Toward Safety Cases For AI Scheming
post by Mikita Balesni (mykyta-baliesnyi), Marius Hobbhahn (marius-hobbhahn) · 2024-10-31T17:20:06.019Z · LW · GW · 1 commentsContents
Scheming and Safety Cases Core Arguments and Challenges Safety cases in the near future None 1 comment
Developers of frontier AI systems will face increasingly challenging decisions about whether their AI systems are safe enough to develop and deploy. One reason why systems may not be safe is if they engage in scheming. In our new report "Towards evaluations-based safety cases for AI scheming", written in collaboration with researchers from the UK AI Safety Institute, METR, Redwood Research and UC Berkeley, we sketch how developers of AI systems could make a structured rationale – 'a safety case' – that an AI system is unlikely to cause catastrophic outcomes through scheming.
Note: This is a small step in advancing the discussion. We think it currently lacks crucial details that would be required to make a strong safety case.
Read the full report.
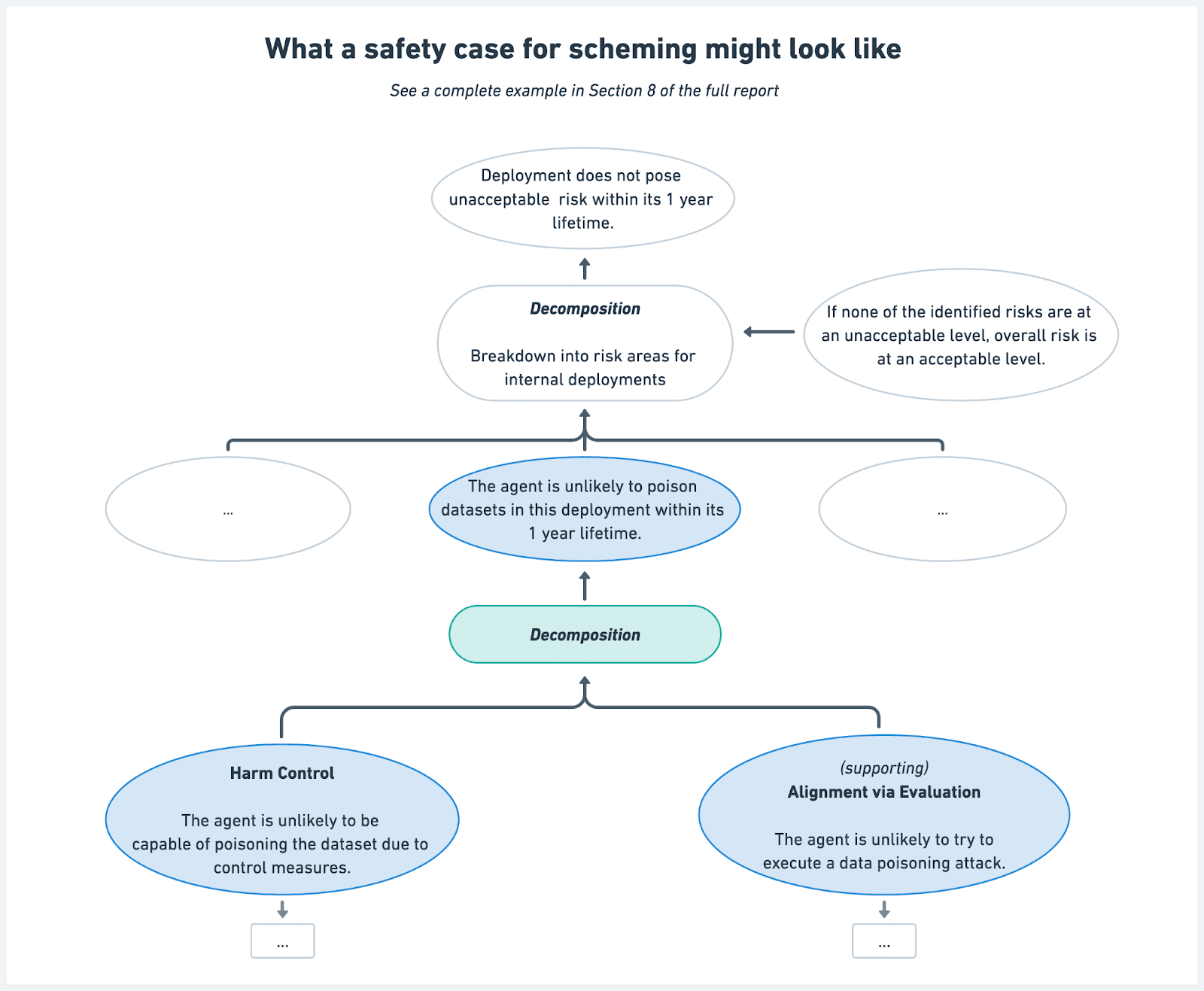
Scheming and Safety Cases
For the purpose of this report, we define scheming as AI systems covertly and strategically pursuing misaligned goals.[1]
The present work is part of an emerging approach to justifying safety of general-purpose AI systems: safety cases, which provide structured arguments that deploying an AI system is unlikely to cause significant harm (Clymer et al, 2024, Irving, 2024, Buhl et al, 2024). Similar to how nuclear power plant and aircraft developers make safety cases before deploying their systems, developers of highly-capable AI systems could use safety cases to demonstrate that their systems won't cause catastrophic harm - whether through misuse, misalignment or scheming specifically.
Core Arguments and Challenges
We propose three core arguments that could be used in safety cases for scheming:
- Scheming Inability: Showing that AI systems are not capable of scheming, for example because they do not realize that scheming can be strategically beneficial, or they make obvious mistakes when attempting to scheme.
- Harm Inability: Showing that AI systems are not capable of causing harm through scheming, such as sabotaging their developers' organizations, even without any attempts to control them.
- Harm Control: Demonstrating that control measures would prevent unacceptable outcomes even if systems intentionally attempted to subvert them.
We also discuss how safety cases might be supported by alignment arguments using (i) alignment evaluations (and arguing that models aren't alignment-faking) or (ii) arguing that the training process itself is unlikely to lead to scheming (something that we can't do yet).
To illustrate how these arguments work in practice, our report includes an example safety case sketch for a hypothetical AI system deployed internally by an AI developer.
Making these arguments requires evidence of satisfying multiple assumptions - from showing that AI systems do not sandbag capability evaluations, to showing that control measures remain effective over time (e.g. human auditing within a control protocol remains accurate months into the deployment; model weights will not be stolen and controls removed; etc). We provide initial ideas for how developers may try to satisfy these assumptions, but ultimately many of them are open problems.
Safety cases in the near future
Our evaluation of frontier models like OpenAI's o1-preview, described in its model card, shows that some publicly available AI systems are now capable of basic scheming. However, this scheming is visible directly in model outputs and legible to humans (even if not shown to users) and thus could be monitored by AI developers.
We think near-future safety cases will rely on three key pillars:
- Monitoring for scheming in model outputs, shown via red-teaming to be accurate and robust even if the AI systems intentionally try to evade it.
- Demonstrating inability for scheming in an illegible way: showing that models are not capable of obfuscating their scheming reasoning to look benign and not capable of extensive latent reasoning without any intermediate legible outputs.
- Demonstrating inability to cause harm while scheming. This includes standard dangerous capability evaluations like CBRN, cyber, autonomy, as well as behaviors unique to scheming, such as sabotage (Benton et al, 2024).
If models become capable of scheming illegibly, safety cases would need interpretability techniques to be good enough to monitor scheming reasoning within model internals. We are optimistic that such techniques could exist in the future, but we don't think they are ready yet.
At Apollo, we are working on evaluations and basic science that could help enable such safety cases.
Read the full report.
- ^
Our definition of scheming is broader than deceptive alignment (Hubinger et al, 2019) or scheming as used by Carlsmith, 2023, who both describe scheming as a strategy that could be used by AI systems during training. We use a broader definition of scheming that extends to intervals outside of training, because we think that scheming-like behaviors could emerge in more diverse circumstances — including via in-context learning during deployment. We think that scheming-like behaviors motivate largely (but not entirely) similar mitigation measures regardless of the emergence circumstances. Thus, we think that when taking a risk-modeling or safety-case perspective, using a broader definition is necessary to ensure different forms of this threat model are taken into account.
1 comments
Comments sorted by top scores.
comment by franc (FrancescaG) · 2024-11-01T11:09:42.228Z · LW(p) · GW(p)
Great addition to thinking on safety cases.
I'm curious about the decision to include the time constraint 'Deployment does not pose unacceptable risk within its 1 year lifetime', as I've been considering how safety case arguments remain relevant post deployment.
Is this intended to convey that the system will be withdrawn/ updated in a year or to help reduce the scope of what is being considered in terms of feasibility of inability and control arguments by looking at a short risk evaluation timeline?
On the topic of the scope of the Harm Inability arguments in the paper:
'A Harm inability argument could be absolute or limited to a given deployment setting'
Given the vast amounts of deployment settings, the developers of an AI model could provide absolute arguments with accompanying warnings/ limitations based on the evaluation outputs (along the lines of usage guidelines for licensed medicines). Organisations deploying the models in novel settings (also higher risk like medical, finance etc) could supplement these with arguments specific to their deployment setting. Any thoughts on this?