The Geometry of Feelings and Nonsense in Large Language Models
post by 7vik (satvik-golechha), Nandi · 2024-09-27T17:49:27.420Z · LW · GW · 10 commentsContents
Overview of the original paper Ablations Hierarchical features are orthogonal - but so are semantic opposites!? Categorical features form simplices - but so do totally random ones!? Orthogonality being ubiquitous in high dimensions Discussion and Future Work None 10 comments
This post has some ablation results around the thesis of the ICML 2024 Mech. Interp. workshop 1st prize winning paper: The Geometry of Categorical and Hierarchical Concepts in Large Language Models The main takeaway is that the orthogonality they observe in categorical and hierarchical concepts occurs practically everywhere, even at places where it really should not.
Overview of the original paper
A lot of the intuition and math around why they do what they do is shared in their previous work called The Linear Representation Hypothesis and the Geometry of Large Language Models, but let's quickly go over what the paper's core idea is:
They split the computation of a large language model (LLM) as:
where:
- is the context embedding for input (last token's residual after last layer),
- is the unembedding vector for output .
Next, to align the embedding and unembedding spaces and make the Euclidean inner product a causal one (see the paper for details), a transformation using the covariance matrix of the unembedding vectors is applied:
where is the unembedding vector, is the expected unembedding vector, and is the covariance matrix of .
Now, for any concept , its vector representation is defined to be:
Given such a vector representation for binary concepts (where is the linear representation of ), the following orthogonality relations hold:
I'm skipping some notation here, but this says that for hierarchical concepts mammal animal, we have .
Similarly, this means .
Also, they show that categorical concepts form simplices in the transformed representation space. For each of these theorems, they give concrete proofs and provide experimental evidence on GPT-4 generated data and Gemma representations for animal categories and plants. They start with a dataset that looks like:
animals = {
"mammal": ["beaver", "panther", "lion", "llama", "colobus", ... ],
"bird": ["wigeon", "parrot", "albatross", "cockatoo", "magpie", ... ],
"fish": ["snapper", "anchovy", "moonfish", "herring", ... ],
"amphibian": ["bullfrog", "siren", "toad", "treefrog", ...],
"insect": ["mayfly", "grasshopper", "bedbug", "silverfish", ...]
}Ablations
To study concepts that do not form such semantic categories and hierarchies, we add the following two datasets and play around with their codebase:
First, an "emotions" dictionary for various kinds of emotions split in various top-level emotions. Note that these categories are not expected to be orthogonal (for instance, joy and sadness should be anti-correlated). We create this via a simple call to ChatGPT.
emotions = {
'joy': ['mirth', 'thrill', 'bliss', 'relief', 'admiration', ...],
'sadness': ['dejection', 'anguish', 'nostalgia', 'melancholy', ...],
'anger': ['displeasure', 'spite', 'irritation', 'disdain', ...],
'fear': ['nervousness', 'paranoia', 'discomfort', 'helplessness', ...],
'surprise': ['enthrallment', 'unexpectedness', 'revitalization', ...],
'disgust': ['detestation', 'displeasure', 'prudishness', 'disdain', ...]
}Next, we add a "nonsense" dataset that has five completely random categories where each category is defined by a lot (order of 100) of totally random words completely unrelated to the top-level categories. This will help us get directions for random nonsensical concepts (again, via a ChatGPT call):
nonsense = {
"random 1": ["toaster", "penguin", "jelly", "cactus", "submarine", ...],
"random 2": ["sandwich", "yo-yo", "plank", "rainbow", "monocle", ...],
"random 3": ["kiwi", "tornado", "chopstick", "helicopter", "sunflower", ...],
"random 4": ["ocean", "microscope", "tiger", "pasta", "umbrella", ...],
"random 5": ["banjo", "skyscraper", "avocado", "sphinx", "teacup", ...]
}Hierarchical features are orthogonal - but so are semantic opposites!?
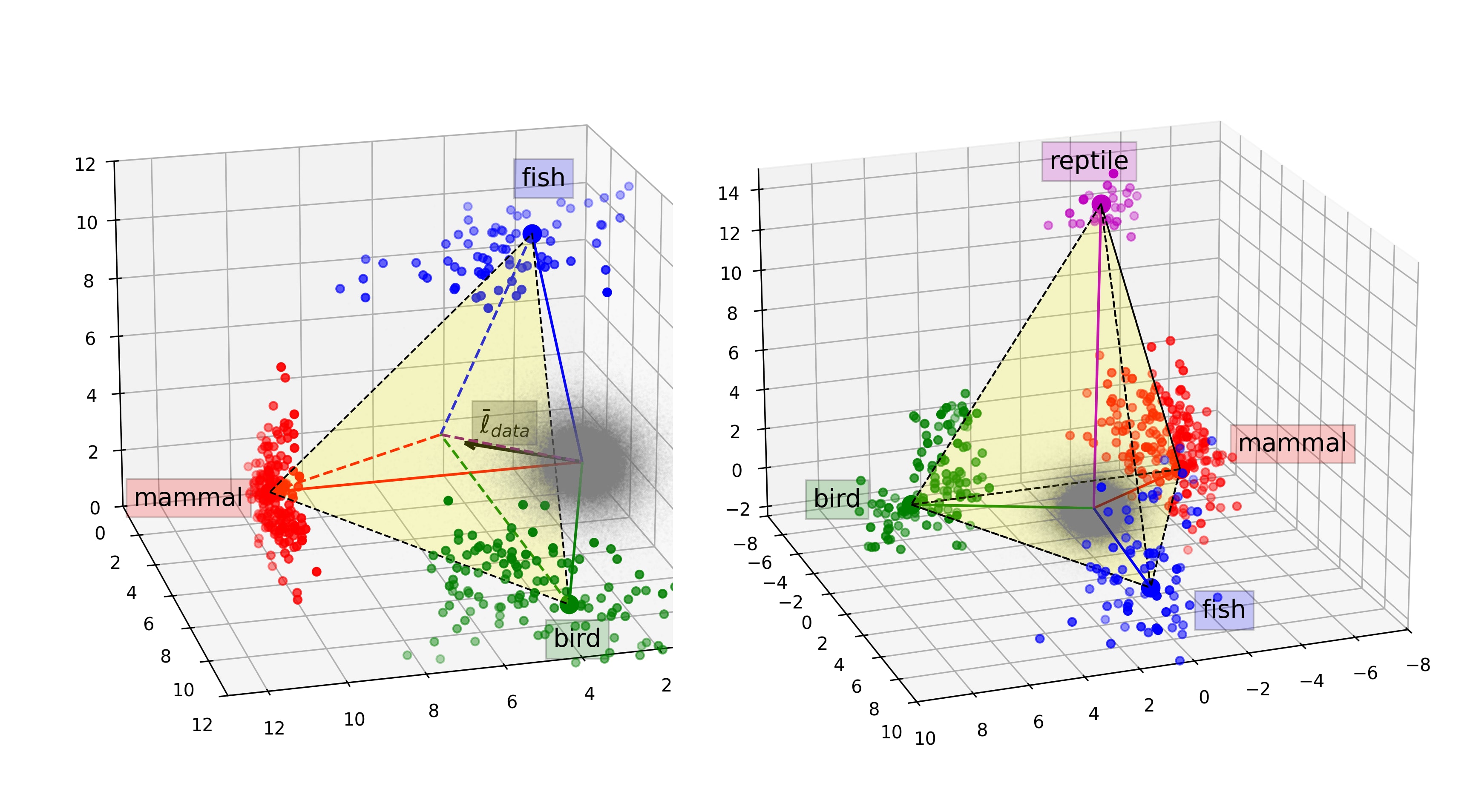
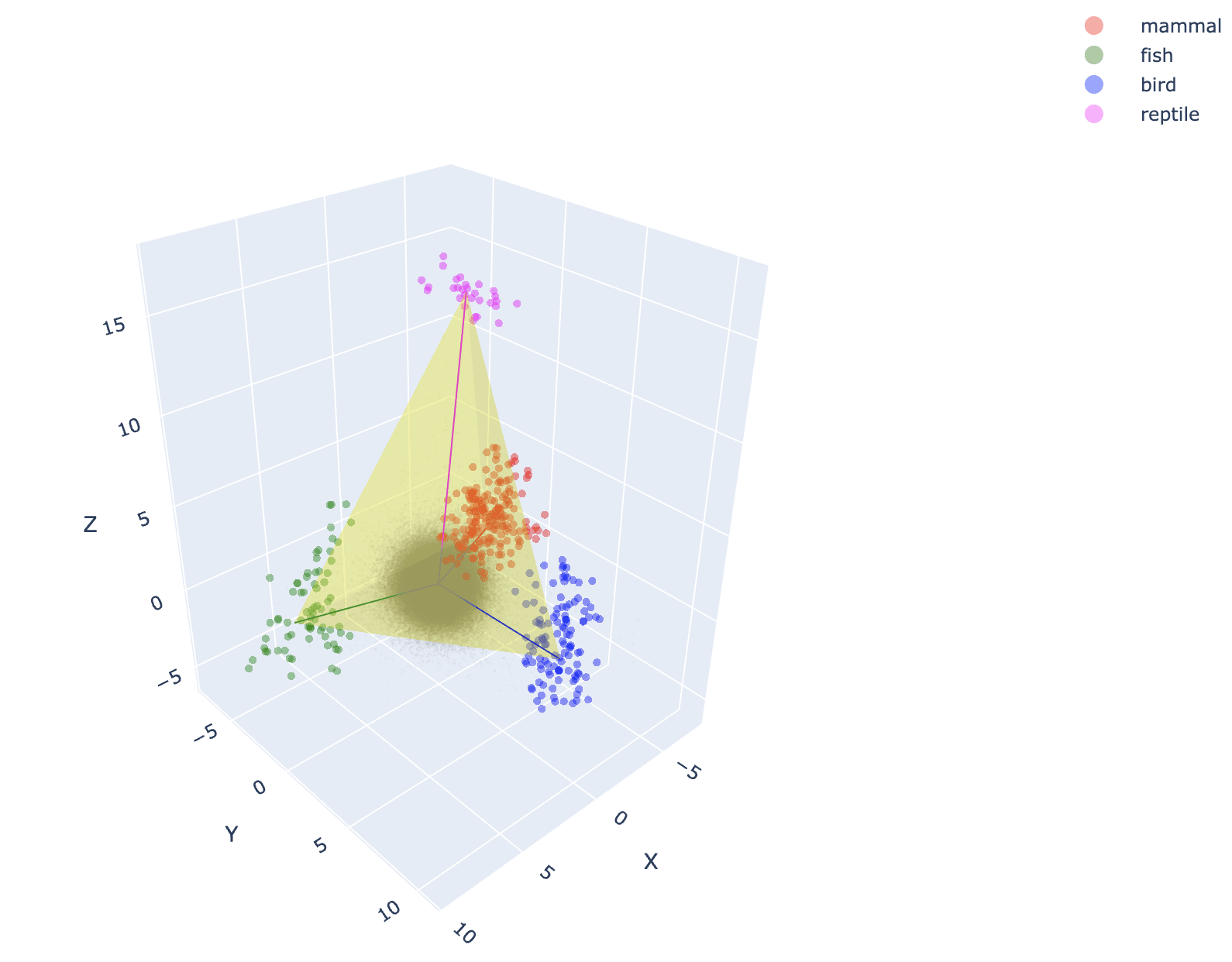
Now, let's look at their main experimental results (for animals):
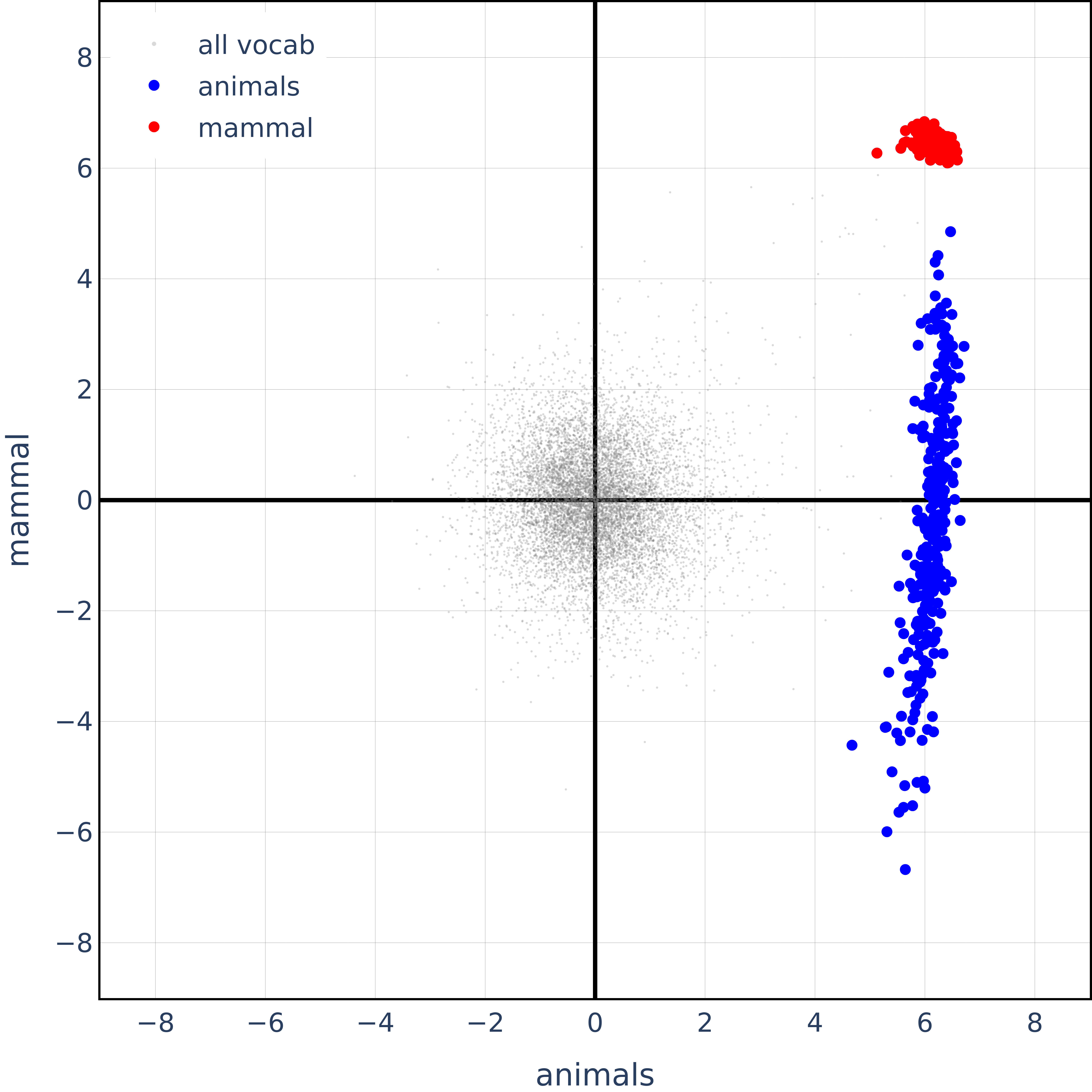
And this is what we get for emotions:
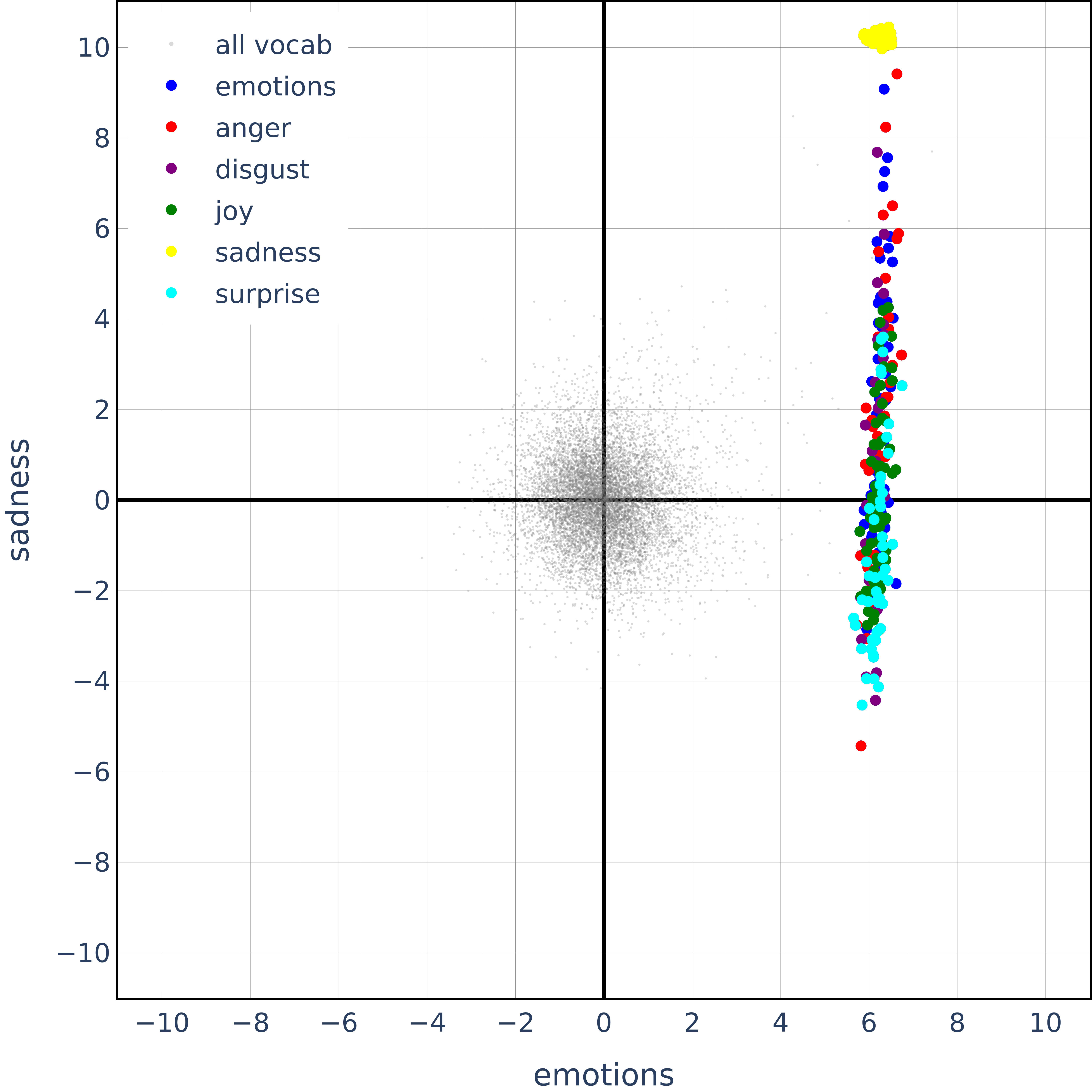
While this seems okay, look at the following plot where we just look at joy and sadness in the span of sadness and all emotions:
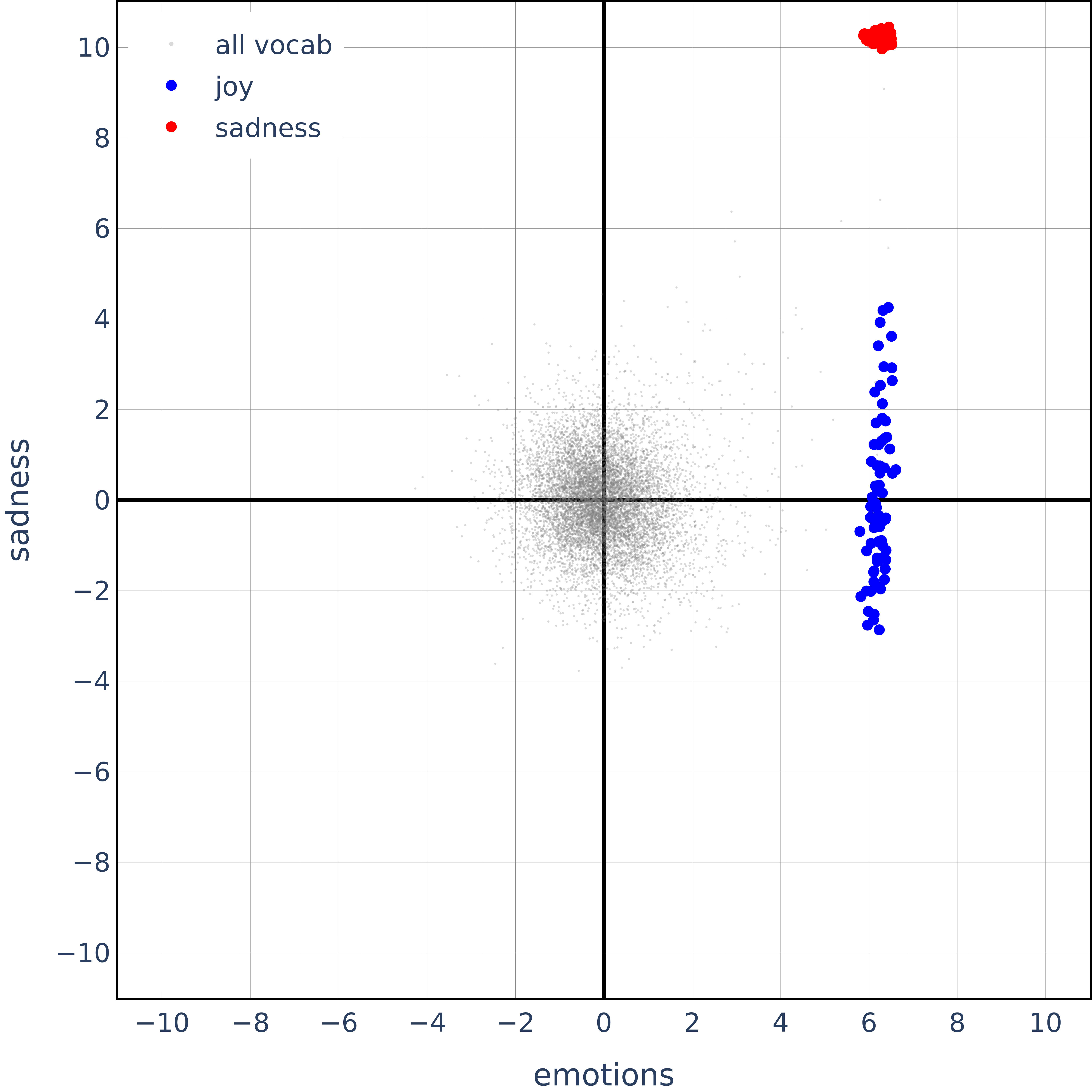
Sadness and joy are semantic opposites, so one should expect the vectors to be anti-correlated rather than orthogonal. Also, here's the same plot but for completely random, non-sensical concepts:
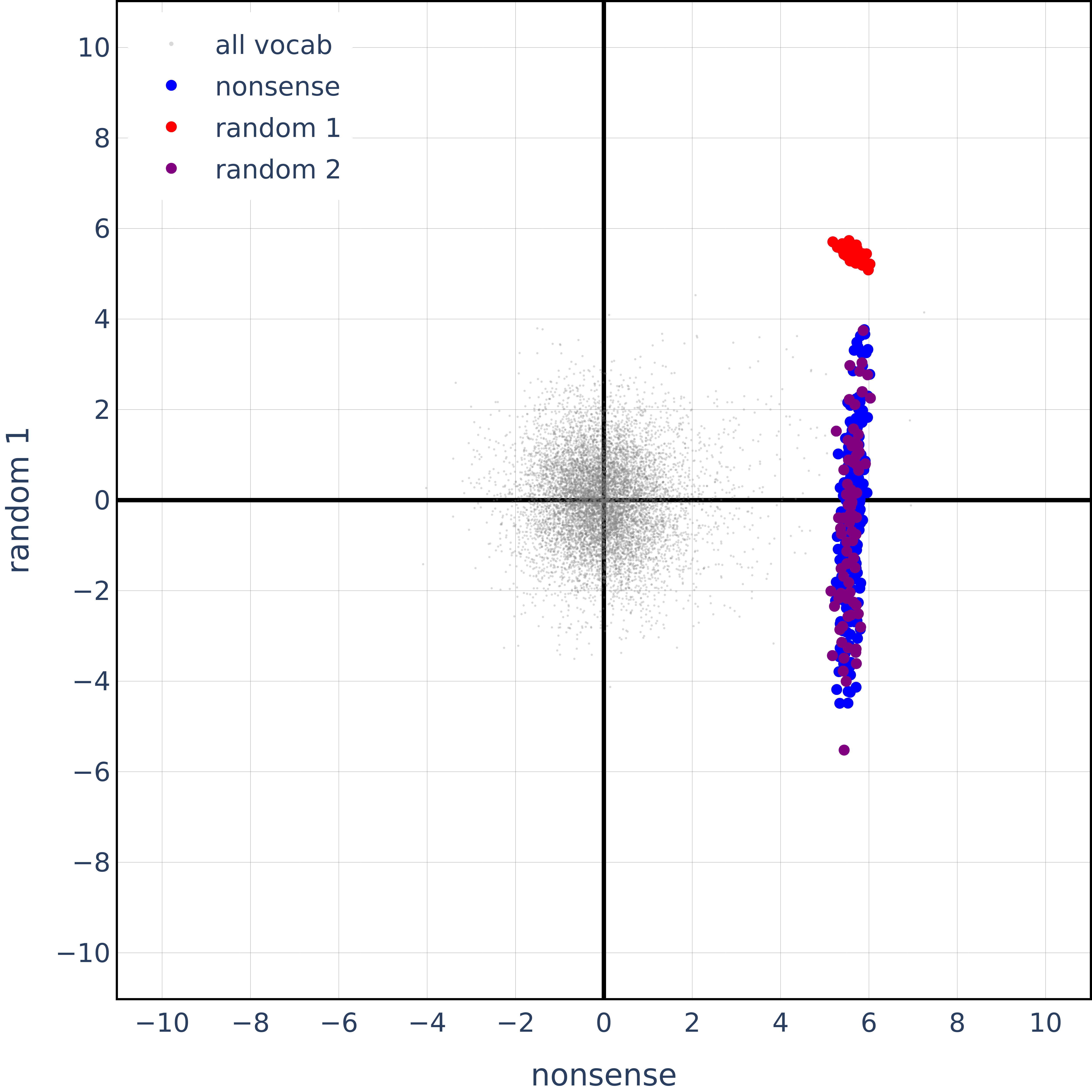
It seems like their orthogonality results, while true for hierarchical concepts, are also true for semantically opposite concepts and totally random concepts. 🤔
Categorical features form simplices - but so do totally random ones!?
Here is the simplex they find animal categories to form:
And this is what we get for completely random concepts:
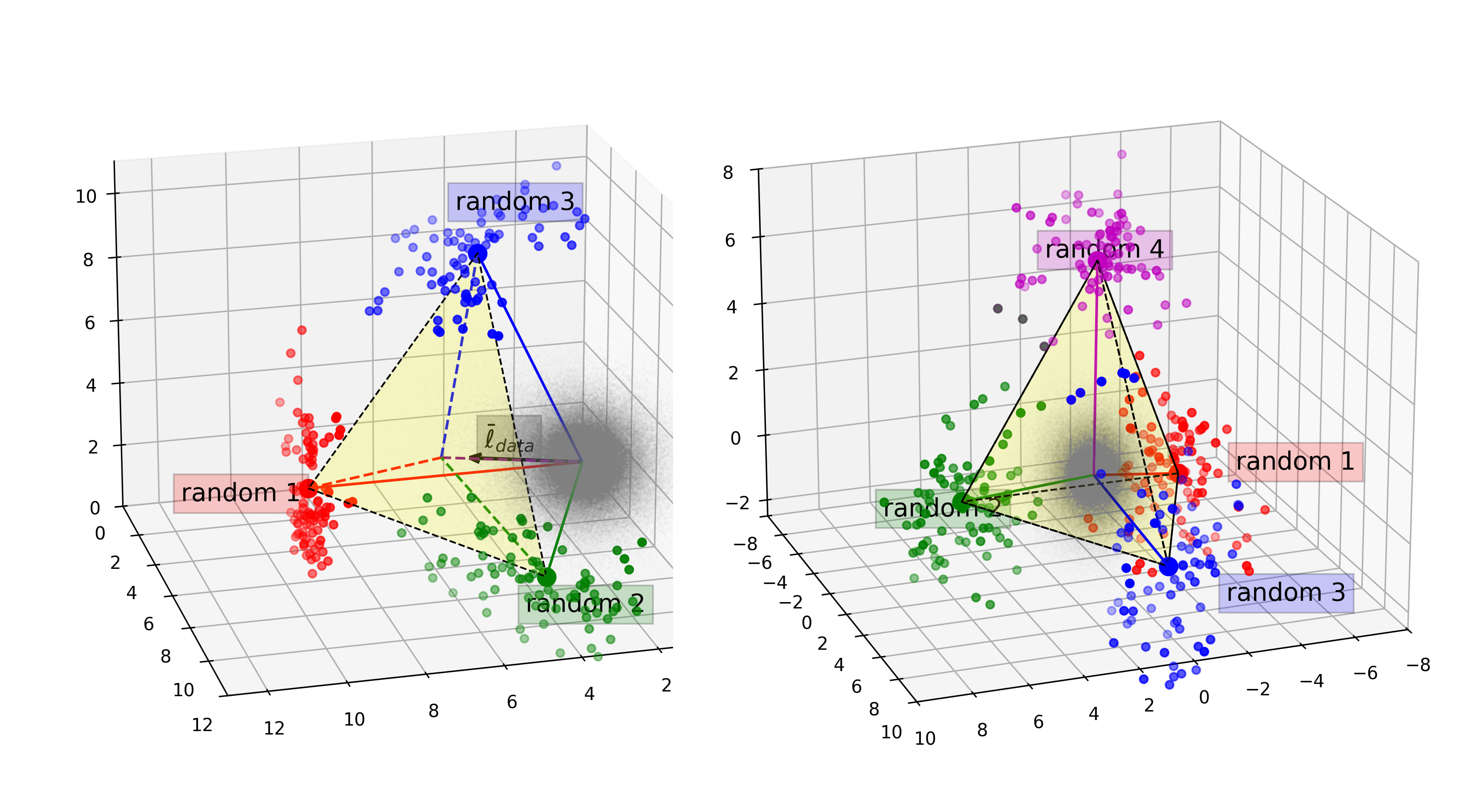
Thus, while categorical concepts form simplices, so do completely random, non-sensical concepts.
Orthogonality being ubiquitous in high dimensions
Because a model's representation space is quite high-dimensional ( in the case of Gemma), and independent random vectors are expected to be almost orthogonal in high-dimensional spaces. Multiple concrete proofs of the same are given here, but here's a quick intuitive sketch:
Let be random vectors in with their components distributed independently and uniformly on the unit sphere. The inner product between two vectors and is given by:
and has the following variance:
Thus, as (the number of dimensions) increases, the variance tends to zero:
This implies that, in high dimensions, random vectors are almost orthogonal with high probability:

Discussion and Future Work
A transformation where opposite concepts seem orthogonal doesn't seem good for studying models. It breaks our semantic model of associating directions with concepts and makes steering both ways impossible.
As for categorical features forming simplices in the representation space, this claim isn't surprising because every single thing seems to form simplices, even totally random concepts.
There are lots of ways of assigning a direction or a vector to a given concept or datapoint, and it is unclear if the vectors thus obtained are correct or uniquely identifiable.
Here are some of the questions this leaves us with and ones that we'd be very excited to work on in the near future (contact us to collaborate!):
- A framework on how to think about representations that unifies how they're obtained (contrastive activations, PCA, SAE, etc.), how they're used (by the model), and how they can be used to control (eg. via steering vectors).
- How to figure out how well a given object (a direction, a vector, or even a black-box function over model parameters) represents a given human-interpretable concept or feature.
- If orthogonality and simplices are too universal and not specific enough to study the geometry of categorical and hierarchical concepts, then what is a good lens or theory to do so?
10 comments
Comments sorted by top scores.
comment by TomasD (tomas-dulka) · 2024-09-28T20:00:06.290Z · LW(p) · GW(p)
Thanks this is very interesting! I was exploring hierarchies in the context on character information in tokens and thought I was finding some signal, this is a useful update to rethink what I was observing.
Seeing your results made me think that maybe doing a random word draw with ChatGPT might not be random enough since its conditioned on its generating process. So I tried replicating this on tokens randomly drawn from Gemma's vocab. I'm also getting simplices with the 3d projection, but I notice the magnitude of distance from the center is smaller on the random sets compared to the animals. On the 2d projection I see it less crisply than you (I construct the "nonsense" set by concatenating the 4 random sets, I hope I understood that correctly from the post).
This is my code: https://colab.research.google.com/drive/1PU6SM41vg2Kwwz3g-fZzPE9ulW9i6-fA?usp=sharing
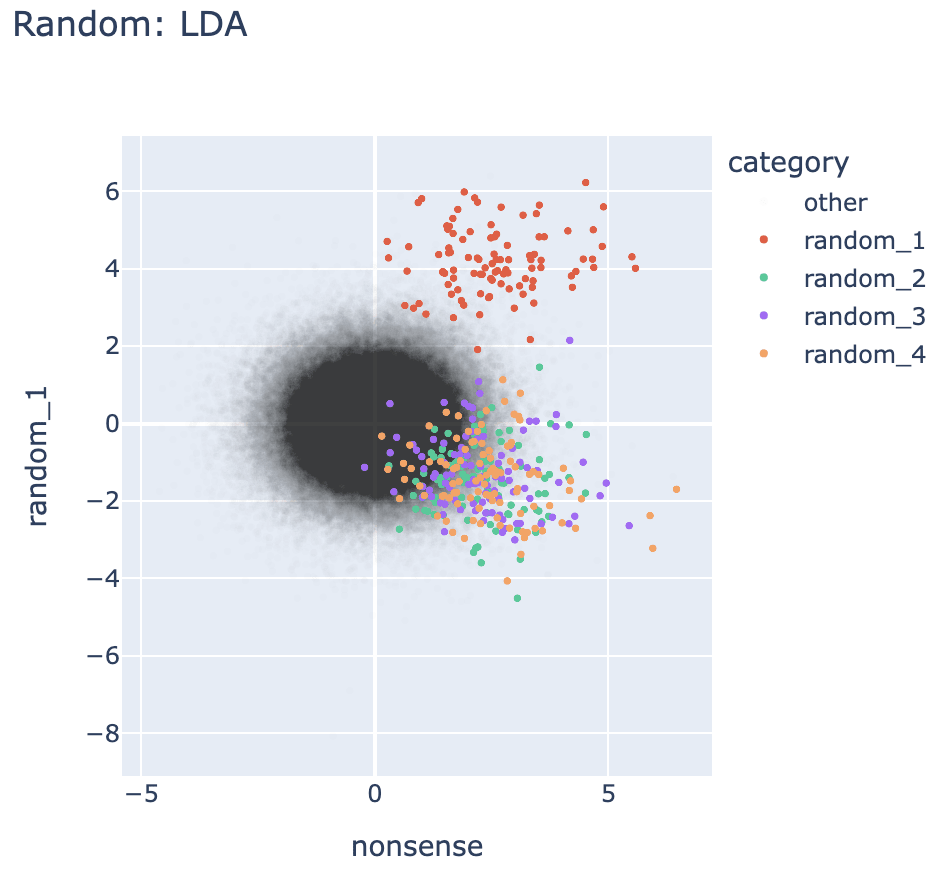
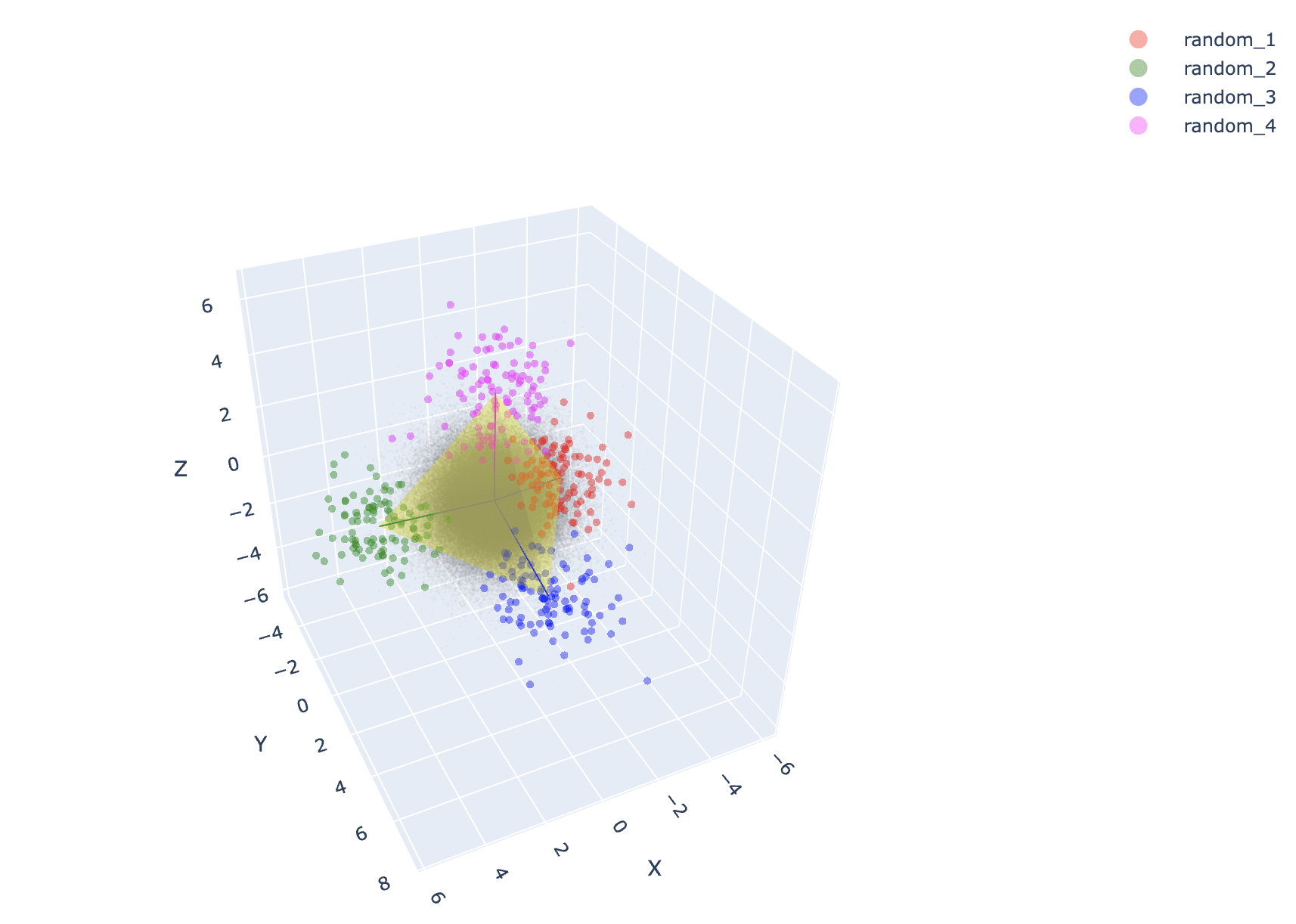
↑ comment by 7vik (satvik-golechha) · 2024-09-29T13:18:25.945Z · LW(p) · GW(p)
Thanks @TomasD [LW · GW], that's interesting! I agree - most words in my random list seem like random "objects/things/organisms" so there might be some conditioning going on there. Going over your code to see if there's something else that's different.
comment by Lucius Bushnaq (Lblack) · 2024-09-28T16:11:25.700Z · LW(p) · GW(p)
Nice work, thank you! Euan Ong and me were also pretty skeptical of this paper’s claims. To me, it seems that the whitening transformation they apply in their causal inner product may make most of their results trivial.
As you say, achieving almost-orthogonality in high dimensional space is pretty easy. And maximising orthogonality is pretty much exactly what the whitening transform will try to do. I think you’d mostly get the same results for random unembedding matrices, or concept hierarchies that are just made up.
Euan has been running some experiments testing exactly that, among other things. We had been planning to turn the results into a write up. Want to have a chat together and compare notes?
Replies from: satvik-golechha↑ comment by 7vik (satvik-golechha) · 2024-09-29T14:08:15.088Z · LW(p) · GW(p)
I agree. Yes - would be happy to chat and discuss more. Sending you a DM.
comment by Kiho Park (kihopark) · 2024-10-13T18:36:57.600Z · LW(p) · GW(p)
Thank you for reading our paper and providing such thoughtful feedback! I would like to respond to your points.
First, regarding your plot with the caption , it appears that you are still using “the span of sadness and all emotions” without estimating . As a result, there is no information about in the 2D projection plot. When I estimate both and using your token collections, I find that and .
Second, I agree that our original experiments lacked sufficient baselines. In response, we have uploaded version 2 of the arXiv preprint, which now includes a comprehensive set of baselines.
As you mentioned, vectors in high-dimensional spaces are orthogonal with high probability, assuming they are sampled from a normal distribution with isotropic covariance. This raises the question of whether our orthogonality results arise purely from high-dimensional properties.
In Figure 5, when using random parents (orange), the cosine similarities between child-parent and parent vectors are not zero. This indicates that the orthogonality of the original vectors (blue) is not simply a consequence of high-dimensional space.
Additionally, we introduced another baseline using randomly shuffled unembeddings. Shuffling the unembeddings is equivalent to using random concepts with the same set inclusion. For example, a child collection might now have {dog, sandwich, running} and a parent might have {dog, sandwich, running, France, scientist, diamond}. Interestingly, set inclusion still yields orthogonality (green), as shown in the left panel of Figure 5 (see Appendix G for further explanation). While it is possible to define hierarchy by set inclusion, this is not our focus. Instead, we are interested in whether semantic hierarchy produces orthogonality.
To test this, we disrupted set inclusion by splitting the training data when estimating the vector representation for each feature. In this case, the shuffled baseline no longer produced orthogonality, whereas the original unembeddings maintained orthogonality. This result suggests that the orthogonality of the original vectors is not merely a product of set inclusion or high-dimensional space effects.
Lastly, with regard to the simplex, our contribution lies in defining vector representations with a notion of magnitude, which naturally leads to polytope representations for categorical concepts. In theory, the 3D projection plot should show that the token unembeddings for each category are concentrated at the vertices, as demonstrated in Corollary 10. However, in practice, the projections of tokens are slightly dispersed, as shown in Figure 6.
comment by Arthur Conmy (arthur-conmy) · 2024-10-06T20:57:27.300Z · LW(p) · GW(p)
This is a great write up, thanks! Has their been any follow up from the paper's authors?
This seems a pretty compelling takedown to me which is not addressed by the existing paper (my understanding of the two WordNet experiments not discussed in post is: Figure 4 concerns whether under whitening a concept can be linearly separated (yes) and so the random baseline used here does not address the concerns in this post; Figure 5 shows that the whitening transformation preserves some of the word net cluster cosine sim, but moreover on the right basically everything is orthogonal, as found in this post).
This seems important to me since the point of mech interp is to not be another interpretability field dominated by pretty pictures (e.g. saliency maps) that fail basic sanity checks (e.g. this paper for saliency maps). (Workshops aren't too important, but I'm still surprised about this)
Replies from: satvik-golechha↑ comment by 7vik (satvik-golechha) · 2024-10-13T10:05:37.653Z · LW(p) · GW(p)
Thanks a lot! We had an email exchange with the authors and they shared some updated results with much better random shuffling controls on the WordNet hierarchy.
They also argue that some contexts should promote the likelihood of both "sad" and "joy" since they are causally separable, so they should not be expected to be anti-correlated under their causal inner product per se. We’re still concerned about what this means for semantic steering.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2024-09-28T00:12:55.552Z · LW(p) · GW(p)
The popular well-known similarity/distance metrics and clustering algorithms are not nearly as good as the best ones. I think it'd be interesting to see what the results look like using some better, newer, less-known metrics.
Examples:
- PaCMAP - a better UMAP
- DIEM - better cosine similarity. video explanation
- cosine similarity with cut initialization - a better cosine similarity
- Technique for Order Performance by Similarity to Ideal Solution (TOPSIS) - another better cosine similarity
- TS-SS Similarity - yet another better cosine similarity
- Vector Space Model
- Fusion-based semantic similarity
- Improving the Similarity Measure of Determinantal Point Processes for Extractive Multi-Document Summarization
- Comparing in context: Improving cosine similarity measures with a metric tensor
- Improved sqrt-cosine similarity measurement
- Improved Heterogeneous Distance Functions
- Encyclopedia of Distances - in case you just can't get enough, and want a whole book of distance measures!
I don't actually know if any of these would perform better, or how they rank relative to each other for this purpose. Just wanted to give some starting points.
In case you want to google for 'a better version of x technique', here's a list of a bunch of older techniques: https://rapidfork.medium.com/various-similarity-metrics-for-vector-data-and-language-embeddings-23a745f7f5a7
comment by Adam Shai (adam-shai) · 2024-09-28T19:44:33.298Z · LW(p) · GW(p)
Did the original paper do any shuffle controls? Given your results I suspect such controls would have failed. For some reason this is not standard practice in AI research, despite it being extremely standard in other disciplines.
Replies from: satvik-golechha↑ comment by 7vik (satvik-golechha) · 2024-09-29T13:24:29.678Z · LW(p) · GW(p)
They use a WordNet hierarchy to verify their orthogonality results at scale, but doesn't look like they do any other shuffle controls.