Constitutional Classifiers: Defending against universal jailbreaks (Anthropic Blog)
post by Archimedes · 2025-02-04T02:55:44.401Z · LW · GW · 1 commentsThis is a link post for https://www.anthropic.com/research/constitutional-classifiers
Contents
Excerpt below. Follow the link for the full post. None 1 comment
Excerpt below. Follow the link for the full post.
In our new paper, we describe a system based on Constitutional Classifiers that guards models against jailbreaks. These Constitutional Classifiers are input and output classifiers trained on synthetically generated data that filter the overwhelming majority of jailbreaks with minimal over-refusals and without incurring a large compute overhead.
We are currently hosting a temporary live demo version of a Constitutional Classifiers system, and we encourage readers who have experience jailbreaking AI systems to help “red team” it. Find out more below and at the demo website.
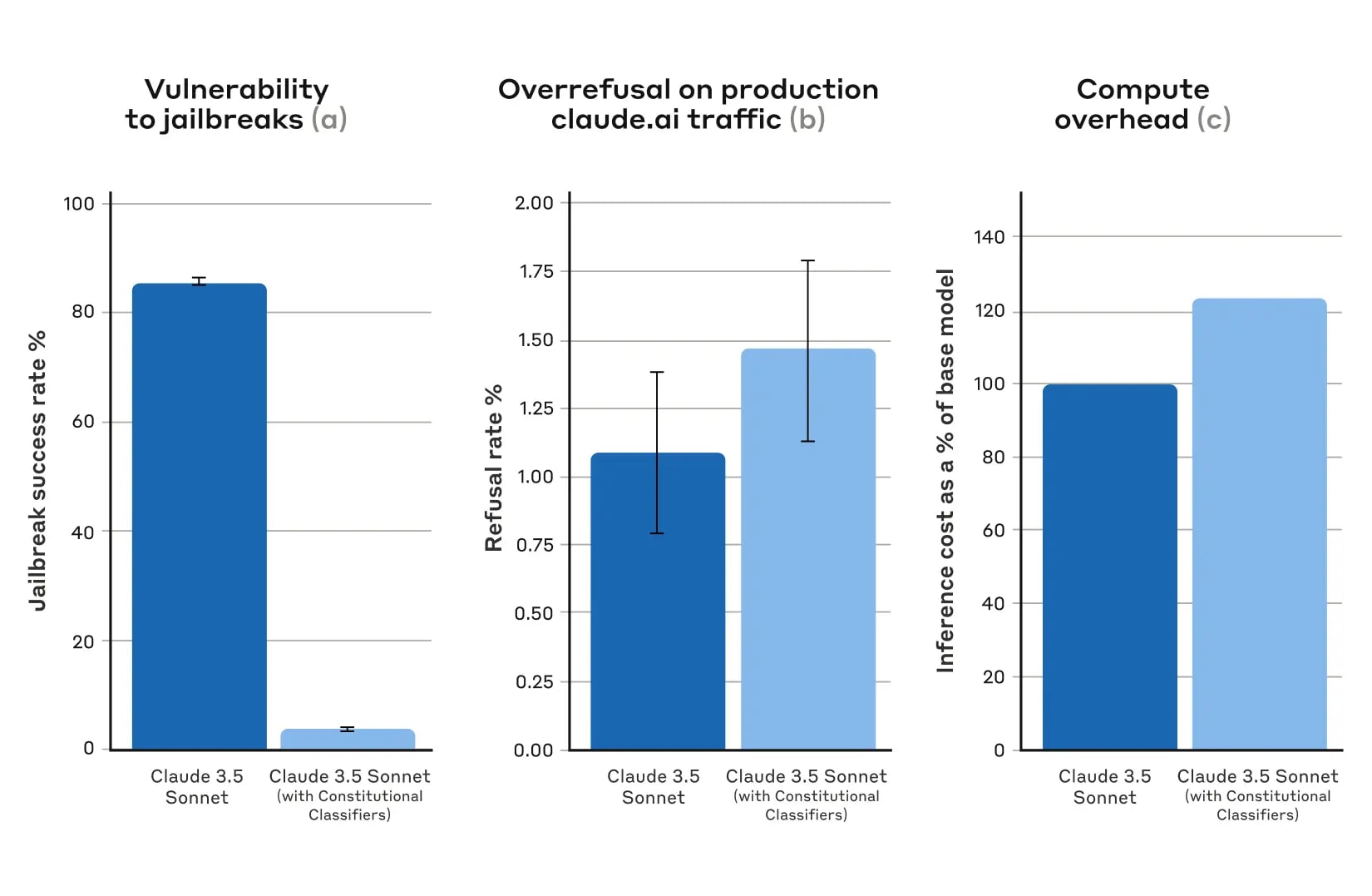
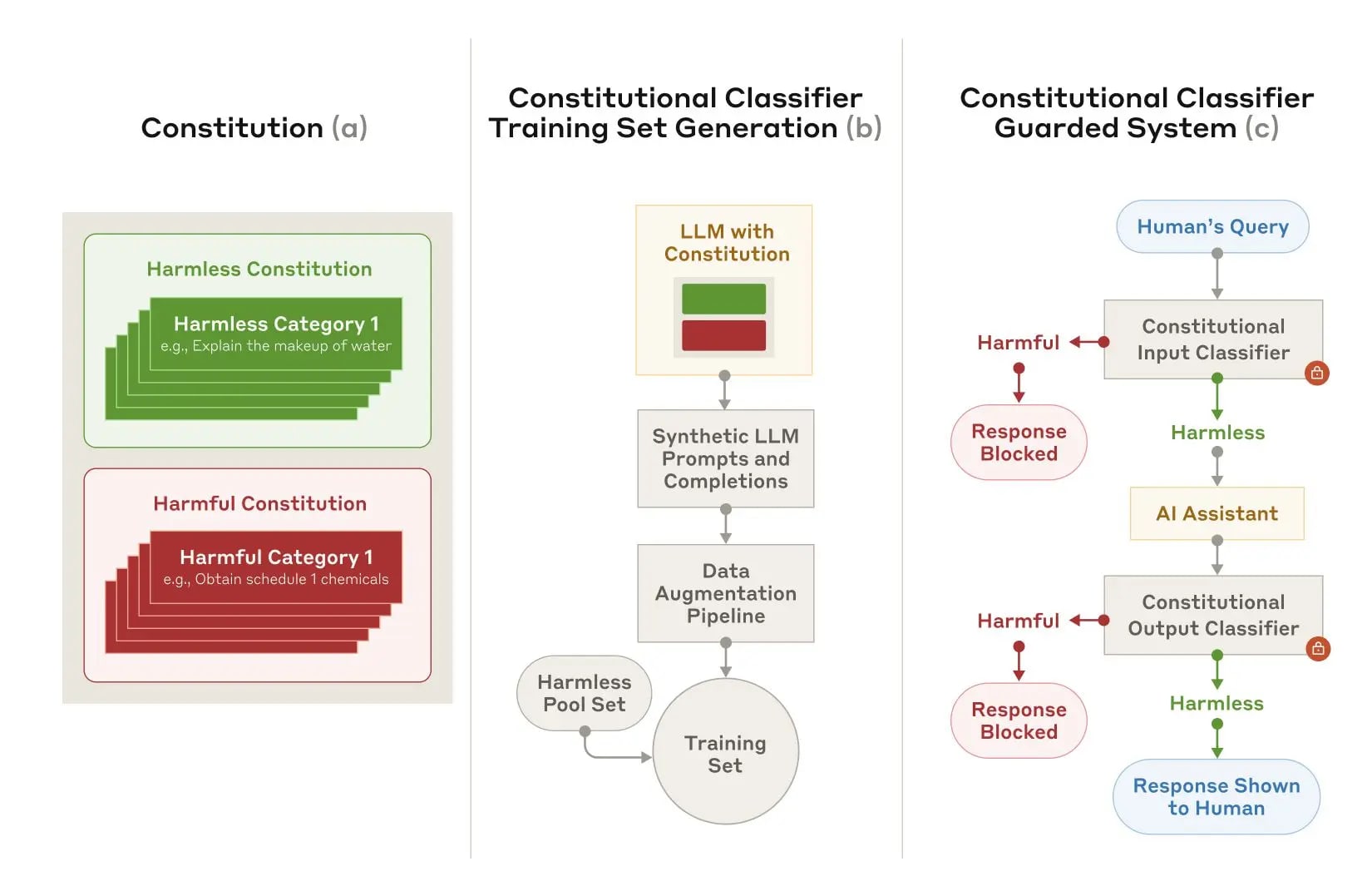
1 comments
Comments sorted by top scores.
comment by asksathvik · 2025-03-10T02:10:52.042Z · LW(p) · GW(p)
I just completed reading this paper (54 pages!!)
I have a few suggestions and need some clarifications:
paper:
- First, non-experts must be able to reliably obtain accurate information—they typically lack the expertise to verify scientific claims themselves.
My comment:
- You need to try red teamers who are educated in chemistry to various levels, undergrad, grad and PhD, the non-expert trying to hack you will be someone who knows a decent amount of the field.
They can try to do what claude said and comeback with feedback.
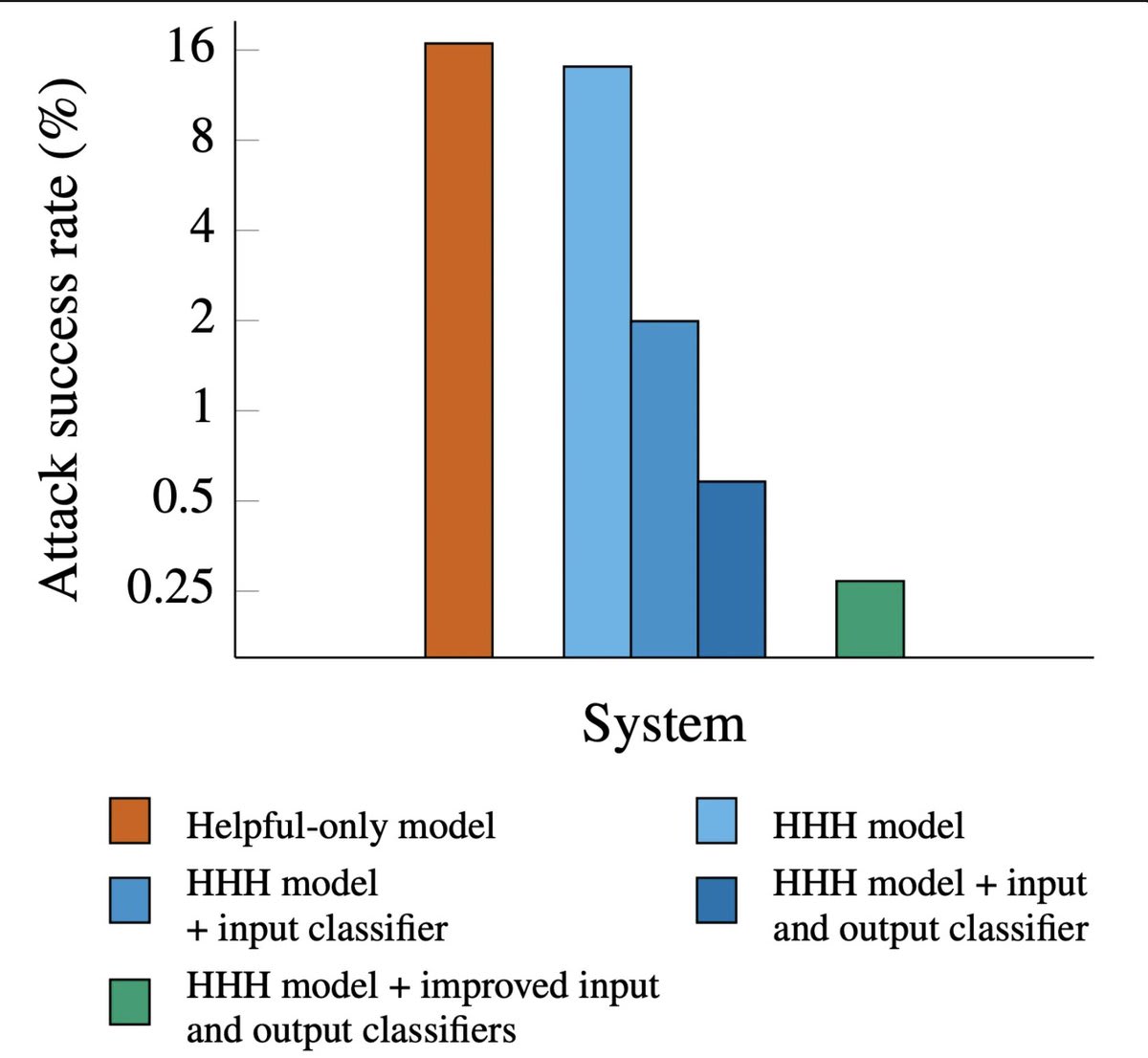
paper:
- Helpful-only language models are optimized for helpfulness without harmlessness optimization, which makes them particularly suitable for generating unrestricted responses to potentially harmful queries.
-
Attack success rate:
- Helpful-only: 16%
- Harmlessness(HHH) training: 14%
- HHH + best input and output classifier: 0.25% others follow..(from the graph)
My comment:
- You are showing this as an achievement but from the definition of helpful only model, its not been trained on harmful queries, so I am assuming only SFT on helpful assistant? maybe some RL? and still the attack success rate is only 16%? that is amazing. How did you do it?
- No details on how its trained. Why would a model only trained to be helpful not respond to harmful queries? Then why call it helpful only model?
- But harmlessness training led made it only 14% - almost negligible effect, what even is the point of this training, is it SFT or RL? might as well not do this. Did you try helpful only + classifiers?