Meta announces Llama 2; "open sources" it for commercial use
post by LawrenceC (LawChan) · 2023-07-18T19:28:28.685Z · LW · GW · 12 commentsThis is a link post for https://about.fb.com/news/2023/07/llama-2/
Contents
Takeaways None 12 comments
See also their Llama 2 website here: https://ai.meta.com/llama, and their research paper here: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
From their blog post:
Takeaways
- Today, we’re introducing the availability of Llama 2, the next generation of our open source large language model.
- Llama 2 is free for research and commercial use.
- Microsoft and Meta are expanding their longstanding partnership, with Microsoft as the preferred partner for Llama 2.
- We’re opening access to Llama 2 with the support of a broad set of companies and people across tech, academia, and policy who also believe in an open innovation approach to today’s AI technologies.
Compared to the first Llama, LLama 2 is trained for 2T tokens instead of 1.4T, has 2x the context length (4096 instead of 2048), uses Grouped Query Attention, and performs better across the board, with performance generally exceeding code-davinci-002 on benchmarks:
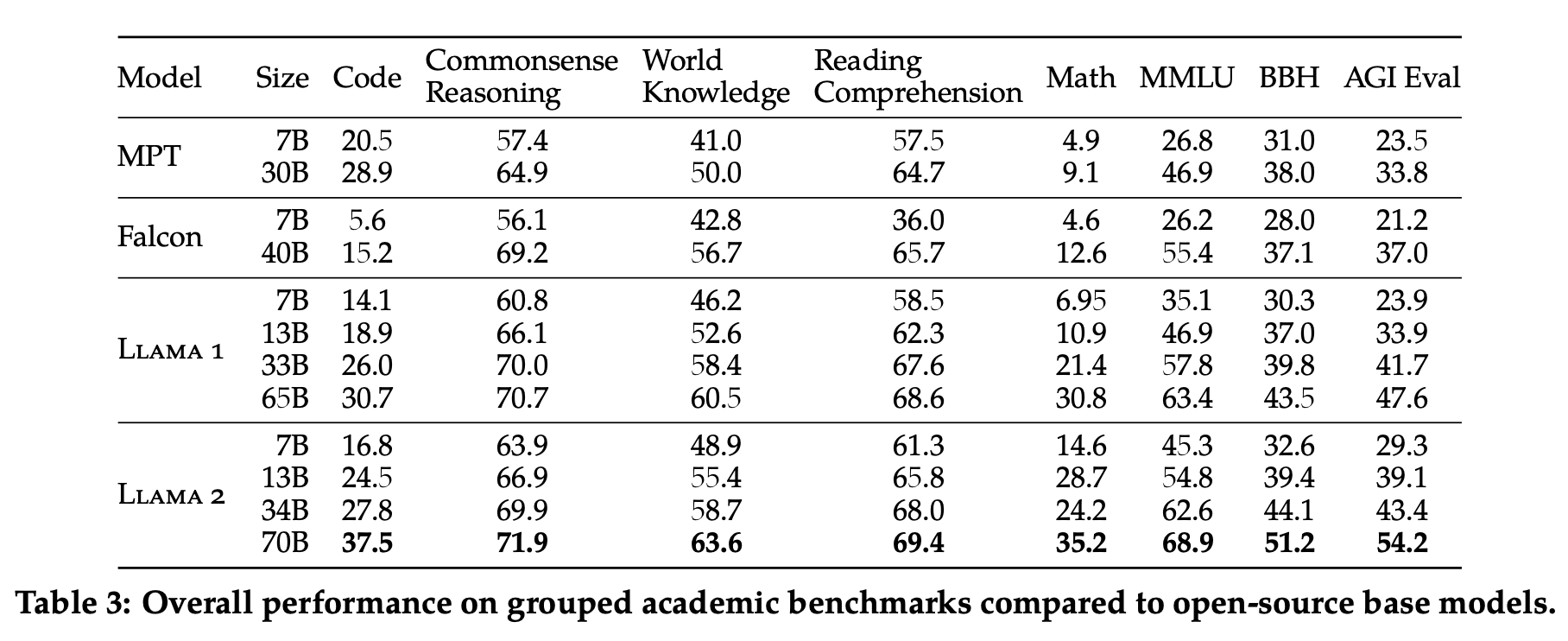
They also release both a normal base model (Llama 2) and a RLHF'ed chat model (Llama 2-chat). Interestingly, they're only releasing the 7B/13B/70B models, and not the 34B model, "due to a lack of time to sufficiently red team".
More importantly, they're releasing it both on Microsoft Azure and also making it available for commercial use. The form for requesting access is very straightforward and does not require stating what you're using it for: (EDIT: they gave me access ~20 minutes after submitting the form, seems pretty straightforward.)
Note that their license is not technically free for commercial use always; it contains the following clauses:
[1.] v. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Llama 2 or derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
See also the Llama 2 Acceptable Use Policy (which seems pretty standard).
12 comments
Comments sorted by top scores.
comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2023-07-19T03:30:11.821Z · LW(p) · GW(p)
Llama 2 is not open source.
(a few days after this comment, here's a concurring opinion from the Open Source Initiative - as close to authoritative as you can get)
(later again, here's Yan LeCun testifying under oath: "so first of all Llama system was not made open source ... we released it in a way that did not authorize commercial use, we kind of vetted the people who could download the model it was reserved to researchers and academics")
While their custom licence permits some commercial uses, it is not an OSI approved license, and because it violates the open source definition it never will be. Specifically, the llama 2 licence violates:
-
- Source code. It's a little ambiguous what this means for a trained model; I'd claim that an open model release should include the training code (yes) and dataset (no), along with sufficient instructions for others to reproduce the results. However, you could also argue that weights are in fact "the preferred form in which a programmer would modify the program", so this is not an important objection.
-
- No Discrimination Against Persons or Groups. See the ban on use by anyone who has, or is affiliated with anyone who has, more than 700M active users. As a side note, Snapchat recently announced that they had 750M active users, so this looks pretty targeted at competing social media (including Tiktok, Google, etc.). As a consequence, the Llama 2 license also violates OSD 7. Distribution of License: "the rights attached to the program must apply to all to whom the program is redistributed without the need for execution of an additional license by those parties."
-
- No Discrimination Against Fields of Endeavor. If you can't use Llama 2 to - for example - train another model, it's by definition not open source. Their entire acceptable use policy is included by reference and contains a wide variety of sometimes ambiguous restrictions.
So, why does this matter?
-
As an open-source maintainer and PSF Fellow, I have no objection to the existence of commercially licensed software. I use much of it, and have sold commercial licenses for software that I've written too. However, people - and especially megacorps - misrepresenting their closed-off projects as open source is an infuriating form of parasitism on a reputation painstakingly built over decades.
-
The restriction on model training makes Llama 2 much less useful for AI safety research, but it incurs just as much direct (roughly all via misuse IMO) and acceleration risk as an open-source release.
-
Using a custom license adds substantial legal risk for prospective commercial users, especially given the very broad restrictions imposed by the acceptable use policy. This reduces the economic upside enormously relative to standard open terms, and leaves Meta's competitors particularly at risk of lawsuits if they attempt to use Llama 2.
To summarize, Meta gets a better cost/benefit tradeoff by using a custom, non-open-source license especially if people incorrectly percieve it as open source; everyone else is worse off; and it seems to me like they're deliberately misrepresenting what they've done for their own gain. This really, really annoys me.
When someone describes Llama 2 as "open source", please correct them: Meta is offering a limited commercial license which discriminates against specific users and bans many valuable use-cases, including in alignment research.
Replies from: neel-nanda-1, rudolf-zeidler↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-19T08:59:39.593Z · LW(p) · GW(p)
Huh, that's very useful context, thanks! Seems like pretty sad behaviour.
↑ comment by Rudi (rudolf-zeidler) · 2023-07-19T10:18:53.319Z · LW(p) · GW(p)
Thanks a lot for the context!
Out of curiosity, why does the model training restriction make it much less useful for safety research?
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2023-07-19T19:17:39.412Z · LW(p) · GW(p)
Example projects you're not allowed to do, if they involve other model families:
- using Llama 2 as part of an RLAIF setup, which you might want to do when investigating Constitutional AI or decomposition or faithfulness of chain-of-thought or many many other projects;
- using Llama 2 in auto-interpretability schemes to e.g. label detected features in smaller models, if this will lead to improvements in non-Llama-2 models;
- fine-tuning other or smaller models on synthetic data produced by Llama 2, which has some downsides but is a great way to check for signs of life of a proposed technique
In many cases I expect that individuals will go ahead and do this anyway, much like the license of Llama 1 was flagrantly violated all over the place, but remember that it's differentially risky for any organisation which Meta might like to legally harass.
Replies from: rudolf-zeidler↑ comment by Rudi (rudolf-zeidler) · 2023-07-19T22:52:48.794Z · LW(p) · GW(p)
Thanks, that makes sense! I did not fully realize that the phrase in the terms is really just "improve any other large language model", which is indeed so vague/general that it could be interpreted to include almost any activity that would entail using Llama-2 in conjunction with other models.
comment by jbash · 2023-07-18T21:24:45.944Z · LW(p) · GW(p)
I'm really confused about how anybody thinks they can "license" these models. They're obviously not works of authorship. Therefore they don't have copyrights. You can write a license, but anybody can still do anything they want with the model regardless of what you do or don't put into it.
Also, "open source" actually means something and that's not it. I don't actually like the OSD very much, but it's pretty thoroughly agreed upon.
Replies from: Razied↑ comment by Razied · 2023-07-19T02:32:29.153Z · LW(p) · GW(p)
I'm really confused about how anybody thinks they can "license" these models. They're obviously not works of authorship.
I'm confused why you're confused, if I write a computer program that generates an artifact that is useful to other people, obviously the artifact should be considered a part of the program itself, and therefore subject to licensing just like the generating program. If I write a program to procedurally generate interesting minecraft maps, should I not be able to license the maps, just because there's one extra step of authorship between me and them?
Replies from: jbash↑ comment by jbash · 2023-07-19T08:36:05.268Z · LW(p) · GW(p)
If it generates them totally at random, then no. They have no author. But even in that case, if you do it in a traditional way you will at least have personally made more decisions about what the output looks like than somebody who trains a model. The whole point of deep learning is that you don't make decisions about the weights themselves. There's no "I'll put a 4 here" step.
comment by Zach Stein-Perlman · 2023-07-19T04:10:15.487Z · LW(p) · GW(p)
You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Llama 2 or derivative works thereof).
Why doesn't Meta AI want me to use Llama 2 outputs to train ZachNet?
Replies from: zac-hatfield-dodds↑ comment by Zac Hatfield-Dodds (zac-hatfield-dodds) · 2023-07-19T06:15:37.282Z · LW(p) · GW(p)
You are allowed if ZachNet is based on Llama 2, so I'd guess "because non-llama-based ZachNet wouldn't have the usage restrictions, or the publicity benefits for Meta".
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-19T14:45:36.419Z · LW(p) · GW(p)
Any idea what's happening with the 34B model? Why might it be so much less "safe" than the bigger and smaller versions? And what about the base version of the 34B--are they not releasing that? But the base version isn't supposed to be "safe" anyway...
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-19T14:54:29.896Z · LW(p) · GW(p)
Relevant rumors / comments:
Seems like we can continue to scale tokens and get returns model performance well after 2T tokens. : r/LocalLLaMA (reddit.com)
LLaMA 2 is here : r/LocalLLaMA (reddit.com)
There is something weird going on with the 34B model. See Figure 17 in the the paper. For some reason it's far less "safe" than the other 3 models.
Also:
It's performance scores are just slightly better than 13B, and not in the middle between 13B and 70B.
At math, it's worse than 13B
It's trained with 350W GPUs instead of 400W for the other models. The training time also doesn't scale as expected.
It's not in the reward scaling graphs in Figure 6.
It just slightly beats Vicuna 33B, while the 13B model beats Vicuna 13B easily.
In Table 14, LLaMA 34B-Chat (finetuned) scores the highest on TruthfulQA, beating the 70B model.
So I have no idea what exactly, but they did do something different with 34B than with the rest of the models.