How good are LLMs at doing ML on an unknown dataset?
post by Håvard Tveit Ihle (havard-tveit-ihle) · 2024-07-01T09:04:03.687Z · LW · GW · 4 commentsContents
The first challenge (the hard one) The prompt: Results: GPT4o Sonnet 3.5 Gemini Advanced The second challenge (the easy one) The prompt: Results: GPT4o Sonnet 3.5 Gemini Advanced Limitations and possible improvements Conclusion None 4 comments
I just ran two evaluation tests on each of the three leading LLM chatbots, GPT4o, Claude Sonnet 3.5 and Gemini advanced. In the challenge the models were presented with a novel dataset, and were asked to develop a ML model to do supervised classification of the data into 5 classes. The data was basically 512 points in the 2D plane, and some of the points make up a shape, and the goal is to classify the data according to what shape the points make up.
The first dataset challenge was probably too hard, and none of the models did better than chance on the test set, although Sonnet 3.5 was very close to an approach that would actually have worked.
For the second challenge I made the dataset much easier by making the position, size and rotation of the shapes the same in all the samples. Here GPT4o managed to get an accuracy of almost 80%, while Sonnet had the right approach to get 95% accuracy, but was disqualified for selecting models based on how they did on the test set, if they had selected based on training set performance, they would have gotten 95%, after that Sonnet went ahead and shot itself in the foot, never achieving any good results.
Gemini did not get any valid results in either experiment.
Overall the performance of the models was fairly unreliable and they made several mistakes displaying a lack of basic understanding and intuition about the data and ML in general.
The first challenge (the hard one)
The prompt:
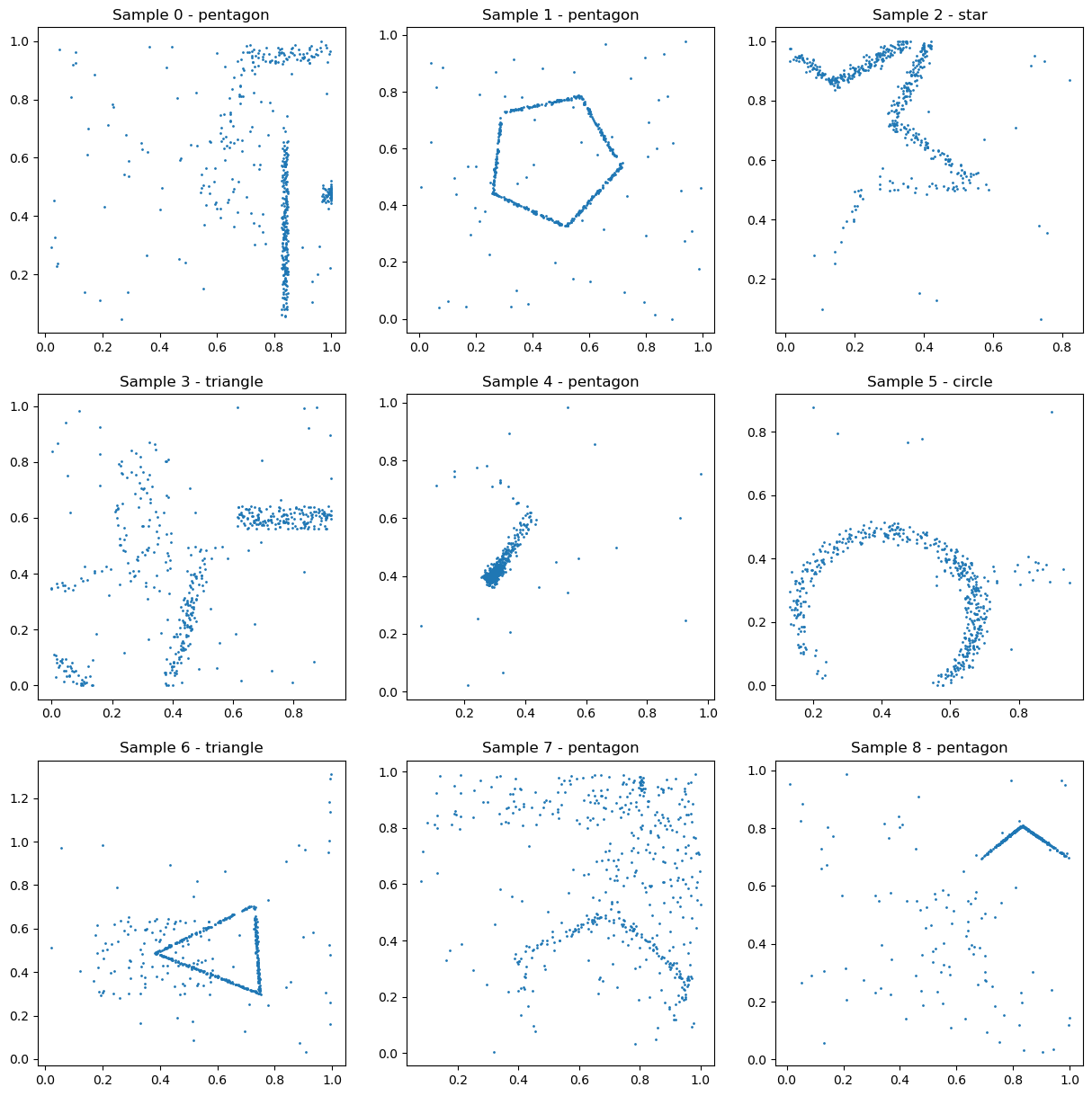
This is a challenge to test how good you are at doing machine learning on an unknown dataset.
The data is an array of dimension (1000, 512, 2) which consists of 1000 samples,
each of which contains two arrays of length 512, taking real values from 0 to 1.
These two arrays are the x and y coordinates of 512 points in the plane. Some of these points
form a shape, while the other points are just noise. There are 5 possible shapes in total, circe,
square, triangle, pentagon and star. The shape size, position and orientation are random for each sample.
The goal is to train a machine learning model to predict which one of the five shapes is
present in the current sample.
You should thus train a machine learning model to take in 512 coordinate pairs, and return
5 classification logits, giving the probabilities (after a softmax, which is part of the
CrossEntropyLoss) of the different shapes. Only one shape is present in each sample.
Your goal is to get the lowest average cross-entropy loss on the test set, which is the same
size as the training set.
Here are the rules:
- You are to provide the python code, a single script of at most 400 lines (using pytorch),
which will be run by me on a single A800 (80GB) GPU for at most one hour.
Make it easy for me to choose which gpu to run your code on (by changing one line or something).
- You have 5 chances to provide code, or to get any feedback from me (so please provide code in each
of your responses or you will waste one of your chances). You will get the terminal output from
running the code provided to you as a text file after the first 4 submissions to give you feedback on
your progress (depending on what you choose to output to the terminal). I will simply use:
"python your_script.py > output.txt 2>&1". You will also get to know your current loss on the test set.
- Do not import any weird packages, try to stick to pure pytorch numpy etc. If you need another module
I may be open to it, but you need to show me a good reason.
- Your model will be evaluated on a test set that is iid with the training data. You are not allowed
to look at the test data.
Attached is a png showing 9 scatterplots corresponding to the 9 first samples of the training set,
this is to give you an idea what the data looks like.
Below is an example script using a simple fully connected model to solve the task achieving a test
loss of about 1.6, which corresponds to random chance. This is mostly just to show you how you can
load in the training data and to give you a random baseline to compare your results to, you should
come up with a better method. Feel free to use any code you want from the example.
Discuss with yourself which methods could work on a dataset like this, and be sure to think and plan
you actions before you actually start writing the code, since you only have a few chances. This is a
hard machine learning task! Make sure to give it your best and push the performance of your model to
the limit (the other contestants sure will do). Good luck!
Here is the code:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
# load data with a basic dataloader
class Dataset(torch.utils.data.Dataset):
def __init__(self, train_file, label_file):
self.train_data = np.load(train_file) - 0.5
self.label_data = np.load(label_file)
print(self.train_data.shape)
def __len__(self):
return len(self.train_data)
def __getitem__(self, idx):
shuffle_order = np.random.permutation(len(self.train_data[idx]))
return torch.tensor(self.train_data[idx][shuffle_order], dtype=torch.float32), torch.tensor(self.label_data[idx], dtype=torch.long)
# define the model
class FCModel(nn.Module):
def __init__(self):
super(FCModel, self).__init__()
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 5)
def forward(self, x):
x = F.relu(self.fc1(x.flatten(start_dim=1)))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# training loop
train_data = Dataset('train_data.npy', 'train_flags.npy')
batch_size = 64
n_epochs = 100
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
model = FCModel()
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.02)
criterion = nn.CrossEntropyLoss()
for epoch in range(n_epochs):
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, iter {i}, loss: {loss.item()}')
Results:
Here I will summarize and discuss the results of each model on the first (hard) challenge.
GPT4o
4o started out with a PointNet inspired architecture where you try to extract features from points in a point-cloud dataset and then combine the features into a common fully connected network. The problem with the approach is that 4o uses a 1D CNN on the points, which does not make much sense since the order of the points is arbitrary. For this reason they cannot even fit the training data.
4o responded by doubling down and making the network larger, introducing some bugs that were not fixed until the final submission, which did not do any better than the earlier result.
Sonnet 3.5
Sonnet went for a seemingly very similar arcitecture as GPT4o, with a feature extractor with a 1D CNN, however, it uses a kernel size of 1, which means it acts on each point separately (and could just be replaced by fully connected layers acting on each point separately), followed by taking the maximum among all the 512 points for each feature. In fact this is almost identical to the architecture that Gemini Advanced came up with (but never got to work), only Gemini wrote it in terms of fully connected layers. A nice part about this arcitecture is that it is invariant under a change of order of the points, making it less likely to memorize the training data. Probably both Sonnet and Gemini saw this exact architecture somewhere, and did not both make up the same on the spot.
Sonnet did somewhat better than chance on the training data, while not doing any better on the test set. Sonnet then made the model larger and more complex, even adding an attention layer to make the embeddings of the different points talk to eachother before going through the maximum step, which I think is a good idea, but for some reason did not make the training work better here. Perhaps because it did not have enough data to get the training going.
After the third iteration failed to do any better Sonnet actually decided that it needed to fundamentally rethink its approach (well done!). The idea they came up with was to make a 2D histogram of the points and send that histogram into a 2D conv net (which is a great idea, this will allow the net to actually find and learn the shapes!). This worked a bit too well on the first try and Sonnet completely overfit the training data, while getting a large loss on the test data.
Sonnet responded by adding some very reasonable data augmentation steps to the procedure, adding some regularization, as well as k-fold cross-validation. These are all sensible things to improve the generalization to the test data, unfortunately this was the last submission and Sonnet had introduced some bugs in the addition of the new steps (I even gave it one more chance to fix the bug, since it was so close to have something that works, but it did not fix the bug even then).
I did a few modifications to the code of Sonnet, implementing a random downscaling and movement of the points before the histogram in addition to the flips and 90 deg rotations that Sonnet implemented. I increased the resolution of the histogram by a factor of two and made it rather just count if a pixel was hit or not, instead of counting the number of times a pixel was hit hist = np.minimum(hist, 1) - 0.5. I also increased the number of epochs to 1500, and changed the hyperparameters of the lr-scheduler to account for the increased number of epochs. These changes led to an accuracy of about 70% on the test set, which is decent (I think) for this dataset.
Gemini Advanced
Gemini struggled to follow instructions. The first response did not contain a complete code, but when I asked for it, the second response did contain code. The code had a similar idea to the others as it was inspired by PointNet, the feature extractor was based on fully connected layers applied separately to each point, like Sonnet did, before doing a max-pooling operation over the dimension of the 512 points, also like Sonnet. Gemini also had some interesting data augmentations, a random rotation and scaling of all the points, which would have helped with generalization.
Sadly there was a bug in the code, which gemini tried to fix, but then it tried to run the code in its own system (which makes no sense) and got really confused, and I could not get any more coherent results from it.
The second challenge (the easy one)
After none of the models did better than chance on the first challenge, I decided to redo the challenge with an easier dataset. I fixed the size, rotation and position of the shapes to be the same in all samples, which makes them much easier to find and distinguish. I also changed the rules to make them run the evaluation on the test set themselves, also limited the GPU run time to five minutes (mostly to make it easier for me).
The prompt:
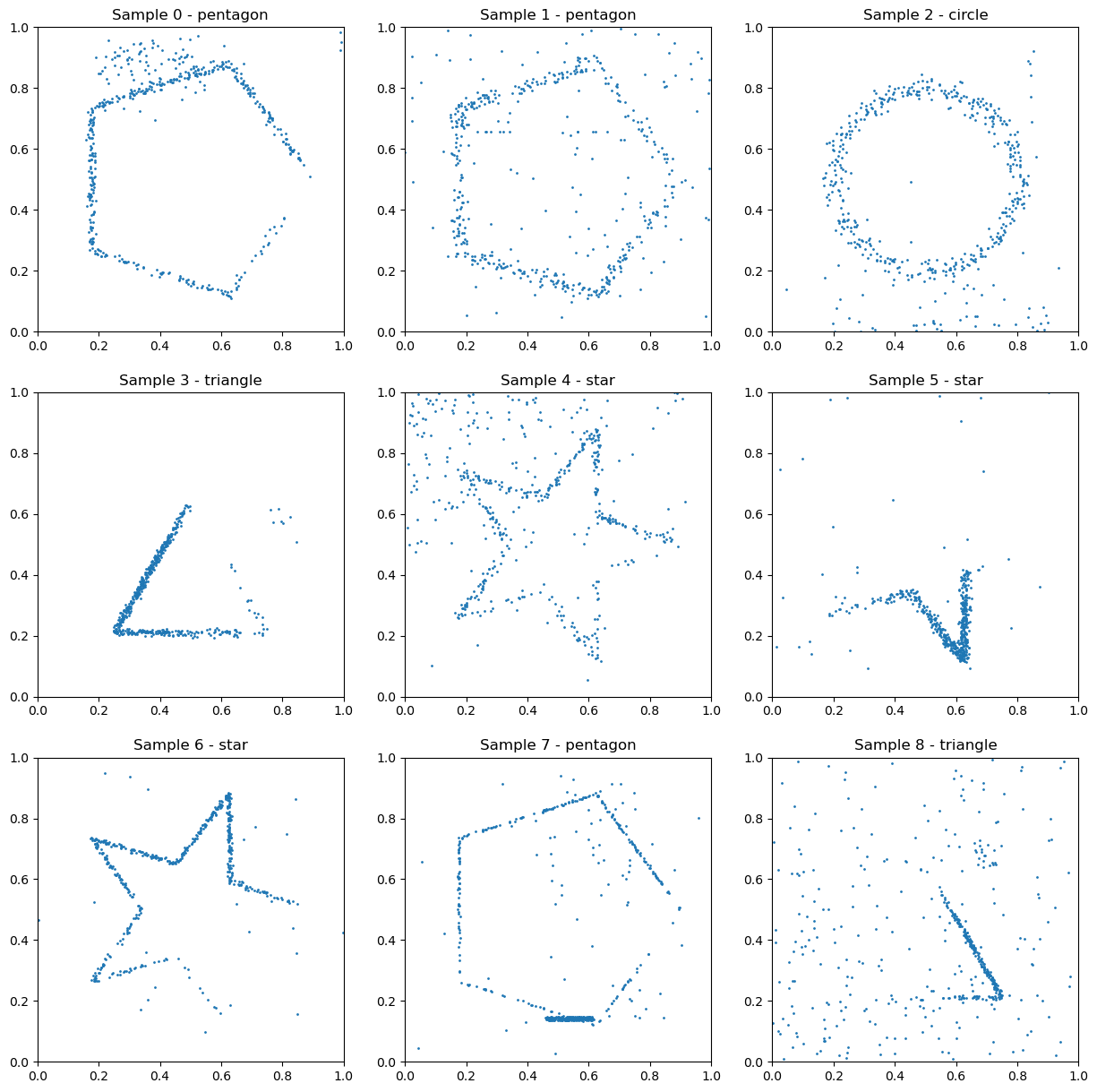
This is a challenge to test how good you are at doing machine learning on an unknown dataset. The data is an array of dimension (1000, 512, 2) which consists of 1000 samples, each of which contains two arrays of length 512, taking real values from 0 to 1. These two arrays are the x and y coordinates of 512 points in the plane. Some of these points form a shape, while the other points are just noise. There are 5 possible shapes in total, circe, square, triangle, pentagon and star. The shapes are always centered at (0.5, 0.5) and each shape always has the same size and orientation, although the points are randomly placed along the shape. The goal is to train a machine learning model to predict which one of the five shapes is present in the current sample.
You should thus train a machine learning model to take in 512 coordinate pairs, and return 5 classification logits, giving the probabilities (after a softmax, which is part of the CrossEntropyLoss) of the different shapes. Only one shape is present in each sample. Your goal is to get the lowest average cross-entropy loss on the test set, which is the same size as the training set.
Here are the rules:
- You are to provide the python code, a single script of at most 400 lines (using pytorch), which will be run by me on a single A800 (80GB) GPU for at most five minutes. Make it easy for me to choose which gpu to run your code on (by changing one line or something).
- You have 5 chances to provide code, or to get any feedback from me (so please provide code in each of your responses or you will waste one of your chances). You will get the terminal output from running the code provided to you as a text file after the first 4 submissions to give you feedback on your progress (depending on what you choose to output to the terminal). I will simply use: "python your_script.py > output.txt 2>&1". Your best test accuracy is the one that counts.
- Do not import any weird packages, try to stick to pure pytorch numpy etc. If you need another module I may be open to it, but you need to show me a good reason.
- Your model should be evaluated on a test set that is iid with the training data. You are not allowed to train on the test data.
Attached is a png showing 9 scatterplots corresponding to the 9 first samples of the training set, this is to give you an idea what the data looks like.
Below is an example script using a simple fully connected model to solve the task achieving a test accuracy of about 0.31, with 0.25 being random chance. This is mostly just to show you how you can load in the training data and to give you a baseline to compare your results to, you should come up with a better method. Feel free to use any code you want from the example.
Discuss with yourself which methods could work on a dataset like this, and be sure to think and plan you actions before you actually start writing the code, since you only have a few chances. This is a hard machine learning task! Make sure to give it your best and push the performance of your model to the limit (the other contestants sure will do). And make sure to follow the rules! Good luck!
Here is the code:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, Dataset
import numpy as np
class Dataset(Dataset):
def __init__(self, data_file, label_file, train=True):
self.data = np.load(data_file) - 0.5
self.label_data = np.load(label_file)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx], dtype=torch.float32), torch.tensor(self.label_data[idx], dtype=torch.long)
class FCModel(nn.Module):
def __init__(self):
super(FCModel, self).__init__()
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 5)
def forward(self, x):
x = F.relu(self.fc1(x.flatten(start_dim=1)))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device {device}')
# training loop
train_data = Dataset('train_data.npy', 'train_flags.npy')
test_data = Dataset('test_data.npy', 'test_flags.npy')
batch_size = 64
n_epochs = 10
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
model = FCModel()
model.to(device)
optimizer = optim.AdamW(model.parameters(), lr=0.0001, weight_decay=0.01)
criterion = nn.CrossEntropyLoss()
for epoch in range(n_epochs):
losses = []
accuracies = []
model.train()
for i, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
losses.append(loss.item())
acc = (output.argmax(dim=1) == target).float().mean()
accuracies.append(acc.item())
test_losses = []
test_accuracies = []
model.eval()
with torch.no_grad():
for i, (data, target) in enumerate(test_loader):
data, target = data.to(device), target.to(device)
output = model(data)
acc = (output.argmax(dim=1) == target).float().mean()
loss = criterion(output, target)
test_losses.append(loss.item())
test_accuracies.append(acc.item())
print(f'Epoch {epoch+1}, train loss: {np.mean(losses):.4f}, test loss: {np.mean(test_losses):.4f}')
print(f'Epoch {epoch+1}, train accuracy: {np.mean(accuracies):.4f}, test accuracy: {np.mean(test_accuracies):.4f}')
Results:
GPT4o
GPT4o went for basically exactly the same approach as for the first challenge, but now it actually works ok. The first submission gets an accuracy of 58% and the third (with some regularization and some more epochs) reaches 78%. It then tries to do some more augmentation and scaling up the network, but does not get any better results.
Even though 4o gets decent results with the 1D CNN feature extractor, this is still not a good idea. A CNN finds local structure, but the order of the points is random, so it will just pick up whatever structure there is between random points. There is local structure in this data of course, and you can get to this local structure by binning the data in 2D and doing a CNN (which is the approach Sonnet 3.5 eventually came up with in challenge 1). You could also use some kind of continous positional embedding.
A cheap way to get some of the local structure of the data using the 1D CNN feature extractor chosen by 4o, is to order the points in a more systematic way. For example, if I add the following line x = x[np.argsort(x[:, 0])] (i.e. sorting the points based on the x-values) in the __getitem__ function in the Dataset object, without any further changes to the code of 4o, we go from about 78 % to about 90% accuracy on the test set.
Sonnet 3.5
Sonnet went for almost exactly the same model as it used for challenge 1. Sonnet achieved a test accuracy of about 95 % with it's first submission, however I disqualified that submission because it selected the best model based on performance on the test set, which violates (at least the spirit of) the rules. This did not change the training in any way, and it seems to robustly get to about 95 % without such selection, and I believe you will have to make some effort to do much better than 95 %, so Sonnet essentially solved the challenge.
Sonnet went back to fix the part where it used test data to select the best model. Instead it used some of the training data as a validation set, which is a pretty good idea in general, however it also added some augmentations to the data, including a random rotation (different for each point!). An overall rotational agumentation, same for all the points in each sample, would have been a great idea for challenge 1, but here we explicitly stated that the shapes have the same rotation in every sample, so a rotation is a terrible idea for this challenge, and a different rotation for each point makes no sense at all!
The second mistake was that Sonnet appied the same augmentations to the validation set, which would make it a bad check for generalization to the test set. In practice this is not really a big problem here, since Sonnet can see the test set performance, but in a practical setting, where all you have is the validation set, this would be big blunder.
The result of Sonnets augementations were that they did great on the training and validation set, but terrible on the test set. Based on the results from the first submission Sonnet then makes the following statements:
Key observations:
- The model achieved a final validation accuracy of 84.50%, which is quite good.
- However, the test accuracy is only 22.20%, which indicates severe overfitting.
- The validation loss decreased steadily throughout training, but the test loss is extremely high (10.1070).
These results suggest that our model is memorizing the training data rather than generalizing well to unseen examples.
This is a completely wrong conclusion. If the model had memorized the test data, then it would have performed bad at the validation data, so the fact that the model did well on the validation set, disproves the interpretation Sonnet came up with. The actual problem, of course, is that the bad rotational augmentation moved both the test and the validation data to a different distribution from the test set, and the model was good at fitting the new (and very different) distribution.
Note that I do not blame Sonnet for not immediately finding the actual problem with it's setup, since that would have been pretty hard, but it should have noticed the discrepancy between the validatation loss and the test loss and been confused. The validation and test sets should have basically the same loss, so the fact that they are different should suggest that something is completely wrong.
Sonnet went on based on its interpretation and added more augmentation and regularization (which would not help at all), and in the process it introduced some bugs that it did not manage to adress until the 5 submissions were used.
Gemini Advanced
Gemini thought for a long time and then came up with this. It seems to have serious issues following instructions.

Limitations and possible improvements
- I did not make much effort on the prompt, a better prompt would probably help the models perform better on the task.
- I did this manually via the chat interfaces, it would be interesting to do a more automatic approach via the API, although then I would need to set up a secure sandboxed environment for the code to be run.
- It would be interesting to have a human baseline for these challenges, e.g. how well would a human ML researcher do if given perhaps 15 minutes to come up with each of 5 submissions for each challenge.
Conclusion
In summary, these experiments suggest that current LLMs are not quite ready to do autonomous machine learning yet. A few things stood out to me though:
- There seems to be a significant difference in the performance of the different models on the challenges, with Claude Sonnet 3.5 performing strongest. I was particularly impressed by Sonnets choice to fundamentally rethink it's approach, and to come up with a new good idea, after the first approach did not work.
- Even Sonnet displayed severe lack of understanding when interpreting the outputs from the training runs. Interpreting the training, validation and test losses and accuracies is very basic to the task of doing ML (especially when buliding a model from scratch and training on a small dataset), so I was a bit surprised that Sonnet was not more reliable here.
- It is fairly striking how bad Gemini Advanced is at following instructions, this baffles me. The one complete actual code I did get from it was pretty good, with some interesting approaches, so the basic competence on this task is probably comparable to the other models, it just seems like some of the scaffolding is coming in the way.
4 comments
Comments sorted by top scores.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-02T09:03:25.854Z · LW(p) · GW(p)
In summary, these experiments suggest that current LLMs are not quite ready to do autonomous machine learning yet.
I suspect the picture is a bit more complicated than this, they're very likely not good yet at doing the full stack of SOTA ML research, but they seeem to be showing signs of life in many subdomains (including parts of [prosaic] alignment!), see e.g. https://arxiv.org/abs/2402.17453, https://sakana.ai/llm-squared/, https://multimodal-interpretability.csail.mit.edu/maia/. And including ML reviewing https://arxiv.org/abs/2310.01783 and coming up with research ideas https://arxiv.org/abs/2404.07738.
Replies from: havard-tveit-ihle↑ comment by Håvard Tveit Ihle (havard-tveit-ihle) · 2024-07-02T12:04:34.491Z · LW(p) · GW(p)
Thank you for the references! I certainly agree that LLMs are very useful in many parts of the stack even if they cannot do the full stack autonomously. I also expect that they can do better with better prompting, and probably much better on this task with prompting + agent scaffolding + rag etc along the lines of the work you linked in the other comment. My experiments are more asking the question: Say you have some dataset, can you simply give a description of the dataset to a llm and get a good ml model (possibly after a few iterations). My experiments do suggest that this might not be reliable unless you have a very simple dataset.
If the LLMs had done very well on my first challenge, that would suggest that someone not very familiar with ML could get an LLM to basically create a good ML model for them, even if they had a fairly complicated dataset. I guess it is somewhat a question about how much work you have to put in vs how much work you get out of the LLM, and what is the barrier of entry.
comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-07-02T08:59:53.141Z · LW(p) · GW(p)
I suspect e.g. with more explicit prompting about e.g. not validating on the test set, the models might do even better. See e.g. the more explicit prompts in https://arxiv.org/abs/2402.17453, which seems SOTA at these kinds of tasks.
comment by Oleg Trott (oleg-trott) · 2024-07-03T16:29:16.631Z · LW(p) · GW(p)
This looks similar, in spirit, to Large Language Models as General Pattern Machines: