Understanding Agent Preferences
post by martinkunev · 2025-02-24T17:46:04.022Z · LW · GW · 0 commentsContents
What are preferences? Modelling preferences How do we determine an agent's preferences? When is a preference not defined? Non-deterministic preferences Indifference Von Neumann Morgenstern utility theorem Completeness and Transitivity Independence Continuity What can we conclude about VNM? Thinking of preferences as a manifestation of utilities the agent assigns to states appears misguided. Complications in the real world None No comments
epistemic status: clearing my own confusion
I'm going to discuss what we mean by preferences of an intelligent agent and try to make things clearer for myself (and hopefully others). I will also argue that the VNM theorem has limited applicability.
What are preferences?
When reasoning about agent's behavior, preferences are a useful abstraction. Preferences encode epistemic information about an agent's behavior. Suppose you are about to play a single game of rock-paper-scissors against an AI. If you know that the AI has a preference for rock over scissors, you can use that knowledge and reason:
(0) If the AI has both rock and scissors among its choices, it will not choose scissors.
(1) The AI can choose freely from the set {rock, paper, scissors}.
(2) Therefore the AI will never play scissors.
Provided you have the goal of winning or at least not losing from the AI, you can conclude that you should play paper.
Consider a chess-playing program that uses MCTS (Monte Carlo Tree Search) to select the next move - e.g. it selects the move estimated to be most likely to lead to mate. We can say that the program prefers a move resulting in mate over other moves, yet its source code does not contain an explicit representation of preferences (such as "capturing a knight is better than capturing a pawn"). Still, the concept of preferences is useful to communicate and reason about the behavior of the agent. When we talk about preferences, we mean to describe knowledge about how the agent acts, not how the agent is implemented. Preferences are in a map of the cognitive system. Even when a program explicitly reasons about preferences, what is encoded in that program are not the actual preferences. Rather, it is some (potentially inaccurate) representation of them.
Humans represent their own preferences internally and can reason about them, although the representations and reasoning are sometimes flawed - e.g. a person may think "I will not eat ice cream" but then end up eating ice cream.
Modelling preferences
All models are wrong, but some are useful
- George Box
One makes a model (a.k.a. a map) of the territory via abstractions - ignoring some details which are deemed irrelevant. An example of such abstraction is splitting the world into an environment and an agent that acts in it. We call a description of the environment at a given moment a state. The environment can change over time, transitioning from one state to another.
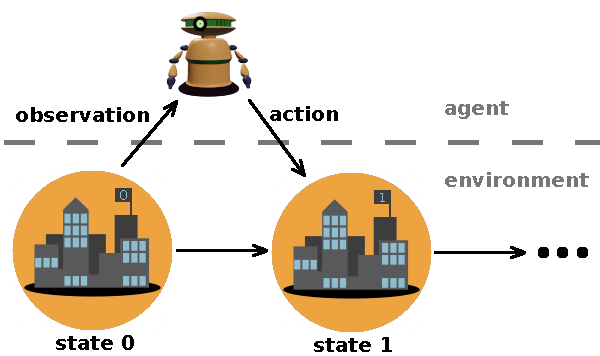
We can think of a model as partitioning the world into equivalence classes of indistinguishable states (the variables which would allow to distinguish those states are "hidden" from the model). The concept of preferences is typically discussed in this modeling context. Preferences are commonly described as a binary relation over states: means that the agent prefers state over state , which is, the agent would not choose an action leading to state if it can instead choose an action leading to state . Note the following:
- The agent may choose an action leading to state when there is no action leading to state .
- Even if there is an action leading to state , the agent may choose an action leading to some other state (if ).
The model in use limits what behavior can be described via preferences. Take chess. If we take just the board as the state, we cannot express as preferences the knowledge that the agent avoids threefold repetition (we need the state to include history of moves for that). In other words, what is included in the description of states determines the expressivity of the preference relation. Imagine an agent which selects between rock, paper and scissors "at random". If we model just the game of rock-paper-scissors, we cannot say anything about the preferences of the agent (we may say that the preferences are incomplete). In reality, randomness stems from uncertainty [LW · GW] and we could take into account how the random choice is made - e.g. taking . Then we could use a model of rock-paper-scissors where the state includes and the played and have preferences like these:
{"unix_time": 1736818026, "shape": "rock"} ≻ {"unix_time": 1736818026, "shape": "paper"}
{"unix_time": 1736818027, "shape": "paper"} ≻ {"unix_time": 1736818027, "shape": "rock"}Including more details in the model makes it more expressive but also more complicated. There is a tradeoff to be made. Model states may be a leaky abstraction. An inappropriate model could make a process falsely seem complicated and may not allow expressing all relevant information while reasoning.
It is common to model an environment as an MDP (Markov Decision Process). This requires including all relevant details into the state so that the transition to the next state is completely determined by the current state and the action of the agent. Sometimes people say that an MDP is a process where next state depends only on the current state and the action - I think this description is somewhat backwards. It's not that the process always has naturally defined states that we could talk about. We make the model and some models have the nice property of being MDPs because they include all relevant information in the state. Some things are easy to model as MDPs and others are not. We can model chess as an MDP where each state includes the list of all moves so far (this information is enough to deduce current board state, whose turn is it, whether castle conditions are met, threefold repetition, etc.).
How do we determine an agent's preferences?
The concept of preferences is only useful if we can establish what preferences an agent has. There are several ways in which this can happen.
* Design an agent with given preferences
In the simplest case (e.g. Good Old-Fashioned AI), we can reason about the semantics of the agent's source code and establish how it would behave on various inputs, which allows us to infer its preferences. For example, we can examine the source code of a thermostat and infer that it prefers 22°C over 21°C. In practice, the process often goes in the other direction - we have some preferences in mind and we write the corresponding source code to produce a program with such preferences. This technique doesn't work as well with Machine Learning, because we don't have a theory of learning (we don't understand on a theoretical level what AIs are produced by the learning algorithms we employ). In case of a neural network, we could still talk about preferences mechanistically (e.g. "when these input neurons are activated, the agent prefers this action over the other one"), but this is not really useful. We would like to express preferences in terms of an ontology which is natural for humans (e.g. "the agent prefers to be nice rather than rude") but there are a couple of obstacles to that: we don't know whether the learned preferences fit into a human ontology; the learned preferences may be too complicated for humans to reason about anyway; we don't know how to translate the mechanistic understanding to a different ontology (this is part of what mechanistic interpretability tries to achieve).
* Infer preferences from behavior (a.k.a. revealed preferences)
This is a more empirical approach where we observe the agent's bahavior on various inputs and try to deduce its preferences. This requires assuming some regularity (assuming a particular map of the territory) in order to generalize. For example, suppose we run the chess AI and at some point observe the board shown. We are interested in particular in the two possible moves shown with arrows.
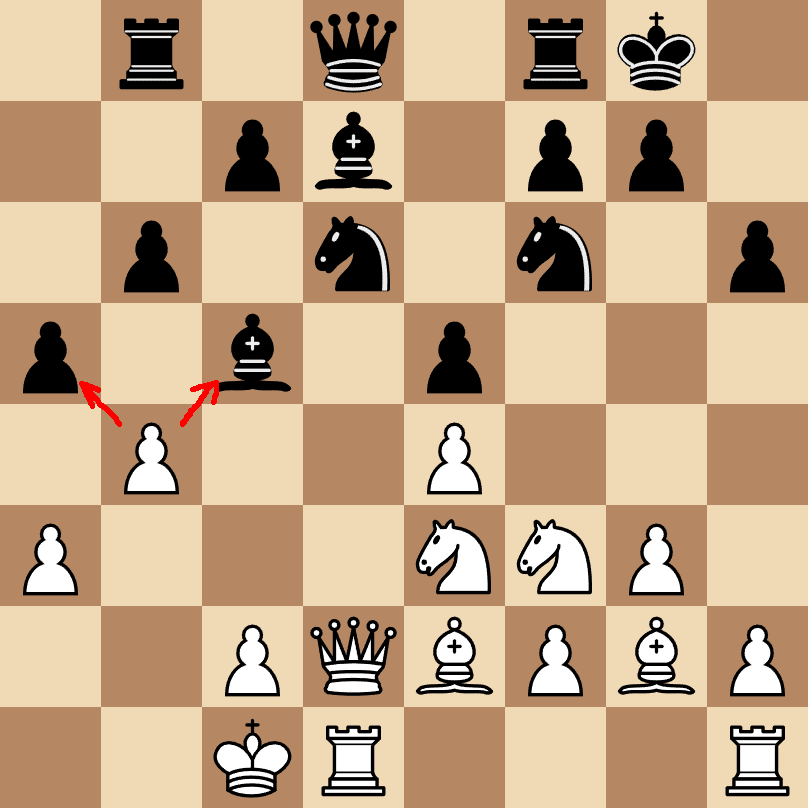
If we observe that the AI makes the move to the right, we can describe the revealed preferences as "given this board state (and history), the AI prefers the action of the right arrow over the action of the left arrow". This information is quite useless, unless we get to exactly the same board state and history in a future game. We cannot observe all possible board histories to get a complete picture of the preferences like that. To get meaningful information from one observation, we constrain the space of possible preferences (in other words, we assume the AI cannot have some sets of preferences). For example, we could assume that the preferences do not depend on the board history. The more assumptions we make, the simpler it becomes to express and reason about preferences - e.g. if we assume the AI doesn't care about the positions of the pieces, we can conclude that the AI prefers capturing the bishop over capturing the pawn. If you play chess, you know that capturing a bishop is often better than capturing a pawn, but not always. There is a tradeoff - the stronger the assumptions we make, the more likely that our descriptions of the preferences will be inaccurate. We can use what we know about the AI's design (e.g. its source code) to inform what assumptions are reasonable. Ideally, we want some constraints, so that we can generalize the revealed preferences, but we also want to not assume anything false. Satisfying both of those conditions becomes very difficult for complex AI systems.
When is a preference not defined?
Imagine an AI for playing tic-tac-toe which selects moves deterministically using a lookup table. Suppose the entry for the empty board says to play at the top right. Then if we examine the source code of the AI, we can determine preferences such as

Can we say anything about preferences between the top center and the middle center as a first move? Whenever those two plays are possible, the top right is also possible and would be selected by the AI. Nothing allows us to infer any preference between those two plays.
This AI does not need lookup table entries for states which cannot be reached by first playing at the top right (for simplicity, we assume the AI always plays first but this assumption is not necessary for the argument). Then what about the preferences between the following two states?

If the lookup table contains all entries, including the ones for non-reachable states, we can define counterfactual preferences of the AI. But let's suppose there are no lookup table entires for the non-reachable states. This does not impair the AI in any practical sense.
Then the preference relation is not defined for this pair of states. We can examine the source code, but there is no lookup table entry or any other information to let us deduce which of the two states is preferred. We can play against the AI as many times as we wish, but we would never observe something relevant to the preference between these states. We could rig the game to make the AI play from a different starting board state, but the AI would simply crash when the board state is not in its lookup table. The preference relation for an AI needs not be connected (it is not the case that for any either or ). It seems that the preference not being defined in this case is not because of a poorly chosen model (e.g. normalizing the board for rotations and reflections would not help).
To summarize, there are AI agents which are not flawed in any meaningful way, and which, when reasonably modeled, have a preference relation that is not connected.
In more complex systems, having no preference defined can happen, for example, when two states never appear in the same context (which could happen due to path dependence).
Non-deterministic preferences
Suppose you watch a friend playing chess against an AI. You see a particular board state and the AI's next move. You get distracted and then look at the screen again. You observe the same board state and this time the AI plays a different move. What does that mean for the preferences of the AI? If we call the first move we observed and the second one , we cannot say that nor that . This is not a counterfactual context, it is different from the case where the preference is not defined. In this case the AI behaves non-deterministically.
What do we make of the AI's behavior? A reasonable assumption is that the AI played a different move to avoid stalemate by the threefold repetition rule. Or you could examine the source code of the AI and notice that it sometimes uses a pseudo-random generator to select a move. Both of these explain the non-deterministic behavior and show that it is due to our model ignoring variables relevant for the AI's choice (the history of previous moves and the hidden state of the pseudo-random number generator respectively). If we use a model that includes those hidden variables in the state, we can describe the behavior of the AI in terms of preferences.
As far as we know the universe is deterministic (we only get irreducible non-determinism if we postulate it exists). All apparent non-determinism in preferences is a manifestation of uncertainty incorporated into the model in which we consider the preferences. This uncertainty can be resolved by introducing hidden variables. If we take a toy model, all uncertainty comes from the physical system where this toy model is instantiated (e.g. in a logical game of chess: hidden variable in the pseudo-random number generator). If we take everything that could causally influence the physical system in mind, there is no place left for uncertainty about the future (the same is true for the past if we take everything that could be casually influenced). Since entropy increases, there are no loops in the trajectory of physical states. Non-determinism is a property of a model.
(Note that our knowledge of physics is incomplete, we may be missing important details which would render this whole discussion misguided.)
Can we use a model with no non-determinism? Not always for at least a couple of reasons:
- There are chaotic processes whose states we cannot model with sufficient precision. Nevertheless we need to reason about those processes.
- From an agent's point of view, there is unavoidable indexical uncertainty about the future. An agent's preferences may depend on a quantum coin flip. Such preferences can only be described after observing the result (if you think about this in the context of many worlds, preferences would differ in each branch).
Indifference
We have established that there are four possibilities for the preferences of an agent between a pair of states and :
(0) ( is always chosen over )
(1) ( is always chosen over )
(2) no preference is defined for and
(3) our model is non-deterministic with respect to and (both preferences can be observed)
Sometimes it is useful to talk about "indifference". This notion seems a little confused. Intuitively indifference tries to convey that two states have the same preference (typically denoted ). Here the word "same" can be interpreted in multiple ways:
We can consider thinking of "indifference" as describing a property of the algorithm the agent runs. Here are several examples of that:
- The two states have the same internal representation in the agent.
- The agent assigns the same "score" to the two states.
- The agent chooses between the two states by tossing a coin.
However, this would be epistemic information about the implementation of the agent and we are interested in describing agent behavior.
Alternatively, we could say that the agent is indifferent between two states when neither is preferred over the other (capturing cases 2 and 3). Case 2 happens when there exists no meaningful way to talk about the preference. Case 3 happens when our model's granularity is too high to express the actual preference.
Whether this definition of indifference is satisfactory depends on how we intend to use it. We will come back to this when discussing Completeness and Transitivity.
Von Neumann Morgenstern utility theorem
Sometimes there is uncertainty about the state a given action will lead to so we talk about an action leading to a distribution over states (a.k.a. a lottery over outcomes). Then we can have preferences over distributions of states.
The Von Neumann Morgenstern (VNM) utility theorem proves that preferences over lotteries can be modeled as the agent maximizing the expected value of some real-valued function (called utility), given that the preferences satisfy four properties, called completeness, transitivity, independence and continuity. The key question is whether we can expect powerful agents to satisfy those properties. Note that the theorem assumes a notion of probability (this will become relevant when talking about indifference).
Completeness and Transitivity
We will discuss the Completeness and Transitivity properties together because completeness relies on the notion of indifference and the definition of indifference needs justification from transitivity. Completeness and transitivity together state that preferences form a linear order - reflexive, antisymmetric, strongly connected, transitive (completeness refers to being strongly connected). Intuitively, this roughly means that all outcomes can be ordered by preference (with possibly some outcomes being of equal preference).
What does it mean for these properties to hold about preferences as defined in the previous sections? We can define to mean . We get reflexivity from how we defined and antisymmetry from how we defined . We also get strongly connectedness from those definitions. How reasonable is it to expect transitivity?
Transitivity of implies transitivity of both and . However, we have no obvious reason to expect that. Even if and , the preference between a and c could still not be defined. Even if and (e.g. because no preference is defined for these pairs of states), it could be the case that . With this definition of indifference, we cannot expect completeness and transitivity to hold for a sufficiently powerful agent. Can we adapt the definition of indifference to salvage those properties?
We could take the transitive closure of and define to mean that both and are false. However, the induced indifference relation could still fail to be transitive. This could be illustrated with a toy example: If a coin lands heads, the agent chooses between and . If it lands tails, the agent chooses between and . Then we have the following preferences (where the cell indicates the preferred state):
| a | b | c | d | |
| a | ~ | ~ | c | ~ |
| b | ~ | ~ | ~ | d |
| c | c | ~ | ~ | ~ |
| d | ~ | d | ~ | ~ |
The transitive closure of does not change anything. We still have and but .
We can imagine this situation to come up in a much more complex environment. We can keep on tinkering with how we define indifference, but it seems that we need some constraints about the implementation of the agent in order to claim that completeness and transitivity hold. It could very well be the case that they do for a sufficiently powerful agent, but this is not self-evident.
The point is that, once you get into the details of defining completeness and transitivity, it is not obvious when those properties hold.
Independence
The Independence property states:
If are lotteries, is some probability, then if and only if
{A with probability p; C with probability 1 - p} ≻ {B with probability p; C with probability 1 - p}
Intuitively, this roughly means that preferences between two options are not affected if the options are only achieved with some probability. Imagine one die where each face is labeled with either "apple" or "banana" and a second die, exactly the same except that the label "banana" is replaced by "cherry". If you prefer banana over cherry (banana ≻ cherry), you'd prefer the first die. Accepting this property becomes problematic if we start asking where the probability comes from.
Take a die with the following sides:
- blue square
- red triangle
- red circle
- blue triangle
- red circle
- yellow circle
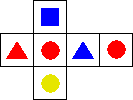
By counting (assuming a fair die) we arrive at the following probabilities:
P(red) = 1/2
P(blue) = 1/3
P(yellow) = 1/6
P(circle) = 1/2
P(triangle) = 1/3
P(square) = 1/6
Now we have the following lotteries:
- A: red and yellow win, blue loses
- B: blue wins, red and yellow lose
- C: always draw
Assuming an AI wants to win, it will have preference . Then take the following compound lotteries:
- A': {A with probability 1/2; C with probability 1/2}
- B': {B with probability 1/2; C with probability 1/2}
Is it reasonable to expect a preference ? It depends on what uncertainty the probabilities reflect. If 1/2 reflects the probability of rolling a circle, we can get the following lotteries:
- A': {A if not a circle; C if circle}
- B': {B if not a circle; C if circle}
This leads to the following probabilities:
P(win | A') = 1/6
P(lose | A') = 2/6
P(win | B') = 2/6
P(lose | B') = 1/6
P(draw | A') = P(draw | B') = 1/2
In this case dominates so having a preference is inconsistent with the goal of winning. The independence property fails because some of the events from the lotteries are dependent. For example
1/3 = P(red or yellow | not a circle) ≠ P(red or yellow) = 2/3
This shows that for sufficiently complex setups (where we cannot assume all probabilities modeled come from independent sources of uncertainty), the independence property fails. On a deeper level, the issue is that preferences over distributions of states only consider probabilities, ignoring what uncertainty is being modeled. Agents which act differently depending on the source of uncertainty cannot be modeled with such preferences.
Continuity
The Continuity property states:
If are lotteries and then there is some probability such that
{A with probability p; C with probability 1 - p} ≻ B ≻ {A with probability 1 - p; C with probability p}
Intuitively, this roughly means that a sufficiently small modification in the outcome probabilities of a lottery does not affect preferences.
Many have argued against assuming the continuity property:
- this [LW · GW] argues that some outcomes are "infinitely" more valuable than others and it's reasonable to not be willing to sacrifice any probability of such an outcome.
- this [LW · GW] argues that continuity is not justified but is accepted because it is technically useful for proving results.
- this argues that lack of preference continuity does not make an agent exploitable.
What can we conclude about VNM?
The VNM theorem is useful in certain idealized settings (e.g. game theory, economic models), but I think it has been given too much attention. Sometimes people point to it as a proof that all rational agents are expected utility maximizers. While this may be the case, the theorem does not prove anything like that. It is not obvious whether the properties assumed by the theorem hold for rational agents. Moreover, the theorem does not say anything about the form of that utility function (except that it is invariant to positive affine transformations).
Thinking of preferences as a manifestation of utilities the agent assigns to states appears misguided.
Complications in the real world
Throughout most of this article I made various assumptions.
Agents are embedded in the real world. The separation between agent and environment is fuzzy (e.g. is a USB flash drive part of the agent or the environment?). Agents and their preferences can change over time and the agent's actions may be causally related to those changes. Even talking about preferences may not make sense in that context. Things get messier if we consider continuous time or relativity - e.g. what is the reference frame of the agent and how to define the state at a time if parts of the agent are moving relative to each other? There probably are other complications which I did not list here.
One of the reasons I'm interested in preferences is because they are relevant for corrigibility. Maybe we could formalize corrigibility as a set of constraints on preferences. We would expect a solution for corrigibility in the real world to still work in simpler settings. If we can better understand corrigibility in those simpler settings, that might help.
0 comments
Comments sorted by top scores.