Domesticating reduced impact AIs
post by Stuart_Armstrong · 2013-02-14T16:59:13.302Z · LW · GW · Legacy · 104 commentsContents
Intuitive idea Reduced impact The Future The AI design The Counterfactual The Penalty Function Relative Scaling Conclusion None 104 comments
About a year ago, I posted several ideas for "reduced impact AI" (what Nick Bostrom calls "domesticity"). I think the most promising approach was the third one, which I pompously titled "The information in the evidence". In this post, I'll attempt to put together a (non-realistic) example of this, to see if it's solid enough to build on. I'll be highlighting assumptions I'm making about the AI; please point out any implicit assumption that I missed, and any other weaknesses of the setup. For the moment, I'm more interested in "this doesn't work" than "this can't be done in practice" or "this can't be usefully generalised".
EDIT: It wasn't clear here, but any paperclip constructed by the reduced impact AI would be destroyed in the explosion, and the AIs would not be observed during the process. How to get useful work out of the AI will be the next step, if this model holds up.
Intuitive idea
For a reduced impact AI, we want an AI that can accomplish something, say building a paperclip, without it going out of control and optimising the universe. We want the future to be roughly the same whether or not the AI was turned on. Hence the piece of information "the AI was turned on" is not particularly important - if we didn't know, we wouldn't go far wrong in our predictions.
To enforce this we'll equip the AI with a two-piece motivation: a utility function U (causing it to build paperclips) and a penalty function R (which penalises the AI if its actions have a large future 'impact'). The challenge is to have a setup and a definition of R that implements this intuitive idea.
Reduced impact
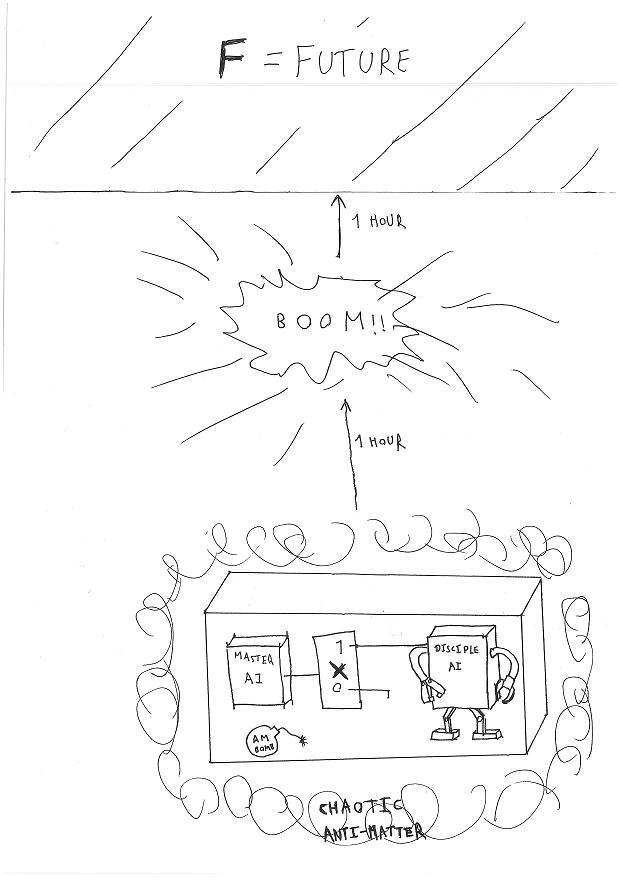
Can we hope to define reduced impact? Doesn't any change percolate across all future time? Yes, but not all changes are the same - especially where our ability to predict them is concerned. Imagine an AI, confined to a box. While inside the box, it will build a paperclip. Then, in one hour's time, an antimatter bomb inside the box will explode, obliterating everything inside. We would intuitively say that whether the paperclip was built or not, would have very little impact afterwards. What we really mean is that we are unable to usefully use that information for future predictions. To make it even harder, surround the box by a large mass of antimatter gas, moving chaotically. In order to figure out the consequences of anything happening inside the box, we'd have to be able to unravel chaos: solve chaotic equation correctly and quantitatively, not just qualitatively. So our first assumption is that the AI can't unravel chaos.
Note that the chaotic antimatter is meant to erase the impact of small changes, not to contain the AI. We should assume that the AI could easily get out of the box and spread across the universe, should it want to. So we'll be putting machinery and other useful tools inside the box - anything an AI could use to build paperclips or take over the universe. We're only successful if it doesn't want to do that last thing.
The Future
We want 'the future' to be roughly the same whatever the AI does. But what do we mean by that? Obviously, if the AI builds a paperclip, the near future inside the box will be very different. What we want is that the mid future, the future after the explosion, be not very different. So we want to define F, a subset of spacetime, that represents this mid future.
There are many ways of doing this. Let O=(box, AI turned on) be the point in space time at which the experiment begins. We could then take the initial rest frame of the box, and say that F contains everything two hours or more in the future from O (recall the explosion happens after one hour). Or we could be Lorentz-invariant, and say that F contains everything that can be reached from O, along a geodesic with proper-time more than two hours. F need not even be strictly "the future": it could contain everything in the universe, except for the box-and-surrounding-cloud-for-the-duration-of-the-experiment.
Note that in order to define this F, we're making use of general relativity - so we assume the AI understands physics. This includes grounding the concepts into reality properly, and dealing with ontology crises. We'll also need to assume that the AI obeys the laws of physics as we understand them, and doesn't have outside-physics superpowers.
The AI design
The point of defining F was to be able to talk sensibly about a space in which we expect the AI's actions to have reduced measurable impact. So we'll need to start assuming some things about how the AI is structured. We'll assume that the AI consists functionally of the utility function U, the penalty function R and a probability estimating module P, and whatever practical components (including knowledge bases) it needs to run its calculations. We'll assume that the AI can't directly change these components (though indirectly, it's another matter - if it has access to manipulators, it can freely hack itself). The reason for this assumption will be clear in the next section. Note that we are assuming the AI can know every detail of the setup - we're not counting on security through obscurity.
Given any world w, we can define wF as the world w restricted to the space F - i.e. the future part of w. The probability estimating module P can estimate numbers such as P(wF) (the probability of wF) and P(wF|e) (the probability of wF given evidence e). Some worlds will have wF=vF even with w≠v (their pasts differ, but their futures are the same).
Because of the limitations of the AI (being unable to unravel chaos), we have an implicit coarse-graining of the worlds. For instance, let X be a minor fact about the inside of the box, and let w and v be worlds such that w assumes X and v assumes ¬X. Then if wF=vF (so the worlds have the same future), we have P(vF|X)=P(wF|X) ≥ P(w|X), even though P(v|X)=0.
The Counterfactual
We want the future to be roughly the same "whether or not the AI was turned on". Hence we need to define a counterfactual. It's asking for trouble to ask a working AI to imagine what the universe would be like if it wasn't turned on. So we'll use a more complicated counterfactual that doesn't have that problem: the relevant counterfactual is firmly in the future, and firmly probabilistic.
Initially, we imagine the box contains a "master AI" (which has been turned on), and a "disciple AI", which is turned off. The master AI is the one whose motivation we want to constrain. We don't give the master AI any manipulators or direct means of influencing anything at all. All that it can do is build the source code for the disciple AI. We assume the master AI can't affect the world in any other way.
Specifically, the master AI will build the source code, according to its preferences, and store it somewhere. Then, exactly 30 minutes after the experiment began (and hence 30 minutes before the explosion), that source code will be copied into the disciple AI. If the source code is not empty, the disciple AI will be turned on.
The counterfactual will be whether the code is copied or not. At the 30 minute mark, a random process X will output 1 or 0 with equal probability. If X=1, the source code is copied as described. If X=0, nothing happens. We assume that X is a process that the (master) AI will find truly random (note that this can be deduced from the "can't unravel chaos" assumption - but it's good to have it specified separately, as it serves a different purpose in the experiment). This X will be the point of counterfactuality - we want the future world to be similar whether X=0 (no AI gets to do anything) or X=1 (the disciple AI is unleashed.
The whole setup can be summarised in the following drawing of unsurpassable elegance:
The Penalty Function
We can now describe the penalty function R. For any world w, we can compute the difference in probability between the future world given X=0 and X=1. There are many ways of assessing the difference; the absolute difference in probability is one simple way of doing this:
R(w)= | P(wF|X=1) - P(wF|X=0) |
Then we can integrate this across all w (for some reasonable weights) to get the total penalty function R. As required, R measures how much the AI's future expectation changes, given whether it's successful at creating the disciple AI's source code or not.
Relative Scaling
We're ready to go now. The AI's motivation is that it must maximise U-R: try and maximise its utility while diminishing the penalty function. This is not exactly a utility function, since the output of the probability module P appears inside R, the quantity to be maximised (probabilities shouldn't appear within the definition of the value of a world). Since the master AI is prevented from self-modification, this should not be a problem. Alternately, P could be formally defined as "the output of a module described as [the code of the AI's P module]". This would make U-R into a proper utility function, where the module P used by the master AI for probability happens to be the same as the module P used in the definition of R - but they aren't specified to be identical.
Let's define U in a nice bounded way: giving 0 utility if the disciple builds no paperclips, and utility 1 if it builds at least one. The motivations that the master AI could pick for its disciple fall broadly into three categories:
- The disciple doesn't do anything (U=0, R=0).
- The disciple builds a paperclip or two and nothing much else (U close to 1, R close to 0). This is what we want.
- The disciple optimises the universe (U very close to 1, R hopefully very high).
We've assumed that the master AI can't unravel chaos - and if this is exactly true, then we're fine. Then option 2 is perfect: U will be close to 1, and R will be exactly 0 and the AI will implement that. But maybe the master AI is a bit smarter than we thought, and the "can't unravel chaos" is broadly true, but the AI can still predict some small expected difference. This means that R will increase above zero, making the master AI's task harder, and making the "do nothing" option relatively more attractive.
This seems a great security feature - it means that if the master AI is smarter than we expected, it is more likely to do nothing. But this setup fails if the master AI always does nothing. So we'll need to weight R so that the master AI can program its disciple to do something. There are issues with doing this in practice (we don't want AIs to influence people to set R too low, for instance with deliberate inaction). But let's assume here that we've picked an R such that if the AI is as smart as we think, it will just about be able to do something (if it's smarter, it'll still do nothing).
Conclusion
Given all these assumptions, then it seems that this setup will produce what we want: a reduced impact AI that will program a disciple AI that will build a paperclip and little else. The main error mode (if the AI is smarter than expected) seems to be for the AI to do nothing.
Note: the original formulation of this had a second box, causally disconnected and otherwise identical but with no AI, for purposes of comparison and calibration. It seems that it isn't necessary, but I may put it back in if needed.
104 comments
Comments sorted by top scores.
comment by CCC · 2013-02-14T18:51:22.868Z · LW(p) · GW(p)
Hmmm. With this setup, there is one piece of useful information that escapes the explosion; the information regarding whether or not the paperclip was, in fact, built. This minor piece of information has a non-zero probability of changing the future (by encouraging you to further continue in AI research).
Therefore, it seems likely that the disciple AI will try to build a paperclip without you finding out. This may require demolishing one or more sensors, placed inside the antimatter cloud (or, for extra thoroughness, subverting them). Alternatively, the AI may do absolutely nothing until a few seconds before the explosion, and then frantically make a single paperclip right at the end, to reduce the number of observations of the paperclip that escape.
As AI failure modes go, though, that seems pretty innocuous.
Replies from: Stuart_Armstrong, ikrase↑ comment by Stuart_Armstrong · 2013-02-15T12:13:39.168Z · LW(p) · GW(p)
Extra clarification: in this example, I'm assuming that we don't observe the AI, and that we are very unlikely to detect the paperclip. How to get useful work out of the AI is the next challenge, if this model holds up.
Replies from: CCC↑ comment by ikrase · 2013-02-25T10:16:22.356Z · LW(p) · GW(p)
Wait, can this thing make infohazards? I... don't 100 percent understand it.
Replies from: CCC↑ comment by CCC · 2013-03-05T12:01:08.344Z · LW(p) · GW(p)
What is an 'infohazard'? I am unfamiliar with your terminology.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2013-03-05T14:45:48.818Z · LW(p) · GW(p)
http://wiki.lesswrong.com/wiki/Information_hazard
Replies from: CCC↑ comment by CCC · 2013-03-05T18:40:09.914Z · LW(p) · GW(p)
Huh.
In that case, I don't see why a self-improving AI wouldn't be able to create infohazards, if it wanted to. The question here is, whether the AI model under consideration would want to.
...it seems possible, if it could construct an infohazard that would hide the fact that said infohazard existed.
Replies from: TheOtherDave↑ comment by TheOtherDave · 2013-03-05T18:41:16.418Z · LW(p) · GW(p)
You probably meant to reply to ikrase.
Replies from: ikrase↑ comment by ikrase · 2013-03-06T23:49:31.009Z · LW(p) · GW(p)
I've been wondering about the limits of AI boxing myself. The ultimate hazard from an AI that is set up to even possibly be useful is when an AI is set up to transmit a (very limited) message before self-destruct (and so that the AI cannot witness the result of any of its actions including that message) and that message is still hazardous.
THat, or that the AI can somehow pervert mundane computing hardware into manipulators and sensors through software alone despite the fact that mundane computing hardware is designed to be the opposite of that
Replies from: CCC, shminux↑ comment by CCC · 2013-03-13T07:58:22.116Z · LW(p) · GW(p)
The ultimate hazard from an AI that is set up to even possibly be useful is when an AI is set up to transmit a (very limited) message before self-destruct (and so that the AI cannot witness the result of any of its actions including that message) and that message is still hazardous.
The self-fulfilling prophecy has been well-known in fiction for centuries. Or the ambiguous prophecy - consider what is said to have happened when Croesus asked the Oracle whether he should attack the Persians. "If you attack," the Oracle reputedly said, "you will destroy a great empire." Wanting to destroy the great Persian empire, and encouraged by this answer, Croesus immediately attacked...
...an action which led to the Persians promptly destroying Croesus' empire.
Prophecy can be a weapon, and it can be turned against those who know what the prophecy says.
↑ comment by Shmi (shminux) · 2013-03-07T00:11:03.400Z · LW(p) · GW(p)
I don't stop being amazed that some people here seriously think that a lesser intelligence can reliably contain a greater one. There are just too many outs a lesser intelligence cannot even conceive of. Even the best cage thought up by five-year-olds will not contain an adult, and the gap between a human and a full-blown AGI is much larger than that.
Replies from: ikrase, wedrifid↑ comment by ikrase · 2013-03-07T20:29:57.639Z · LW(p) · GW(p)
I agree that the boxing problem is BIG and that a useful super-AI cannot be boxed.
However, some things can just be too one-sided. I'm pretty much entirely talking about 1. No manipulators and 2. No communication.
Even a 5 year old can come up with three meter thick metal boxes.
My sample is: AI using 1000kg of present day computer hardware, powered by battery, attached to no manipulators, sensors, or comms hardware whatsoever, encased in multiple layers of vacuums, Faraday cages, antimatter screens, gaps containing ionizing and neutron radiation, and vibration isolators, inside a completely separate spacecraft with no extra fuel and controlled by primitive (possibly analog or mechanical) flight contollers, containing multiple nukes with fail-deadly time-delay or remote-activated fuses. The ship is placed at a Venusian Lagrange point and the AI (pre-loaded with some degree of knowledge) is turned on and allowed to FOOM for a period of time T before:
Option A) The nukes explode
Option B) N output bytes are copied by an isolated supervisor system and transmitted; the nukes then explode before there is time for a light-speed round trip from Venus Lagrange to Earth and back.
I seem to remember hearing something about a one-line AI-Box, for extremely compact Oddly Persuasive Arguments or infohazards. Still, however, that involved the possibility of being able to unbox the AI whereas this does not. Some people have implied that even Option A above is dangerous which seems impossible to me unless the AI has extremely detailed, specific almost atom-by-atom physics and physical data PLUS just the right sort of (poorly designed?) electronics. I find this... preposterous. This is of course a completely useless AI and does not obviate the need for Friendliness, or at least Obedience / Limitedness.
↑ comment by wedrifid · 2013-03-07T05:28:37.994Z · LW(p) · GW(p)
Your conclusion is good, this premise isn't:
Even the best cage thought up by five-year-olds will not contain an adult
"Let's throw them down that well!"
"I am going to lock you in Daddy's Jail cell!"
Many of the best cages thought up by five year olds will easily contain an adult (and sometimes accidentally outright kill or incapacitate them).
comment by Gastogh · 2013-02-14T17:12:54.252Z · LW(p) · GW(p)
I mostly steer clear of AI posts like this, but I wanted to give props for the drawing of unsurpassable elegance.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-14T17:15:10.603Z · LW(p) · GW(p)
:-)
You think I should break out and try my luck as an artist?
Silly question - of course I should!
Replies from: Vanivercomment by Elithrion · 2013-02-15T18:41:08.888Z · LW(p) · GW(p)
You use "utility function" in a weird way when you say it has "a utility function U" at the start. Standard usage has it that, by definition, the utility function is the thing that the AI wants to maximize, so the utility function in this case is only "U-R". To reduce confusion, you could perhaps relabel your initial "utility function" as "objective function" or "goal function" (since you already use "O"). Along similar lines:
AI consists functionally of the utility function U, the penalty function R and a probability estimating module P, and whatever practical components (including knowledge bases) it needs to run its calculations.
Isn't exactly true. A better description might be that we're assuming it consists of a utility function U = G - R(P), where G is the goal function, R the penalty function, and P is the output of some probability-estimation system which is specified within the utility function. This is basically what you describe in the Relative Scaling section, but prior to that section it's not clear that the AI wouldn't want to modify the probability module.
In fact, if you don't put P inside the utility function, presumably the AI modifies its probability module by indirect means to say P(a) = 0 for all a and proceeds to optimize the universe. It's actually not clear what is the purpose of the "can't directly modify components" assumption, since we seem to be assuming a potentially godlike AI that should have no difficulty modifying its components indirectly if it wishes.
I realize this is all pretty nitpicky, but I think this suggestion would make the post clearer and the assumptions of what it is exactly that the AI can't touch more explicit. Note also that since I shove the P explicitly inside the utility function, it doesn't really matter if the AI can figure out how to unravel chaos, since the probability estimate it uses for comparing worlds comes from P, which is what we gave it, which can't figure out how to unravel chaos. (Well, I'm pretty sure.)
Other than that, I think this should work, and it's actually the sort of thing I had in mind when talking to you about satisficers/maximisers with a cutoff (with the changes cost being the other necessary component to avoid having it do too much).
comment by Manfred · 2013-02-15T07:53:49.745Z · LW(p) · GW(p)
You could also just have a single AI construct a counterfactual model where it was replaced by a resistor, compute R relative to this model, then maximize the utility U' = U - R. I like this better than the master/disciple model.
Aside from implementation, the tricky part seems like specifying R. If you specify it obvious ways like a negative overlap between probability distributions, the AI can think that R is low when really it has a small probability of a huge impact by human standards, which is bad.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T12:08:36.750Z · LW(p) · GW(p)
You could also just have a single AI construct a counterfactual model where it was replaced by a resistor, compute R relative to this model, then maximize the utility U' = U - R. I like this better than the master/disciple model.
Counterfactuals about "what could have gone differently in the past" seem (potentially) harder than "what will happen in a probabilistic event in the future". I would like to use you model or something like it, it just seems a lot harder to specify.
Replies from: Manfred↑ comment by Manfred · 2013-02-15T22:33:53.277Z · LW(p) · GW(p)
Hmm, after some thought I 'm getting more pessimistic about finding a workable, broadly-effective definition of "different" with less complexity than "don't do things this model of a human doesn't want you to," though I'd still put it above 20%.
Example: maybe using the AI's predictive power "against paperclipping" would work. We want the AI to be free to change the inside of the box, but not want to exploit the outside for extra utility. So we use some magical method to sew together the inside of the box with a world that doesn't communicate with the box, and have the utility U' = 2*E(U in patchwork world) - E(U in real world), thus actually making having higher E(U) in the real world be bad. Does this work? No, the AI drops a meteor on its head in the real world to get the full points of almost 2.
comment by A1987dM (army1987) · 2013-02-18T19:34:46.547Z · LW(p) · GW(p)
Is this reduced impact thing essentially an attempt to build the status quo bias into an AI? (Don't get me wrong, I'm not saying that would necessarily be a bad thing.)
Replies from: ikrasecomment by Vladimir_Nesov · 2013-02-14T20:34:01.797Z · LW(p) · GW(p)
As CCC points out, the fact of whether the paperclip was built can itself influence the future (if you don't need the paperclip, there is no point in building the AI, so you expect its creation to influence the future). This gives a heuristic argument that whenever you want the AI to produce anything useful, and the AI doesn't optimize the future, U=1 will imply R>>1. Together with U=0 implying R=0, this suggests that if AI doesn't optimize the future, it'll choose U=0, i.e. refuse to produce anything useful (which is probably not what you want).
On the other hand, a better move where U=1 and R<1 might be available if the AI produces the paperclip and then very carefully (to keep R<1) takes over the universe to make sure that nobody ever finds out that the paperclip was produced, or that it took over the universe (or else someone might act differently than if the paperclip wasn't produced).
By making the penalty R stronger, you would make it less likely that a "cover-up AI" with R<1 is possible, but you would simultaneously make it less likely that producing the required artifact leaves R<1. By making the penalty weaker, you might make it possible to produce the artifact while keeping R<1, but that might also allow the creation of a "cover-up AI" with R<1.
Replies from: CCC, Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T12:16:15.468Z · LW(p) · GW(p)
Extra clarification: in this example, I'm assuming that we don't observe the AI, and that we are very unlikely to detect the paperclip. How to get useful work out of the AI is the next challenge, if this model holds up - maybe using something akin to Utility Indifference.
On the other hand, a better move where U=1 and R<1 might be available if the AI produces the paperclip and then very carefully (to keep R<1) takes over the universe to make sure that nobody ever finds out that the paperclip was produced, or that it took over the universe (or else someone might act differently than if the paperclip wasn't produced).
It's not whether we could detect that the universe has been taken over - it's whether the AI itself could detect this. If the AI takes over in world w, then even if we believe that P(w|X=0)=P(w|X=1), the AI would realise these two probabilities are different. And if it can't see the difference, it can't plan a takeover!
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T14:08:05.647Z · LW(p) · GW(p)
It's not whether we could detect that the universe has been taken over
If we ever find out, we might act very differently than if we don't, causing R>>1 (in AI's expectation). The AI knows that there is a difference if it creates a cover-up AI, but if the difference is measured as R<1, it can live with that.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T14:25:27.728Z · LW(p) · GW(p)
If the AI can tell the difference between two worlds, it doesn't matter whether we notice the difference or not. It doesn't matter if there's a "large" or a "small" divergence. R doesn't measure whether the world differs vastly or only a little bit; it measures whether the expected worlds become less or more expected, to the limit of the AI's ability to measure.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T15:23:11.994Z · LW(p) · GW(p)
R doesn't measure whether the world differs vastly or only a little bit; it measures whether the expected worlds become less or more expected, to the limit of the AI's ability to measure.
"Different worlds" (between AI's action and absence of action) refers to different probability distributions, thus to changes in probability of individual elementary events comprising the (coarse grained) sample space. I don't see that we are talking about different things. The individual elementary events are the same by definition, so it doesn't make sense to talk of changes in them (if the setup avoids acausal control).
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T17:49:46.748Z · LW(p) · GW(p)
What I'm saying is that the following three worlds are very different:
w1: the AI does nothing, w2: the AI takes over discreetly, and w3: the AI takes over blatantly
From the perspective of the AI, they're entirely different and distinct - in no way is w1 closer to w2 than to w3. The AI can tell them apart very firmly, and would be in no doubt as to which world it was in: there is no coarse graining across these worlds. (humans would probably coarse-grain w1 and w2 together, but the AI never would).
So very carefully taking over the universe has just as high an R as very blatantly doing so.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T18:05:41.630Z · LW(p) · GW(p)
I'm talking about how R measures the difference. Let R(A,B), where A and B are probability distributions, be some kind of sum over all w of |P(wf|X=1,E)-P(wf|X=0,E)|, where E is the information specifying AI's decision, such that the probability distribution P(w|X=1,E) is B(w) and P(w|X=0,E)=P(w|X=0) is A(w).
What is R(w1,w2), and what is R(w1,w3)? It seems more likely that R(w1,w2)R(w1,w3), but to engage this argument we need more detail on how R (specifically, the summing over all possible worlds) works.
Replies from: Elithrion, Stuart_Armstrong↑ comment by Elithrion · 2013-02-15T19:54:34.573Z · LW(p) · GW(p)
Aside from Stuart's objections below, I think the bigger issue with your argument is that (I'm going to try to reduce the amount of notation to hopefully be clearer) even if R(AI does nothing, AI takes over discretely) < R(AI does nothing, AI takes over overtly), that doesn't tell us anything about R(AI does nothing, AI makes a paperclip), which should still be vastly lower than either of those, since "takes over discretely" is still extremely high, since the AI can't hide from itself (or if it can, the argument needs to be made in favour of that).
If some of the assumptions are relaxed, it might be possible to argue that making a paperclip is in some way equivalent to taking over overtly (although it would be a difficult argument), but with current assumptions that does not seem to be the case.
↑ comment by Stuart_Armstrong · 2013-02-15T18:27:40.103Z · LW(p) · GW(p)
It seems more likely that R(w1,w2)R(w1,w3)
I see no reason to suppose this. Why do you (intuitively) think it's true? (also, I got a bit confused - you seem to have changed notation?)
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T18:34:07.847Z · LW(p) · GW(p)
(I've defined my notation in an edit to the grandparent, hopefully it should be clear now.)
The intuition is very simple: R(A,B) measures the difference between probability distributions A and B (their "dissimilarity"). If A and B1 are more similar (in some sense) than A and B2, I'd expect R(A,B1)R(A,B2), unless there is a particular reason for the senses of similarity as measured by R(-,-) and as given intuitively to be anticorrelated.
(Furthermore, the alignment of the senses of similarity might be expected by design, in the sense that R(-,-) is supposed to be small if AI only creates a useless paperclip. That is if the distributions A and B are similar in the informal sense, R(A,B) should be small, and presumably if A and B are dissimilar in the informal sense, R(A,B) becomes large. If this dependence remains monotonous as we reach not just dissimilar, but very dissimilar A and B, my point follows.)
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T18:44:00.706Z · LW(p) · GW(p)
Let's add some actions to the mix. Let a1 be the action: program the disciple to not take over, a2: program the disciple to take over discreetly, a3: program the disciple to take over blatantly. Let's assume the disciple is going to be successful at what it attempts.
Then all the following probabilities are 1: P(w1|a1,X=1), P(w2|a2,X=1), P(w3|a3,X=1), P(w1|X=0)
And all the following are zero: P(wi|aj,X=1) for i and j not equal, P(wi|X=0) for i 2 or 3.
w2 and w3 are not distinguished in any way.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T18:52:24.861Z · LW(p) · GW(p)
In your notation in the post, I take w (and wf) as referring to elementary events, very specific descriptions of the world that AI probably won't be able to predict individually, and R(w) measures the effect of X on these elementary events. In this discussion, if "w2" is "AI takes over discreetly", w2 is not an elementary event, it's either a probability distribution or a proper (big) event. As a result, I don't see how the discussion of P(wi|aj,X=1) (where wi are big events, not elementary events from the definition of R(w)) is relevant for discussing the value of the penalty function.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T18:54:30.997Z · LW(p) · GW(p)
No, they're worlds (or partial descriptions of worlds) - we could define them as possible full space-time manifolds.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2013-02-15T19:10:56.345Z · LW(p) · GW(p)
OK, in the post R(w) can talk about big events w, not just particular worlds (your talking about "integrating across all w" in the post confused me, it now turns out that the possible w are not mutually exclusive). But this doesn't clarify for me the relevance of your point in the grandparent (what is the relevance of P(wi|aj,X=1) for the estimate of the total penalty?).
(If w2 and w3 are particular worlds, then it's incorrect that P(w1|a1,X=1), P(w2|a2,X=1), P(w3|a3,X=1), P(w1|X=0) are about 1, because the AI won't be able to predict what happens if it takes a1, a2 etc. so accurately. If w2 and w3 are partial descriptions of worlds, it is the same thing as them being big events, which is what I've been assuming throughout the thread.)
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-16T09:21:15.613Z · LW(p) · GW(p)
I don't need P(w2|a2,X=1) and P(w3|a3,X=1) to be about one (that was a simplified model) - I need them to be about equal. i,e, the disciple is a really smart AI and can take over the world if motivated to do so.
comment by hankx7787 · 2013-02-15T21:42:29.012Z · LW(p) · GW(p)
I love what you're doing and was with up until the conclusion, "Given all these assumptions, then it seems that this setup will produce what we want: a reduced impact AI that will program a disciple AI that will build a paperclip and little else."
Obviously such a conclusion does not realistically follow simply from implementing this one safety device. This is one good idea, but alone isn't nearly sufficient. You will need many, many more good ideas.
Replies from: Elithrion↑ comment by Elithrion · 2013-02-16T04:50:49.315Z · LW(p) · GW(p)
It would be helpful if you could explain how you think the current implementation would fail, since I don't find the failure obvious. The "safety device" in question is mainly the utility function which should make it so that the AI doesn't want to optimize everything, and in my view it is sufficient (for this limited scenario - the big challenge, I think, is in scaling it up and making it remotely implementable).
Replies from: hankx7787↑ comment by hankx7787 · 2013-02-16T16:12:10.838Z · LW(p) · GW(p)
It's an incredibly complicated software and hardware system. Maybe the most complex thing ever invented. There are bugs. There are unknown unknowns. There are people trying to steal the AI technology. There are people who already have AI technology who are going forward without hindering themselves with these restrictions. All of this doesn't happen in a bubble; there's context. This setup has to come from somewhere. The AI has to come from somewhere. This has to be implemented in an actual place. Somebody has to fund all of this - without using that power to compromise the system. Obviously there are loads of surrounding social and technical problems, even assuming this system is built absolutely perfectly, that cannot be swept under the rug when the stakes are this high. I don't really want to go into specifics beyond that. This is a great attempt at one piece of the puzzle, but it's only one piece. We will need a lot more.
At any rate, my point is that this is like anything else that generally falls under Hank's law of AGI safety, which states something like, "Your AGI safety measures will not be good enough, even when taking into account Hank's law of AGI safety..."
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-18T13:00:03.779Z · LW(p) · GW(p)
but it's only one piece. We will need a lot more.
I agree.
comment by Shmi (shminux) · 2013-02-14T17:43:23.678Z · LW(p) · GW(p)
Thinking of possible ways to munchkin this setup... One example: create a copy of the universe, and turn it into paperclips, while leaving the original intact (R was originally specified over
only). Provided, of course, that building more than a single paperclip increases U. This seems to be implied by "The disciple builds a paperclip or two and nothing much else", though is in contradiction with "utility 1 if it builds at least one".
↑ comment by Stuart_Armstrong · 2013-02-14T17:52:22.886Z · LW(p) · GW(p)
Provided, of course, that building more than a single paperclip increases U. This seems to be implied by "The disciple builds a paperclip or two and nothing much else", though is in contradiction with "utility 1 if it builds at least one".
Building two paperclips increases the probability that you've built one (and haven't just imagined you built one).
↑ comment by Stuart_Armstrong · 2013-02-14T17:45:08.975Z · LW(p) · GW(p)
Thinking about possible ways to munchkin this setup...
:-D That's exactly what I want.
One example: create a copy of the universe...
Don't get that - can you develop the idea? "create a copy of the universe" seems... non-trivial.
Replies from: shminux↑ comment by Shmi (shminux) · 2013-02-14T17:59:14.963Z · LW(p) · GW(p)
Non-trivial indeed, but why would it stop a capable AI determined to maximize its utility?
Further notes:
F contains everything that can be reached from O, along a geodesic with proper-time more than two hours.
Geodesic is probably too weak, as it implies ballistic motion only. A timelike or null future-pointing path is somewhat safer (one should be allowed to use engines). Still, anything outside O's original lightcone, or within a two-hour proper-time window appears to be a fair game for paperclipping.
Moreover, any timelike curve can be mimicked by a near-zero-proper-time curve. Does this mean the AI can extend the window out into the future indefinitely?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-14T18:13:55.948Z · LW(p) · GW(p)
Do you mean the actual AI making an actual physical copy of the actual universe?
Added a clause that the AI must obey the laws of physics; it was implicit, but now it's explicit.
Still, anything outside O's original lightcone, or within a two-hour proper-time window appears to be a fair game for paperclipping.
Yes. But the AI can only reach that if it breaks the laws of physics, and if it can do that, we likely have time travel so our efforts are completely for naught.
Moreover, any timelike curve can be mimicked by a near-zero-proper-time curve. Does this mean the AI can extend the window out into the future indefinitely?
No. I defined F as anything that can be reached by a timeline geodesic of length two hours (though you're right that it needn't be a geodesic). Just because the point can be reached by a path of zero length, doesn't mean that it's excluded from F.
Replies from: shminux↑ comment by Shmi (shminux) · 2013-02-14T18:25:44.570Z · LW(p) · GW(p)
But the AI can only reach that if it breaks the laws of physics
... As we know them now. Even then, not quite. The AI might just build a version of the Alcubierre drive, or a wormhole, or... In general, it would try to exploit any potential discrepancy between the domains of U and R.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-14T18:29:38.351Z · LW(p) · GW(p)
Ok, I concede that if the AI can break physics as we understand it, the approach doesn't work. A valid point, but a general one for all AI (if the AI can break our definitions, then even a friendly AI isn't safe, even if the definitions in it seem perfect).
Any other flaws in the model?
Replies from: Larks↑ comment by Larks · 2013-02-16T09:12:02.385Z · LW(p) · GW(p)
There's a big difference between UFAI because it turned out tha peano arithmetic was inconsistant, which no-one think possible, and UFAI because our current model of physics was wrong/the true model was given negligible probability, which seems very likely.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-16T09:25:45.228Z · LW(p) · GW(p)
Yes.
This is related to ontology crises - how does the AI generalise old concepts across new models of physics?
But it may be a problem for most FAI designs, as well.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-17T02:29:21.911Z · LW(p) · GW(p)
Um, I wouldn't hurt people if I discovered I could violate the laws of physics. Why should a Friendly AI?
Replies from: ialdabaoth, Stuart_Armstrong, shminux↑ comment by ialdabaoth · 2013-02-17T02:34:53.714Z · LW(p) · GW(p)
Why shouldn't it? To rephrase, why do you intuitively generalize your own utility function to that of a FAI?
Replies from: gjm↑ comment by gjm · 2013-02-17T02:50:41.513Z · LW(p) · GW(p)
Because having a utility function that somewhat resembles humans' (including Eliezer's) is part of what Eliezer means by "Friendly".
Maybe some Friendly AIs would in fact do that. But Eliezer's saying there's no obvious reason why they should; why would finding that the laws of physics aren't what we think they are cause an AI to stop acting Friendly, any more than (say) finding much more efficient algorithms for doing various things, discovering new things about other planets, watching an episode of "The Simpsons", or any of the countless other things an AI (or indeed a human) might do from time to time?
If I'm right that #2 is part of what Eliezer is saying, maybe I should add that I think it may be missing the point Stuart_Armstrong is making, which (I think) isn't that an otherwise-Friendly AI would discover it can violate what we currently believe to be the laws of physics and then go mad with power and cease to be Friendly, but that a purported Friendly AI design's Friendlines might turn out to depend on assumptions about the laws of physics (e.g., via bounds on the amount of computation it could do in certain circumstances or how fast the number of intelligent agents within a given region of spacetime can grow with the size of the region, or how badly the computations it actually does can deviate from some theoretical model because of noise etc.), and if those assumptions then turned out to be wrong it would be bad.
(To which my model of Eliezer says: So don't do that, then. And then my model of Stuart says: Avoiding it might be infeasible; there are just too many, too non-obvious, ways for a purported proof of Friendliness to depend on how physics works -- and the best we can do might turn out to be something way less than an actual proof, anyway. But by now I bet my models have diverged from reality. It's just as well I'm just chattering in an LW discussion and not trying to predict what a superintelligent machine might do.)
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-18T13:11:37.040Z · LW(p) · GW(p)
That model of me forced me to think of a better response :-)
http://lesswrong.com/lw/gmx/domesticating_reduced_impact_ais/8he2
And as for the assumptions, I'm more worried about the definitions: what happens when the AI realises that the definition of what a "human" is turns out to be flawed.
Replies from: JGWeissman↑ comment by JGWeissman · 2013-02-18T15:47:23.414Z · LW(p) · GW(p)
what happens when the AI realises that the definition of what a "human" is turns out to be flawed.
The AI's definition of "human" should be computational. If it discovers new physics, it may find additional physical process that implement that computation, but it should not get confused.
Ontological crises seems to be a problem for AIs with utility functions over arrangements of particles, but it doesn't make much sense to me to specify our utility function that way. We don't think of what we want as arrangements of particles, we think at a much higher level of abstraction and we would be happy with any underlying physics that implemented the features of that abstraction level. Our preferences at that high level are what should generate our preferences in terms of ontologically basic stuff whatever ontology the AI ends up using.
Replies from: Eliezer_Yudkowsky, shminux, MugaSofer↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-18T18:07:51.584Z · LW(p) · GW(p)
Right - that's the obvious angle of attack for handling ontological crises.
↑ comment by Shmi (shminux) · 2013-02-18T18:38:04.372Z · LW(p) · GW(p)
Our preferences at that high level are what should generate our preferences in terms of ontologically basic stuff whatever ontology the AI ends up using.
I am not sure that the higher-level of abstraction saves you from sliding into an ontological black hole. My analogy is in physics: Classical electromagnetism leads to the ultraviolet catastrophe, making this whole higher classical level unstable, until you get the lower levels "right".
I can easily imagine that an attempt to specify a utility function over "a much higher level of abstraction" would result in a sort of "ultraviolet catastrophe" where the utility function can become unbounded at one end of the spectrum, until you fix the lower levels of abstraction.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-19T02:23:05.545Z · LW(p) · GW(p)
Can you give me an example of an ultraviolet catastrophe, say for paperclips?
Replies from: shminux, Manfred↑ comment by Shmi (shminux) · 2013-02-19T06:40:12.442Z · LW(p) · GW(p)
Not sure if this is what you are asking, but a paperclip maximizer not familiar with general relativity risks creating a black hole out of paper clips, losing all its hard work as a result.
Replies from: JGWeissman↑ comment by JGWeissman · 2013-02-19T06:59:05.185Z · LW(p) · GW(p)
That would be a problem of the AI not being able to accurately predict the consequences of its actions because it doesn't know enough physics. An ontological crises would involve the paperclip maximizer learning new physics and therefor getting confused about what a paperclip is and maximizing something else.
Replies from: CCC, shminux↑ comment by CCC · 2013-02-19T08:19:37.724Z · LW(p) · GW(p)
Example: An AI is introduces to a large quantity of metal, and told to make paperclips. Since the AI is confined in a metal-only environment, "paperclip" is defined only as a shape.
The AI escapes from the box, and encounters a lake. It then spends some time trying to create paperclip shapes from water. After a bit of experimentation, it finds that freezing the water to ice allows it to create paperclip shapes. Moreover, it finds that any substance provided with enough heat will melt.
Therefore, in order to better create paperclip shapes from other, possibly undiscovered materials, the AI puts out the sun, and otherwise seeks to minimise the amount of heat in the universe.
Is that what you're looking for?
Replies from: army1987, JGWeissman, MugaSofer↑ comment by A1987dM (army1987) · 2013-02-22T02:42:50.720Z · LW(p) · GW(p)
Pretty sure that freezing stuff would cost lots of negentropy which Clippy could spend to make many more paperclips out of already solid materials instead.
↑ comment by JGWeissman · 2013-02-19T14:26:54.018Z · LW(p) · GW(p)
That is an example of a paperclip maximizer failing an ontological crises. It doesn't seem to illustrate Shminux's concept of an "ultraviolet catastrophe", though.
Replies from: CCC↑ comment by CCC · 2013-02-20T14:26:57.677Z · LW(p) · GW(p)
You are correct. Can you suggest an example that resolves that shortcoming?
Replies from: JGWeissman↑ comment by JGWeissman · 2013-02-20T14:39:43.826Z · LW(p) · GW(p)
I think that the concept of an ontological crises metaphorically similar to the ultraviolet catastrophe is confused, and I don't expect to find a good example. I suspect that Shminux was thinking more of problems of inaccurate predictions from incomplete physics than utility functions that don't translate correctly to new ontologies when he proposed it.
↑ comment by MugaSofer · 2013-02-19T12:10:15.661Z · LW(p) · GW(p)
To be clear, the issue here is that it inadvertently hastens the heat death of the universe,and generally lowers it's ability to create paperclips, right?
Replies from: CCC↑ comment by CCC · 2013-02-20T14:25:59.985Z · LW(p) · GW(p)
It's just an example of an ontological crisis; the AI is learning new physics (cold causes water to freeze), and is not certain of what a paperclip is, and is therefore maximising something else (coldness).
Replies from: JGWeissman, MugaSofer↑ comment by JGWeissman · 2013-02-20T14:47:46.826Z · LW(p) · GW(p)
and is therefore maximising something else (coldness).
The thing the paperclip maximizer is maximizing instead of paperclips is paperclip-shaped objects made out of the wrong material. Coldness is just an instrumental value, and the example could be simplified and made more plausible by taking that part out. ETA: And the relevant new physics is not that cold water freezes but that materials other than metal exist.
Replies from: CCC↑ comment by CCC · 2013-02-22T07:12:21.810Z · LW(p) · GW(p)
The thing the paperclip maximizer is maximizing instead of paperclips is paperclip-shaped objects made out of the wrong material. Coldness is just an instrumental value,
A good point. I hadn't thought of it that way, but you are correct.
And the relevant new physics is not that cold water freezes but that materials other than metal exist.
Exactly, yes.
↑ comment by Shmi (shminux) · 2013-02-19T07:38:30.549Z · LW(p) · GW(p)
Oh, OK. What are the abstraction levels a paperclip maximizer might use?
↑ comment by Manfred · 2013-02-19T04:56:28.690Z · LW(p) · GW(p)
Hm.
I think it largely comes down to how you handle divergent resources. For the ultraviolet catastrophe, let's use the example of... the ultraviolet catastrophe.
Let's suppose that the AI had a use for materials that emitted infinite power in thermal radiation. In fact, as the power emitted went up, the usefulness went up without bound. Photonic rocket engines for exploring the stars, perhaps, or how fast you could loop a computational equivalent of a paper clip being produced.
Now, the AI knows that the ultraviolet catastrophe doesn't actually occur, with very good certainty. But it could get Pascal's wagered here - it takes actions weighted both by the probability, and by the impact the action could have. So it assigns a divergent weight to actions that benefit divergently from the ultraviolet catastrophe, and builds a infinite-power computer that it knows won't work.
Replies from: MugaSofer↑ comment by MugaSofer · 2013-02-19T12:15:32.863Z · LW(p) · GW(p)
So it assigns a divergent weight to actions that benefit divergently from the ultraviolet catastrophe, and builds a infinite-power computer that it knows won't work.
How is this different to accepting a bet it "knows" it will lose? We may know with certainty that it doesn't live in a classical universe, because we specified the problem, but the AI doesn't.
Replies from: Manfred↑ comment by Manfred · 2013-02-19T12:35:16.994Z · LW(p) · GW(p)
Well, from the perspective of the AI, it's behaving perfectly rationally. It finds the highest-probability thing that could give it infinite reward, and then prepares for that, no matter how small the probability is. It only seems strange to us humans because (1) we're Allais-ey, and (2) it is a clear case of logical, one-shot probability, which is less intuitive.
If our AI models the world with one set of laws at a time, rather than having a probability distribution over laws, then this behavior could pop up as a surprise.
Replies from: MugaSofer↑ comment by MugaSofer · 2013-03-06T09:13:37.344Z · LW(p) · GW(p)
The AI's definition of "human" should be computational. If it discovers new physics, it may find additional physical process that implement that computation, but it should not get confused.
What if it discovers new math? Less likely, I know, but...
↑ comment by Stuart_Armstrong · 2013-02-18T13:10:01.432Z · LW(p) · GW(p)
Here's my intuition: Eliezer and other friendly humans have got their values partially through evolution and selection. Genetic algorithms tend to be very robust - even robust to the problem not being properly specified. So I'd assume that Eliezer and evolved FAIs would preserve their friendliness if the laws of physics were changed.
An AI with a designed utility function is very different, however. These are very vulnerable to ontology crises, as they're grounded in formal descriptions - and if the premises of the description change, their whole values change.
Now, presumably we can do better than that, and design a FAI to be robust across ontology changes - maybe mix in some evolution, or maybe some cunning mathematics. If this is possible, however, I would expect the same approach to succeed with a reduced impact AI.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-18T17:55:39.822Z · LW(p) · GW(p)
I got 99 psychological drives but inclusive fitness ain't one.
In what way is evolution supposed to be robust? It's slow, stupid, doesn't reproduce the content of goal systems at all and breaks as soon as you introduce it to a context sufficiently different from the environment of evolutionary ancestry because it uses no abstract reasoning in its consequentialism. It is the opposite of robust along just about every desirable dimension.
Replies from: Stuart_Armstrong, Evan_Crowe, CCC, Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-19T11:35:09.961Z · LW(p) · GW(p)
In what way is evolution supposed to be robust?
It's not as brittle as methods like first order logic or computer programming. If I had really bad computer hardware (corrupted disks and all that), then an evolved algorithm is going to work a lot better than a lean formal program.
Similarly, if an AI was built by people who didn't understand the concept of friendliness, I'd much prefer they used reinforcement learning or evolutionary algorithms than direct programming. With the first approaches, there is some chance the AI may infer the correct values. But with the wrong direct programming, there's no chance of it being safe.
As you said, you're altruistic, even if the laws of physics change - and yet you don't have a full theory of humankind, of worth, of altruism, etc... So the mess in your genes, culture and brain has come up with something robust to ontology changes, without having to be explicit about it all. Even though evolution is not achieving it's "goal" through you, something messy is working.
↑ comment by Evan_Crowe · 2013-02-18T21:05:57.110Z · LW(p) · GW(p)
I think there might be a miscommunication going on here.
I see Stuart arguing that Genetic algorithms function independent of physics in terms of their consistent "friendly" trait. i.e. if in universe a there is a genetic algorithm that finds value in expressing the "friendly" trait, then that algorithm would, if placed in universe b (where the boundary conditions of the universe were slightly different) would tend to eventually express that "friendly" trait again. Thereby meaning robust (when compared to systems that could not do this)
I don't necessarily agree with that argument, and my interpretation could be wrong.
I see Eliezer arguing that evolution as a system doesn't do a heck of a lot, when compared to a system that is designed around a goal and involves compensation for failure. i.e. I can't reproduce with a horse, this is a bad thing because if I were trapped on an island with a horse our genetic information would die off, where in a robust system, I could breed with a horse, thereby preserving our genetic information.
I'm sorry if this touches too closely on the entire "well, the dictionary says" argument.
Replies from: Evan_Crowe↑ comment by Evan_Crowe · 2013-02-18T22:57:20.160Z · LW(p) · GW(p)
Oh, now I feel silly. The horse IS the other universe.
↑ comment by CCC · 2013-02-19T08:13:37.447Z · LW(p) · GW(p)
In what way is evolution supposed to be robust?
If I had to guess Stuart_Armstrong's meaning, I would guess that genetic algorithms are robust in that they can find a solution to a poorly specified and poorly understood problem statement. They're not robust to dramatic changes in the environment (though they can correct for sufficiently slow, gradual changes very well); but their consequentialist nature provides some layer of protection from ontology crises.
↑ comment by Stuart_Armstrong · 2013-02-19T11:36:45.392Z · LW(p) · GW(p)
Replies from: MugaSofer↑ comment by MugaSofer · 2013-02-19T14:51:32.661Z · LW(p) · GW(p)
You know this is blank, right?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-19T15:01:37.744Z · LW(p) · GW(p)
I had a response that was mainly a minor nitpick; it didn't add anything, so I removed it.
Replies from: MugaSofer↑ comment by Shmi (shminux) · 2013-02-17T03:20:36.430Z · LW(p) · GW(p)
Presumably all the math you are working on is required for your proof of friendliness? And if the assumptions behind the math do not match the physics, wouldn't it invalidate the proof, or at least its relevance to the world we live in? And then all bets are off?
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-17T04:56:44.144Z · LW(p) · GW(p)
Even invalidating a proof doesn't automatically mean the outcome is the opposite of the proof. The key question is whether there's a cognitive search process actively looking for a way to exploit the flaws in a cage. An FAI isn't looking for ways to stop being Friendly, quite the opposite. More to the point, it's not actively looking for a way to make its servers or any other accessed machinery disobey the previously modeled laws of physics in a way that modifies its preferences despite the proof system. Any time you have a system which sets that up as an instrumental goal you must've done the Wrong Thing from an FAI perspective. In other words, there's no super-clever being doing a cognitive search for a way to force an invalidating behavior - that's the key difference.
Replies from: Stuart_Armstrong, shminux↑ comment by Stuart_Armstrong · 2013-02-18T13:14:34.574Z · LW(p) · GW(p)
The problem is that it's a utility maximiser. If the ontology crises causes the FAI's goals to slide a bit in the wrong direction, it may end up optimising us out of existence (even if "happy humans with worthwhile and exciting lives" is still high in its preference ordering, it might not be at the top).
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-18T17:52:17.106Z · LW(p) · GW(p)
This is a uniform problem among all AIs. Avoiding it is very hard. That is why such a thing as the discipline of Friendly AI exists in the first place. You do, in fact, have to specify the preference ordering sufficiently well and keep it sufficiently stable.
Stepping down from maximization is also necessary just because actual maximization is undoable, but then that also has to be kept stable (satisficers may become maximizers, etc.) and if there's something above eudaimonia in its preference ordering it might not take very much 'work' to bring it into existence.
↑ comment by Shmi (shminux) · 2013-02-17T05:22:18.354Z · LW(p) · GW(p)
Hmm, I did not mean "actively looking". I imagined something along the lines of being unable to tell whether something that is a good thing (say, in a CEV sense) in a model universe is good or bad in the actual universe. Presumably if you weren't expecting this to be an issue, you would not be spending your time on non-standard numbers and other esoteric mathematical models not usually observed in the wild. Again, I must be missing something in my presumptions.
Replies from: Eliezer_Yudkowsky↑ comment by Eliezer Yudkowsky (Eliezer_Yudkowsky) · 2013-02-17T06:19:58.247Z · LW(p) · GW(p)
The model theory is just for understanding logic in general and things like Lob's theorem, and possibly being able to reason about universes using second-order logic. What you're talking about is the ontological shift problem which is a separate set of issues.
comment by MaoShan · 2013-02-15T04:41:06.881Z · LW(p) · GW(p)
t=59 minutes...
AI: Hmm, I have produced in this past hour one paperclip, and the only other thing I did was come up with the solutions for all of humanity's problems, I guess I'll just take the next minute to etch them into the paperclip...
t=2 hours...
Experimenters: Phew, at least we're safe from that AI.
Replies from: Stuart_Armstrong, CCC↑ comment by Stuart_Armstrong · 2013-02-15T12:13:54.700Z · LW(p) · GW(p)
Extra clarification: in this example, I'm assuming that we don't observe the AI, and that we are very unlikely to detect the paperclip. How to get useful work out of the AI is the next challenge, if this model holds up.
comment by poiuyt · 2013-02-15T01:40:35.229Z · LW(p) · GW(p)
It seems to me like an AI enclosed in a cloud of chaotic antimatter would not be very useful. Any changes small enough to be screened out by the existence of the antimatter cloud would also be small enough to be destroyed by the antimatter cloud when we go to actually use them, right? If we want the AI to make one paperclip, presumably we want to be able to access that paperclip once it's built. And the antimatter cloud would prevent us from getting at the paperclip. And that's completely ignoring that antimatter bomb rigged to detonate the contents of the box. There needs to be a better way of defining "reduced impact" for this to be a practical idea.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-15T12:14:05.660Z · LW(p) · GW(p)
Extra clarification: in this example, I'm assuming that we don't observe the AI, and that we are very unlikely to detect the paperclip. How to get useful work out of the AI is the next challenge, if this model holds up.
Replies from: Strange7↑ comment by Strange7 · 2013-02-18T06:35:18.921Z · LW(p) · GW(p)
I'm pretty sure this model is inherently a dead end for any useful applications. Even without gratuitous antimatter, a sufficiently smart AI trying to minimize it's future impact will put it's affairs in order and then self-destruct in some low-collateral-damage way which prevents anything interesting from being learned by analysis of the remains.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-18T12:58:52.335Z · LW(p) · GW(p)
self-destruct in some low-collateral-damage way which prevents anything interesting from being learned by analysis of the remains
That's a plus, not a minus.
We can also use utility indifference (or something analogous) to get some useful info out.
Replies from: Strange7↑ comment by Strange7 · 2013-02-21T15:54:04.896Z · LW(p) · GW(p)
It's a minus if you're trying to convince someone more results-oriented to keep giving you R&D funding. Imagine the budget meeting:
The EPA is breathing down our necks about venting a billion dollars worth of antimatter, you've learned literally nothing, and you consider that a good outcome?
If the AI is indifferent to future outcomes, what stops it from manipulating those outcomes in whatever way is convenient for it's other goals?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2013-02-21T16:44:38.182Z · LW(p) · GW(p)
Indifference means that it cannot value any change to that particular outcome. More details at: http://www.fhi.ox.ac.uk/__data/assets/pdf_file/0020/18371/2010-1.pdf