrose and Quintin Pope have argued [AF · GW] that a treacherous turn is a high-frequency behavior as it involves a phase shift in behavior from the training distribution to the test distribution. This safety argument is an example of the sort of reasoning we could do if we knew the inductive biases of AI models.
- ^
Barring constant functions
- ^
We can easily see that L has the wrong bias, and think of ways to create a periodic function from the approximation by stitching together infinitely many copies of it. But that’s us intervening in L, so it doesn’t affect L’s inductive bias.
- ^
This is true even if only because an ASI would certainly have the power to cause the world to change drastically.
4 comments
Comments sorted by top scores.
comment by cubefox · 2024-09-25T15:11:08.707Z · LW(p) · GW(p)
For many architectures, we know that neural networks are biased towards low-frequency functions, even at initialization.
If we can determine if a given behavior is low-frequency, then we can have some confidence that neural networks will fail to learn it by default.
These statement seem to contradict each other?
Replies from: Algon↑ comment by Algon · 2024-09-25T20:20:28.348Z · LW(p) · GW(p)
That's an error. Thank you for pointing it out!
Replies from: cubefox↑ comment by cubefox · 2024-09-25T20:35:05.370Z · LW(p) · GW(p)
Okay, that makes more sense now. So the obvious question would be about the interpretation of low/high frequency. That's quite a low-level concept. Does it correspond to simplicity/complexity? Or underfitting/overfitting?
Replies from: Algon↑ comment by Algon · 2024-09-26T17:21:14.091Z · LW(p) · GW(p)
I think it's unclear what it corresponds to. I agree the concept is quite low-level. It doesn't seem obvious to me how to build up high-level concepts from "low-frequency" building blocks and judge if the result is low-frequency or not. That's one reason I'm not super-persuaded by Nora Belrose' argument that deception if high-frequency, as the argument seems too vague. However, it's not like anyone else is doing much better at the moment e.g. the claims that utility maximization has "low description length" are about as hand-wavy to me.