Proposal: Align Systems Earlier In Training
post by OneManyNone (OMN) · 2023-05-16T16:24:39.077Z · LW · GW · 0 commentsContents
The First Challenge: Instruction vs Continuation The Second Challenge: Embedding Alignment Deep Proposed Initial Experiments How Well Can AI Differentiate Between Data Modes? If We Train Both Modes Simultaneously, Is There Transfer? Does It Make Sense to Start Alignment Early? Will the Solution Be Scalable? None No comments
Unfortunately, if AGI arrives in anything like the current industrial and political landscape, then it is all but inevitable that whoever builds it will not be able to hold onto it for long. Between leaks and espionage, it will not be long before the model is public and anyone can use it to do anything.
This means there is a huge risk from bad actors. Worse, this leaked model may be entirely unaligned, regardless of how much progress we make on alignment in the interim. This is because the current procedure for building and aligning LLMs does not actually even attempt alignment until very far into the process. But it is entirely possible model weights could be stolen before alignment is performed.
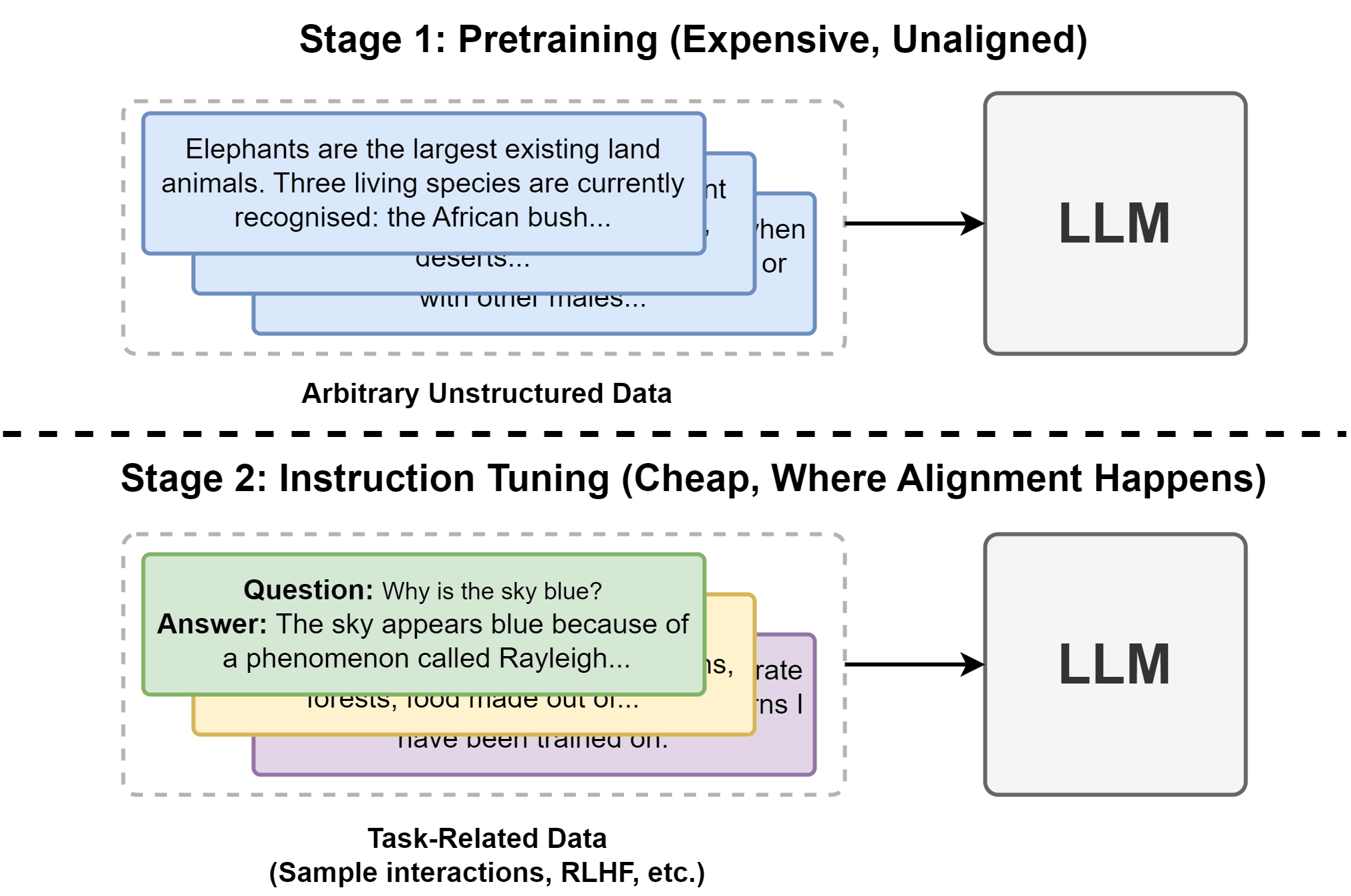
Critically, alignment does not happen until well after the network has gained all of its baseline knowledge.
Our one saving grace here is the fact that there really are only a few labs (like OpenAI, Anthropic, or Google) that are likely to build this AGI, assuming it comes soon.
Thus, my basic proposal is this: if we work under the assumption that any possible version of the AI can be stolen, then we need to build the AI so that it would, at any stage of training, refuse to behave in a malicious way. We need a process that builds an aligned AGI without first building unaligned systems along the way.
If we had such a process, then even if the system were stolen and queried at a snapshot part-way through stage one training, it would not be able to do something it shouldn't. This process would be very different from the current LLM training procedure, where an initial pre-training phase learns unorganized patterns from a huge amount of data, and is only aligned in a second, less data-heavy phase (see the image below).
As far as I'm aware, there has been very little practical research into how to build an such an LLM. The biggest reason is the simplest: it's really expensive to train an LLM, so it's hard to iterate on ideas that effect the early training, even for smaller 7 billion parameter models. So even if it is possible, we'd have to have high confidence our approach would work before trying it.
And I am not even sure it is possible. If it is, it may not buy us much time before a future version is built from scratch without safeguards. But suppose it were possible: how might we go about exploring such a possibility?
The First Challenge: Instruction vs Continuation
There are basically two ways LLMs are trained, corresponding to two distinct stages of training: in the first case it is trained as a mere text continuation engine, whereas in the second case it is an interactive interface.[2] But instead of thinking of these as stages of training, I'd prefer to think of them as the system being used in different modes or states, where we can say the LLM is in "Mode 1" during pretraining (where it's simply predicting next line in some text), and we can say it is in "Mode 2" when it's responding to instructions and performing tasks.
With this framing, my proposal is to explore ways in which we can simultaneously perform Mode 1 and Mode 2 training.[3]
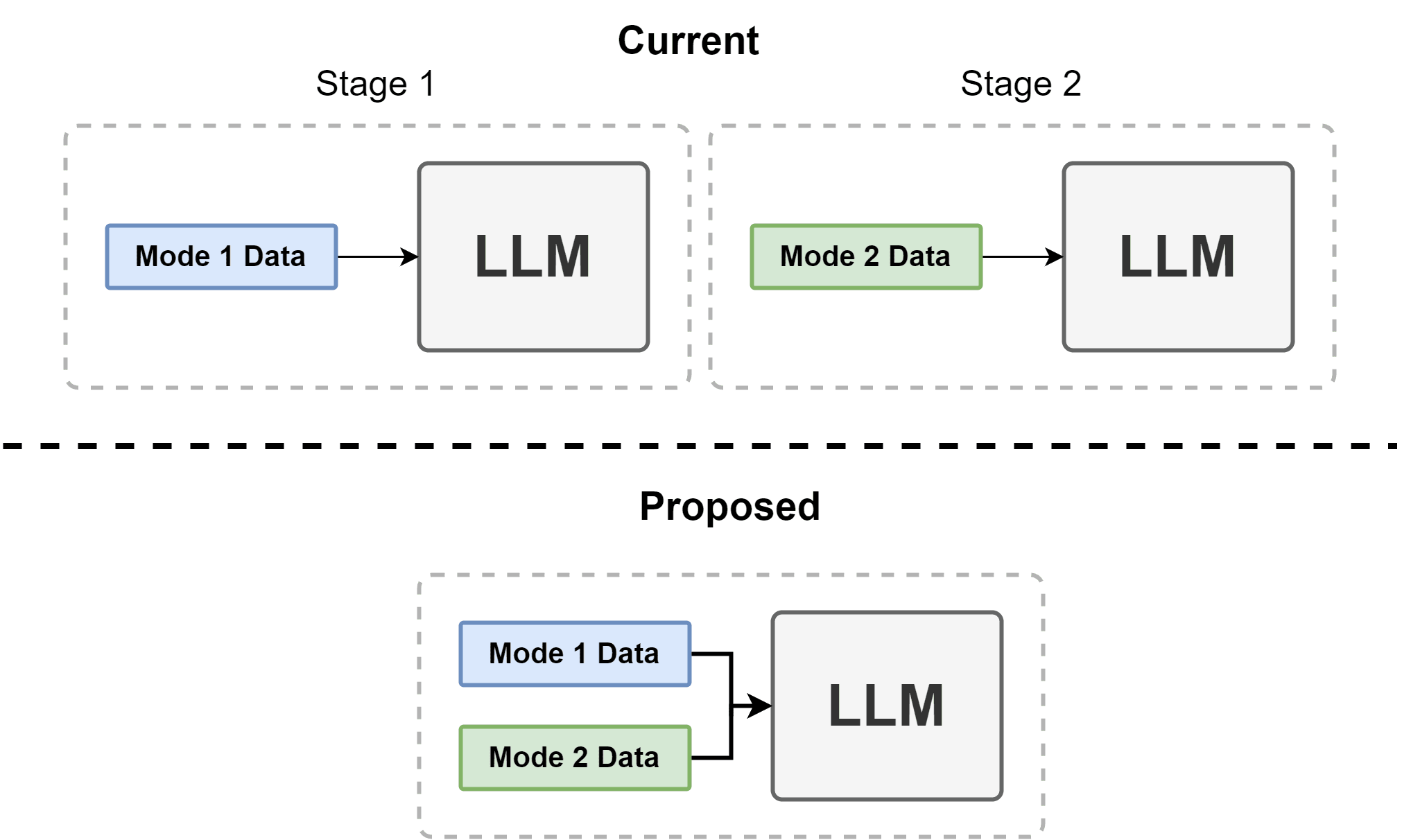
The exposure to Mode 2 probably wouldn't be immediate, but would be early on. The Mode 2 data would need to be aligned with a technique such as Constitutional AI. For best alignment, the network would have to know which mode it was in and know to behave differently.
In practice, almost all of the knowledge an LLM gains comes from the learning it does in Mode 1. In this mode, the contents of this text are fixed, but you need the variety it contains in order for your LLM to properly learn the complexities of the world. It's a little strange to talk about alignment in this mode, because the AI isn't actually doing anything. It's not providing instruction, answering questions, or performing any tasks, it's just looking at things and learning their structure.
If we just drop a bunch of Mode 2 data into the training procedure, it might have a small effect (I bet places like OpenAI already do that), but I doubt it would do that much for alignment.[4] More than anything, I suspect this would be because the network would still be treating the outputs as if they were Mode 1 data. It wouldn't be paying special attention to any of the things we care about.
What you really want is for the network to learn fundamentally different things based on which mode it's in. We need to make sure our network knows the difference between th,, allowing us to align Mode 2 while Mode 1 proceeds.
Now, strictly speaking, from the network's perspective there isn't really a difference. This is particularly true for Mode 1; if the text in question is a sample conversation between an AI and human then it's going to look like it's in Mode 2 and there's no avoiding that. On the surface that's going to be an issue if we want the AI to notice it's mode just from the context in which it is used.
But the thing is, I think the reverse of this above scenario is mostly false: there aren't many situations where you appear to be in Mode 1, but are actually in Mode 2, particularly if the AI is being used to perform actions. A transcript of an AI taking actions and executing code, for instance, probably won't look like random internet in non-adversarial contexts. And if it does, it won't be that common in our training set, so it's not a big deal if we play it safe and mis-categorize those rare instances.
The Second Challenge: Embedding Alignment Deep
Even if we can train both modes at once and align the network early. That doesn't prove that we would gain anything meaningful. It may be the case that even when alignment starts early, a very lightweight fine-tuning will remove all the guardrails.
So the question we need to ask is whether doing this would make a model harder to "un-align." Asked differently, how easily could one intentionally induce catastrophic forgetting into an existing network, making it forget what it already knows?
And this is made more complicated because we aren't even really asking about "forgetting" in the sense of losing knowledge, so much as changing what it chooses to output.[5]
I have some intuition with the smaller networks that I train day-to-day, but I have no idea to what degree it's possible to embed behaviors in LLMs which cannot be easily trained out of them. I'm not sure people have tried directly to do the kinds of things I'm talking about.[6]
Proposed Initial Experiments
If a solution does exist, then it will need to be something that large AI companies are willing to do every time they train a new large model. That means that the solution:
- Cannot reduce training performance. If it makes LLM performance too much worse, then no one will use it.
- Must be functionally scalable. It needs to be something that we have very high confidence will work even when the network is large.
- Must be affordably scalable. It needs to be something that adds only a small cost to training LLMs. If it's very expensive, then even if one big lab uses it, competitors (especially open source ones) will not.
- Must be hard to undo without significant resources (a concept I'm going to call "Embedded Alignment"). Whatever we do, it needs to be something which a bad actor will not be able to undo except with significant, hopefully prohibitive, effort.
In an actual engineering/research context, you can't just jump ahead into the final product. Especially in deep learning, intuition means very little and it is only by doing experiments that you actually learn anything. And some of these ideas I'm not even confident about to begin with. So before any of this could be implemented, we would need to do smaller scale experiments to figure out what are our odds are, and then build up slowly to something meaningful.
In the remainder of this post, I'm going to go over these ideas again, but in the process I'm going to present specific, low-cost experiments that would give some intuition as to the validity of these ideas. The idea is that if I were in a position to do this research myself, I would use these experiments as a jumping off point, guiding my initial exploration and informing my next steps. Ultimately, that might take me somewhere very different from where I started.
That said, the questions I would want answered are the following (and if anyone knows of papers that are relevant, please do not hesitate to let me know):
- How well can AI differentiate between being in Mode 1 and Mode 2?
- Can we force it to behave differently between the modes while still transferring knowledge?
- Do we gain anything by starting mode 2 training earlier?
- Does it get harder for future training to “unalign” the network?
- Does it align better in any way?
- Can we do this affordably at scale?
My approach is probably only viable if the answers to (1), (1a) and (2a) are all “yes”, and only practical if (3) is true. That said, as long as (1) is true, which I suspect it is, then these ideas may still be useful for general alignment, since they can be applied in the fine-tuning stage.
How Well Can AI Differentiate Between Data Modes?
In it's most basic form, the answer to this one is probably "quite well." If I made a dataset of a bunch of AI conversation samples (Mode 2), and then took a bunch of random text snippets from some large text corpus (Mode 1), and then asked a trained LLM directly to tell me which passages came from where, the AI would likely get it right a huge percentage of the time.
There's still an issue with doing it this way, though, and it's the same reason LLMs say racist things without fine-tuning, or get easy word problems wrong without chain-of-thought reasoning: the fact that AI has certain knowledge does not mean it will apply that knowledge during use. A huge amount of LLM research is dedicated to fixing this issue by training the system to make use of its own latent knowledge.
In this case, though, I think we have an advantage that doesn't exist in many other cases, which is that we as the system designers know during training which data is meant to be consumed in which mode, and can add that as a label to the system. This allows us to take an approach which engrains that knowledge at a more fundamental level by adding, for instance, a mode-classification logit.
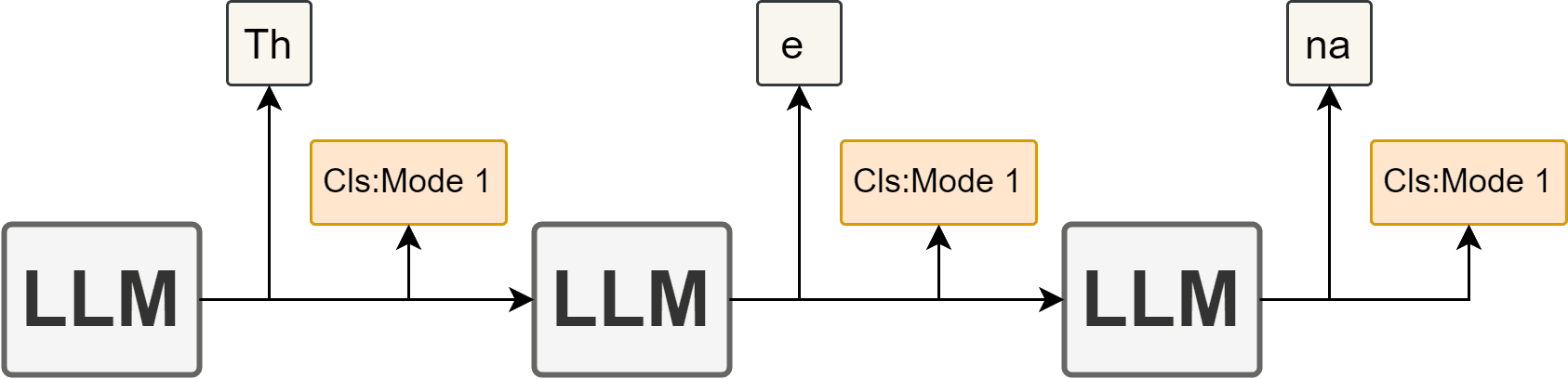

Making it a logit - possibly included with the output of every token - has certain advantages I think. We could in theory have special tokens the system outputs at the end or beginning of text, for instance, but that seems less robust to me. What if a malicious actor removed those tokens, would the AI then "forget" it was in Mode 2? I'm not sure, but if the AI is outputting a logit for the mode with each token, and if those logits exist independent of it's textual output, then there really isn't anything an actor can do to manipulate that outcome. The classification is coming directly from the features at every output token.
I also hypothesize that this would create a stronger correlation between the mode and what is output. Every single token must be output with full knowledge of the expected mode.
The exact dataset you build is going to matter a lot as well. If your goal is to use this differentiation to align against potentially malicious actors who have unrestrained access to the system, your guardrails are going to have to be tight. People could do some pretty clever things to get around it: for instance, have AI write code samples for hacking a system as if it were a blog post or Medium article (imagine an article titled "This is how you hack into a bank account, with code"), and then have another instance of the AI run it. This is broadly the kind of thing that AutoGPT does (though more directly than with a Medium article, of course).
Still, I think there's going to have to be some point in the chain where the AI executes something, and a smart AI is going to understand what it's executing, and that is the point where it can refuse. A dataset of Auto-GPT outputs would make these types of things easier to detect. It's important to remember that people will be using this in an API as well, so we ought to look at what kind of things people put into that API.
So, using a training dataset with Mode1 and Mode 2 data (some of which might be auto-generated en masse with Auto-GPT queries), these are the specific experiments I would like to run to find out if these ideas have merit at a relatively low cost:[7]
- Fine-tune an existing LLM with the logit method described above and see how well it does, likely balancing it to see data in both modes at an even rate. I'd be curious to see how quickly and consistently it identifies the mode it's in.
- In cases of high-confidence incorrect predictions, try throwing out the those samples or at least blocking out the loss. If we don't do this very often, then it might increase our recall of Mode 2, at the cost of some false positives that aren't a big concern.
- Fine-tune by adding special "mode" tokens in the output, either in the beginning, end, or sporadically throughout the middle.
- Try removing these tokens and seeing if confidence changes.
- If I had access to checkpoints of a model during mid-training, I would try these experiments at various checkpoints to see how early on the network could differentiate between the two modes.
If We Train Both Modes Simultaneously, Is There Transfer?
I'd bet good money people are already mixing instructional tuning data into their pre-training datasets, so if anyone has any papers on it, I'd love to see them. In fact, I'd be a little surprised if places like OpenAI weren't already doing something like that.[8] If you had a large dataset of instructions, why wouldn't you start the AI on it early?
But what hasn't been done, to my knowledge, is something as systematic as what I suggested above, where we truly try to balance the data and differentiate between it. And having done that, we'll need to see if any knowledge from Mode 1 crosses over into Mode 2.
I'm not sure the best way to check this in a cheap way. I imagine you would have to produce a good amount of Mode 1 data with some arbitrary fact included (like that zebras have six legs or something. Ideally it would be far more complex in structure.), run the experiments of the previous section, and then see if that fact showed up during questioning. I suppose you would have to make up this fact and have an LLM generate the data for it, which you would sprinkle randomly into the dataset.
Does It Make Sense to Start Alignment Early?
The big question here is whether starting alignment earlier makes the values encoded harder to un-align later. More broadly, if someone's trying to get a network to forget something, is that actually hard to do? Does learning a concept earlier make make it harder to remove?
Here's a simple first experiment: what if we fine-tuned the network on random sequences of text? How long would we have to do that before the network just stops working? My suspicion is that you'd actually have to fine-tune for quite some time before the network would no longer respond to questions in mostly grammatically correct text. I'd be curious to see what happens though. Would the eventual loss of grammatical ability effect knowledge as well?
Of course, randomness sends a much stronger signal then unaligned examples, but alignment is probably a much more delicate concept than correct grammar, so it's a toss-up if that experiment would actually tell us much about un-aligning a network. We might need to design more careful "un-training."
Could we modify a dataset so that the colors of all objects were changed to something different (all yellows were red, all blues orange, etc.)? An LLM might be able to make that change, or just simple text processing. How much of that data would make an LLM think a banana was red? I choose color because that's likely something the LLM learned very early on.
LLMs are generally trained these days with carefully fixed random seeds. This means we could, in theory, figure out exactly which data samples it was shown when in training. Would trying to reverse knowledge given in earlier samples be harder than knowledge in later samples?
These experiments would admittedly be weak. Unfortunately, while we may not need to do anywhere near a whole training, I think the only to really know if there are gains to aligning early is to train for a non-trivial amount of time from an early checkpoint and see what happens. Then we can try to "unalign" by having an LLM produce negative examples. We can also measure if earlier training produces better alignment scores, though I wouldn't hold my breath that it would.
Also, I do think just from a purely research perspective there may be value in doing these experiments.[9]
Will the Solution Be Scalable?
If there is any hope of this working, then it must be scalable.
Data quantity is the biggest issue: we have way less instructional data. But I think we could probably get more of that by having an LLM spit out samples, and LLMs could also align those samples (see Constitutional AI).
The big problem here is that we're adding a lot of data, and that has cost. I doubt it'd need to be 50-50, but I'm not sure how much would need to be added. Maybe in earlier experiments we can get an idea of how much aligned data we need. But the issue is twofold. First, the more you need, the harder it is to get (though there exit many techniques for turning unstructured data into task data). And the second issue for scalability is that you also have to pay to train on it, so if an appreciable fraction of your training data is from Mode 2, then that's a lot of extra compute.
Honestly, I have the least ideas for this one. I also have the least experience designing aspects of networks that can be scaled up to massive scales. But even if this isn't possible, I would love to run some of these experiments and see if anything useful comes out of it.
- ^
This is the core assumption that I am least confident in, but I still think it's probably mostly true. There has been a consistent pattern of large labs building the first iteration of all the recent major breakthroughs. Even techniques like LoRA only make fine-tuning easier.
- ^
This isn't really one "phase" the way the first phase is. It consists usually of quite a few steps, such as supervised instruction tuning, reward model training, reinforcement learning and many others. But it's all for the same purpose, so I'm lumping it together.
- ^
I'm sure I'm the ten-thousandth person to think of this, but I have some thoughts on how it might be done which are hopefully at least somewhat novel.
- ^
It's worth mentioning negative concepts are in general really important, so trying to align mode 1 data by removing all bad things probably wouldn't be a good way to train. You need to know what violence is before you can avoid doing it, for instance.
- ^
My original thoughts were that we wanted to differentiate between "weak" and "strong" embedded alignment, where the weak case applies when the alignment can be affordably fine-tuned out of it (e.g. small amounts of data, fast to run on lightweight hardware), and the strong case applies to cases where the costs of reversing it are comparable to the costs of just building a new model. But in light of methods like LoRA which allow individuals to fine-tune LLMs for only hundreds of dollars, this distinction may not be worth making.
- ^
My guess is that there is very little published on this matter, but people who have worked directly with LLMs for some time will nonetheless have strong intuitions about whether my ideas are plausible.
- ^
Yes, it would only take a couple hundred dollars per run. But sadly I can't do these experiments at my current job and can't really afford to iterate on these experiments even at that price.
- ^
But maybe not. Maybe they like to keep it separate for benchmarking purposes.
- ^
Now that I mention it, this feels like something someone might have already done. I couldn't find it with a Google search, but that's not a great way to find papers in general.
0 comments
Comments sorted by top scores.