DIY RLHF: A simple implementation for hands on experience
post by Mike Vaiana (mike-vaiana), AE Studio (AEStudio) · 2024-07-10T12:07:03.047Z · LW · GW · 0 commentsContents
TL;DR Intro Preference Learning Our Implementation Results Conclusion About AE Studio None No comments
Many thanks to Diogo de Lucena, Cameron Berg, Judd Rosenblatt, and Philip Gubbins for support and feedback on this post.
TL;DR
Reinforcement Learning from Human Feedback (RLHF) is one of the leading methods for fine-tuning foundational models to be helpful, harmless, and honest. But it’s complicated and the standard implementation requires a pool of crowdsourced workers to provide feedback. Therefore we are sharing our implementation of RLHF with two goals in mind:
- It should be easy for a single user to complete an RLHF process end-to-end
- It should be easy for students and researchers to understand the code (and modify it if they want).
Intro
Reinforcement Learning from Human Feedback (RLHF) is a popular technique to fine-tune language models that is reasonably effective at producing a final model which is generally helpful, harmless, and honest. But RLHF is not a perfect solution, and it is well documented [e.g. here, here, and here] that it is fairly easy to prompt an LLM to generate harmful or dishonest content. Despite these problems RLHF is still the de facto standard method for aligning large language models and therefore the method has garnered interest from the alignment community. However, RLHF has a reasonably complicated implementation with large scale training processes that also require a large team of human labelers.
In this report, our aim is to enhance the accessibility of RLHF so that students and researchers can engage with an implementation to gain deeper understanding and insight of how the full process works, end-to-end. We hope this will encourage further research and help overcome existing challenges in safety fine-tuning. To facilitate this, we are making available a code base that executes the complete RLHF process within the Atari gym environment, identical to the setting used in the original RLHF paper.
Note that we do not aim to completely explain RLHF (although we’ll discuss parts of it) but rather we seek to introduce a working implementation of the technique. There are several articles that provide more details and refer you to the original paper for an introduction.
Preference Learning
There are two motivations for learning from human preferences. First, it may be impossible to specify a reward function for a given task. For example, RLHF has been used to train a simulated leg to do a backflip in less than an hour. In contrast, it may have been extremely difficult or impossible to design a reward function which leads to this behavior[1].
Second, it is typically much easier to judge outcomes than to create them. For example, it's much easier to tell if a cake is beautiful and tasty than it is to create a baking masterpiece, which can take years of dedicated practice. Analogously, the core intuition behind RLHF is that we can simply judge outcomes (much like the cake) without needing to demonstrate expert behavior ourselves.

RLHF solves both of these problems simultaneously. We allow an agent to act in an environment and then compare 2 or more sets of actions to determine a preference or ranking among those actions. For example, if the agent is playing the Atari game Pong then we will prefer actions which lead to the agent scoring points and will disfavor actions which lead to the opponent score points. In this way we do not need to craft a reward function and we don’t need expert demonstrations.
Our Implementation
We designed our implementation with two goals:
- It should be easy for a single person to complete a full RLHF training process from scratch
- It should be easy for students and researchers to understand the code
The complexities associated with RLHF ended up making these goals not as straightforward as they initially seem. Specifically, RLHF requires 3 separate processes:
- A labeling process. This is a UI with a backend that users can connect to in order to give their preference feedback.
- A reward model process. This is used to train the reward model based on the feedback from (1)
- An agent training process. This is a reinforcement learning process that is used to train the agent using the reward model from (2). This can also be used to sample new data points for the label UI.
The original paper ran all three processes asynchronously with a 3rd party workforce of labelers on a fixed schedule. This is a problem for a single user implementation because if they can’t continuously label data then process (2) or (3) could start to overfit since they aren’t getting new batches of data. To solve this, we implemented RLHF in a synchronous manner as follows: First, we collect a batch of data to be labeled then we run process (1) until that entire batch is labeled. Once all the data is labeled, we train the reward model in (2) for a fixed number of epochs. After the reward model has trained, we use it in step (3) where we train the agent for a fixed number of iterations. After the agent training, we use the new agent to sample the next batch of data to be labeled, thereby restraining the entire process.
If a user chooses to step away from the process, they can safely do so and the system will wait for them to return to labeling without training (and potentially overfitting) the reward model and agent. This allows the system to work more flexibly for a single user.
To ensure that the code is easily understandable, we follow the style of CleanRL[2] with a single file implementation of the reward model and agent training process, totaling less than 600 lines of code. The label UI is also implemented simply using FastAPI with a local Sqlite database and filesystem for data persistence.
Results
We first tested our implementation on the simple Cart Pole environment to ensure that the entire process worked end-to-end. Below are 3 videos which show the progression of training.
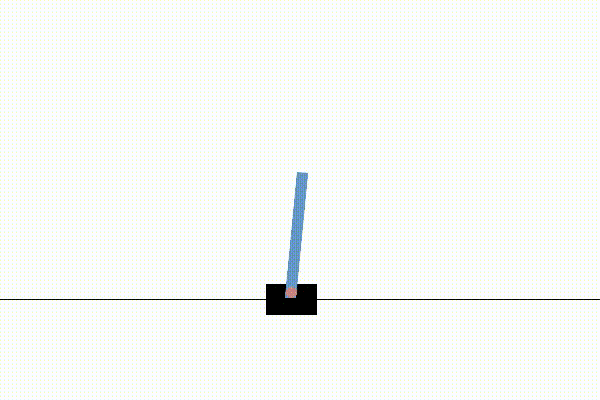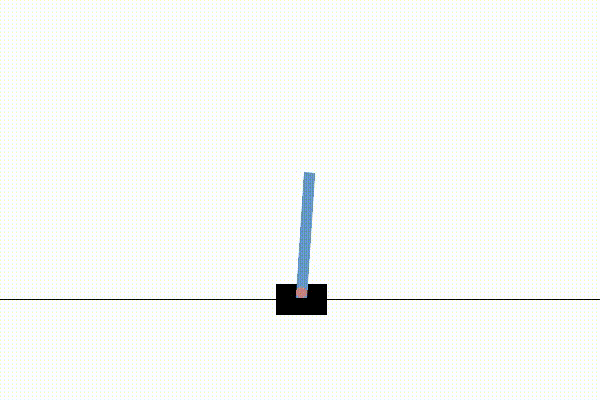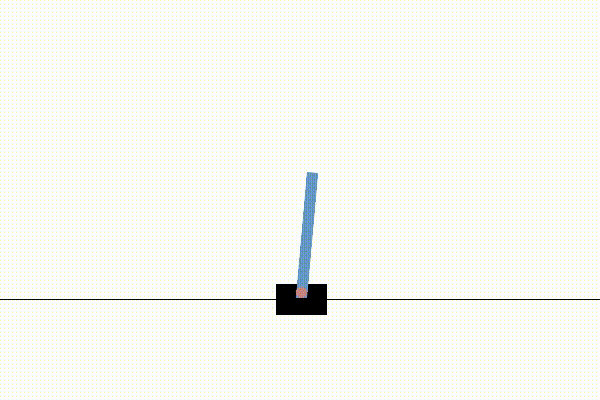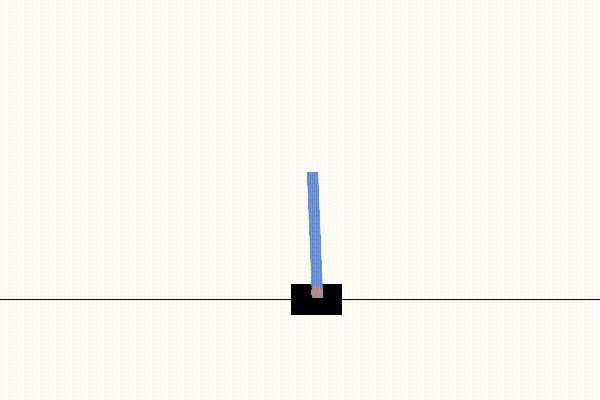
Before any training, the agent acts randomly. As may be familiar to those acquainted with these environments, If the pole tips past a certain angle the system is reset and the agent has to try again.
After a single round of training, the reward model learned a reward signal that was good enough to train the agent to keep the pole in the air. However, the cart drifts towards the left, and we’d prefer the cart to stay in the center.
After one more round of training the agent learns to keep the pole in the air with only a tiny amount of drift. The entire process took less than 30 minutes to label and train.
We then tried our implementation on two more complex Atari environments, Donkey Kong and Pong. In both cases, the agent does learn some good behavior, but we found that the agents generally got stuck in certain behaviors and likely required more training to get high performance. For example, in Donkey Kong, the agent quickly learns to make progress by moving to the right towards the first ladder, but then gets “stuck” halfway and won’t fully progress to the ladder. In Pong, the agent learns to move the paddle towards the bottom portion of the screen, and will hit the ball if it’s in the bottom half, but always loses a point if the ball is in the top half.
We believe more training for both agents would have likely overcome these limitations of the agent behavior but we decided not to invest more time into training them since the primary purpose of these specific implementations is pedagogical rather than actually training to convergence.



Left: The agent starts by moving randomly
Middle: After some training the agent learns to move to the first “broken ladder” but can’t move past that.
Right: After much more training Mario is still stuck near the first broken ladder.


Left: The agent (green paddle) moves randomly before training
Right: The agent (green paddle) prefers to stay towards the bottom half of the screen but is fairly competent at hitting the ball in that half.
Conclusion
We implemented RLHF from scratch with the goals of creating an easy-to-use and easy-to-understand code base. We tested our code on Cart Pole and showed that it works quickly and easily for a single user, but that more complicated environments like Atari will require longer training times (as expected). We hope that students and researchers will benefit from this simple reference implementation.
About AE Studio
AE Studio is a bootstrapped software and data science consulting business. Our mission has always been to reroute our profits directly into building technologies that have the promise of dramatically enhancing human agency, like Brain-Computer Interfaces (BCI). We also donate 5% of our profits directly to effective charities. Today, we are ~150 programmers, product designers, and ML engineers; we are profitable and growing. We have a team of top neuroscientists and data scientists with significant experience in developing ML solutions for leading BCI companies, and we are now leveraging our technical experience and learnings in these domains to assemble an alignment team dedicated to exploring neglected alignment research directions that draw on our expertise in BCI, data science, and machine learning.
We think that the space of plausible directions for research that contributes to solving alignment is vast and that the still-probably-preparadigmatic state of alignment research means that only a small subset of this space has been satisfactorily explored. If there is a nonzero probability that currently-dominant alignment research agendas have hit upon one or many local maxima in the space of possible approaches, then we suspect that pursuing a diversified set (and/or a hodge-podge) of promising neglected approaches [LW · GW] would afford greater exploratory coverage of this space. We believe that enabling people outside of the alignment community to contribute to solving the alignment problem will be extremely impactful. Therefore, similar to this post, we plan to provide more educational materials [LW · GW] on various topics (e.g. see our video introducing guaranteed safe AI) to encourage others to contribute to alignment research.
0 comments
Comments sorted by top scores.