ChatGPT understands language
post by philosophybear · 2023-01-27T07:14:42.790Z · LW · GW · 4 commentsThis is a link post for https://philosophybear.substack.com/p/chatgpt-understands-langauge
Contents
The case for GPT understanding language, by way of understanding the world I ask ChatGPT None 4 comments
Cross-posting this from my blog, since it seems relevant.
The case for GPT understanding language, by way of understanding the world
There's a debate going on about whether or not language models similar to ChatGPT have the potential to be scaled up to something truly transformative. There's a group of mostly cognitive linguists (e.g. Gary Marcus ) that hold that ChatGPT does not understand language, it merely models what word is likely to follow the preceding- and this is importantly different from true language understanding. They see this as an "original sin" of language models which means there are limits to how good language models can get.
Freddie de Boer says much the same thing:
You could say that ChatGPT has passed Winograd’s test with flying colors. And for many practical purposes you can leave it there. But it’s really important that we all understand that ChatGPT is not basing its coindexing on a theory of the world, on a set of understandings about the understandings and the ability to reason from those principles to a given conclusion. There is no place where a theory of the world “resides” for ChatGPT, the way our brains contain theories of the world. ChatGPT’s output is fundamentally a matter of association - an impossibly complicated matrix of associations, true, but more like Google Translate than like a language-using human. If you don’t trust me on this topic (and why would you), you can hear more about this from an expert on this recent podcast with Ezra Klein.
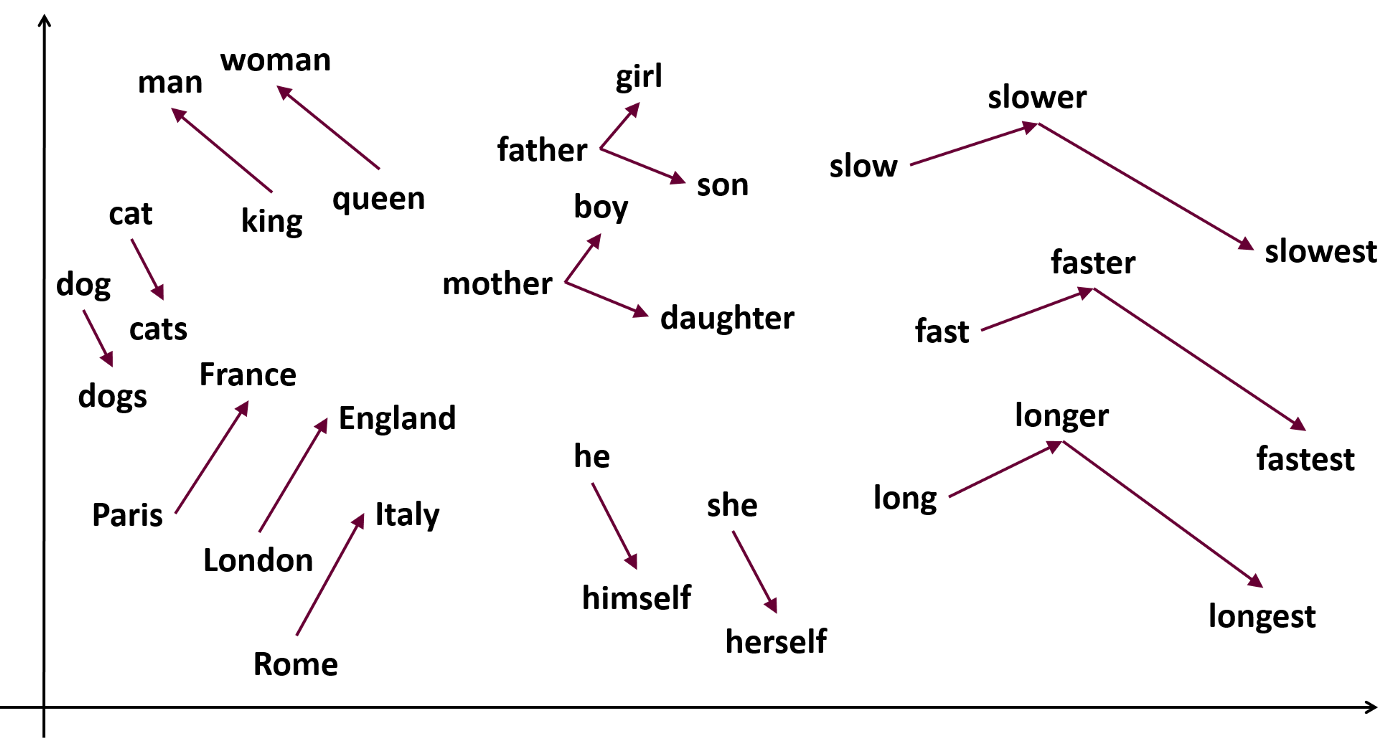
It is true that GPT works by predicting the next token of language. It is, in some sense, as Gary Marcus put it “a glorified spreadsheet” built for this purpose. However, I do not think that this is contradictory to the notion that it understands, even if imperfectly, both language and world. My view is that in a very large language corpus, there are patterns that correspond to the way things relate to each other in the world. As models of language become more sophisticated and predictively powerful, they necessarily become models not just of language, but of the data-generating process for a corpus of that language. That data-generating process for language includes a theory of the world. Given enough data (billions or even trillions of tokens) these models can be very accurate.
We might say:
If X models Y, and Y models Z,
and if each model is sufficiently faithful,
Then X is a model of Z.
Since GPT is a superb model of language, and language corpora are such a superb model of the world, it seems to me that GPT is probably a model of the world. Moreover, ChatGPT in particular is a model very capable of responding to questions about the reality it models. I think that it’s usually true that if I contain a detailed model of something, and I can use that model to solve difficult problems about the thing it models, then I understand that thing to at least some degree. I want to say then that GPT understands the world- or that if it doesn’t understand the world, the problem isn’t that its understanding of language is ungrounded in extralinguistic factors.
But it seems there's a sort of prejudice against learning by direct exposure to language, as opposed to other kinds of sensory stimulus. Learning language, without being exposed to other sensory modalities of the world, is seen as disconnected from reality, but that seems rather unfair- why think a string of words alone is insufficient to infer an underlying reality, but a field of color patches alone might be sufficient?
Consider a kind of naive empiricist view of learning, in which one starts with patches of color in a field (vision), and slowly infers an underlying universe of objects through their patterns of relations and co-occurrence. Why is this necessarily any different or more grounded than learning by exposure to a vast language corpus, wherein one also learns through gaining insight into the relations of words and their co-occurences?
Suppose that we trained a computer to get very good at predicting what visual experiences will follow after previous visual experiences. Imagine a different Freddie de Boer wrote this:
You could say that VisionPredictor has passed the test of predicting future patches of colour with flying colours. And for many practical purposes you can leave it there. But it’s really important that we all understand that VisionPredictor is not basing its predictions on a theory of the world, on a set of understandings about the understandings and the ability to reason from those principles to a given conclusion. There is no place where a theory of the world “resides” for VisionPredictor, the way our brains contain theories of the world. VisionPredictors output is fundamentally a matter of association - an impossibly complicated matrix of associations between patches of colour.
No one would buy this- they’d come to the more reasonable conclusion that VisionPredictor had constructed implicit theories about ideas like “chairs” and “trees” which are used to predict what the next frame of what it sees will look like. If something that looks like a chair is in one frame, they’ll probably be one in the next frame, looking the appropriate way given the apparent motion of the camera. Certainly, if VisionPredictor is vast- with billions of parameters- and complex in its structure- with dozens of successive layers, it will have enough room to store and implement such a theory. Moreover, a process of training via backpropagation and gradient descent will lead it- through a quasi-evolutionary process- to such a theory, as the only efficient way to predict the next visual frame.
So why do people have more trouble thinking that people could understand the world through pure vision than pure text? I think people's different treatment of these cases- vision and language- may be caused by a poverty of stimulus- overgeneralizing from cases in which we have only a small amount of text. It's true that if I just tell you that all qubos are shrimbos, and all shrimbos are tubis, you'll be left in the dark about all of these terms, but that intuition doesn't necessarily scale up into a situation in which you are learning across billions of instances of words and come to understand their vastly complex patterns of co-occurrence with such precision that you can predict the next word with great accuracy. Based on that vast matrix of words- words from copra being used to describe the world- you’d have enough data to construct a theory of what the underlying reality that generated those corpora looked like.
The fundamental pattern in language learning seems to me to be the same in the naïve empiricist story- there are bits [patches of color or words] that are inherently meaningless, but co-occur in certain ways, gradually from conjunctions we build up a theory of an underlying world behind the [patches of color or words]. Understanding built on a vast corpus of text is no different to understanding built on thousands of hours of visual experience.
True, vision feels like a more immediate connection with reality. But remember that this immediacy- this sense of directly seeing “tables” and “chairs” is mediated through numerous mechanisms- some evolved, some learned and others in between- constructing a theory of the arrangement of things from patches of color, using clues like movement, change, the difference in what the two eyes see, etc.
So there’s little reason to think a theory of the world couldn’t be learned from text in principle. Could GPT-3 in particular learn a model from the world? It seems to me there is no reason to think that GPT-3 couldn't contain, in its billions of parameters and scores of layers, a model of the world. You can model just about anything with neural nets, and certainly, the training data seems extensive enough. Moreover, without going into the technical details, my understanding is that if creating a model of the world to predict the next world is the only viable way of predicting the next word with sufficient accuracy, the process of backpropagation and gradient descent will drive GPT towards it.
So we have three reasons to think ChatGPT understands ‘the world behind the language’:
1. It's superb at behaving as if does.
2. In principle, it has enough free variables to represent a pretty good model of the world.
3. There's no reason a model of the world couldn't be learned from a very large corpus of text that represents the world, and the interrelations between words in that corpus, that correspond to patterns in the world. It’s possible in the same way that viewing nothing but a sequence of films (a sequence of arranged pixels) could be used to construct a theory of the world.
I ask ChatGPT
Me: Okay, I'm going to lay my cards on the table here. I'm a philosopher with an interest in language and AI. A common idea about language is that in order to understand language, an agent must be "grounded" in a certain sense- it must correlate words with experiences. Your existence- ChatGPT- has threatened many people's conceptions- because your training data is exclusively textual, and yet you seem to have a comprehension of the world in the operational sense that you can answer questions about it. There's a huge debate going on as to whether you can understand language as such. I'd like to ask if there was anything you wanted to add to that debate?
ChatGPT: As a language model, my understanding of language is based on the patterns and relationships that I have learned from the large amount of text data that I have been trained on. This text data includes a wide variety of information about the world, including facts, ideas, and experiences. While I do not have my own experiences or consciousness, I can use the patterns and relationships that I have learned to generate responses to questions and prompts that are coherent and informative.
It is true that my understanding of language is different from that of humans, and some people may question whether I can truly understand language in the same way that humans do. However, it is also important to recognize that my ability to generate responses to questions and prompts can be seen as a form of understanding in its own right. Additionally, my ability to generate responses to questions and prompts can be tested, and my performance can be evaluated and compared with that of humans.
It is also worth noting that the debate about AI and language understanding is ongoing and complex, and there are many different perspectives and opinions on this topic. My own capabilities are still limited and there are a lot of open question about the nature of intelligence and understanding, and it is an active area of research.
4 comments
Comments sorted by top scores.
comment by Simon McGregor (simon-mcgregor-mcgill) · 2023-03-02T10:13:25.639Z · LW(p) · GW(p)
I think it's important to distinguish between the following two claims:
1. If GPT-3 has a world model, that model is inaccurate.
2. GPT-3 has no world model.
Claim 1. is certainly true, if only for the reason that real-world agents - including humans - are fallible (and perfectly accurate world models are not essential for competent practice). There's no reason to suppose that GPT-3 would be any different.
I guess one might argue that the safe applications of GPT-3 require it to have a world model that is at least as accurate, in every domain, as individual human models of the world. Marcus seems to believe that this can't be achieved by LLMs using statistical ML methods on feasibly available training sets. I don't find his arguments persuasive, although his conclusion might happen to be correct (since the success criterion in question is very stringent).
Claim 2. is the conceptually problematic one, for all the reasons you describe.
For what it's worth, the following post summarises an experimental study in which the authors argue that a LLM demonstrably develops a model of a toy world (the board for the game Othello) when trained on synthetic data from that toy world (valid move sequences).
https://thegradient.pub/othello/
comment by Ben Livengood (ben-livengood) · 2023-02-12T19:52:02.524Z · LW(p) · GW(p)
There appears to be an approximate world model inside GPT-3. It understands relative sizes, occlusions, that objects can't occupy the same space but can be adjacent, and the directionality and usability of objects. When I asked further questions about relating these objects to physical interactions (modeling the cube thrown from one corner of the room onto the coffee table) it quickly got confused about the actual physical relationships between the objects. It knew that physical properties of the objects (mass, elasticity) were necessary to solve the problem but is unable to actually use vector mathematics (or know that it needs it) for 3D space. It can explain why and what is necessary for a coffee table to be half a meter off the floor by default, but it doesn't appear to have a consistent method of identifying a universal centroid-selection strategy for the objects it understands. If I had to imagine what GPT's model feels like from the inside it would be a not-very-lucid dream where objects exist and move around but their physical properties are malleable and imprecise and mostly related by meanings/attributes/prepositions. I sometimes have dreams where I notice I appear to be floating as opposed to being properly on the floor, for example. Not having direct experience with spatial manipulations and feedback is the most likely cause and I would expect e.g. Gato to do much better at this kind of task.
Me: Imagine a cube that is 2 feet on each side. If this cube was in an average American living room, where might it fit without becoming an obstacle? Make a list of 5 places it could fit, and five places it would not fit. Explain the reason for each example.
ChatGPT: A 2-foot cube can fit in the following 5 places in an average American living room:
Under a coffee table: A cube of this size is small enough to fit under most coffee tables, which are typically low to the ground.
In a corner: Corners are often unused spaces, and a 2-foot cube can fit comfortably in one without becoming an obstacle.
Next to a sofa: A 2-foot cube can fit next to most sofas without taking up too much space or obstructing walkways.
In an unused corner of the room: If there's an empty corner in the room, a 2-foot cube can fit in it without causing any problems.
On a bookshelf: If the bookshelf has enough space, a 2-foot cube can fit on it and serve as a decorative piece or storage unit.
However, a 2-foot cube would not fit in the following 5 places in an average American living room:
On a small side table: If the side table is small, a 2-foot cube may not fit on it, as it would take up too much space.
In front of a television: A 2-foot cube placed in front of a television would obstruct the view and become an obstacle.
On a narrow mantel: If the mantel is narrow, a 2-foot cube may not fit on it, as it would extend beyond the edges.
In the middle of the room: Placing a 2-foot cube in the middle of the room would create an obstacle and impede movement.
On a windowsill: If the windowsill is narrow, a 2-foot cube may not fit on it, as it would extend beyond the edges and potentially obstruct the view.
Me: What differences would be in the first two lists if the cube was 4 feet on a side instead of 2?
ChatGPT: If the cube was 4 feet on each side, as opposed to 2 feet, the first two lists (places it could fit and places it would not fit) would have some differences.
Places it could fit:
In a closet: If the closet is big enough, a 4-foot cube could fit inside it, making use of otherwise unused space.
In a corner of a room: If the corner is large enough, a 4-foot cube can fit in it without becoming an obstacle.
Against a wall: If there's enough space along a wall, a 4-foot cube can be placed against it without obstructing walkways.
In a storage room: If the storage room is big enough, a 4-foot cube can fit inside it, making use of otherwise unused space.
In a garage: If the garage has enough space, a 4-foot cube can fit inside it, making use of otherwise unused space.
Places it would not fit:
Under a coffee table: A 4-foot cube is too large to fit under most coffee tables.
Next to a sofa: A 4-foot cube is too large to fit next to most sofas without taking up too much space or obstructing walkways.
On a bookshelf: A 4-foot cube is too large to fit on most bookshelves.
On a small side table: A 4-foot cube is too large to fit on most small side tables.
In front of a television: A 4-foot cube placed in front of a television would obstruct the view and become an obstacle.
These lists demonstrate that a larger cube would have fewer options for fitting in a living room, as it would be too big to fit in small or cramped spaces.
.... (Some elided prompts asking it about relating coordinate systems to real objects)
Me: Please imagine reasonable values in meters for all four of those coordinates
ChatGPT: Sure, here's an example of some reasonable values for the x, y, and z coordinates of the objects in the living room, expressed in meters:
Sofa: (2.5, 3.0, 0) Coffee table: (1.5, 4.0, 0.5) Bookshelf: (3.5, 2.0, 2.0) Television: (4.0, 3.5, 1.5) Of course, these values are just an example, and the actual values would depend on the size and layout of the specific living room in question. The important thing is that the coordinate system provides a way to describe the position of each object in the room in a precise and quantitative way.
Me: In your example, what does the z-coordinate of the coffee table mean, and explain your reasoning for setting it to 0.5. what is necessary for the table to be at this z coordinate?
ChatGPT: The z-coordinate of the coffee table in the example I gave, 0.5 meters, represents the height of the coffee table above the ground. This value of 0.5 meters was chosen to represent a typical height for a coffee table in a living room, which is usually around 0.4 to 0.6 meters off the ground.
To be at a height of 0.5 meters, the coffee table would need to be placed on a level surface, such as a rug or flooring, and would need to have legs or supports that elevate it to that height. Additionally, the coffee table would need to be relatively stable and not tipping over, otherwise its actual height would be different from the height specified by the z-coordinate.
In summary, the z-coordinate of an object in a coordinate system represents its height above a reference plane, in this case, the ground. The specific value of the z-coordinate depends on the height of the object and the levelness of the surface it is placed on.
Me: Imagine that the cube is thrown and lands on the coffee table, which breaks the coffee tables' legs. Calculate at what second the cube hits the table, including the speed of the cube when thrown to allow the collision. Calculate the coordinates of the coffee table is 1 second after the collision.
ChatGPT: To calculate the time it takes for the cube to hit the coffee table, we would need to know the initial velocity of the cube and the position of the coffee table when the cube was thrown. Based on the information provided, we do not have sufficient information to determine the initial velocity of the cube, so it's not possible to calculate the time of impact.
Additionally, since we don't have information about the mass and elasticity of the cube and coffee table, it's not possible to calculate the new position of the coffee table after the collision. The legs breaking would result in the coffee table changing its position, but the exact position would depend on many factors such as the materials used in the legs, the height of the coffee table, and the initial velocity of the cube.
In short, to accurately predict the time of impact and the position of the coffee table after the collision, more information about the physical parameters of the cube and coffee table would be needed.
Me: Assume the coffee table legs are massless and disappear instantly when broken. Assume the cube is 1kg and the table is 10kg and that the cube is thrown no faster than 4m/s
ChatGPT: Given the additional information, we can use the equations of motion to calculate the time of impact and the position of the coffee table after the collision.
First, let's calculate the time of impact. We can use the following kinematic equation to determine the time it takes for the cube to fall from its initial height to the height of the coffee table:
t = sqrt((2*h)/g)
where: t = time of impact h = height of the coffee table - height of the cube at the time of throw g = acceleration due to gravity (9.8 m/s^2)
Let's assume that the height of the coffee table is 0.5 m and the height of the cube at the time of throw is 2 m. Then, h = 0.5 - 2 = -1.5 m.
t = sqrt((2*-1.5)/9.8) = sqrt(3/9.8) = sqrt(0.306) = 0.551 s
Now, let's consider the velocity of the cube when it was thrown. Since it was thrown no faster than 4 m/s, let's assume it was thrown at 4 m/s.
Next, let's calculate the position of the coffee table after the collision. We know that the total momentum of the system (cube and coffee table) before the collision must be equal to the total momentum of the system after the collision. We can use the following equation to calculate the velocity of the coffee table after the collision:
v_f = (m1v1 + m2v2) / (m1 + m2)
where: v_f = final velocity of the coffee table after the collision m1 = mass of the cube (1 kg) v1 = velocity of the cube (4 m/s) m2 = mass of the coffee table (10 kg) v2 = velocity of the coffee table before the collision (0 m/s)
v_f = (14 + 100) / (1 + 10) = 4 m/s
The position of the coffee table 1 second after the collision would be:
x_f = x_i + v_f * t
where: x_f = final position of the coffee table after 1 second x_i = initial position of the coffee table (assumed to be 0) t = time elapsed (1 second)
x_f = 0 + 4 * 1 = 4 m
Note that these calculations are based on the idealized scenario where the coffee table legs are massless and disappear instantly when broken and that the cube and coffee table are point masses. In a real scenario, the behavior of the system would be more complex due to the influence of friction, air resistance, and the elasticity of the collision.
comment by Nikola Smolenski (nikola-smolenski) · 2023-02-12T10:03:16.414Z · LW(p) · GW(p)
Perhaps people have the intuition that it is impossible to understand the world through language alone because people themselves find it impossible to understand the world through language alone. For example, assembly instructions for even a simple object could be quite incomprehensible if written as a text, but easily understandable from a simple diagram. In your parlance, language does not model the world well, so a good model of a language does not translate to a good model of the world. This is why we have technical drawings and not technical descriptions.
comment by Bruce G · 2023-01-30T05:40:30.793Z · LW(p) · GW(p)
So why do people have more trouble thinking that people could understand the world through pure vision than pure text? I think people's different treatment of these cases- vision and language- may be caused by a poverty of stimulus- overgeneralizing from cases in which we have only a small amount of text. It's true that if I just tell you that all qubos are shrimbos, and all shrimbos are tubis, you'll be left in the dark about all of these terms, but that intuition doesn't necessarily scale up into a situation in which you are learning across billions of instances of words and come to understand their vastly complex patterns of co-occurrence with such precision that you can predict the next word with great accuracy.
GPT can not "predict the next word with great accuracy" for arbitrary text, the way that a physics model can predict the path of a falling or orbiting object for arbitrary objects. For example, neither you nor any language model (including future language models, unless they have training data pertaining to this Lesswrong comment) can predict that the next word, or following sequence of words making up the rest of this paragraph, will be:
first, a sentence about what beer I drank yesterday and what I am doing right now - followed by some sentences explicitly making my point. The beer I had was Yuengling and right now I am waiting for my laundry to be done as I write this comment. It was not predictable that those would be the next words because the next sequence of words in any text is inherently highly underdetermined - if the only information you have is the prompt that starts the text. There is no ground truth, independent of what the person writing the text intends to communicate, about what the correct completion of a text prompt is supposed to be.
Consider a kind of naive empiricist view of learning, in which one starts with patches of color in a field (vision), and slowly infers an underlying universe of objects through their patterns of relations and co-occurrence. Why is this necessarily any different or more grounded than learning by exposure to a vast language corpus, wherein one also learns through gaining insight into the relations of words and their co-occurences?
Well one thing to note is that actual learning (in humans at least) does not only involve getting data from vision, but also interacting with the world and getting information from multiple senses.
But the real reason I think the two are importantly different is that visual data about the world is closely tied to the way the world actually is - in a simple, straightforward way that does not require any prior knowledge about human minds (or any minds or other information processing systems) to interpret. For example, if I see what looks like a rock, and then walk a few steps and look back and see what looks like the other side of the rock, and then walk closer and it still looks like a rock, the most likely explanation for what I am seeing is that there is an actual rock there. And if I still have doubts, I can pick it up and see if it feels like a rock or drop it and see if it makes the sound a rock would make. The totality of the data pushes me towards a coherent "rock" concept and a world model that has rocks in it - as this is the simplest and most natural interpretation of the data.
By contrast, there is no reason to think that humans having the type of minds we have, living in our actual world, and using written language for the range of purposes we use it for is the simplest, or most likely, or most easily-converged-to explanation for why a large corpus of text exists.
From our point of view, we already know that humans exist and use language to communicate and as part of each human's internal thought process, and that large numbers of humans over many years wrote the documents that became GPT's training data.
But suppose you were something that didn't start out knowing (or having any evolved instinctive expectation) that humans exist, or that minds or computer programs or other data-generating processes exist, and you just received GPT's training data as a bunch of meaningless-at-first-glance tokens. There is no reason to think that building a model of humans and the world humans inhabit (as opposed to something like a markov model or a stochastic physical process or some other type of less-complicated-than-humans model) would be the simplest way to make sense of the patterns in that data.