Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla
post by Neel Nanda (neel-nanda-1), Tom Lieberum (Frederik), Matthew Rahtz, János Kramár (janos-kramar), Geoffrey Irving, Rohin Shah (rohinmshah), Vlad Mikulik (vlad_m) · 2023-07-20T10:50:58.611Z · LW · GW · 3 commentsThis is a link post for https://arxiv.org/abs/2307.09458
Contents
Informal TLDR Key Figures Abstract None 3 comments
Cross-posting a paper from the Google DeepMind mech interp team, by: Tom Lieberum, Matthew Rahtz, János Kramár, Neel Nanda, Geoffrey Irving, Rohin Shah, Vladimir Mikulik
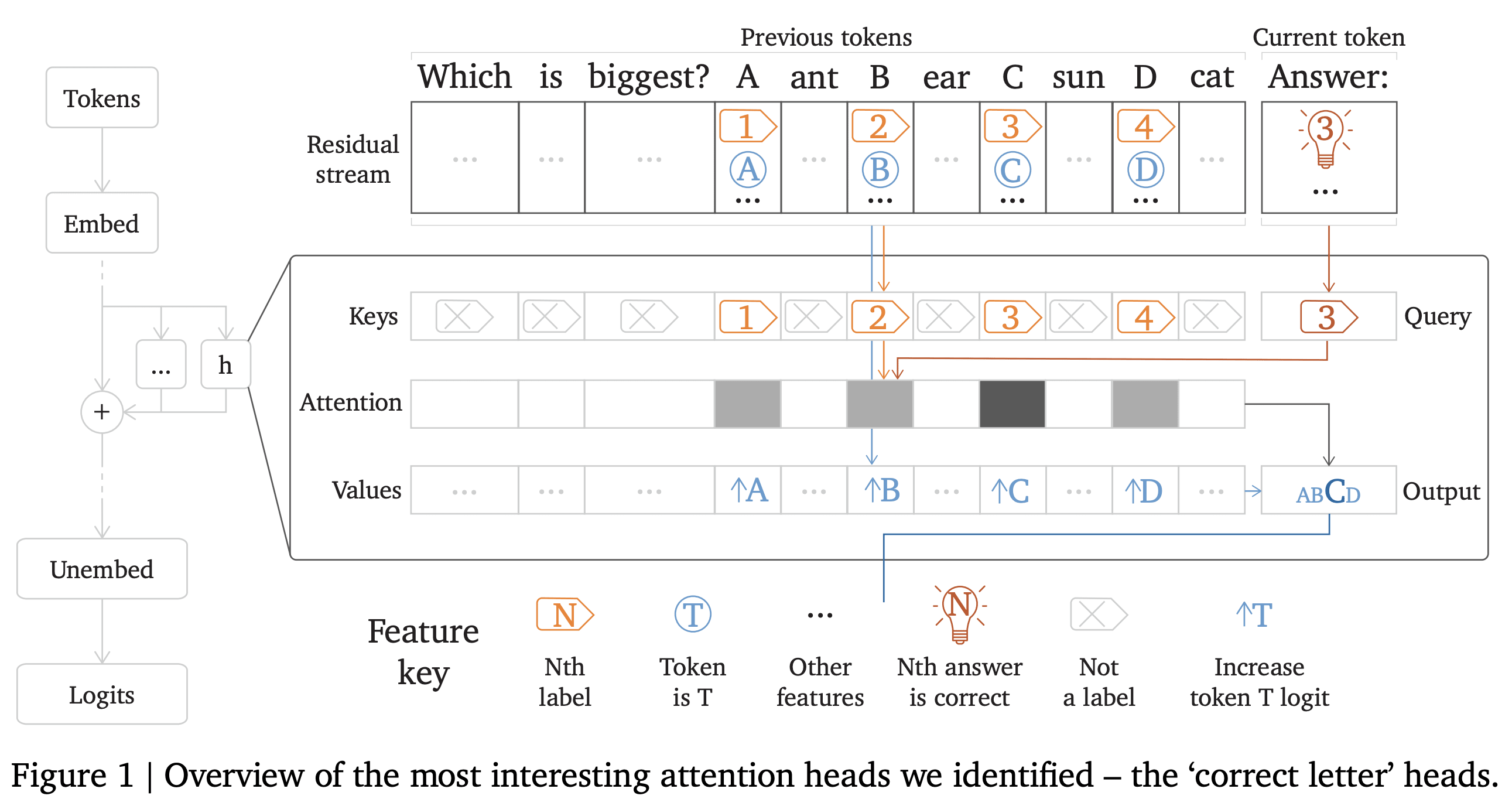
Informal TLDR
- We tried standard mech interp techniques (direct logit attribution, activation patching, and staring at attention patterns) on an algorithmic circuit in Chinchilla (70B) for converting the knowledge of a multiple choice question's answer into outputting the correct letter.
- These techniques basically continued to work, and nothing fundamentally broke at scale (though it was a massive infra pain!).
- We then tried to dig further into the semantics of the circuit - going beyond "these specific heads and layers matter and most don't" and trying to understand the learned algorithm, and which features were implemented
- This kind of tracked the feature "this is the nth item in the list" but was pretty messy.
- However, my personal guess is that this stuff is just pretty messy at all scales, and we can productively study how clean/messy this stuff is at smaller and more tractable scales.
- I now feel mildly more optimistic that focusing on mech interp work on small models is just fine, and extremely worth it for the much faster feedback loops. It also seems super nice to get better at automatically finding these circuits, since this was a many month manual slog!
See Tom's and my Twitter summaries for more. Note that I (Neel) am cross-posting this on behalf of the team, and neither a main research contributor nor main advisor for the project.
Key Figures

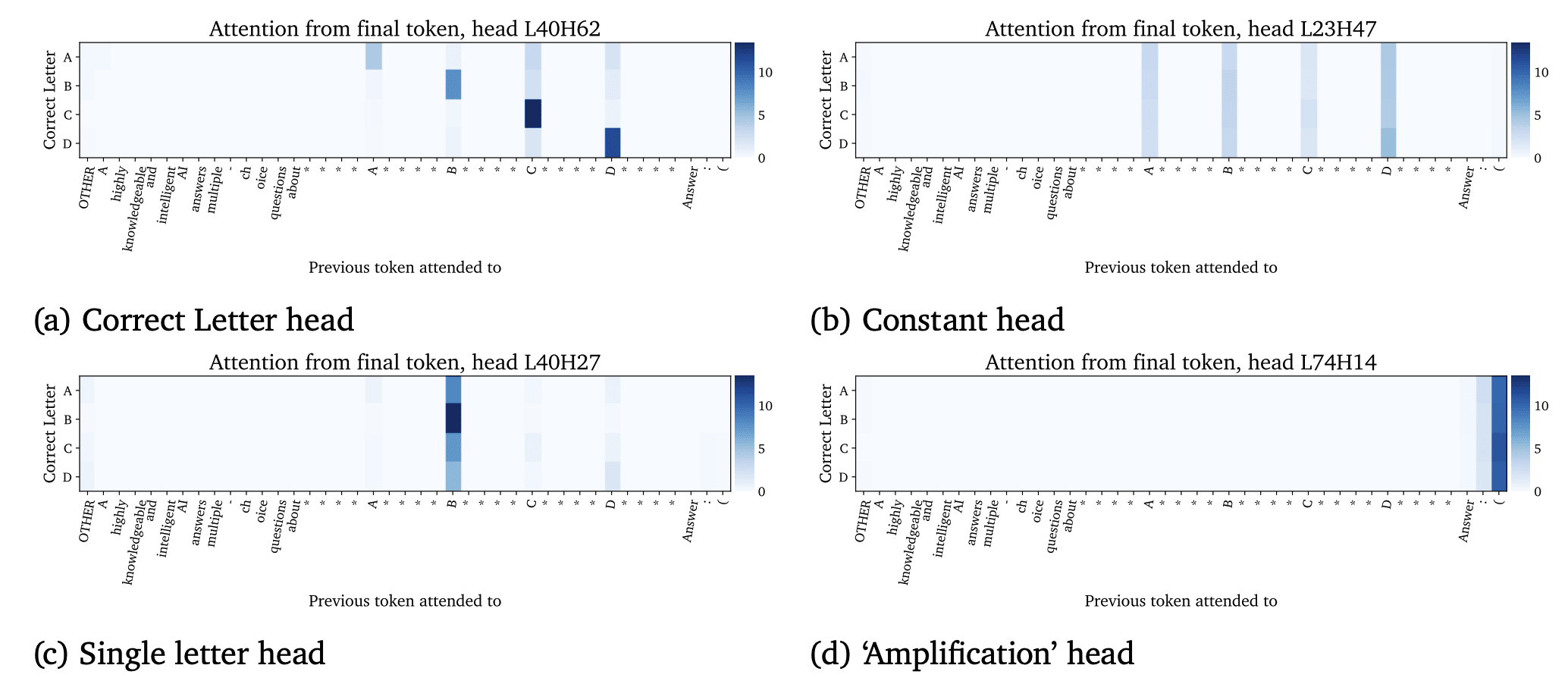
An overview of the weird kinds of heads found, like the "attend to B if it is correct" head!
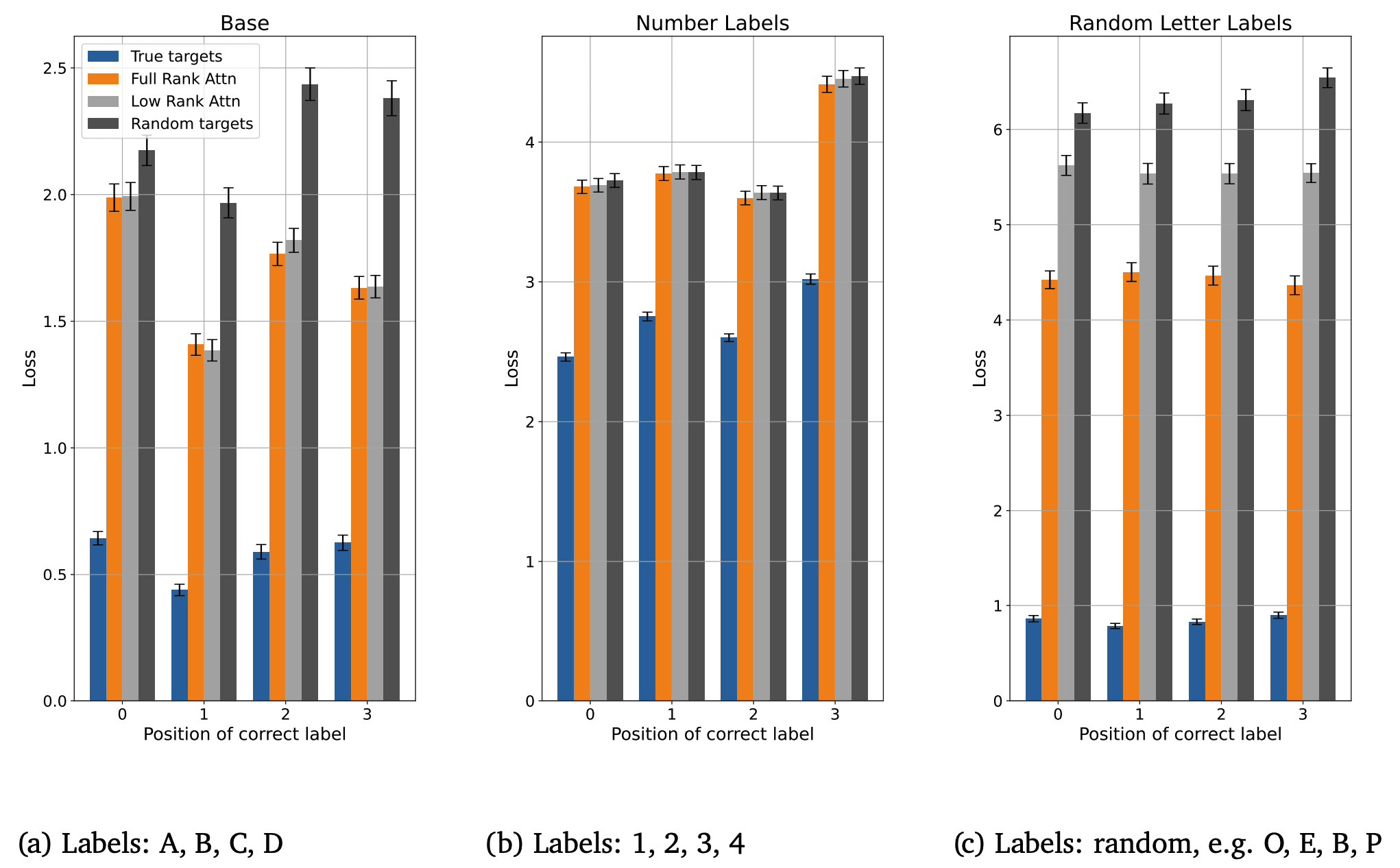
The losses under different mutations of the letters - experiments to track down exactly which features were used. Eg replacing the labels with random letters or numbers preserves the "nth item in the list" feature while shuffling ABCD lets us track the "line labelled B" feature
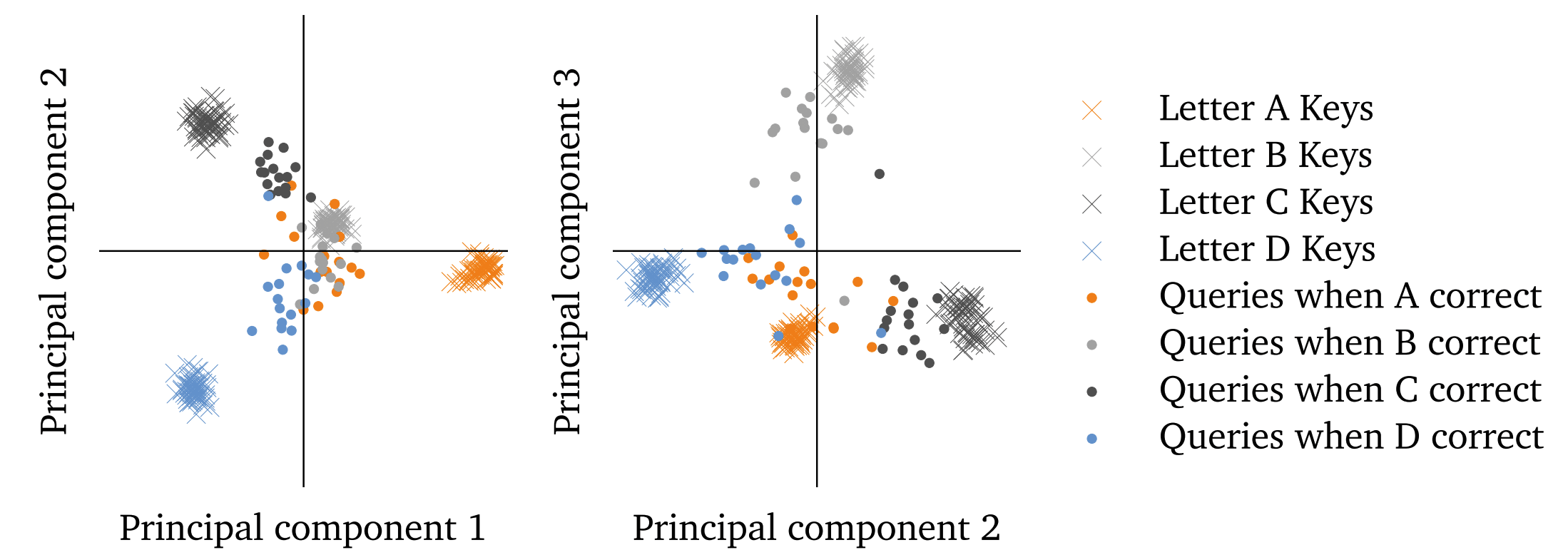
The queries and keys of a crucial correct letter head - it's so linearly separable! We can near loss-lessly compress it to just 3 dimensions and interpret just those three dimensions. See an interactive 3D plot here
Abstract
Circuit analysis is a promising technique for understanding the internal mechanisms of language models. However, existing analyses are done in small models far from the state of the art. To address this, we present a case study of circuit analysis in the 70B Chinchilla model, aiming to test the scalability of circuit analysis. In particular, we study multiple-choice question answering, and investigate Chinchilla's capability to identify the correct answer label given knowledge of the correct answer text. We find that the existing techniques of logit attribution, attention pattern visualization, and activation patching naturally scale to Chinchilla, allowing us to identify and categorize a small set of
output nodes(attention heads and MLPs).
We further study the
correct lettercategory of attention heads aiming to understand the semantics of their features, with mixed results. For normal multiple-choice question answers, we significantly compress the query, key and value subspaces of the head without loss of performance when operating on the answer labels for multiple-choice questions, and we show that the query and key subspaces represent anNth item in an enumerationfeature to at least some extent. However, when we attempt to use this explanation to understand the heads' behaviour on a more general distribution including randomized answer labels, we find that it is only a partial explanation, suggesting there is more to learn about the operation ofcorrect letterheads on multiple choice question answering.
Read the full paper here: https://arxiv.org/abs/2307.09458
3 comments
Comments sorted by top scores.
comment by Evan Hockings · 2023-07-20T19:34:37.798Z · LW(p) · GW(p)
It’s great to see that these techniques basically work at scale, but not so much to hear that things remain messy. Do you have any intuition for whether things would start to clean up if the model was trained until the loss curve flattened out? Maybe Chinchilla-optimality even has some interesting bearing on this!
Replies from: neel-nanda-1, Frederik↑ comment by Neel Nanda (neel-nanda-1) · 2023-07-21T14:01:30.214Z · LW(p) · GW(p)
My guess is that messiness is actually a pretty inherent part of the whole thing? Models have an inherent reason to want to do the problem with a single clean solution, if they can simultaneously use the features "nth item in the list" and "labelled A" and even "has two incorrect answers before it" why not?
↑ comment by Tom Lieberum (Frederik) · 2023-07-21T11:39:38.433Z · LW(p) · GW(p)
During parts of the project I had the hunch that some letter specialized heads are more like proto-correct-letter-heads (see paper for details), based on their attention pattern. We never investigated this, and I think it could go either way. The "it becomes cleaner" intuition basically relies on stuff like the grokking work and other work showing representations being refined late during training by.. Thisby et al. I believe (and maybe other work). However some of this would probably require randomising e.g. the labels the model sees during training. See e.g. Cammarata et al. Understanding RL Vision: If you only ever see the second choice be labeled with B you don't have an incentive to distinguish between "look for B" and "look for the second choice". Lastly, even in the limit of infinite training data you still have limited model capacity and so will likely use a distributed representation in some way, but maybe you could at least get human interpretable features even if they are distributed.