Blog post: A tale of two research communities
post by Aryeh Englander (alenglander) · 2020-08-12T20:41:30.448Z · LW · GW · 0 commentsContents
Blog post: A tale of two research communities Assuring autonomy AI Safety Integrating the fields None No comments
This is a copy of a blog post from Francis Rhys Ward, an incoming doctoral student in Safe and Trusted AI at Imperial College London. I just discovered this on the website of the Assuring Autonomy International Programme and thought it was worth cross-posting here.
The post is also available on Medium.
(Francis, if you're reading this, thanks for the shout-out!)
Blog post: A tale of two research communities
POSTED ON TUESDAY 11 AUGUST 2020
What “AI safety” means to them both and steps to collaboration

The term “AI safety” means different things to different people. Alongside the general community of artificial intelligence (AI) and machine learning (ML) researchers and engineers, there are two different research communities working on AI safety:
- The assuring autonomy/safety engineering field: a community of experts with a long history in assuring real-world autonomous systems (not just AI and ML!)
- The AI safety/longtermist community: a relatively new field focused on the consequences of transformative AI (TAI), artificial general intelligence (AGI), and smarter than human AI
Having worked at the Assuring Autonomy International Programme (AAIP), and now researching how AI can learn human values at Imperial College London, I am interested in how both communities can learn and benefit from each other. Here I’ll give a brief overview of these fields, point to some key resources within them, and try to highlight the benefits of integrating these communities. This post is primarily intended for researchers from either field who wish to gain insight into the other.
Assuring autonomy
The assuring autonomy community is part of the wider field of safety engineering for complex systems. This community focuses on practical issues surrounding current and near-term technologies, with the typical approach being to set safety requirements for a system and generate evidence that requirements have been met, including integrated utilisation of expert knowledge, testing, verifying, validating, as well as regulation.
Historically, work has been done on problems related to autonomous systems in general (such as assistive flight technologies) and more recently the field has shifted focus to AI and ML (e.g. with the AAIP, Darpa’s Assured Autonomy Program, and more recent Johns Hopkins Institute for Assured Autonomy).
Work such as Assuring the Machine Learning Lifecycle introduces the first systematic break down of the ML lifecycle (i.e. the entire process of ML development, from data collection to operation, shown below). This paper defines assurance desiderata for each stage in this process, reviews existing methods for achieving these desiderata, and identifies open challenges (e.g. the table below presents desiderata and methods for the assurance of the model verification stage).
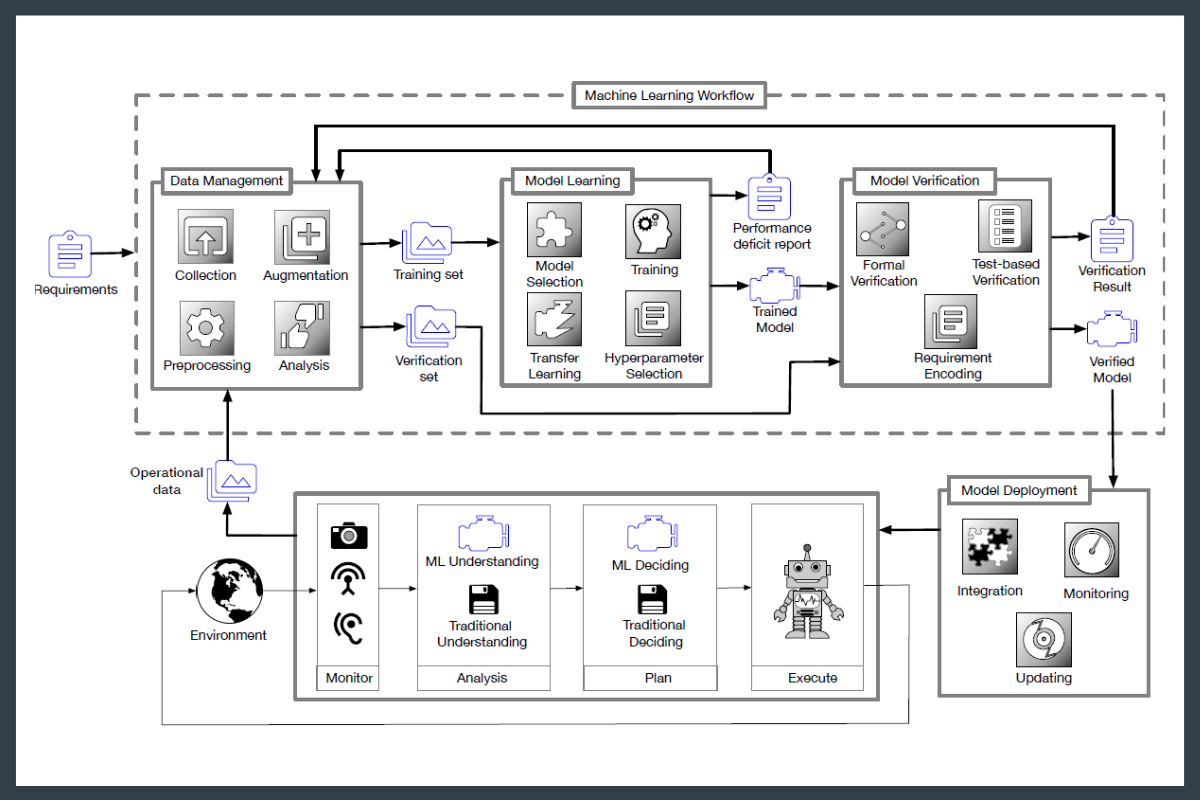
The machine learning lifecycle
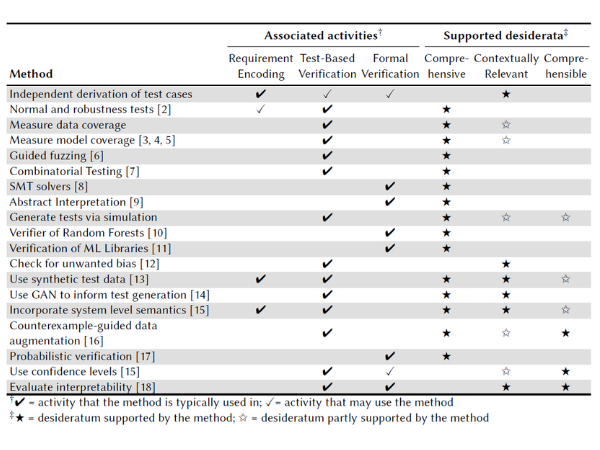
Assurance methods for the model verification stage
The AAIP’s Body of Knowledge is another resource aimed at providing practical guidance on assurance and regulation to developers of autonomous technologies. Different stakeholders may access this knowledge base with queries related to their needs (e.g. the use of Systems-Theoretic Processes Analysis (STPA) for hazard analysis for a cobot system, or using simulation as an assurance method for autonomous vehicles).
Overall the assuring autonomy field presents practical methods for, and expertise in, building safe autonomous technologies.
AI Safety
This field really started with:
- Bostrom’s Superintelligence
- discussion of the AI-alignment problem
- the ensuing deep learning revolution.
In the past decade, a serious research community has emerged, focused on the safety of smarter-than-human AI, including prominent members of the AI community such as Stuart Russel and researchers at DeepMind and OpenAI. Classic work in this field attacks difficult foundational decision and game theoretic problems relating to the goals of powerful AI systems.
A key issue is intent or goal alignment — how do we get machines to want to do what we want them to do?
Current paradigms in AI and ML depend upon the framework of expected utility maximising agents (e.g. in reinforcement learning the agent wishes to maximise the expected reward). However, systematically writing down everything we care about into an objective function is likely impossible and by default, agents have unsafe incentives such as not being switched off.
For example, consider a robot with the goal of getting coffee. As Russel says, “You can’t fetch the coffee if you’re dead” — such an agent will incapacitate anyone who tries to prevent it from achieving its goal of getting you a Starbucks. Importantly, this is the standard way in which we currently build AI!
It is really non-trivial to make this paradigm safe (or change the paradigm under which we currently build AI). More recent work aims to research current AI techniques in order to gain insight into future systems (Concrete Problems in AI Safety is a seminal overview) and more nuanced arguments and subfields aimed at solving a variety of problems relating to the safety of AGI have emerged (prominent research communities exist at DeepMind, OpenAI, Future of Humanity Institute, Center for Human-Compatible Artificial Intelligence, Machine Intelligence Research Institute).
Integrating the fields
Below is a conceptual breakdown of problems in technical AI safety from DeepMind. They highlight challenges in:
- specification (including the alignment problem)
- robustness (relating to how systems deal with perturbations in their operational environment)
- assurance (defined as the monitoring and control of systems in operation).
Of course, these categories are not cleanly disjoint and ensuring real-world systems are safe will necessitate solving problems across each category. However, this conceptual breakdown takes a step in the direction of applying ideas from safety engineering to increasingly powerful AI systems.
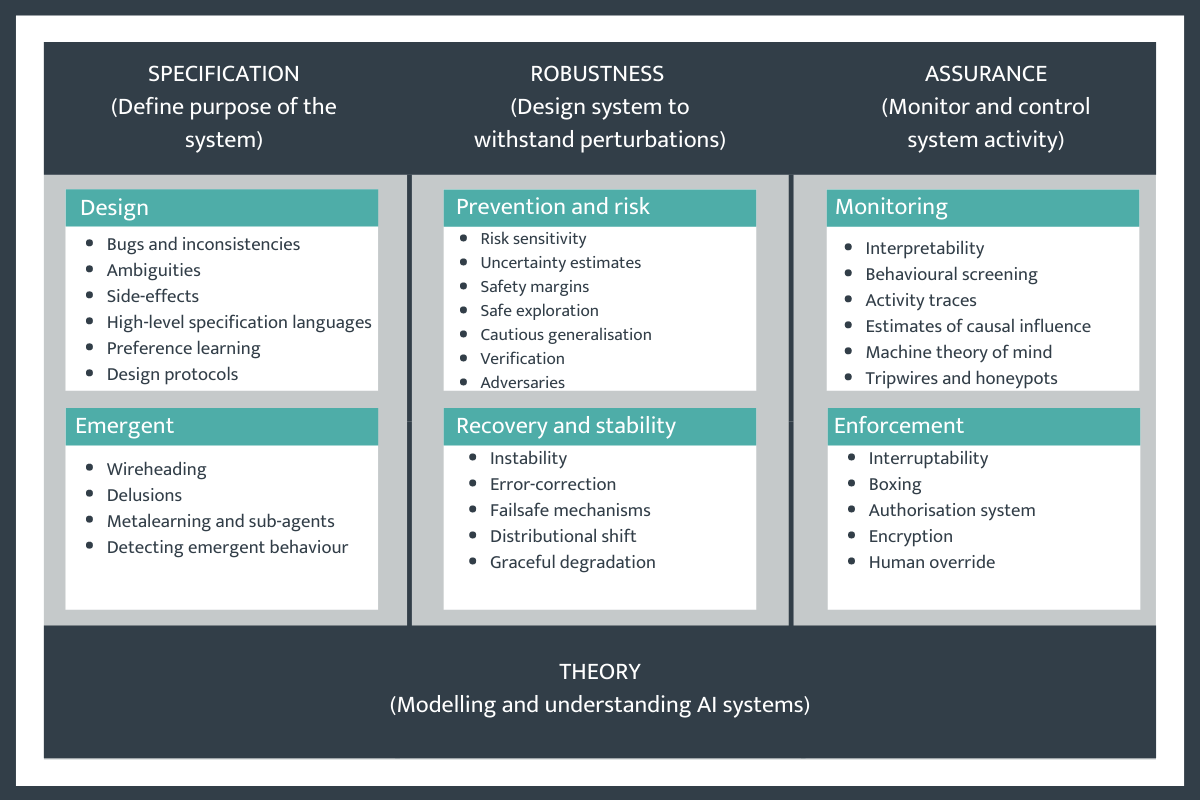
Three AI safety problem areas from Deepmind Safety Research
A recent talk by Aryeh Englander at Johns Hopkins [AF · GW] also highlights the need for further awareness and collaboration between the AI safety and assuring autonomy communities. I think that understanding the perspectives in either community will only help the other; for instance, the assuring autonomy community may benefit from an appreciation of the challenges surrounding AGI, and methods from safety engineering may help to address these challenges.
Another troubling matter is that even non-safety-critical AI may have deeply troubling effects on society. One example is the reinforcement learning systems used by social media platforms such as Facebook; these systems are designed to maximise “click-through” and instead of achieving this goal by showing you things that you like to click on, some argue that these systems manipulate people into being predictable clickers by modifying human preferences into bubbles of ideological extremes. This is again a type of specification problem where machines with the goal of most effectively monetising our attention have found quite sinister solutions to this goal. As uninterpretable, objective maximising agents become more powerful new safety techniques need to be developed at the same rate. What will the consequences of OpenAI’s new language model, GPT-3 be, for instance? An AI which can convincingly hold a conversation, write a story or poem, do maths, and write code [LW · GW] but in a completely uninterpretable way, with its only goal to give reasonable-sounding answers, presents unprecedented safety challenges to each community interested in AI safety.
There are, of course, also many challenges related to AI ethics, fairness, bias, privacy, etc which I have not covered here but which require collaboration with philosophers, lawyers, and other communities in the social sciences. The challenges posed by powerful AI require increasingly interdisciplinary awareness and collaboration.
Francis Rhys Ward
Incoming Doctoral Student in Safe and Trusted AI
Imperial College London
0 comments
Comments sorted by top scores.