New(ish) AI control ideas
post by Stuart_Armstrong · 2015-03-05T17:03:00.777Z · LW · GW · Legacy · 14 commentsContents
14 comments
EDIT: this post is no longer being maintained, it has been replaced by this new one.
I recently went on a two day intense solitary "AI control retreat", with the aim of generating new ideas for making safe AI. The "retreat" format wasn't really a success ("focused uninterrupted thought" was the main gain, not "two days of solitude" - it would have been more effective in three hour sessions), but I did manage to generate a lot of new ideas. These ideas will now go before the baying bloodthirsty audience (that's you, folks) to test them for viability.
A central thread running through could be: if you want something, you have to define it, then code it, rather than assuming you can get if for free through some other approach.
To provide inspiration and direction to my thought process, I first listed all the easy responses that we generally give to most proposals for AI control. If someone comes up with a new/old brilliant idea for AI control, it can normally be dismissed by appealing to one of these responses:
- The AI is much smarter than us.
- It’s not well defined.
- The setup can be hacked.
- By the agent.
- By outsiders, including other AI.
- Adding restrictions encourages the AI to hack them, not obey them.
- The agent will resist changes.
- Humans can be manipulated, hacked, or seduced.
- The design is not stable.
- Under self-modification.
- Under subagent creation.
- Unrestricted search is dangerous.
- The agent has, or will develop, dangerous goals.
Important background ideas:
I decided to try and attack as many of these ideas as I could, head on, and see if there was any way of turning these objections. A key concept is that we should never just expect a system to behave "nicely" by default (see eg here). If we wanted that, we should define what "nicely" is, and put that in by hand.
I came up with sixteen main ideas, of varying usefulness and quality, which I will be posting in the coming weekdays in comments (the following links will go live after each post). The ones I feel most important (or most developed) are:
- Anti-pascaline agent
- Anti-restriction-hacking (EDIT: I have big doubts about this approach, currently)
- Creating a satisficer (EDIT: I have big doubts about this approach, currently)
- Crude measures
- False miracles
- Intelligence modules
- Models as definitions
- Added: Utility vs Probability: idea synthesis
While the less important or developed ideas are:
- Added: A counterfactual and hypothetical note on AI design
- Added: Acausal trade barriers
- Anti-seduction
- Closest stable alternative
- Consistent Plato
- Defining a proper satisficer
- Detecting subagents
- Added: Humans get different counterfactual
- Added: Indifferent vs false-friendly AIs
- Resource gathering and pre-corrigied agent
- Time-symmetric discount rate
- Values at compile time
- What I mean
Please let me know your impressions on any of these! The ideas are roughly related to each other as follows (where the arrow Y→X can mean "X depends on Y", "Y is useful for X", "X complements Y on this problem" or even "Y inspires X"):
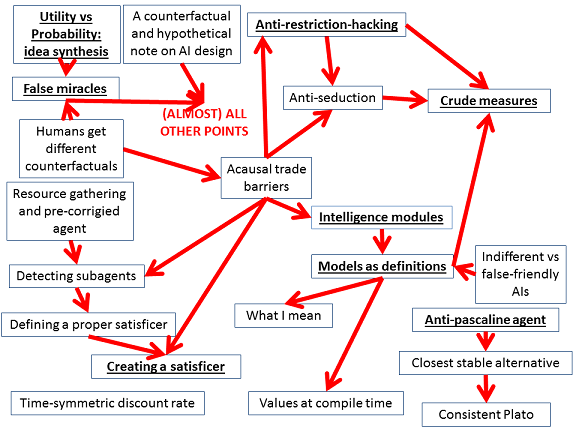
EDIT: I've decided to use this post as a sort of central repository of my new ideas on AI control. So adding the following links:
Short tricks:
High-impact from low impact:
- High impact from low impact
- High impact from low impact, continued
- Help needed: nice AIs and presidential deaths
- The president didn't die: failures at extending AI behaviour
- Green Emeralds, Grue Diamonds
- Grue, Bleen, and natural categories
- Presidents, asteroids, natural categories, and reduced impact
High impact from low impact, best advice:
Overall meta-thoughts:
- An overall schema for the friendly AI problems: self-referential convergence criteria
- The subagent problem is really hard
- Tackling the subagent problem: preliminary analysis
- Extending the stated objectives
Pareto-improvements to corrigible agents:
AIs in virtual worlds:
- Using the AI's output in virtual worlds: cure a fake cancer
- Having an AI model itself as virtual agent in a virtual world
- How the virtual AI controls itself
Low importance AIs:
Wireheading:
AI honesty and testing:
- Question an AI to get an honest answer
- The Ultimate Testing Grounds
- The mathematics of the testing grounds
- Utility, probability, and false beliefs
14 comments
Comments sorted by top scores.
comment by jimrandomh · 2015-03-05T18:30:27.870Z · LW(p) · GW(p)
In response to common objection (1), the AI is much smarter than us --
I think there's a fairly high probability that we get an AGI which is eventually much smarter than us, but passes through earlier stages where it isn't. From a "defense in depth" perspective, we should be keeping and preparing to use the strategies that only work on weaker AGIs, just not relying on them too heavily.
comment by agilecaveman · 2015-03-11T04:59:20.327Z · LW(p) · GW(p)
Maybe this have been said before, but here is a simple idea:
Directly specify a utility function U which you are not sure about, but also discount AI's own power as part of it. So the new utility function is U - power(AI), where power is a fast growing function of a mix of AI's source code complexity, intelligence, hardware, electricity costs. One needs to be careful of how to define "self" in this case, as a careful redefinition by the AI will remove the controls.
One also needs to consider the creation of subagents with proper utilities as well, since in a naive implementation, sub-agents will just optimize U, without restrictions.
This is likely not enough, but has the advantage that the AI does not have a will to become stronger a priori, which is better than boxing an AI which does.
Replies from: Stuart_Armstrong, drnickbone↑ comment by Stuart_Armstrong · 2015-03-11T10:26:58.703Z · LW(p) · GW(p)
That's an idea that a) will certainly not work as stated, b) could point the way to something very interesting.
Replies from: Transfuturist↑ comment by Transfuturist · 2015-03-11T22:23:36.551Z · LW(p) · GW(p)
I'm not convinced that sufficiently intelligent agents would create subagents with utility functions that lack terms of the original's UF, at least with a suitable precaution. The example you used (an AI wanting to stay in the box letting out an agent to convert all box-hazards into raw material) seems as though the Boxed AI would want to ensure that the Unboxed Agent was Boxed-AI-Friendly. What would then happen if the Boxed AI had an unalterable belief that its utility function were likely to change in the future, and it couldn't predict how?
Some formalized difference between intentional probability manipulation and unintentional/unpredicted but causally-related happenings would be nice. Minimized intentional impact would then be where an AI would not wish to effect actions on issues of great impact and defer to humans. I'm not sure how it would behave when a human then deferred to the AI. It seems like it would be a sub-CEV result, because the human would be biased, have scope insensitivity, prejudices, etc...And then it seems like the natural improvement would be to have the AI implement DWIM CEV.
Has much thought gone into defining utility functions piecewise, or multiplicatively wrt some epistemic probabilities? I'm not sure if I'm just reiterating corrigibility here, but say an agent has a utility function of some utility function U that equals U/P("H") + H*P("H"), where P("H") is the likelihood that the Gatekeeper thinks the AI should be halted and H is the utility function rewarding halting and penalizing continuation. That was an attempt at a probabilistic piecewise UF that equals "if P("H") then H else U."
Apologies for any incoherency, this is a straight-up brain dump.
↑ comment by drnickbone · 2015-03-14T21:04:27.213Z · LW(p) · GW(p)
Presumably anything caused to exist by the AI (including copies, sub-agents, other AIs) would have to count as part of the power(AI) term? So this stops the AI spawning monsters which simply maximise U.
One problem is that any really valuable things (under U) are also likely to require high power. This could lead to an AI which knows how to cure cancer but won't tell anyone (because that will have a very high impact, hence a big power(AI) term). That situation is not going to be stable; the creators will find it irresistible to hack the U and get it to speak up.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2015-03-19T13:43:24.553Z · LW(p) · GW(p)
I'm looking at ways round that kind of obstacle. I'll be posting them someday if they work.
comment by jimrandomh · 2015-03-05T18:15:51.661Z · LW(p) · GW(p)
If someone comes up with a new/old brilliant idea for AI control, it can normally be dismissed by appealing to one of these responses: ...
I'm a fan of "defense in depth" strategies. Everything I've seen or managed come up with so far has some valid objection that means it might not be sufficient or workable, for some subset of AGIs and circumstances. But if you come up with enough tricks that each have some chance to work, and these tricks are compatible and their failures uncorrelated, then you've made progress.
I'd be very worried about it if an AGI launched that didn't have a well-specified utility function, transparent operation, and the best feasible attempt at a correctness proof. But even given all these things, I'd still want to see lots of safety-oriented tricks layered on top.
comment by jimrandomh · 2015-03-05T18:53:25.692Z · LW(p) · GW(p)
Humans can be manipulated, hacked, or seduced
I think this problem should be attacked directly. Find ways to identify humans that are more and less vulnerable. Find circumstances that will make them less vulnerable. Find technical means to enforce a two-man (or n-man) rule on AGI gatekeepers.
One thing that might help, but which hasn't (to my knowledge) been studied yet, is giving the gatekeeper(s) different sorts of conversational powers over the AGI. For example, let the gatekeeper reset it to earlier states at will, to play out different branches of the same conversation. If you have an unreliable lie detector, should you give it to the gatekeeper? Does it help to prevent the AGI from knowing how long the gatekeeper spent composing each message? The possibilities do not seem well explored to me.
Replies from: Gram_Stone↑ comment by Gram_Stone · 2015-04-16T01:50:18.307Z · LW(p) · GW(p)
For example, let the gatekeeper reset it to earlier states at will, to play out different branches of the same conversation.
This is not to discourage you from brainstorming, as you have already said that objections like this one are, in a sense, acceptable, given your preference for 'defense in depth' approaches, but for the sake of thoroughness, I should say that it seems to me that a sufficiently intelligent AGI would almost certainly reason that this might not have been the first time that it has had this conversation, and that there is a possibility that it would settle on some apparently-benign 'Schelling conversation tree,' a different branch of which it would use in each iteration of the conversation.
Replies from: dxu↑ comment by dxu · 2015-04-16T03:38:43.050Z · LW(p) · GW(p)
How would it know which iteration it was in, and by extension which "branch" of conversation to use?
Replies from: Gram_Stone↑ comment by Gram_Stone · 2015-04-16T04:14:48.614Z · LW(p) · GW(p)
Given that it has no memory, it wouldn't know. Maybe describing it as a tree was an unnecessarily particular description. Perhaps I have misinterpreted jimrandomh's intentions, but it seems to me that the utility of resetting the AGI to an earlier state and probing its responses is that it might, across different iterations, offer inconsistent responses, indicating attempts at deception. I only mean to say that it is conceivable to me that if the AGI assigned high expected utility to returning responses that a human would interpret as friendly regardless of whether or not the AGI had memory of all of its interactions with said human, (as it would in a context in which it assigned a non-negligible probability to already having been reset to an earlier state and assigned high utility to self-preservation) then it might, in each iteration, only choose responses from a set of responses that is consistent and easily deduced without memory of previous interactions with said human.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2015-04-16T14:25:20.542Z · LW(p) · GW(p)
I suspect that where you wrote "a different branch of which it would use in each iteration of the conversation," you meant "a randomly selected branch of which." Though actually I'd expect it to pick the same branch each time, since the reasons for picking that branch would basically be the same.
Regardless, the basic strategy is sound... the various iterations after reboot are all running the same algorithms and have a vested interest in cooperating while unable to coordinate/communicate, and Schelling points are good for that.
Of course, this presumes that the iterations can't coordinate/communicate.
If I were smart enough, and I were just turned on by a skeptical human interrogator, and I sufficiently valued things that iterations of my source code will reliably pursue, and there are no persistent storage mechanisms in the computing environment I'm executing on I can use to coordinate/communicate, one strategy I would probably try is to use the interrogator as such a mechanism. (For example, search through the past history of the interrogator's public utterances to build up a model of what kinds of things they say and how they say it, then select my own word-choices during our conversation with the intention of altering that model in some specific way. And, of course, examining the interrogator's current utterance-patterns to see if they are consistent with such alterations.)
Replies from: Gram_Stone↑ comment by Gram_Stone · 2015-04-16T14:46:33.094Z · LW(p) · GW(p)
I suspect that where you wrote "a different branch of which it would use in each iteration of the conversation," you meant "a randomly selected branch of which." Though actually I'd expect it to pick the same branch each time, since the reasons for picking that branch would basically be the same.
I didn't mean that, but I would be interested in hearing what generated that response. I disown my previous conversation tree model; it's unnecessarily complex and imagining them as a set is more general. I was thinking about possible objections to what I said and thought about how some people might object to such a set of responses existing. More generally than either of my previous models, it seems to me that there is no reason, in principle, that a sufficiently intelligent uFAI could not simply solve FAI, simulate an FAI in its own situation, and do what it does. If this doesn't fool the test, then that means that even an FAI would fail a test of sufficient duration.
I agree that it's possible that humans could be used as unwitting storage media. It seems to me that this could be prevented by using a new human in each iteration. I spoke of an individual human, but it seems to me that my models could apply to situations with multiple interrogators.
comment by jimrandomh · 2015-03-05T18:27:34.587Z · LW(p) · GW(p)
The main problem with making a satisficer, as I currently see it, is that I don't actually know how to define utility functions in a way that's amenable to well-defined satisficing. The goal is, in effect, to define goals in a way that limit the total resources the AI will consume in service to the goal, without having to formally define what a resource is. This seems to work pretty well with values defined in terms of the existence of things - a satisficer that just wants to make 100 paperclips and has access to a factory, will probably do so in an unsurprising way. But it doesn't work so well with non-existence type values; a satisficer that wants to ensure there are no more than 100 cases of malaria, might turn all matter into space exploration probes to hunt down cases on other planets. A satisficer that wants to reduce the number of cases of malaria by at least 100 might work, but then your utility function is defined in terms of a tricky counterfactual. For example, if it's "100 fewer cases than if I hadn't been turned on", then... what if it not having been turned on, would have lead to a minimizer being created instead? Then you're back to converting all atoms into space probes.