REPL's and ELK
post by scottviteri · 2022-02-17T01:14:07.683Z · LW · GW · 4 commentsContents
4 comments
In my previous I talked about read-eval-print loops as providing a type signature for agents. I will now explain how you can quickly transition from this framework to an ELK solution. Notation is imported from that post.
Imagine we have two agents, a human and a strong AI, denoted H and M respectively. They both interact with the environment in lockstep, according to the following diagram.
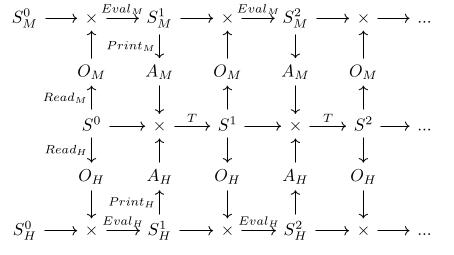
We have the human's utility function , which is defined on the human's model of reality. We would like to lift to a version that the machine can use to influence the world in way that is agreeable to the human, which we can do by learning a mapping F : and deriving .
But we haven't yet said what properties we want the ontology map F to have. I want to call two concepts and equal if they act the same with respect to transformation: f. f() = f() → = . The issue is that since the concepts have different types we cannot feed them as arguments to the same function. So instead let's say that s:S, (, (s)) = (, (s)) → = . But now we are back to the same problem where we are trying to compare concepts in two different ontologies. But this does give us a kind of inductive step where we can transfer evidence of equality between concept pairs (, ) and (', '). I also believe that this kind of a coherence argument is the best we can do, since we are not allowed to peer into the semantic content of particular machine or human states when constructing the ontology map.
Consider the following two graphs.

My intuition is that even if I don't know the labels of the above graphs, I can still infer that the bottom nodes correspond to each other. And the arrows that I get in the context of ELK are the agents' Eval transitions, leading to the following commutative diagram specification for F.
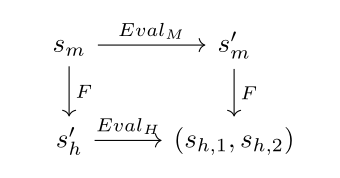
We can learn an ontology map F : by minimizing the difference between two paths from a state , one in which the machine's prediction function is used and one in which the human's prediction function is used. Concretely, I propose minimizing Dist(,) + |U()-U()| where = F((,)) and = (F(),), Dist is a distance metric in , and observations and are generated by the same underlying state S.
If you are interested in getting more detail and why I believe this circumvents existing counterexamples, please check out the full .
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-02-24T05:58:17.667Z · LW(p) · GW(p)
I can't help but feel that this sneakily avoids some of the hard parts of the problem by assuming that we know how to find certain things like "the state according to the AI/human" from the start.
Replies from: noumero↑ comment by Noumero (noumero) · 2022-02-25T14:00:09.340Z · LW(p) · GW(p)
Yeah, this is the part I'm confused about as well. I think this proposal involves training a neural network emulating a human? Otherwise I'm not sure how (F(),) is supposed to work. It requires a human to make a prediction about the next step using observations and the direct translation of the machine state, which requires us to have some way to describe the full state in a way that the "human" we're using can understand. This precludes using actual humans to label the data, because I don't think we actually have any way to provide such a description. We'd need to train up a human simulator specifically adapted for parsing this sort of output.
comment by Noumero (noumero) · 2022-02-19T03:28:29.482Z · LW(p) · GW(p)
I'm a bit confused about how it'd be work in practice. Could you provide an example of a concrete machine-learning setup, and how its inputs/outputs would be defined in terms of your variables?
Replies from: scottviteri↑ comment by scottviteri · 2022-04-11T17:01:05.156Z · LW(p) · GW(p)
A proper response to this entails another post, but here is a terse explanation of an experiment I am running: Game of Life provides the transition T, in a world with no actions. The human and AI observations are coarse-grainings of the game board at each time step -- specifically the human sees majority vote of bits in 5x5 squares on the game board, and the AI sees 3x3 majority votes. We learn human and AI prediction functions that take in previous state and predicted observation, minimizing difference between predicted observations and next observations given the Game of Life transition function. We then learn F between the AI and the human. We run the AI and human and lockstep and see if the AI can use F to suggest better beliefs in S_H, as measured by ability of the human to predict its future observations.