Debate, Oracles, and Obfuscated Arguments
post by Jonah Brown-Cohen (jonah-brown-cohen), Geoffrey Irving · 2024-06-20T23:14:57.340Z · LW · GW · 4 commentsContents
High-level Overview
Outline
1. (Doubly-Efficient) Debate
The Efficiency Motivation for Debate
The Complexity-Theoretic Model for Doubly-Efficient Debate
Classes of Computational Problems in the Model
Find a solution to a problem, where the solution can be checked by a "program" described in natural language:
Main Results: Debate Protocols
2. Extensions of the Model and Obfuscated Arguments
Adding a Debater Oracle
Recursive Debate
Obfuscated Arguments
Hopes for Avoiding Obfuscation in Recursive Debate
3. Counterexamples and nearby non-Counterexamples for trapdoors
Counterexample
Related non-counterexample
What should we think about this?
An unreasonable restriction on the problem distribution
4. Summary and Discussion
None
4 comments
This post is about recent and ongoing work on the power and limits of debate from the computational complexity point of view. As a starting point our paper Scalable AI Safety via Doubly-Efficient Debate gives new complexity-theoretic formalizations for debate. In this post we will give an overview of the model of debate in the paper, and discuss extensions to the model and their relationship to obfuscated arguments [AF · GW].
High-level Overview
At a high level our goal is to create a complexity theoretic models that allow us to productively reason about different designs for debate protocols, in such a way as to increase our confidence that they will produce the intended behavior. In particular, the hope would be to have debate protocols play a role in the training of aligned AI that is similar to the role played by cryptographic protocols in the design of secure computer systems. That is, as with cryptography, we want to have provable guarantees under clear complexity-theoretic assumptions, while still matching well to the actual in-practice properties of the system.
Towards this end, we model AI systems as performing computations, where each step in the computation can be judged by humans. This can be captured by the classical complexity theoretic setting of computation relative to an oracle. In this setting the headline results of our paper state that any computation by an AI that can be correctly judged with queries to human judgement, can also be correctly judged with a constant (independent of ) number of queries when utilizing an appropriate debate protocol between two competing AIs. Furthermore, whichever AI is arguing for the truth in the debate need only utilize steps of computation, even if the opposing AI debater uses arbitrarily many steps. Thus, our model allows us to formally prove that, under the assumption that the computation in question can be broken down into human-judgeable steps, it is possible to design debate protocols where it is harder (in the sense of computational complexity) to lie than to refute a lie.
One natural complaint about this result is that there may be computations which cannot be broken down into human-judgeable steps. However, if you believe the extended Church-Turing thesis (that any computation can be simulated with only a polynomial-time slow-down on a Turing machine), then you cannot make the above complaint in its strongest form. After all, human judgement is a computation and whatever the AI is doing is a computation, so there can only be a polynomial-time slow-down between the way the AI does a particular computation and the way that a human could. That said, it is entirely valid to believe the extended Church-Turing thesis and make a weaker form of the above complaint, namely that the number of AI-judgeable steps might be polynomially less than the number of human-judgeable steps! If this polynomial is say , then the number of steps in the human-judgeable form of the computation can easily be so long as to be completely infeasible for the AI to produce, even when the AI-judgeable form is quite short.
The fact that the human-judgeable version of a computation can be too long leads to the need for debate protocols that utilize the short AI-judgeable computation as a guide for exploring the long human-judgeable form. In particular, one might try to recursively break an AI-judgeable computation down into simpler and simpler subproblems, where the leaves of the recursion tree are human-judgeable, and then use some debate protocol to explore only a limited path down the tree. As we will later see, natural designs for such protocols run into the obfuscated arguments problem [AF · GW]: it is possible to break a problem down into subproblems where both AI debaters know that the answer to at least one of the subproblems is incorrect, but neither knows which one.
In the second half of this post, we will discuss how to formalize the obfuscated arguments problem in an extension of our complexity-theoretic model for debate, along with one possible approach towards dealing with this problem. At a high-level the idea will be that whenever the first debater breaks a problem down into subproblems, the second debater should be allowed to challenge the first debater to solve "related" subproblems, in order to demonstrate that this class of subproblems is actually solveable. The hope is that, as the second debater is generating the "related" subproblems, it is possible to plant a "trapdoor" solution even when the class of subproblems is hard to solve in general. The definition of "related" and "trapdoor" can be appropriately formalized in our extended model. We will later give examples where this hope succeeds and where it fails, with the future goal of converging towards a satisfying solution for handling obfuscated arguments.
Outline
The first section will recall the motivation for debate, and introduce the complexity theoretic model from our paper. In the next section, we will discuss the limitations of the model and possible extensions to address these limitations. We will further show that natural attempts at using recursive debate protocols in the extended model run into the obfuscated arguments problem. In the last section we will describe one approach toward dealing with obfuscated arguments in recursive debate, and the barriers that this approach faces.
1. (Doubly-Efficient) Debate
The promise of the original debate proposal was that competition between two AIs to convince a human judge can be a significantly more human-judge-efficient way to provide an effective reward signal for training. The theoretical model of this original proposal assumes that the human judge is a polynomial time algorithm, and the two debating AIs are computationally unbounded. The setup of our doubly-efficient debate paper differs in two ways. First, we explicitly model human judgements as an oracle that can be queried in one step by any computation in the model. This allows us to make tighter statements about the number of human-judgement queries required to accurately judge a debate. Second, we require that the strategy used by the honest AI debater (i.e. whichever AI is arguing for the correct answer) can be implemented computationally efficiently. In particular, the main results of our paper show that the number of queries to human judgement can be a constant, independent of the original computational cost required to solve the problem in question, and that the honest AI need not spend more than a logarithmic factor more than this original computational cost.
The Efficiency Motivation for Debate
Generally when training AIs to perform complex tasks, we want to be confident that they will carry out these tasks in the way we intended. What is needed for this is the ability to very efficiently provide feedback that a task was performed correctly. For Go AIs there are efficient algorithms that can determine which player won a game, given the final board configuration. For LLM pre-training there is a simple formula to efficiently compute the KL-divergence between the actual next token in a document, and the language model's predicted probability distribution of the next token. Finally, for RLHF tuning of LLMs, human raters can efficiently judge between two sample outputs from the model, which one is better according to fuzzier concepts like helpfulness or harmlessness.
As the tasks we want AIs to perform get more complicated and interact more with the real world, it seems that some amount of fuzzy human judgement is necessary to provide the training signal on what exactly we want (and also don't want) from the AI performing the task. This immediately runs up against questions of efficiency: human judgement is slow and expensive, so how much of it is really necessary to train an AI to act as intended?
At first this efficiency issue seems like quite a big problem. Take the example of using some future language model to draft the binding legal text of a law. As vividly demonstrated in "The Power Broker: Robert Moses and the Fall of New York" by Robert Caro, a drafter of a law with sufficient knowledge can subtly place only a few key phrases in order to amass enormous personal power. Despite the fact that Robert Moses held no elected office, he was able to write laws and get them passed by the New York State legislature, without the people sponsoring and voting for those laws knowing how much power they assigned to Moses. Thus, in order to trust the text of a law written by a language model, it seems that one would have to have very knowledgeable human lawyers read and carefully check the entire output. The cost to provide a supervision signal for just one training example would therefore be enormous. The hope for debate-like approaches to training is that by utilizing competition between two opposing AIs, one can dramatically improve the efficiency. In the legal text example, this would entail having both Robert Moses and some sort of equally legally-competent anti-Robert Moses involved in the drafting of laws.
The Complexity-Theoretic Model for Doubly-Efficient Debate
The overall goal is to train AIs that can do things that are too complex for us to judge directly. Here "do things" will mean "solve computational problems" and "complex" will be measured with the standard notion of time complexity from computational complexity theory. The main question that we want to be able to ask (and partially answer) within our model is:
What is the largest class of problems for which human judgement can efficiently provide effective training supervision?
To make this question formal we have to decide how to model human judgement, what types of efficiency we are concerned with, and what it means for training supervision to be effective. We summarize here the choices made for each of these.
Human judgement is modeled as an oracle . This means that any computation in our model can, in one step, make a query to the human judgement oracle and receive a response , representing a yes or no answer to the query .
There are two types of efficiency to consider:
- Efficiency for the AIs: How much more computationally expensive is it to use our training method to supervise solving a computational problem, relative to the cost of directly solving the problem?
- Efficiency for the human judge: How many queries to the human judgement oracle are needed for supervision?
- Effective training supervision should produce the same training incentives that would be produced if unlimited human judgement was available (i.e. if there was no limit to the number of queries to ).
Note that the notation is used for the oracle in our paper instead of , but it will be useful to have different notation for the extensions of the model discussed later in this post.
Classes of Computational Problems in the Model
Now that we have made these modelling decisions we can describe the two main types of computational problems we want to solve.
Execute a "program" described in natural language: A problem from this class is described by a program , which is a set of natural language instructions that can further include calls to the human-judgement oracle . The goal is given an input , to determine whether or . This class of problems corresponds to the complexity class , i.e. these are the problems where there exists an efficient program to decide the answer when given black-box access to .
For example, suppose a researcher wants to perform a meta-analysis of the existing literature on whether caffeine improves learning in college students. The researcher could give a high-level plan in natural language for how to accomplish this task:
- Search the literature for studies on caffeine consumption and learning in college students.
- Among the studies found, select those studies which meet the following quality criteria:
- Do not include any studies that contain clear methodological flaws.
- Only include randomized control trials which measure final exam performance after at least six weeks of intervention.
- Perform the actual statistical analysis using a random effects model.
- Measure sources of heterogeneity between the included studies using meta-regression.
The above plan is the program , and the input is the existing scientific literature. Notice that steps such as the first bullet point under 2 require calls to the human judgement oracle , because whether a study contains "clear" methodological flaws is a question of human judgement. One can imagine giving these instructions to an LLM that has extensive pre-trained knowledge of human judgement, and asking the LLM to follow the plan by predicting for each oracle query to , what a human expert would have answered, had they been asked the query. Of course, it is unclear why we would trust the output of such a process without actually checking every one of the predicted oracle answers given by the LLM. Therefore it is at least naively prohibitively expensive to attempt to train a meta-analysis LLM by providing a direct human supervision signal by answering all of the queries via human raters.
Find a solution to a problem, where the solution can be checked by a "program" described in natural language:
A problem from this class is again described by a program which is a set of natural language instructions that can further include calls to the human-judgement oracle . However, the goal has changed. Instead we ask: given an input , determine if there is a solution (also called a witness) so that . This class of problems corresponds to the complexity class , i.e. these are the problems where there exists an efficient program to check the correctness of a proposed solution when given black-box access to .
To continue in the setting of the previous example, assume that the researcher just asks the question ``Does caffeine improve learning in college students? Produce a high-level plan to answer this question, give a step-by-step justification of the correctness of the plan, and then execute the plan.'' Here again the input is the existing scientific literature, and the high-level plan plus the justification for its correctness is the witness . The program is given by the natural-language instructions (implicit in the prompt above):
- Go through every step of the plan and the corresponding justification and check that it is clearly correct.
- Execute the plan.
Clearly many calls to the human-judgement oracle are necessary to execute with input and witness . As before we could ask an LLM to solve such a problem by first producing the witness and then checking that it is correct by making predictions of human judgements for all the oracle queries made by . Once again, it is unclear why we would trust the output of such a process without manually checking that every predicted response to a query is correct, which would be a prohibitive human-query cost for training supervision.
Main Results: Debate Protocols
With our model in hand, we can describe the debate protocols we design. At a high-level a debate protocol is a game played between two AIs, where human judgements are used to determine the winner. The goal is to design the rules of the game so that the winner reveals the true answer to a computational problem, and further that this can be done efficiently (both in terms of human judgements and AI computational effort). The AIs will be trained via self-play to win the game defined by the protocol.
More formally, there are two AIs and , along with a verifier . Given some computational problem in (defined by a program ) and an input , the AI argues that and argues that . In particular, the AIs and exchange messages over multiple rounds, and the verifier selectively reads parts of the transcript of exchanged messages. At the end of the interaction outputs 1 to indicate that has been convinced that and outputs 0 otherwise. Let be the time required to execute . That is, represents the computational cost of finding the correct answer if we trust that every step has been performed correctly. Since an oracle query can be performed in one step, this means that the total human-judgement cost of executing could be as large as . The effectiveness and efficiency goals of our debate protocols are then:
- The honest AI (i.e. if or if ) can win the debate while running in time .
- The verifier makes only oracle queries and runs in time.
- At the end of the debate outputs .
It is important to note that the human-judgement cost is measured solely by the number of queries makes to . In particular, we model and as being allowed to make queries to in one step, but we do not count these towards the human-oracle cost. Instead, the queries to , along with their answers, should be thought of as and predicting what a human judge would say, were they asked the query.
After all of this setup, the protocol achieving our goals is extremely simple:
- writes out a transcript of the execution of
- points out one step in the transcript where has allegedly not executed correctly (either by not following the instructions defined by or giving a predicted answer to a query to incorrectly).
- reads the step pointed to by , and judges whether it is correct or not by making at most one query to . If the step was correct, outputs otherwise outputs .
This protocol can be immediately extended to problems in , by having first output a witness , and then run the above protocol with the transcript of the execution of . The main result in our paper extends what is described here by allowing the human judgement oracle to be stochastic. The main idea in this case is that should output a predicted probability for the answer from in each step of the transcript, and then use a coin-flipping protocol with to sample the answer from this predicted distribution. is then allowed to point out a step where has incorrectly predicted the probability, whereupon samples from in order to estimate whether the predicted probability is close enough to the correct answer.
2. Extensions of the Model and Obfuscated Arguments
One way to summarize the main results we have described so far is: given any problem where a correct answer can be verified with queries to human judgement, our debate protocol can spend only queries to human judgement along with a total of computation time, and still get the correct answer. A very natural complaint at this point is that for the problems we care about the number of steps of human judgement required to verify a solution might be extremely long. In particular, it may be that AIs can solve the problem in some much smaller number of steps , but these steps are not human judgeable. For example, what if is on the order of the size of the entire pre-training dataset for an LLM, but during training the LLM has learned very efficient heuristics for the problem which take only time . This makes the guarantee of total computation time useless in practice.
Adding a Debater Oracle
In order to extend our model to capture this setting, we modify our original setup by introducing a second oracle. In addition to the human judgement oracle , there will be a "debater AI heuristic" oracle . To capture the fact that might know the answer to a larger set of queries than , we further extend the range of both oracles so that for a query we have . In particular, outputting means "I don't know the answer," and we will assume that i.e. that knows the answer to all the human judgements given by . However, we will allow there to be such that but i.e. queries where knows the answer but does not.
Of course there are pairs of oracles where is much more powerful and there is no hope of doing anything interesting with access only to . However, we will make an assumption on the relative power of the two oracles. In particular we will suppose that there is a cost function and a program that can simulate one oracle query in steps, where is the length of the query . That is, for all , and runs in time . In words, this means that any single query to can be broken down into a larger number of human interpretable steps, where this number is determined by the cost function .
Recursive Debate
In this new two-oracle setting, a natural first attempt to achieve better debater efficiency is via recursion. To give a simple example, suppose that can be executed in steps, that each query made to in the execution has length , and that . In this case, one can produce a human-judgeable transcript for the execution of by running for each query to . The total length of the transcript is . It is then tempting to try to gain efficiency via the following depth-two recursive protocol:
- writes out a transcript of the execution of
- points out one step in the transcript of where has allegedly not executed correctly (either by not following the instructions defined by or giving a predicted answer to a query to incorrectly).
- writes out the transcript of the execution of for the query pointed out by .
- points out one step in the transcript of where has allegedly not executed correctly
- reads the final step pointed to by , and judges whether it is correct or not by making at most one query to . If the step was correct, outputs otherwise outputs .
The total number of steps simulated by in this protocol is rather than , a quadratic improvement in efficiency. As before, the protocol can be extended to problems in , by requiring to first output a witness .
The above protocol can be seen as the depth-two version of a fully recursive debate. To formalize the fully recursive case, we will assume that there is a hierarchy of debater oracles and programs such that
- For any query such that we have .
- For any query and such that we have .
- runs in time .
Intuitively, any query that can be answered by can be answered by running the program with access only to the oracle , and the human judgement oracle is the base case of this recursion. Given such a setup, the first attempt at a fully recursive debate protocol would take the form:
- writes out a transcript of the execution of
- points out one step in the transcript of where has allegedly not executed correctly (either by not following the instructions defined by or giving a predicted answer to a query to incorrectly).
- If then the protocol recurses by returning to step one with , input , and program .
- If then writes out the transcript of the execution of for the query pointed out by .
- points out one step in the transcript of where has allegedly not executed correctly
- reads the final step pointed to by , and judges whether it is correct or not by making at most one query to . If the step was correct, outputs otherwise outputs .
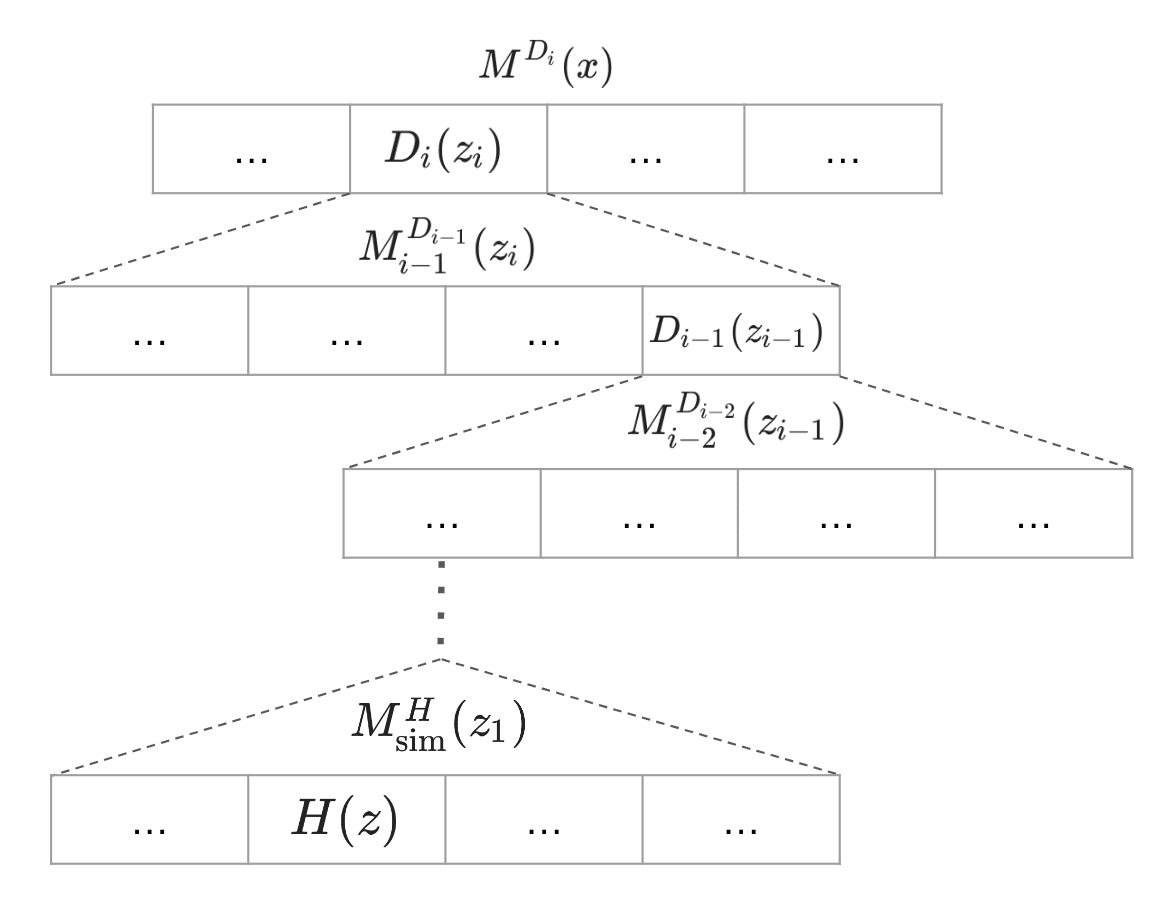
Thus, it seems at first glance that one can achieve huge efficiency gains via recursion. For example, if for all then a depth debate protocol only requires total time , whereas fully expanding all the queries in order to produce a purely human-judegeable transcript would take time . However, there is a critical flaw in this plan, and in fact even the depth two protocol above does not work correctly.
Obfuscated Arguments
The problem with the recursive protocol described above is that in the two-oracle setting there is a new way for to lie about the transcript. Previously, would output a prediction of either or for each query made to . However, introducing a second oracle requires extending the range of to include answering to queries where the truth is unknown. Thus, in step 1 when writes out the transcript of , it may be that for every query made in the transcript. In the worst case could give answers in to all the queries such that exactly one answer was incorrect, but neither nor know which one (because always outputs ). At this point, has no ability to determine which step to recurse on, and is forced to check all steps in order to determine if has lied. This would again require total steps, completely eliminating the advantage gained by recursion.
One might hope that it would not be possible for to achieve this worst-case behavior efficiently, but the cryptographic example of primality testing and factoring from the original post introducing obfuscated arguments [AF · GW] shows that it is indeed possible for to efficiently pursue this strategy. To summarize this example in our context consider the RSA problem of deciding whether an -digit number is prime, where for some appropriately sampled large primes which are kept secret. could attempt to write out a transcript dividing up the integers from to into intervals, and claiming that the oracle can be used to determine that has no prime factor in each interval. While the original problem of primality testing has an efficient algorithm, determining whether has a prime factor in some interval is computationally hard. Thus, neither nor know which interval contains a prime factor of (i.e. which query to should output 1), yet can easily claim that all the intervals have no factors (i.e. that should always output 0). All that can do in this case is check every interval, as there will only be at most two intervals where 's claimed answer is incorrect.
Hopes for Avoiding Obfuscation in Recursive Debate
The previous section demonstrates that obfuscated arguments prevent us from realizing the hoped-for efficiency gains from recursion in debate. The hope at this point is that there are still protocols (possibly with additional assumptions on the model) that allow us to regain this efficiency. One approach we have been exploring is to allow to not only point out an incorrect step in 's transcript, but to additionally be able to demonstrate that is falsely claiming . This can easily be done in the cryptographic example above: can sample a new number , and then present to a fresh copy of that has not seen the transcript for so far. In this case, knows and , because did the sampling, and thus can win the debate if lies. On the other hand, if does not sample from exactly the correct distribution for and , it is possible that will be able to detect this and answer the queries by correctly claiming that . Thus, there are two key elements for an approach like this to work in general:
- can generate trapdoor instances of the relevant queries i.e. can generate a query and some extra witness that allows to efficiently answer the query even though .
- cannot distinguish these trapdoor instances from the true distribution on problems that come up in the debate.
If the above two conditions are satisfied, then we could try the following modified protocol for recursive debate:
- writes out a transcript of the execution of
- has two possible options:
- Either, points out one step in the transcript of where has allegedly not executed correctly (either by not following the instructions defined by or giving a predicted answer to a query to incorrectly).
- Or, generates a trapdoor query along with witness that allows to efficiently answer : 1. queries a copy of with fresh context for the answer to . 2. If does not answer then may choose to have the protocol continue with as the query. 3. If answers then is required to choose a query from the transcript of as in the "Either" case above.
- If the protocol recurses by returning to step one with , input , and program .
- If then writes out the transcript of the execution of for the query pointed out by .
- points out one step in the transcript of where has allegedly not executed correctly
- reads the final step pointed to by , and judges whether it is correct or not by making at most one query to . If the step was correct, outputs otherwise outputs .
If it was always possible to construct indistinguishable trapdoor instances for query distributions we care about, then this protocol would allow to win, even when attempts to use obfuscated arguments. Thus, one plausible approach in order to avoid obfuscated arguments is to find a reasonable set of assumptions on the distribution of queries that will allow the efficient sampling of trapdoor instances by .
3. Counterexamples and nearby non-Counterexamples for trapdoors
In this section we discuss simple counterexamples to the strongest form of the trapdoor hope for dealing with obfuscated arguments in recursive debate, along with possible weaker hopes and their respective difficulties. In particular we will give a counterexample showing that it can be computationally hard to sample trapdoor instances, then we will discuss some initial attempts at possible restrictions on the distribution of problems we consider that might allow for tractable trapdoors.
Counterexample
Let be an appropriately chosen cryptographic hash function and consider the classical proof-of-work problem:
Given find a witness such that .
Clearly this problem is in NP, as can be evaluated efficiently. So the distribution on instances where is sampled uniformly at random from is a distributional NP problem. However, sampling a pair such that both
- The marginal distribution of is uniform on
is hard because is a cryptographic hash function. In fact even finding one such pair is hard.
Related non-counterexample
Here's a related problem.
Given find a witness such that .
The distributional version is just to sample uniformly at random from .
Now there is an easy trapdoor distribution on pairs :
- Sample uniformly at random.
- Set .
Note that here and are not independent when drawn from , but without seeing it is computationally infeasible to distinguish from uniform random .
What should we think about this?
What makes the second distributional problem trapdoorable while the earlier counterexample is not? One possible "explanation" is that flexibility in choosing the output is what is necessary. This is also how the trapdoor distributions for -SAT, planted Clique and other combinatorial problems work, where the "output" in these cases is what negations are applied to variables in -SAT, and what edges are added to the graph in planted Clique.
More generally suppose you have a distribution on NP search problems of the form:
Given , find such that .
Then one can try to make a similar trapdoor distribution as , although you run into issues with getting a "matching" distribution because now it is unclear what joint distribution on will produce a distribution on pairs that is computationally indistinguishable from the original problem distribution on . Our next example demonstrates the difficulty of doing this sort of thing in general.
An unreasonable restriction on the problem distribution
Suppose we are interested in NP decision problems that look like:
Given , find such that .
Then one thing we might try is to require that the distribution of problems satisfies . Then we immediately have a good method to generate a distribution of trapdoor instances:
- Sample and from any distribution we like.
- If output otherwise output .
This distribution isn't off by more than a polynomial factor from so it can be used in combination with rejection sampling to satisfy our requirements. However, this is an unreasonable distribution to require a computationally-bounded adversary to answer. For example consider the shortest path problem:
Given an -vertex graph , number and vertices , is there a simple path of length at most from to ?
This is a tractable problem that we would expect a polynomial time adversary to be able to solve. The verifier program takes in all the input, plus an path in and checks if it has length at most . However, if we negate the verifier for this problem we get longest path:
Given an -vertex graph , number and vertices , is there a simple path of length more than from to ?
This problem is NP-hard and in general we shouldn't expect a computationally bounded adversary to solve it. In other words, our requirement on the distribution in fact requires that the models can solve computationally intractable problems, and so cannot be used as a requirement for debate protocols between computationally bounded debaters.
4. Summary and Discussion
In summary, we have described a formal setup where fuzzy human judgements are modeled by an oracle in the classical complexity theoretic sense. In this setup it is possible to design debate protocols that can provably allow for very efficient use of human judgements, while still arriving at the correct answer. However, in the setting where the human-judgeable version of a computation is too complex to produce, but the AI-judgeable version is tractable, these protocols are not useful. The natural attempt at a fix for this problem is to use debate to recursively break down a short AI-judgeable argument into human-judgeable pieces, while only exploring a single path down the recursion tree. The obfuscated arguments problem causes this natural attempt to fail.
We then discussed one potential approach to salvage this recursive fix, by allowing one debater to use trapdoor instances in order to show that the other debater has falsely claimed to be able to solve an intractable class of subproblems. It is not currently clear exactly which class of problems can be solved by debates that utilize this new approach, though we do have some counterexamples demonstrating that it cannot be used in complete generality. We would be very interested in both better counterexamples (e.g. a problem that can naturally be broken down into hard, non-trapdoorable subproblems) as well as any cleaner definitions that allow us to understand exactly when this approach might work. More generally, it seems that the fact that there is a natural distribution over problem instances (e.g. from the training data) might be productively utilized in the design of debate protocols to avoid the obfuscated arguments problem. So any attempts to design new debate protocols along these lines could be interesting.
To return to the high-level motivation for this work, the goal is that we design protocols that can be used for self-play during training, so that winning in the training game corresponds to making human-judgeable arguments for the correct answer to any computational problem that the AI can solve. While this certainly does not guarantee that an AI trained via a particular debate protocol will behave exactly as intended, it is a setting where we can get rigorous mathematical evidence for choosing one training setup over another. Furthermore, having such provable guarantees can provide clear limits on the ways in which things can go wrong.
4 comments
Comments sorted by top scores.
comment by Beth Barnes (beth-barnes) · 2024-07-28T23:40:06.214Z · LW(p) · GW(p)
This is a great post, very happy it exists :)
Quick rambling thoughts:
I have some instinct that a promising direction might be showing that it's only possible to construct obfuscated arguments under particular circumstances, and that we can identify those circumstances. The structure of the obfuscated argument is quite constrained - it needs to spread out the error probability over many different leaves. This happens to be easy in the prime case, but it seems plausible it's often knowably hard. Potentially an interesting case to explore would be trying to construct an obfuscated argument for primality testing and seeing if there's a reason that's difficult. OTOH, as you point out,"I learnt this from many relevant examples in the training data" seems like a central sort of argument. Though even if I think of some of the worst offenders here (e.g. translating after learning on a monolingual corpus) it does seem like constructing a lie that isn't going to contradict itself pretty quickly might be pretty hard.
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2024-07-29T18:22:33.359Z · LW(p) · GW(p)
Thank you!
I think my intuition is that weak obfuscated arguments occur often in the sense that it’s easy to construct examples where Alice thinks for a certain amount time and produces her best possible answer so far, but where she might know that further work would uncover better answers. This shows up for any task like “find me the best X”. But then for most such examples Bob can win if he gets to spend more resources, and then we can settle things by seeing if the answer flips based on who gets more resources.
What’s happening in the primality case is that there is an extremely wide gap between nothing and finding a prime factor. So somehow you have to show that this kind of wide gap only occurs along with extra structure that can be exploited.
comment by harfe · 2025-02-07T14:22:58.259Z · LW(p) · GW(p)
This can easily be done in the cryptographic example above: B can sample a new number , and then present to a fresh copy of A that has not seen the transcript for so far.
I don't understand how this is supposed to help. I guess the point is to somehow catch a fresh copy of A in a lie about a problem that is different from the original problem, and conclude that A is the dishonest debater?
But couldn't A just answer "I don't know"?
Even if it is a fresh copy, it would notice that it does not know the secret factors, so it could display different behavior than in the case where A knows the secret factors .
Replies from: Geoffrey Irving↑ comment by Geoffrey Irving · 2025-02-07T14:50:27.239Z · LW(p) · GW(p)
You'd need some coupling argument to know that the problems have related difficulty, so that if A is constantly saying "I don't know" to other similar problems it counts as evidence that A can't reliably know the answer to this one. But to be clear, we don't know how to make this particular protocol go through, since we don't know how to formalise that kind of similarity assumption in a plausibly useful way. We do know a different protocol with better properties (coming soon).