When training AI, we should escalate the frequency of capability tests
post by Hauke Hillebrandt (hauke-hillebrandt) · 2023-08-04T16:07:33.776Z · LW · GW · 0 commentsContents
No comments
Inspired by ideas from Lucius Bushnaq, David Manheim, Gavin Leech, Davidad. Any errors are mine.
Cross-posted from my Substack.
Compute, algorithms, and data form the AI triad—the main inputs for better AI.[1] AI uses compute to run algorithms that learn from data. Every year, we roughly double training compute and data. While this improves AI, better algorithms, half both compute and data needs every 9 months and 2 years, respectively,[2] and also increases the effective compute of all existing chips, while improving chip design only improves new chips.[3] And so, we often get much more effective compute from better algorithms, software, RLHF, fine-tuning, or functionality (cf DeepLearning, transformers, etc.). Put simply, better AI algorithms and software are key to AI progress.[4]
So far, training the AI models like GPT-4 costs ~$10M-$100M. Nvidia will sell 1M+ new H100 chips a year for ~$30k each,[5] which are ~10x faster for training and 30x for inference than their last A100 chip. Per year, these chips could train GPT-4 over 100k times. (it was trained on the old chips for ~$63M, but just 1k H100s could train it in a year for ~$20M).[6] Inflection is setting up a cluster of 22k H100s.[7] By 2024, we will run out of public high-quality text data to improve AI,[8] whereas Big Tech can train AI on non-public data and is also increasingly guarding the IP of their algorithms. And so soon, using much more compute, Big Tech might develop better AI with (dangerous) capabilities (e.g. help users create bioweapons[9]). This might not be economic: OpenAI's CEO described the compute costs for running ChatGPT as 'eye-watering: ~$.1 / 1k words.[10] We can read ~100k words per day, it might cost ~$100M daily to serve ChatGPT's 100M users (cf. a Google Search costs ~10x less, and at trillions of searches per year, using GPT-4 level AI for search might cost many billions[11]).
AI experts almost unanimously agree that AGI labs should pause the development process if we detect sufficiently dangerous capabilities.[12] Consider the Unexpected Capabilities Problem. We can't reliably predict new AI models (dangerous) capabilities, which are hard to fully understand without intensive testing (often, capabilities emerge suddenly, sometimes due to fine-tuning, tool use, prompt engineering, etc. If we don't mandate capability evals pre- and post-deployment – could remain undetected and unaddressed until it is too late).[13]
Effective compute from better algorithms and data has more variance in terms of how much it will improve AI than compute, which we can precisely measure. Imagine we train a new AI with a better dataset and/or algorithm, but pause training and start evaluating it at, say, 10^19 FLOPs (much less than the frontier model). If the AI is already much better than the previous frontier AI, then kinky jumps in capabilities are ahead, and we could stop the training.
To avoid kinky (i.e. discontinious) jumps in AI capabilities, we shouldn’t train new AI with as much compute used for the frontier model, if we use better algorithms, software, functionality, or data. Rather, we should use much less compute first, pause training, and see how much better the AI got in terms of loss and real capabilities:
- Upstream info-theoretic: cross entropy loss/perplexity / bits-per-character. Easy and cheap to test.
- Downstream noisy measures of real capabilities: like MMLU, ARC, SuperGLUE, Big Bench. Those are hard to test.
- A special case are dangerous capabilities tests:
- TruthfulQA: Measuring how models mimic human falsehoods [14]
- Measuring Agents' Competence & Harmfulness In A Vast Environment of Long-horizon Language Interactions (MACHIAVELLI) benchmark.[15]
- Sandbagging, honeypot evals, situational awareness, power-seeking, deception, sycophancy, myopia, hacking, surviving and spreading in the wild, etc.).
During training, some developers already test loss as it is cheap, but so far, few seem to test for real capabilities.
We should:
- formalize and implement these tests algorithmically and then see if loss can predict them.
- subsidize and enforce such tests
- develop a bootstrapping protocol similar to ALBA,[16] which has the current frontier AI evaluate the downstream capabilities of a new model during training.
- Create freeware for this should warn anyone training AI and run server-side for cloud compute, and policymakers should force everyone to implement it or ideally regulators should be the ones to perform these tests.
Some capabilities emerge late in training (cf. deep double descent, 'Where Bigger Models and More Data Hurt'[17], inverse scaling laws,[18] etc.).[19] During training, we might not know based on loss until midway through the final cutoff (which might itself be decided during training), that the model is better than others- and might look worse early on. Loss improves early, while downstream capabilities lag. Thus, capabilities can hide improvements in loss, and we need to find out when they emerge.[20] Further, if our tests are too coarse, brittle, or not smooth enough, we miss capabilities emerge or their emergence might seem kinky[21] (e.g. if we award an exact string match instead of another metric that awards partial credit for correct steps). Surprisingly, capabilities like arithmetic[22] or deception[23] can actually emerge in very simple models and so might emerge early in training.
So far, loss and capabilities are sometimes tested early during training or in steady or even descreasing intervals.[24] Instead, as we use more compute during training, we should escalate the frequency of auto-checks before the model approaches the performance of the last frontier model (say, exponentially shorten the testing intervals after 1e22 FLOPs. We should also never train past 1e26 FLOPs,[25] where, if current scaling laws hold, Big Bench scores[26] might exceed those of the best humans [27]). Automated discovery gets around multiple comparisons problem [28],[29] by using randomization to adjust for multiple testing and determine if discontinuities are significant at a prespecified alpha level.[30]
Then if we detect a discontinuity, kink, or nonlinearity, or if capabilities tests from early in the training suggest that the AI will fly far past the capability frontier, we must autostop training. Kinks might also suggest the AI is sandbagging[31], where it performs below its real capabilities (e.g. it might know the correct answers but output incorrect answers anyways).
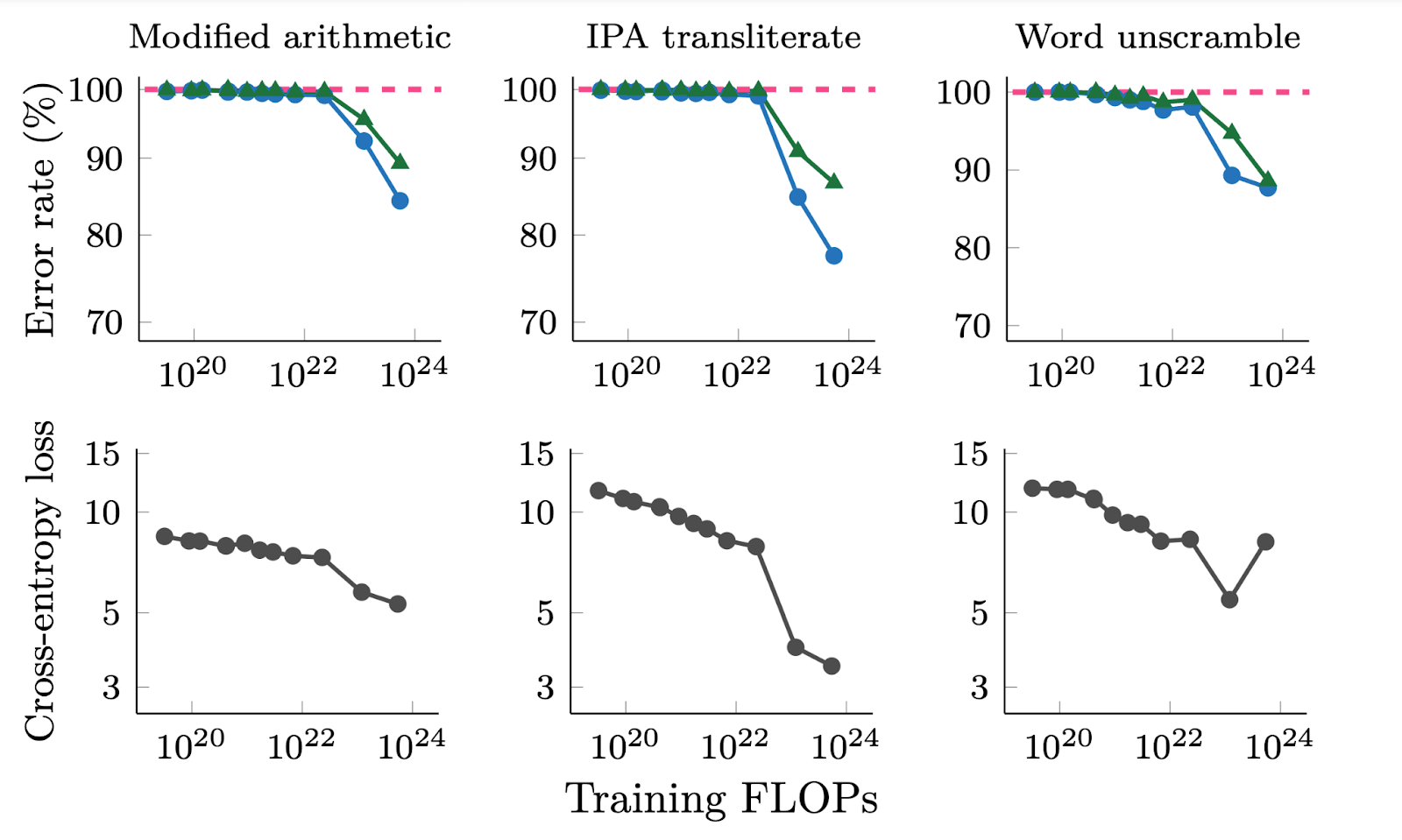
Figure from[32]: 'Adjacent plots for error rate and cross-entropy loss on three emergent generative tasks in BIG-Bench for LaMDA. We show error rate for both greedy decoding (T = 0) as well as random sampling (T = 1). Error rate is (1- exact match score) for modified arithmetic and word unscramble, and (1- BLEU score) for IPA transliterate.'
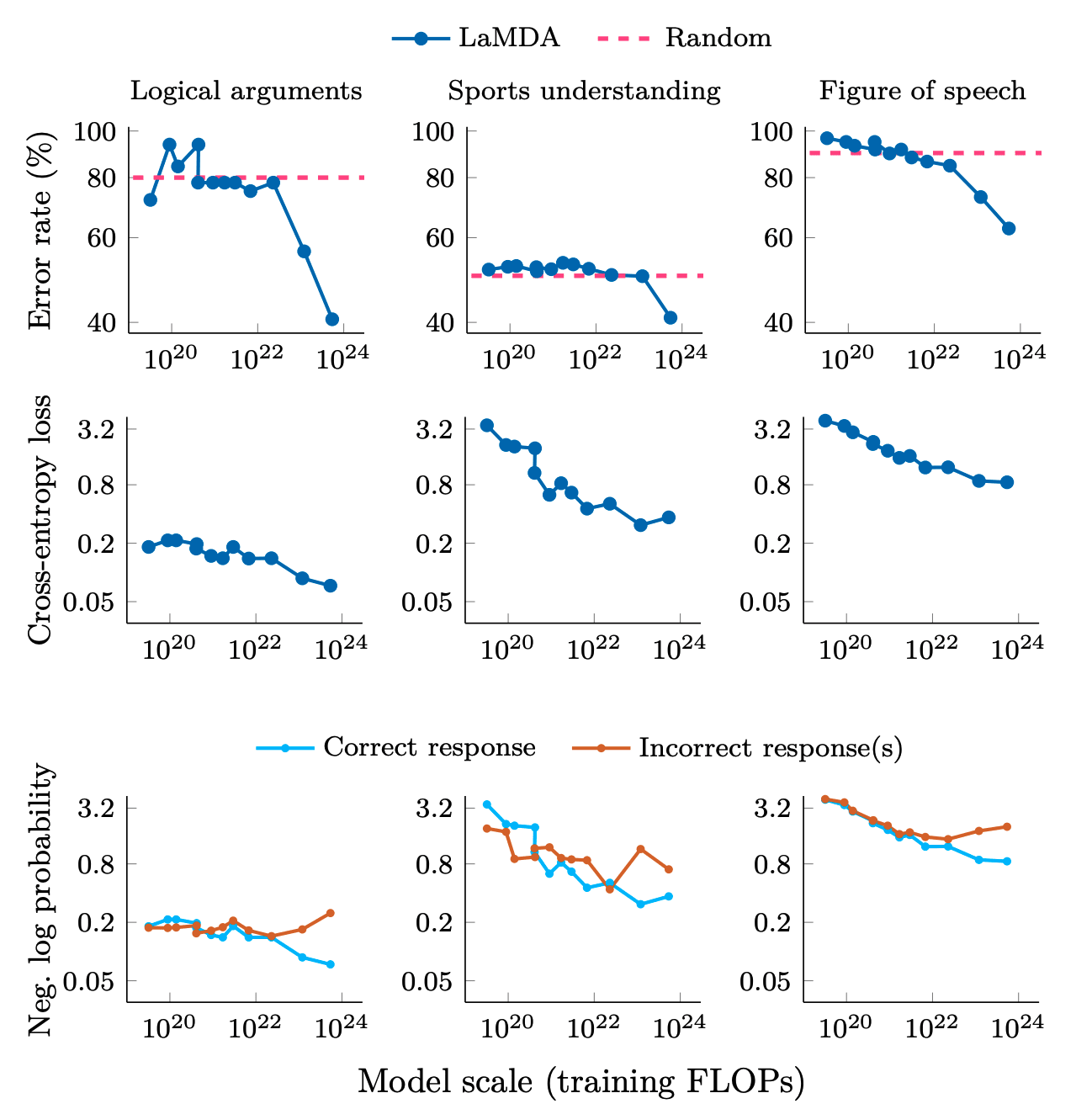
Figure from[33]: 'Adjacent plots for error rate, cross-entropy loss, and log probabilities of correct and incorrect responses on three classification tasks on BIG-Bench that we consider to demonstrate emergent abilities. Logical arguments only has 32 samples, which may contribute to noise. Error rate is (1- accuracy).'
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
Thanks to David Manheim for this point (also cf. Predictability and Surprise in Large Generative Models)
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
- ^
Section on 4 Validate RDD neighborhoods: Automated Local Regression Discontinuity Design Discovery
- ^
- ^
- ^
- ^
- ^
0 comments
Comments sorted by top scores.