Medical Image Registration: The obscure field where Deep Mesaoptimizers are already at the top of the benchmarks. (post + colab notebook)
post by Hastings (hastings-greer) · 2023-01-30T22:46:31.352Z · LW · GW · 1 commentsContents
Background: Introduction to Image Registration Neural Networks Arrive Explicitly multistep Neural Registration Hunting for a Mesaoptimizer None 1 comment
Background: Introduction to Image Registration
Image registration, or finding the corresponding points in a pair of, eg, MRI scans, is one of the fundamental tasks in medical image computing- needed for aligning post/pre-op brain scans, tracking lung motion during inhalation, computing statistics across populations etc. The standard formulation of this task is, given two images and , find an invertible function such that the point in corresponds to the point x in , (or equivalently, a point y in moves to in ). For two images of the same body part on the same person, such as the common task of aligning an MRI of a prostate to an ultrasound of that same organ, "corresponds" is extremely well defined: two points correspond if they contain the same physical cell or piece of cartilage. For two images of different people, the correct answer is more nebulous: certainly the center of Alex's pineal gland has a corresponding point in Bob's head, but what about points in the grey matter, which is uniquely folded in every person?
Instead of hunting correspondences directly, we could introduce a surrogate objective. The traditional approach is to parametrize by then introduce a reward function that scores various , such as
,
or
"The squared difference between the warped moving image and the fixed image, plus a penalty to encourage smoothness".
The minimizing value of is then found via some kind of search. For details, a good introduction: (2004)[1]. For a modern, powerful implementation see ANTs, NiftyReg
Neural Networks Arrive
Finding the minimizing value of turns out to be quite expensive computationally- the leading package ANTs can take nearly an hour to align two high resolution images on its highest setting (named SyNOnly if you want to dig into it). An alternative has emerged in recent years: optimize a neural network that takes in two images and directly spits out a function . The initial approach was to register a large collection of images using the traditional methods to create a dataset and then train using a standard supervised learning objective along the lines of Quicksilver[2] is a canonical paper advocating this approach . However, an alternative soon emerged: just differentiate through the similarity and regularity penalties, then through the network:
This approach just requires images: there is no need to pre-compute ground truth transforms to train to imitate.
Explicitly multistep Neural Registration
The above objective can be solved by a network without any special structure to encourage mesaoptimization. However, adding structure improves performance- to encourage mesaoptimization, we will define a simple world where the network can perform a series of actions: the network takes actions by warping , and at each time step it is fed the warped image from the previous time step. This way, it can gradually move one image to align with the other, or align it in the first step then subsequently make small adjustments, or take any other action- it is only scored on the alignment after all timesteps have passed. (I think that this multiple step process is Mesaoptimization, but that analogy is the shakiest part of this post)
This is an approach being applied right now: I know it's the approach behind ltian in this leaderboard https://www.cbica.upenn.edu/BraTSReg2022/lboardValidation.html because I'm on that entry. It's also used in AVSM, ICON, LapIRN (roughly), etc.
But lets step back from huge, 100M parameter models.
Lets train a simple MLP that takes in an MNIST image and outputs a vector that moves each pixel
class FCNet(torch.nn.Module):
def __init__(self, size=28):
super().__init__()
self.size = size
self.dense1 = nn.Linear(size * size * 2, 50)
self.dense2 = nn.Linear(50, 50)
self.dense3 = nn.Linear(50, size * size * 2)
torch.nn.init.zeros_(self.dense3.weight)
torch.nn.init.zeros_(self.dense3.bias)
def forward(self, x, y):
x = torch.reshape(torch.cat([x, y], 1), (-1, 2 * self.size * self.size))
x = F.relu(self.dense1(x))
x = F.relu(self.dense2(x))
x = self.dense3(x)
x = torch.reshape(x, (-1, 2, self.size, self.size))
return x
and put it in the aforementioned world using the icon_registration library
inner_net = icon.FunctionFromVectorField(FCNet(size=28))
n2 = inner_net
for _ in range(8):
n2 = icon.TwoStepRegistration(
n2,
inner_net
)
net = icon.losses.DiffusionRegularizedNet(n2, icon.ssd, lmbda=.05)
net.assign_identity_map(sample_batch.shape)
After training it on pairs of the 5s in MNIST,
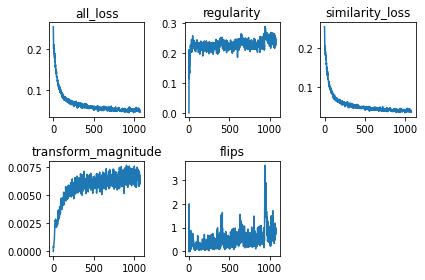
it nicely minimizes the loss we asked it to minimize

Hunting for a Mesaoptimizer
So at this point, we have a network that appears to perform optimization to find the that minimizes . Wearing my alignment research hat, I am curious about:
- Its algorithm: Is it really performing an iterative optimization against a loss? Can we find that loss in its weights?
- Its inner alignment: Is it trying to optimize the same thing that the outer Adam descent is optimizing, or something else that has a similar minimum on the training set?
- Its generality: When we go out of distribution, what happens? Will it fail to optimize, optimize the right thing, or optimize something else?
I don't have answers to 1 or 2 yet, but I have a tentative answer to 3, and it's that once out of distribution, the network optimizes something else.
Specifically, if after training on 5s, we evaluate on 7s, the network does not merely warp the 7s to align with each other. Instead, sometimes it warps the moving 7 to look like a 5, then aligns that 5 to the fixed 7. It's hard to assign agency to a MLP with a hidden layer size of 50, but it sure looks to me like its inner alignment is to first bring the input data in-distribution, and only then optimizes the least squares loss by aligning parts of the 5 to parts of the 7.

I'm still researching this and am new to alignment research- any tips on how to prove what the inner goal actually is?
Here is a notebook to produce these figures:
https://colab.research.google.com/drive/1mHjOHf2EA9KzcX6UAAMSx71xoOftssCr?usp=sharing
The network trains in about 50 seconds, so you should not fear to play around with changing hyperparameters, etc.
- ^
Crum WR, Hartkens T, and Hill DLG. Non-rigid image registration: theory and practice. Br J Radiol 2004; 77:
https://www.birpublications.org/doi/10.1259/bjr/25329214?url_ver=Z39.88-2003&rfr_id=ori:rid:crossref.org&rfr_dat=cr_pub%20%200pubmed
- ^
https://arxiv.org/abs/1703.10908 Quicksilver: Fast Predictive Image Registration - a Deep Learning Approach
1 comments
Comments sorted by top scores.
comment by Robert Miles (robert-miles) · 2024-08-22T12:04:05.939Z · LW(p) · GW(p)
This is an interesting post!
I'm new to alignment research - any tips on how to prove what the inner goal actually is?
Haha! haaaaa 😢